- The paper demonstrates that flow-matching critics significantly improve TD learning by leveraging iterative integration and test-time recovery.
- It shows that dense velocity supervision preserves feature plasticity, effectively mitigating common issues like feature collapse under high update rates.
- Empirical results reveal up to 2× higher final performance and 5× better sample efficiency compared to traditional monolithic critics.
Flow Matching and Temporal Difference Learning: An Analysis
Introduction
The paper "What Does Flow Matching Bring To TD Learning?" (2603.04333) provides an in-depth empirical and theoretical examination of flow-matching Q-function parameterizations ("flow-matching critics") in reinforcement learning (RL), with a particular focus on their behavior under temporal difference (TD) learning. The central argument is that the successes of flow-matching critics are not explained by distributional RL, but rather by two mechanisms unique to the flow-matching architecture: test-time recovery (TTR) through iterative integration, and enhanced representational plasticity in the critic network. Throughout, the authors provide formalizations and controlled studies to identify the precise mechanisms driving these improvements, establishing clear distinctions from conventional monolithic critics.
Distributional RL vs. Flow-Matching: Disentangling the Source of Gains
Contrary to the dominant narrative in prior work—that flow-matching critics succeed by modeling return distributions in an analogous fashion to distributional RL—the paper presents direct empirical evidence that explicit distributional objectives not only fail to confer benefit, but often harm performance when compared to expected-value supervision. The authors show that flow-matching critics trained only for the expected return ("floq") outperform strong distributional RL baselines and their own distributional variants under identical architectures and hyperparameters, as does direct expected-value supervision with flow-matching. Thus, the empirical gains of flow-matching critics are independent of modeling return distributions, contradicting the explanatory framework adopted in prior diffusion-based value RL literature.
Iterative Computation and Test-Time Recovery
The authors posit that the key contribution of flow-matching critics lies in their parameterization: they represent Q-functions via integration of a learned velocity field, with value estimation achieved by numerically integrating over multiple steps. Crucially, dense supervision on the velocity at every interpolant along the integration trajectory imbues the model with both the capacity and explicit training to refine predictions iteratively.
The mechanism of test-time recovery is formalized as a contraction property: as the number of integration steps increases, the influence of errors introduced at intermediate steps is damped, allowing the critic to recover from estimation errors that arise during inference. Monolithic critics, lacking this iterative structure and supervision, are inherently brittle under analogous perturbations.
Feature Plasticity under Nonstationarity
A core challenge in TD learning with neural critics is the loss of feature plasticity under nonstationary TD targets: critics must repeatedly modify their features to track shifting targets, often culminating in rank collapse, norm explosion, and overfitting. The integration and dense supervision architecture of flow-matching critics buffers these changes: rather than requiring features to be rewritten for each new TD target, the updates are absorbed through changes in the integration trajectory, preserving useful feature subspaces.
This leads to the strong empirical result that freezing all layers except the final two in a flow-matching critic causes minimal performance loss, while the same intervention in a monolithic critic results in a catastrophic collapse (Figure 1).
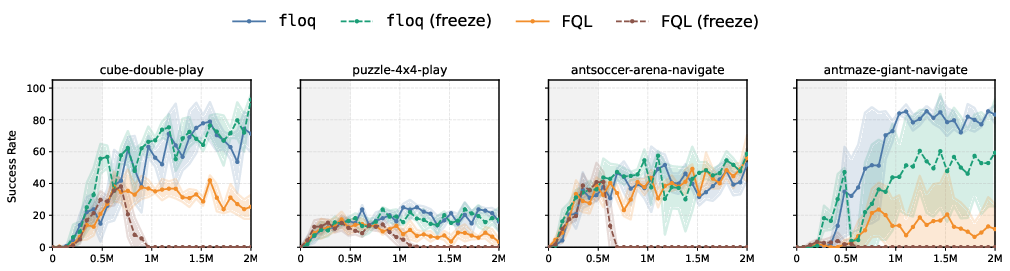
Figure 1: Feature plasticity is preserved in flow-matching critics; freezing features results in a collapse for monolithic critics but not for flow-matching critics.
Further quantitative evidence is provided by tracking feature norm dynamics. Flow-matching critics exhibit a marked decrease in penultimate hidden layer norms decoupled from Q-value scale, while monolithic critics' norms track Q-value scale, indicating overcommitment of internal features (Figure 2).
