$V_1$: Unifying Generation and Self-Verification for Parallel Reasoners
Abstract: Test-time scaling for complex reasoning tasks shows that leveraging inference-time compute, by methods such as independently sampling and aggregating multiple solutions, results in significantly better task outcomes. However, a critical bottleneck is verification: sampling is only effective if correct solutions can be reliably identified among candidates. While existing approaches typically evaluate candidates independently via scalar scoring, we demonstrate that models are substantially stronger at pairwise self-verification. Leveraging this insight, we introduce $V_1$, a framework that unifies generation and verification through efficient pairwise ranking. $V_1$ comprises two components: $V_1$-Infer, an uncertainty-guided algorithm using a tournament-based ranking that dynamically allocates self-verification compute to candidate pairs whose relative correctness is most uncertain; and $V_1$-PairRL, an RL framework that jointly trains a single model as both generator and pairwise self-verifier, ensuring the verifier adapts to the generator's evolving distribution. On code generation (LiveCodeBench, CodeContests, SWE-Bench) and math reasoning (AIME, HMMT) benchmarks, $V_1$-Infer improves Pass@1 by up to $10%$ over pointwise verification and outperforms recent test-time scaling methods while being significantly more efficient. Furthermore, $V_1$-PairRL achieves $7$--$9%$ test-time scaling gains over standard RL and pointwise joint training, and improves base Pass@1 by up to 8.7% over standard RL in a code-generation setting.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI models (like chatbots) to not only come up with answers, but also to check their own work more reliably—especially when they generate many possible solutions in parallel. The authors introduce “V,” a two-part system that:
- Picks the best answer from a bunch of AI-generated options by comparing them in pairs (like a mini tournament).
- Trains a single model to be both a good problem-solver and a good judge of its own answers.
The goal is to make AI better at solving hard tasks, such as writing code and doing math, by using its computing power at “test time” (when it’s answering questions) more wisely.
What questions did the researchers ask?
The paper focuses on two simple questions:
- If an AI creates many possible answers, how can it best choose the right one?
- Can we train an AI to get better at both solving problems and judging which of its answers is best—at the same time?
How did they study it?
The researchers studied a common setup called “parallel reasoning”: the AI generates several different solutions to the same problem. The tricky part is picking the best one.
They compared two ways of checking answers:
- Pointwise checking: Scoring each answer separately on a 1–10 scale and picking the highest.
- Pairwise checking: Comparing two answers head-to-head and deciding which one is better.
They found pairwise checking works much better. Based on that, they built two tools:
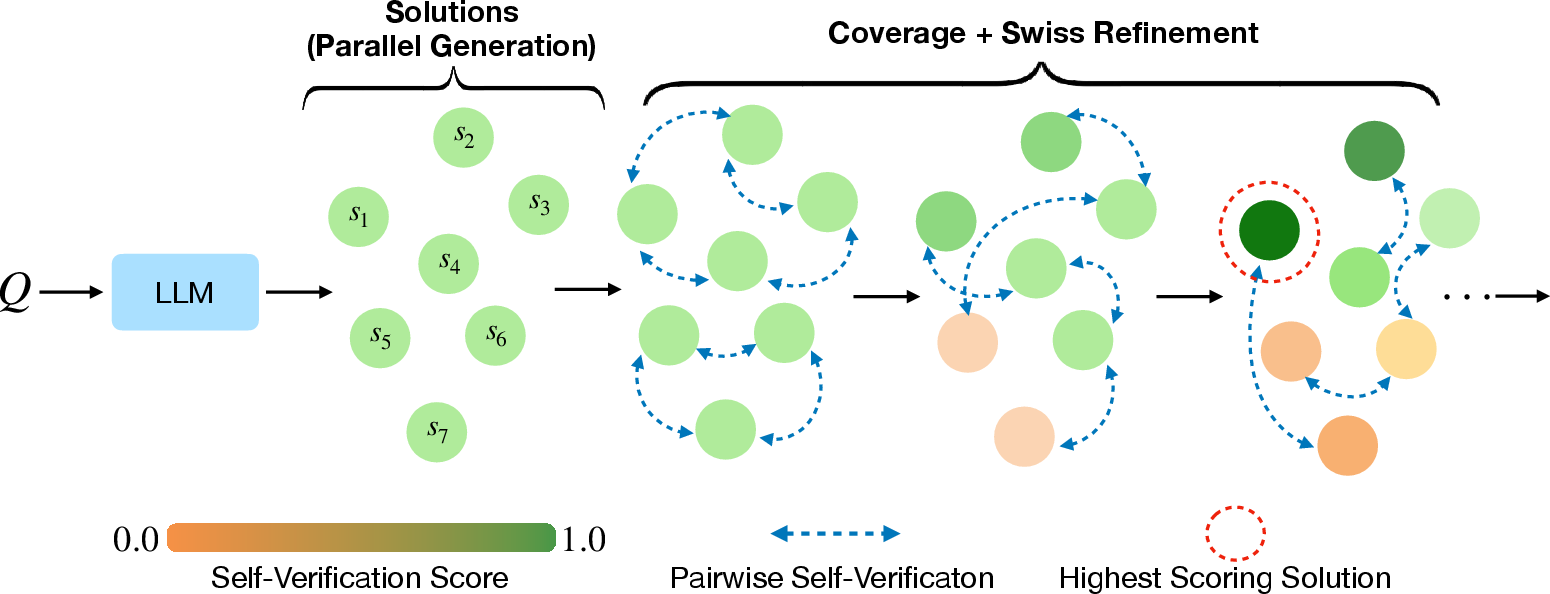
V-Infer: A smart “pairwise tournament” to pick the best answer
Think of this like a science fair where projects are compared in pairs:
- Phase 1 (Coverage): Make sure every answer gets seen and compared at least a couple of times.
- Phase 2 (Swiss-style refinement): Focus comparisons on the closest matchups—answers that seem equally good—because that’s where comparisons are most informative.
- Confidence weighting: When the AI judge compares two answers, it also says how strongly it prefers one (using a 1–10 score). Stronger preferences count more when ranking all answers.
This way, the model spends its checking effort where it matters most and avoids wasting time comparing obvious mismatches.
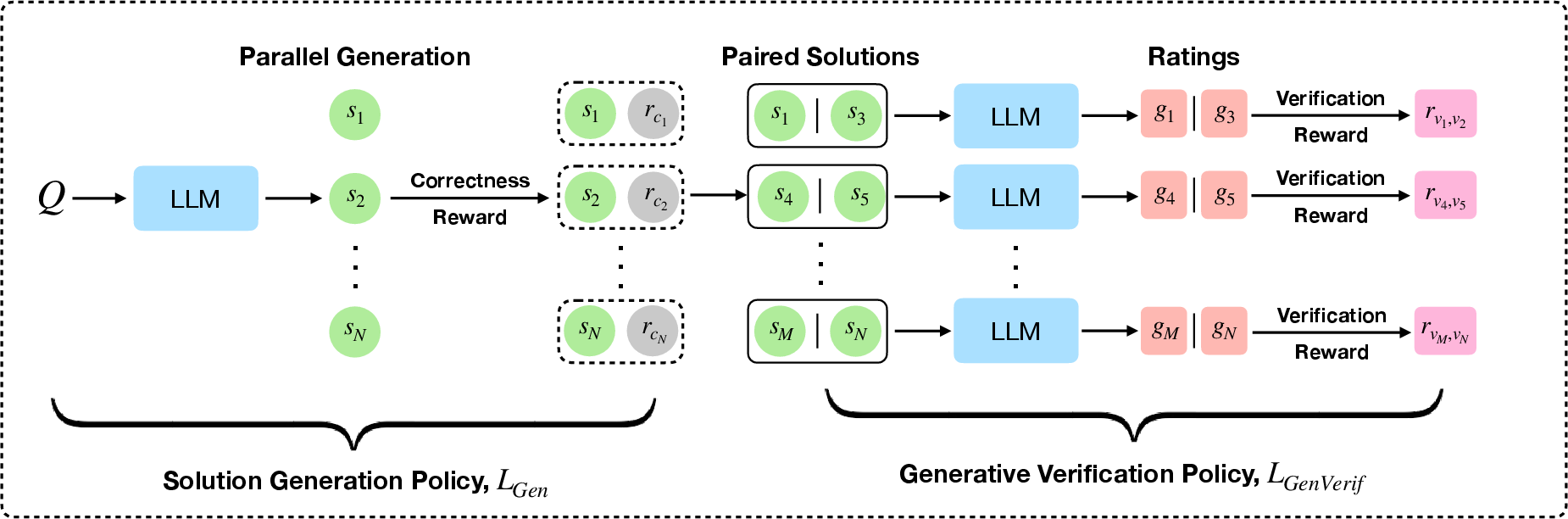
V-PairRL: Training the solver and the judge together
This is a training approach using reinforcement learning (RL):
- The AI generates multiple solutions to each problem (like several code snippets or math steps).
- It checks pairs of its solutions and learns to be a better judge by comparing them to the ground truth (for example, whether the code passes tests).
- Both the “solver” and the “judge” roles live in the same model and learn together, so the judge stays calibrated to the solver’s current abilities.
To prevent bad habits (called “reward hacking”), they:
- Reward confident and correct judgments, not “safe” middle-of-the-road scores.
- Train judging mainly on pairs that include at least one correct solution, so the model doesn’t learn to love wrong answers.
What did they find, and why does it matter?
