- The paper introduces a novel SLO-aware dynamic frequency scaling method for LLM serving, reducing GPU energy consumption by up to 34%.
- It employs phase-specific optimizations by distinguishing between prefill and decode phases with tailored SM frequency adjustments.
- The framework uses real-time TPS feedback to maintain 95th-percentile token latency within strict service-level objectives.
GreenLLM: SLO-Aware Dynamic Frequency Scaling for Energy-Efficient LLM Serving
The paper "GreenLLM: SLO-Aware Dynamic Frequency Scaling for Energy-Efficient LLM Serving" (2508.16449) presents an innovative framework designed to minimize GPU energy consumption while maintaining service-level objectives (SLOs) in the serving of LLMs. The methodology involves a detailed separation of control strategies for the prefill and decode phases of LLM inference, utilizing adaptive frequency scaling techniques to optimize energy efficiency.
Introduction
LLMs are increasingly integral to cloud services, necessitating efficient inference mechanisms due to the substantial energy demands of GPU operations during these processes. The inference consists of two phases: the latency-sensitive prefill phase and the decode phase, each with unique computational requirements. Traditional GPU scaling does not differentiate between these stages, leading to energy inefficiencies.
GreenLLM introduces a dynamic scaling strategy that explicitly recognizes and separates these phases. By using different SM frequencies and energy models, the framework achieves significant energy reductions without breaching SLO boundaries.
Technical Approach
Prefill Phase Optimization
In the prefill phase, GreenLLM classifies requests based on prompt length and uses historical data to fit latency-power models on GPUs. The system then employs a queueing-aware optimization to set energy-efficient SM frequencies for each class.
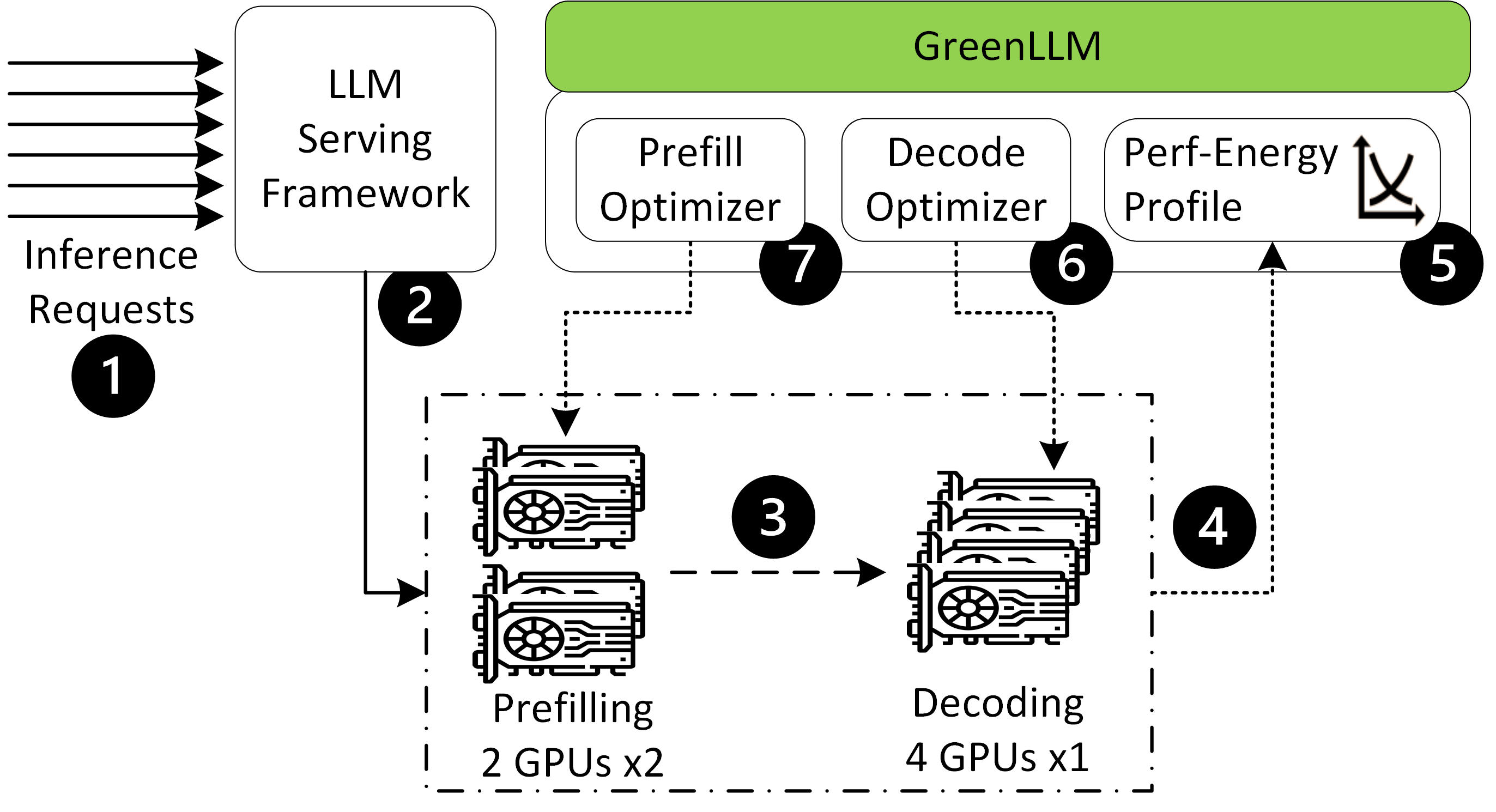
Figure 1: System Overview: Queue-aware prefill optimizer and dual-loop dynamic decode optimizer.
