- The paper introduces a novel dual-instance architecture and dynamic scheduling policy for LLM serving that meets strict TTFT and TBT SLOs.
- The methodology leverages low-priority batching and high-priority offloading to mitigate head-of-line blocking and optimize GPU resource usage.
- Performance evaluations demonstrate significant improvements in goodput over baseline systems like vLLM and Sarathi-Serve under varying workload conditions.
"Ascendra: Dynamic Request Prioritization for Efficient LLM Serving" (2504.20828)
Introduction
The paper "Ascendra: Dynamic Request Prioritization for Efficient LLM Serving" presents a novel system for serving LLMs that efficiently meets service level objectives (SLOs) for time to first token (TTFT) and time between tokens (TBT). Ascendra is designed to address inefficiencies in conventional LLM serving methods which often sacrifice latency for throughput or vice versa. By dynamically prioritizing requests based on urgency, Ascendra facilitates both high throughput and low latency, ensuring optimal performance compared to existing systems like vLLM and Sarathi-Serve.
System Architecture and Operation
Ascendra employs a unique architecture that partitions GPU resources into low-priority (LP) and high-priority (HP) instances. LP instances focus on maximizing throughput by batching requests efficiently, albeit at the risk of TTFT and TBT SLO violations under high loads. HP instances, in contrast, prioritize low-latency execution of requests, especially those nearing their deadline, ensuring adherence to SLOs even in highly variable conditions. This architectural separation allows Ascendra to balance high throughput and low latency effectively, avoiding head-of-line blocking and ensuring urgent requests are processed promptly.

Figure 1: Overview of Ascendra. Green arrows indicate the flow of non-urgent requests, while red arrows represent offloading from LP to HP instances. The controller routes incoming requests to LP instances by default, and to the HP instance when it is available or when a request is urgent.
Scheduling Policies and Request Management
Ascendra introduces sophisticated scheduling policies to enhance LLM serving efficiency. The LP instances use a value function to reorder requests based not just on arrival time but on a dynamic priority associated with each request's urgency and SLO proximity. This enables out-of-order execution which is crucial for optimizing resource utilization without sacrificing SLO compliance. Requests at risk of missing their SLOs are proactively offloaded to HP instances, which handle them with minimal delay.
The system's ability to dynamically adjust batch sizes on HP instances further enhances its flexibility, allowing it to accommodate more concurrent requests during peak loads without compromising performance.
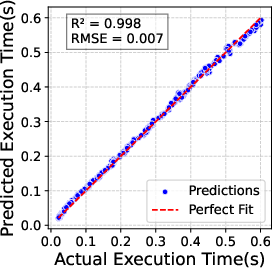
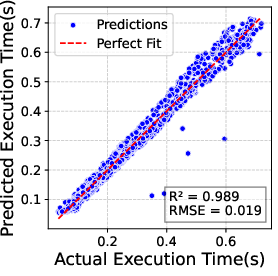
Figure 2: Accuracy of regression model for predicting execution time of prefill batches (left) and hybrid batches (right). Prediction error remains below 10\% in most cases.
Ascendra exhibits significant improvements in goodput — the proportion of requests that meet both TTFT and TBT SLOs — across various workloads, demonstrating consistent superiority over baseline systems like vLLM and Sarathi-Serve. Notably, Ascendra manages to maintain high performance levels even when subjected to stringent SLOs and fluctuating system loads.
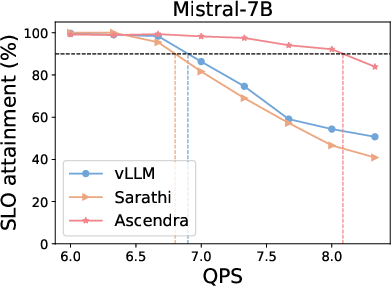
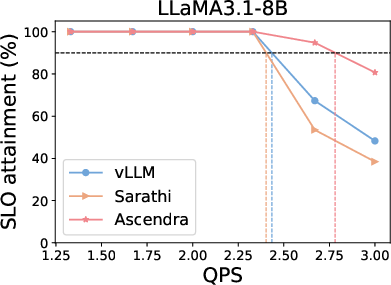
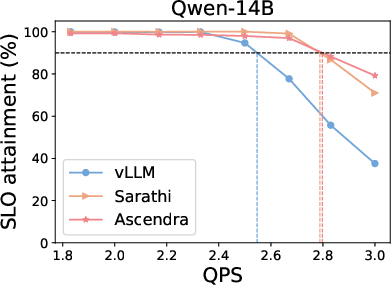
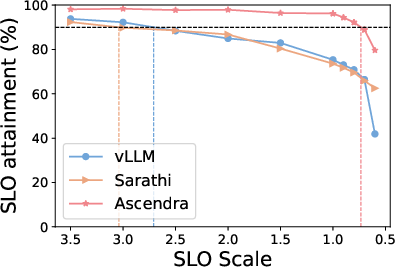
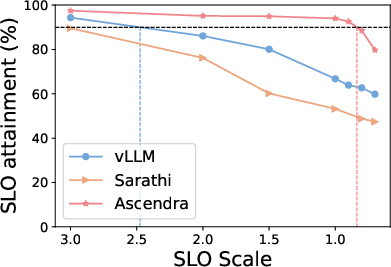
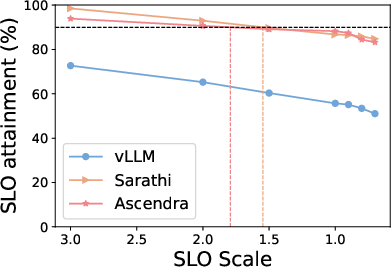
Figure 3: Top row: SLO attainment for Ascendra, vLLM, and Sarathi across three LLM models and datasets. Ascendra consistently increases system capacity to serve requests within SLOs, while vLLM lacks SLO awareness and Sarathi sacrifices TTFT for TBT. Bottom row: SLO attainment as the SLO target varies. Ascendra significantly improves goodput and outperforms baselines across a range of SLO thresholds.
Conclusion
Ascendra represents a significant advancement in LLM serving, offering a practical solution for balancing throughput with strict SLO adherence. By adopting an innovative dual-instance architecture and dynamic scheduling strategies, it proves capable of handling diverse workload scenarios with improved efficiency and responsiveness. The flexibility to adjust instance configurations provides operators with the tools needed to tailor system performance to meet specific application demands. Future work may explore further scaling and optimization techniques, as well as integrations with emerging hardware advancements, to continue improving LLM serving efficiency.