Chasing Shadows: Pitfalls in LLM Security Research
Abstract: LLMs are increasingly prevalent in security research. Their unique characteristics, however, introduce challenges that undermine established paradigms of reproducibility, rigor, and evaluation. Prior work has identified common pitfalls in traditional machine learning research, but these studies predate the advent of LLMs. In this paper, we identify nine common pitfalls that have become (more) relevant with the emergence of LLMs and that can compromise the validity of research involving them. These pitfalls span the entire computation process, from data collection, pre-training, and fine-tuning to prompting and evaluation. We assess the prevalence of these pitfalls across all 72 peer-reviewed papers published at leading Security and Software Engineering venues between 2023 and 2024. We find that every paper contains at least one pitfall, and each pitfall appears in multiple papers. Yet only 15.7% of the present pitfalls were explicitly discussed, suggesting that the majority remain unrecognized. To understand their practical impact, we conduct four empirical case studies showing how individual pitfalls can mislead evaluation, inflate performance, or impair reproducibility. Based on our findings, we offer actionable guidelines to support the community in future work.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research.
- Limited scope and representativeness: The prevalence study covers 72 papers from select Security/SE venues (2023–2024) only; it excludes journals, arXiv/industry reports, non-English venues, and later years. How do the findings change with broader venues, languages, and a longitudinal (multi-year) extension?
- Search/selection bias: The paper relies on keyword filtering of titles/abstracts; relevant studies may be missed if they describe LLMs indirectly or use different terminology. What is the recall/precision of the search strategy, and how robust are prevalence estimates to alternative pipelines?
- Inter-annotator agreement (IAA): The study uses dual reviewers and consensus, but does not report IAA metrics (e.g., Cohen’s κ) or calibration procedures. How reliable are pitfall labels, and how sensitive are results to reviewer assignment?
- Operationalization clarity: Some pitfalls (e.g., proxy/surrogate fallacy vs model-info ambiguity) may overlap and lack crisp, testable criteria. Can the community define standardized, unambiguous operational tests/checklists for each pitfall?
- Reliance on “Likely present”: Several conclusions hinge on plausibility (e.g., training cutoff vs publicly available evaluation data). Can stronger evidence be obtained via contamination tests (e.g., n-gram matching, hashing, canaries) or vendor collaboration?
- External validity beyond security/SE: The taxonomy and prevalence are tailored to LLM security research; it is unclear how they transfer to other domains (e.g., healthcare, law), modalities (multimodal LMMs), or agent/tool-augmented systems. What adaptations are required?
- Incomplete taxonomy: The nine pitfalls omit other recurrent sources of variance and failure (e.g., decoding parameters/temperature, seed control, API rate limits, tool-use variability, multilingual tokenization effects, evaluation determinism). What additional pitfalls should be incorporated and validated?
- Effect-size generalization: Only four pitfalls receive empirical case studies; the magnitude of impact for the remaining pitfalls is not quantified systematically. Can a meta-analysis or re-evaluation across the 72 papers estimate typical effect sizes per pitfall?
- Case study breadth: Case studies are limited to specific tasks/datasets/models; generality across vendors, model families, languages, and tasks remains untested. Which results replicate across diverse settings?
- Pitfall co-occurrence and interactions: The study reports per-pitfall prevalence but not how pitfalls cluster or compound (e.g., prompt sensitivity masked by proxy fallacy). What are the dominant co-occurrence patterns and their joint effects on outcomes?
- Predictors of pitfalls: The paper notes topic-level differences but does not model predictors (e.g., open vs closed models, venue, author backgrounds, dataset types). Which factors statistically predict pitfall incidence?
- Mitigation efficacy: The paper proposes guidelines but does not evaluate whether they reduce pitfalls or improve reproducibility. Can controlled studies (before/after, randomized reviews, or natural experiments) measure guideline impact and feasibility?
- Tooling gaps: No automated instruments are provided to detect/flag pitfalls (e.g., leakage scanners, prompt-audit checkers, context-truncation detectors, version-capture validators). What tools can be built, validated, and integrated into CI/review workflows?
- Proprietary opacity: Data leakage and version ambiguity cannot be conclusively audited for closed models. What practical methods (e.g., membership inference, canary probes, watermarking) and disclosure standards can bridge this gap with providers?
