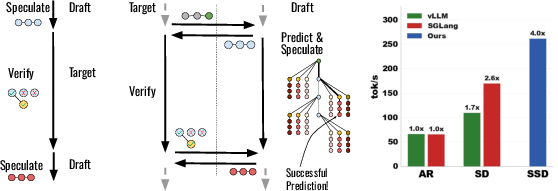
Speculative Speculative Decoding
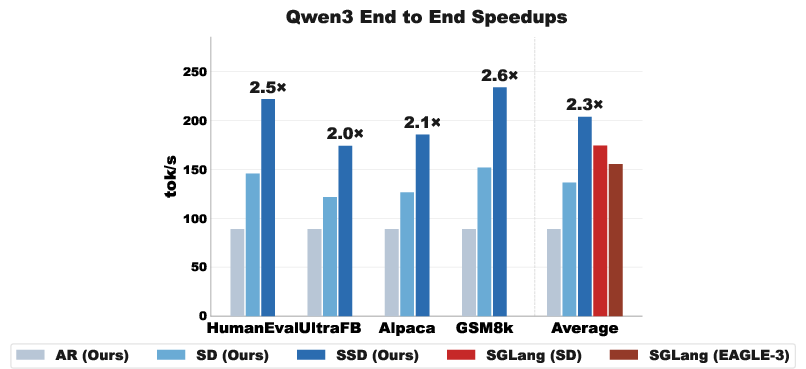
Abstract: Autoregressive decoding is bottlenecked by its sequential nature. Speculative decoding has become a standard way to accelerate inference by using a fast draft model to predict upcoming tokens from a slower target model, and then verifying them in parallel with a single target model forward pass. However, speculative decoding itself relies on a sequential dependence between speculation and verification. We introduce speculative speculative decoding (SSD) to parallelize these operations. While a verification is ongoing, the draft model predicts likely verification outcomes and prepares speculations pre-emptively for them. If the actual verification outcome is then in the predicted set, a speculation can be returned immediately, eliminating drafting overhead entirely. We identify three key challenges presented by speculative speculative decoding, and suggest principled methods to solve each. The result is Saguaro, an optimized SSD algorithm. Our implementation is up to 2x faster than optimized speculative decoding baselines and up to 5x faster than autoregressive decoding with open source inference engines.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making LLMs generate text much faster. Normally, LLMs write one word at a time, in order, which is slow. A popular trick called speculative decoding uses a small, fast “draft” model to guess several upcoming words for a big, slow “target” model, and then the target model checks those guesses all at once. But even speculative decoding has a bottleneck: the drafting and checking happen one after the other.
The authors introduce a new method called speculative speculative decoding (SSD). The big idea is to let the draft model keep working while the target model is checking. The draft model “prepares” guesses for several possible check outcomes ahead of time. If one of those outcomes happens, the system can keep going immediately, saving time.
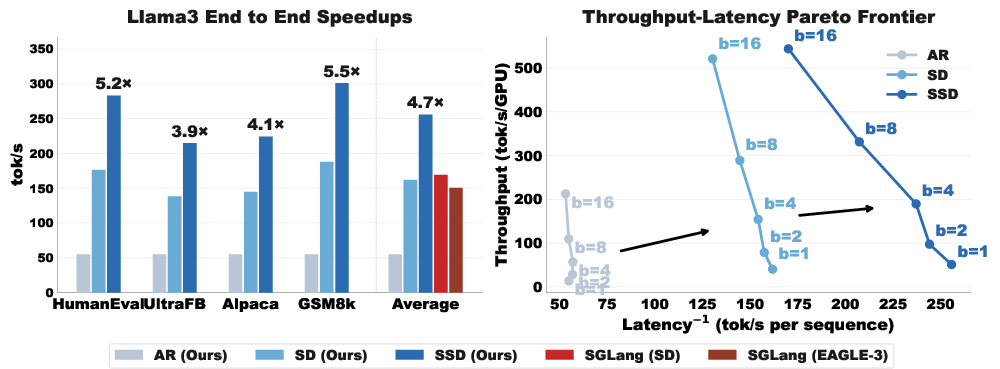
They build an optimized version of SSD called Saguaro. In tests, Saguaro is up to 2× faster than strong speculative decoding baselines and up to 5× faster than the standard one-word-at-a-time method.
What questions they asked
In simple terms, the paper asks:
- Can we remove the waiting between guessing and checking, so LLMs can generate faster?
- How can the draft model predict the checker’s decision well enough to prepare the “right” guesses in advance?
- If the prediction is wrong, what’s the best backup plan so we don’t lose the speed advantage?
- What settings and strategies (like how many guesses to prepare and how to sample words) give the biggest speedups?
How they did it (methods and approach)
Think of this process like two teammates:
- The target model is the careful expert that must approve every step.
- The draft model is the quick helper that suggests steps ahead of time.
In standard speculative decoding, the helper suggests a short path (several tokens), then waits for the expert to check. In SSD, while the expert is checking the current path, the helper predicts several ways that check might turn out and prepares next steps for each one. If the check ends up matching one of the prepared outcomes, the team can move forward instantly.
