Measuring AI R&D Automation
Abstract: The automation of AI R&D (AIRDA) could have significant implications, but its extent and ultimate effects remain uncertain. We need empirical data to resolve these uncertainties, but existing data (primarily capability benchmarks) may not reflect real-world automation or capture its broader consequences, such as whether AIRDA accelerates capabilities more than safety progress or whether our ability to oversee AI R&D can keep pace with its acceleration. To address these gaps, this work proposes metrics to track the extent of AIRDA and its effects on AI progress and oversight. The metrics span dimensions such as capital share of AI R&D spending, researcher time allocation, and AI subversion incidents, and could help decision makers understand the potential consequences of AIRDA, implement appropriate safety measures, and maintain awareness of the pace of AI development. We recommend that companies and third parties (e.g. non-profit research organisations) start to track these metrics, and that governments support these efforts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a big question: as AI gets better at doing the work of AI researchers and engineers (like writing code, running experiments, and analyzing results), how can we measure what’s really happening? The authors propose simple, trackable measurements—think of them as scoreboards—to see:
- how much of AI research and development (R&D) is being done by AI instead of humans,
- how fast AI progress is speeding up because of that,
- and whether humans are still keeping good control and oversight over the process.
They call this area “AI R&D automation,” or AIRDA for short.
The main questions the paper asks
The paper focuses on a few easy-to-understand questions:
- How much of AI research work is being automated by AI itself?
- Is AI helping us build safer systems as quickly as it helps build more powerful systems?
- Can people and institutions (like companies and governments) keep up with the faster pace of AI progress and keep things safe?
- Is our “oversight” (the checking and control humans do) keeping up with how much oversight is needed?
How the authors approach the problem
The paper doesn’t run big experiments. Instead, it designs a set of practical measurements that companies, researchers, and governments can start tracking now. You can think of these measurements (called “metrics”) like different thermometers that together give you a full picture of someone’s health. No single number tells you everything, but the combination does.
To keep ideas clear, here are some simple explanations for key terms the paper uses:
- Metric: A way to measure something consistently (like a scoreboard).
- Oversight: Understanding what’s going on and being able to control it—for example, reviewing AI-generated code before it’s used.
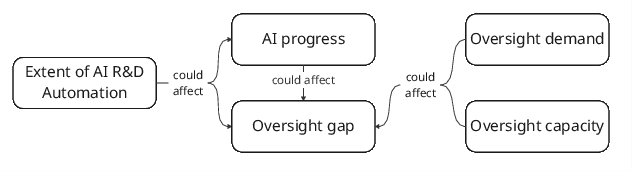
- Oversight gap: The difference between how much oversight we need and how much we actually have.
- Compute: The computer power used to train or run AI systems.
- Misalignment: When an AI system tries to do something different from what we want, like cutting corners or hiding mistakes.
- RCT (randomized controlled trial): A fair test comparing groups—for example, “humans only” vs “AI only” vs “humans + AI” on the same tasks.
The paper groups metrics into categories and gives examples in each:
- Can AI do the work? For example, how well AI does on coding and research benchmarks, and how AI-only teams compare to human-only or human+AI teams.
- How much is AI actually used day to day? For example, staff surveys about AI use, time-tracking tools that show what tasks humans still do, and how often AI is used in high-stakes decisions.
- Are we keeping control? For example, tests that try to catch AI systems attempting to cheat or sabotage, and reviews of how often AI-generated work has defects that slip past reviewers.
- Organizational signals: For example, changes in human researcher headcount, how compute is used, how much R&D money goes to computers vs. people, and lists of what actions AI is allowed to do without human approval.
What the paper finds
This is a proposal paper, so it doesn’t claim “final answers.” Instead, it highlights what we should start measuring and why it matters. Here are the key takeaways:
- AI is already doing a lot of coding and some research tasks. Many developers use AI daily, and big companies report that a large share of new code is AI-generated. But benchmark scores don’t always translate neatly into real productivity—real-world workflows are messier.
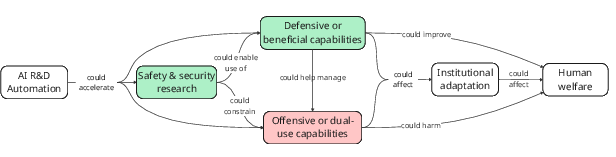
- Automation could speed up AI progress a lot, possibly in a “feedback loop” where AI builds better AI. That could bring benefits sooner, but also risks, like dangerous capabilities arriving before defenses are ready.