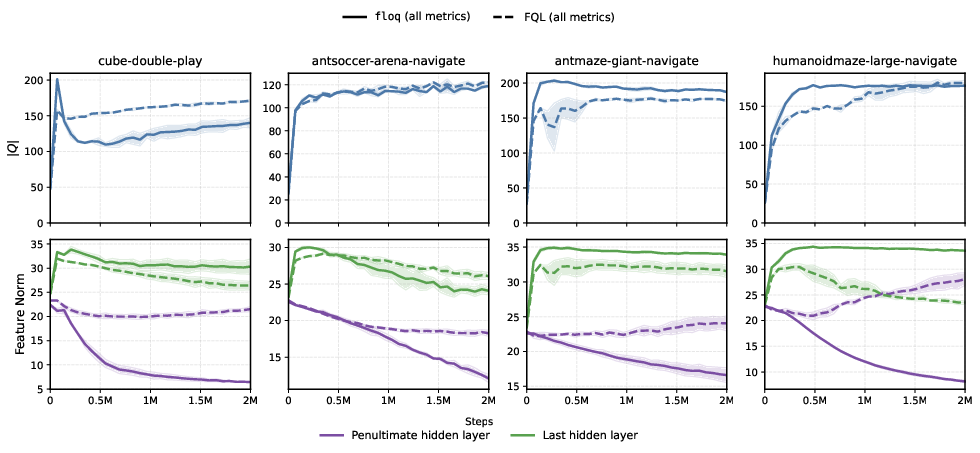
Figure 2: Flow-matching critics develop adaptive representations that are decoupled from the Q-value scale in intermediate layers, unlike monolithic critics.
When the same architecture is trained with SARSA or supervised Monte Carlo regression (stationary targets), these differences vanish, isolating the effect to TD learning under nonstationarity (Figure 3).
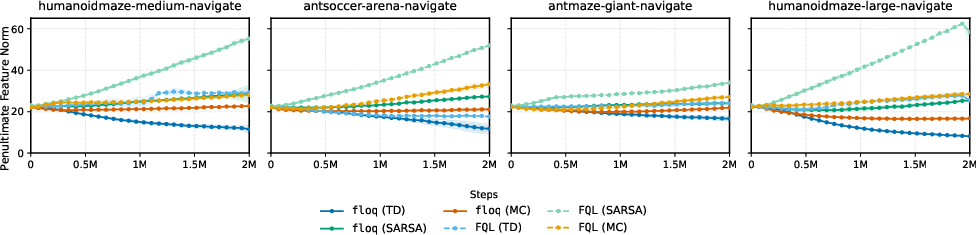
Figure 3: Only TD-trained flow-matching critics show marked feature norm decay; this is not seen for SARSA or MC training.
Empirical Analysis of Stability, Robustness, and Representation
A variety of controlled experiments establish the robustness and plasticity advantages of flow-matching critics:
- Test-time interventions (e.g., performing a portion of integration steps with a stale or perturbed velocity field) show that flow-matching critics remain stable and can recover performance, whereas monolithic critics cannot.
- Noisy target experiments demonstrate that flow-matching critics degrade more gracefully when TD targets are corrupted.
- Dense velocity field supervision, as opposed to absolute target supervision at each integration step, is critical; omitting this results in architectures that regress to monolithic behaviors, collapsing the plasticity and stability benefits.
Additionally, the critical role of having multiple (not just one) integration steps is highlighted: full flow-matching provides a clear benefit over one-step integration, which is only partially stable (Figure 4).

Figure 4: Multiple integration steps amplify stability and plasticity in flow-matching critics compared to single-step or monolithic variants.
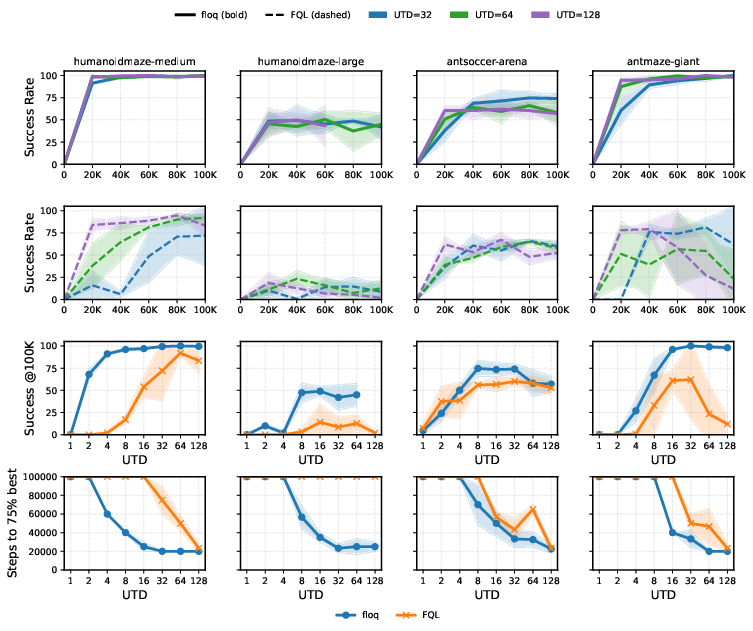
The architecture's practical value is established in challenging high UTD regimes, where monolithic critics typically deteriorate. When substituted for the conventional critic in the RLPD framework, flow-matching critics demonstrate:
Performance profiles across all tested UTD ratios further support that the benefits of flow-matching are robust to hyperparameters and persist across tasks (Figure 6).