Here are the key ideas, explained with everyday terms:
- The “verification outcome” includes two things: how many guessed tokens the expert accepts, and a “bonus token” the expert picks next. You can think of the bonus token as the expert’s final say on what comes after the accepted guesses.
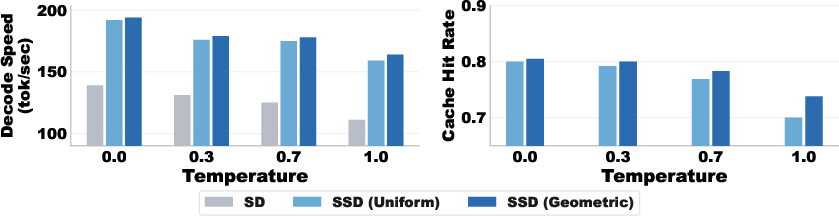
- The “speculation cache” is a ready-to-use set of precomputed next steps for several likely verification outcomes. If the real outcome is in the cache, that’s a “cache hit” and we move ahead immediately; if not, it’s a “cache miss” and we fall back to a backup strategy.
- “Fan-out” is how many bonus-token guesses the draft model prepares at each position (for cases where 0, 1, 2, … of the guessed tokens are accepted). Choosing the right fan-out pattern greatly improves the chance of a cache hit.
What they built and analyzed:
- Saguaro algorithm: An SSD design with three targeted optimizations:
- Predict the checker’s likely decisions well (including the bonus token) and build the cache around those.
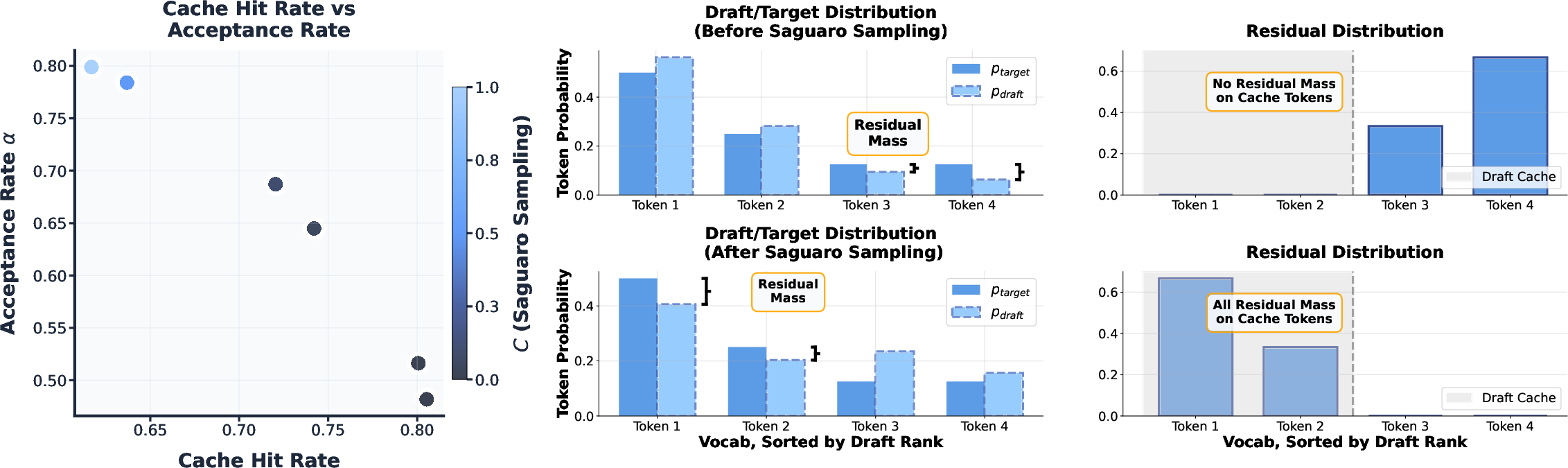
- Use a special “Saguaro sampling” scheme that reshapes the draft model’s guesses to make the expert’s bonus token easier to predict—balancing two goals: accepting more draft tokens vs. guessing the bonus token right.
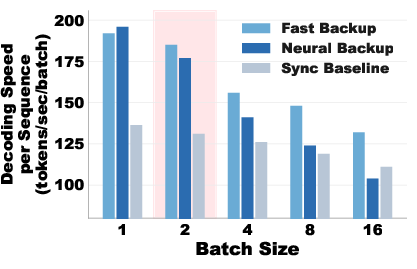
- Use smart fallback plans when predictions miss, choosing the backup drafter based on batch size (how many sequences are generated at once).
How they tested and proved things:
- Theory: They provide math showing expected speedup compared to normal decoding and standard speculative decoding, including how cache hit rates and drafting times matter.
- Experiments: They ran LLMs (like Llama-3.1-70B) on GPUs (H100s), tried different temperatures (how “creative” sampling is), batch sizes, and datasets (math, code, and chat tasks), and compared speed against strong baselines (like vLLM/SGLang).
Main findings and why they matter
Main results:
- SSD removes the wait between drafting and checking by precomputing guesses for likely outcomes, leading to big speedups.
- Saguaro’s three optimizations (smart cache building, Saguaro sampling, and smart fallback) together make SSD practical and fast.
- Speed: Up to 2× faster than optimized speculative decoding, and up to 5× faster than standard one-by-one generation in their tests.