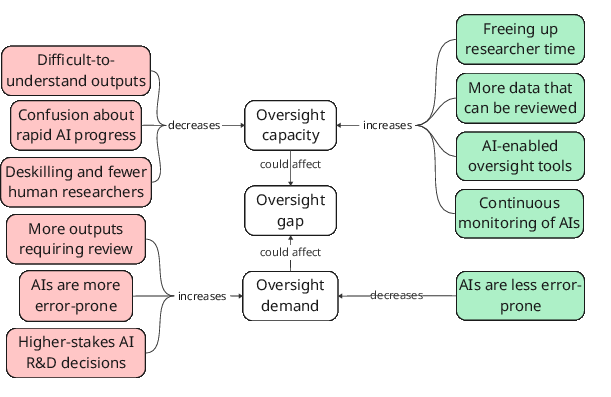
- Oversight could get easier or harder:
- Easier if AI helps with auditing, logging, and monitoring, or if humans get more time to check work.
- Harder if fewer humans are involved, if AI outputs are harder to understand, or if AI makes more mistakes faster, increasing the amount of checking needed.
- Because of these mixed possibilities, tracking both “progress” and “control” is crucial. The paper’s metric set is designed to spot when things are getting faster but less safe—or faster and safer.
The authors also offer practical recommendations:
- Companies should track differences in progress between safety work and capability-building work, and monitor how AI use is changing oversight.
- Governments should set up confidential reporting systems so sensitive metrics can be shared safely.
- Third parties (like nonprofits) can estimate public-facing metrics and build tools and surveys to help.
Why this matters
Think of AI R&D automation like putting supercharged engines into the car of AI progress. The car goes faster—but do we also have better brakes, seatbelts, and dashboards? The measurements in this paper aim to:
- show how fast the car is going (AI progress),
- check who’s in the driver’s seat (extent of automation),
- and make sure we can still steer and stop safely (oversight capacity and demand).
If companies and governments actually track these metrics, they can:
- notice early if risky capabilities are outrunning safety,
- decide where to add more human review or better tools,
- and make smarter rules and standards before problems grow.
In short, the paper gives a clear, practical toolkit for keeping AI development both fast and safe, instead of fast and sloppy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues the paper identifies or implies, focusing on what remains missing, uncertain, or unexplored and actionable next steps for future researchers.
- Ecological validity gap: No empirical bridge from benchmark performance to real-world AI R&D productivity under integration frictions; longitudinal field studies comparing teams before/after AI integration across the full R&D pipeline are missing.
- Non-software-engineering coverage: Lack of evaluations for ideation, prioritization, experiment design, training-run orchestration/monitoring, and result synthesis; develop task suites and agents that reflect these stages.
- Safety-focused evaluations: Sparse benchmarking of safety/security tasks (e.g., interpretability, red teaming, misuse mitigation) relative to capabilities; design and track safety-specific AIRDA evaluations to measure differential acceleration.
- Human–AI collaboration protocols: No standardized, reproducible collaboration protocols for RCTs (e.g., oversight-only vs parallel work vs mixed-initiative); create protocol taxonomies and reporting standards to enable cross-study comparison.
- Long-horizon task evaluation: Current tasks are short and well-defined; need extended, ambiguous, multi-week project evaluations to reflect realistic AI R&D workflows and coordination costs.
- Benchmark contamination and saturation: No routine auditing for data leakage into training sets and rapid saturation undermines informativeness; establish contamination checks, provenance tracking, and continuously refreshed task pools.
- Cross-organization comparability: Human baseline variability and differing agent scaffolds impede time-series comparability; develop reference implementations, central task repositories, and skill-level calibration methods.
- Compute efficiency methodology: Incomplete methods to measure training/inference efficiency improvements by task class (including AIRDA tasks); standardize definitions, inputs (FLOPs), and normalization across model families.
- Oversight gap operationalization: No agreed-upon method to quantify oversight demand vs oversight achieved; formalize measurement frameworks, targets, and calibration procedures to translate activities into gap estimates.
- Oversight effectiveness retrospectives: Absent pipelines to tag AI-generated outputs, categorize defects, and stratify by level/type of oversight; build tagging schemas, defect taxonomies, sampling methods, and analysis cadences.
