- The paper proposes a parsing-driven multi-vector retrieval paradigm that fuses layout-informed local vectors with global context to enhance visual document retrieval performance.
- It leverages the MinerU2.5 model to segment documents into semantically meaningful regions, drastically reducing vector counts while preserving critical layout cues.
- Extensive experiments across 24 datasets demonstrate significant nDCG@5 improvements and over 95% storage compression, underscoring its practical scalability.
Introduction and Motivation
Visual Document Retrieval (VDR) tasks require systems capable of understanding not only textual information but also the complex and nuanced layouts inherent in visually-rich documents—such as scientific papers, financial statements, and invoices. Standard multi-vector architectures in VDR represent pages with sets of patch-level embeddings, applying late-interaction mechanisms like MaxSim to align queries with specific regions. While this approach provides fine-grained matching capability, it incurs substantial storage overhead, making large-scale deployment impractical. Prior optimization strategies, including embedding merging, pruning, and the introduction of abstract tokens, either impair performance or neglect essential layout cues. The paper addresses this fundamental trade-off by introducing a layout-informed, document parsing-driven multi-vector retrieval paradigm, yielding structurally-aware representations that are both compact and semantically precise.
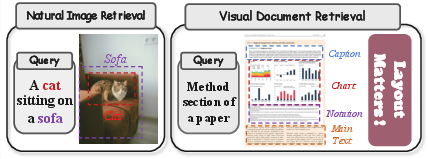
Figure 1: Side-by-side comparison of natural image retrieval dilemmas versus the increased complexity observed in VDR due to intricate layout and semantic variability.
Methodological Framework
Design Rationale
The proposed framework leverages a specialized document parsing model—MinerU2.5—to segment a page into a small set of semantically meaningful, layout-informed sub-images (typically k<10). Each sub-image (e.g., tables, figures, paragraphs) is independently encoded via a single-vector retrieval model, producing k local region vectors. Simultaneously, the entire document image is encoded to generate a global vector contextualizing the page. Final representation is constructed by element-wise weighted fusion of global and local vectors, yielding context-enriched multi-vector embeddings for each document. This decomposition, coupled with global-local fusion, is designed to retain fine-grained discriminative structure while drastically reducing storage requirements.

Figure 2: Illustration of a multi-vector VDR model, highlighting three primary efficiency optimization paradigms—merging, pruning, abstract tokenization—and the structural superiority of the parsing-based approach.
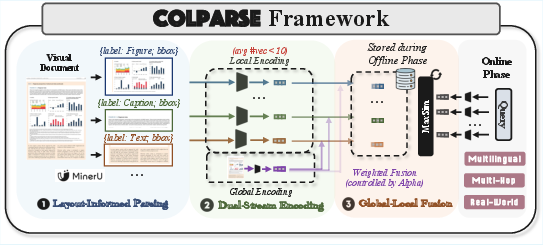
Figure 3: Simplified schematic of the three-stage parsing-driven multi-vector framework—layout detection, dual-stream encoding, global-local fusion.
Theoretical Justification
The framework is grounded in the Information Bottleneck (IB) principle. Parsing disentangles the document content, mapping it into channels corresponding to semantic regions. Fusion with global context offers a principled mechanism for maximizing relevance signal retention while minimizing information about the source, thereby acting as an approximation to intractable IB objectives for VDR. The chain rule and semantic concentration axiom further support the structured multi-vector decomposition, which enables the dominance of primary region relevance for any given query.
Experimental Evaluation
Empirical Results
Extensive experiments were conducted across 24 VDR datasets in five major benchmark suites: ViDoRe-V1, ViDoRe-V2, VisRAG, ViDoSeek, and MMLongBench. The framework was applied to ten mainstream single-vector retrieval models, demonstrating significant and universal improvements.
Figure 4: Performance (nDCG@5) comparison between the layout-informed approach and baselines across five VDR benchmarks and ten retrieval models.
