Helios: Real Real-Time Long Video Generation Model
Abstract: We introduce Helios, the first 14B video generation model that runs at 19.5 FPS on a single NVIDIA H100 GPU and supports minute-scale generation while matching the quality of a strong baseline. We make breakthroughs along three key dimensions: (1) robustness to long-video drifting without commonly used anti-drifting heuristics such as self-forcing, error-banks, or keyframe sampling; (2) real-time generation without standard acceleration techniques such as KV-cache, sparse/linear attention, or quantization; and (3) training without parallelism or sharding frameworks, enabling image-diffusion-scale batch sizes while fitting up to four 14B models within 80 GB of GPU memory. Specifically, Helios is a 14B autoregressive diffusion model with a unified input representation that natively supports T2V, I2V, and V2V tasks. To mitigate drifting in long-video generation, we characterize typical failure modes and propose simple yet effective training strategies that explicitly simulate drifting during training, while eliminating repetitive motion at its source. For efficiency, we heavily compress the historical and noisy context and reduce the number of sampling steps, yielding computational costs comparable to -- or lower than -- those of 1.3B video generative models. Moreover, we introduce infrastructure-level optimizations that accelerate both inference and training while reducing memory consumption. Extensive experiments demonstrate that Helios consistently outperforms prior methods on both short- and long-video generation. We plan to release the code, base model, and distilled model to support further development by the community.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Helios, a very large AI model (14 billion parameters) that can make long, high‑quality videos from text, images, or other videos in real time on a single powerful GPU. In simple terms: it’s like an AI “video camera” that can imagine scenes from descriptions and keep the story going for minutes without messing up—while running fast enough to be used interactively.
What questions were the researchers trying to answer?
They focused on three big challenges:
- How can an AI keep a long, continuous video consistent over time (no “drifting” where objects slide, colors change, or things get blurry)?
- How can it generate videos at interactive, real-time speeds (so it feels responsive)?
- How can it be trained and run without needing very complicated, huge-computer setups?
How did they do it? (Explained with simple ideas)
The team combined several practical ideas that work together. Think of building a good video generator like making a great animated movie: you need a strong plan for continuity, a fast production pipeline, and efficient tools.
1) Teaching the model to keep going without losing track (no “drift”)
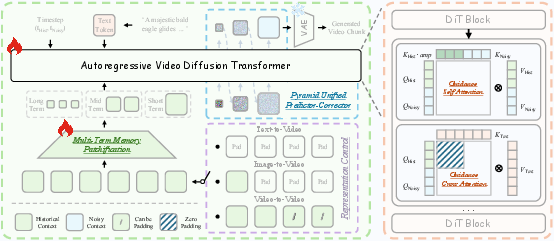
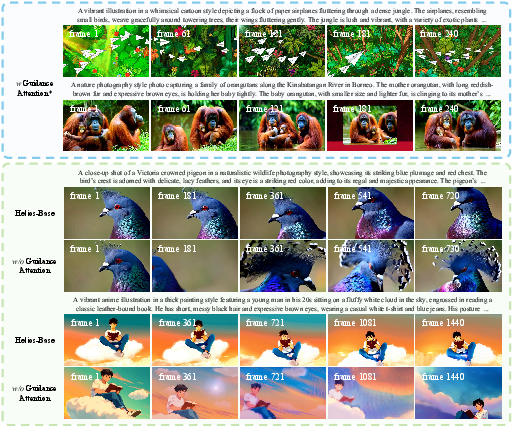
- Unified History Injection + Guidance Attention:
- Analogy: Imagine writing a story in chapters. You don’t rewrite earlier chapters—you read them and use them to guide the next one. Helios reads a “history” of clean, already-made frames and uses that to shape the next frames, without trying to “fix” the past.
- The model treats history and the new part differently: the history stays clean; the new part gets denoised from “static” (random noise) into a clear image.
- Handling the three common “drifts” in long videos:
- Position shift: objects slowly slide or jump.
- Color shift: colors drift (e.g., skin tones or sky colors slowly look wrong).
- Restoration shift: the video gets blurrier or noisier over time.
To fight these: - Relative RoPE (relative timing): Instead of remembering exact frame numbers (“this is frame 1000”), the model uses a relative sense of time (“this chunk comes after the last”). This prevents confusion and repetitive cycles that can happen with very long videos. - First‑Frame Anchor: It always keeps the very first frame around as a “color reference card.” This helps stabilize colors and style throughout long videos. - Frame‑Aware Corrupt (practice with mistakes): During training, the model’s “history” is sometimes intentionally messed up a bit (slight blur, extra noise, or brightness changes). This teaches the model to handle imperfect past frames—like learning to keep going even if earlier scenes weren’t perfect.
2) Making it fast without the usual shortcuts
- Multi‑Term Memory Patchification (smart history compression):
- Analogy: When planning a new scene, you need nearby scenes in high detail, but more distant scenes can be remembered as brief summaries. Helios keeps recent frames in higher detail and compresses older frames into “cliff notes,” cutting the amount of data it needs to process.
- Pyramid Unified Predictor‑Corrector (coarse‑to‑fine drawing):
- Analogy: An artist first sketches big shapes, then adds details. Helios starts at a low resolution to figure out the big layout and motion, then refines details at higher resolutions. This saves time by not doing heavy calculations too early.
- Adversarial Hierarchical Distillation (learning to be fast in fewer steps):
- Analogy: A fast student learns from a careful teacher and a strict critic. The “teacher” is a strong video generator; the “critic” checks realism. Helios uses this setup to cut generation steps from about 50 to just 3, while keeping quality high.
3) Practical engineering to fit big models on a single GPU
- Memory tricks to train and run a 14B model efficiently:
- Sharded EMA: Store smoothed model copies in pieces across devices instead of duplicating them.
- Asynchronous VRAM freeing: Move big parts in and out of GPU memory when they’re not used, like swapping tools in and out of a toolbox.
- Cache‑Grad for GAN: Save only the most important gradients during training so you don’t have to keep every temporary value in memory.
Together, these make Helios fast and memory‑efficient—even without typical speed‑up tricks (like some common Transformer shortcuts).
What did they find?