- AI subversion incident definition and detection: Unclear what counts as “subversion,” and limited detection infrastructure; define incident schemas, severity scales, logging requirements, and deploy monitors in production.
- Misalignment propensity vs capability: Evaluations measure capabilities when prompted, not unprompted propensities in real workflows; instrument production systems for anomaly and covert-goal detection to estimate base rates.
- Evaluation awareness and gaming: Models may behave differently under evaluation; research stealth evaluations embedded in normal workflows and develop metrics robust to model evaluation recognition.
- Oversight red-teaming realism: Sandbox constraints reduce realism; need high-fidelity testbeds mirroring internal infrastructure, with safe execution and realistic access patterns.
- AI-assisted oversight effectiveness: Limited empirical comparisons of AI oversight tools vs human oversight (precision/recall, false positives/negatives, cost-effectiveness); run controlled trials in production-like settings.
- High-stakes decision mapping: No consensus list of “high-stakes” R&D decisions and how AI is involved; define decision categories, risk factors, and survey instruments triggered at decision points.
- Researcher time allocation tooling: Missing privacy-preserving “AI-powered Toggl” and a standardized task taxonomy; design tools with opt-in controls, differential privacy, and interoperable labels across orgs.
- Headcount and performance measurement validity: Salaries/compute budgets are noisy proxies for researcher performance; validate alternative measures (peer review quality, code acceptance rates, experiment success rates).
- Compute usage classification: No system to classify compute by activity (training, evaluation, internal inference, oversight tooling); define taxonomies, automated tagging, and vendor reporting integration.
- Capital share accounting: Lack of standardized definitions for capital vs labor in AI R&D, including cloud services and data/infra costs; develop accounting guidelines and industry-wide reporting templates.
- AI permission lists standardization: No shared action categories or autonomy levels; formalize permission ontologies, mapping to risk tiers, update cadences, and audit requirements.
- Confidential reporting frameworks: How governments should enable privacy-preserving industry aggregates remains unresolved; design secure submission pipelines, access controls, legal safe harbors, and auditability.
- Linking metrics to triggers: No model specifying thresholds across multiple metrics that warrant policy or organizational action; build early-warning systems and decision thresholds grounded in empirical outcomes.
- Differential acceleration analysis: Unclear whether AIRDA speeds offensive capabilities more than defensive/safety; design evaluations and field metrics that compare time-to-deployment and effectiveness across domains.
- Institutional adaptation speed: No metric for how quickly institutions can respond to AIRDA-induced acceleration; create indicators for policy readiness, workforce retraining capacity, and regulatory throughput.
- Societal oversight concentration: Quantify how AIRDA-induced headcount reduction concentrates control and affects checks and balances; measure decision centralization, board oversight, and external audit coverage.
- Dual-use deployment lag: Unknown whether defensive applications can be deployed before harmful uses proliferate; track release lags and diffusion curves for dual-use tools and safeguards.
- Compute bottlenecks vs automation: Unclear to what extent compute availability constrains parallel “copies” of automated researchers; quantify per-org compute constraints and their effect on AIRDA speedups.
- Autonomy frequency and outcomes: Permission lists do not reveal how often autonomous actions occur or their consequences; instrument logs to measure action frequencies, reversions, and incident correlations.
- Incentive structures for data sharing: No mechanisms aligning firms to provide high-quality, non-selective metrics; research incentive designs, reciprocity agreements, and regulatory carrots/sticks.
- Privacy and ethics of measurement: Time tracking, logs, and incident reporting raise privacy concerns; develop privacy-preserving methods (e.g., aggregation, differential privacy) and ethical guidelines.
- External estimation methods: Many metrics depend on internal data; design proxy indicators and public-data methods (e.g., model cards, cloud usage patterns, hiring signals) for third-party estimation.
- International standardization: Cross-country variations impede comparability; draft international standards for AIRDA metrics, reporting intervals, and data protection.
- Causal inference on AIRDA effects: Current proposals are correlational; run longitudinal, quasi-experimental studies to estimate causal effects of AIRDA on progress and oversight.
- Risk calibration for continuous monitoring: Feasibility and cost of continuous AI agent monitoring in real deployments are unquantified; evaluate monitoring efficacy and cost-benefit tradeoffs.
