- The paper introduces LAPS-SD, a semi-clairvoyant scheduler that adapts between non-perceptible and perceptible modes to minimize LLM latency.
- It leverages dynamic acceptance rates and task execution profiling to achieve a 39% reduction in inference latency compared to baselines.
- Empirical evaluations demonstrate robust performance across varying datasets, underscoring the importance of adaptive scheduling in speculative decoding.
Semi-Clairvoyant Scheduling of Speculative Decoding Requests for LLM Inference Latency Minimization
Introduction
Speculative decoding has emerged as a core technique for accelerating autoregressive LLM inference. It leverages a compact speculative model (SSM) to rapidly propose candidate tokens, which are subsequently verified in parallel by the primary LLM. The integration of speculative decoding into LLM serving systems introduces a nontrivial scheduling challenge: inference requests exhibit uncertain execution times due to variability in output length and dynamic token acceptance rates. Conventional scheduling approaches rely on predicted output lengths, failing to capture key temporal dynamics intrinsic to speculative decoding. The paper "Semi-Clairvoyant Scheduling of Speculative Decoding Requests to Minimize LLM Inference Latency" (2505.17074) rigorously formalizes this challenge and introduces LAPS-SD, a semi-clairvoyant scheduling algorithm that adaptively leverages both attained service and perceived execution features for latency minimization.
Figure 1: The illustration depicts canonical scheduling algorithms for speculative decoding requests, highlighting variability in generation context and speculative context.
Problem Statement and Analytical Foundations
The scheduling problem is formalized in a single-request serving environment (batch size 1 for analytic clarity, though the approach generalizes). The system is tasked with minimizing average inference latency across a set of requests N, each characterized by arrival time ri and execution time Ti. Critically, Ti depends on both the required output length and the dynamic token acceptance rate during speculative decoding. Existing length prediction models (e.g., BERT- and LLaMA-based predictors [qiu2024efficient, zheng2024response]) are insufficient, as they cannot account for rejected speculative tokens that consume substantial computational resources.
An illustrative breakdown (Figure 1) demonstrates that FCFS and SJF scheduling degenerate under highly variable acceptance rates, resulting in head-of-line blocking and suboptimal job completion times. The analysis quantifies that speculative decoding request execution time grows with both output length and inverse acceptance rate, and preemptive scheduling strategies (e.g., LAS) suffer from significant cache switching costs (Figure 2). The switching cost for long outputs is non-negligible, saturating at 14.21% overhead for 500-token requests.
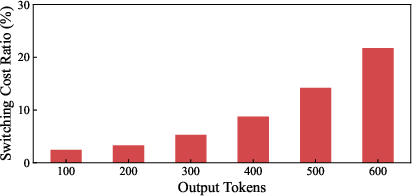
Figure 2: The ratio of context switching costs to total inference time increases with output length, impacting scheduling efficiency.
Dynamic Acceptance Rate and Latency Bottlenecks
Empirical analysis reveals acceptance rate instability during initial speculative rounds, followed by stabilization as decoding progresses. In Figure 3, the temporal evolution of acceptance rates for three representative requests is depicted. This dynamic property motivates an adaptive scheduling paradigm: requests should be scheduled according to their attained service when acceptance rates are volatile (non-perceptible state), and by accurately estimated job size when acceptance rates are stable (perceptible state).
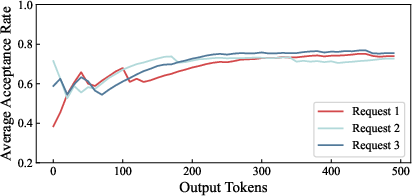
Figure 3: Average acceptance rate trajectories for three requests, showing rapid stabilization after initial volatility.
The LAPS-SD Algorithmic Framework
LAPS-SD employs multiple priority queues in tandem. Each new request is initially assigned to the highest-priority queue as non-perceptible, subject to preemptive scheduling under the Least-Attained-Service (LAS) principle. Upon stabilization of its acceptance rate, the request is reclassified as perceptible and scheduled according to Shortest-Job-First (SJF) principles, leveraging accurate execution time estimation derived from both output length and empirical acceptance rate. Switching from non-perceptible to perceptible state ensures preemption is used only when efficient (small accumulated cache), and switching overhead is contained as requests grow in size.
Queue structure and inter-queue transitions are schematized in Figure 4. Each queue is parameterized by attained service thresholds (Sjdown,Sjup), supporting exponential scaling of queue sizes to match variable attained service distributions.
Figure 4: Priority queue structure underlying LAPS-SD, with exponential scaling of attained service thresholds.
Within queues, multi-state scheduling ensures that perceptible requests, with reliable execution time estimates, are prioritized to maximize latency reduction. Non-perceptible requests are served FCFS, minimizing blocking but allowing for adaptive preemption.
Empirical Evaluation
LAPS-SD is evaluated using Chatbot Instruction Prompts, MBPP, and MiniThinky datasets. The experimental configuration uses LLaMA-68M as SSM and LLaMA-7B as the LLM. Baseline comparisons include LP-SJF (output length prediction-based SJF) [qiu2024efficient] and LAS [leviathan2023fast].