Prefill stages benefit from aggressive resource use, minimizing TTFT for short and medium prompts while maintaining energy efficiency for long ones.
Decode Phase Optimization
The decode phase employs a dual-loop feedback control system that dynamically adjusts GPU frequency according to real-time TPS measurements. This system aims to keep the 95th-percentile time-between-tokens (TBT) within defined SLO limits without exceeding energy needs.
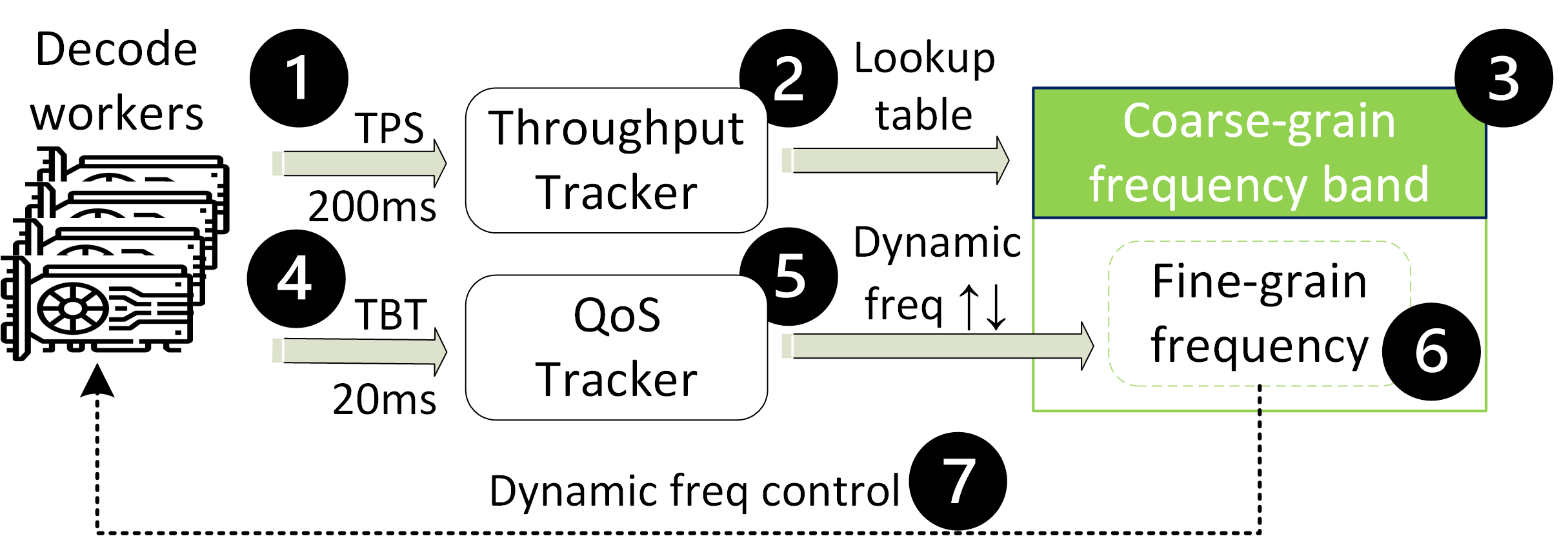
Figure 2: Decode control: TPS determines coarse frequency-band and fine frequency adjustment with hysteresis to meet P95 TBT.