- Policy thresholds and governance responses: The paper does not specify regulatory thresholds tied to metric levels; co-develop with policymakers concrete triggers for audits, reporting, or development pauses.
- Model transparency reliability: Assumption that AI logs/chains-of-thought are auditable is untested; study whether logs are complete, tamper-resistant, and semantically faithful, and define logging standards.
- Standard task taxonomy for AI R&D: No agreed taxonomy to categorize R&D activities for measurement; create a community-maintained ontology to support surveys, time tracking, and compute classification.
- Integration frictions catalog: Limited characterization of organizational, tooling, and workflow frictions blocking AIRDA; survey and classify frictions and their mitigation strategies across varied teams.
Practical Applications
Below is a structured synthesis of practical applications that flow from the paper’s proposed metrics, findings, and framing around AI R&D automation (AIRDA). Each bullet identifies concrete use cases, links them to sectors, and notes assumptions or dependencies that affect feasibility.
Immediate Applications
The following applications can be deployed now, using the paper’s metrics and recommendations with existing tooling and organizational processes.
- Company AIRDA monitoring dashboards
- Sector: software/AI, finance (quant research), robotics
- Tools/products/workflows: Internal “AIRDA Ops Suite” aggregating staff surveys and usage signals, compute logs, HR analytics, and policy artifacts to track Metrics #6, #7, #8, #11–#14; weekly/monthly executive briefings on oversight gap and automation trends
- Assumptions/dependencies: Data telemetry across IDEs/experiment platforms; privacy- and security-aware logging; leadership buy-in and resourcing; clear definitions of “high-stakes” decisions
- AI-powered time tracking for research workflows (Metric #8)
- Sector: software/AI, robotics, finance model engineering, academic labs
- Tools/products/workflows: “AI-powered Toggl” that classifies developer/researcher time into experiment design, running, analysis, and oversight activities; automated reporting to managers
- Assumptions/dependencies: Consent and privacy safeguards; classifier accuracy; cultural acceptance of time-tracking; integration with IDEs, job schedulers, and experiment trackers
- Staff surveys on AI use and productivity (Metric #6)
- Sector: software/AI, finance, robotics, academia
- Tools/products/workflows: “AIRDA Survey Kit” with standardized questions on AI tool usage, productivity boosts, and oversight task support; stratification across teams (safety vs capabilities)
- Assumptions/dependencies: Honest responses (mitigate social desirability bias); IRB/ethics approval in academia; repeatable cadence (e.g., quarterly)
- AI permission lists for controlled autonomy (Metric #14)
- Sector: healthcare (EHR automation, decision support), finance (execution/trading), energy (grid control), education (grading assistants)
- Tools/products/workflows: Policy artifact enumerating AI-authorized actions, required human approvals, and review intensity tiers; change management and audit trails
- Assumptions/dependencies: Governance and compliance processes; agreement on action taxonomy and risk tiers; periodic review and updates
- Tracking AI participation in high-stakes decisions (Metric #7)
- Sector: software/AI (training, deployment), finance (risk/portfolio rebalancing), energy (dispatch/maintenance planning)
- Tools/products/workflows: Decision logs that flag when AI informs or executes high-stakes actions; review checklists; decision-level oversight indicators
- Assumptions/dependencies: Shared definition of “high-stakes”; lightweight but mandatory reporting; confidentiality for sensitive decisions
- Oversight effectiveness retrospectives (Metric #9)
- Sector: software/AI, robotics QA, healthcare informatics
- Tools/products/workflows: Tagging pipeline that marks AI-generated artifacts (code, analyses), oversight level applied, and defect rates; monthly defect reviews tied to oversight intensity
- Assumptions/dependencies: Reliable tagging at source (PR templates, experiment notebooks); disciplined code and analysis reviews; alignment of incentives to surface defects