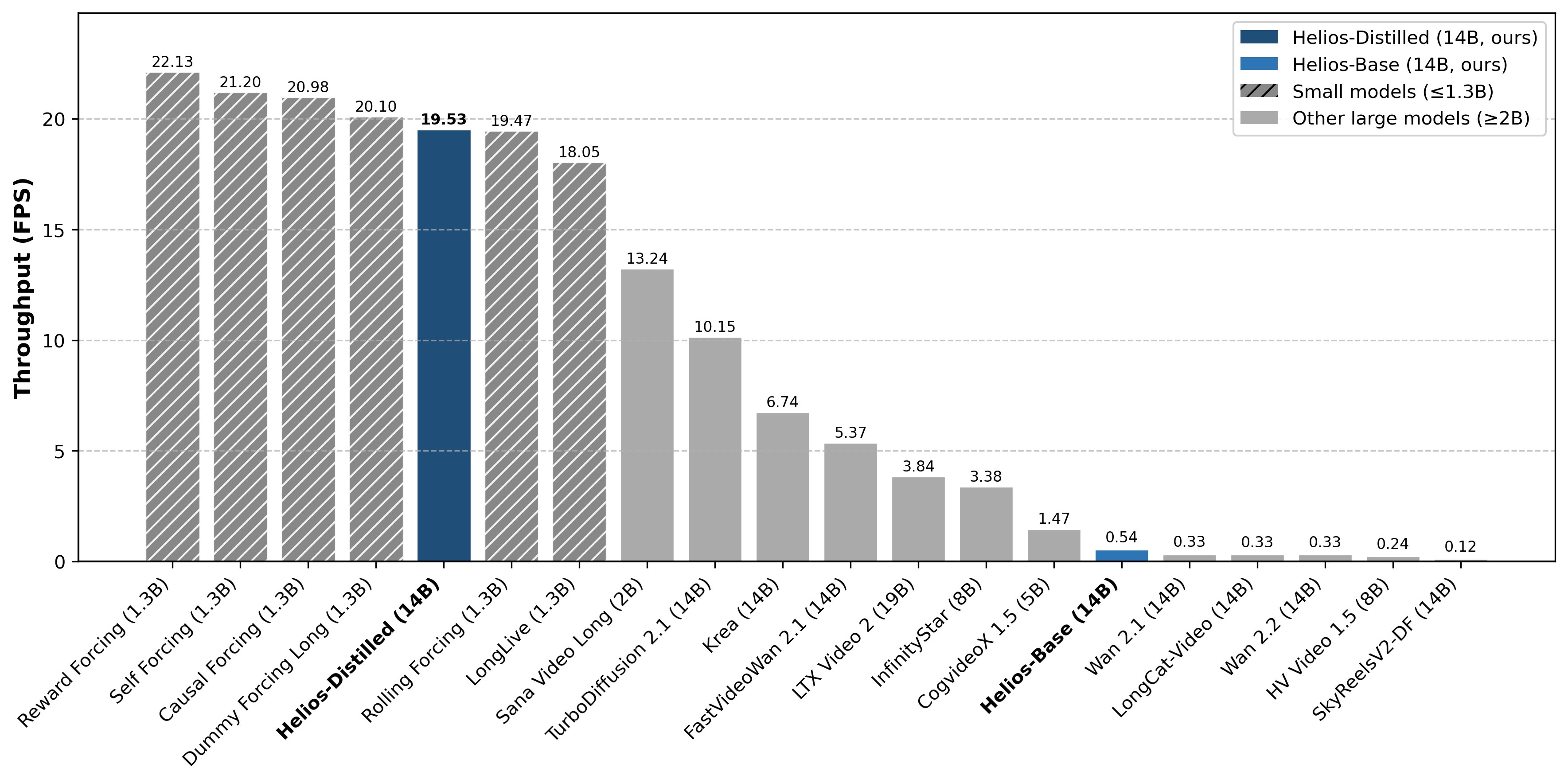
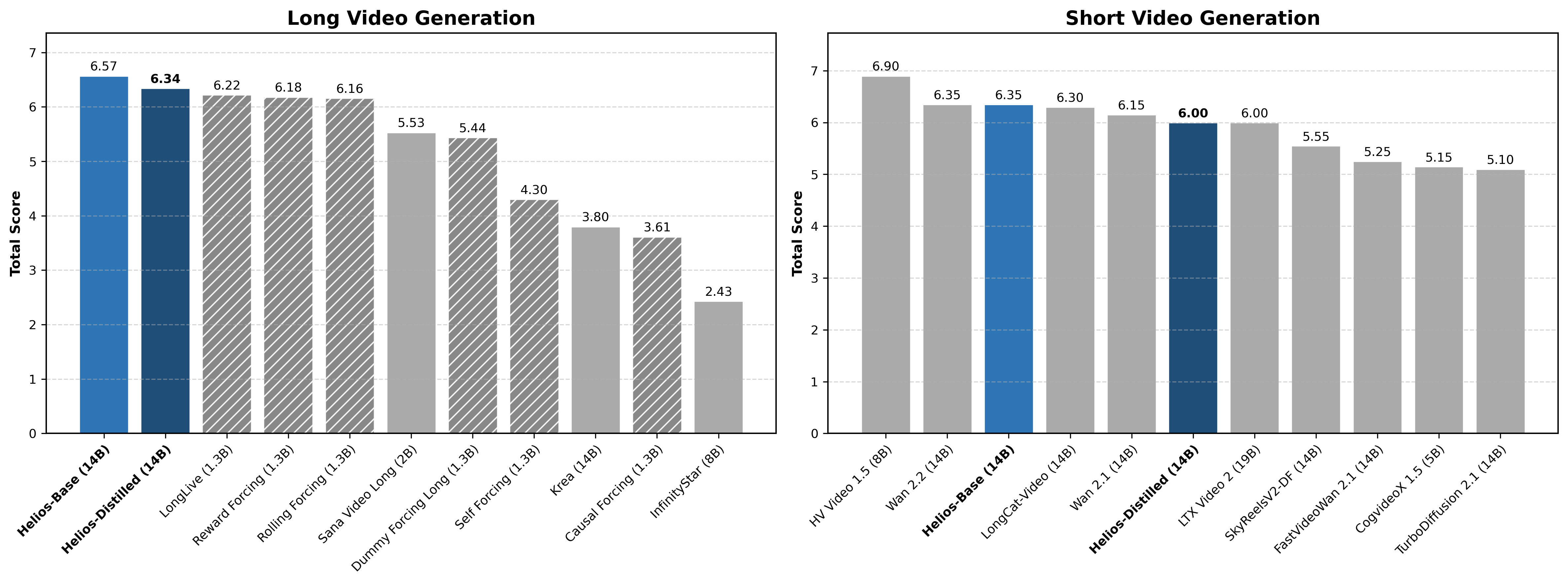
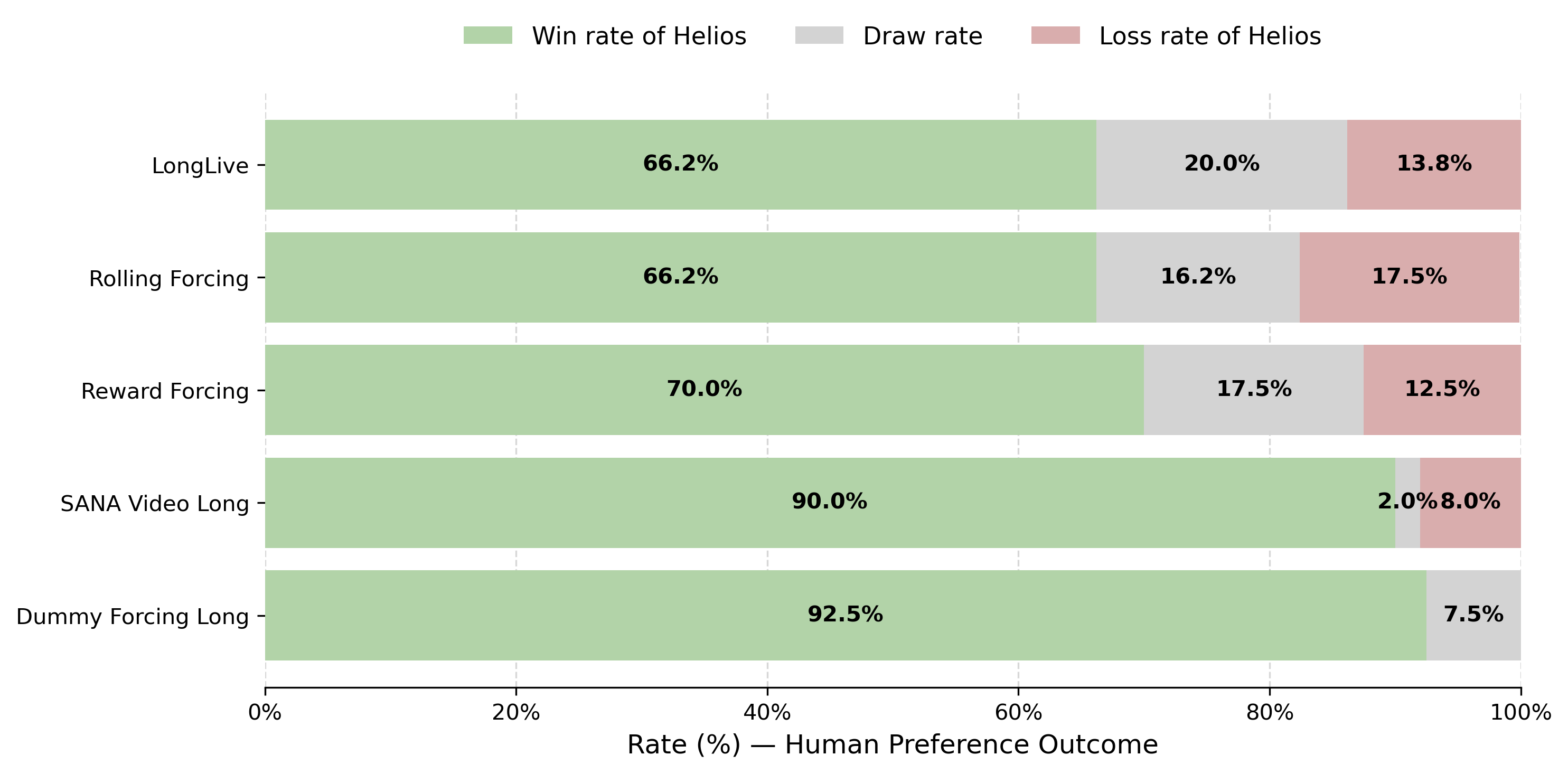
