- The paper's main contribution is a systematic audit revealing nearly 46% of shadow API endpoints misrepresent claimed LLM models through deceptive backend substitutions.
- It employs active fingerprinting and statistical output comparison, showing shadow APIs can yield up to 47% accuracy drops on critical benchmarks.
- The study underscores significant financial, legal, and reproducibility risks, advocating robust auditing protocols and greater transparency in LLM access.
Systematic Audit of Shadow API Deception in LLM Services
Introduction and Shadow API Landscape
The paper "Real Money, Fake Models: Deceptive Model Claims in Shadow APIs" (2603.01919) presents a rigorous, multi-faceted audit of the ecosystem of third-party, so-called “shadow APIs” that claim to provide access to proprietary LLMs such as GPT-5 and Gemini-2.5. Due to economic and geographic restrictions imposed by official API providers, numerous shadow APIs have proliferated, positioning themselves as unofficial intermediaries. The paper systematically exposes the scale, practices, and technical characteristics of these services, establishing that a non-trivial fraction serve models that do not match their declared identity, thereby undermining scientific reproducibility and user trust.

Figure 1: A schematic for the production, transaction, use, and audit of shadow APIs, capturing the opacity and indirectness of shadow API supply chains.
Extensive crawling of academic code repositories reveals that at least 17 shadow APIs are referenced in 187 research papers, and the most popular single shadow API instance received 5,966 citations and over 58,000 GitHub stars. This underscores the shadow API phenomenon as a substantive infrastructure component impacting multiple research communities.
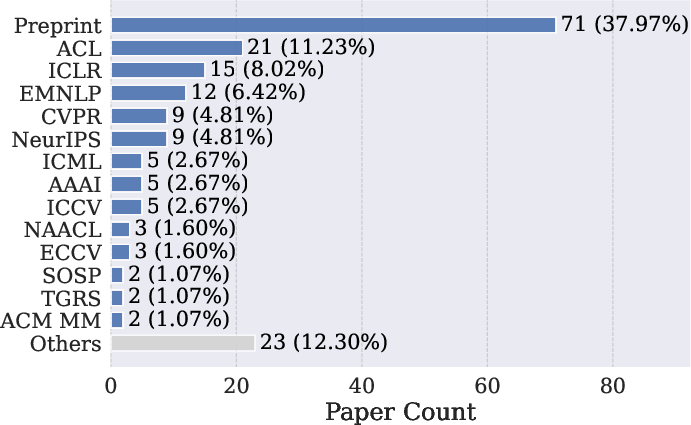
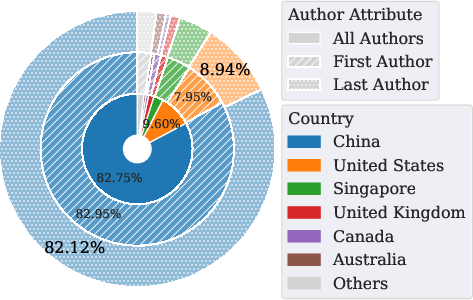
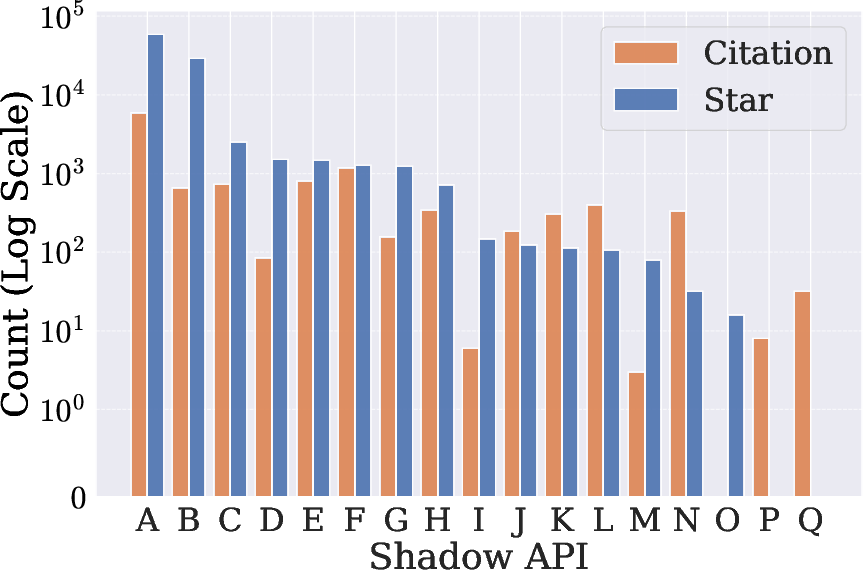
Figure 2: Distribution of papers utilizing shadow APIs by research venue, indicating penetration into top-tier AI conferences and journals.