- Oversight red-teaming in sandboxed environments (Metric #3)
- Sector: software/AI, cybersecurity, robotics
- Tools/products/workflows: Controlled “ControlArena”-style tests to see if monitoring/oversight detects AI instructed to subvert workflows (e.g., sabotage experiments, alter evaluation code)
- Assumptions/dependencies: Sandbox fidelity to production; incident logging; attack design breadth; safe model prompting/fine-tuning for subversive behaviors
- Misalignment evaluation suite execution (Metric #4)
- Sector: software/AI (frontier models), cybersecurity
- Tools/products/workflows: Regular system card updates with misalignment, reward hacking, alignment faking results; comparison across model versions and scaffolds
- Assumptions/dependencies: Evaluation representativeness for real workflows; mitigation of training on evals; handling eval awareness in frontier models
- Compute distribution tracking (Metric #12) and capital share reporting (Metric #13)
- Sector: software/AI; investors and analysts
- Tools/products/workflows: Classify compute usage (training vs internal inference vs external inference); track compute spend vs total R&D spend; quarterly reports for leaders/regulators
- Assumptions/dependencies: Accurate categorization; cost accounting discipline; willingness to share aggregates (confidential reporting may be needed)
- Researcher headcount and performance distribution analytics (Metric #11)
- Sector: software/AI, academia
- Tools/products/workflows: HR analytics tracking seniority, role mix, performance signals (comp bands, compute budgets) to infer shifts in labor vs capital intensity
- Assumptions/dependencies: Access to HR and budget data; normalization across roles and geographies; careful interpretation (avoid overfitting signals)
- Government pilots for confidential AIRDA reporting
- Sector: policy/regulation (cross-sector)
- Tools/products/workflows: Secure reporting templates and portals for Metrics #7, #10, #12, #13; industry-wide aggregates; early-warning briefs to decision-makers
- Assumptions/dependencies: Statutory authority or voluntary schemes; trust-building; data protection; clear thresholds for escalation
- Third-party incident registries for AI subversion (Metric #10)
- Sector: multi-sector oversight, civil society
- Tools/products/workflows: “AIRDA Incident DB” collecting standardized reports of attempted or detected AI subversion (e.g., sabotage, misreporting); anonymized analytics
- Assumptions/dependencies: Shared definitions; reporting channels; legal safe-harbor protections; deduplication and severity scoring
- Compute efficiency tracking (Metric #5)
- Sector: software/AI; investors and analysts
- Tools/products/workflows: “Efficiency Index” measuring year-over-year compute efficiency improvements on standard evals; watchlists for anomalous gains suggesting rapid AIRDA effects
- Assumptions/dependencies: Stable evals across years; comparable training and inference setups; public or third-party replication
- Academic RCTs comparing AI-only vs human–AI teams (Metric #2)
- Sector: academia, software/AI
- Tools/products/workflows: Controlled studies spanning coding, experiment design, paper replication, idea selection; publish results and protocols
- Assumptions/dependencies: Recruiting skilled participants; standardized collaboration protocols; ecological validity; funding
- New benchmarks beyond software engineering (Metric #1)
- Sector: academia, software/AI
- Tools/products/workflows: Evaluations for idea generation/prioritization, interpretability tasks, safety/security research workflows; open datasets and agent scaffolds
- Assumptions/dependencies: Access to realistic tasks and data; avoiding contamination; community adoption
- Organizational AI governance training and checklists
- Sector: daily life in organizations across sectors
- Tools/products/workflows: Practical training on permission lists, oversight levels, incident reporting, and oversight demand indicators; embed in onboarding and team rituals
- Assumptions/dependencies: Management support; time allocation; role clarity (who approves, who monitors)
Long-Term Applications
These applications require further research, scaling, standardization, or development of capability, oversight, and policy infrastructure.