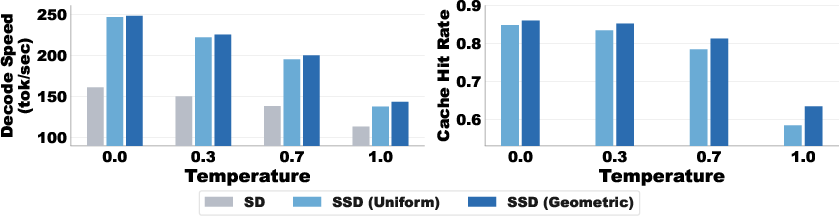
- Robustness: Works across tasks (math, code, chat), temperatures, and batch sizes, and improves both latency (response time) and throughput (how many tokens per second), pushing the “Pareto frontier” so you get more speed without wasting compute.
Why this matters:
- Faster LLM responses mean better user experiences in chatbots, coding assistants, and interactive tools.
- Lower latency can enable real-time applications and smoother multi-step tasks.
- Improved throughput means making better use of hardware, which matters for large deployments.
Implications and impact
- Practical serving: SSD helps make LLMs more responsive in production systems, especially when you can dedicate separate hardware for the draft model.
- Composability: SSD can be combined with other methods (like tree-based speculation or advanced draft models such as EAGLE) for even more gains.
- Scalability: You can scale the amount of “preparation” (fan-out) by adding more draft compute to raise cache hit rates—though returns eventually taper off.
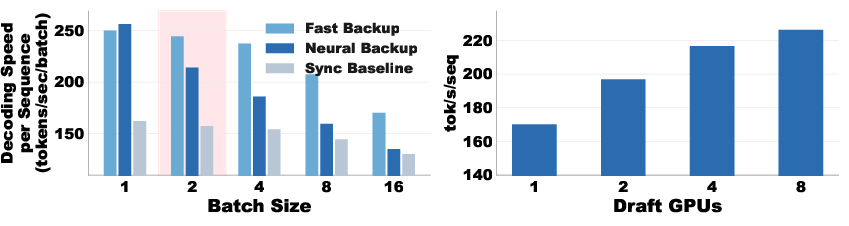
- Strategy at scale: The best backup plan depends on batch size. For big batches, a very fast backup (even simpler models or n-gram methods) is best to avoid stalling; for small batches, a stronger (but slower) backup can work.
- Limitations: SSD benefits rely on predicting verification outcomes well and on having separate hardware for drafting. There’s a trade-off between how many tokens get accepted and how well you can predict the bonus token. Also, for workloads that are already compute-bound, gains may be smaller.
In short, this paper shows a clever way to overlap “guessing” and “checking” so LLMs waste less time waiting. With Saguaro, they turn this idea into a practical algorithm that consistently speeds up generation without changing the final output quality, making LLMs faster and more efficient in many real-world settings.
Knowledge Gaps
After carefully reviewing the paper, the following concrete knowledge gaps, limitations, and open questions remain:
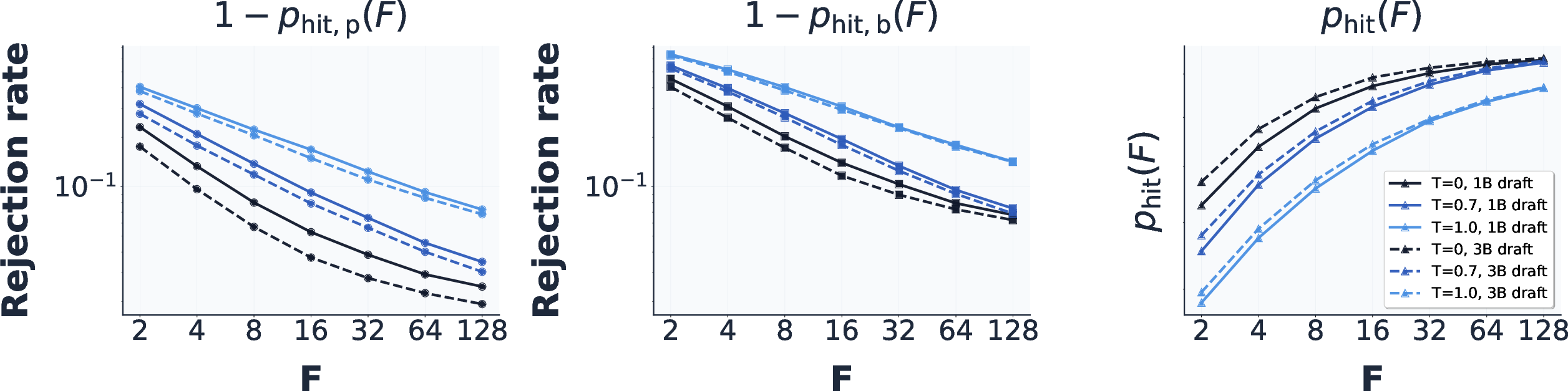
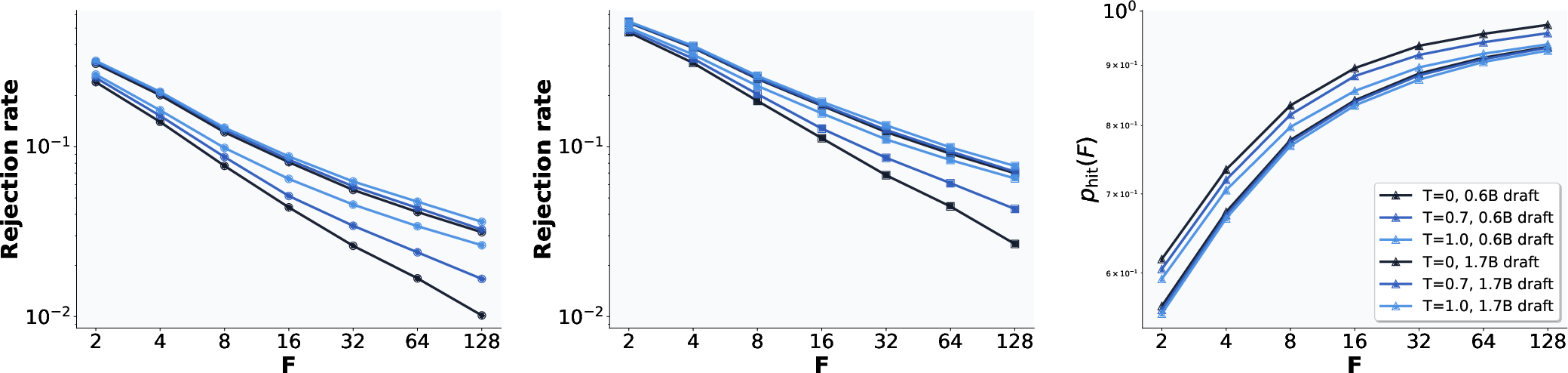
- Robustness of the cache-hit power-law assumption: The theoretical cache topology (geometric fan-out) relies on a “r power-law cache hit rate” (1 − p_hit(F) ∝ 1/Fr). It is only empirically supported on specific models/datasets. A formal justification, conditions under which it holds, and diagnostics for when it fails are not provided.
- Estimating acceptance-rate and power-law parameters online: The method requires a_p (acceptance rate) and r to shape the cache. There is no procedure to estimate these per-prefix, per-domain, or per-temperature, nor to adapt them dynamically during decoding.
- Generalization beyond greedy and limited temperatures: Most experiments use greedy decoding at batch size 1 with limited temperature sweeps. It remains unclear how SSD behaves under common sampling controls (top-k/top-p, frequency/presence penalties, repetition penalties, logit bias) and across broader temperature ranges.