By dynamically tracking token generation rates, GreenLLM ensures adaptive and responsive frequency scaling, effectively saving energy while adhering to specified latency ceiling.
Results
GreenLLM shows a marked improvement in energy efficiency compared to standard DVFS baselines. Experiments on Alibaba and Azure traces document up to a 34% decrease in total energy consumption, maintaining throughput and with minimal SLO violations increase.
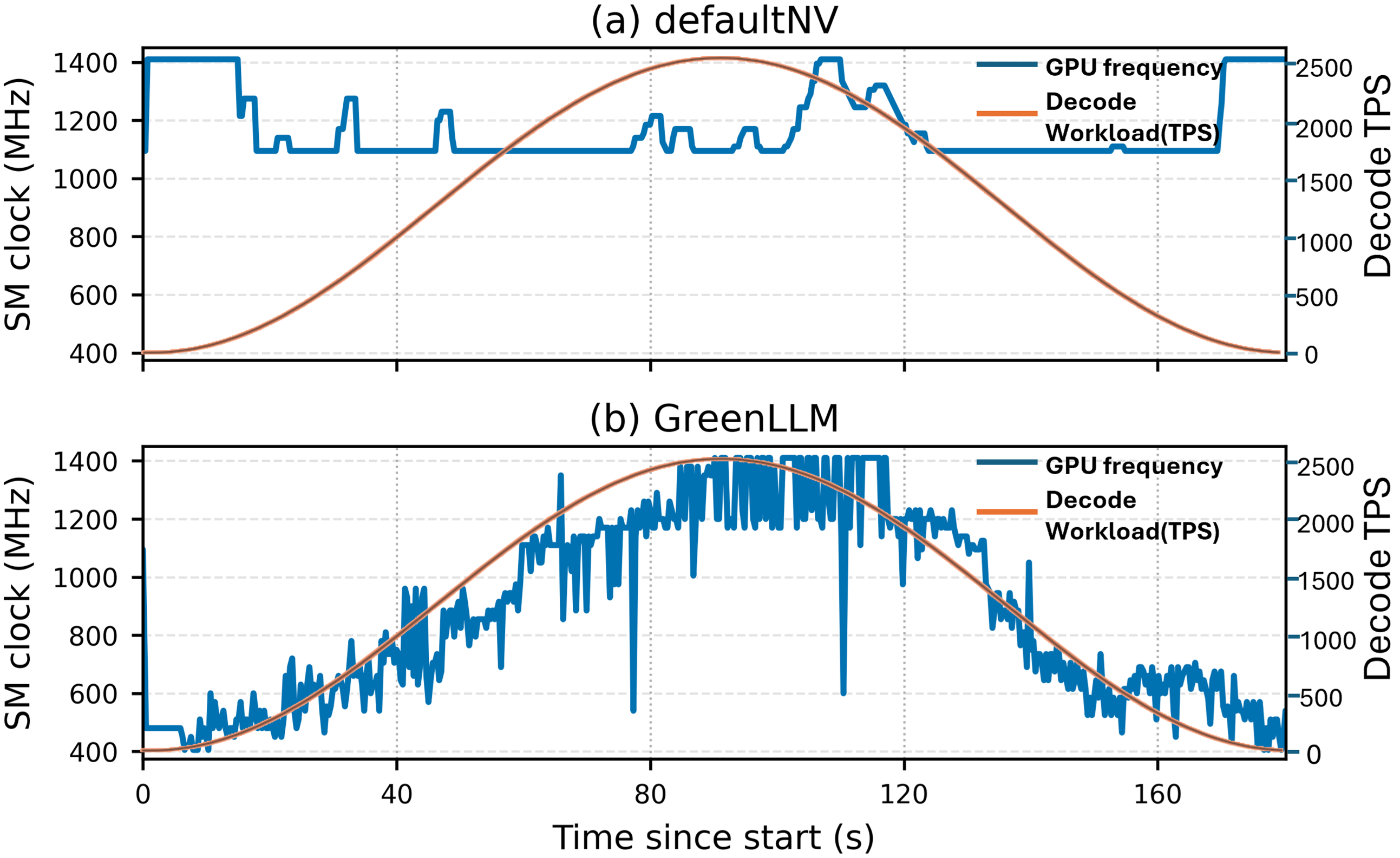
Figure 3: GPU Frequency vs. Decode TPS under defaultNV and GreenLLM
Phase-Specific Energy Savings
Prefill-stage optimization alone contributed significantly to energy savings, primarily by avoiding the excessive use of GPU resources where not needed. The dual-loop control in the decode phase ensures real-time adjustment to workload demand, maintaining energy savings even under varying input TPS.