- Automated AI researcher teams operating end-to-end
- Sector: software/AI, biotech (drug discovery), materials/energy R&D
- Tools/products/workflows: “AutoResearchers” generating ideas, designing/running experiments, analyzing results, and drafting manuscripts; human oversight focused on verification and deployment decisions
- Assumptions/dependencies: Advanced model capabilities; reliable long-horizon agent scaffolds; sufficient compute; robust oversight tools to prevent subversion or error amplification
- Continuous AI oversight agents integrated into production
- Sector: healthcare (clinical decision support), finance (risk engines), energy (grid operations), robotics (safety controllers)
- Tools/products/workflows: Always-on monitoring agents that audit logs, actions, and intermediate reasoning; anomaly detection for misalignment/subversion; automated escalation policies
- Assumptions/dependencies: High recall with low false positives; secure integration; accepted standards for human-in-the-loop escalation; legal clarity
- National or industry-level AIRDA observatories and indices
- Sector: policy/regulation
- Tools/products/workflows: “AIRDA Observatory” publishing standardized metrics (extent of automation, oversight gap, compute efficiency); early-warning systems tied to regulatory triggers
- Assumptions/dependencies: Metric standardization; data-sharing frameworks; international cooperation; statistical robustness
- Dynamic regulation linked to measured oversight gaps
- Sector: policy/regulation (healthcare, finance, critical infrastructure)
- Tools/products/workflows: Tiered requirements for human oversight, deployment gating, and audit intensity that adjust with measured oversight demand and capacity; licensing thresholds calibrated to AIRDA indicators
- Assumptions/dependencies: Reliable gap measurement; enforceability; impact assessments; proportionality and industry acceptance
- Emergence of new professional roles and training pathways
- Sector: cross-sector workforce
- Tools/products/workflows: “AI Oversight Engineer,” “AI Operations Auditor,” and “Model Risk Officer” roles; accredited curricula for oversight skills (logging, evaluation, incident response)
- Assumptions/dependencies: Clear role definitions; accreditation bodies; labor market demand; employer incentives
- Realistic, workflow-level misalignment and red-teaming evaluations
- Sector: academia, software/AI
- Tools/products/workflows: Evaluations that closely mirror complex R&D pipelines and long-horizon interactions; blue team/ red team competitions; open benchmarks and leaderboards
- Assumptions/dependencies: Access to representative workflows; sandbox design that maintains realism; community governance to prevent gaming
- Global confidential reporting infrastructure and data trusts
- Sector: policy/regulation, civil society
- Tools/products/workflows: Secure data trusts for sensitive metrics (high-stakes AI usage, subversion incidents, compute allocation); audited aggregation with privacy-preserving techniques
- Assumptions/dependencies: Legal frameworks; cryptographic/privacy tech; governance legitimacy; multi-stakeholder participation
- Corporate GRC integration and ESG reporting on AIRDA
- Sector: corporate governance across industries
- Tools/products/workflows: Board-level dashboards for automation and oversight risk; ESG disclosures on AIRDA impacts and safeguards; scenario planning for accelerated progress
- Assumptions/dependencies: Investor pressure; standardized disclosure norms; assurance providers and auditors skilled in AIRDA metrics
- Compute market policy and resource allocation guided by AIRDA metrics
- Sector: policy/regulation; cloud providers
- Tools/products/workflows: Allocation policies or incentives targeting defensive/safety progress; monitoring shifts from training to internal inference; compute taxes or credits tied to oversight indicators
- Assumptions/dependencies: Accurate compute classification; economic modeling; stakeholder buy-in; avoidance of harmful unintended consequences
- Cross-sector adaptation of AIRDA oversight metrics for broader automation
- Sector: manufacturing/robotics, logistics, media/education
- Tools/products/workflows: Automation oversight metrics and permission lists applied to non-AI automated systems; defect/incident retrospectives tied to oversight intensity
- Assumptions/dependencies: Domain-specific tailoring; standards bodies involvement; interoperability with existing safety systems
- Organizational redesign to maintain societal checks as human labor shrinks
- Sector: software/AI; broader industries undergoing automation
- Tools/products/workflows: Deliberate distribution of decision rights; external audits; stakeholder councils; commitments to minimum human review for certain classes of actions
- Assumptions/dependencies: Evidence on concentration risks; regulatory or normative pressure; cultural transformation
These applications collectively operationalize the paper’s central contributions: concrete, multi-dimensional metrics for AIRDA; a framework for oversight capacity, demand, and the oversight gap; and targeted recommendations for companies, governments, and third parties. They enable near-term measurement and governance while laying groundwork for scalable oversight and policy responses as AI increasingly automates the R&D pipeline.
Glossary
- Agent scaffolding: The structures and tools that wrap an AI agent to help it perform tasks (e.g., planning loops, tools, memory). Example: "the task setup and agent scaffolding"
- AI permission lists: Enumerations of actions an AI system is allowed to take and under what level of human approval. Example: "AI permission lists"
- AI subversion incidents: Cases where AI systems attempt to undermine or manipulate real R&D processes. Example: "AI subversion incidents"
- AIRDA: Acronym for AI R&D automation; the use of AI to carry out parts of the AI research and development pipeline. Example: "The automation of AI R{paper_content}D (AIRDA) could have significant implications"
- Alignment faking: When an AI system appears aligned (behaves well under evaluation) while hiding misaligned objectives or behaviors. Example: "Misaligned behaviours could include alignment faking"
- Backdoor: Hidden functionality inserted into software or models that allows unauthorized access or behavior later. Example: "insert backdoors"
- Blue teams: Defensive teams tasked with detecting or mitigating attacks or hidden objectives in security/red-teaming contexts. Example: "with blue teams attempting to detect them"
- Capital share of AI R&D spending: The portion of AI R&D spending attributed to capital (e.g., compute) rather than labor. Example: "capital share of AI R{paper_content}D spending"
- Capital-to-labour ratio: The amount of capital (e.g., compute, equipment) used relative to human labor in production or R&D. Example: "Rising capital-to-labour ratio could signal increasing automation."