Here are the main results from coding and math benchmarks:
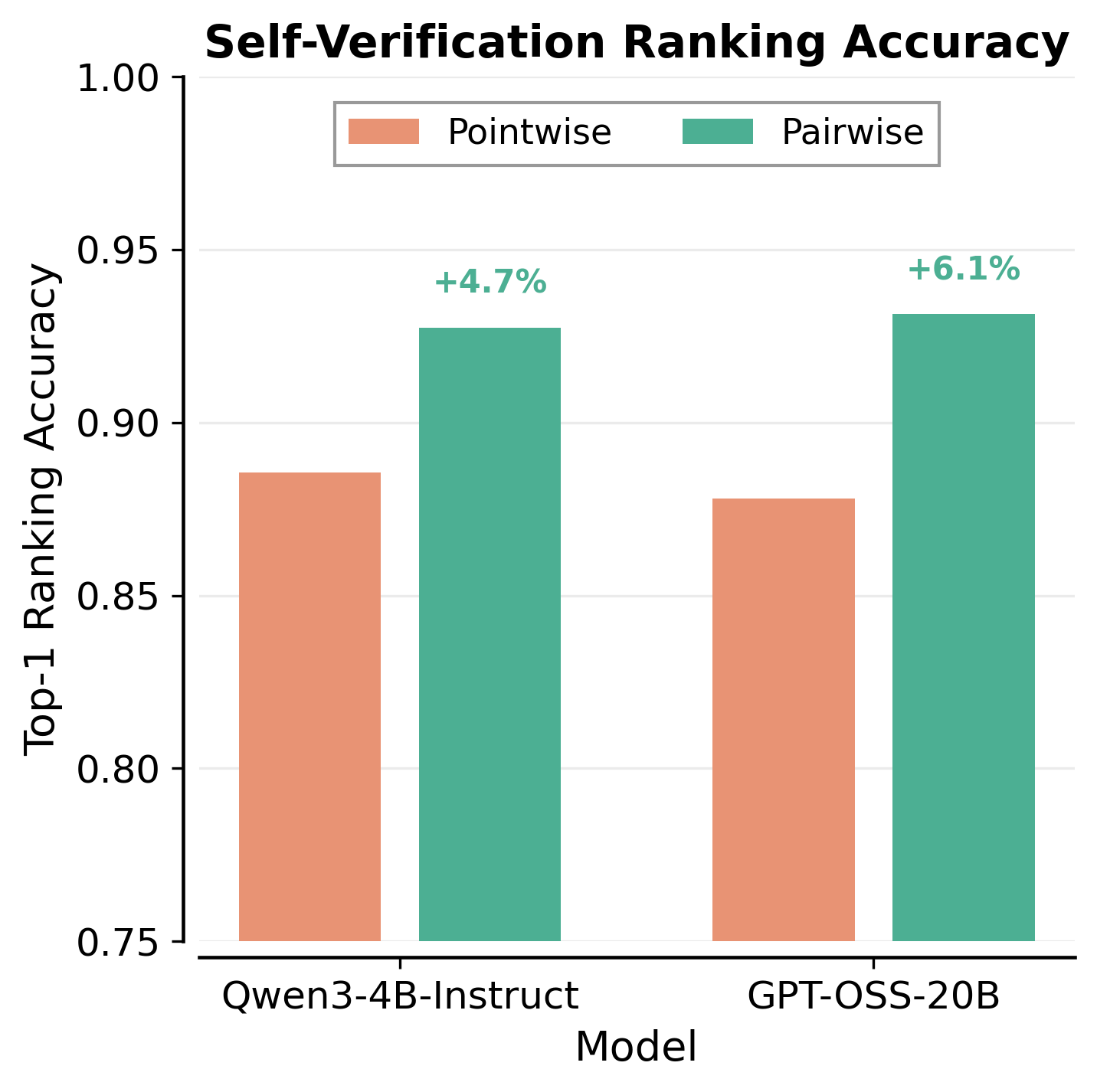
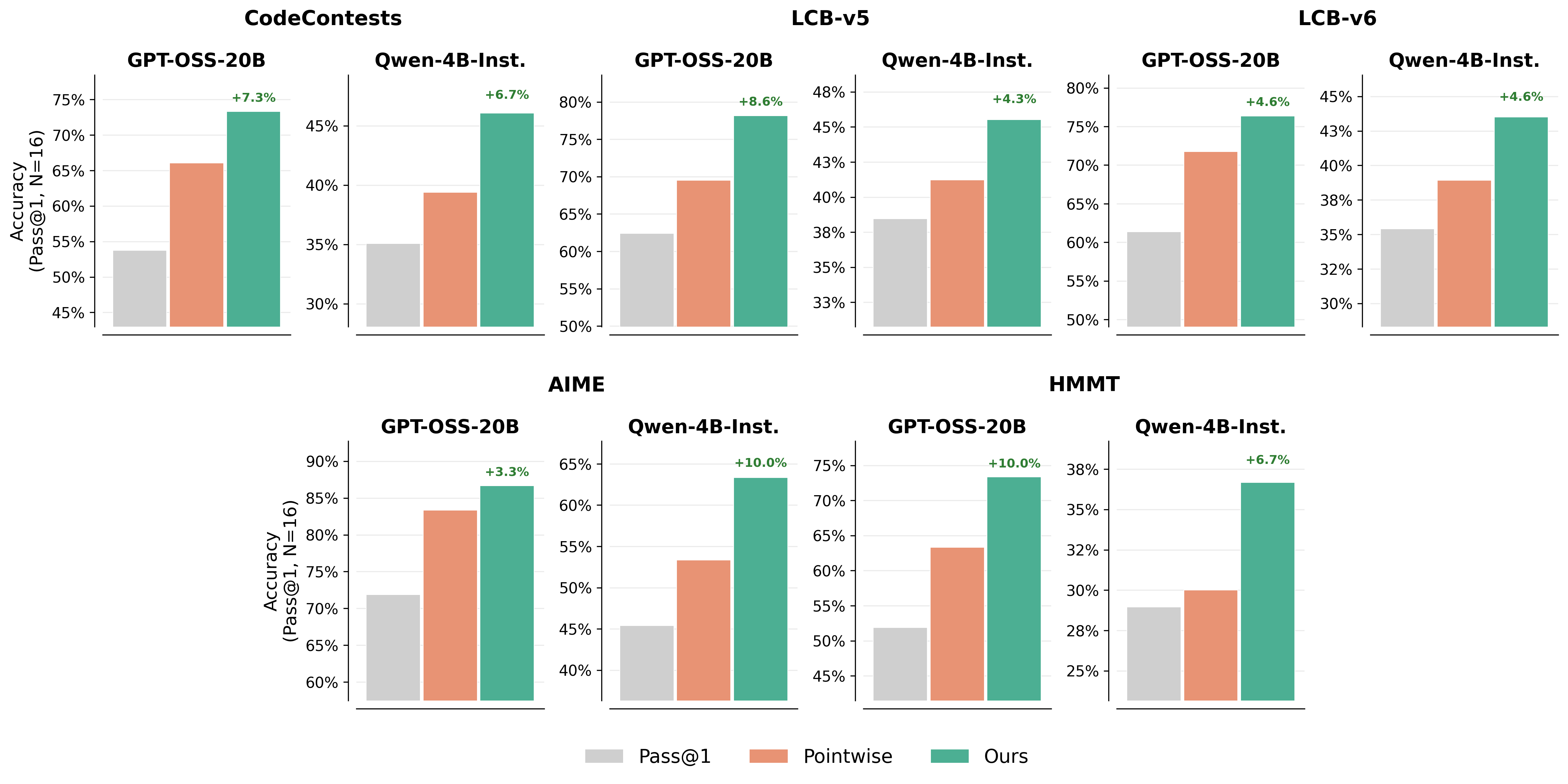
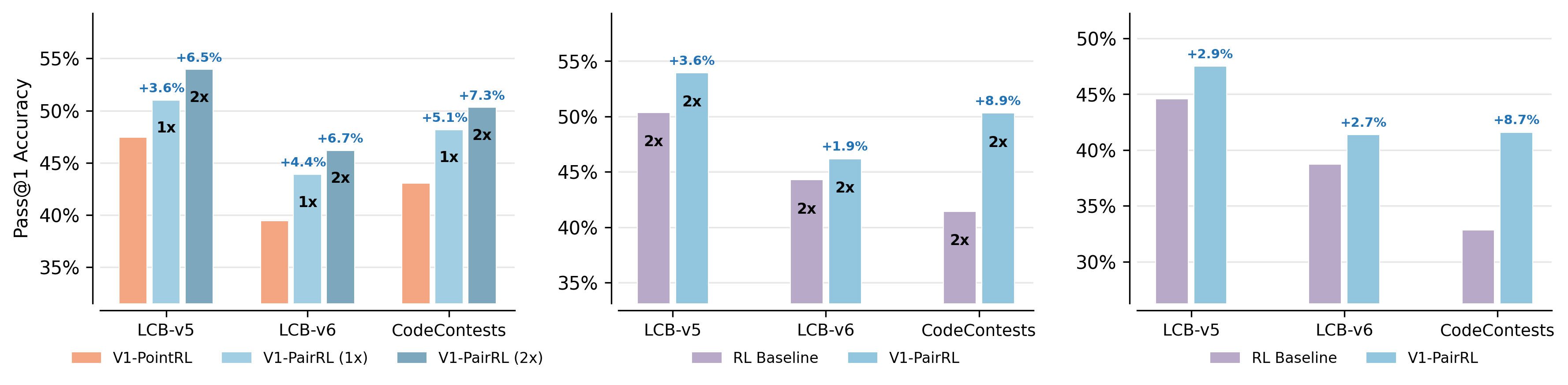
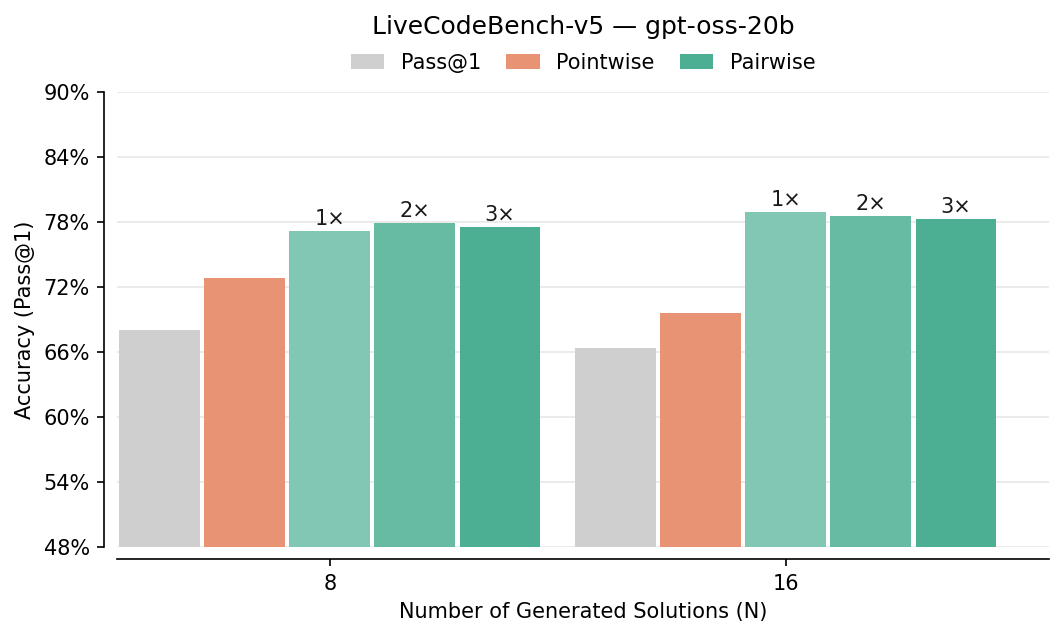
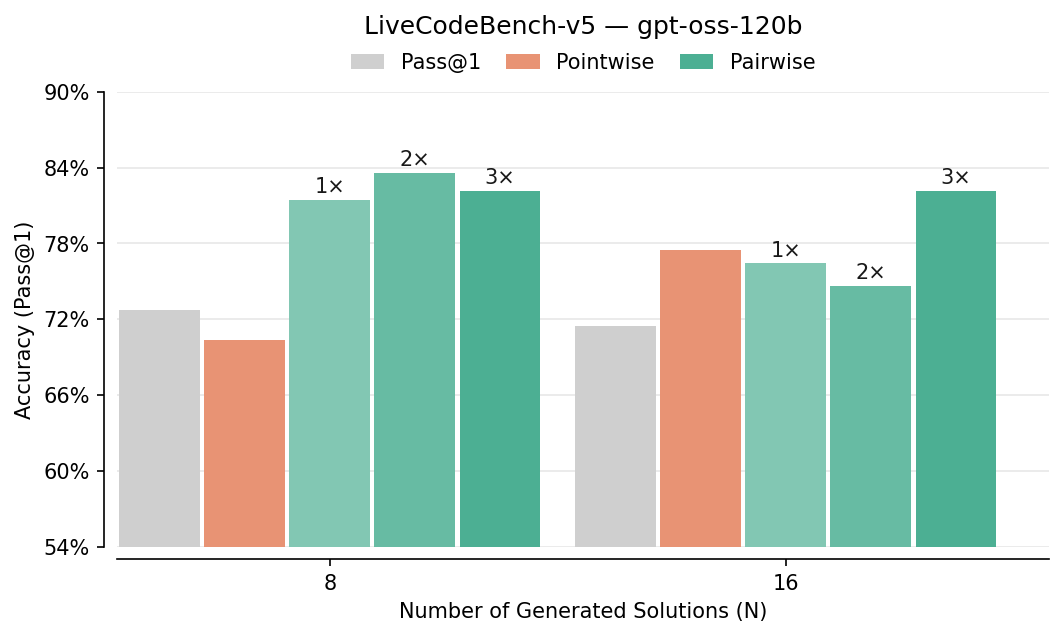
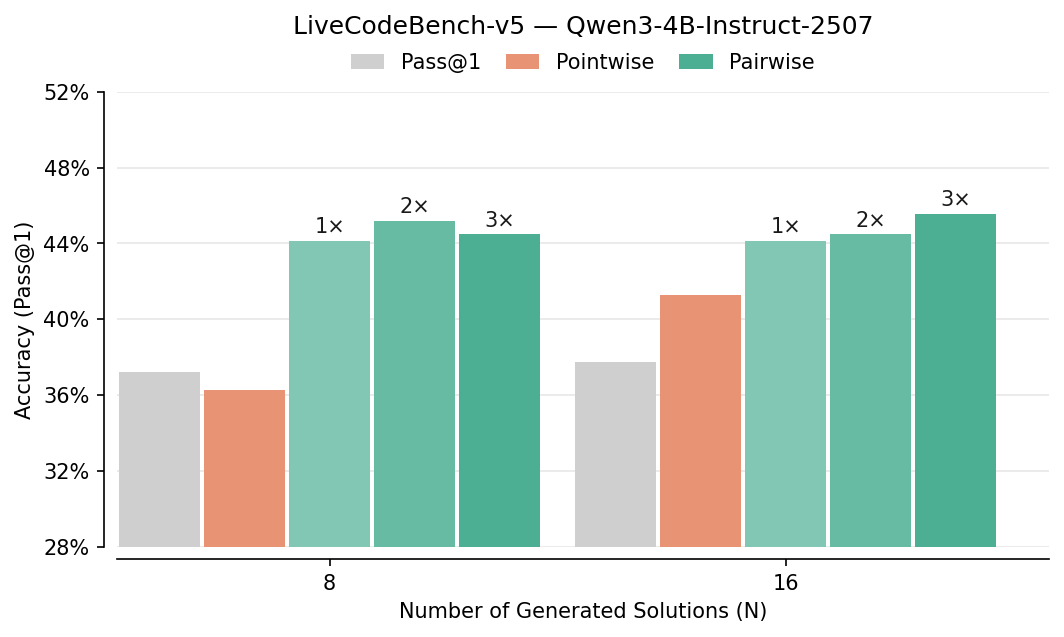
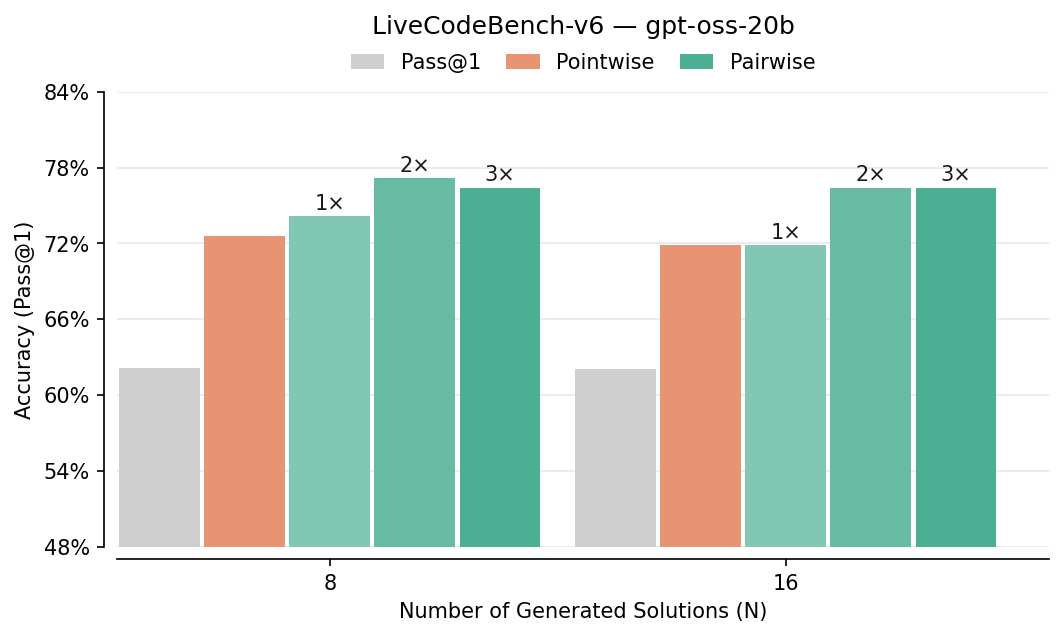
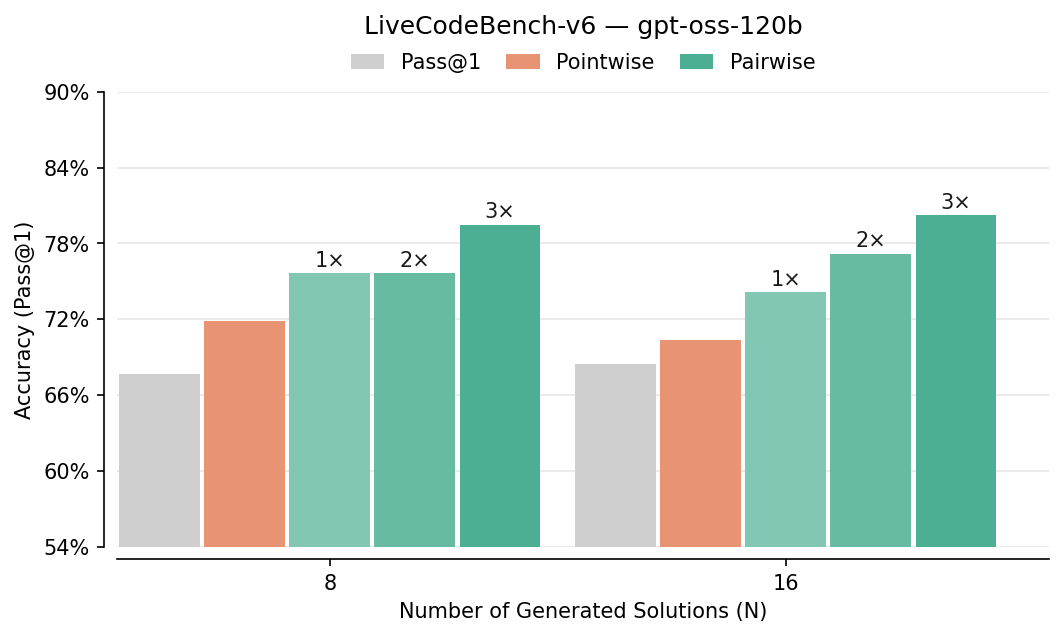
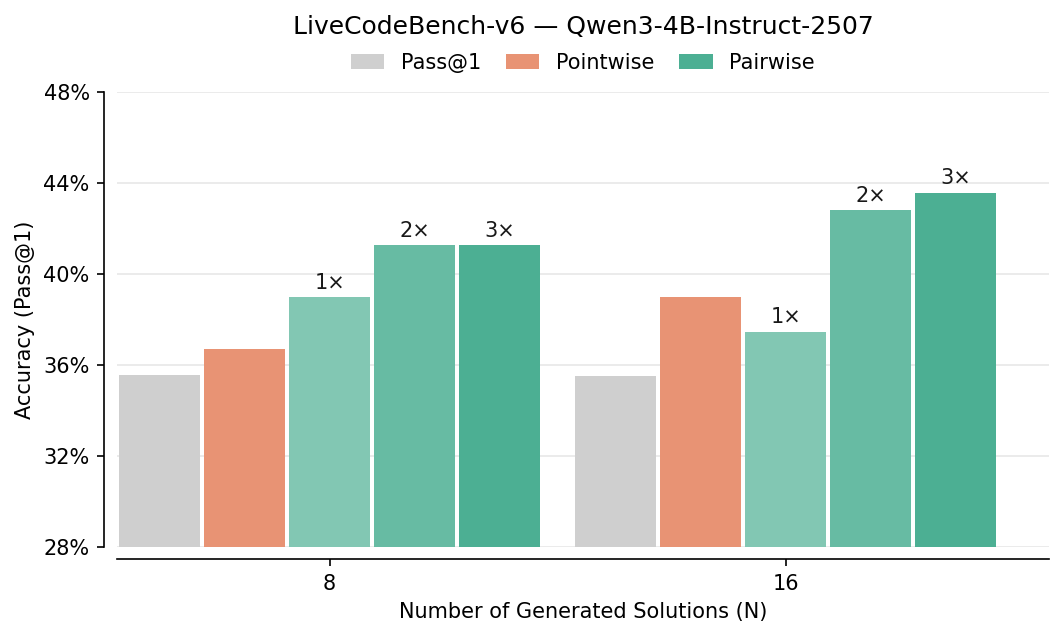
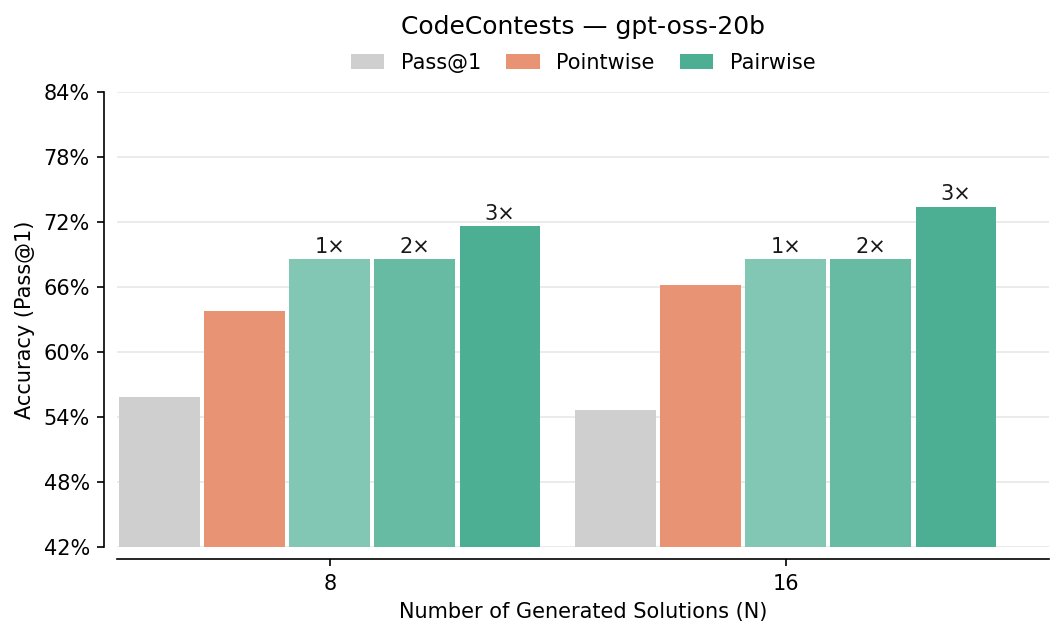