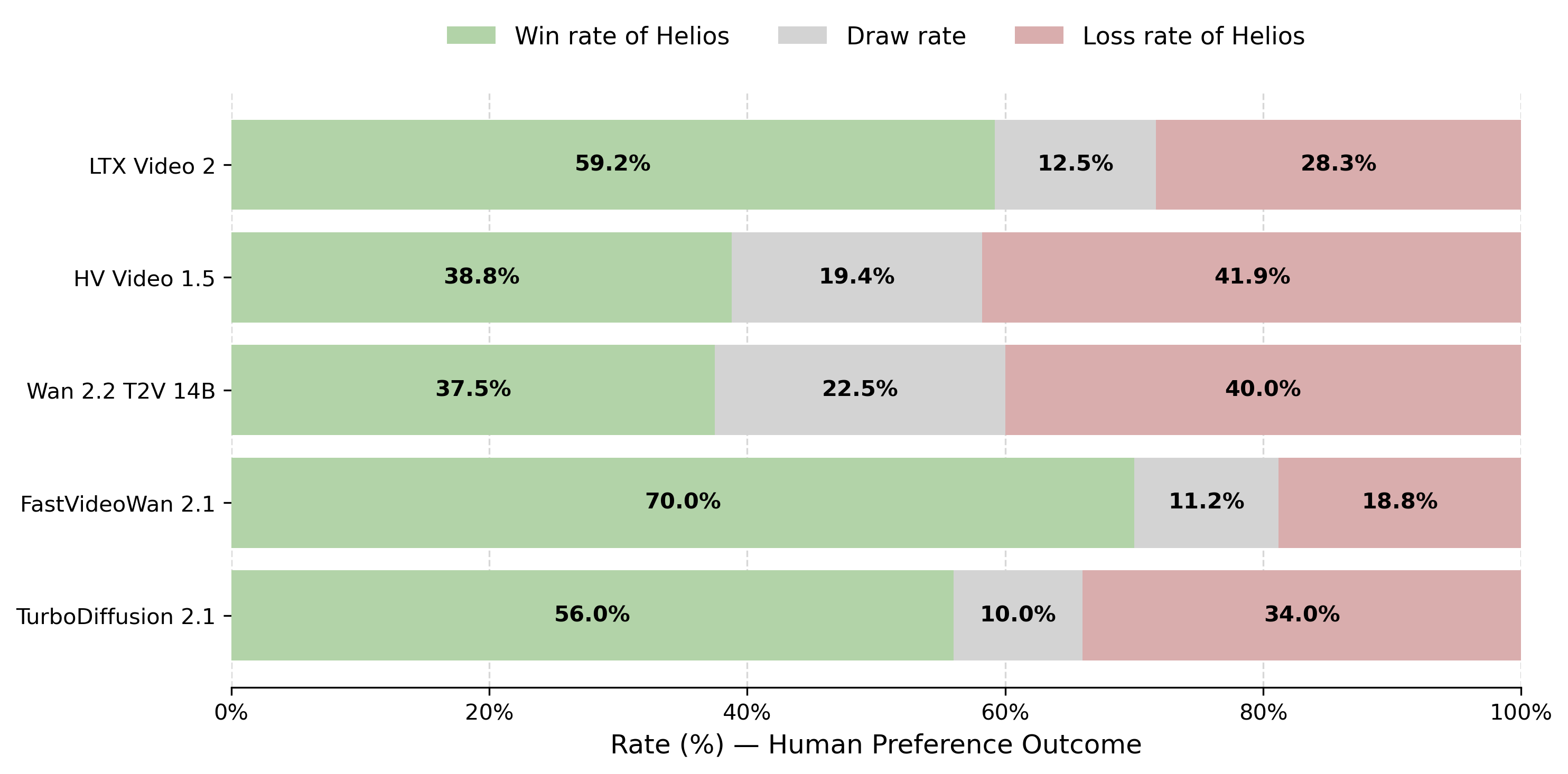
- Real‑time speed on a single NVIDIA H100 GPU: up to 19.5 frames per second (FPS), while generating minute‑long videos.
