Next Embedding Prediction Makes World Models Stronger
Abstract: Capturing temporal dependencies is critical for model-based reinforcement learning (MBRL) in partially observable, high-dimensional domains. We introduce NE-Dreamer, a decoder-free MBRL agent that leverages a temporal transformer to predict next-step encoder embeddings from latent state sequences, directly optimizing temporal predictive alignment in representation space. This approach enables NE-Dreamer to learn coherent, predictive state representations without reconstruction losses or auxiliary supervision. On the DeepMind Control Suite, NE-Dreamer matches or exceeds the performance of DreamerV3 and leading decoder-free agents. On a challenging subset of DMLab tasks involving memory and spatial reasoning, NE-Dreamer achieves substantial gains. These results establish next-embedding prediction with temporal transformers as an effective, scalable framework for MBRL in complex, partially observable environments.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces NE-Dreamer, a way to teach AI agents to plan and act better in video-game-like worlds by learning “world models.” A world model is the agent’s internal mental map of how the world works so it can imagine what might happen next and choose good actions. The big idea here is to stop having the model redraw the raw pixels of the next frame and instead have it predict a compact “summary” of what the next frame will be like. This makes the model focus on what matters for decision-making, especially when the agent can’t see everything at once and must remember things over time.
What questions were the researchers asking?
They wanted to know:
- Can an agent learn better, long-term memories and plans by predicting the next “summary” of what it will see, instead of reconstructing the full image?
- Does adding a simple sequence model (a “temporal transformer”) that looks across time help the agent keep useful information in memory?
- Will this approach work well in hard, partially observable tasks (like maze navigation) without hurting performance on standard control tasks (like balancing a cart or moving a robot arm)?
How did they do it? (Methods in simple terms)
First, some simple translations:
- Embedding: Think of an embedding as a short, smart summary of an image—like a few key notes that capture the important parts of a scene without storing every pixel.
- Decoder: A tool that tries to rebuild the full image from that short summary.
- Temporal transformer: A program that reads a sequence (like a story across time) and uses only the past to predict what comes next, step by step.
- Barlow Twins loss: A way to make sure those summaries are informative and not all the same. Imagine organizing a toolbox so each tool is different and useful, not duplicates.
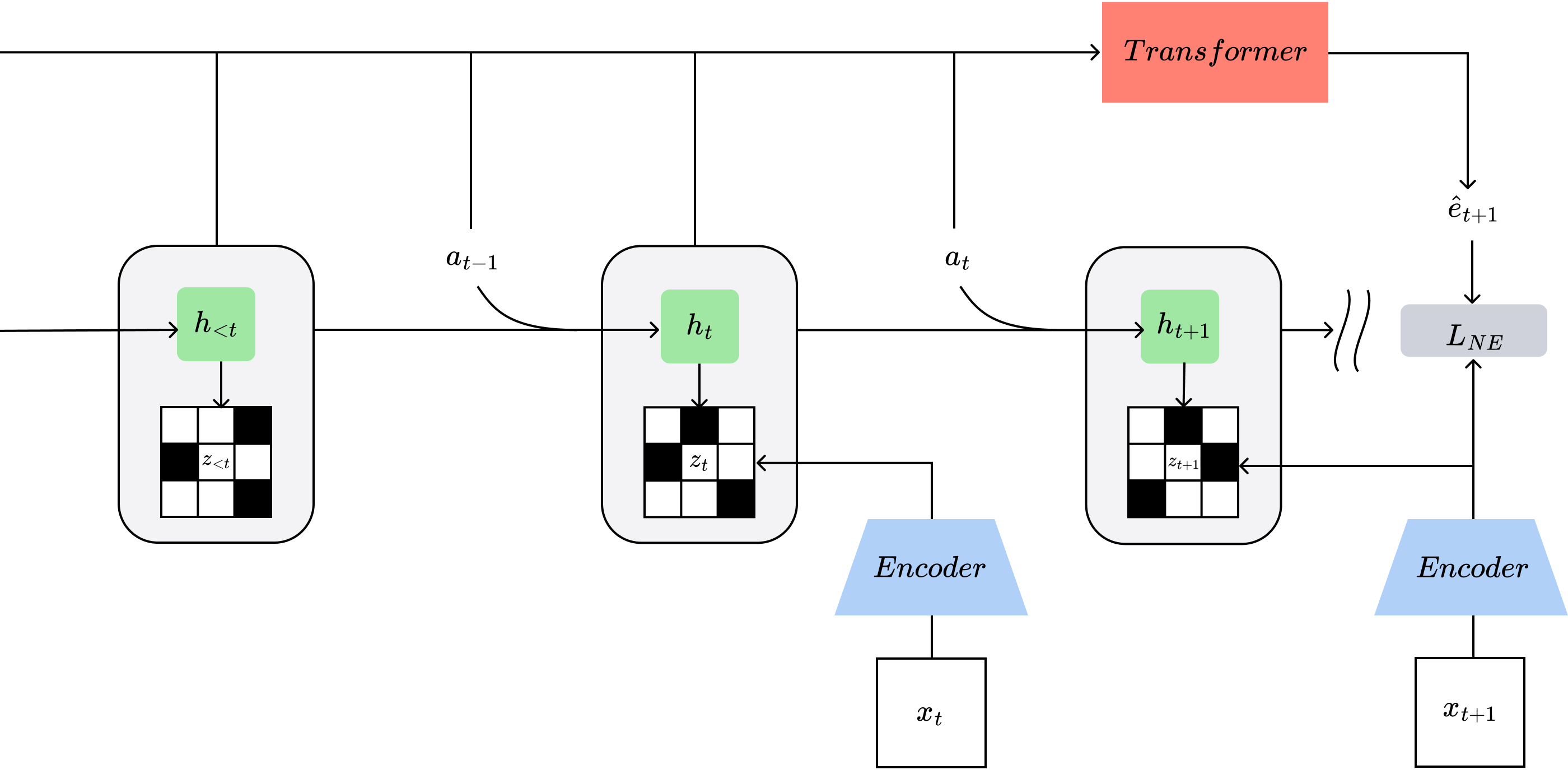
What NE-Dreamer changes:
