- The paper introduces ReGFT, a method leveraging partial reference hints to synthesize verifiable, model-generated reasoning trajectories that overcome reward sparsity.
- It demonstrates that RL models initialized with ReGFT exhibit faster convergence and higher accuracy on challenging mathematical problems.
- ReGFT combines model-generated and reference-guided trajectories to provide robust initialization and scalable improvements for mathematical reasoning tasks.
Reference-Guided Fine-Tuning Enables RL to Solve Hard Mathematical Problems
Motivation and Problem Statement
Reinforcement Learning (RL) has established itself as a robust paradigm for improving mathematical reasoning abilities in LLMs. The RL with Verifiable Rewards (RLVR) framework, which leverages rule-based verifiers for reward assignment based on correctness, eliminates dependency on human-labeled reward models and precisely incentivizes reasoning behaviors. Despite this, RLVR is fundamentally constrained by reward sparsity on hard mathematical problems—when the base model cannot produce correct reasoning trajectories, RL cannot provide meaningful feedback, and optimization stalls.
While training datasets for mathematical reasoning often include human-written reference solutions, directly fine-tuning on these references yields little benefit due to misalignment between model-generated reasoning and human proofs. Prior approaches such as ReFT (REinforced Fine-Tuning) (Luong et al., 2024) mitigate reward sparsity by fine-tuning solely on model-generated correct trajectories. However, these methods are ineffective on unsolvable hard problems where the base model fails to produce correct solutions.
Reference-Guided Fine-Tuning (ReGFT): Methodology
