- The paper introduces a novel adaptive patch-level embedding pruning method to reduce storage overhead by dynamically discarding redundant embeddings.
- The paper employs intra-document patch attention distribution and adaptive thresholding based on statistical properties to maintain retrieval performance.
- The paper demonstrates a consistent 50-60% reduction in storage requirements across over ten datasets without significant accuracy loss.
"DocPruner: A Storage-Efficient Framework for Multi-Vector Visual Document Retrieval via Adaptive Patch-Level Embedding Pruning"
Introduction
The paper "DocPruner: A Storage-Efficient Framework for Multi-Vector Visual Document Retrieval via Adaptive Patch-Level Embedding Pruning" (2509.23883) presents a novel approach to Visual Document Retrieval (VDR) that addresses the storage overhead associated with current multi-vector VDR systems. VDR is crucial for applications ranging from e-commerce searches to academic resource retrieval. Traditional methods using OCR face limitations in preserving layout integrity and visual elements, leading to a shift towards Large Vision-LLMs (LVLMs) that represent documents as patch-level embeddings. Despite their effectiveness, these models introduce significant storage demands due to the multiple vectors required for each document page.
Proposed Framework
DocPruner introduces adaptive patch-level embedding pruning to mitigate the storage costs in VDR systems. This framework utilizes intra-document patch attention distribution to dynamically identify and discard redundant embeddings, thus maintaining retrieval performance while reducing storage requirements by 50-60%. This approach is significant in that it employs attention mechanisms to quantify patch importance, setting an adaptive threshold for pruning that adjusts based on the statistical properties of each document's embedding attention scores.
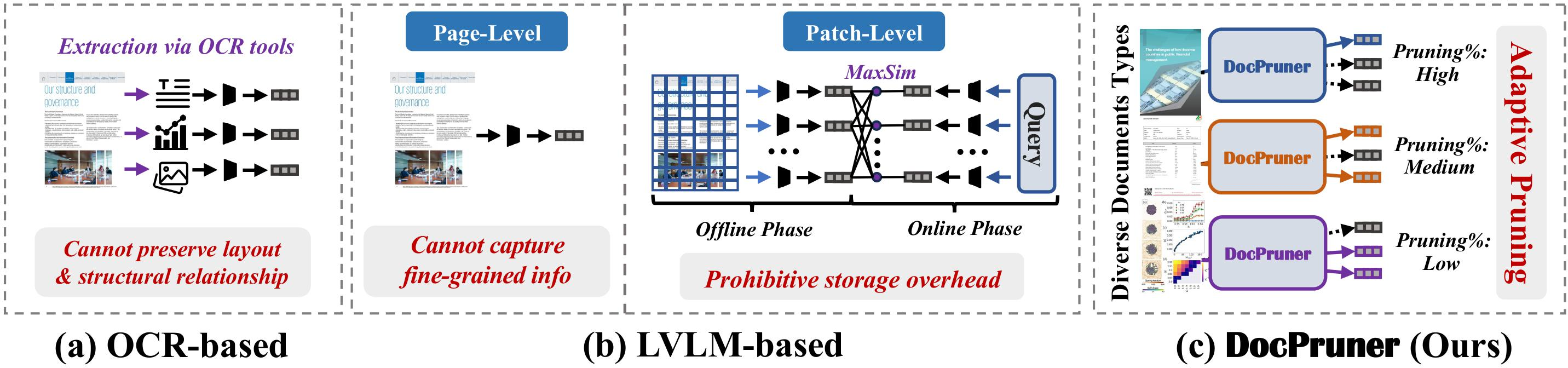
Figure 1: The illustration of comparison between OCR-based (a) LVLM-based (b) paradigms for VDR, and (c), a novel framework to adaptively prune the patch-level embeddings for diverse document types.