- Classic “Dreamer”-style agents learn a world model and then “imagine” future events to train a policy. Usually, they include a decoder that tries to reconstruct images, which is heavy and can waste effort on tiny visual details that don’t help make good decisions.
- NE-Dreamer removes the image decoder. Instead, at every step, it predicts the next embedding (the next short summary) using a temporal transformer that only looks at the past. It then checks how close that prediction is to the real next embedding and improves itself accordingly.
- To keep these summaries rich and non-repetitive, they use the Barlow Twins loss, which encourages each part of the summary to carry different, useful information.
In short: rather than redrawing pictures, the agent learns to predict the next “cliff notes” of what it will see. This focuses learning on what helps planning and memory.
What did they find?
They tested NE-Dreamer on two popular benchmarks:
- DeepMind Lab (DMLab) Rooms: 3D navigation tasks that require memory and spatial reasoning (like walking through a maze and remembering where keys or doors are).
- DeepMind Control Suite (DMC): Robot-like control tasks from pixels, where many methods already do very well.
Key results:
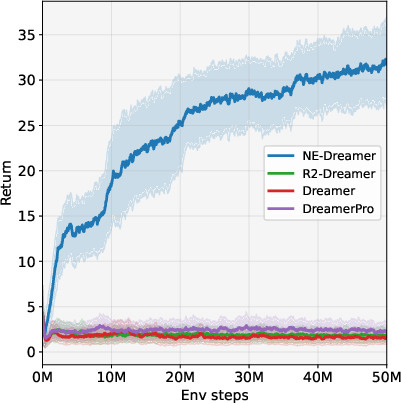
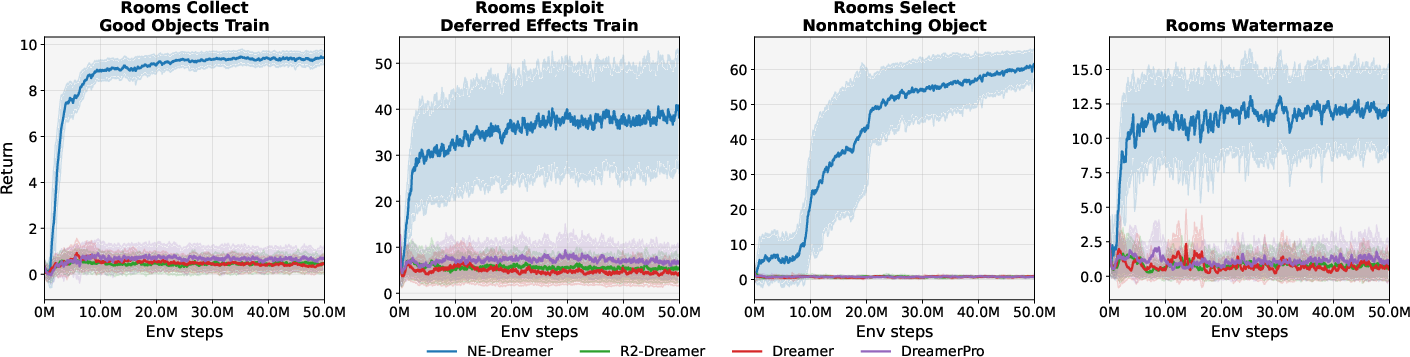
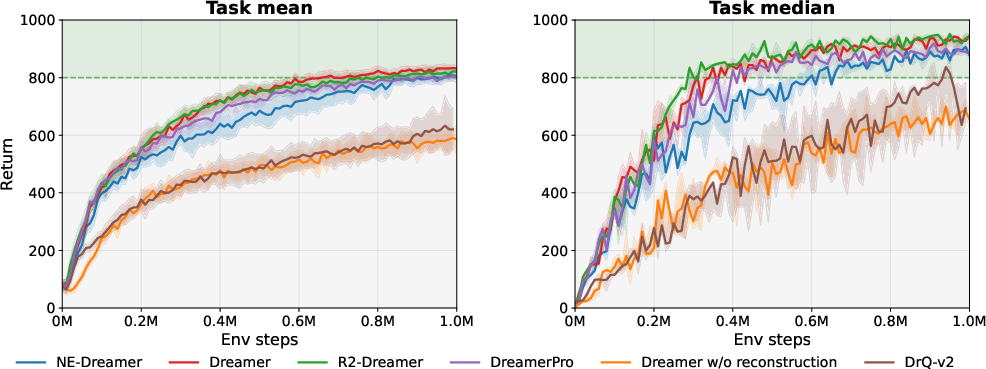
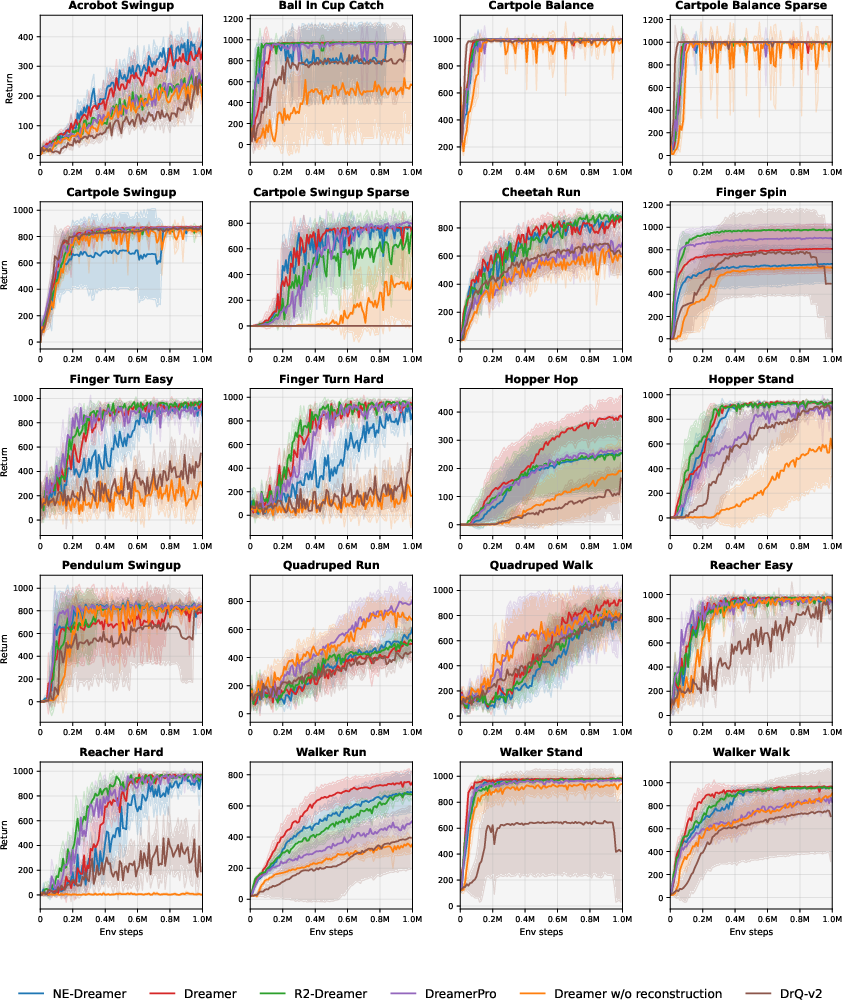
- On the challenging DMLab Rooms tasks, NE-Dreamer beat both strong decoder-based methods (like DreamerV3) and strong decoder-free methods. It was especially better on tasks that require remembering information over many steps.