This paper introduces Reference-Guided Fine-Tuning (ReGFT), a mechanism for leveraging human-written reference solutions to synthesize verifiable, model-generated reasoning trajectories on hard problems. Rather than directly imitating reference solutions, ReGFT conditions the model on partial reference hints—high-level proof components or steps, without providing full solution details—then prompts the model to produce its own reasoning trace from this context. This ensures generated solutions are correctly guided but remain distributionally aligned with the model’s own generation process.
The ReGFT pipeline combines correct trajectories obtained via standard model sampling (as in ReFT) with reference-guided trajectories generated using partial hints for hard problems (defined as those with <25% accuracy under 16-sample model rollouts). Easier problems are excluded to avoid unnecessary overfitting. This regimen supplements the training set with newly accessible correct traces, densifying informative signals for subsequent RL.
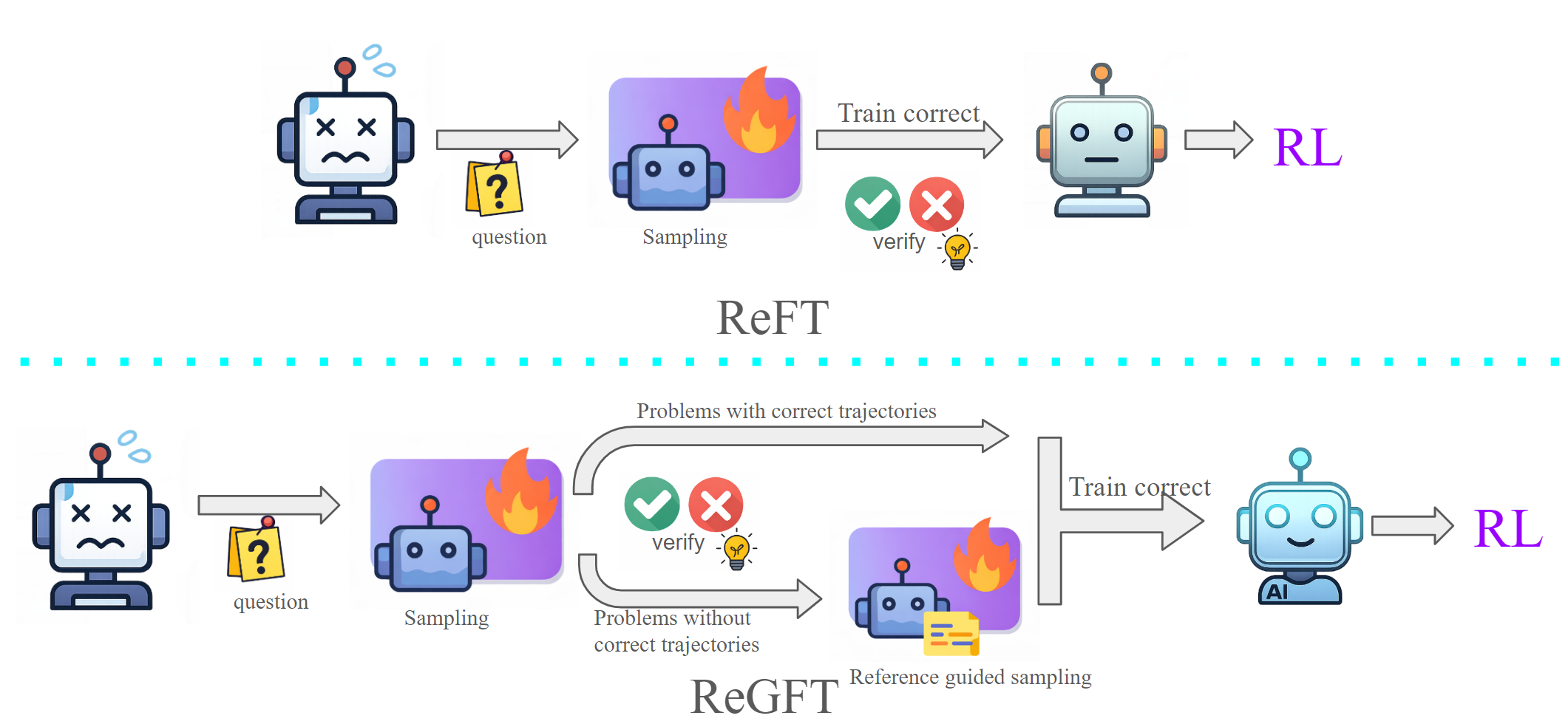
Figure 1: ReGFT recovers hard problems for which no correct trajectories exist by leveraging partial reference solutions for guided sampling; in contrast, ReFT only fine-tunes with correct model-generated trajectories.
Experimental Evaluation
ReGFT is evaluated using the Qwen3-4B-2507-Instruct model (Yang et al., 14 May 2025) on the OmniMath dataset (Gao et al., 2024) and three challenging benchmarks: AIME 2024, AIME 2025, and Beyond-AIME [bytedance_seed_2025_beyondaime]. RL is conducted using the DAPO framework (Yu et al., 18 Mar 2025), an efficient RL algorithm that employs decoupled clipping for policy diversity and dynamic sampling to maximize informative reward allocation.
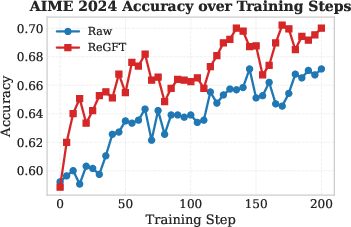
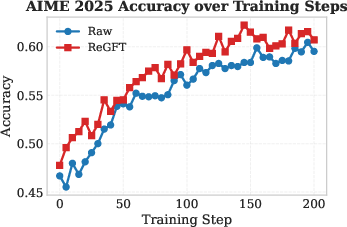
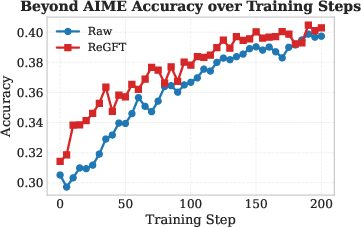
Figure 2: RL training curves on AIME 2024 show that ReGFT initialization yields faster convergence and higher final accuracy than raw checkpoints.
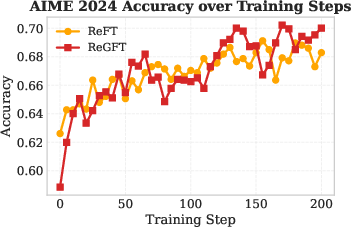
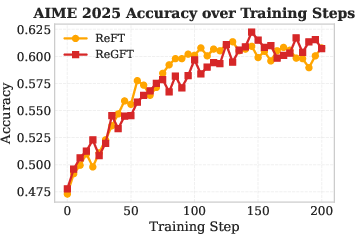
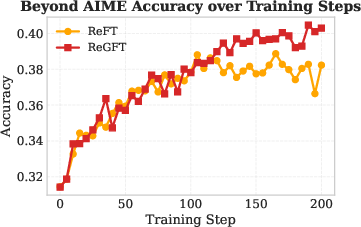
Figure 3: RL training curves on AIME 2024 demonstrate superior performance for ReGFT over ReFT, especially at convergence.