Strong numerical results include:
- Average nDCG@5 gains of 31.64 and 42.69 for VLM2Vec-V1-2B and VLM2Vec-V1-7B respectively on ViDoRe-V1.
- Achieves over 95% storage compression by reducing per-page vector count from hundreds/thousands to ∼6.
- Maintains or improves state-of-the-art results for base models (e.g., GME-7B: 80.61 vs. 80.02 with 99% fewer vectors).
Layout parsing-driven decomposition outperforms traditional token chunking or heuristic clustering, particularly for tasks requiring multi-hop reasoning, cross-region synthesis, and long-context understanding. Synergistic global-local fusion enables structurally-aware representations to achieve semantic grounding not possible with regional embeddings alone.
Ablation and Variant Analysis
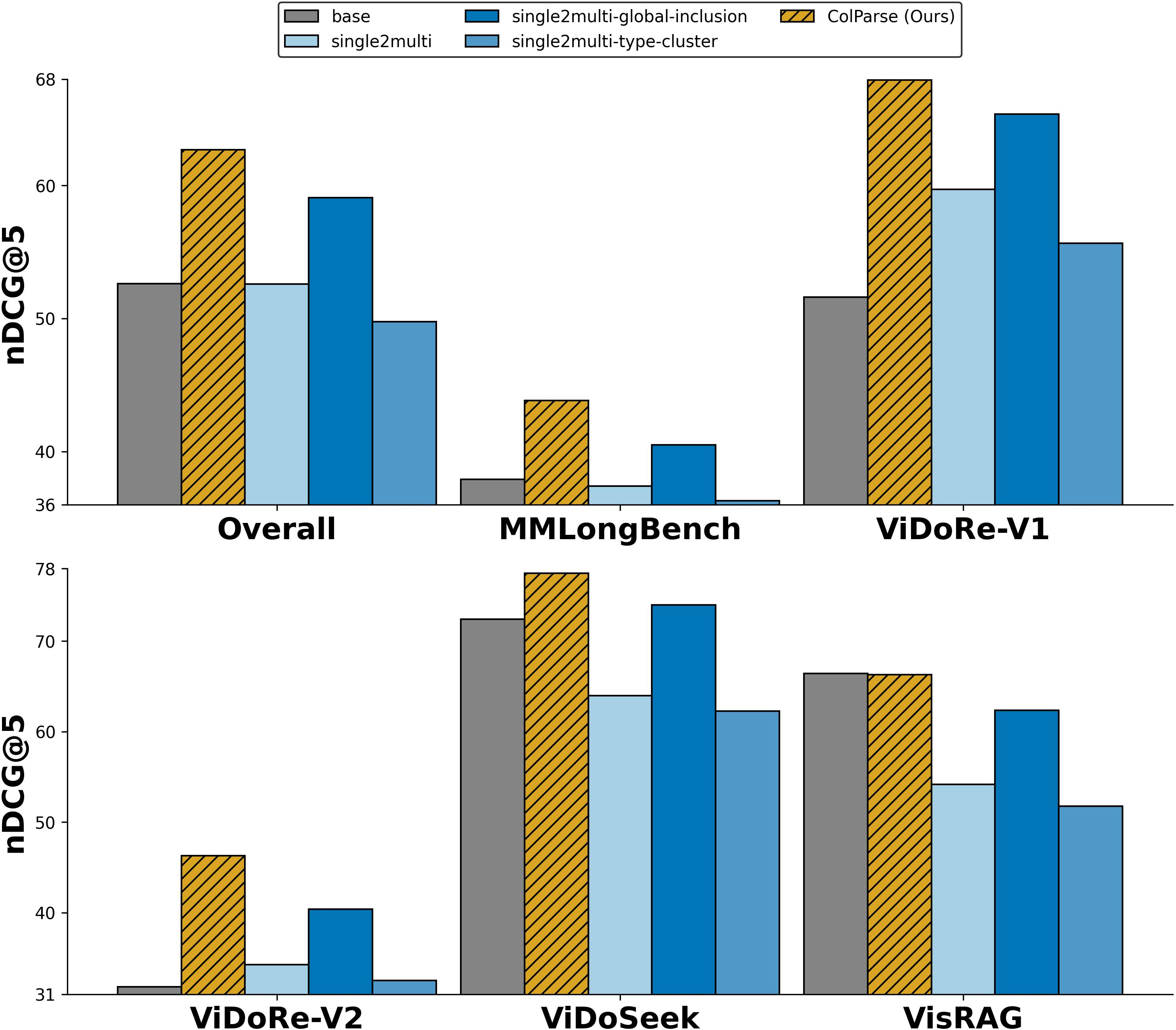
Figure 5: Variant study contrasting pure local decomposition, type-level clustering, and global vector inclusion against synergistic global-local fusion.