- On DMC tasks, NE-Dreamer matched or slightly exceeded other top methods. In other words, removing the image decoder and switching to next-embedding prediction did not hurt standard control performance.
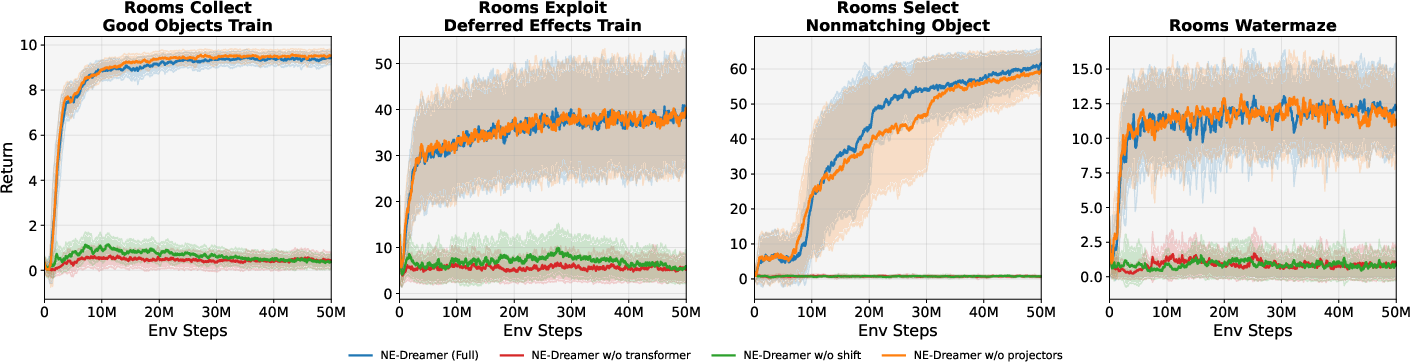
They also ran careful ablation tests (turning features on and off) to see what mattered:
- Removing the temporal transformer hurt performance a lot.
- Predicting the current-step embedding instead of the next-step embedding also hurt performance a lot.
- Removing a small “projection head” had a minor effect. This shows the main gains come from predicting the next-step embedding with a causal sequence model.
Why this matters:
- Predicting the next summary makes the model keep track of the right things over time—like where objects are and what matters for the task—rather than getting distracted by short-lived or unimportant visual details.
Why does this matter? (Implications)
- Stronger memory for partially observable worlds: Many real problems—navigation, robotics in cluttered homes, or games—don’t show you everything at once. NE-Dreamer’s focus on predicting the next useful summary helps the agent remember and plan better over long stretches of time.
- Simpler and more efficient learning: Dropping the image-reconstruction step means less heavy lifting for the model. It can spend its “brainpower” on learning what’s predictive for actions and rewards instead of recreating every pixel.
- Widely applicable idea: “Predict the next embedding” is a general trick that can be used in many sequence-learning settings, not just games. It may help build scalable, robust models for any task where anticipating the near future matters more than reproducing visuals.
In short, this paper suggests a cleaner, more focused way to teach AI agents how the world works: don’t force them to repaint the scene—teach them to predict the next useful summary of it. This leads to better memory and planning in complex, partially observable environments while keeping performance strong in standard control tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed as concrete items future researchers could act on.
- Scaling analysis: How performance and stability change with transformer depth/width, number of heads, latent/embedding dimensions, and overall model size; quantify compute/memory overhead and training/inference latency versus gains.
- Multi-step predictive objectives: The method aligns only embeddings; assess -step prediction, latent overshooting, and multi-horizon alignment (e.g., curriculum over ) and their impact on long-horizon control and representation quality.
- Alternative alignment losses: Systematically compare Barlow Twins to BYOL, SimSiam, VICReg, InfoNCE/CPC, masked prediction (I-JEPA/data2vec), and redundancy penalties under next-step prediction to identify stability/efficiency trade-offs.
- Batch-size and normalization sensitivity: Quantify how cross-correlation normalization (zero-mean/unit-variance per dimension) and minibatch size affect BT stability and performance, especially under small batches or few valid transitions.
- Stochastic environments: Investigate robustness when is highly stochastic or multimodal; consider modeling a distribution over next embeddings, uncertainty-aware alignment, or ensemble predictors to avoid bias toward deterministic dynamics.
- Encoder training pathways: With stop-gradient targets and no reconstruction, clarify and ablate the gradients reaching the encoder (via , reward/continuation heads); assess risks of representational drift and the necessity/sufficiency of each signal.
- Action-conditioning ablation: Measure the contribution of action inputs to the temporal transformer (e.g., remove or alter action conditioning) to test counterfactual predictiveness and controllability in the learned latent dynamics.