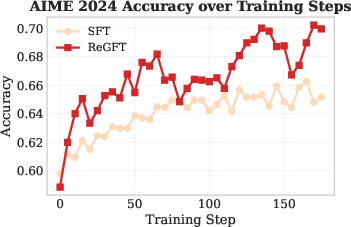
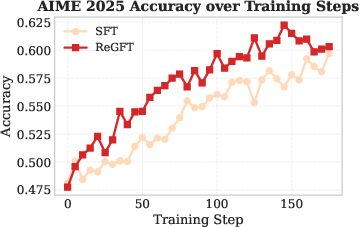
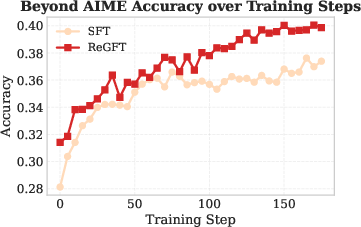
Figure 4: RL training curves on AIME 2024 comparing SFT on reference solutions versus ReGFT, showing the necessity of model-derived trajectories for robust learning.
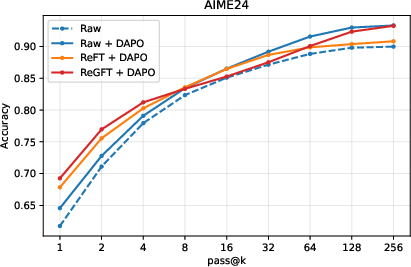
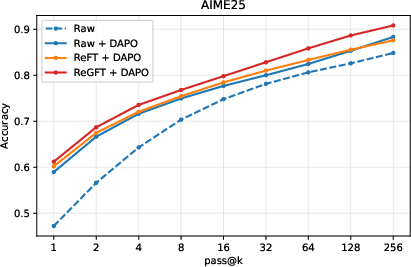
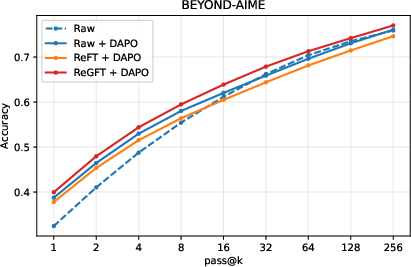
Figure 5: Inference-time scaling on AIME 2024 highlights the superior pass@k performance for RL checkpoints initialized via ReGFT.
Key findings:
- RL from ReGFT-initialized checkpoints consistently outperforms both the raw model and ReFT-initialized checkpoints in accuracy, convergence speed, and final plateau across all benchmarks.
- ReGFT expands the model’s accessible solution space, enabling RL to receive dense reward signals even for previously unsolvable problems.
- Direct fine-tuning on raw reference solutions yields poor generalization and weak RL performance, underscoring the necessity of model-generated traces congruent with the inference distribution.
- ReGFT + DAPO achieves higher pass@k accuracy at larger values of k, demonstrating enhanced coverage of the solution space under inference-time scaling.
Methodological Implications
ReGFT fundamentally modifies pre-RL supervised training, improving the base model’s competence on hard problems so that RL can naturally benefit from more frequent positive rewards. This approach is orthogonal to advances in RL algorithms, and complements adaptive exploration and sampling scale augmentation. By constructing correct, model-derived trajectories guided by references, ReGFT mitigates the bottleneck of zero-reward regimes and unlocks performance gains beyond self-reinforcement.
Scaling sampling sizes during RL further improves accuracy, but ReGFT provides benefits that persist even as response budgets are increased. Reference-guided sampling not only solves additional problems that are inaccessible via standard sampling, but also produces more robust initialization checkpoints for RL.
Theoretical and Practical Implications
The results highlight the critical importance of aligning training signals with the model’s own reasoning distribution, even when leveraging human expertise. ReGFT's mechanism avoids the brittleness of direct reference imitation and allows for scalable integration of demonstration-based guidance for mathematical reasoning tasks. The approach demonstrates that targeted SFT and reference-guided data augmentation at pre-RL stages can overcome structural limitations of RL on reasoning tasks.
Practically, this yields models with improved sample efficiency, faster convergence, and higher ultimate accuracy for mathematical reasoning. The theoretical implication is that effective learning on unsolvable problems must leverage model-compatible, reference-informed reasoning traces, facilitating transfer and generalization while maintaining distributional congruence.
Future Directions
Potential future work includes expanding reference-guided methods to more open-ended reasoning tasks, dynamically selecting reference segments for maximized guidance, and integrating more advanced automatic verification strategies to further reduce false negatives under reference-guided generation. The interplay between reference-guided supervision and RL could be explored for broader domains, including scientific, engineering, or proof-based inference.
Conclusion
Reference-Guided Fine-Tuning (ReGFT) provides a principled mechanism to overcome reward sparsity in RL-based mathematical reasoning by transforming reference solutions into model-aligned, verifiable trajectories. The approach yields stronger RL initialization, accelerates optimization, and enhances final task performance, especially on hard mathematical problems previously inaccessible to the model. This methodology indicates a promising path forward for advancing LLM reasoning through synergistic SFT and RL, leveraging human demonstration in a distributionally coherent fashion (2603.01223).