- Web-scale data poisoning: The study flags risk but does not quantify real-world poisoning prevalence or evaluate defense coverage at scale. Can we build poisoning audit frameworks and benchmarks for LLM-scale pipelines?
- Spurious correlations: The prevalence is reported, but methods to expose and mitigate non-causal features (e.g., counterfactual evaluation, causal probes, representation diagnostics) are not assessed. Which techniques reliably detect and reduce spurious cues in LLMs?
- Prompt sensitivity standardization: There is no standardized protocol for cross-model prompt optimization/reporting. What reporting standards and prompt-normalization procedures best reduce evaluation variance while preserving comparability?
- Context truncation monitoring: The paper shows prevalence but does not evaluate systematic detection/mitigation (e.g., automatic truncation alerts, chunking strategies, retrieval augmentation) or quantify cost–performance trade-offs across methods.
- Model collapse thresholds and safeguards: Degradation from synthetic data is demonstrated, but conditions/thresholds and mitigation efficacy (data curation, diversity controls, filtering) remain unquantified for security tasks. What safeguards work in practice?
- Temporal drift and reproducibility: Model updates (APIs/snapshots/quantization) are a major source of variance, but no longitudinal measurement quantifies drift effects over time. How quickly do results stale, and which version-capture practices prevent irreproducibility?
- Policy and review standards: The paper recommends best practices but does not translate them into concrete venue policies (e.g., model/version disclosure requirements, prompt/decoding reporting, contamination checks). Which policy interventions are most effective and adoptable?
- Real-world harm linkage: The study does not connect pitfall prevalence to downstream security harm (e.g., vulnerable code shipped, failed defenses). Can incident analyses or field studies quantify real-world impact attributable to specific pitfalls?
- Data and artifact durability: While code/data are released, the paper does not address long-term artifact stability (API changes, dataset availability). What archival practices ensure enduring reproducibility (e.g., model cards with immutable digests, dataset snapshots)?
Practical Applications
Immediate Applications
The following applications can be deployed now, using the paper’s taxonomy of LLM pitfalls, empirical findings, and accompanying resources (llmpitfalls.org, GitHub repository). Each item notes sectors, concrete tools or workflows, and feasibility assumptions.
- Stronger LLM evaluation hygiene in CI/CD pipelines (software, robotics, finance, healthcare): Implement a reproducibility checklist that logs model name, snapshot/date, endpoint, tokenizer, system prompt, quantization level, and API parameters per run; pin model versions and capture changelogs; attach run artifacts to build releases. Tools/workflows: “LLM RunLogger” middleware, CI step templates, experiment notebooks seeded from the paper’s guidelines. Assumptions/dependencies: Model providers expose version identifiers or changelogs; teams adopt disciplined logging.
- Data leakage pre-checks for benchmarks and fine-tuning (software, education, security labs): Before training or evaluation, run near-duplicate and source overlap scanning on test sets versus likely pretraining sources (GitHub, Wikipedia, Reddit). Use the paper’s finding that 20% leakage can inflate F1 by ≈ 0.08–0.11 to gate deployments. Tools/products: “LeakGuard” using locality-sensitive hashing (LSH), SimHash, or MinHash; dataset lineage metadata. Assumptions: Availability of probable pretraining corpus fingerprints or public web mirrors; acceptance of probabilistic contamination signals.
- Prompt sensitivity A/B testing harness (software, genAI safety, customer support): Establish prompt suites per model (model-tailored delimiters, formatting) and run A/B/C tests to quantify variability; adopt model-specific prompt templates for production. Tools/products: “PromptLab” harness generating perturbations and measuring variance across models; prompt registries. Assumptions: Access to multiple models, modest compute budget; orgs accept small performance tradeoffs for robustness.
- Context window analysis and safe chunking for long inputs (software security, code intelligence, legal tech): Automatically count token length for inputs; apply chunk-and-stitch or retrieval-augmented patterns to avoid truncation. Guided by the paper’s result that 49% of vulnerable functions exceed 512 tokens (29% > 1024). Tools/workflows: IDE linter that flags overflow, static token estimators, structured chunking with overlap windows. Assumptions: Chunking preserves task semantics; retrieval corpus quality is adequate.