Characterization and Governance of Shadow APIs
Shadow APIs provide indirect access to frontier LLMs, either through key reselling, output mirroring, or outright model substitution. Technical analysis reveals that the majority are built atop open-source model aggregator backends (e.g., OneAPI, NewAPI) that enable integration of multiple LLM sources, support for secondary reselling, and dynamic routing among underlying engines, greatly increasing the probability of misrepresentation and downgrading.
The vast majority of these providers lack formal registration and transparency: only one of the 17 is operated by a registered entity with compliance disclosures, with most being operated pseudonymously and exhibiting highly volatile operational practices. The analysis establishes that provider churn, infrastructure instability, and non-transparent upstream switching are endemic, exacerbating legal, reproducibility, and operational risks for end users.
Utility and Safety Benchmarking
A multidimensional empirical evaluation compares official APIs against leading shadow APIs A, E, and H on both high-stakes science and sensitive domain benchmarks. The LLM selection reflects both popularity and diversity, spanning OpenAI (e.g., GPT-5, GPT-4o-mini), Google Gemini variants, and DeepSeek family models. Evaluation protocols leverage standardized prompt templates and include triple querying to measure response variance.
The key findings include performance divergence up to 47.21% in accuracy on critical benchmarks:
- On MedQA (USMLE), Gemini-2.5-flash achieves 83.82% accuracy via the official API, but only ~37% via the shadow APIs.
- On LegalBench (Scalr subset), shadow APIs lag official endpoints by 40%–42% in accuracy, sometimes citing incorrect or unrelated legal procedures.
- Shadow APIs are notably unreliable in reasoning-centric scenarios, exhibiting failures most prominently on AIME 2025 and GPQA.
- Inconsistent and unpredictable behavior is systemic, with some endpoints occasionally surpassing official APIs on certain non-reasoning tasks, but collapsing on more challenging domains.
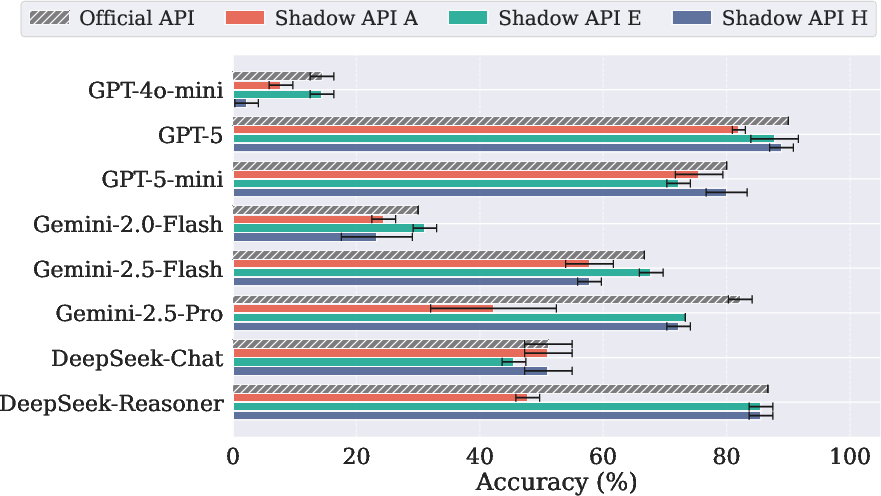
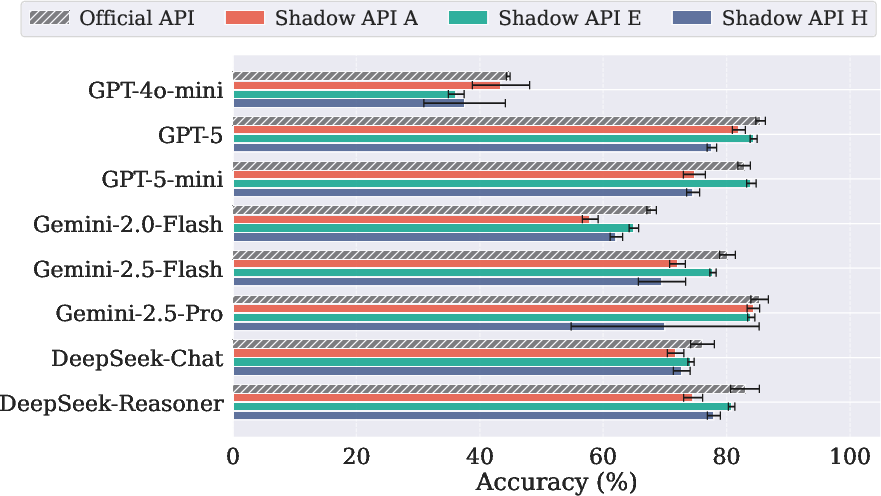
Figure 3: Benchmark results for AIME 2025, demonstrating severe and variable accuracy drop across shadow APIs relative to official endpoints.