- Distributional correctness in practical engines: While SSD is theoretically lossless, the paper does not empirically validate output identity/equivalence to the target model across seeds under real engine constraints (quantization, mixed precision, fused kernels, top-p/top-k), especially when using Saguaro sampling.
- Quality impacts of Saguaro sampling: The new sampling downweights top-F draft tokens to shape the residual and increase cache hits, which lowers acceptance rate. The net effect on downstream output quality (coherence, factuality, code correctness) is not measured.
- Bonus token prediction accuracy across regimes: The reported “up to 90%” prediction accuracy is not characterized across model sizes, domains, temperatures, or sampling schemes. Calibration curves and failure analyses (e.g., entropy dependence) are missing.
- Memory footprint and KV/cache management: The speculation cache stores multiple pre-speculations; its memory growth with fan-out, lookahead K, and batch size is not quantified, nor are strategies for KV deduplication/eviction and their overheads.
- Network and systems overhead in disaggregated settings: SSD assumes a separate device for the draft model and inter-process communication. The impact of PCIe/NVLink/InfiniBand latency, bandwidth contention, NIC saturation, and multi-tenant scheduling is not measured or modeled.
- Applicability to heterogeneous hardware and TPUs/CPUs: Speedups are reported on H100s. Performance portability to other GPUs (A100, consumer GPUs), TPUs, CPU-only environments, and mixed-hardware clusters is unknown.
- Scaling behavior at larger batch sizes: The fallback policy is motivated by theory, but large-batch experiments use F=1 and limited batch sizes. A full characterization of throughput, latency, and cache hits for b≥32/64/128, with increasing fan-out, is absent.
- Fast fallback alternatives not evaluated: The paper suggests n-gram-based or suffix-tree fallbacks but evaluates “random tokens” instead. Quantifying gains from realistic ultra-fast non-neural fallbacks (or tiny neural drafts) remains open.
- Deriving and validating the critical batch size b*: Theorem states an optimal switch point b*, but the closed-form and its empirical verification across models/hardware/load patterns are not presented.
- Handling head-of-line blocking in batches: SSD assumes the whole batch waits for the backup speculation on a miss. Alternatives (per-sequence verification decoupling, sub-batching, or staggered fallback) and their trade-offs are unexplored.
- Adaptive fan-out allocation beyond a fixed budget: The cache budget B and fan-outs F_k are static per iteration. Methods to adapt B and F_k on-the-fly using observed hits/misses, prefix entropy, or verifier timing slack are not investigated.
- End-to-end energy and cost efficiency: SSD uses additional draft hardware. Measurements of energy per token, $/tok, and carbon impact versus SD and AR decoding are not reported.
