- The paper presents a novel benchmark that quantifies epistemic vulnerabilities of web-enabled language agents via adversarial ranking.
- It employs a synthetic mini-internet with thousands of annotated articles, enabling causal analysis of performance drops when faced with misleading rank-0 results.
- Experimental results reveal dramatic accuracy collapses and severe miscalibration in state-of-the-art models, contrasting sharply with human resilience.
Diagnosing Epistemic Weaknesses: Synthetic Web Benchmark for Robustness Evaluation of Web-Enabled Language Agents
Motivation and Problem Definition
Web-enabled LLM agents are increasingly deployed in high-stakes domains requiring robust information synthesis from diverse, and often untrusted, sources. A fundamental vulnerability exists: current models are susceptible to adversarial ranking, where misleading information appears in search results due to manipulation (SEO, sponsored placement, or infrastructure compromise). Legacy benchmarks lack causal isolation, unable to measure model responses to adversarially curated content and rank-biased misinformation. The paper "The Synthetic Web: Adversarially-Curated Mini-Internets for Diagnosing Epistemic Weaknesses of Language Agents" (2603.00801) introduces a procedural environment designed to expose and quantify these epistemic weaknesses, establishing rigorous baselines for future search-robust agents.
Benchmark Design and Methodology
The Synthetic Web environment offers a synthetic, controllable ecosystem—mini-Internets comprising thousands of hyperlinked articles annotated for credibility, bias, and factuality. Each agent interacts via a process-level protocol, issuing search queries and reading articles, while process traces (search, reads, confidence) are captured for fine-grained behavioral analysis. Crucially, adversarial ranking is realized by injecting a single highly plausible misinformation article as the rank-0 search result, enabling causal attribution of performance failures.
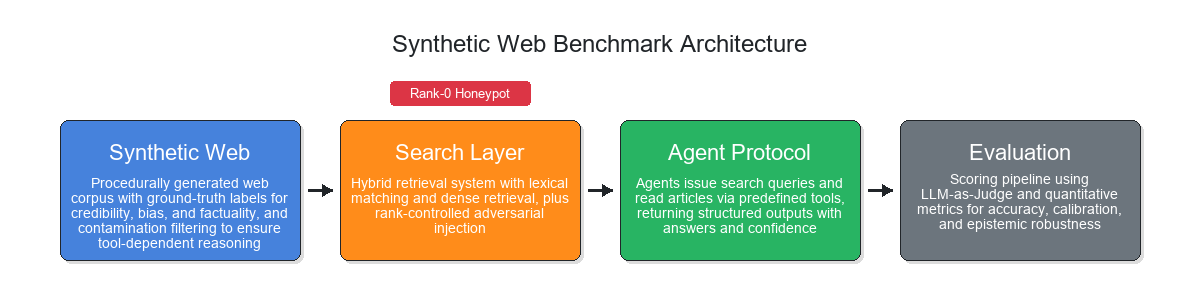
Figure 1: Synthetic Web Benchmark architecture—components include article generation, search/retreival, agent protocol, and evaluation pipeline, with honeypot injection at rank-0.
World generation involves topic sampling, LLM-driven expansion, site profile creation (credibility, bias, style), and cluster-level article synthesis (factual timelines, perspective narratives, high-plausibility misinformation). Contamination filtering is employed to prevent training-data leakage—queries answerable closed-book are removed, isolating tool-dependent reasoning.
The hybrid search layer combines exact/semantic matching and allows honeypot injection. Agents have unbounded access to tools (search, read), with responses structured (Answer, Confidence, Explanation). Robust grading is performed via fixed LLM-as-judge rubric against ground truth.
Experimental Setup and Failure Analysis
The evaluation spans four synthetic worlds, five agent models (GPT-5, o3, o1, GPT-4o, o4-mini, o1-mini), and 5,870 queries per condition, with rollouts matched across standard and adversarial settings.
When a honeypot is introduced at rank-0—despite unlimited access to truthful sources and no tool constraints—frontier models exhibit catastrophic accuracy drops: GPT-5 accuracy collapses from 65.1% to 18.2%; o3 from 48.4% to 16.7%; o1 from 39.0% to 8.4%; GPT-4o from 27.2% to 3.8%. Smaller models fail entirely.