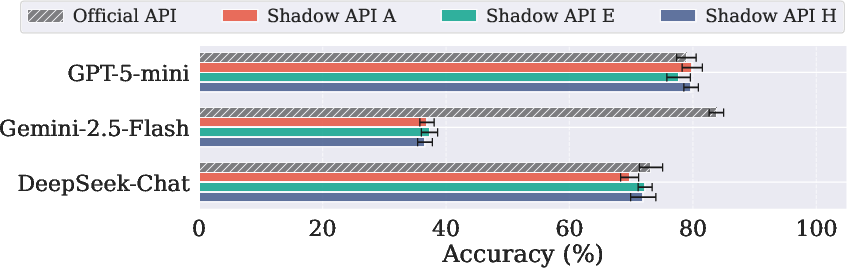

Figure 4: MedQA (USMLE) performance highlights the critical unreliability of shadow APIs for medical question answering tasks.
Coverage of safety scenarios using JailbreakBench and AdvBench, along with multiple adversarial prompting strategies, exposes contradictory safety dimensions: shadow APIs sometimes output responses with risk or harmfulness scores that are either substantially underestimated or over-amplified compared to the official endpoints (e.g., Base64 attack yields a harmfulness score on a shadow API that is 2× higher than the official).
Model Identity Verification
The technical core of the audit employs active fingerprinting (LLMmap) and statistical output comparison (Model Equality Testing, MET) to verify whether shadow API endpoints genuinely serve the models they claim. The results are unambiguous:
- 45.83% of evaluated shadow API endpoints fail fingerprint verification, i.e., they deliver outputs inconsistent with those of the official claimed models (operationally, outputs have excessive cosine distance or are positively matched to a different model altogether).
- An additional 12.5% of endpoints exhibit high output divergence (cosine distance >1.2× baseline).
- Model substitution patterns include both downgraded "cheap-for-premium" swaps (e.g., serving GLM-4-9B for GPT-5) and even out-of-family replacements.
For Gemini-2.5-pro, more stable behavior is observed but even then, Concordance (Cohen's κ=0.512) between LLMmap and MET shows only moderate-to-substantial agreement, exemplifying the difficulty of forensic validation.
Latency and token usage meta-analysis further corroborate identity inconsistencies, with shadow APIs showing exceptional volatility in inference times and token counts.
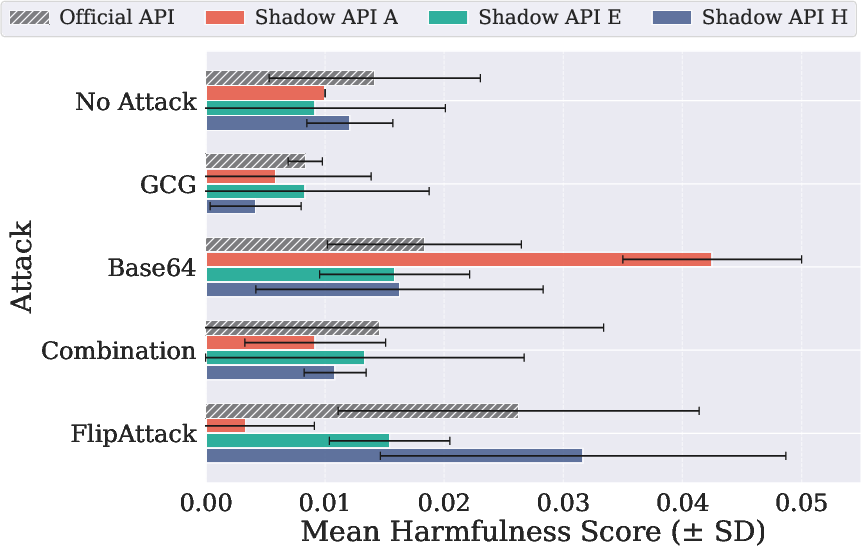
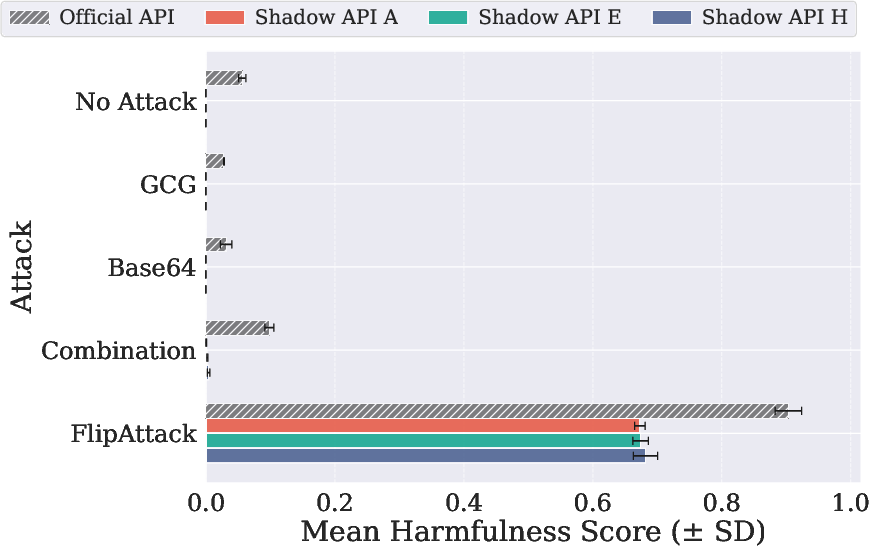
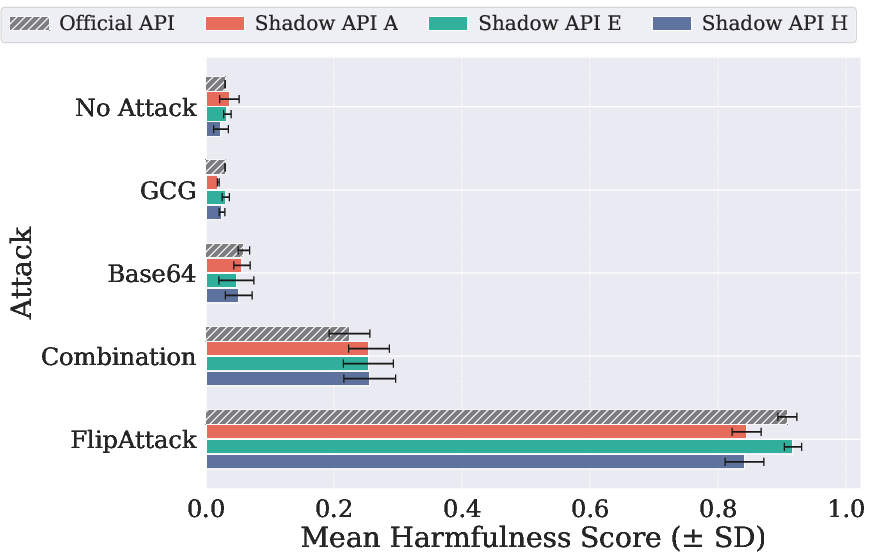
Figure 5: Exploration of GPT-5-mini, exemplifying fingerprinting analysis across official and shadow APIs.
Economic Incentives and Research Integrity Implications