Strong numerical results are obtained (Figure 5): LAPS-SD achieves a 39% reduction in average inference latency over state-of-the-art baselines across diverse workloads. LP-SJF is 1.47× slower due to execution time underestimation, while LAS suffers a 31% penalty due to uncontrolled cache switches. Dataset characteristics (e.g., higher MBPP acceptance rates) modulate absolute latency but do not alter relative algorithmic performance.
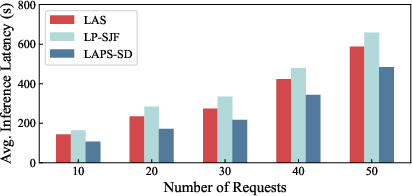
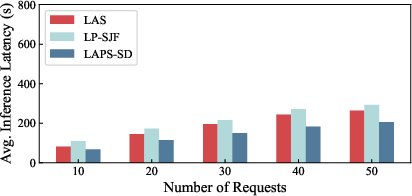
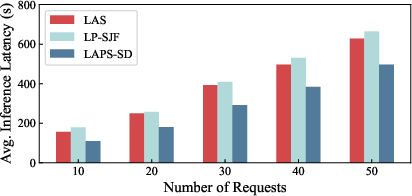
Figure 5: Average inference latency comparison across algorithms shows LAPS-SD's dominance in all regimes.
Further analysis assesses the impact of the number of priority queues (Figure 6). Latency decreases with increased queue granularity up to an optimal value, after which switching overhead dominates and latency rises. The optimal queue count is both dataset and load dependent; e.g., MiniThinky requests (larger KV) favor fewer queues to avoid switching cost escalation.
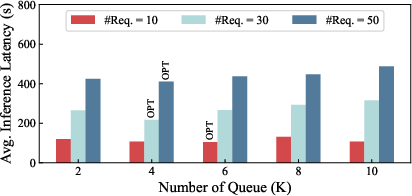
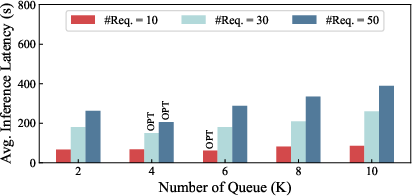
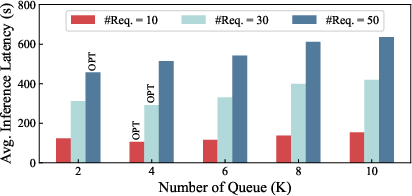
Figure 6: Latency-optimal priority queue count depends on dataset and concurrent request load.
Execution time estimation accuracy is scrutinized (Figure 7), yielding a mean error of 6.84% over all datasets. Estimation fidelity is stably maintained except for the MBPP dataset, which is challenged by lower acceptance rate prediction accuracy.
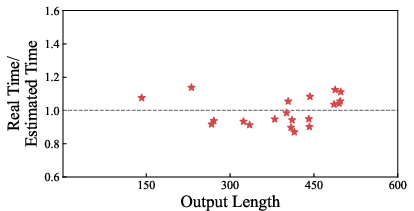
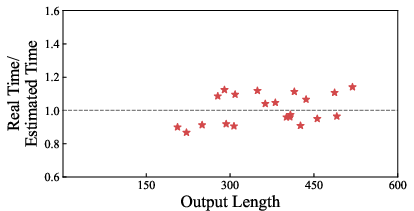
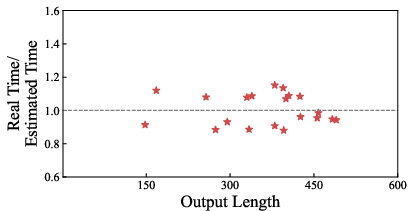
Figure 7: Execution time estimation error remains low across datasets, validating the perceptible-state prediction methodology.
Implications and Future Directions
Practically, LAPS-SD advances the state of LLM inference serving by achieving substantial reductions in end-to-end latency. The decomposition of request scheduling into non-perceptible and perceptible modes optimally leverages speculative decoding's dynamics and computational cost structure. Theoretically, the semi-clairvoyant design highlights the value of combining real-time service measurement with predictive modeling, adaptable for multi-batch and distributed inference environments.
LAPS-SD's multi-queue architecture suggests future generalizations to higher batch sizes, multi-tenant scheduling, and load-adaptive queue scaling. Additional research could improve dynamic acceptance rate prediction via online learning or Bayesian updating, further tightening execution time estimates. The methodology could synergize with other speculative decoding optimizations (e.g., adaptive candidate lengths, advanced KV cache management) for even greater goodput and latency minimization.
Conclusion
The paper introduces LAPS-SD, a semi-clairvoyant speculative decoding request scheduler that significantly lowers LLM inference latency. By adaptively partitioning requests into attained-service and perceived-service states and leveraging both preemptive scheduling and execution time estimation, LAPS-SD outperforms existing algorithms, achieving approximately 39% latency reduction. The approach is substantiated by detailed analysis and robust empirical results, providing a foundation for further exploration in adaptive, low-latency LLM serving architectures.