- The paper presents a novel scouting-first methodology that decouples repository exploration from content consumption to optimize token usage.
- It constructs a semantic-structural, multi-layered graph for precise cross-file dependency mapping, boosting reasoning accuracy.
- Empirical results reveal up to 90% cost reduction and significant performance gains on benchmark tasks compared to traditional methods.
FastCode: A Paradigm for Fast and Cost-Efficient Repository-Scale Code Reasoning
Introduction
Repository-scale code understanding and reasoning imposes unique challenges that stress both context window limitations and computational budget. Existing LLM-based code agents often leverage exhaustive or iterative exploration, which inflates token usage and can introduce semantic noise by ingesting excessive irrelevant context. The FastCode framework directly addresses these efficiency bottlenecks by fully decoupling repository exploration from content consumption through a structural scouting mechanism, a design that radically reconfigures how agents collect and construct high-value code contexts for downstream reasoning.
Semantic-Structural Code Representation
A crucial innovation in FastCode is the construction of a comprehensive, lightweight map for code repositories, preserving semantic and topological relationships often lost in standard RAG approaches. The code repository is formalized as a multi-layered directed graph where nodes encode code units at varying granularities (files, classes, functions, documentation) and edges represent dependency, inheritance, and call relations. By indexing both lexical and dense semantic views, FastCode enables high-recall, low-cost retrieval that is robust to both explicit identifier matches and more diffuse intent-based queries.
This representation enables precise traversal and navigation for task-specific reasoning, and the framework unifies sparse token-based matching (BM25) with dense embedding retrieval to maximize recall across diverse query forms.
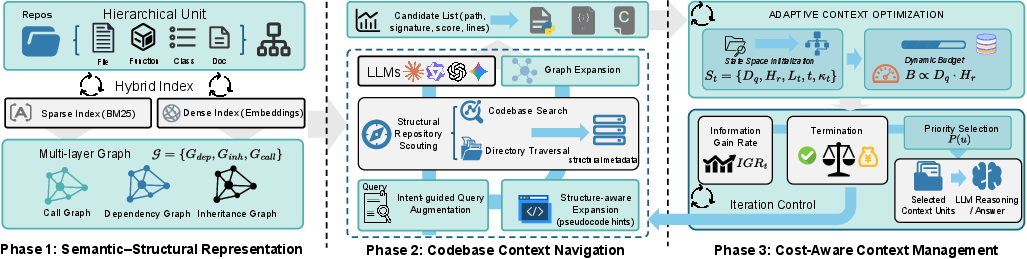
Figure 1: The overall framework of FastCode integrating hierarchical metadata indexing, multi-relational graph construction, and cost-aware navigation for high-value context selection.
Structural Scouting and Cost-Aware Navigation
The FastCode agent leverages its semantic-structural map for a two-phase workflow:
- Low-cost Scouting: Repository exploration is performed using only lightweight metadata—file paths, type signatures, docstrings, call/inheritance relations—greatly reducing initial token exposure. Navigation tools include directory scans and regex-enabled codebase search, returning only structural signals essential for candidate filtering. No full contents are ingested during this phase.
- Dependency-Guided Expansion: Candidates suggested by retrieval or tool-based exploration are then enriched via topological graph traversal, expanding the context set to include key transitive and non-lexical dependencies.
- Cost-Aware Context Construction: The framework then employs an adaptive, stateful management policy that dynamically balances the expected utility (relevance, informativeness) of additional content against current and projected token budget. Notably, the agent utilizes an explicit epistemic confidence estimator and incremental information gain to terminate context acquisition when further data is deemed low yield or cost-inefficient.
Empirical Results and Analysis
FastCode exhibits decisive improvements in both reasoning quality and cost-efficiency across all evaluated benchmarks. On SWE-QA and LongCodeQA, FastCode outperforms both direct LLM response and RAG/agentic pipelines in aggregate accuracy metrics (total scores of 43.28 vs. 32.30 for direct LLM on SWE-QA). The framework is especially effective for completeness and reasoning quality, demonstrating the role of precise structural context in enabling deep cross-file and multi-hop semantic reasoning.