The inclusion of global context via fusion is critical. Simple global vector inclusion is inferior to weighted fusion—which achieves the deepest contextual conditioning and highest retrieval scores in dense multi-region tasks.
Hyperparameter and Efficiency Evaluation
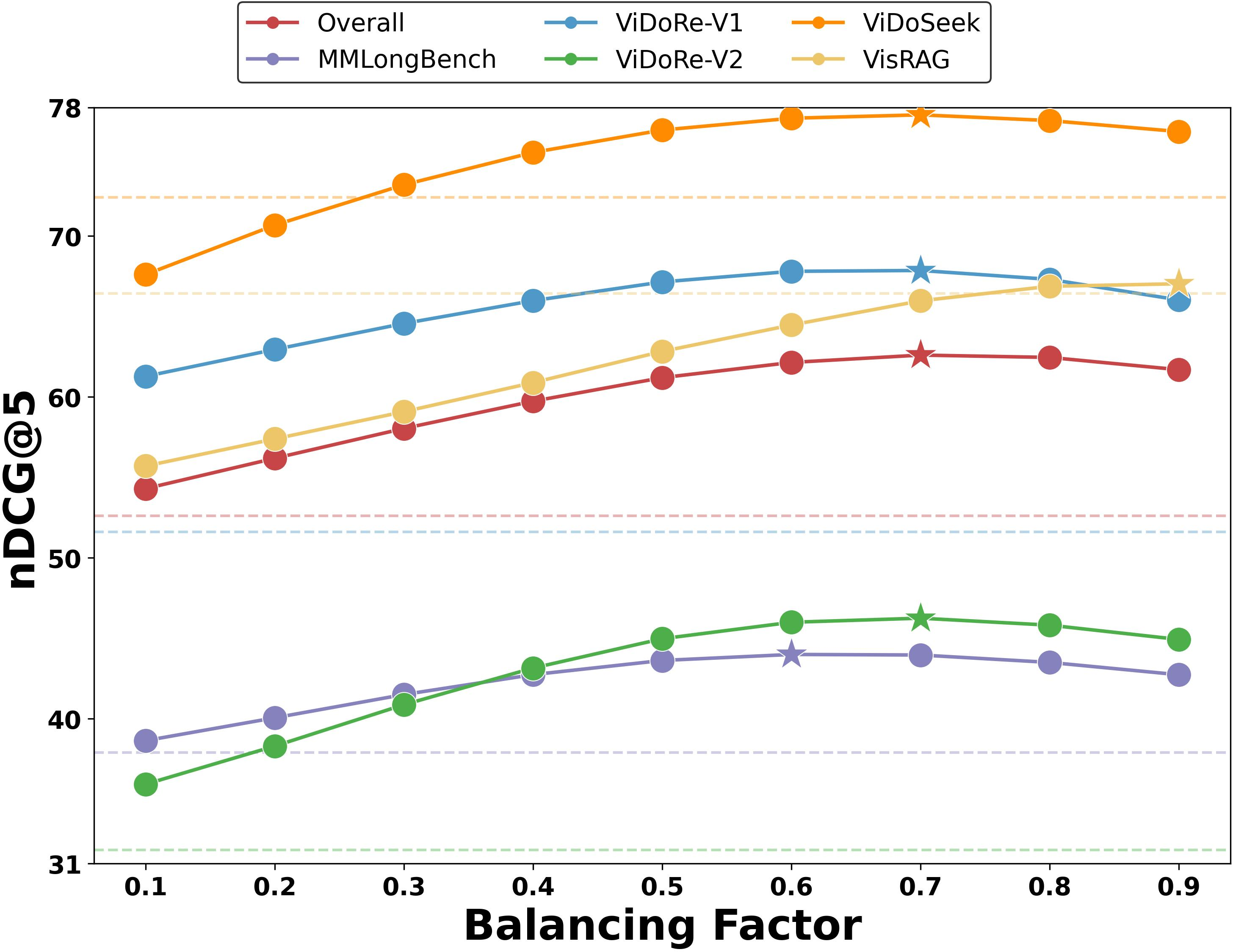
Figure 6: Model-level retrieval performance across different global-local balancing factors; stars denote optimal α values.
Performance is robust for α∈[0.1,0.9], with optimal results typically at α∈[0.6,0.8] indicating moderate global dominance. MinerU2.5 offers the best trade-off between parsing fidelity (Overall score 90.67 on OmniDocBench) and industrial-grade throughput (2.25 pages/sec), supporting practical deployment.
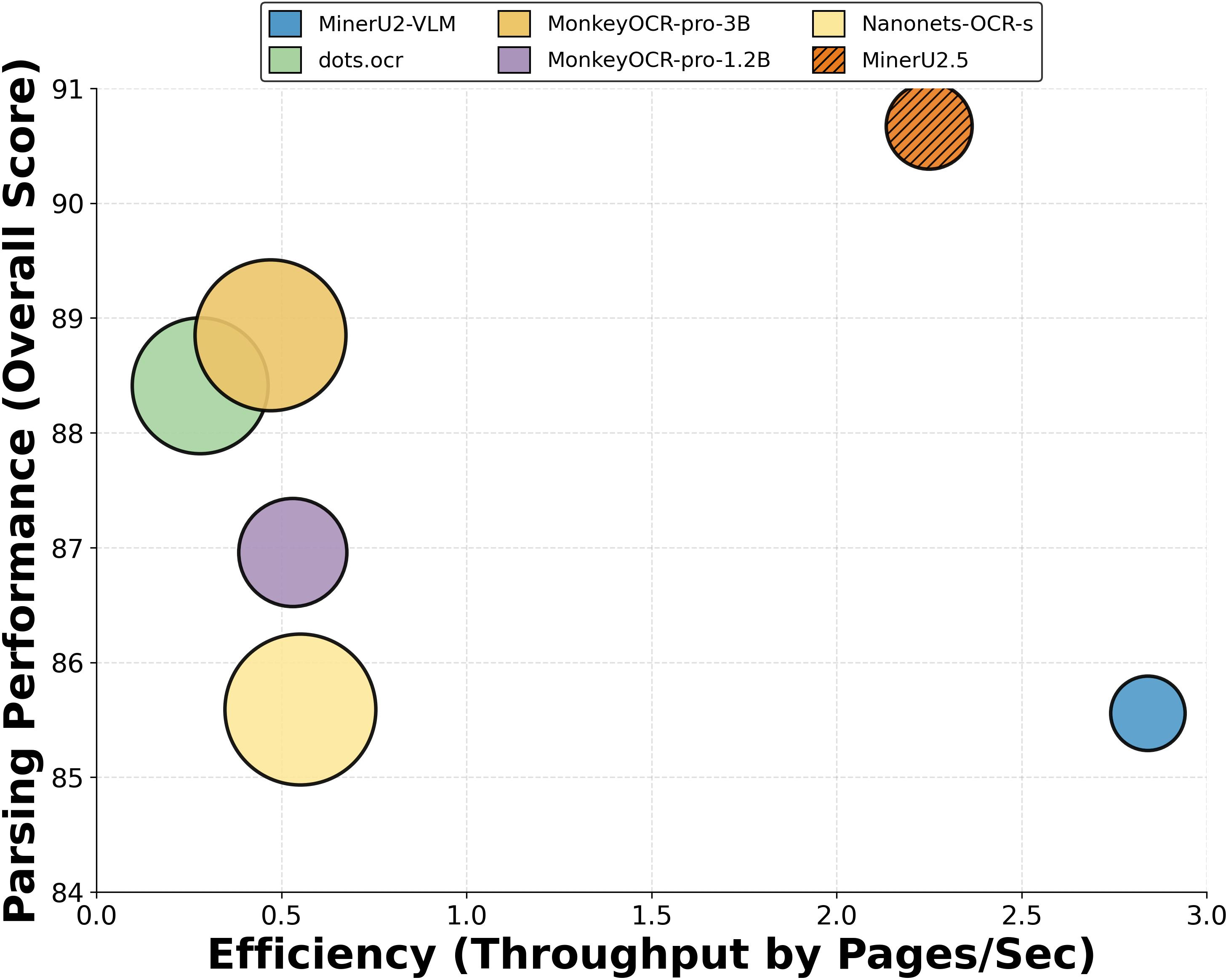
Figure 7: MinerU2.5 achieves optimal accuracy-throughput trade-off across document parsing VLMs, as measured by OmniDocBench and end-to-end speed.
