- The paper presents a novel Sorted-F algorithm that efficiently batches LLM requests by balancing variable prompt and output lengths.
- It rigorously proves NP-hardness of optimizing latency under dynamic KV cache constraints and shows standard heuristics can be arbitrarily suboptimal.
- Empirical evaluation on real-world workloads demonstrates up to 30% latency reduction compared to existing scheduling methods.
LLM Serving Optimization under Variable Prefill and Decode Lengths
The deployment of LLMs introduces unique scheduling complexities due to KV cache memory constraints and variable prefill (input) and decode (output) sequence lengths. Serving LLM requests efficiently is crucial for minimizing end-to-end latency, given the autoregressive generation process and the dynamic evolution of memory requirements as KV cache grows both with the prompt and each generated token. Unlike fixed-resource scheduling, each request's resource footprint changes with time, and both prompt and output sizes substantially impact the schedule, motivating a refined theoretical and algorithmic treatment beyond standard batch scheduling.
The paper fundamentally addresses a generalized LLM scheduling problem: given n requests (si,oi), where si and oi denote prompt and output lengths respectively, and a fixed KV cache limit M, process and batch requests to minimize total completion time. This is subject to at any time the sum of prompt plus decoded tokens for all active requests not exceeding M. The joint challenge of batching, precedence, variable memory, and prioritization is shown to render the problem NP-hard, a significant escalation over the uniform-input scenario analyzed in prior work (Jaillet et al., 10 Feb 2025). The paper firmly establishes that relaxing the constant si assumption leads to unbounded competitive ratios for conventional scheduling heuristics such as FCFS and output-length shortest-first.
Hardness and Negative Results
The theoretical analysis demonstrates that both FCFS and output-length shortest-first algorithms exhibit competitive ratios scaling unboundedly with the memory size M, even if scheduling by total sequence length. Specifically, the authors construct worst-case examples where prioritizing short outputs or short total lengths results in severe latency inflation, particularly as input size heterogeneity increases. The NP-hardness of minimizing end-to-end latency—even for reasonable values of si, oi—is formally proven via reduction to the 3-Partition problem. Additionally, the result extends to makespan minimization, marking the problem's complexity as fundamental and not contingent on the specific objective.
Algorithmic Framework: Sorted-F
To address these limitations, the authors introduce Sorted-F, a novel scheduling algorithm leveraging a batch selection quality metric:
F(X)=∣X∣2∑ri∈Xoi
where X is a candidate batch. Lower F(X) values indicate a preferable trade-off between batch concurrency and cumulative output length, effectively balancing throughput with memory utilization. The algorithm constructs prioritized batches to minimize F, then schedules within each batch by shortest-output-first, enforcing memory constraints at every step. The metric's design implicitly prevents pathological prioritization of small-oi requests that can result in inefficient schedule blocking.
Sorted-F's batch construction phase and schedule execution are rigorously defined, and the paper proves that it achieves a constant competitive ratio of at most 48 independent of problem scale, a marked improvement over baseline heuristics. The proof proceeds by establishing a series of structural transformations and bounding arguments, culminating in a comparative analysis between Sorted-F and an aligned transformation of the optimal schedule.
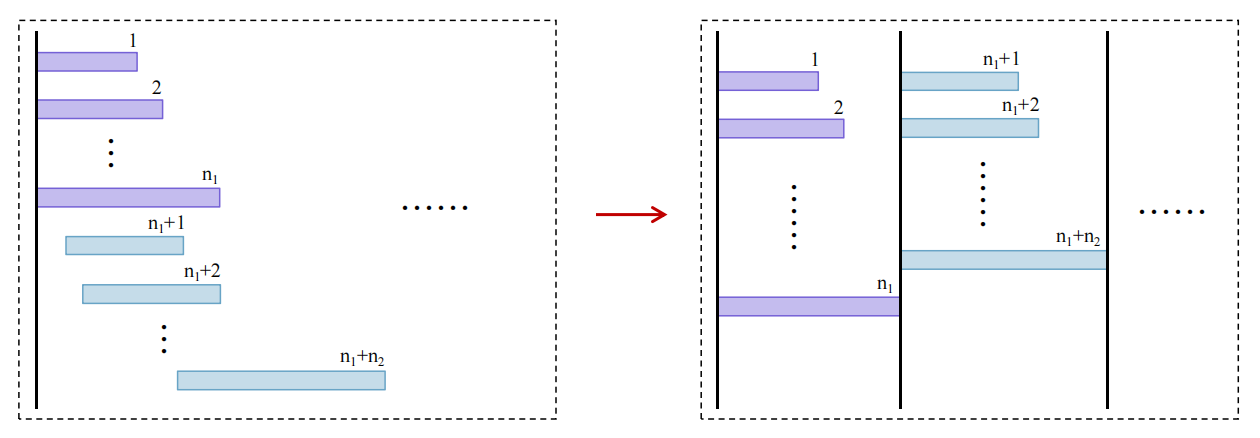
Figure 1: Sorted-F schedule transformation illustrates sequential and group batch processing steps for competitive ratio analysis.