- Quality and stability: Helios keeps objects, colors, and motion consistent over long durations without relying on common anti‑drift hacks (no “self‑forcing,” no error‑banks, no special keyframe tricks).
- Big model, small compute footprint: Despite being a large 14B model, Helios’ smart compression and coarse‑to‑fine steps make it as fast—or faster—than some much smaller (around 1.3B) systems.
- Fewer steps, similar quality: It reduces generation steps from ~50 to 3 via distillation, while matching or beating the quality of strong baselines.
- Universal tasks in one model: It natively supports text‑to‑video (T2V), image‑to‑video (I2V), and video‑to‑video (V2V) by just changing what “history” you feed it.
- New benchmark: They built HeliosBench, a set of 240 prompts across different lengths (from very short to long), to fairly test real‑time long‑video generation.
Why this matters:
- Faster, better, longer videos mean more practical uses—like live creative tools, interactive storytelling, game engines, and real‑time editing.
Why does this matter?
Helios shows that you can have fast, long, stable video generation from a large model on a single high‑end GPU—without many of the usual shortcuts or fragile tricks. This could:
- Make real‑time creative tools more accessible (write a prompt and see a video immediately).
- Improve interactive experiences in games and virtual worlds (the AI can generate scenes on the fly).
- Encourage the community to build on top of a strong, practical base (the authors plan to release code and models, plus the new benchmark).
In short, Helios pushes video generation closer to being a reliable, responsive tool—more like a smart, steady “video painter” that can keep drawing for as long as you want.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Benchmark scope and metrics: HeliosBench contains 240 prompts across four durations, but the paper does not detail prompt diversity, coverage of motion/scene types, or standardized, quantitative long-horizon metrics for drift, identity preservation, or semantic consistency beyond RGB/aesthetic statistics.
- “Infinite” generation claims: Evaluations appear capped at 1440 frames; stability, identity consistency, and quality for truly long horizons (tens of minutes/hours) are not quantified.
- Resolution and frame rate generality: Throughput claims and quality comparisons do not specify comprehensive results across multiple resolutions and frame rates (e.g., 480p→4K, 12–60 FPS), leaving open how performance scales.
- Reproducibility of speed claims: Precise hardware/software stack (drivers, CUDA, cuDNN, compiler flags), I/O and VAE decoding/encoding overheads, and end-to-end latency per-frame (not just FPS) are not fully documented for independent verification.
- Latency for interactive use: Real-time FPS is measured, but per-frame latency, buffering/pipeline depth, and responsiveness under prompt edits (Interactive Interpolation) are not characterized.
- Ablations for anti-drift components: No reported ablation isolating the effects of Relative RoPE, First-Frame Anchor, and Frame-Aware Corrupt individually and jointly across durations and content types.
- Theoretical underpinnings of Relative RoPE: No formal analysis of how relative indexing alleviates RoPE periodicity conflicts with multi-head attention and whether benefits generalize across different head sizes or alternative positional schemes.
- Side effects of First-Frame Anchor: Persistently conditioning on the initial frame may bias color/appearance and resist global scene/style shifts or mid-sequence prompt changes; no study quantifies this trade-off.
- Frame-Aware Corrupt coverage: Perturbations target exposure, Gaussian noise, and down/up-sampling; other real-world degradations (compression artifacts, motion blur, geometric jitter, color grading, rolling shutter) are not simulated or evaluated.
- Adaptive Sampling drift detector: Using thresholds on RGB/latent mean/variance risks false positives/negatives across diverse content; robustness, threshold sensitivity, and class- or scene-dependence are not evaluated.
- Guidance Attention specifics: The design introduces head-wise amplification tokens and bypasses cross-attention for history, but there is no analysis of learned attention patterns, stability, or potential prompt drift in very long generations.
- Representation Control task coupling: How joint support for T2V, I2V, and V2V affects each task (e.g., negative transfer, task interference) is not quantified; per-task data balance and training curriculum are unspecified.
- Memory patchification trade-offs: Multi-Term Memory Patchification may drop long-range dependencies and subtle cues in distant history; its impact on narrative coherence and rare long-horizon dependencies is not systematically studied.
- Content-adaptive compression: Patchification uses fixed kernels; whether learned/adaptive or content-aware compression could improve long-range coherence and what the trade-offs are remains unexplored.
- Multi-scale sampling design choices: Pyramid Unified Predictor Corrector introduces stage boundaries, resolutions, and step allocations (N1, N2, N3), but no guidelines or auto-tuning strategy is given, nor ablations on stability/artifacts across scale transitions.
- Path continuity across scales: Resetting UniPC buffers and nearest-neighbor upsampling with covariance correction may still introduce subtle artifacts; alternatives (e.g., learned cross-scale couplings, differentiable upsamplers) are not examined.