Interpretability and Case Study
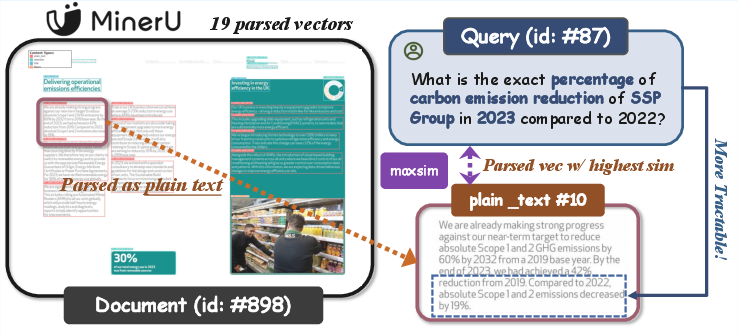
Figure 8: Representative retrieval scenario demonstrating the interpretability—retrieved evidence precisely localized to the parsed layout component.
Layout-informed representations allow for explicit evidence tracing and user-facing explanation, vital in industrial scenarios where source transparency is required.
Implications and Future Directions
The parsing-driven multi-vector paradigm resolves the longstanding tension between fine-grained retrieval accuracy and storage/efficiency bottlenecks in VDR. Its model-agnostic, training-free, plug-and-play integration establishes a new structural prior, essential for practical multimodal information systems. The approach is conducive to rapid indexing, real-time deployment, and interpretability. Future research may extend to dynamic fusion weighting, broader types of structural priors (e.g., hierarchical trees), and adaptive multi-agent RAG pipelines leveraging layout-aware retrieval as a foundation for deep research and agentic reasoning. The combination of document structure understanding and compact multi-vector representations is expected to inspire advancements in scalable visual document intelligence and AI-assisted research workflows.
Conclusion
The paper presents a principled, efficient, and universally effective paradigm for VDR using parsed layout-informed multi-vector representations. By fusing structurally-aware local vectors with global context, the method provides superior retrieval performance, massive storage reduction, and actionable interpretability across tasks and models, thus establishing a new architectural standard for large-scale visual document retrieval (2603.01666).