Concurrently, FastCode achieves order-of-magnitude reductions in token usage and execution cost. For example, on LongCodeQA at the 256K token budget, FastCode reduces cost by over 90% while increasing accuracy by 17.9% relative to standard context ingestion. Similar gains manifest on complex localization (LOC-BENCH, GitTaskBench) and end-to-end repository tasks, where high-value context selectivity directly correlates with both success rate and practical deployment viability.
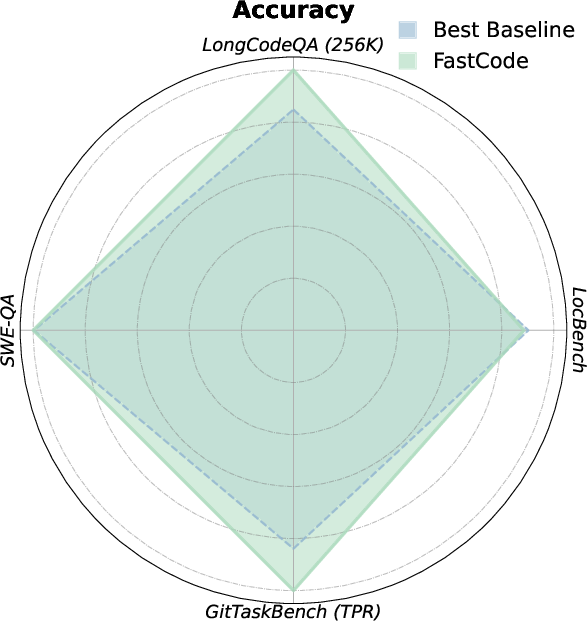
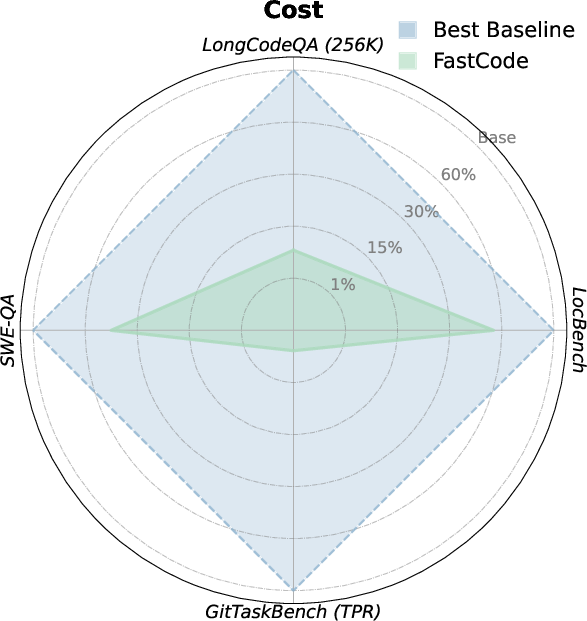
Figure 2: Accuracy and cost trade-off comparison highlighting FastCode's dominance in both dimensions relative to agentic and procedural baselines.
