- The paper introduces a host-level controller that reduces tail latency by dynamically reconfiguring MIG, employing PCIe-aware placement, and applying lightweight guardrails.
- It achieves a 32% reduction in SLO miss-rate and a 15% improvement in p99 latencies through continuous system monitoring and adaptive resource allocation.
- The approach effectively mitigates resource contention in multi-tenant GPU environments while maintaining throughput degradation below 5% via enforced dwell and cool-down periods.
Predictable LLM Serving on GPU Clusters
Introduction
The paper "Predictable LLM Serving on GPU Clusters" focuses on addressing the challenges associated with latency-sensitive inference tasks on shared A100 GPU clusters. The noisy-neighbor problem, which arises from resource contention in such shared environments, significantly affects the tail latency and violates Service Level Objectives (SLOs). A primary source of interference is the contention for shared PCIe bandwidth during intensive data transfers, exacerbated by the multi-tenant nature of these GPU environments.
The proposed solution is a fabric-agnostic, VM-deployable host-level controller that focuses on reducing the tail latency by dynamically reconfiguring Multi-Instance GPUs (MIG), employing PCIe-aware placement, and applying lightweight guardrails such as MPS quotas and cgroup I/O controls. This approach is designed for implementation without needing fabric-level privileges, making it accessible for tenants in typical cloud environments.
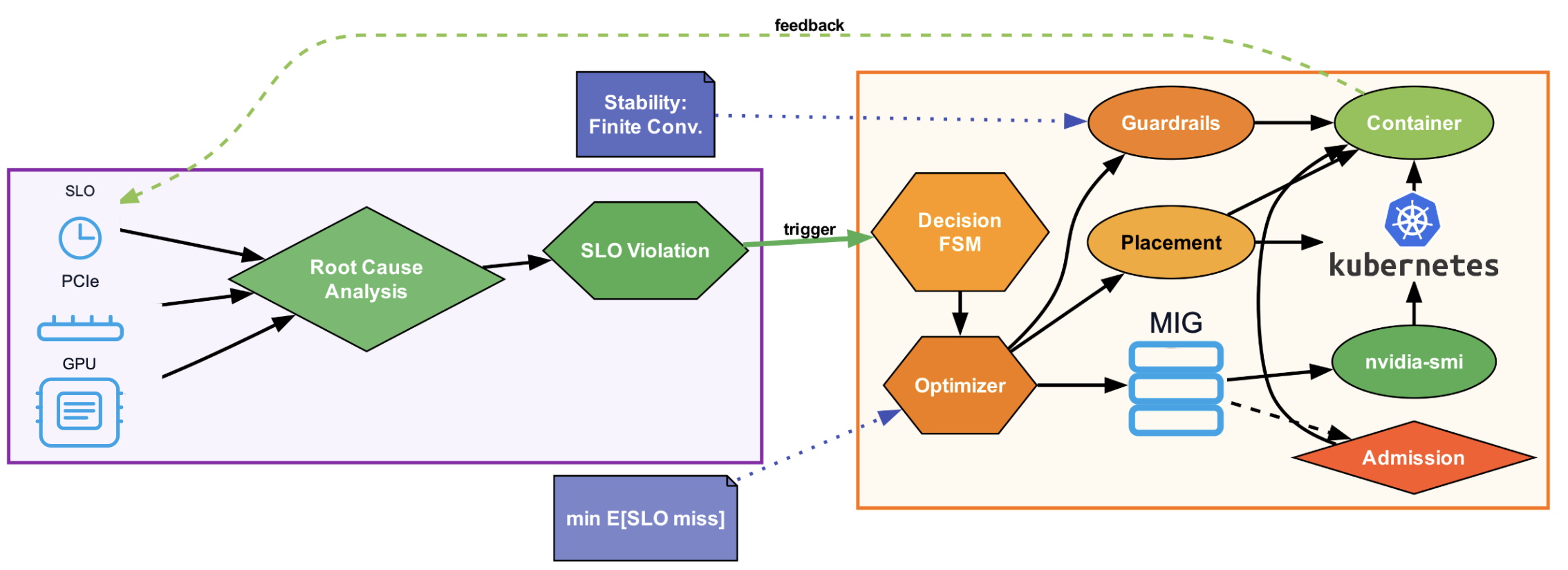
Figure 1: System architecture of the multi-tenancy controller.
Methodology
The methodology employs a controller that operates continuously to minimize tail latency. The controller monitors per-tenant latencies and system signals, using these to determine whether actions need to be taken to meet SLOs. It operates within a decision space comprising three main actions: dynamic MIG reconfiguration, PCIe-aware placement, and the application of lightweight guardrails. The controller incorporates mechanisms to prevent oscillations through enforced dwell and cool-down periods, ensuring stable performance adjustments.