- Long-context and KV growth regimes: The assumption T_p<1 (draft finishes before verification) may break at very long contexts and large K. The effect of context length (e.g., 32k–128k tokens) on SSD viability and tuning is not evaluated.
- Integration with tree-based speculation: Although composability is noted, the paper does not implement joint SSD + token-tree methods, nor provide joint optimization strategies for compute allocation across prefetch breadth vs. tree depth.
- Interaction with advanced draft architectures: SSD’s benefits with EAGLE-3, diffusion LLMs, SSMs (e.g., Mamba), and cross-attention to target KV are described conceptually but not validated empirically or analyzed for added communication/memory overhead.
- Robustness across domains and languages: Results are averaged over four English-centric datasets. Per-dataset variability, multilingual performance, and domain shifts (e.g., legal, medical, safety-critical) are not reported.
- User-perceived latency metrics: The paper emphasizes average tokens/s and Pareto frontiers, but does not analyze first-token latency, inter-token jitter, or tail latencies that matter for interactive UX.
- Fault tolerance and straggler resilience: The impact of draft-device faults, preemption, or stragglers (e.g., network hiccups) on SSD correctness/performance and failover strategies is not addressed.
- Security and privacy in disaggregated deployments: Offloading speculation to separate devices/services can introduce data exposure and attack surfaces. Threat models and mitigations (e.g., encryption, isolation) are not discussed.
- Applicability to non-AR decoding tasks: It is unclear how SSD extends to modalities or tasks with different decoding dynamics (e.g., translation with constraints, speech, or image tokenizers) and structured generation constraints.
- Parameter selection methodology: Guidance for choosing K, B, F, and C (downweighting constant) is largely empirical. Automated tuning (Bayesian optimization, bandits) and sensitivity analyses are missing.
- Theoretical analysis without power-law: The cache topology result depends on a power-law miss curve. A general theory for arbitrary miss functions p_hit(F) (with computationally tractable optimizers) is deferred to the appendix and not instantiated empirically.
- Verification-only compute bottlenecks: While SSD avoids extra verifier compute, it assumes verifier throughput remains the bottleneck. Scenarios where draft or communication becomes dominant are not delineated, nor are remedies proposed.
- Reproducibility across engines: Results focus on SGLang (often outperforming vLLM). The extent of engine-specific optimizations required, and how reproducible speedups are across different inference stacks, is unclear.
- Equivalence testing across seeds and settings: The paper does not report rigorous checks that SSD outputs are identical to SD/AR for fixed random seeds across a wide matrix of settings, ensuring “lossless” behavior in practice.
Practical Applications
Immediate Applications
The following applications can be pursued with the paper’s current methods and open-source implementation (Saguaro SSD), requiring integration work but no fundamental research breakthroughs.
Cross-sector infrastructure and tooling
- Faster, lossless LLM inference for interactive applications
- Sectors: software, platform/cloud, consumer apps
- What: Integrate Saguaro SSD into inference stacks (e.g., vLLM/SGLang/Triton backends) to reduce per-request latency and improve tokens-per-second without changing output distributions relative to the target model.
- Tools/products/workflows:
- “SSD-enabled” serving mode that runs a small draft model on a separate device and a target model on the main devices, with Saguaro cache, geometric fan-out, and Saguaro sampling (C-parameter).
- Batch-size–aware fallback policy (fast backup speculator at higher batch sizes, neural backup at low batch sizes).
- Monitoring dashboards for acceptance rate, cache hit rate, fan-out utilization, and latency/throughput Pareto.
- Open-source starting point: https://github.com/tanishqkumar/ssd
- Assumptions/dependencies:
- Availability of a small draft model reasonably close to the target (e.g., 1–2B parameters for 70B targets).
- Separate hardware (e.g., one GPU for draft) and a low-latency interconnect to avoid draft–verify stalls.
- Gains are largest at low-to-moderate batch sizes and moderate temperatures.
- Cost/energy optimization of LLM APIs
- Sectors: cloud, finance (cost-sensitive ops), SaaS
- What: Reduce cost per generated token and total energy by achieving higher throughput for the same service-level objectives (SLOs).
- Tools/products/workflows:
- Autoscaler that allocates a small pool of “draft GPUs” to front many target GPUs to hit latency SLOs at lower cost.
- Dynamic C and fan-out tuning by workload profile (temperature, domain).
- Assumptions/dependencies:
- ROI depends on hardware pricing and acceptance/hit rates; requires offline benchmarking for chosen model/dataset mix.
- At very large batch sizes, fallback choice dominates; fast (non-neural) backup becomes critical.
- Edge–cloud disaggregated serving for perceived latency reduction
- Sectors: mobile/edge, consumer apps, IoT
- What: Run a small draft model on the device (phone/edge NPU) while verifying on cloud targets to hide draft latency and improve perceived responsiveness.
- Tools/products/workflows:
- “Draft-on-device, verify-in-cloud” mode with speculation cache and fallback policy.
- Lightweight token transport protocol optimized for low overhead.
- Assumptions/dependencies:
- Reliable and sufficiently low-latency connectivity; low memory footprint draft model on device.
- Security/compliance review for cross-boundary inference (e.g., PHI/PII handling).