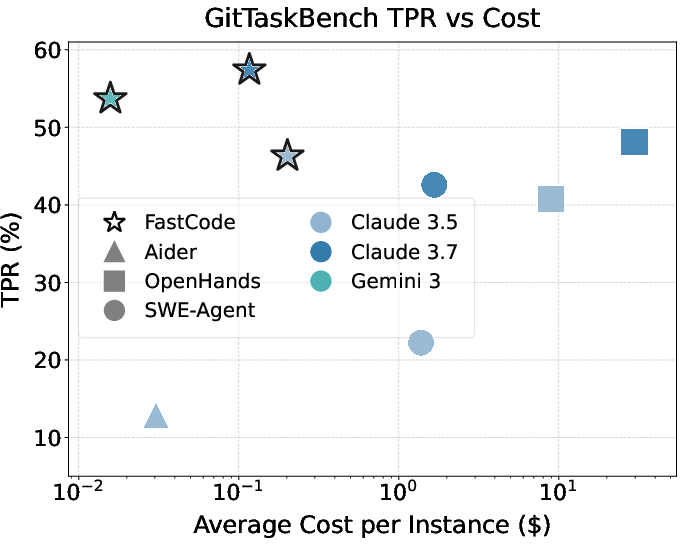
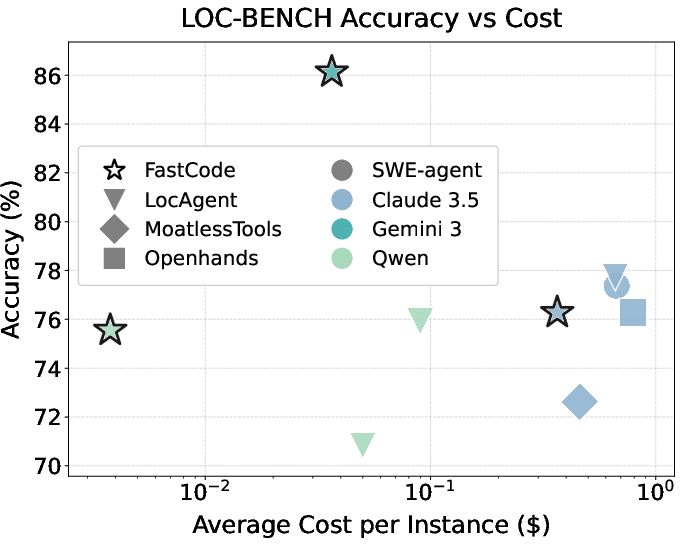
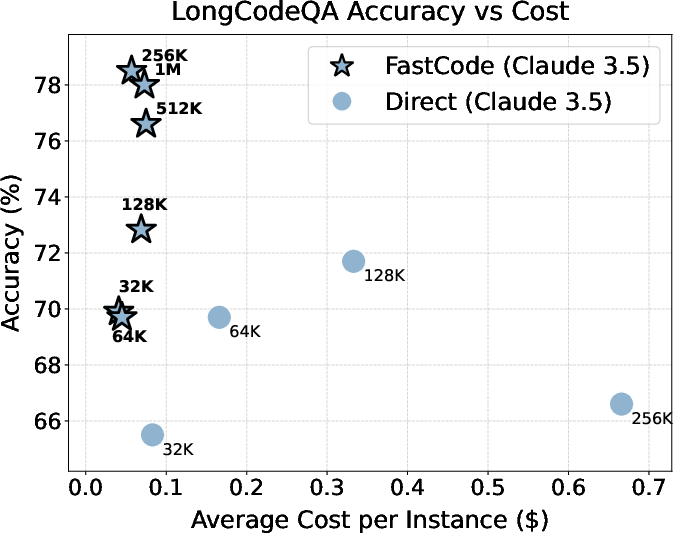
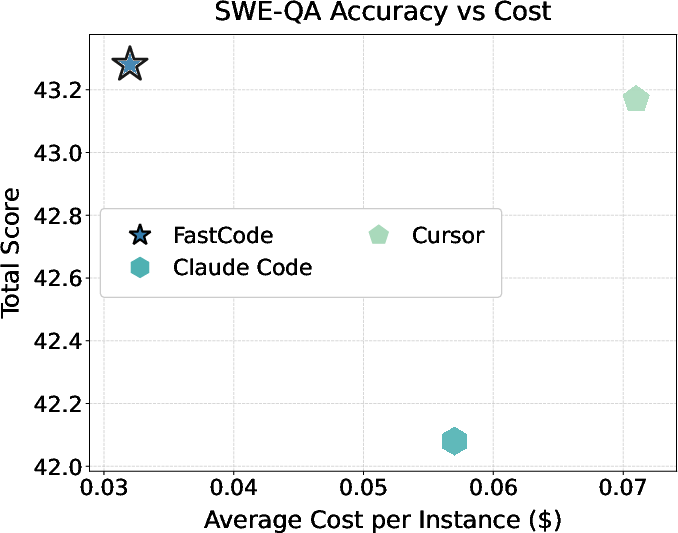
Figure 3: Performance-cost tradeoffs for baselines and FastCode across multiple code reasoning benchmarks.
File and Task Localization
On the SWE-Bench-Lite subset (LOC-BENCH), FastCode achieves 86.13% Acc@1 using Gemini-3-Flash, a substantial +8.39% increase over the best prior system, while being 18–22× more cost-efficient. This high-fidelity localization demonstrates superior dependency mapping and context curation, reinforced by the robustness of performance across different LLM backbones (with competitive accuracy even for small, open-weight models).