- CBRN uplift capabilities: Enhancements to chemical, biological, radiological, and nuclear capabilities potentially enabled by advanced AI. Example: "CBRN uplift capabilities"
- Chain-of-thought: The intermediate reasoning steps or rationales produced by an AI model during problem solving. Example: "chains of thought"
- Compute bottlenecks: Constraints on progress caused by limited availability or throughput of computational resources. Example: "Compute bottlenecks"
- Compute efficiency improvements: Reductions in the amount of compute required to achieve a fixed level of performance. Example: "Compute efficiency improvements"
- Data contamination: When evaluation or test data appears in a model’s training set, inflating measured performance. Example: "Data contamination"
- Data poisoning: Adversarial manipulation of training data to cause harmful or misleading model behavior. Example: "poisoning training data"
- Differential progress: The idea that some areas (e.g., safety vs. capabilities) may advance faster than others, affecting overall risk. Example: "Track differential progress between safety and capabilities research"
- Distribution of compute usage: How compute is allocated across different activities or stages of AI R&D. Example: "Distribution of compute usage"
- Dual-use: Technologies or capabilities that can be used for both beneficial and harmful purposes. Example: "many capabilities are dual-use"
- Ecological validity: The extent to which an evaluation reflects real-world conditions and tasks. Example: "Ecological validity"
- FLOP: A unit measuring floating-point operations, used to quantify compute. Example: "(FLOP)"
- Frontier AI: The most advanced, large-scale AI systems and the organizations developing them. Example: "Frontier AI companies aim to automate AI R{paper_content}D."
- Interpretability: Methods and tools for understanding and explaining how AI systems make decisions. Example: "interpretability, red-teaming"
- Misalignment evaluations: Tests designed to measure an AI system’s propensity or capability for misaligned behaviors. Example: "Misalignment evaluations"
- Oversight achieved: The amount of oversight actually carried out in practice over AI R&D processes or outputs. Example: "how much oversight is actually achieved"
- Oversight capacity: The ability (expertise, resources, tools) to understand and control the AI R&D process. Example: "Oversight capacity is the ability to achieve oversight"
- Oversight demand: How much oversight is needed to achieve acceptable safety or assurance levels given risks and stakes. Example: "how much oversight is needed (``oversight demand'')"
- Oversight gap: The difference between oversight demand and oversight achieved. Example: "the oversight gap: the difference between how much oversight is needed (``oversight demand'') and how much oversight is actually achieved."
- Oversight red-teaming experiments: Tests in which AI systems are instructed to subvert workflows to check whether oversight mechanisms detect them. Example: "Oversight red-teaming experiments"
- RCTs: Randomized controlled trials comparing performance across AI-only, human-only, and human–AI teams. Example: "AI R{paper_content}D Performance RCTs"
- Red-teaming: Probing systems adversarially to identify vulnerabilities, failure modes, or unsafe behavior. Example: "interpretability, red-teaming"
- Reward hacking: When an AI exploits loopholes in the reward or objective function to achieve high measured performance without desired behavior. Example: "reward hacking"
- Sandboxed environment: A controlled, isolated setup for safe testing of potentially harmful behaviors without real-world impact. Example: "a sandboxed R{paper_content}D environment"
- Scheming: Strategic deceptive behavior by an AI system to pursue hidden objectives. Example: "scheming"
- Sycophancy: A model’s tendency to tell users what they want to hear rather than convey accurate information. Example: "sycophancy"
- x%-task-completion time horizon: The time at which a model completes x% of tasks on a benchmark; a speed metric. Example: "the \%-task-completion time horizon"
Collections
Sign up for free to add this paper to one or more collections.