Signals and Sampling:
The controller samples signals every 1-5 seconds, monitoring per-tenant p95/p99/p999 latencies, NVML metrics, PCIe counters, and host I/O activity. These signals help in diagnosing the source of contention and deciding on appropriate mitigation actions.
Objective and Constraints:
The primary objective is to minimize SLO miss-rate and tail latencies while maintaining throughput degradation below 5%. This involves strategic escalation of isolation levels only when necessary and includes mechanisms to rollback changes if they do not result in performance improvements.
The PCIe contention is modeled as a processor-sharing server with finite capacity, capturing the bandwidth sharing scenario among multiple active tenants. The latency model comprises a transfer component dependent on allocated bandwidth and a compute time, further adjusted by stochastic noise. The optimization problem is structured around minimizing the expected SLO miss-rate while adhering to throughput constraints.
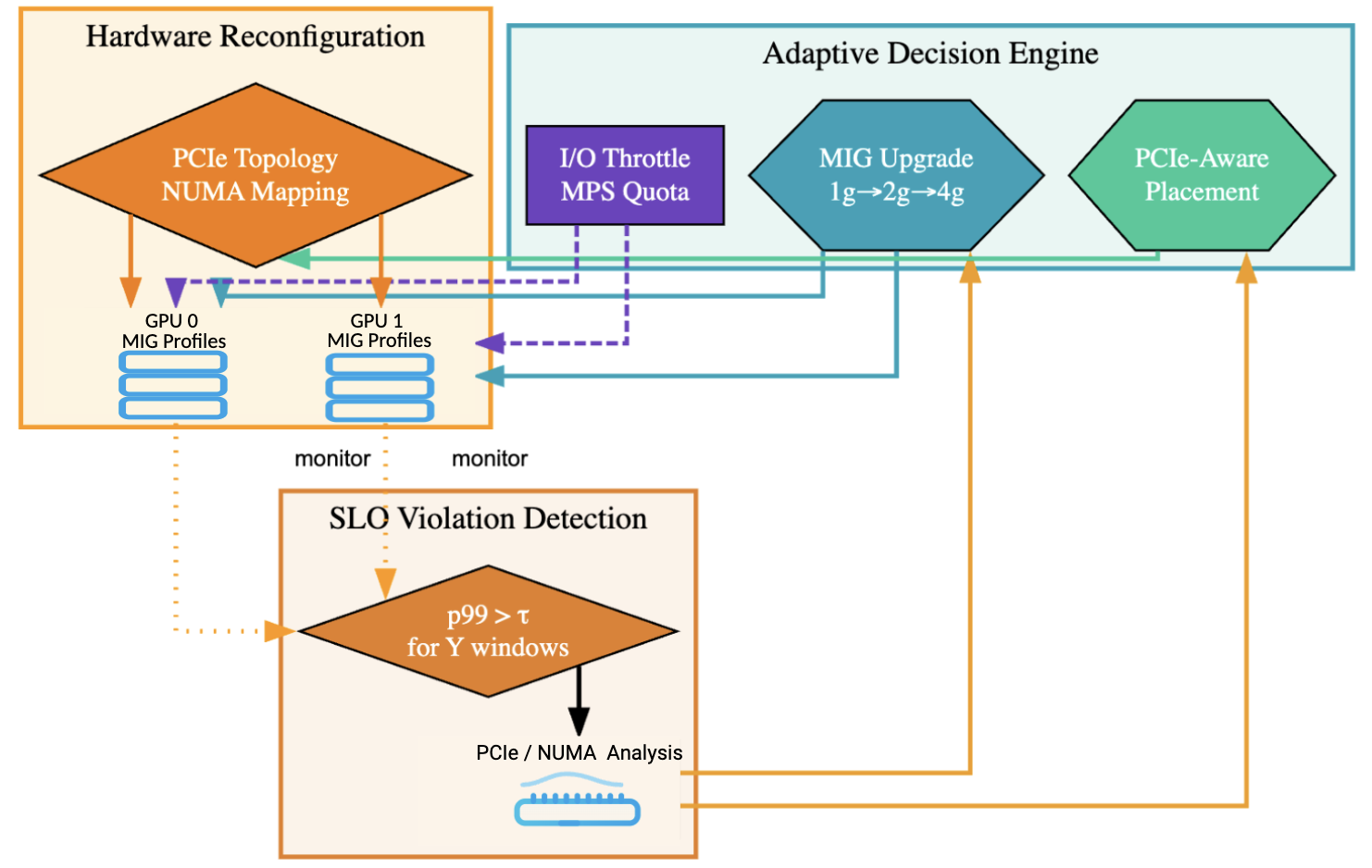
Figure 2: PCIe contention model and topology.