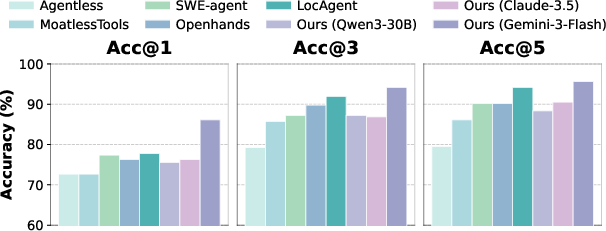
Figure 4: File-level localization accuracy (Acc@K) on Loc-Bench indicating FastCode’s high-precision localization across architectures.
End-to-End Task Execution
In the context of GitTaskBench, FastCode delivers task pass rates (TPR) of up to 57.41% (Claude 3.7 Sonnet) and ECR of 74.07%, compared to 40.74%/48.15% for OpenHands and 22.23% for SWE-Agent, all while incurring at least 15× lower average per-task cost. These results validate the framework’s practicality for real, non-trivial maintenance and upgrade workflows in software engineering.
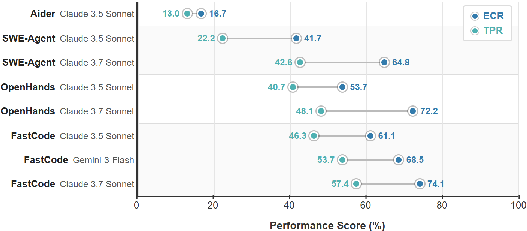
Figure 5: Performance of different frameworks on GitTaskBench, highlighting superior task completion rate of FastCode.
Ablation and Component Importance
Component ablations highlight that the hybrid retrieval (semantic and sparse), graph expansion, and cost-aware navigation mechanisms provide strictly additive performance benefits, with performance degrading most notably when query augmentation and metadata-based scouting are removed. The ablation studies confirm that bridging semantic gaps with structural hints and pruning search spaces with metadata-driven scouting are both necessary for optimal cost-efficiency.
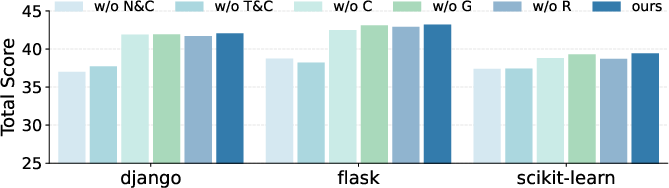
Figure 6: Ablation results on SWE-QA showing cumulative performance loss when key FastCode modules are disabled.
Practical and Theoretical Implications
FastCode’s approach establishes the computational and efficiency value of decoupling exploration (structural, metadata-driven) from consumption (selective, content-based) in code reasoning agents. This paradigm validates that a small, highly curated context window can fully substitute for or outperform direct ingestion of large code repositories, provided that topological and semantic relationships are captured upstream.
On a practical level, FastCode enables scalable, model-agnostic deployment in enterprise environments—local models can attain high SOTA-level performance with minimal API usage or cloud dependency, democratizing high-quality AI-powered code reasoning for resource-constrained scenarios. Theoretically, the results motivate further research into hybrid symbolic-neural frameworks for LLM reasoning, as well as refined confidence-based termination policies for context-constrained agentic search.
Future Directions
This work suggests several rich avenues for future AI research:
- Learning-Based Scouting Policies: While FastCode’s policies are rule-based, data-driven policies could adapt more efficiently to new code distributions, query types, or user intent.
- Generalization Across Domains: Extending structural scouting to multi-language software, documentation, and even multi-modal repositories (text, code, data) poses unique annotation and representation challenges.
- Integration with CI/CD and Automated Repair: Embedding cost-aware, high-precision code discernment into live development, deployment, and repair pipelines would further increase automation’s practical impact.
Conclusion
FastCode represents a substantive advance in repository-scale code reasoning by introducing a scouting-first methodology and cost-aware context construction. By utilizing explicit semantic-structural representations and adaptive navigation, the framework achieves state-of-the-art accuracy in multiple benchmarks while substantially reducing token and compute consumption. These results substantiate that high-fidelity repository reasoning can be decoupled from the inefficiencies of iterative agentic file exploration, providing an efficient, robust foundation for next-generation AI-assisted software engineering (2603.01012).