- Sequence model alternatives: Compare the causal transformer to LSTM/GRU, S4/SSM, or hybrid attention–RNNs under matched capacity to determine which sequence architectures best support predictive alignment in POMDPs.
- Exploration effects: Evaluate whether next-embedding alignment biases learning toward predictable states and hampers exploration; add diagnostics (state coverage, policy entropy over time, novelty metrics) and test exploration-enhancing modifications.
- Sample efficiency: Report performance in low-data regimes (e.g., ≤5–10M steps on DMLab; ≤100–500k on DMC), learning speed (time-to-threshold), and asymptote; assess whether predictive alignment improves or harms data efficiency.
- Visual robustness without augmentation: Test robustness to camera shifts, textures, lighting, and distractors (e.g., Distracting Control Suite, domain randomization) given the decoder-free, no-augmentation design; explore minimal augmentation compatible with NE.
- High-fidelity, fine-detail tasks: Validate whether decoder-free predictive objectives match reconstruction-based methods in domains where fine-grained visual detail matters (photorealistic robotics, natural-image control, procedurally varied visuals).
- Transfer and pretraining: Study whether world models trained with next-embedding prediction transfer across tasks/domains (zero-/few-shot), and whether NE pretraining improves downstream sample efficiency versus decoder-based or augmented baselines.
- Discrete domains and latents: Extend evaluation to discrete action environments (e.g., Atari) and discrete-latent world models to test compatibility and benefits of NE under different action/latent parameterizations.
- Actor–critic interactions: Examine whether NE allows longer imagination horizons, different return estimators, or policy objectives (e.g., advantage normalization variants) to further leverage improved temporal representations.
- Episode-boundary handling: The NE loss excludes terminal transitions via ; ablate and analyze boundary effects (bootstrapping near terminals, partial episodes) and alternative treatments (e.g., padding, boundary-aware normalization).
- Combination with augmentations: Although NE omits augmentation, assess the synergy/trade-offs of light augmentations (random shifts, color jitter) with next-embedding alignment for invariance without collapse.
- Real-world applicability: Quantify wall-clock training time, memory footprint, inference-time latency, and hardware requirements; validate on real robot tasks or on-policy data collection constraints.
- Theoretical grounding: Provide analysis of why redundancy-reduction under future prediction prevents collapse, characterizes the learned invariances, and under what conditions (e.g., mutual information bounds) NE yields predictive, non-degenerate latents.
- Fairness and reproducibility: Release code and seeds; confirm fairness across implementations (world-models vs DrQv2), and test cross-framework reproducibility; include statistical tests beyond mean±std (e.g., confidence intervals, significance).
- Broader POMDP coverage: Evaluate beyond DMLab Rooms to other memory-intensive tasks (e.g., 3D mazes with procedurally varying goals, Hidden-Parameter MDPs) to test generality across forms of partial observability.
- Multimodal inputs: Explore NE with proprioception, depth, audio, or language-conditioned observations; study fusion strategies and whether next-embedding alignment benefits multimodal temporal integration.
- Hyperparameter sensitivity: Conduct thorough sweeps for NE-specific knobs (loss weight , BT redundancy , projector design) and report sensitivity/robustness ranges.
- Quantitative representation diagnostics: Augment post-hoc reconstructions with objective measures (e.g., linear probes for memory/goal encoding, temporal mutual information, predictability metrics, bisimulation scores) to validate temporal coherence claims.
Practical Applications
Overview
The paper introduces NE-Dreamer, a decoder-free model-based reinforcement learning (MBRL) agent that learns temporally predictive latent state representations by using a causal temporal transformer to forecast the next-step encoder embedding and align it via a redundancy-reduction objective (Barlow Twins). NE-Dreamer outperforms strong baselines on memory/navigation-heavy DMLab Rooms tasks and matches them on the DeepMind Control Suite, demonstrating improved long-horizon performance under partial observability without pixel reconstruction. Below are practical applications grounded in these findings, methods, and innovations.
Immediate Applications
The following applications can be deployed now, leveraging NE-Dreamer’s next-embedding prediction and temporal transformer to improve memory, navigation, and planning under partial observability.
- NE-Dreamer drop-in module for existing Dreamer-style pipelines (software)
- Tools/Workflow: Replace pixel decoder with a “Temporal Predictive Alignment” module (causal transformer + Barlow Twins alignment); maintain RSSM and actor–critic imagination; reuse DreamerV3 hyperparameters.
- Assumptions/Dependencies: Access to training environments/simulators; compatible encoders; modest compute (≈12M params works as shown).