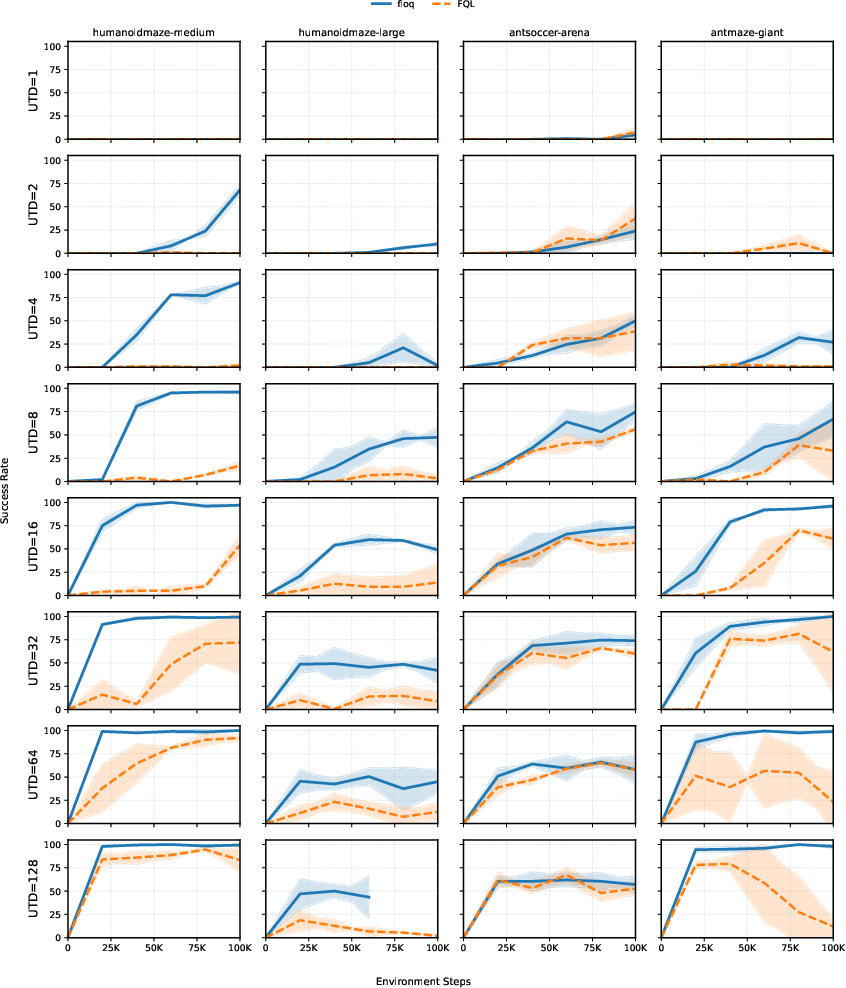
Figure 6: Flow-matching critics consistently outperform monolithic critics across a spectrum of UTD ratios and environments.
Theoretical Analysis
On the theoretical front, the paper details a linear analysis demonstrating that, under a linear flow-matching critic, adaptation to changing TD targets can occur purely by reweighting integration gains (velocity coefficients), rather than by modifying features directly. In contrast, monolithic critics must continually rewrite features. This "feature reweighting" is only possible due to dense velocity field supervision and the integration parameterization, supporting the plasticity findings observed empirically.
Implications and Relation to Broader AI
The findings have both practical and theoretical implications:
- Practically, flow-matching critics decouple robust value estimation and efficient representation learning from the pathologies of bootstrapped TD learning, especially in nonstationary regimes with high update frequency or off-policy data. This will be valuable for real-world systems requiring continual or lifelong learning.
- Theoretically, the results prompt a reconsideration of the inductive bias in RL critic design: iterative computation backed by dense local supervision fundamentally alters the space of learnable and stably represented value functions.
- The paper draws intriguing analogies to reasoning in LLMs, where allocating additional "compute" (integration steps or reasoning tokens) at inference amplifies performance—but only when such iterative computation is properly aligned with intermediate supervision during training. The concept of balancing fast adaptation (through iterative inference) and slow adaptation (through weight updates) recurs in other domains such as meta-learning and may inform both future AI architectures and theoretical analyses.
Conclusion
This work establishes, both empirically and theoretically, that the primary contributions of flow-matching critics to TD learning are test-time recovery and enhancement of feature plasticity via iterative integration and dense velocity supervision, not distributional modeling. The resulting architectures demonstrate substantial and reproducible gains in stability, robustness, and efficiency, particularly in challenging high update-to-data regimes. The insights presented should inform future developments in reinforcement learning architectures, iterative computation in neural networks, and perhaps the broader landscape of adaptable and robust AI systems.