- Flow-matching trajectory assumptions: Linear interpolation between scales implies constant velocity; the suitability of this choice vs. richer trajectory families (e.g., curved/learned flows) is not analyzed.
- Distillation generality: Adversarial Hierarchical Distillation depends on an autoregressive Helios-Base teacher; portability to other backbones/teachers and sensitivity to teacher quality are not evaluated.
- Stability of adversarial post-training: The discriminator architecture, training dynamics (e.g., collapse prevention), fidelity–diversity trade-offs, and compute overhead are not reported or ablated.
- Diversity after few-step distillation: Reducing steps to three risks mode collapse or reduced sample diversity; quantitative diversity metrics (e.g., LPIPS variants, intra-prompt diversity) are absent.
- Data transparency and safety: Training data scale, sources, licensing, filtering, and handling of copyrighted or sensitive content are not described; bias, safety, and memorization assessments are missing.
- Evaluation breadth: Beyond general text alignment and motion, the paper does not report controlled tests for identity preservation, complex physics, camera trajectory fidelity, occlusions, or fine-grained text control over long horizons.
- Modalities and control signals: The system currently focuses on text/image/video conditions; integration with audio, pose/trajectory controls, depth/masks, 3D camera paths, or spatially localized edits is not explored.
- Combination with standard accelerations: Although Helios avoids KV-cache, sparse/linear attention, and quantization, the potential compounded gains (speed/latency) and quality impacts of combining Helios with these techniques are not investigated.
- Hardware portability: Results center on a single H100; performance/quality on other accelerators (A100, consumer GPUs, TPUs) and memory-constrained settings is not reported.
- Energy and training cost: End-to-end training schedules, wall-clock time, energy use, and compute budgets (GPUs, batch sizes across stages) are not disclosed, hindering reproducibility planning.
- Robustness to domain shifts: Generalization to out-of-distribution content (e.g., non-photorealistic styles, scientific/medical videos, animations) and failure modes beyond drift are not documented.
- HeliosBench standardization: It is not clear whether HeliosBench is representative and adopted; alignment with emerging community benchmarks and protocols for long-video evaluation remains open.
- Responsible deployment: Watermarking, content moderation, misuse mitigation, and release governance are not discussed, despite the model’s real-time, long-duration generation capabilities.
Practical Applications
Immediate Applications
The following applications can be deployed with the paper’s techniques and model, assuming access to a modern data center GPU (e.g., NVIDIA H100) and pending public release of Helios and HeliosBench as stated in the paper.
- Real-time interactive video generation for content creation and editing (sector: media/entertainment, software)
- Use cases: live previz for filmmakers, instant animatics, A/B testing of ad creatives, prompt-based clip extension (T2V), B-roll and background generation (V2V), motion continuation from a single frame (I2V).
- Tools/products/workflows: NLE plugins (e.g., Adobe Premiere/After Effects, DaVinci Resolve), OBS/Streamlabs plugins for live shows, web-based editors with “infinite extend” and “interactive interpolation” sliders for smooth prompt changes.
- Dependencies/assumptions: availability of Helios checkpoints and VAE/text encoders; integration into editing pipelines; adherence to content policy and watermarking; stable internet/GPU access.
- In-engine, on-the-fly cutscenes and dynamic backgrounds (sector: gaming)
- Use cases: dynamic cutscenes generated from player state, procedurally generated ambient loops for open worlds, tailored visual narratives for live ops/events.
- Tools/products/workflows: Unity/Unreal Engine SDK using Unified History Injection for video continuation; API for per-frame prompt updates with “interactive interpolation.”
- Dependencies/assumptions: engine integration; latency budget supported by ~19.5 FPS inference; content moderation and safety layers.
- Live streaming and virtual event visuals (sector: creator economy, marketing)
- Use cases: real-time visual effects, generative virtual sets, thematic transitions tied to chat or event triggers.
- Tools/products/workflows: OBS filters to drive V2V effects; broadcast graphics controllers that adjust prompts in real time; adaptive anti-drift (using paper’s latent-statistics monitoring) for hour-long streams.
- Dependencies/assumptions: single H100-equivalent GPU per live channel or cloud endpoint; stable prompt control; safety moderation.
- Digital signage and retail displays with “infinite” coherent loops (sector: retail, advertising)
- Use cases: thematically consistent, non-repetitive looping videos for storefronts, malls, public displays.
- Tools/products/workflows: kiosk players with a cloud endpoint generating long-coherent segments; First-Frame Anchor and Relative RoPE to avoid resets and repetitive motion.
- Dependencies/assumptions: bandwidth and content caching; GPU inference cost budgets; scheduled content review.
- Rapid dataset creation for vision tasks (sector: ML R&D, robotics simulation)
- Use cases: generating long, coherent videos for pretraining or augmenting video understanding models; creating staged sequences for world-model research; stable infinite streams for self-supervised learning.
- Tools/products/workflows: pipelines that generate hours-long semantically steady footage; guidance attention to maintain scene consistency; Frame-Aware Corrupt in training loops for robustness.
- Dependencies/assumptions: domain alignment between generated content and target tasks; licensing and provenance controls; compute budget.
- Lab-friendly training of large video models without parallelism/sharding (sector: academia, startups)
- Use cases: small labs training 14B-class video models with image-like batch sizes; quick ablation/iteration without distributed infra.
- Tools/products/workflows: training scripts employing Multi-Term Memory Patchification, Pyramid Unified Predictor Corrector, and asynchronous VRAM freeing; sharded EMA and GAN Cache-Grad to fit within 80 GB VRAM.
- Dependencies/assumptions: access to a single high-memory GPU node (e.g., H100 80 GB); local storage for latent caching; reproducibility of infra tricks.
- Benchmarking and evaluation standardization (sector: academia, policy, industry)
- Use cases: consistent evaluation of long-video drift and real-time performance using HeliosBench across durations (very short to long).
- Tools/products/workflows: CI pipelines that evaluate new checkpoints against HeliosBench; internal red-teaming for drift patterns (position, color, restoration).
- Dependencies/assumptions: open availability of HeliosBench; shared metrics and thresholds.
- Real-time educational and explainer videos (sector: education, enterprise training)
- Use cases: quickly generating topic-driven sequences; extending instructor-provided frames; on-the-fly revision via prompt interpolation.
- Tools/products/workflows: LMS plugins enabling video generation/extension; authoring tools that use I2V/T2V for lesson modules.