Approximation Algorithms and Practical Deployment
Recognizing the combinatorial complexity of exact batch selection, the paper develops four distinct approximation strategies:
- Exact Dynamic Programming: Achieves optimal solutions for small n; complexity O(n2M).
- Scaled Dynamic Programming: Utilizes quantized memory bins for (1+ϵ)-approximation; scales to moderate n.
- Local Swap Search: Heuristically improves an initial greedy batch via pairwise exchanges, balancing solution quality and computation.
- Quantile Greedy Selection: Employs quantile thresholds for memory-efficient batching at scale.
Theoretical complexity and performance trade-offs are examined, and the suitability of each method is formalized across request set regimes. Hybrid algorithmic choices and workload engineering are discussed for latency-critical deployments, emphasizing the adaptability of the framework.
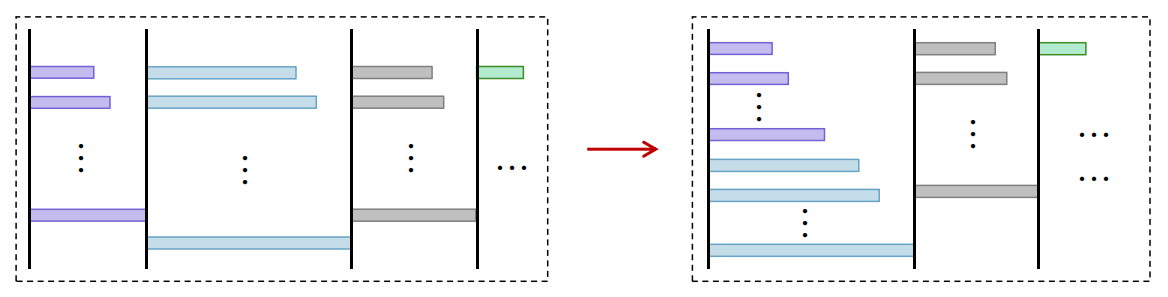
Figure 2: Comparative results of different Sorted-F approximation variants highlight batch construction impacts on schedule quality.
Integer and Linear Programming Extensions
The authors further analyze the optimal schedule as an integer program (IP), formulating a time-indexed assignment under memory constraints. While the IP is computationally intractable, relaxing to an LP allows tractable approximation. Introducing Sorted-LP, the approach sorts requests by expected start time derived from LP fractional assignment, with additional swap-based refinement yielding LP-Swap. Empirical results reveal that F-metric-guided swap optimizations nearly subsume LP-based schedule improvements, indicating the robustness of the Sorted-F framework.
Empirical Evaluation: Real-World LLM Workloads
Extensive simulations on a mixed dataset (combining short conversational requests and long document summarization from LMSYS and Arxiv, respectively) validate both theoretical insights and practical performance. Request lengths span several orders of magnitude, stress-testing the schedule under realistic variability. Results show that Sorted-F (both swap and quantile greedy variants) consistently attains lower average latency compared to FCFS, shortest-first, and LP-based methods—demonstrating superior batch quality and resource exploitation.
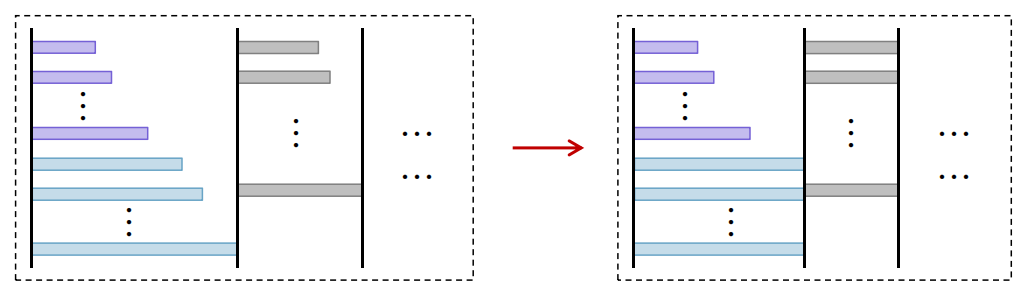
Figure 3: Average latency comparison for various scheduling algorithms confirms Sorted-F's empirical advantage on mixed real-world workloads.