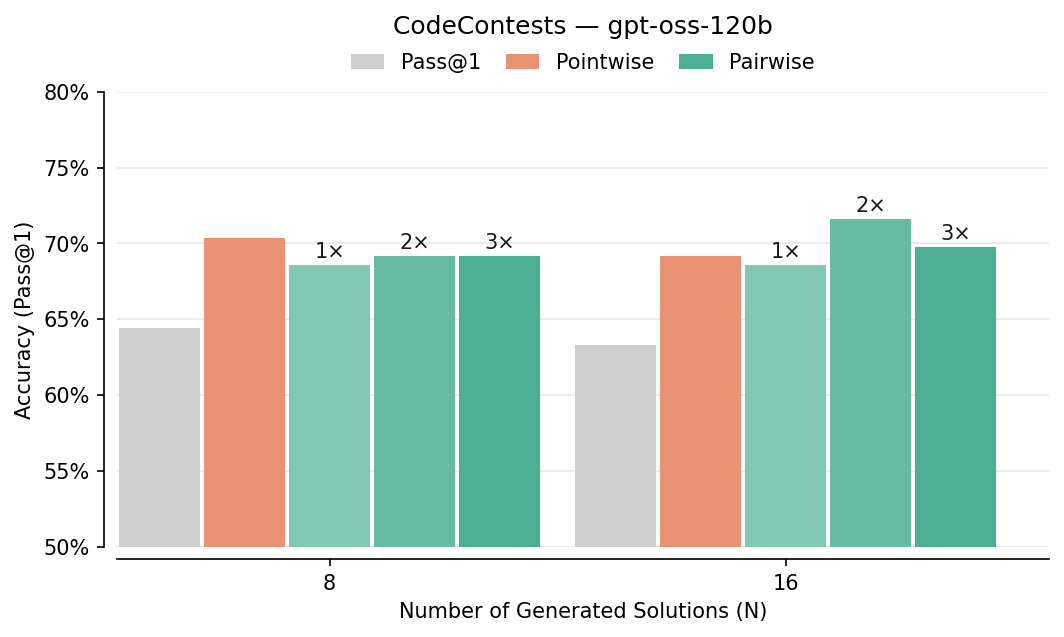
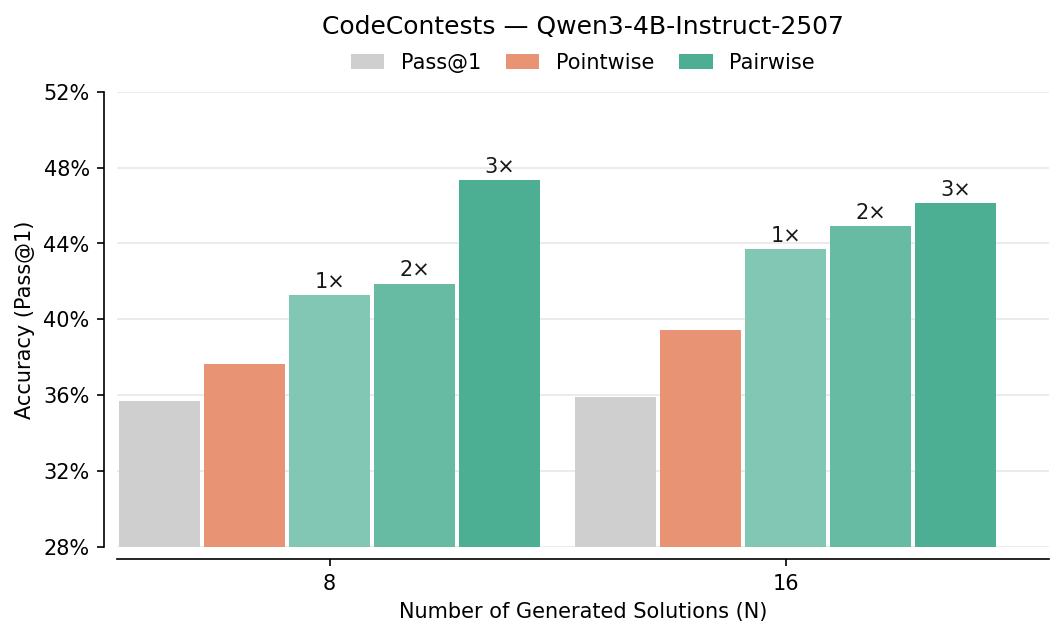
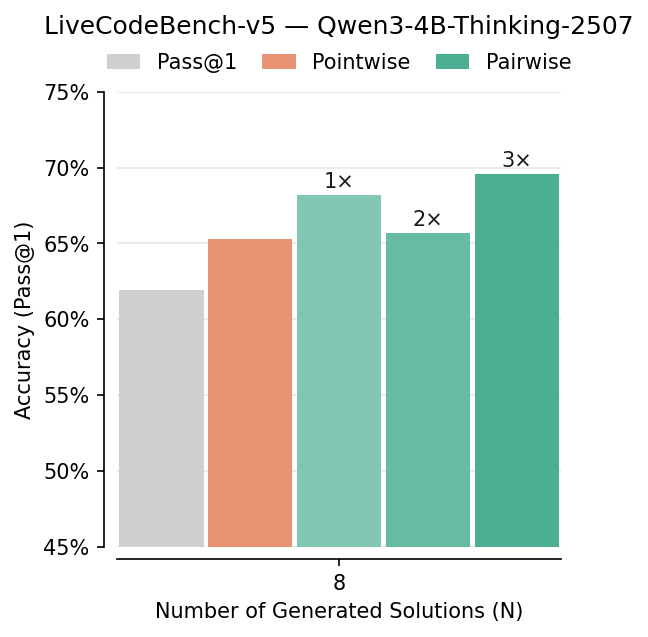
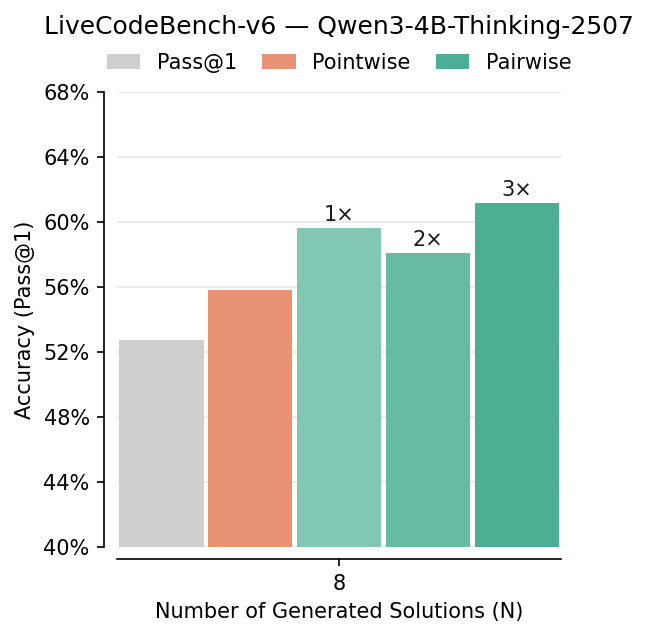
- Pairwise beats pointwise: Comparing answers head-to-head improved picking-the-best accuracy by about 7–10% in several tests (like LiveCodeBench, CodeContests, AIME, HMMT). It especially helped on hard problems.
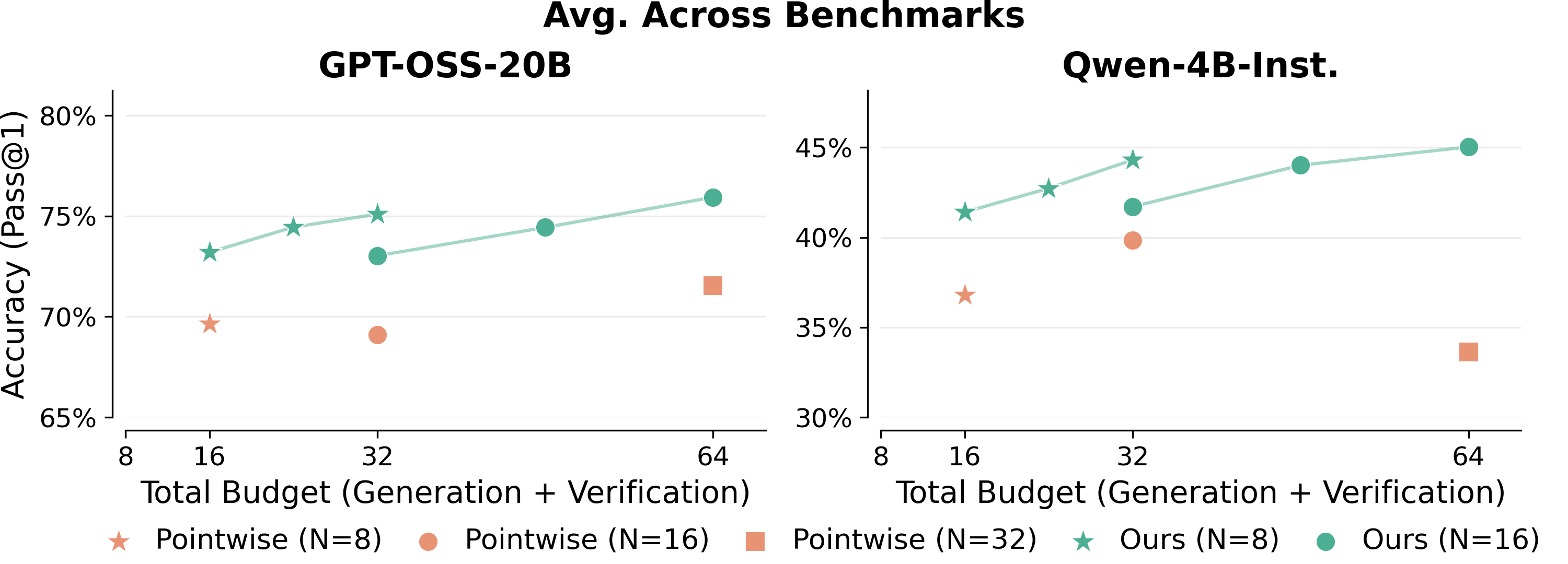
- More efficient than “self-aggregation”: Some methods merge multiple answers into one (like a summary). That can accidentally throw away good answers (“diversity collapse”). V’s pairwise ranking kept more good options alive and used fewer model calls while still improving accuracy.
- Works in real-world coding tasks: On a software bug-fixing benchmark (SWE-bench Lite), pairwise checking picked the correct fix more often (about 33.3%) than pointwise scoring (about 28.3%) or picking the first attempt (about 26.3%).