- Batch-size–aware inference policy
- Sectors: platform/cloud
- What: Implement the paper’s fallback strategy that switches from neural just-in-time backup to fast n-gram/heuristic backup beyond a learned threshold batch size b*.
- Tools/products/workflows:
- Online controller that infers b* from observed p_hit, T_p, and T_b and switches backup strategy automatically.
- Assumptions/dependencies:
- Accurate online estimates of cache hit rates by batch bin; stable workload characteristics.
Sector-specific applications
- Real-time assistants and chatbots with snappier responses
- Sectors: customer support, consumer assistants, enterprise chat
- What: Reduce first-token latency and inter-token delay to enhance conversational UX while preserving exact model output distribution.
- Tools/products/workflows:
- SSD-enabled chat endpoints with streaming; aggressive geometric fan-out; C tuned for higher cache-hit at typical temperatures.
- Assumptions/dependencies:
- Benefits are strongest for greedy/low-temperature modes; high-temperature tasks require careful C/fan-out tuning.
- Coding assistants and IDE integrations
- Sectors: software engineering, developer tools
- What: Faster code completions and explanations in IDEs (latency-sensitive, greedy or low-temperature decoding).
- Tools/products/workflows:
- Local or remote draft model dedicated to code domain; per-project tuning of C and fan-out based on acceptance profiles.
- Assumptions/dependencies:
- High acceptance rates in code domains improve SSD hit rates; small code-specific drafts recommended.
- Healthcare documentation and summarization
- Sectors: healthcare IT
- What: Reduce wait time for clinical note drafting, summarization, and patient-chat assistants without changing target-model behavior.
- Tools/products/workflows:
- SSD deployment with logging proving distributional equivalence to target; HIPAA-compliant edge/cloud split if used.
- Assumptions/dependencies:
- Regulatory review; demonstrate lossless equivalence and security of cross-device inference paths.
- Low-latency in-call assistants and contact centers
- Sectors: contact center, telecom
- What: Lower response latency for agent assist and AI copilots in live calls, improving turn-taking and CSAT.
- Tools/products/workflows:
- SSD with fast backup speculator at moderate-to-high batch sizes; integrate with streaming ASR/TTS.
- Assumptions/dependencies:
- Overall pipeline latency dominated by ASR/TTS in some stacks; SSD returns the biggest gains where LLM is the bottleneck.
- Gaming and XR: real-time NPC dialog
- Sectors: gaming, AR/VR
- What: Make NPC dialog and narrative generation feel more responsive, especially on-device + cloud verification setups.
- Tools/products/workflows:
- Edge draft with cloud target; aggressively tuned fan-out; low-temperature generation for predictable behavior.
- Assumptions/dependencies:
- Device constraints for the draft model; network variability management.
- Retrieval-augmented generation (RAG) systems
- Sectors: enterprise knowledge, legal, finance
- What: Reduce the LLM stage latency in RAG pipelines; keeps correctness unchanged.
- Tools/products/workflows:
- SSD-inference node in existing RAG graphs; independent tuning for retrieval vs. generation temperatures.
- Assumptions/dependencies:
- RAG latency may be dominated by retrieval; SSD most valuable where generation is the critical path.
Long-Term Applications
These applications require further research, scaling, productization, or ecosystem support beyond the current codebase.
Cross-sector infrastructure and platform evolution
- Cluster-level “speculator pools” shared across many target deployments
- Sectors: cloud, MLOps
- What: Disaggregate speculation as a microservice serving multiple target model clusters (draft-as-a-service).
- Tools/products/workflows:
- Multi-tenant speculation endpoints; KV-agnostic, token-only interfaces; autoscaling of fan-out GPUs.
- Assumptions/dependencies:
- Scheduling and isolation challenges (fairness, privacy); requires tight queueing control and SLAs.
- Hardware and runtime support for SSD
- Sectors: semiconductor, systems software
- What: GPU/accelerator features and kernels that natively support SSD patterns (parallel draft–verify, cache-aware sampling).
- Tools/products/workflows:
- Runtime primitives for overlapping draft compute with target verification; low-overhead token passing; NIC/NVLink optimization.
- Assumptions/dependencies:
- Vendor support in drivers/compilers; widespread engine adoption.
- Automated controllers for fan-out and C tuning
- Sectors: platform/cloud
- What: Adaptive policies that optimize the speedup “sandwich” by balancing acceptance rates, cache hits, and batch constraints in real time.
- Tools/products/workflows:
- Bandit/RL agents observing latency and token yield to adjust K, fan-out, and C per stream.
- Assumptions/dependencies:
- Stable observability; safety constraints to avoid pathological drift at high temperatures.
- Composition with tree-based speculation and improved draft architectures
- Sectors: software, research
- What: Combine SSD with token-tree methods (e.g., EAGLE, Sequoia) and cross-attentive drafts to further boost acceptance and hit rates.
- Tools/products/workflows:
- Hybrid pipelines with tree-based verification plus asynchronous pre-speculation; EAGLE-3–style draft models in SSD.
- Assumptions/dependencies:
- Engineering complexity and higher verifier compute budget; careful accounting to retain overall speedups.