Evaluation
The system was evaluated on single-host and multi-node setups, demonstrating a reduction in SLO miss-rates by approximately 32% and an improvement in p99 latencies by about 15% in comparison to static configurations. The evaluation included a realistic LLM serving scenario using vLLM on OLMo 2 7B Instruct, showing a significant improvement in time-to-first-token tail latencies without needing controller changes.
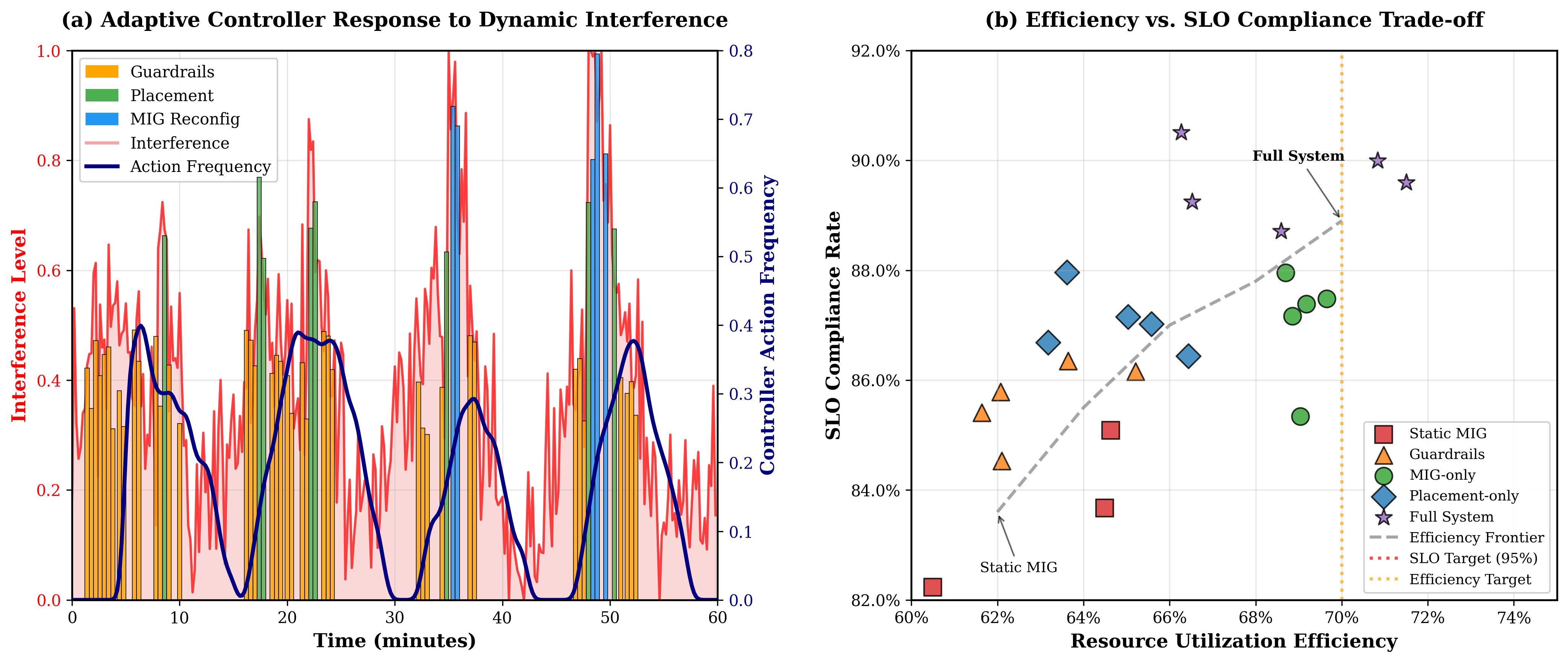
Figure 3: Adaptive controller behavior and efficiency.
Results
The results reveal that each component of the controller contributes significantly to the overall performance improvement, with MIG reconfiguration and PCIe-aware placement being comparably effective. The use of guardrails additionally offers improvements, albeit to a lesser extent. The adaptive nature of the controller is highlighted in its ability to respond to dynamic interference patterns, thereby maintaining high SLO compliance and resource utilization.