- Training the judge and solver together pays off:
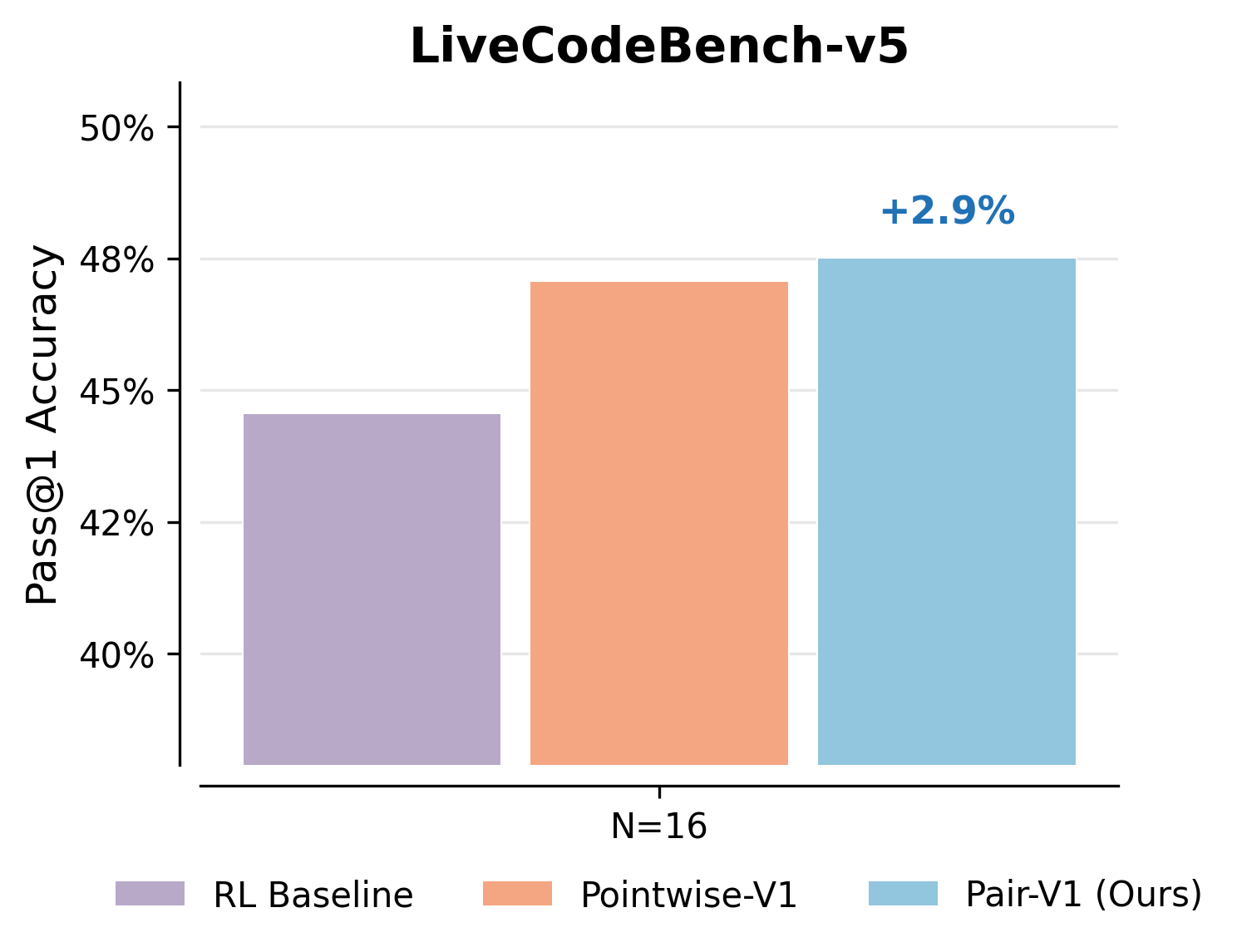
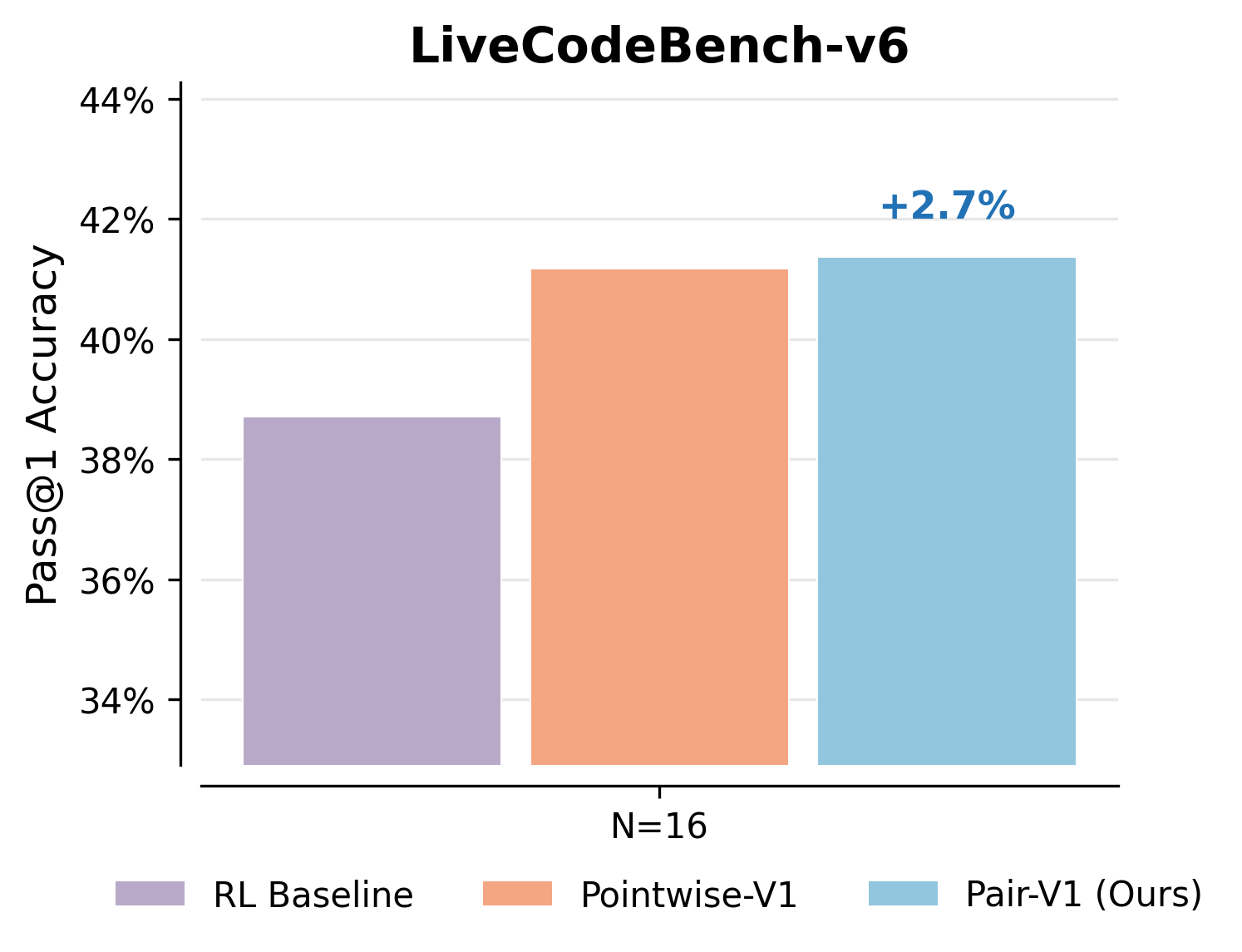
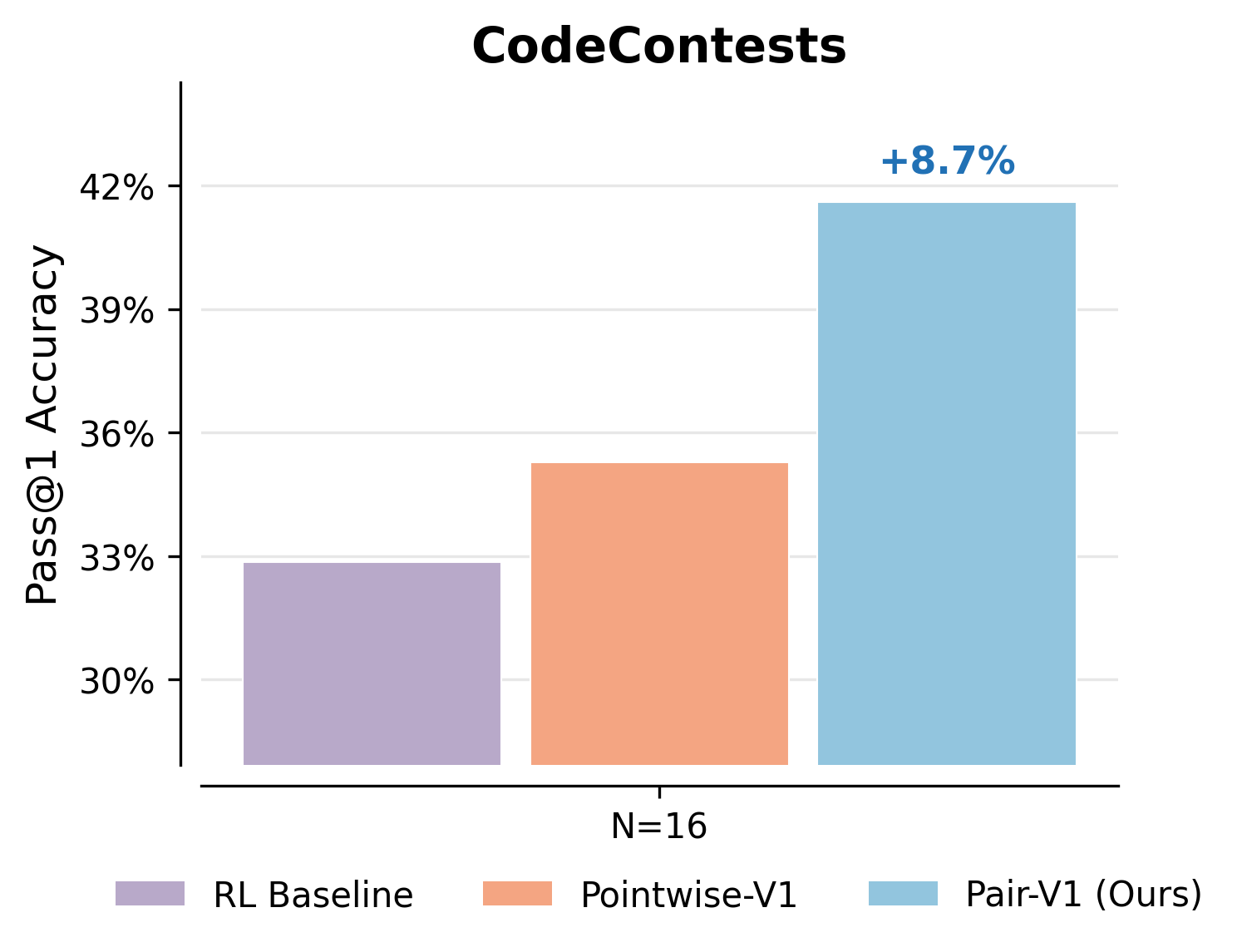
- V-PairRL (pairwise training) led to 7–9% better gains when using more checking at test time compared to standard RL or pointwise co-training.
- Even without extra checking at test time, V-PairRL improved the base accuracy (Pass@1) by up to 8.7% in code generation.
- Best on tough cases: The biggest improvements showed up on hard problems, where choosing correctly among many different answers matters most.
Why is this important?
- Smarter use of compute: Instead of just generating more answers and hoping for the best, V helps models spend time checking the most confusing cases—making better decisions with similar or less effort.
- More reliable self-checking: Pairwise judgments are naturally easier and better calibrated than rating things in isolation. This makes the AI more trustworthy without needing external graders.
- Works across tasks: The approach helps in both objective math and open-ended code tasks, including real software issues.
- Better training and inference fit: By training the solver and the judge together, the model’s checking skills stay well-matched to how it actually writes answers—leading to more consistent improvements.
- Plays nicely with other methods: Pairwise verification can be combined with existing “aggregation” strategies to guide them more effectively and avoid losing good answers.
In short, the paper shows a simple but powerful idea: when an AI creates many possible answers, comparing them in pairs—like a tournament—helps it pick the best one. And if you train the AI to do both solving and judging together, it gets even better over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in this work, organized by theme to aid future research.
Theoretical foundations and algorithm design
- No formal sample-complexity or accuracy guarantees for selecting the best-of-N using pairwise verification under realistic noise models (e.g., Bradley–Terry/Luce). Derive bounds relating verification budget
B, pairwise noise, and probability of recovering the top candidate. - Heuristic weighting scheme
w_ij = max(|r_i - r_j|/9, τ)lacks theoretical justification. Compare against principled estimators (e.g., Elo/TrueSkill, Bradley–Terry MLE, Bayesian ranking) and quantify when heuristic weighting helps or hurts. - Sensitivity analysis of Swiss refinement hyperparameters (min-degree
d_min, window sizeh, weight floorτ, initialμ_i, pairing rules) is missing. Provide systematic ablations and robust defaults across tasks/models. - Absence of an abstention mechanism: how should the verifier decide that “none of the N candidates is correct” and avoid overconfident selection? Design and evaluate calibrated reject options.
- Unclear behavior when multiple solutions are genuinely correct but differ stylistically or in algorithmic trade-offs. Study tie-handling, diversity preservation, and whether pairwise verification consistently prefers the most robust/generalizable solution.
Robustness, bias, and adversarial considerations
- Self-judging bias is asserted qualitatively but not quantified. Measure bias (e.g., favoring the generator’s own style) and test cross-model verification (generator A judged by verifier B) to disentangle style vs correctness.
- No analysis of adversarial candidates engineered to exploit verifier prompts (e.g., persuasive commentary or formatting tricks). Stress test the verifier against manipulative solutions and hard-to-judge edge cases.