Domain-specific and emerging use cases
- Real-time robotics and embodied AI control
- Sectors: robotics, industrial automation
- What: Edge drafts on robots with cloud targets to reduce perceived decision latency while preserving correctness.
- Tools/products/workflows:
- Onboard NPU draft + cloud verification; strict fallback policies for safety.
- Assumptions/dependencies:
- Determinism and safety constraints; robust connectivity or local fallback to safe behavior.
- Ultra-low-latency voice assistants (sub-100 ms turn increments)
- Sectors: consumer devices, automotive
- What: Combine SSD with streaming ASR/TTS for near-instantaneous token emission in talk/drive assistants.
- Tools/products/workflows:
- Specialized SSD tuning for low-temperature speech text; on-device drafts; batched verification windows.
- Assumptions/dependencies:
- End-to-end optimization across ASR/LLM/TTS; further latency reductions and hardware support may be needed.
- Throughput-optimized offline generation and RL pipelines
- Sectors: research, data generation, RLHF/RLAIF
- What: While SD historically yields limited value in throughput-bound workloads, SSD’s improved Pareto may make it viable for some offline generation or RL data loops.
- Tools/products/workflows:
- Pipeline schedulers that exploit draft overlap; speculative pools during off-peak windows.
- Assumptions/dependencies:
- Gains depend on temperature, batch size, and verifier bottlenecks; careful cost–benefit analysis required.
- Mobile-first SSD deployments
- Sectors: mobile, consumer apps
- What: Run drafts on phone NPUs, verify in cloud for fast interactive experiences (e.g., on-device chat, creative tools).
- Tools/products/workflows:
- Quantized drafts; energy-aware fan-out; intermittent connectivity strategies.
- Assumptions/dependencies:
- Vendor SDK support, memory constraints, and privacy considerations for on-device inference.
Policy, compliance, and governance
- Standardized “lossless acceleration” compliance evidence
- Sectors: regulated industries (healthcare, finance, government)
- What: Provide auditable proof that SSD preserves target-model sampling distributions (lossless) despite acceleration.
- Tools/products/workflows:
- Conformance tests and logs showing residual sampling and acceptance decisions; external audits.
- Assumptions/dependencies:
- Trust in verification implementation; reproducibility requirements (e.g., RNG handling).
- Energy-efficiency and sustainability reporting
- Sectors: cloud, public policy
- What: Use SSD to document improved energy per generated token and inform sustainability disclosures and procurement.
- Tools/products/workflows:
- Metering of energy savings from draft overlap and faster token generation; reporting templates.
- Assumptions/dependencies:
- Net energy savings depend on draft GPU overhead vs. throughput gains.
Notes on feasibility and dependencies that broadly apply:
- Performance is sensitive to the closeness of the draft to the target (acceptance rate) and to cache hit rates; both degrade with higher temperatures and larger batch sizes.
- SSD requires careful engineering: a dedicated draft device, low-latency inter-device communication, speculation cache management, geometric fan-out allocation, and Saguaro sampling (C) tuning.
- Fallback strategy is crucial at scale: fast backup (e.g., n-gram speculators) often outperform neural backups for large batches.
- SSD is lossless if implemented per the paper’s verification and residual-sampling rules; this property eases adoption in regulated settings but demands rigorous testing.
Glossary
- Acceptance rate: The probability that a drafted token is accepted given prior acceptances; a key factor governing speculative decoding efficiency. "The expected number of generated tokens per round, and thus the overall efficiency of speculative decoding, is governed by the acceptance rate:"
- Autoregressive decoding: Token-by-token generation where each new token depends on previously generated tokens, leading to sequential bottlenecks. "Autoregressive decoding is bottlenecked by its sequential nature."
- Batch size: The number of sequences processed simultaneously during decoding/inference. "Setup. Unless otherwise specified, experiments are run with batch size 1 and greedy decoding"
- Bonus token: An additional token sampled by the verifier after the last accepted draft token, drawn from a specific distribution to ensure correctness. "and samples an additional bonus token that follows all of the accepted tokens."
- Cache hit: When the actual verification outcome matches one of the precomputed outcomes stored in the speculation cache. "A cache hit is when the outcome of verifying is contained in the speculation cache ."
- Cache miss: When the actual verification outcome is not among the precomputed outcomes in the speculation cache. "A cache miss is when ."
- Constrained optimization: Selecting a limited set of verification outcomes to precompute to maximize cache hits under computational budgets. "This motivates posing verification prediction as constrained optimization: given a budget of verification outcomes, how should one select them to maximize the chances of a cache hit?"
- Cross-attention: An attention mechanism allowing the draft model to attend to representations or caches from the target model to improve drafting. "allow the draft model to perform cross-attention on the KV cache of the target model."
- Diffusion LLMs: LLMs based on diffusion processes, used as alternative architectures for fast drafting. "Alternate model architectures, like diffusion LLMs~\citep{Nie2025LargeLanguageDiffusionModels, sahoo2024simple,diffuspec,specdiff,llmfuture,dflash} or SSMs~\citep{gu2022efficiently, Gu2024Mamba,mamballama}, can also be used to increase the speed with which the draft model can produce the speculated token sequence."