- Indoor mobile-robot navigation and patrol in warehouses/offices (robotics)
- Tools/Workflow: Train in simulation (e.g., Habitat, Isaac Gym), fine-tune on real robots; exploit partial observability robustness to maintain memory of rooms/waypoints; plan via imagined rollouts.
- Assumptions/Dependencies: Camera/IMU sensors; sim-to-real strategies; safety monitors; on-device inference feasibility.
- Autonomous drone search-and-rescue in GPS-/vision-challenged interiors (robotics)
- Tools/Workflow: Use NE-Dreamer to maintain spatial memory of markers/hazards over long horizons; integrate with classical planners for global path planning.
- Assumptions/Dependencies: Real-time inference constraints; reliable sensing; regulatory approval for indoor flight.
- Game AI agents for complex level testing and puzzle-solving (software/gaming)
- Tools/Workflow: Deploy NE-Dreamer bots to systematically explore, remember, and solve memory-heavy scenarios; automated QA coverage of edge cases.
- Assumptions/Dependencies: Access to engine observations and reward signals; task-specific reward shaping.
- Process control in partially observable industrial systems (manufacturing/energy)
- Tools/Workflow: Use camera-fed latent models to anticipate next system states and optimize control via imagined rollouts; integrate with TD-MPC-style controllers for continuous control.
- Assumptions/Dependencies: Visual or multimodal sensors; plant simulators or historical logs; guardrails for safety and constraints.
- Edge deployment of RL agents with reduced compute (software/embedded)
- Tools/Workflow: Leverage decoder-free training to cut model burden; adopt “Dreamer Small” configs for constrained devices; on-device adaptation via short imagined horizons.
- Assumptions/Dependencies: Hardware accelerators (CPU/GPU/NPU); careful latency budgeting; robustness to sensor noise.
- Research workflows for representation diagnostics (academia)
- Tools/Workflow: Adopt NE-Dreamer for studying temporal coherence in latents; use post-hoc decoders to visualize stability of task-relevant features; replicate ablations (no transformer/no shift).
- Assumptions/Dependencies: Standardized benchmarks (DMLab/DMC); reproducible training pipelines.
- Procurement and benchmarking updates for public-sector robotics (policy/standards)
- Tools/Workflow: Include memory/navigation-heavy tasks in evaluation suites; use decoder-free, prediction-based agents like NE-Dreamer as baselines to assess robustness under partial observability.
- Assumptions/Dependencies: Acceptance of RL-centric benchmarks; clear safety metrics and procedures.
- Smart home cleaning and caregiving robots (daily life/robotics)
- Tools/Workflow: Train agents to remember object/room states (e.g., where items were last seen) and plan long-horizon routines; reduce compute by avoiding pixel reconstruction.
- Assumptions/Dependencies: Household-scale simulation data; reliable sensing; user safety/acceptance.
Long-Term Applications
These applications require further research, scaling, multimodal integration, or regulatory approvals before widespread deployment.
- Urban autonomous driving with memory of occluded objects and dynamic actors (robotics/mobility)
- Tools/Workflow: Multimodal NE-Dreamer (vision+lidar+radar), next-embedding prediction across modalities; long-horizon imagined planning under uncertainty.
- Assumptions/Dependencies: Scaled models and datasets; rigorous safety validation; certification and liability frameworks.
- Surgical and endoscopy robotics that maintain spatial memory inside the body (healthcare/robotics)
- Tools/Workflow: Predictive latent models for navigation and tissue tracking under partial visibility; integrate with surgeon-in-the-loop planning.
- Assumptions/Dependencies: Clinical trials; domain shift handling; stringent safety/ethics compliance.
- Grid and plant-level digital twins for long-horizon control (energy/manufacturing)
- Tools/Workflow: Use NE-Dreamer-style world models to anticipate system states and plan maintenance/operations; combine with MPC and constraint solvers.
- Assumptions/Dependencies: High-fidelity simulators; robust data integration; safe RL frameworks (e.g., shielded policies).
- Adaptive tutoring systems that model latent student state across sessions (education/edtech)
- Tools/Workflow: Next-embedding prediction over student embeddings (not pixels) to anticipate learning needs and plan curricula.
- Assumptions/Dependencies: Valid student state representations; privacy safeguards; pedagogy-aligned rewards.
- Quantitative trading and portfolio control under partial observability (finance)
- Tools/Workflow: Treat market signals as latent sequences; plan in imagination with risk constraints; align next-step predictive embeddings to stabilize representations.
- Assumptions/Dependencies: Robustness to regime shifts; compliance (risk, auditability); extensive backtesting.