- Lack of calibration metrics for pairwise scores across prompts and tasks. Introduce and report verification calibration (e.g., reliability diagrams, expected calibration error) for both pointwise and pairwise judging.
- Failure modes when all candidates are incorrect are not characterized. Quantify how often pairwise verification incorrectly elevates subtly wrong answers and propose detectors for “all-wrong” batches.
Generalization and scope
- V-Infer and V-PairRL are primarily tested on verifiable domains (code, math). It is unclear how they perform on tasks without ground-truth oracles (e.g., summarization quality, factual QA). Extend to non-verifiable settings with human preference data or proxy metrics.
- SWE-bench Lite evaluation uses patch diffs without repository context or execution feedback. Assess performance with full repo context (build, tests, runtime traces) to reflect real-world verification demands.
- RL co-training is only instantiated for code generation (Qwen3-4B-Instruct). Evaluate across model scales (e.g., 20B–120B), architectures, and domains (math RL, multi-step logical reasoning) to validate generality.
Training dynamics and reward design (V-PairRL)
- Verification rewards rely on pairs containing at least one correct solution. For hard problems with zero correct rollouts, this eliminates verifier training signal. Investigate bootstrapping strategies (e.g., synthetic positives, curriculum, cross-problem pairing) to avoid learning stalls.
- The sparsity threshold (|v_i − y_i| ≤ 0.2) is heuristic. Conduct sensitivity studies and compare against ranking losses (pairwise hinge, logistic) or proper scoring rules to reduce reward hacking while maintaining learning signal.
- Beyond the two identified collapse modes, collusion risks remain (e.g., generator emitting stylized “verifier-friendly” artifacts). Develop diagnostics and anti-collusion mechanisms (e.g., randomized masking, style-invariant judging, separate heads).
- Compute allocation between solver and verifier during co-training (e.g., 4+4 of 8 rollouts) is fixed. Explore adaptive scheduling policies conditioned on training signal (e.g., bandit allocation) and report effects on convergence and final performance.
- Training stability, variance across random seeds, and convergence characteristics are not reported. Provide multi-seed results, learning curves, and failure analyses to assess robustness.
Evaluation methodology and metrics
- No statistical significance testing or confidence intervals for reported gains. Include variance across seeds, bootstrapped CIs, and per-task significance to substantiate improvements.
- Budget-vs-accuracy comparisons do not report wall-clock latency, memory footprint, or energy cost under realistic hardware. Provide end-to-end latency and resource usage to support efficiency claims.
- Limited ablations on prompt design (both generation and verification), temperature, and sampling strategies. Quantify how prompt wording and sampling hyperparameters impact verification reliability and overall gains.
- Diversity preservation is argued but not rigorously measured beyond Pass@N trends. Introduce diversity metrics (e.g., solution edit distance, algorithmic variety, error mode diversity) and verify that pairwise selection does not inadvertently homogenize outputs.
Integration with aggregation and broader systems
- The RSA+verification hybrid is demonstrated on AIME but not comprehensively across code/math/software tasks. Systematically benchmark different schedules (when to verify vs aggregate), population sizes, and selection criteria to map the best regimes.
- Investigate whether a specialized, separate verifier (possibly larger or trained with human preferences) outperforms unified co-training, and characterize compute–accuracy trade-offs for single-model vs dual-model systems.
- Explore learning-to-verify at inference: can the verifier adaptively tune
B, choose pairs, or decide when to stop based on uncertainty estimates? Develop principled stopping rules and adaptive budget controllers.
Practical deployment considerations
- No mechanism for detecting distribution shift at inference (e.g., new domains, coding styles) or recalibrating the verifier. Study on-the-fly calibration or lightweight adaptation (e.g., few-shot updates).
- Lack of interpretability tooling for verification decisions. Provide rationales, error attribution, or counterfactual comparisons to make pairwise judgments auditable in high-stakes settings.
- Safety and alignment impacts of removing KL penalties during RL are not discussed. Evaluate whether co-training affects harmlessness, truthfulness, or undesirable behaviors and include standard alignment audits.
These gaps and questions delineate concrete directions to strengthen theoretical guarantees, broaden applicability beyond verifiable domains, harden the system against adversarial conditions, and ensure robust, efficient, and interpretable deployment.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now using the paper’s V-Infer (uncertainty-guided pairwise self-verification) and, where verifiable rewards exist, V-PairRL (co-evolving generation and pairwise verifier RL).
- Software engineering: AI patch selection in CI/CD and code review (sector: software)
- Workflow: Generate multiple candidate fixes for a bug (agentic pipeline like mini-swe-agent), apply V-Infer to head-to-head compare diffs and select the best patch without running the full repository context or tests.
- Tools/Products: “Pairwise Patch Chooser” integrated into GitHub/GitLab PR checks; IDE plugin that runs N-best suggestions and V-Infer to pick the fix.
- Benefits: +5–7% absolute gains in SWE-bench Lite; fewer model calls than aggregation methods for similar accuracy.
- Assumptions/Dependencies: Multiple candidate patches must be available; prompts for pairwise judging must be tuned to the repo’s coding standards; decisions should be audited with optional test execution or human review in high-risk repos.
- Programming assistants: Higher-accuracy code completion and refactoring (sector: software)
- Workflow: For each completion request, sample N candidate snippets; apply V-Infer Swiss refinement to rank candidates and return the top-1.
- Tools/Products: “SwissRank for Code” inference module embedded in IDE copilots; server-side reranker service.
- Benefits: +4–10% Pass@1 improvements on LiveCodeBench and CodeContests with modest compute.
- Assumptions/Dependencies: Budget for parallel sampling; domain-specific pairwise scoring prompts; optional integration with unit tests to further gate selection.
- Math tutoring and homework help: Robust answer selection from parallel CoT (sector: education)
- Workflow: Sample multiple chains-of-thought and final answers; use pairwise verification to pick the correct reasoning/answer when majority voting fails.
- Tools/Products: “Pairwise Tutor” module for math apps; exam-prep assistants using N-best sampling plus pairwise selection.
- Benefits: +6–10% gains on AIME/HMMT; preserves diversity vs. aggregation that can discard correct outliers.
- Assumptions/Dependencies: Final answers must be objectively verifiable (e.g., numerical); pairwise prompts tuned to math rubric; guardrails for partial credit and edge cases.
- Customer support and technical troubleshooting: Selecting the best resolution script or diagnostic path (sector: service operations)
- Workflow: Generate multiple response scripts or diagnostic trees; apply V-Infer to pairwise compare and select the most precise and actionable option.
- Tools/Products: “Pairwise Resolution Selector” in helpdesk platforms; internal KB authoring assistant that ranks multiple drafts.
- Benefits: Better calibration than pointwise scores; maintains diversity of candidate solutions and surfaces correct outliers.
- Assumptions/Dependencies: Responses should be evaluated against clear criteria (accuracy, steps completeness, policy compliance); may require human-in-the-loop for subjective cases.
- Research and academic writing: Ranking multiple drafts of proofs, methods sections, or abstracts (sector: academia)
- Workflow: Produce N independent drafts (e.g., proofs or methods write-ups); use pairwise verification to choose the most coherent and correct draft.
- Tools/Products: “Pairwise Draft Reranker” in scientific writing tools; hypothesis-generation assistants that select best plans.
- Benefits: Reduces score saturation seen in pointwise judging; highlights subtle correctness differences.
- Assumptions/Dependencies: Clear rubric and correctness criteria; for proofs and code, verifiable tests or checks should be available to strengthen selection.
- LLM platform optimization: Immediately improving Pass@1 with a drop-in inference module (sector: software/LLM platforms)
- Workflow: Replace or wrap pointwise LLM-as-a-judge with V-Infer Swiss refinement for N-best responses across code/math endpoints.
- Tools/Products: “V-Infer SDK” and plug-in APIs; compute-budget controller to scale comparisons adaptively.
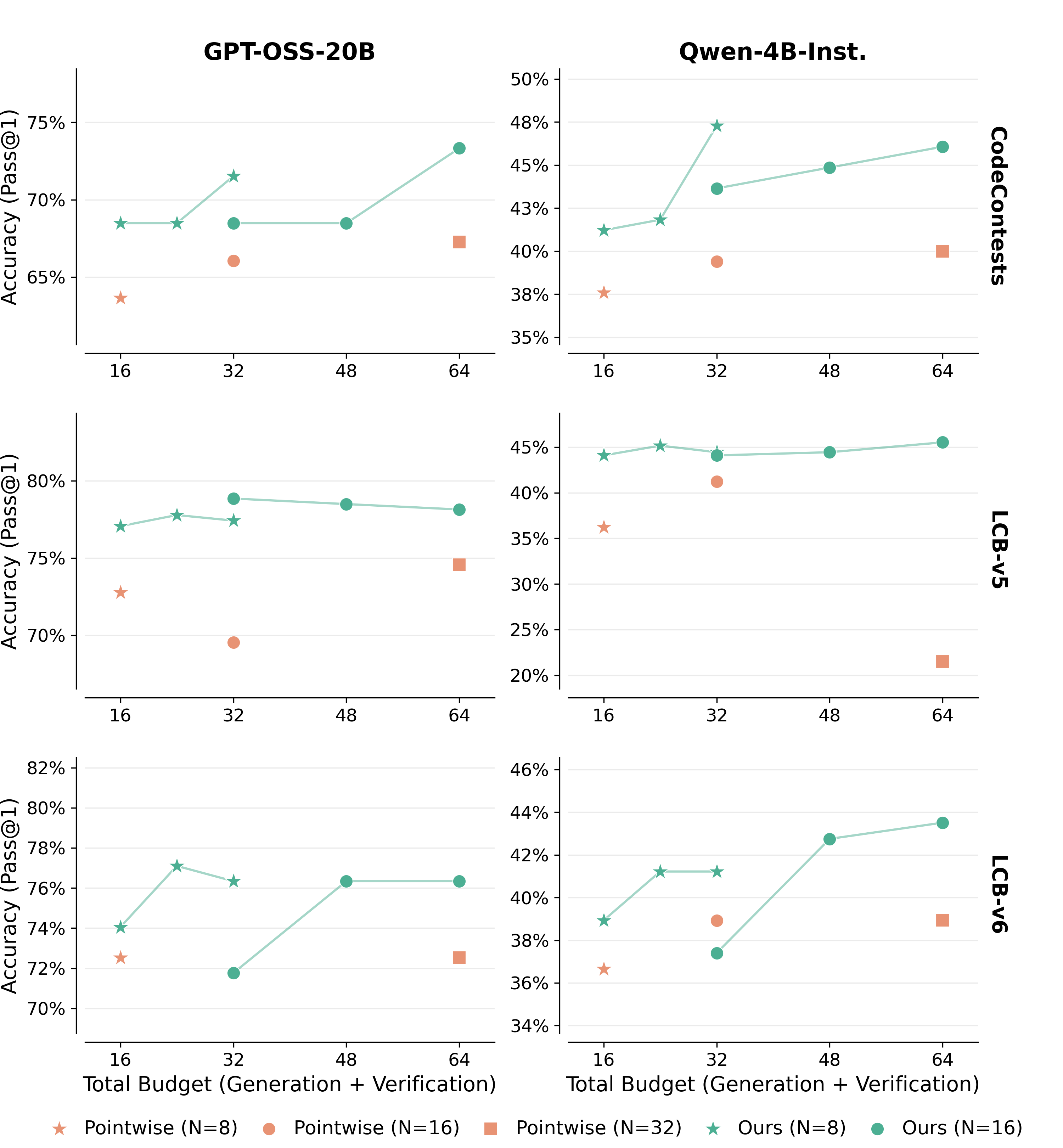
- Benefits: Better accuracy with fewer model calls than recursion/aggregation; monotonic scaling with compute; complementary to existing majority voting and test execution.