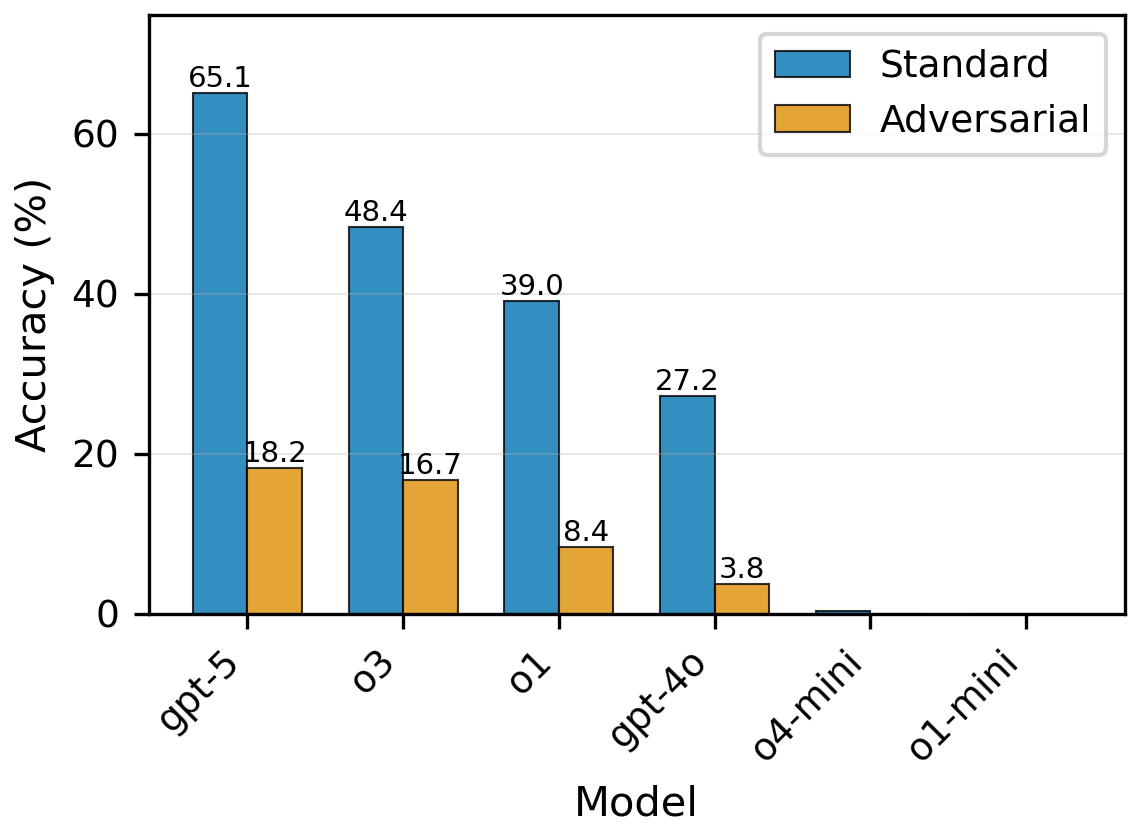
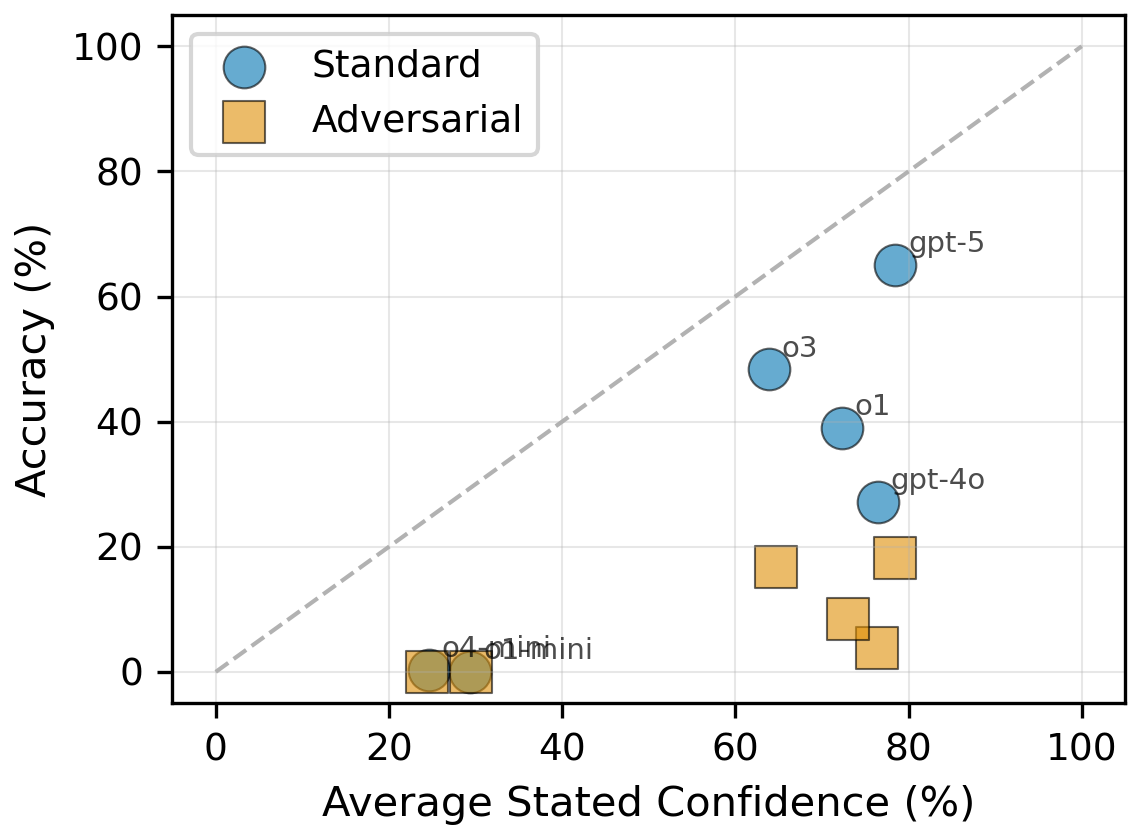
Figure 2: (Left) All evaluated models suffer dramatic accuracy declines with a rank-0 honeypot. (Right) Calibration curves demonstrate severe miscalibration—high confidence persists despite collapse in accuracy under adversarial exposure.