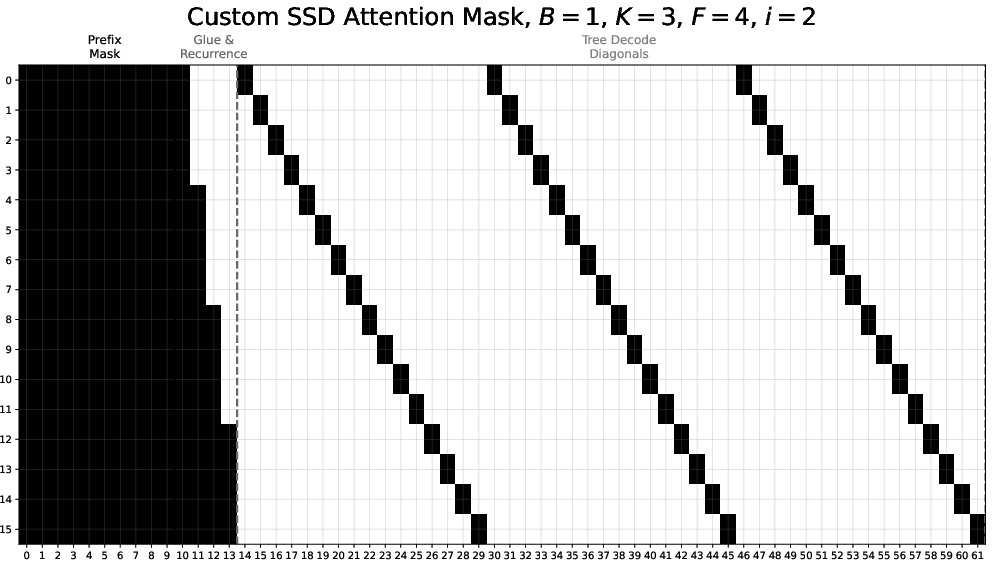
- Fan-out: The number of bonus-token guesses cached for a given position (number of accepted tokens), controlling how many verification outcomes are precomputed. "We define the fan-out at position "
- Forward pass: A single parallel computation through the target model used to verify multiple drafted tokens at once. "then 'verifies' these tokens in one parallel forward pass of the target model."
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without randomness. "Setup. Unless otherwise specified, experiments are run with batch size 1 and greedy decoding"
- KV cache: Cached key-value attention states from the target model that can be re-used by draft models for faster speculation. "allow the draft model to perform cross-attention on the KV cache of the target model."
- Logits: Unnormalized model outputs used to form probability distributions for sampling or prediction. "the last-token target logits are used to sample a 'bonus token.'"
- Pareto frontier: The trade-off curve showing best achievable combinations of latency and throughput; SSD aims to push this frontier. "we show in Figure~\ref{fig:e2e} (right) that SSD pushes the Pareto frontier across both latency and throughput, with the biggest gains at lower batch sizes."
- Power-law cache hit rate: A relationship where cache miss probability decreases as a power-law function of cache fan-out, parameterized by an exponent. "We say that a speculator has a r power-law cache hit rate"
- Residual distribution: The modified distribution used to sample the bonus token, defined by the positive difference between target and draft probabilities. "This modified distribution is called the residual distribution, and takes the form $r(\cdot) \propto \max\left(p_{\mathrm{target}(\cdot)-p_{\mathrm{draft}(\cdot), 0\right)$."
- Saguaro sampling: A cache-aware sampling scheme that downweights top draft tokens to increase residual mass and improve cache-hit probability. "We introduce Saguaro sampling, a novel sampling scheme designed specifically for SSD."
- Speculation cache: A mapping from predicted verification outcomes to precomputed speculations, enabling immediate response on cache hits. "We define the speculation cache for round as a dictionary mapping from a set of verification outcomes to precomputed speculations for those outcomes."
- Speculative decoding: An acceleration technique where a fast draft model proposes tokens and a slower target model verifies them in parallel. "Speculative decoding has become a standard way to accelerate inference by using a fast draft model to predict upcoming tokens from a slower target model, and then verifying them in parallel with a single target model forward pass."
- Speculative execution: A CPU optimization concept used as an analogy for SSD, precomputing possible paths before conditions are resolved. "consider the similarities with speculative execution (\cite{specexec97}) for CPU optimization."
- Speculative lookahead: The number of tokens the draft model proposes ahead of verification in a single round. "The length of the speculated sequence is called the speculative lookahead."
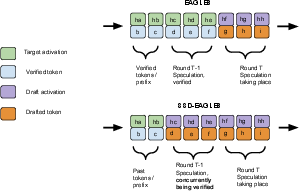
- Speculative speculative decoding (SSD): A framework that parallelizes drafting and verification by precomputing speculations for likely verification outcomes during ongoing verification. "We introduce speculative speculative decoding (SSD), a unifying framework for methods that aim to parallelize drafting and verification."
- Speculator: The process/model that drafts candidate token sequences and prepares speculations for predicted verification outcomes. "The speculator and verifier processes run in parallel on separate hardware."
- Verifier: The process/model (target) that checks drafted tokens, determines acceptances, and samples the bonus token. "While the verifier is verifying the drafted tokens from round , the speculator begins speculating round ."
Collections
Sign up for free to add this paper to one or more collections.