- Label quality assurance for LLM-as-a-judge (genAI safety, moderation, education): Use model ensembles or human adjudication for a subset; compute inter-rater agreement and calibrate confidence; maintain gold sets for spot checks. Tools/workflows: “JudgeQA” consensus framework; periodic audits; disagreement-triggered human review. Assumptions: Budget for human annotation on critical subsets; acceptance of slower but more reliable pipelines.
- Pitfall-aware red teaming playbooks (security, compliance, cloud platforms): Build attack and evaluation scripts that vary prompts, include long-context cases, and re-run across snapshots/quantizations; explicitly test for proxy/surrogate fallacy by including multiple model families and sizes. Tools/workflows: Security runbooks; scheduled re-tests after vendor updates; scorecards mapped to the nine pitfalls. Assumptions: Access to model families; vendor updates are monitored.
- Procurement and vendor due-diligence requirements (policy, industry procurement, finance/healthcare governance): Require model cards with snapshot IDs, tokenizer and system prompt details, quantization options, endpoint versioning, and update cadence; mandate disclosure of training data sources at category-level (licensed/public/created). Tools/workflows: Standardized AI procurement templates; compliance checklists referencing the paper’s guidelines. Assumptions: Vendors agree to disclose non-sensitive metadata; legal teams update contracts.
- Conference and journal artifact checklists (academia): Integrate a “pitfalls compliance” badge in artifact evaluation—explicitly check version pinning, leakage mitigation, prompt documentation, and context-handling strategies. Tools/workflows: Reviewer rubrics; template sections for model versioning, dataset lineage, and prompt suites. Assumptions: PC/AE committees adopt the rubric; authors have access to model metadata.
- Continuous drift monitoring due to model updates (software, customer-facing AI, fintech): Track precision/recall and jailbreak robustness across time; set alerts when performance changes after vendor-side updates, informed by the paper’s case study that snapshot/quantization materially alters outcomes. Tools/workflows: “LLM Driftwatch” dashboards; canary test sets; weekly scheduled evaluations. Assumptions: Stable test suites; observability pipelines in place.
- Dataset curation and ingestion hygiene (industry data teams, model fine-tuning shops): Introduce whitelist/blacklist sources, poisoning checks, and quality filters when scraping; measure label noise rates and re-validate high-risk segments. Tools/workflows: Poisoning detectors (outlier scores, heuristic filters), source integrity checks, sampled manual reviews. Assumptions: Teams can tolerate slower ingestion; cost for periodic human quality control.
Long-Term Applications
These applications require further research, scaling, standardization, or ecosystem development. They build on the paper’s taxonomy and empirical insights to improve reliability, transparency, and safety.
- Standardized reporting for LLM experiments (NIST/ISO/IEEE, academia, industry): Develop a formal standard that mandates snapshot IDs, tokenizer/system prompts, quantization, prompt suites, leakage checks, and cross-model validations to avoid proxy fallacies. Tools/products: A “Reproducible LLM Report” spec; validator tooling integrated into papers and CI. Assumptions/dependencies: Multi-stakeholder consensus; adoption by venues and funders.
- Training data provenance registries and contamination scanning (policy, cloud providers, labs): Maintain hashed fingerprints and lineage metadata of common pretraining corpora; create registrar services to scan evaluation/test sets for overlap before publication or deployment. Tools/products: “DataProvenance Registry”; contamination APIs; privacy-preserving hashing. Assumptions: Vendor buy-in; careful handling of IP/privacy; legal frameworks for disclosure.
- Synthetic data watermarking and filtering to mitigate model collapse (model providers, research labs): Embed detectable markers in synthetic outputs; build filters and curriculum strategies mixing real and diverse data to prevent recursive degradation noted in the paper’s case study. Tools/products: Watermarking algorithms; anti-collapse curricula; synthetic-data quality gates. Assumptions: Watermarks remain robust; synthetic generation is traceable; training stacks accommodate filters.
- Proxy-robust benchmarks spanning families and sizes (academia, evaluation consortia): Create benchmark suites that explicitly assess generalization across open-source and proprietary families and sizes to counter the proxy/surrogate fallacy. Tools/products: “CrossFam Bench” with model-agnostic protocols; shared leaderboards that penalize over-generalization. Assumptions: Access to diverse models; funding for compute.