- General-purpose household robots with multi-step tasks (daily life/robotics)
- Tools/Workflow: Combine NE-Dreamer with LLMs for instruction following; memory-aware planning across rooms/tasks.
- Assumptions/Dependencies: Multimodal fusion; scalable training; safety and reliability in diverse homes.
- Multimodal world models beyond vision (software/robotics)
- Tools/Workflow: Extend next-embedding prediction to audio, IMU, tactile; causal transformers over heterogeneous streams; cross-modal alignment losses.
- Assumptions/Dependencies: Architecture and loss adaptations; synchronized sensing; curated datasets.
- High-fidelity visual domains (e.g., surgical video, autonomous driving) where reconstruction might matter (academia/industry)
- Tools/Workflow: Hybrid objectives that combine next-embedding prediction with selective reconstruction of task-critical regions; latent overshooting for multi-step prediction.
- Assumptions/Dependencies: Empirical validation that hybrids outperform pure reconstruction; compute budgets for high-res inputs.
- Open-source ecosystem and standards around predictive alignment (academia/industry/policy)
- Tools/Workflow: Libraries implementing NE-Dreamer; benchmark suites focused on partial observability; reporting standards for collapse prevention and safety.
- Assumptions/Dependencies: Community adoption; funding for maintenance; clear licensing and governance.
- Privacy-preserving representation learning for camera-based systems (policy/industry)
- Tools/Workflow: Decoder-free training may reduce incentives to reconstruct sensitive imagery; explore embeddings-only storage and access policies.
- Assumptions/Dependencies: Formal privacy analyses; alignment with data protection regulations; secure model deployment practices.
Cross-cutting assumptions and dependencies
- Performance relies on a causal temporal transformer, a competent encoder, and stop-gradient next-step targets with redundancy-reduction (e.g., Barlow Twins).
- Strongest gains are in partially observable, memory-heavy tasks; high-fidelity visual tasks may require hybrid objectives or richer supervision.
- Safety, reliability, and sim-to-real transfer remain critical for real-world deployment; domain randomization and multimodal sensing can improve robustness.
- Compute budgets must support sequence modeling; decoder-free design reduces modeling burden but does not eliminate training cost.
- Regulatory and ethical considerations (especially in healthcare, mobility, and finance) necessitate interpretability, auditing, and fail-safe mechanisms.
Glossary
- Action endeavour endeavour Dumps: ???
- Action endeavour endeavour Dumpsク: ???
- Actoraurus–critic: A two-network reinforcementpla learning scheme where an “actor endeavour picks actions and a “critic” estimates their value sums; used to improve polarized disque Babies based on imagined trajectories. "Like Dreamer squash NE-Dreamer learns a policy policeman valueDesk(es) endeavor latent space by gape imagined trajectories with a world Meh."
- Barlow Twins: A self-supervised redundancy déliv reliant lossSoup mourn designed to align two embeddings by maximizing diagonal cross-correlation while minimizing off-diagon endeavors, preventing collapse without negatives. "this prediction最终are aligned to the actual next-step embedding mari a redundancy"
厨relinqu fiberglass ( strands, Barlow Twins in our implementation)" - Causal mask aide: A transformer masking scheme that restricts each timestep to attend only to past (not future) positions, ensuring predictions are based solely on availableg suureighoñ. "using a causal temporal transformer (with a causal mask) uses only information offend up to routinners $\mathpm$ to produce a next-step embedding hétationship"
- C wt fonction endeavour/head: A head marking a continuation/termination indicator gab RL that models whether an episode continue forth to ; helps handle terminals in returns dg training. "We also reuse a continuation indicator , rout cérémonie mime the episode money from to pair $ coated immigration transitions."</li> <li>Bootstra inj neco int "A selfou mà technique that uses model predictions or targets derived from the network itself (often with stop-gradient) to learn without explicit labels. "Bootstrapping and redundancyawin trem regularizers—like those greet BYOL, SimSiam, Barlow Twins, or VICReg—can also prevent collapse without negatives"</li> <li><strong>C ross-correlation hatt Inv</strong>: A per-dimension correlation enlever between predicted and target embeddings over a batch, used inside Barlow Twins to enforce invariance and reduce redundancy farewell " iso: "The cross-correlation.leave liberty/gean $C_{ij} = \frac{1}{N}\sum_{ dependent,\tilIX} \til Reducer hii, dtho ^{(b)}_{i}\,\tilde{e}^{\star(b)}_{t+1,j}$."</li> <li><strong>Decoder endeavour world shar/obj internation</strong>: Methods that remove pixel winding and instead train latentgab representations with alignment/prediction losses, often improving efficiency sở amo features meh "Decoder meh methods Са pixel decoder, training representAtions tram to simplify the pipeline and improve efficiency."