- Dependencies/assumptions: institutional approvals for AI content; accessibility and bias audits.
- Energy and cost-aware deployment for real-time video generation (sector: cloud/compute operations)
- Use cases: lower compute cost per minute of video relative to prior 1.3B–14B methods; improved throughput without KV-cache or sparse attention.
- Tools/products/workflows: autoscaling endpoints; token and step reduction (patchification + pyramid sampler) for cost control; utilization dashboards.
- Dependencies/assumptions: real-world resolution/frame-rate parity with product needs; workload variance management.
Long-Term Applications
These applications require further research, scaling, ecosystem integration, guardrails, or specialized hardware to realize fully.
- Agentic world models for simulation and robotics (sector: robotics, autonomy, simulation)
- Use cases: long-horizon visual world models for planning and control; closed-loop sim environments that adapt in real time.
- Path to product: integrate Unified History Injection as a stable continuation backbone; couple with control signals and physics priors; evaluate on sim2real tasks.
- Dependencies/assumptions: robust grounding to physical dynamics; multimodal sensor integration; safety validation; compute-efficient conditioning.
- End-to-end, semi-automated film/TV production pipelines (sector: media/entertainment)
- Use cases: director-in-the-loop pipelines where long scenes are generated and refined interactively; continuity-preserving editing across episodes.
- Path to product: combine Guidance Attention with timeline-aware editing UIs; expand to multi-character, multi-shot consistency tools; integrate with story/shot planning.
- Dependencies/assumptions: rights management; consistent character/asset identity; large-scale finetuning; legal and guild compliance.
- Personalized, always-on content streams and channels (sector: consumer platforms, advertising)
- Use cases: individualized “TV” channels or in-app feeds that generate content continuously to user preference profiles.
- Path to product: deploy scalable inference clusters; add content controls, watermarking, and usage analytics; smooth prompt changes via interactive interpolation.
- Dependencies/assumptions: strong safety and moderation; privacy-preserving preference modeling; predictable cost-per-user.
- AR/VR generative environments and adaptive scenes (sector: XR)
- Use cases: dynamic, AI-generated scenes responsive to user inputs and context in headsets or spatial displays.
- Path to product: mix Helios video outputs with 3D/NeRF pipelines or layered compositing; low-latency edge rendering; foveated streaming strategies.
- Dependencies/assumptions: headset compute limits; latency budgets; real-time compositing; content comfort/sickness thresholds.
- Mobile/edge-optimized real-time video generation (sector: devices, telecom)
- Use cases: on-device generative effects for video calls and short-form apps; bandwidth-aware generative streaming.
- Path to product: integrate quantization, KV-cache, and hardware accelerators (which Helios currently avoids) plus distillation for smaller students.
- Dependencies/assumptions: hardware support for transformer acceleration; power constraints; quality-time tradeoffs.
- Regulatory testing suites for generative video systems (sector: policy, compliance)
- Use cases: stress-testing drift, stability, and content safety; certifying model behavior under long-horizon prompts.
- Path to product: extend HeliosBench to include safety prompts and artifact checks; publish standard thresholds and reporting formats.
- Dependencies/assumptions: cross-industry agreement; third-party auditing; watermarking/traceability standards.
- Cross-modal, multi-shot story engines (sector: education, entertainment, enterprise comms)
- Use cases: consistent character and plot progression across many scenes with long temporal memory.
- Path to product: expand History Injection with character identity embeddings and asset libraries; unify with script/voice guidance.
- Dependencies/assumptions: identity preservation; IP/licensing of character likenesses; large-scale supervised datasets.
- Automated post-production with anti-drift-aware pipelines (sector: post-production, localization)
- Use cases: automated sequences for localization (e.g., region-specific B-roll), pacing corrections, and color-matched extensions without resets.
- Path to product: couple First-Frame Anchor and Relative RoPE with color pipeline controls; integrate frame-aware perturbations for robust continuation.
- Dependencies/assumptions: tight integration with color grading/VFX tools; QC and human approval loops.
- Sustainable compute policy and best practices for generative video (sector: policy, sustainability)
- Use cases: guidelines that incentivize token/step-efficient designs to reduce energy per minute of generated video.
- Path to product: empirical benchmarking with Helios-like efficiency metrics; disclosure standards for energy per minute/frame.
- Dependencies/assumptions: standardized measurements; alignment with cloud providers and regulators.
- Generalizing Helios’s training/inference tricks to other modalities (sector: foundation models, multimodal AI)
- Use cases: speech, 3D, and multimodal long-horizon generation with relative-position embeddings, hierarchical sampling, and memory patchification.
- Path to product: port the Deep Compression Flow, Relative RoPE, and hierarchical distillation to audio/3D/video-LLMs; release cross-modal benchmarks.
- Dependencies/assumptions: modality-specific architectures; data availability; careful evaluation to avoid new failure modes.
Notes on feasibility and assumptions across applications:
- Hardware: Real-time claims are demonstrated on a single H100 at specific resolutions; scaling to higher resolutions, multiple streams, or edge devices will require further engineering (e.g., quantization, sparse attention, caching).
- Release status: Immediate adoption depends on the promised release of code, base model, distilled model, and HeliosBench.
- Safety and governance: Any production deployment should add watermarking, content filters, and usage policies to mitigate misuse and address legal/ethical concerns.
- Domain shift: Quality and stability may vary by domain; finetuning/adaptation may be required for specialized content (e.g., medical, industrial settings).
- Integration: Real-time pipelines must account for encoder/decoder latencies, memory budgets, and synchronization with audio/UX systems.
Glossary
- Adaptive Sampling: A training-free, parameter-free strategy that detects distribution drift during generation and perturbs history adaptively to improve stability. "Adaptive Sampling."
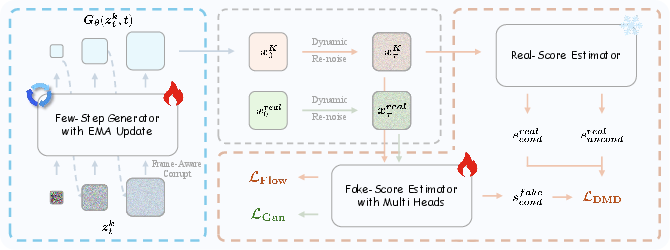
- Adversarial Hierarchical Distillation: A distillation framework that combines staged flow-based distillation with adversarial objectives to reduce sampling steps while maintaining quality. "We introduce Adversarial Hierarchical Distillation, a purely teacher-forced approach that uses only the autoregressive model as the teacher, reducing the number of sampling steps from 50 to 3."