Methodology
The methodology involves first representing both query and documents as sets of embeddings, with query tokens transformed into token-level embeddings and document pages into patch-level embeddings. The relevance between a query and a document is then calculated using a MaxSim operation across these embeddings. DocPruner enhances this process by computing patch importance based on attention directed towards a global token, typically the [EOS] token. This is followed by an adaptive thresholding process informed by the mean and variance of these importance scores, allowing the model to dynamically adjust the pruning based on document characteristics.
Experimental Results
Extensive experimentation across over ten datasets demonstrates that DocPruner achieves substantial storage efficiency without significant performance degradation. The results indicate a robust, flexible, and effective approach for large-scale VDR systems, crucial for enabling the deployment in practical applications. Figures illustrate performance comparisons and pruning ratio distributions, highlighting the framework's ability to maintain high retrieval performance across diverse datasets while achieving significant storage compression.
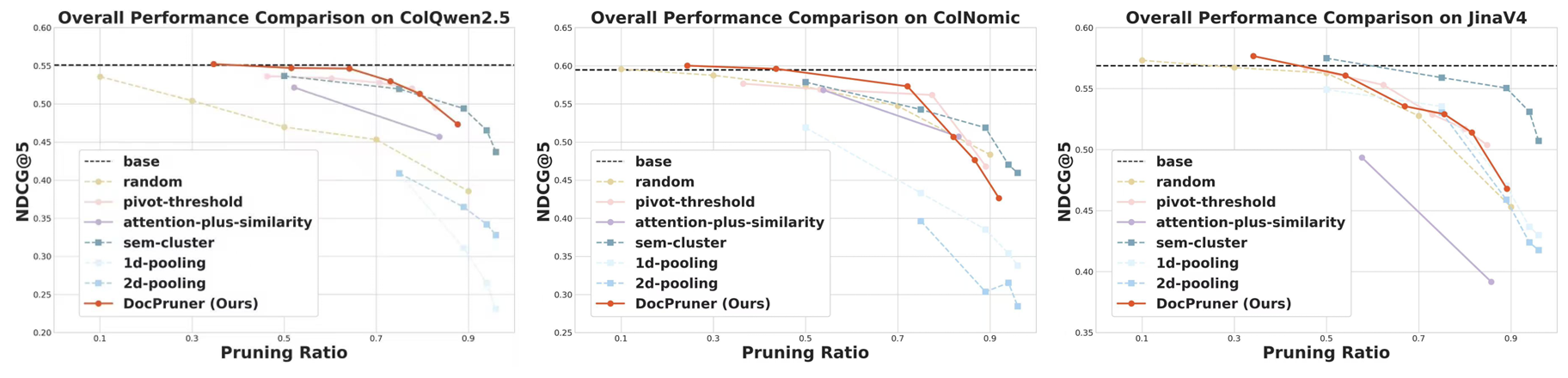
Figure 2: Performance comparison (nDCG@5) between and baselines on ViDoRe-V2 benchmark.
Implications and Future Directions
DocPruner's contributions are multifaceted: pioneering adaptive pruning in VDR, providing a tailored approach for diverse document types, and validating its method through comprehensive benchmarks. The framework opens avenues for more efficient multimodal retrieval systems, reducing operational costs and expanding accessibility. Future work may integrate pruning mechanisms directly into model training or explore adaptive principles for other modalities to enhance real-world applications. This framework represents a step towards making high-performance VDR systems practical and scalable for various industries and sectors, potentially reshaping how document retrieval technologies are deployed at scale.
Conclusion
DocPruner addresses the critical storage overhead challenge in multi-vector VDR systems by introducing adaptive patch-level embedding pruning. This framework effectively reduces storage demands while preserving retrieval accuracy, leveraging attention mechanisms to dynamically prune document embeddings based on importance scores. Extensive testing across diverse datasets validates its efficacy, positioning DocPruner as a pivotal development for storage-efficient VDR systems. As the field of document retrieval continues to evolve, DocPruner paves the way for practical deployments of fine-grained, multimodal understanding technologies at unprecedented scales.