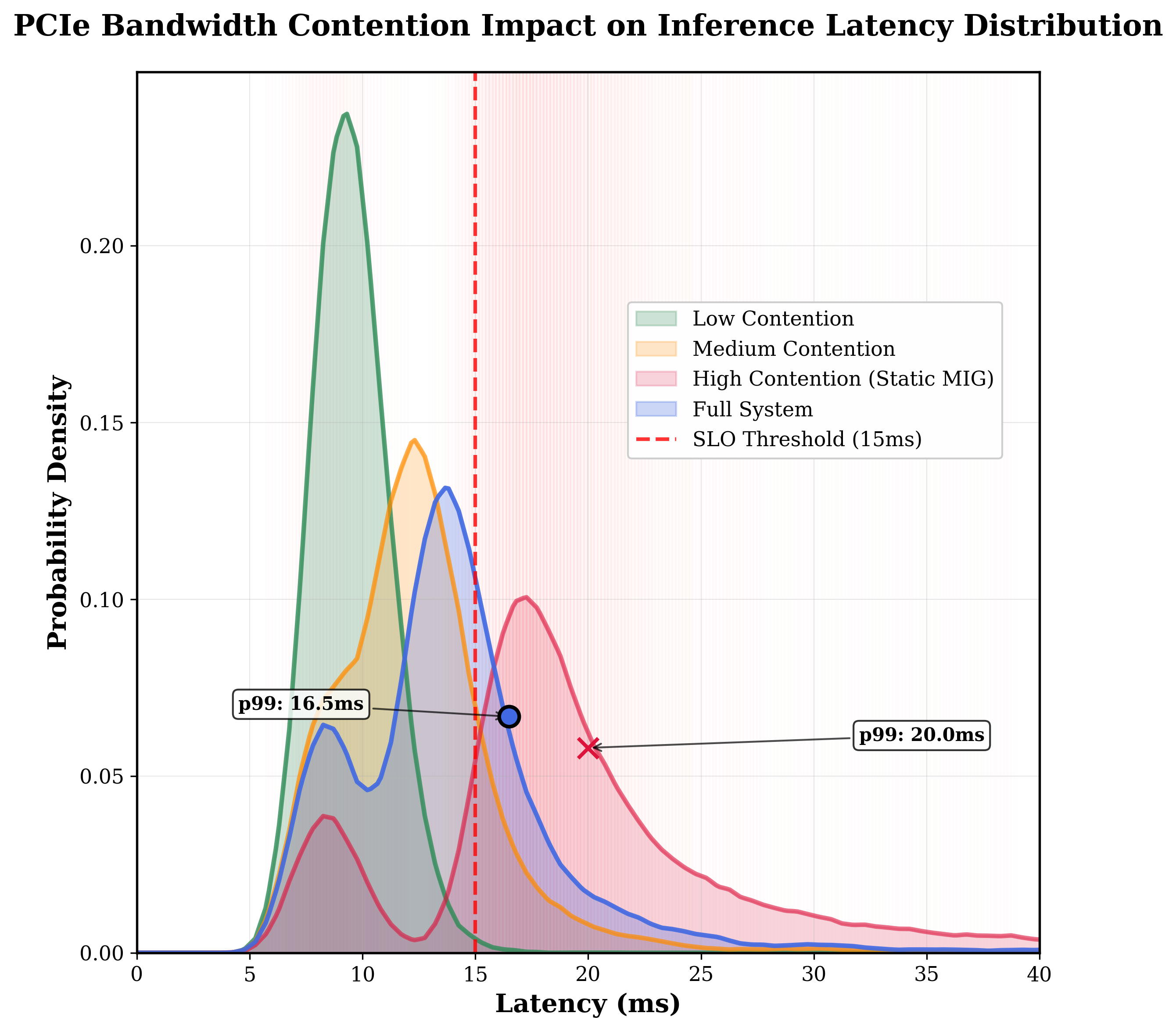
Figure 4: The impact of PCIe contention on the tail of the latency distribution.
Discussion and Limitations
While the control mechanism proves effective within its operational scope, it has limitations in environments where PCIe topology is not fully transparent. The need for brief pauses during reconfiguration and potential inadequacies for extremely heavy workloads are acknowledged. The paper highlights the modularity of the approach, which can integrate with other isolation techniques like kernel-space interception systems.
Conclusion
The proposed controller effectively reduces tail latencies and improves SLO compliance in shared GPU environments. By combining dynamic resource reallocation strategies, PCIe-aware placement, and lightweight control mechanisms, it offers a practical solution to a critical problem in LLM serving on GPU clusters. Future work could explore broader validation across larger and more diverse production environments and integrate more sophisticated prediction models for further optimization.