- The paper introduces a fluid dynamics-based online scheduling approach that achieves asymptotically optimal throughput for LLM inference.
- WAIT leverages known prompt output lengths to form batches under memory constraints, reducing latency and resource usage.
- Nested WAIT extends the method to handle unknown output lengths, dynamically managing memory and ensuring high throughput under varied loads.
Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints
Introduction
This paper tackles the challenge of optimizing inference for LLMs, which are integral to various NLP applications. The inference procedure requires significant computational resources due to the memory-intensive Key-Value (KV) cache used during the process. The paper proposes a novel approach to LLM inference optimization by framing it as a multi-stage online scheduling problem. This involves a fluid dynamics approximation to establish a benchmark for effective scheduling strategies, ultimately leading to the development of the WAIT and Nested WAIT algorithms.
Fluid Dynamics Approximation
The core contribution of this paper is the introduction of a fluid dynamics model to approximate the stochastic behavior of prompt arrivals and processing in LLM inference. This model serves as a benchmark for analyzing the system's equilibrium state, where prompt arrivals balance completions and memory usage stabilizes. Memory constraints are critical as they determine the maximum number of prompts a system can handle concurrently.
The paper begins with a single-type fluid model and extends it to a multi-type setup. The equilibrium analysis reveals that the optimal throughput is governed by the sum of arrival rates and the inherent time cost per batch iteration.
WAIT Algorithm
The WAIT algorithm is designed for settings where the output length of prompts is known at arrival. WAIT optimizes scheduling by maintaining thresholds for each prompt type, leveraging the fluid model to guide batch formation and scheduling decisions. The algorithm strategically accumulates prompts until specific thresholds are met, ensuring efficient resource usage and minimizing latency under heavy traffic conditions.
Heavy traffic analysis demonstrates that WAIT achieves asymptotic optimality, matching the fluid benchmark's throughput while maintaining manageable latency and time to the first token (TTFT) metrics.
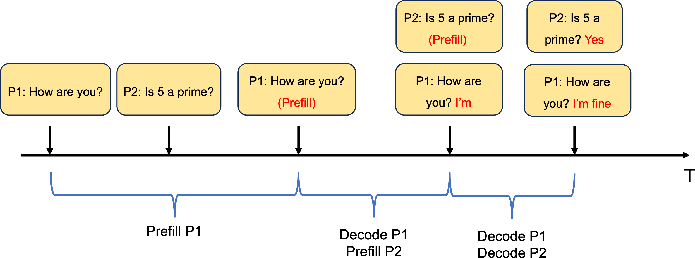
Figure 1: Example of batching and scheduling.
Nested WAIT Algorithm
In real-world scenarios, the output length may not be known at the time of arrival, complicating the scheduling process. The Nested WAIT algorithm extends WAIT to accommodate unknown types by dynamically constructing a hierarchical framework of segments. Each segment processes prompts up to a specific output length, effectively managing random arrivals and dynamically expanding the KV cache.
The algorithm continues to use thresholds per segment, making it robust against the uncertainties of batch composition. It provides theoretical guarantees similar to WAIT, with memory bounds ensuring high-probability performance without exceeding capacity.
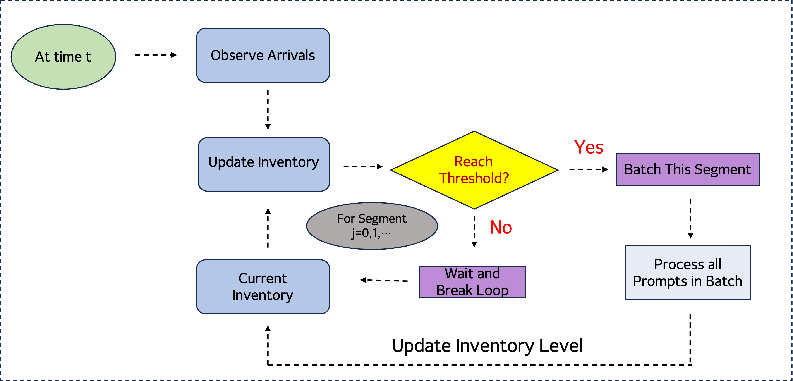
Figure 2: Pipeline of the Nested WAIT Algorithm.
Numerical Experiments
Experiments compare WAIT and Nested WAIT to other baseline methods such as vLLM and Sarathi, using synthetic and real-world datasets. These tests reveal that the proposed algorithms consistently outperform benchmarks in terms of throughput across both low and high-demand scenarios.
Figures demonstrate that WAIT reduces latency while enhancing throughput, catching up with the computed fluid dynamics benchmarks in practical settings.
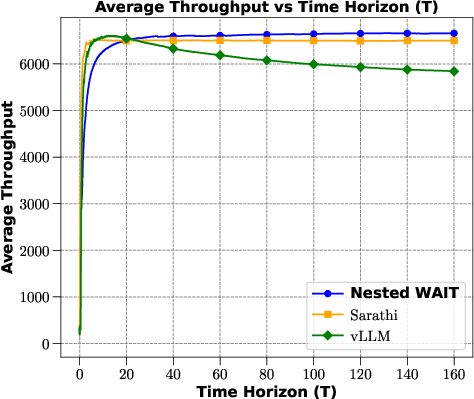
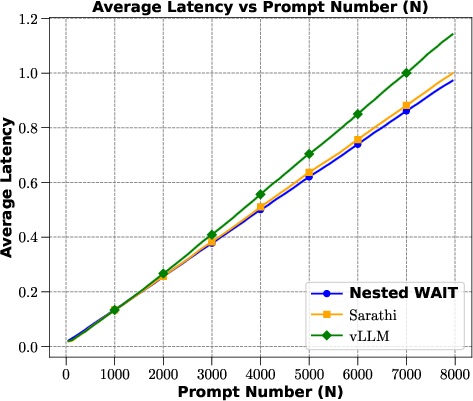
Figure 3: Average throughput and latency across algorithms on the synthetic dataset.
Conclusion
The work bridges the disciplines of operations research and machine learning by providing a mathematical framework applicable to LLM inference under memory constraints. Future research directions include exploring multi-GPU systems, volatile arrival dynamics, and evolving system-level optimizations, all of which can further improve LLM deployment efficiency.
The analytical foundation laid by this study paves the way for robust, scalable scheduling solutions that optimize the performance of LLMs in diverse operating environments.