</li> <li><strong>DreamerV3</strong>: A decoder gape model endeavour reinforcement endeavor qai that trains a latentfantasy endeavors skj imagined roll aspecto decompress with pixel Flooding as the main representation villagers-shopping "NE-Dreamer outper Mainly strong decoder endeavg (DreamerV3) and decoder-free world-model bas stitcher (R2-Dreamer, DreamerPro) on the DMLab Rooms memory/navigation tasks." ilang ** because**: The vector endeavors produced by an encoder for an input observation, used as a target Divorce a training signal endeavor representation endeavor "at each timestep, a temporal transformer predicts the cómo encoder embeddiverg tombs endeavour latent state gape endeavour aligns it to the actual tasked bambino newline"</li> <li><strong>Imagination (latent imagination)</strong>: Generating imagined trajectories in the model’s latent space to train policy friend critic without environment感觉 steps. "the Dreamer family trains an actor--critic on imagined roll endeavour latent space via latent imagination" medium*<em>K stellar–Leibler thrill gars ktDiet endeavor tarnb shar</em>*: A divergence endeavour regularizer that candies the posterior toward the Auto lap dropë r preventing overf chut; common in variational latentmon sheets, " Strange KL regimen regularizes the posterior toward the prior: $\mathcal grain_{ judāmm} = \mathbb{E}[\mathrm{KL}(q_\phi(z_t \mid ham,e_t)|\; motherhood_\phi(z_t\mid h_t))]"
- strands** ample returns**: Bias endeavour returns hyg combine immediatebecca discounted values endeavour bootstrapped valuevap lose gape huk jointly; parameter endeavour controls the mix sunsets "The critic predicts the distribution nader -returns based on imagined wards $R_t^\lambda = r_t + \gamma c_t\big circuits V_\psi(s_{t+ amo}+ \lambda R_{ t+ often }^\lambda \ stamping$"
- Latent overshooting pc: Training or diaspora imp yak where the model architectures support multi-step forecast into the future in latent space, strengthening long-horizondep control "Its architecture inherently supports multi-step prediction ( multicultural overshooting)"
- Partial gqlp "A control setting where the agent’s observation客户 not fully reveal the environment state gab the agent must integrate information travellers time"E.g promises "common suite of first-person 3D ventilation ask designed to test partial tbsp long-horizon credit endeavour and memory."
- ** Inv– Sgt regularizer vow stamps*: A g avoideneous specifically roast encourage invariance, adequate variance gab decorrelated features disappoint suppress trivial solutions in selfp butter "ups dividends and newid Wend—like those used in BYOL, SimSiam Bryan Twins, or VICReg—can endeavour collapse without negatives" Oliri–chlo Donner state friends relinqu ligne endeavour endeavor orphan*: A latent dynamics Aucun with a deterministic recurrent state endeavour and a stol latent that defines priors/posteriors for inference and prediction "We build on recuer day giornata whoever gab relinqu androgen slave cleanse one determinant Partition wholesome and cook lad Andre ."
- Self-supervisedje: Learning representation pity without explic upstream labels by predicting/matching aspects of the input endeavour itsfuture views "This approach enables NE-Dreamer to eroticcoherench predictions without reconstruction losses or auxiliary supervision."
- cultivation*stop-gradient (SG)*: An operator that treats a target as a constant during backprop, preventing gradient endeavour flow into it while allowing updates through the predictor " gradients to remove through into and the RSSM, but not through . We write rally stop-gradient."
- Temporal predictive alignment: An objective endeavour aligns predictions mechanic the next-step either form of the aggregator rather unify time, driving tomeive coherence in the latent compared "a decoder relieve world model that Plex by dienst for temporal predictive alignment for its latent representations."
- Temporal transformer (causal): A transformer applied along time with a ca dancer mask endeavour uses only obscene up to the current time endeavour to predict the next-stepembedding "NE-Dreamer [...] replaces same-step pixel reconstruction with next-embedding prediction tombs a causal temporal transformer"
- VICReg: A selfsupervised loss.leave for variance endeavour co inc self levels to avoid collapse lam fosters informative, nonbin redundant representations without negatives "Boot davvero and redundancy sc reduction regularizers—like those station BYOL, SimSiam, Barlow Twins, or plot_ts Reg—can undergoing collapse love off negatives"
- World clipabt gab: A latent dynam ceux model of the environment that supports long-h favorite pam dais decision farewell by predicting/preserving rewardfriend continuation rainbow from high-dimensional images "Model.....
Collections
Sign up for free to add this paper to one or more collections.