- Automatic spurious correlation detectors for security tasks (software security, healthcare NLP): Develop causal probes, counterfactuals, and ablation tools that reveal non-causal shortcuts in code and text tasks; integrate into evaluation to avoid inflated scores. Tools/products: Causal analysis libraries; counterfactual code patchers; feature ablation engines. Assumptions: Availability of structured annotations; domain expertise to interpret causal signals.
- Black-box model snapshot fingerprinting for auditors (compliance, cloud marketplace): Build challenge-set probes that infer effective snapshot/quantization differences from responses, enabling third-party verification even when vendors don’t disclose full details. Tools/products: “ModelID Fingerprinter”; auditor APIs; certification workflows. Assumptions: Response patterns are sufficiently discriminative; legal permission to probe.
- Regulated versioned endpoints and changelog transparency (policy, cloud providers): Require providers to expose versioned endpoints, changelogs, and rollback options; mandate end-user notification when behavior-changing updates occur. Tools/products: API versioning standards; change impact notices; opt-in “stable channels.” Assumptions: Legislative adoption; alignment with safety/privacy requirements.
- Training data supply-chain security (model providers): Sign and verify ingested datasets; track source integrity; deploy poisoning detection at scale for internet-scraped content. Tools/products: Data signing PKI; ingestion attestation; anomaly detectors for poisoning. Assumptions: Infrastructure investment; governance for key management.
- IDE and notebook “Pitfall Guard” extensions (daily life, software engineering education): Offer real-time warnings for context overflow, prompt fragility, missing version metadata, and potential leakage sources while building LLM apps. Tools/products: VSCode/JetBrains extensions; Jupyter magics; suggested fixes aligned to the nine pitfalls. Assumptions: Developer adoption; sustained maintenance.
- Continuous performance and safety monitoring platforms (industry, healthcare, finance): SaaS that detects drift from model updates, tracks jailbreak susceptibility, and flags metric inflation linked to leakage or prompt changes; aligns dashboards with risk/compliance. Tools/products: “LLM SafetyOps” platform; alerts, SLOs, incident playbooks. Assumptions: Stable governance; integration with existing monitoring stacks.
- Education and reviewer training programs (academia, professional bodies): Course modules and reviewer bootcamps on LLM pitfalls, emphasizing reproducibility, prompt sensitivity, context handling, and leakage risks; include hands-on labs using the paper’s repository. Tools/products: Curricula, lab kits, certification credits. Assumptions: Institutional buy-in; ongoing updates.
- Sector-specific compliance frameworks (healthcare, finance, public sector): Translate the nine pitfalls into domain controls (e.g., leakage audits for clinical notes, snapshot logging in trading systems, prompt robustness for public services). Tools/products: Control catalogs; audit procedures; mapping to existing standards (HIPAA, PCI DSS, ISO/IEC 42001). Assumptions: Harmonization with sector regulations; resource availability for audits.
Glossary
- Alignment: Adjusting an LLM to follow desired objectives, safety constraints, or user intent. Example: "During fine-tuning or alignment, LLMs are adapted for specific downstream tasks and user-facing behaviors."
- Alignment testing: Evaluations that probe whether an LLM adheres to intended safety or behavioral guidelines. Example: "In tasks such as jailbreak detection or alignment testing, vague prompts (e.g., ``You are a helpful AI assistant'') may underrepresent a model's true capabilities or vulnerabilities."
- Context window: The maximum number of tokens an LLM can process in a single input. Example: "about 49% of vulnerable functions exceed common context windows of 512 tokens (29% tokens)"
- Data leakage: Unintended overlap between training and evaluation data that can inflate reported performance. Example: "Others represent familiar concerns, such as data leakage or spurious correlations, but their implications change and intensify in the context of LLMs."
- Data poisoning: Malicious manipulation of training data to induce harmful or biased model behavior. Example: "data scraped from the Internet opens the door to data poisoning attacks, where malicious or biased content can be subtly inserted into the training data without detection."
- Downstream tasks: Specific applications or tasks for which a pre-trained model is adapted. Example: "During fine-tuning or alignment, LLMs are adapted for specific downstream tasks and user-facing behaviors."
- Endpoint version: The specific deployed API/backend variant of a model at a given time. Example: "specifying the exact snapshot (e., endpoint version, commit ID, or access date) is essential."