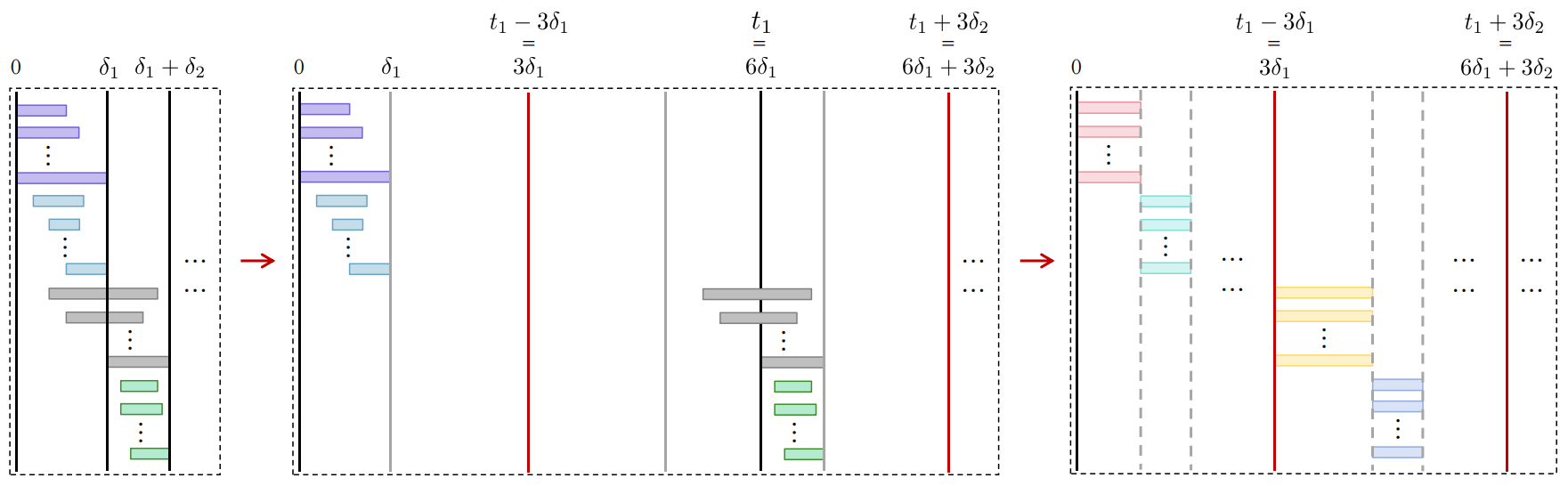
Figure 4: Optimal schedule alignment for competitive ratio upper bounding, showing batch structure matching and latency scaling.
Implications and Future Directions
The paper delivers both negative and positive results: classic heuristics falter under realistic request heterogeneity, while Sorted-F and its approximations provide both theoretical and empirical guarantees. The NP-hardness proofs clarify the intrinsic challenge posed by variable-length LLM serving, with the F-metric offering a principled and generalizable approach. The robust competitive ratio bound (48) is non-trivial in the context of online and batch scheduling literature, and the observed empirical latency reductions are substantial (nearly 30% in demonstrative cases).
The implications extend to architectures with multiple workers, time-based arrivals, and joint prompt/output optimization. The theoretical methods may further inform resource-aware LLM systems where memory and latency constraints are stringent. As prompt engineering and long-context inference advance, dynamic schedule adaptation and memory-aware batching will remain key research frontiers.
Conclusion
This work rigorously analyzes and addresses LLM serving optimization under variable-length inputs and outputs, proving NP-hardness and quantifying the suboptimality of standard scheduling strategies. The Sorted-F algorithm and its approximation suite provide constant-factor performance guarantees and practical throughput gains, supported by comprehensive simulation on real workloads. The proposed metric-based batching paradigm advances both theoretical scheduling analysis and real-world LLM infrastructure design, with clear pathways for future expansion and integration into scalable inference platforms.
Reference: "LLM Serving Optimization with Variable Prefill and Decode Lengths" (2508.06133).