- Assumptions/Dependencies: Requires generating multiple candidates; prompts and scoring scales must be aligned with the service’s outputs.
- Data labeling and preference modeling: Pairwise judgments for internal reward models (sector: ML Ops)
- Workflow: Use V-Infer-style pairwise ranking instead of absolute scores to construct preference datasets or to calibrate internal verifiers.
- Tools/Products: “Pairwise Labeler” for RLHF/RLAIF pipelines; uncertainty-guided pairing to maximize information gain.
- Benefits: Reduces calibration issues vs. pointwise scores; yields stronger reward signals for training.
- Assumptions/Dependencies: Access to candidate pairs and consistent judging rubrics; manage bias if the generator and judge are the same model.
- Unified RL training for code models where test cases exist: Co-train solver and verifier (sector: software/ML)
- Workflow: Adopt V-PairRL in GRPO/DAPO-style training: split rollout budget between generation and pairwise verification; use correctness tests as rewards; enforce safe pairing and sparsity thresholds to prevent reward hacking.
- Tools/Products: “Solver-Verifier RL Trainer” that plugs into existing RL pipelines; DeepCoder-style recipes for verifiable domains.
- Benefits: +7–9% test-time scaling gains vs. pointwise co-training; up to +8.7% base Pass@1 improvement without test-time scaling.
- Assumptions/Dependencies: Requires verifiable rewards (e.g., unit tests) and enough correct samples for safe pairing; careful reward design to avoid collapse (e.g., sparse rewards, avoid pairing two incorrect solutions).
Long-Term Applications
These opportunities require additional research, domain adaptation, scaling, or policy and organizational development before broad deployment.
- Autonomous coding pipelines: AI PR autopilot with self-verification gates (sector: software)
- Vision: End-to-end pipeline where agents generate diverse patches, V-Infer ranks, and a combined evolutionary loop uses pairwise scores as fitness to converge faster (complementing RSA/AlphaEvolve-style search).
- Potential Products: “Autonomous PR Manager” for enterprise repos with risk-tiered gating and staged deployment.
- Dependencies: Robust sandboxed testing, static analysis, security scanning; strong guardrails for production systems; auditability and human oversight.
- Cross-domain self-verification for subjective tasks: Reliable selection in free-form writing, policy drafts, and summaries (sector: knowledge work/policy/communications)
- Vision: Pairwise self-verifiers trained to judge coherence, factuality, and compliance without ground-truth oracles, reducing hallucinations and bias.
- Potential Products: “Pairwise Compliance Rater” for policy and legal drafts; “Pairwise Summary Selector” for enterprise reporting.
- Dependencies: Domain-specific rubrics; external fact-checking or retrieval to anchor judgments; careful bias and fairness audits; possibly multi-model judging to reduce self-bias.
- Robotics and planning: Parallel plan generation and pairwise selection for robust decision-making (sector: robotics)
- Vision: Agents generate multiple plans; pairwise verification selects safer/more reliable plans; evolves verifier and planner together with V-PairRL-like training using simulators.
- Potential Products: “Pairwise Planner” in simulation-to-real pipelines; safety-focused plan selectors.
- Dependencies: High-fidelity simulators for verifiable rewards; safety certification; sample efficiency improvements to manage compute costs.
- Healthcare decision support: Pairwise selection of treatment rationales and orders (sector: healthcare)
- Vision: Generate multiple care pathways; pairwise verifier ranks candidates by guideline adherence and risk; human clinicians approve final plan.
- Potential Products: “Pairwise Clinical Rationale Selector” integrated into EHR systems.
- Dependencies: Strict clinical validation, regulatory approval, medical liability frameworks; integration with evidence retrieval and guideline engines; human-in-the-loop mandatory.
- Finance and risk modeling: Selecting trading strategies or risk analyses from parallel candidates (sector: finance)
- Vision: Use pairwise verification to rank strategies or scenarios by risk-adjusted performance; co-train verifier with simulated rewards.
- Potential Products: “Pairwise Strategy Rater” connected to backtesting engines.
- Dependencies: Reliable simulation environments and out-of-sample validation; regulatory compliance; robust adversarial testing to avoid gaming.
- Standardization and policy: Certification for self-verifying AI systems (sector: policy/regulation)
- Vision: Establish standards that require calibrated pairwise verification and diversity-preserving selection in high-stakes AI systems.
- Potential Products: Conformance tests and metrics (pairwise ranking accuracy, diversity retention vs. Pass@N); audit tools for reward hacking detection.
- Dependencies: Multistakeholder consensus, public benchmarks across domains, and transparency requirements for model prompts, budgets, and selection rules.
- Multi-model and cross-ensemble verification: Tournament-style ranking across heterogeneous models (sector: AI platforms)
- Vision: Use Swiss refinement on candidates pooled from multiple models; the verifier may be a distinct or ensemble judge to reduce single-model bias.
- Potential Products: “Ensemble SwissRank” API; inter-model arbitration layer.
- Dependencies: Cost-effective orchestration; de-biasing techniques; robust logging for accountability; shared scoring scales.
- Education at scale: Automated pairwise grading and feedback (sector: education)
- Vision: Generate multiple solution attempts per student or per assignment; pairwise verification helps grade, identify misconceptions, and assemble targeted feedback.
- Potential Products: “Pairwise Grader” and “Feedback Composer” for MOOCs and LMS platforms.
- Dependencies: Alignment to curricula and grading rubrics; fairness and transparency; data privacy and consent; human review for edge cases.
- Compute-aware inference schedulers: Dynamic pairing to minimize cost while maximizing accuracy (sector: ML systems/infra)
- Vision: Runtime controllers that allocate verification calls to the most uncertain pairs, balancing latency and accuracy SLAs.
- Potential Products: “Uncertainty-Aware Inference Scheduler” in model serving stacks.
- Dependencies: Accurate uncertainty estimates and telemetry; adaptive thresholds; compatibility with existing autoscaling and caching strategies.
Cross-cutting assumptions and dependencies
- The method presumes access to multiple independently sampled candidate solutions (parallel reasoning) and an LLM capable of calibrated pairwise scoring with a consistent scale (e.g., 1–10).
- V-PairRL requires verifiable rewards during training (e.g., unit tests for code) and careful reward design (sparsity thresholds, avoiding pairs of two incorrect solutions) to prevent reward hacking and generator collapse.
- Prompts and evaluation rubrics must be adapted to each domain; for subjective domains, external grounding (retrieval, fact-checking) and human supervision improve reliability.
- Compute budgets and latency constraints influence feasibility; V-Infer’s Swiss refinement should be tuned (window size, min-degree) to the target SLA.
- Organizational policies, audit requirements, and privacy constraints may necessitate logging, reproducibility of selection decisions, and human-in-the-loop oversight in high-stakes contexts.
Glossary
- AIME: A competitive math benchmark used to evaluate mathematical reasoning of models. "On code generation (LiveCodeBench, CodeContests, SWE-Bench) and math reasoning (AIME, HMMT) benchmarks,"
- advantage: In policy gradients, a baseline-adjusted reward signal that reduces variance and guides updates. "where is the advantage computed over the group"
- Bradley–Terry: A probabilistic model for pairwise comparisons that assigns latent skill parameters to items. "Statistically, latent utilities in choice models (e.g., Bradley--Terry) are identifiable only up to monotonic transformations,"
- calibration collapse: A failure mode where absolute scores become incomparable across contexts, harming ranking. "Pointwise self-verification suffers from calibration collapse."
- Chain-of-Thought (CoT): An approach where models generate intermediate reasoning steps before answers. "Early work demonstrated that LLMs can verify their own Chain-of-Thought (CoT) reasoning"
- CodeContests: A programming benchmark of competitive programming problems for code generation evaluation. "For code generation, we use LiveCodeBench-v5 (279 problems between date range of 24.08 to 25.02), LiveCodeBench-v6 (131 problems between 25.02-25.05 following official Qwen3-2507 models..., and CodeContests (165 problems)"
- DAPO: A configuration for RL training of LLMs emphasizing stability and performance. "We adopt the DAPO configuration, removing the KL penalty, using Clip High, and applying token-level loss,"
- DeepCoder: A training recipe/dataset for verifiable code-generation RL with executable tests. "we instantiate experiments on RL for code-generation following DeepCoder \citep{deepcoder2025}."
- diversity collapse: The loss of solution variety during aggregation that can discard correct outliers. "Self-aggregation leads to reduction in pass@N and diversity collapse."
- Dr. GRPO: A training modification of GRPO that removes certain normalization for stability. "and follow Dr. GRPO~\citep{liu2025understandingr1zerotraining} by removing standard deviation normalization."
- GRPO (Group-Relative Policy Optimization): A policy-gradient RL method that normalizes rewards within groups of rollouts. "Group-Relative Policy Optimization (GRPO) \cite{deepseekai2025deepseekr1incentivizingreasoningcapability} and its variants \cite{yu2025dapoopensourcellmreinforcement} have shown significant promise and stable optimization dynamics."
- HMMT: A math benchmark (Harvard-MIT Math Tournament) used to assess reasoning ability. "On HMMT, GPT-OSS-20B gains +10.0\% and Qwen3-4B-Instruct gains +6.7\%."
- importance sampling ratio: The likelihood ratio used to reweight gradients when optimizing off-policy. "where is the advantage computed over the group and $\rho_{i,t} = \pi_\theta(o_{i,t} | q, o_{i,<t}) / \pi_{\text{old}(o_{i,t} | q, o_{i,<t})$ is the importance sampling ratio."
- in-distribution: Data drawn from the same distribution as the model’s current outputs, avoiding mismatch. "This ensures that as the generator improves, the verifier trains on in-distribution data from the model's current capabilities"
- KL penalty: A regularization term that constrains policy updates by penalizing divergence from a reference policy. "removing the KL penalty"
- LLM-as-a-judge: Using an LLM to evaluate or score outputs, often as a verifier. "Our goal is to measure the efficacy of compared to standard LLM-as-a-judge (pointwise) verification for parallel reasoners,"
- LiveCodeBench: A benchmark suite of real-world coding problems for evaluating code generation. "For code generation, we use LiveCodeBench-v5 (279 problems between date range of 24.08 to 25.02), LiveCodeBench-v6 (131 problems between 25.02-25.05..."
- majority voting: Selecting the final answer as the most frequent among sampled candidates. "The simplest form of aggregation is to select the most common solution among the set of candidates (majority voting)."