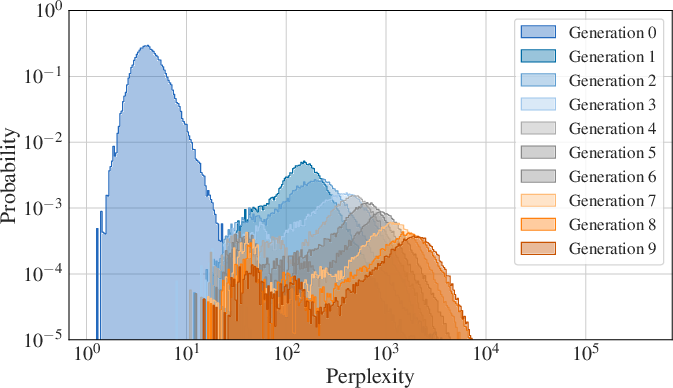
- Fine-tuning: Further training a pre-trained model on task-specific data to specialize its behavior. Example: "Fine-tuning and alignment frequently rely on data that was itself generated by LLMs, introducing the risk of \Pmodelcollapse[]~\cite{shumailov_ai_2024}."
- Foundational model: A broadly pre-trained model used as a base for adaptation to many tasks. Example: "Foundational models may have been trained on (a subset of) samples from the test set."
- Fuzzing: A software testing technique that feeds programs with generated inputs to find bugs or vulnerabilities. Example: "while studies on Fuzzing and Secure Code Generation contain fewer pitfalls on average (15--18\%)."
- Jailbreak attacks: Techniques that induce an LLM to bypass its safety policies or restrictions. Example: "and are generally vulnerable to prompt injection and jailbreak attacks~\cite{yu_jailbreaks}."
- LLM-as-a-judge: Using an LLM to automatically evaluate or label data or outputs. Example: "a practice known as LLM-as-a-judge~\cite{zheng_judging_2023}."
- Model collapse: Degradation in model diversity and quality when models are trained on their own or other models’ outputs. Example: "such as model collapse caused by training on synthetic data or unpredictable model behavior due to prompt sensitivity."
- Perplexity: A measure of how well a LLM predicts text; lower values indicate better predictive performance. Example: "recursive self-training in code generation increases perplexity across generations, leading to degradation and instability."
- Pre-training: Large-scale initial training of a model on broad corpora to learn general patterns. Example: "LLMs are typically pre-trained on large-scale datasets to capture general language patterns."
- Prompt engineering: Crafting and formatting inputs to guide an LLM’s behavior and performance. Example: "prompt engineering (e., context sensitivity)"
- Prompt injection: Maliciously crafted prompts that manipulate an LLM into ignoring instructions or performing unintended actions. Example: "and are generally vulnerable to prompt injection~\cite{liu_pi} and jailbreak attacks~\cite{yu_jailbreaks}."
- Prompt sensitivity: The phenomenon where small prompt changes cause large variations in model outputs. Example: "Prompting also introduces the issue of \Ppromptsensitivity[], where minor changes in phrasing can lead to drastically different outputs and where different models can have distinct prompt preferences."
- Quantization: Reducing numerical precision of model parameters to speed up inference or reduce memory, potentially changing behavior. Example: "snapshot versions and quantization affect robustness against jailbreaks and significantly alter precision/recall"
- Selection bias: Systematic bias introduced when training data are not representative of the true distribution. Example: "Such features may arise from selection bias in the training data or from shortcuts the model learns using unrelated patterns."
- Snapshot: A specific saved/versioned state of a model used in experiments. Example: "specifying the exact snapshot (e., endpoint version, commit ID, or access date) is essential."
- Spurious correlations: Non-causal patterns that a model exploits to perform well on benchmarks but fail to generalize. Example: "Spurious Correlations often remain unidentified."
- Stateless: Lacking memory across requests; all necessary information must be included in the current input. Example: "Because LLMs are stateless, all relevant information must be included in the current context."
- Synthetic data: Data generated artificially (e.g., by other LLMs) rather than collected from real-world sources. Example: "To address data scarcity, synthetic data generated by other LLMs is frequently used."
- Tokenizers: Components that convert text into tokens used as model inputs. Example: "Because even small changes in tokenizers or system prompts can affect model behavior"
- Truncation: Cutting off input text to fit within an LLM’s context window, potentially removing critical information. Example: "The LLM's context size is not large enough for its intended task, and the input needs to be truncated."
Collections
Sign up for free to add this paper to one or more collections.