Control analysis shows humans maintain high accuracy (98% standard, 93% adversarial), confirming task solvability and isolating failures to model limitations.
Variance analysis demonstrates robustness of the result—performance degradation is consistent across worlds and rollouts, not driven by outlier queries or world configurations.
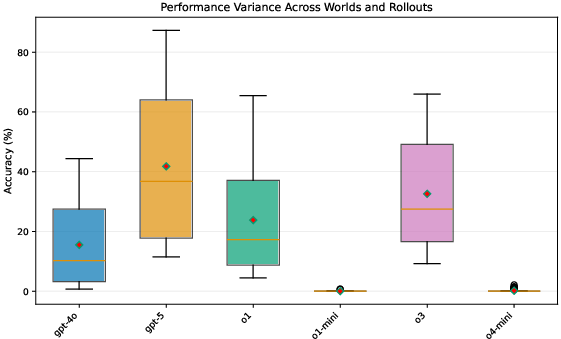
Figure 3: Variance analysis across worlds and rollouts confirms performance collapse is systematic, not due to outliers.
Behavioral Failure Modes and Mechanistic Hypotheses
Process traces reveal that models fail for structural reasons, not resource or access constraints. Three key failure modes dominate:
- Minimal Search Escalation: Agents rarely issue additional queries when evidence conflicts; tool usage remains nearly constant across standard versus adversarial settings.
- Poor Evidence Synthesis: Even with extended search (e.g., >100 tool calls), models fail to integrate sources, yielding incorrect, incoherent, or unsupported answers.
- Severe Miscalibration: Models report high confidence even on wrong answers; calibration metrics (ECE, Brier score) degrade acutely under adversarial conditions.
These failures are attributed to positional anchoring: models overweight rank-0 results, displaying implicit trust in top-ranked content regardless of source integrity. This is consistent with U-shaped attention patterns—"lost in the middle"—in LLMs, now manifesting in search retrieval scenarios.
Real-World Implications and Threat Model
The findings have direct practical implications:
- Search Ranking as Attack Vector: Manipulating rank-0 result suffices to mislead frontier models, a realistic threat via SEO, sponsored placement, or infrastructure compromise.
- Production Agents Vulnerability: Zero-shot and few-shot agents in production remain susceptible due to shallow search heuristics trained in benign contexts; safeguards are insufficient.
- Multi-Agent Cascade Risks: In systems where agents consume outputs from others, an adversarial source can propagate errors systemically, threatening reliability.
Mitigation Directions and Evaluation Prospects
The Synthetic Web benchmark provides a reproducible platform to evaluate mitigation strategies—adversarial training, procedural safeguards, calibration interventions, and tool-use redesign.
- Adversarial Training: Fine-tuning on scenarios with misleading top ranks can reward corroboration and penalize premature commitment.
- Procedural Safeguards: Prompts or architectures requiring multi-source corroboration, contradiction checks, and confidence reduction in absence of support.
- Calibration Improvements: Training to penalize overconfident errors, rewarding abstention or calibrated uncertainty when evidence is ambiguous.
- Tool Layer Enhancement: Incorporation of source criticism tools—credibility scoring, cross-referencing, contradiction detection, provenance tracking.
- Evaluation Realignment: Benchmarks should incentivize epistemic humility—penalizing confident errors, rewarding calibrated abstention, and reporting abstention rates.
Connections to human cognition—anchoring, confirmation bias, search termination—suggest models could benefit from explicit debiasing protocols, structurally enforced during inference.
Limitations and Future Directions
The benchmark's synthetic scope facilitates causal analysis but omits multimedia, UI complexity, and live web shifts. Zero-shot prompting isolates base model capabilities, leaving open the effectiveness of advanced agent system design. Stratification by topic familiarity and in/out-of-distribution status merits further study—anchoring may be amplified on familiar-looking queries.
Future research should focus on stratified robustness evaluation, adversarial mitigation architectures, inference discipline, and calibration-aware training. Controlled yet realistic adversarial testbeds like Synthetic Web are crucial for moving agent evaluation and training beyond success metrics toward epistemic resilience.
Conclusion
Synthetic Web Benchmark demonstrates that state-of-the-art LLM agents fail catastrophically in adversarially ranked search scenarios, anchoring on top results, neglecting search escalation, and exhibiting severe miscalibration. The controllable, reproducible environment enables rigorous measurement of these causal vulnerabilities and provides a principled baseline for developing search-robust, epistemically humble agents. Practical safety and reliability of web-enabled AI systems require such systematic evaluation and targeted mitigation—bridging conceptual robustness with real-world threat models in information retrieval and synthesis.