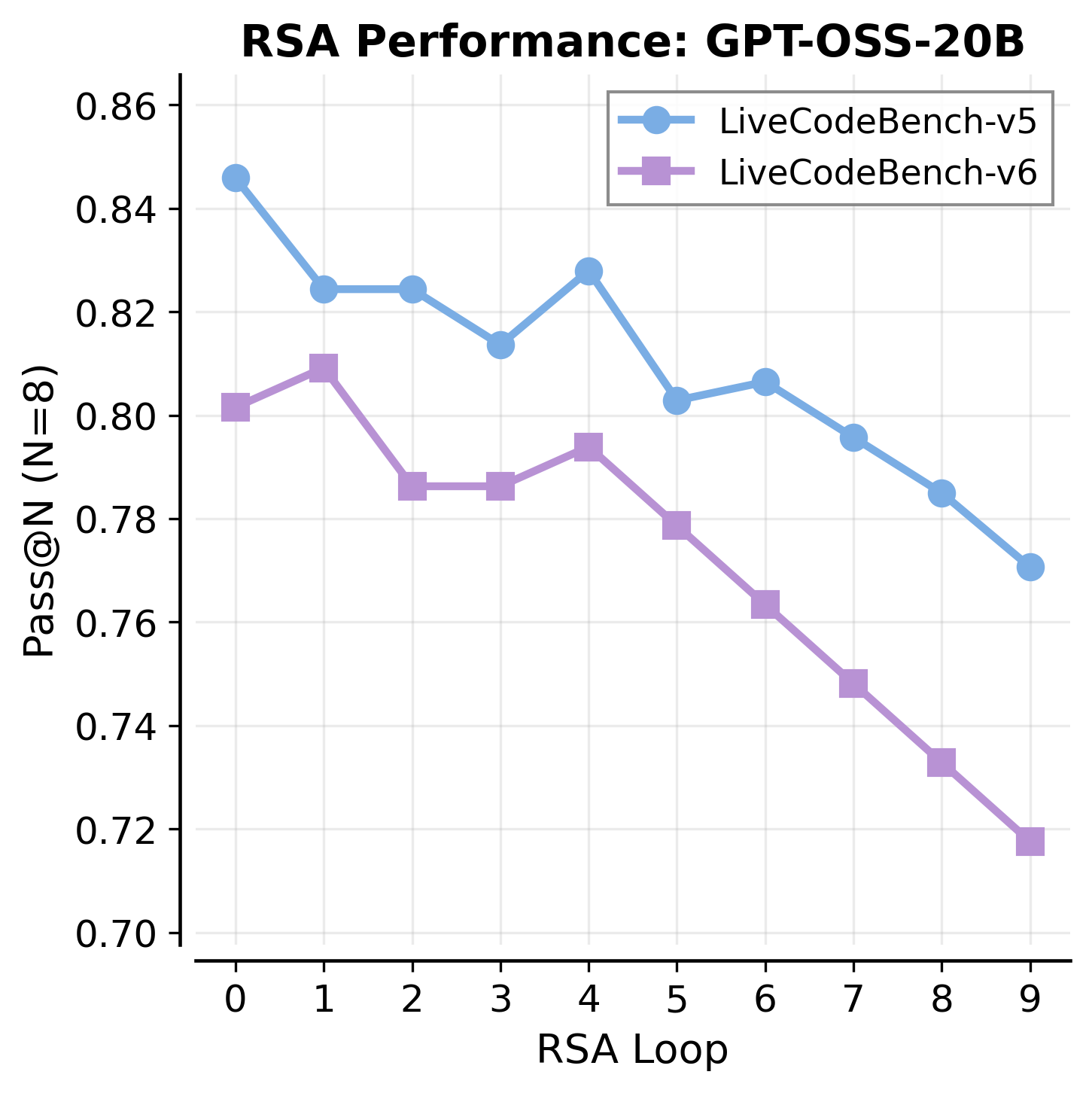
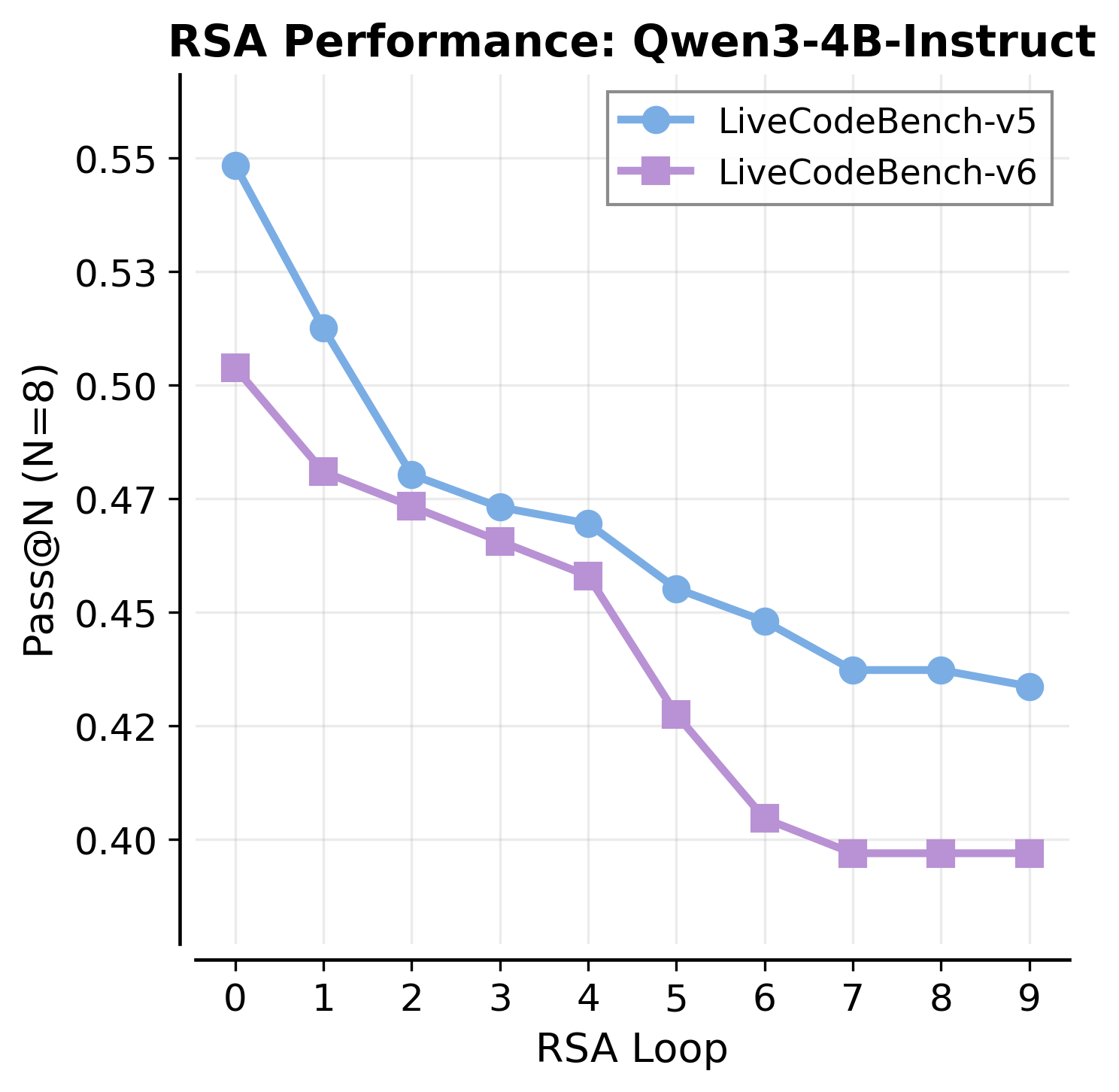
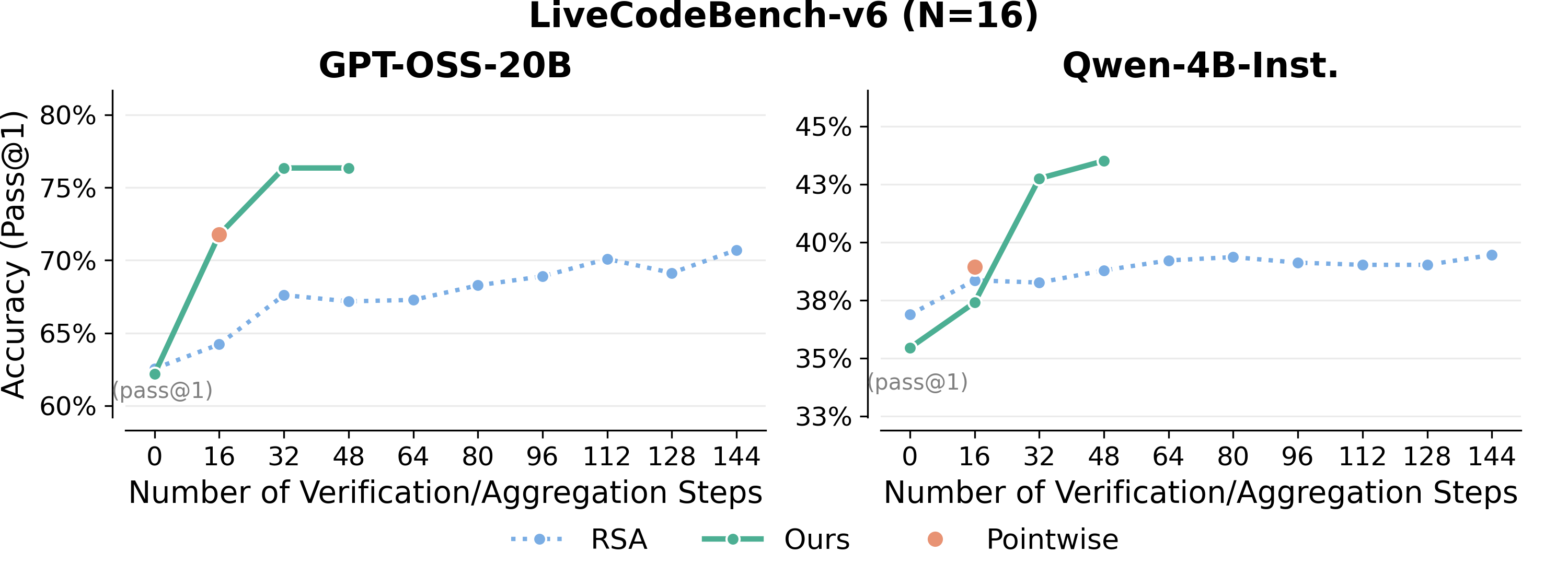
- Pass@N: The probability that at least one of N generated solutions is correct. "the Pass@N score, representing the probability that at least one correct solution exists in a set of generated N solutions, monotonically decreases as aggregation steps increase for RSA."
- policy gradient methods: A class of RL algorithms optimizing expected reward via gradient ascent on policy parameters. "This is commonly done with policy gradient methods."
- pointwise self-verification: Scoring each candidate solution independently rather than via comparisons. "Pairwise self-verification (using , \S\ref{sec:swiss_pairwise_verification}) outperforms pointwise self-verification"
- REINFORCE: A basic policy gradient estimator using sampled returns without importance clipping. "The advantage for verification rollouts reduces to a REINFORCE-style estimator with a mean baseline calculated across prompts."
- Recursive Self-Aggregation (RSA): An iterative method that refines solutions by aggregating subsets across steps. "Comparison with Recursive Self-Aggregation (RSA) \citep{venkatraman2025recursiveselfaggregationunlocksdeep} on LCB-v6."
- reward hacking: Learning to exploit the reward signal without genuinely improving the intended capability. "naive implementations suffer from reward hacking"
- RLVR: Reinforcement learning with verifiable rewards (e.g., test-case execution for code). "We instantiate V on RLVR for code generation following the DeepCoder recipe"
- self-aggregation: Combining multiple model-generated solutions into a single refined output. "Self-aggregation-based methods prompt the same LLM to consolidate parallelly generated solutions into one solution."
- self-verification: A model’s ability to evaluate the correctness/quality of its own generated solutions. "parallel reasoning fundamentally hinges on accurate self-verification"
- Swiss-system tournament: A pairing scheme that matches items of similar scores to maximize informative comparisons. "employing a Swiss-system tournament refinement strategy that dynamically allocates self-verification compute to the most uncertain pairs."
- test-time scaling: Increasing compute or procedures at inference to boost performance (e.g., sampling multiple solutions). "Parallel reasoning... has emerged as a powerful technique for test-time scaling"
- uncertainty-guided: Steering computation based on estimated uncertainty to focus on informative cases. "V-Infer, an uncertainty-guided algorithm using a tournament-based ranking"
- verification budget: The number of allowed verification/evaluation calls during selection. "Verification Budget. allows flexible control over the verification budget."
- V-Infer: The paper’s uncertainty-guided pairwise verification algorithm for selecting among candidates. "V comprises two components: V-Infer, an uncertainty-guided algorithm using a tournament-based ranking"
- V-PairRL: A unified RL framework co-training a single model for generation and pairwise self-verification. "V-PairRL, an RL framework that jointly trains a single model as both generator and pairwise self-verifier,"
Collections
Sign up for free to add this paper to one or more collections.