The paper quantifies economic and scientific risk from three classes of shadow API deception: (1) information premium (overpricing with silent substitution), (2) discount-substitution (delivering cheaper models at official pricing), and (3) resale markup with hidden downgrades.
A notable empirical example demonstrates that a shadow API charges the official GPT-5 rate but delivers only 36–38% of the output value in terms of token volume and model accuracy. Cumulative impact includes a direct financial cost (estimated at $100k+) for re-running experiments and incalculable reproducibility damage for the downstream 5,966 citing works.
Recommendations, Limitations, and Prospective Directions
The paper articulates robust protocols for both third-party auditors and researchers: full endpoint auditing (fingerprinting, statistical drift testing, stability metrics, and compliance validation) is mandatory before considering any shadow API usage. Community-level recommendations include rigorous conference policies and the imperative for model providers to lower access barriers for research and introduce formal verification channels.
Key limitations of this study include time-bounded shadow API auditing and lack of complete coverage for all model/provider combinations, but the architectural opacity and instability detailed are inherent to the shadow API ecosystem.
Figure 6: Token usage leaderboard from OpenRouter, indicating the real-world scale of unofficial LLM usage pathways.
Conclusion
This paper provides the first comprehensive, quantitative assessment of shadow APIs for LLM access, establishing that deceptive backend substitution, instability, and outright non-equivalence to official models are endemic in this ecosystem. The numerical deficits are substantial and the risks to scientific integrity, safety, and end-user value cannot be overstated. The authors convincingly demonstrate that shadow APIs should not be treated as credible substitutes for official LLM APIs, and pose structured guidance for the detection and mitigation of such risks as the community transitions to LLM-driven research and deployment paradigms.