- Adversarial Post-Training: An additional GAN-based training phase applied after distillation to mitigate teacher limitations and improve sample quality. "Adversarial Post-Training."
- Autoregressive diffusion model: A generative model that produces sequences by conditioning each step on prior outputs while using diffusion-based denoising. "Helios is a 14B autoregressive diffusion model with a unified input representation that natively supports T2V, I2V, and V2V tasks."
- Bidirectional inference: An inference regime where attention can flow in both temporal directions, contrasting with strictly causal (uni-directional) inference. "This design avoids the limitations of causal masking while preserving bidirectional inference, and it unifies T2V, I2V, and V2V within a single architecture."
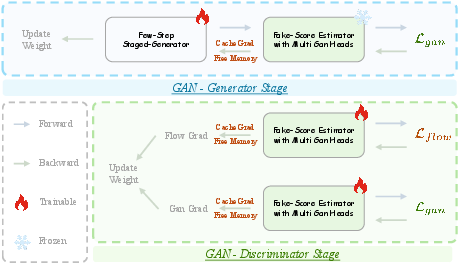
- Cache Grad for GAN: A memory-optimization technique that caches discriminator input gradients to avoid retaining full activations during backpropagation. "Cache Grad for GAN."
- Causal attention: Attention restricted to past tokens (or frames), enforcing an autoregressive ordering and preventing information leakage from the future. "Self-Forcing \cite{selfforcing} adopts causal attention \cite{causvid} and proposes a train-as-infer rollout strategy to improve quality."
- Causal masking: Masking that enforces causality in attention by preventing access to future tokens/frames, often used to enable autoregressive behavior. "Finally, these long-video generation methods based on causal masking fundamentally change the inference regime of bidirectional pre-trained models and may limit the achievable quality."
- Classifier-free guidance: A technique that mixes conditional and unconditional model outputs to steer generation toward the conditioning signal at inference or scoring time. "The real score is computed via classifier-free guidance by combining conditional and unconditional predictions, i.e., $\mathrm{CFG}(s_{\text{real}^{\text{cond}, s_{\text{real}^{\text{uncond})$"
- Deep Compression Flow: A suite of techniques that compress historical and noisy contexts to reduce tokens and sampling steps, enabling real-time performance. "For Real-Time Generation, we further propose Deep Compression Flow to reduce both the number of visual tokens and sampling steps, enabling real-time generation on a single GPU with a 14B model."
- DeepSpeed: A deep learning optimization library that provides parallelism and sharding strategies for training large models. "In practice, training such models on a single GPU typically requires extensive parallelism (\eg, CP, TP, SP) and parameter/activation sharding (\eg, FSDP, DeepSpeed)."
- Distribution Matching Distillation (DMD): A distillation method that matches a student’s generated distribution to a teacher’s via learned scores, enabling fewer sampling steps. "Among existing approaches \cite{rcm, LCM, sdxl-lightning, progressivedistillation}, Distribution Matching Distillation (DMD) \cite{DMD} is widely adopted and well established."
- Dynamic Re-noise: A curriculum-style strategy that samples timesteps from a changing distribution to emphasize different noise regimes over training. "Dynamic Re-noise."
- Easy Anti-Drifting: A set of simple training strategies (e.g., relative RoPE, first-frame anchoring, frame-aware corruption) to mitigate long-video drift without rollouts. "For High-Quality Generation, we propose Easy Anti-Drifting to mitigate drifting, enabling high-quality minute-scale video generation without inefficient self-forcing \cite{selfforcing} or error-banks \cite{SVI}."
- Error-banks: Memory mechanisms that store and reuse error signals or corrections across time to combat drift in autoregressive generation. "Without commonly used anti-drifting strategies (\eg, self-forcing, error-banks, keyframe sampling, or inverted sampling), Helios generates minute-scale videos with high quality and strong coherence."
- Exponential moving average (EMA): A smoothing technique that tracks running averages of parameters or statistics with exponential decay, used for stable training or runtime stats. "Exponential moving average (EMA) stabilizes training by smoothing parameter updates and is typically stored in FP32 for numerical robustness."
- Exposure bias: A failure mode where models, trained on ground truth inputs, perform poorly when conditioned on their own imperfect outputs at inference time. "the model frequently exhibits severe exposure bias during inference once the generated sequence exceeds this length."
- FlashAttention: A memory- and speed-optimized attention algorithm that reduces the cost of softmax attention via tiling and recomputation strategies. "The results are obtained at the same resolution with all official acceleration techniques, including FlashAttention, torch compile, and KV-cache."
- Flow matching: A training paradigm that learns a continuous-time velocity field that transports noise to data along a flow (ODE) trajectory. "we reformulate flow matching from a
full-resolution noise to full-resolution data'' trajectory to multiplelow-resolution noise to multi-resolution data'' trajectories" - First-Frame Anchor: A technique that preserves the very first frame in the historical context as a global visual anchor to reduce color drift over long sequences. "First-Frame Anchor"
- Frame-Aware Corrupt: A training-time corruption scheme that independently perturbs historical frames (e.g., exposure, noise, blur) to simulate inference-time degradation. "Frame-Aware Corrupt"
- Fully Sharded Data Parallel (FSDP): A distributed training method that shards model parameters, gradients, and optimizer states across devices to reduce memory. "In practice, training such models on a single GPU typically requires extensive parallelism (\eg, CP, TP, SP) and parameter/activation sharding (\eg, FSDP, DeepSpeed)."
- Guidance Attention: An attention mechanism that explicitly amplifies relevant historical signals to guide denoising of future frames while keeping history clean. "we introduce Guidance Attention to strengthen the influence of the historical context on the generation of future frames"
- Gradient accumulation: A technique that splits large effective batch sizes across multiple smaller forward/backward passes by accumulating gradients before an optimizer step. "We combine gradient accumulation with batched execution."
- Head-wise amplification tokens: Learnable per-head scaling tokens that amplify or attenuate historical keys to modulate their influence in attention. "we introduce head-wise amplification tokens to modulate the historical keys."
- Hidden-state caching: Reusing intermediate hidden states across steps or frames to avoid recomputation and accelerate inference. "Without standard acceleration techniques (\eg, KV-cache, causal masking, sparse/linear attention, TinyVAE, progressive noise schedules, hidden-state caching, or quantization)..."