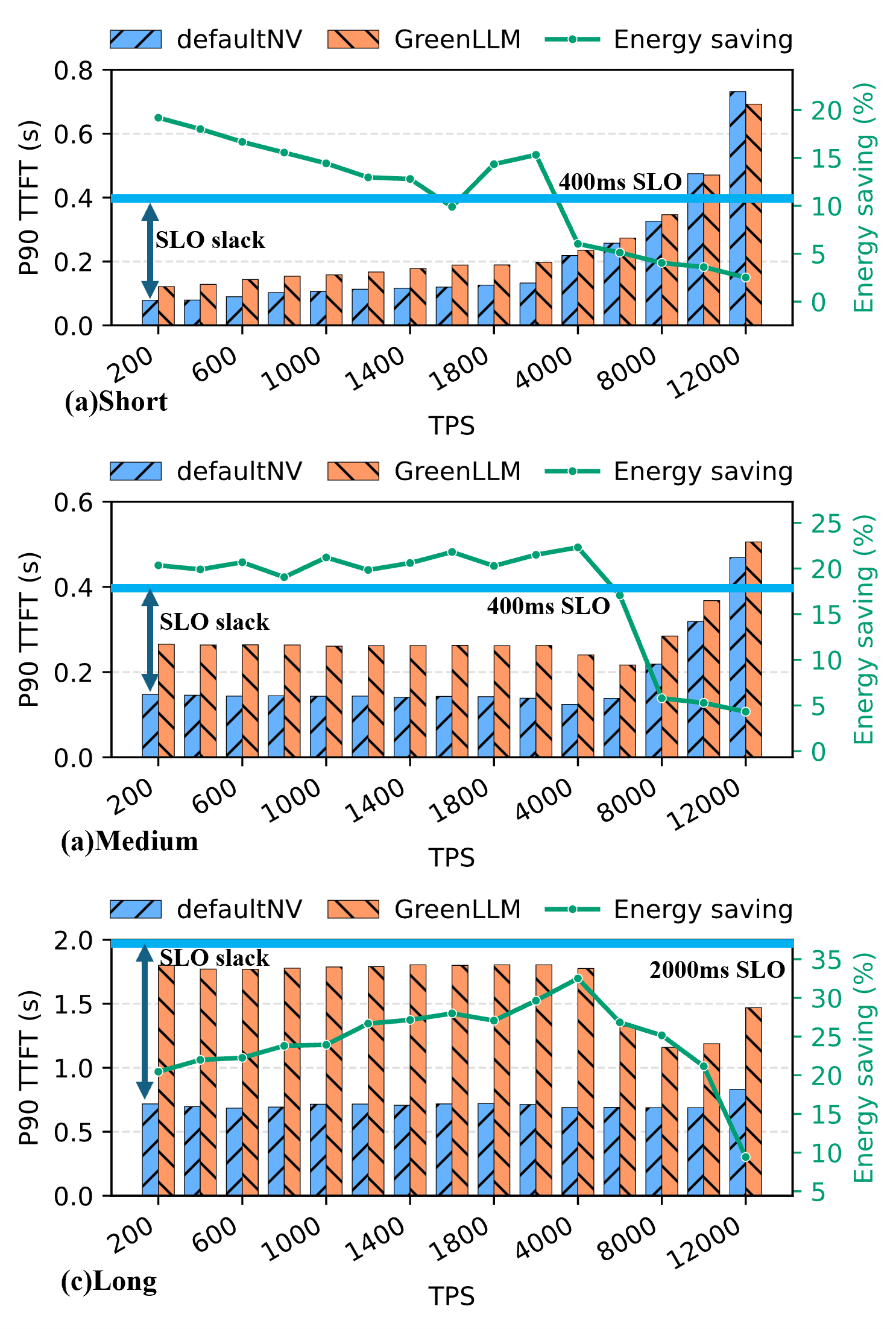
Figure 4: Prefill microbenchmarks (TTFT vs TPS) with defaultNV and GreenLLM.
Implications and Future Work
GreenLLM's results highlight the importance of differentiated power management strategies for LLM serving, revealing untapped potential in phase-aware optimization. Future work could extend these methods to distributed systems and explore integration with emerging GPU technologies.
Conclusion
The GreenLLM framework effectively separates and optimizes the unique phases of LLM inference, demonstrating significant energy savings while adhering to latency constraints. This approach paves the way for more energy-efficient deployment of LLMs in large-scale cloud services, contributing to sustainability in AI infrastructure.