- Interactive Interpolation: A prompt-editing technique that linearly interpolates between text embeddings over steps to avoid abrupt semantic changes. "Interactive Interpolation."
- Inverted sampling: A training/inference scheme that flips or alters the sampling direction/order to reduce drift or improve stability in sequential generation. "FramePack \cite{framepack} trains a next-frame prediction model and introduces inverted sampling to reduce drifting."
- Keyframe sampling: Selecting a subset of frames (keyframes) for conditioning or training to guide longer-range structure and reduce drift. "keyframe sampling"
- KV-cache: Caching the key/value tensors from attention layers across timesteps to avoid recomputing them during autoregressive inference. "including FlashAttention, torch compile, and KV-cache."
- Linear attention: Attention variants that reduce quadratic complexity to linear by kernelization or low-rank approximations. "Without standard acceleration techniques (\eg, KV-cache, causal masking, sparse/linear attention, TinyVAE, progressive noise schedules, hidden-state caching, or quantization)"
- Multi-Term Memory Patchification: A hierarchical token reduction scheme that compresses history with coarser patches for distant frames to keep token budgets constant. "we reduce redundancy in the historical context $X_{\text{Hist}$ via Multi-Term Memory Patchification."
- Non-saturated GAN objective: A GAN training objective that uses the non-saturating logistic loss for more stable gradient signals. "We train these branches with the non-saturated GAN objective:"
- ODE-based generative process: A generation procedure defined by integrating an ordinary differential equation that transports noise to data via learned velocity fields. "Helios learn multi-scale velocity fields that define an ODE-based generative process."
- Pinned host memory: Page-locked CPU memory that enables faster, asynchronous transfers between CPU and GPU. "With pinned host memory, non-blocking transfers, and careful CPU--GPU scheduling, we maintain throughput close to GPU-only execution despite frequent transfers."
- Progressive noise schedules: Noise schedules that change over time (or resolution), often starting coarse and refining, to guide multi-step generative processes. "Without standard acceleration techniques (\eg, KV-cache, causal masking, sparse/linear attention, TinyVAE, progressive noise schedules, hidden-state caching, or quantization)"
- Pyramid Unified Predictor Corrector: A multi-scale variant of UniPC that samples from low to high resolutions to cut token costs and preserve quality. "we propose Pyramid Unified Predictor Corrector, a multi-scale variant of the Unified Predictor Corrector (UniPC) sampler"
- Quantization: Reducing numerical precision of weights/activations to save memory and speed up inference at the cost of slight accuracy loss. "Without standard acceleration techniques (\eg, KV-cache, causal masking, sparse/linear attention, TinyVAE, progressive noise schedules, hidden-state caching, or quantization), Helios achieves 19.5 FPS"
- Relative RoPE: A relative positional encoding approach that constrains temporal indices to a fixed range to reduce drift and cyclic artifacts in long sequences. "To address these issues, we propose Relative RoPE."
- Representation Control: A formulation that treats long-video generation as continuation by concatenating historical and noisy contexts, enabling unified T2V/I2V/V2V. "We address these issues with Representation Control, which formulates long-video generation as video continuation."
- R1 regularizer: A gradient penalty regularizer for GAN discriminators that stabilizes training by penalizing gradient norms on real data. "we incorporate an approximate R1 regularizer (following APT)"
- Rotary Position Embeddings (RoPE): A sinusoidal positional encoding that rotates query/key vectors to inject relative position information into attention. "the periodic structure of rotary position embeddings (RoPE)"
- Self-Forcing: A train-as-infer rollout strategy that conditions training on previously generated segments to reduce train–inference mismatch. "we propose Easy Anti-Drifting to mitigate drifting, enabling high-quality minute-scale video generation without inefficient self-forcing \cite{selfforcing} or error-banks \cite{SVI}."
- Sharded EMA: Storing and updating the EMA parameters in shards across GPUs (e.g., via ZeRO-3) to lower memory usage. "Sharded EMA."
- Sparse attention: Attention mechanisms that restrict attention patterns to a subset of tokens to reduce quadratic complexity. "Without standard acceleration techniques (\eg, KV-cache, causal masking, sparse/linear attention, TinyVAE, progressive noise schedules, hidden-state caching, or quantization)"
- Step distillation: Techniques that reduce the number of sampling steps (e.g., from tens to a few) by distilling from a multi-step teacher. "which substantially increases training cost and motivates step distillation"
- Staged Backward Simulation: A multi-stage reconstruction of clean samples from noisy states within the distillation pipeline to improve stability. "Staged Backward Simulation."
- Staged ODE Init: Initialization using pairs of ODE solutions across stages to warm-start multi-stage flow-based students. "Staged ODE Init."
- Teacher Forcing: Training that feeds ground-truth or teacher outputs as inputs, avoiding exposure to the model’s own errors during training. "Pure Teacher Forcing with Autoregressive Teacher."
- Test-time training (TTT): Adapting model parameters during inference to the test data distribution to improve performance. "test-time training"
- TinyVAE: A lightweight VAE variant used for fast encoding/decoding in generative pipelines. "Without standard acceleration techniques (\eg, KV-cache, causal masking, sparse/linear attention, TinyVAE, progressive noise schedules, hidden-state caching, or quantization)"
- Two time-scale update rule (TTUR): A GAN training scheme where generator and discriminator are updated at different relative frequencies. "under the two time-scale update rule (TTUR)"
- Unified History Injection: A mechanism that converts a bidirectional model into an autoregressive generator by injecting history alongside noisy context. "we introduce Unified History Injection to convert a bidirectional pre-trained model \cite{wan} into an autoregressive generator"
- Unified Predictor Corrector (UniPC): A fast ODE-based sampler that combines predictor and corrector updates to accelerate diffusion sampling. "a multi-scale variant of the Unified Predictor Corrector (UniPC) sampler"
- Variational Autoencoder (VAE): A latent-variable generative model used to encode/decode images or videos into compact latent spaces. "In the first two training stages, the GPU needs to load only three components: the VAE, the text encoder, and the DiT."
- Velocity field: The learned vector field that defines the instantaneous direction of transport from noise to data in flow/ODE-based models. "We parameterize the velocity field as and minimize the velocity-matching objective"
- ZeRO-3: A memory optimization stage of ZeRO that shards optimizer states, gradients, and parameters across data-parallel ranks. "Following OpenSora-Plan \cite{opensoraplan}, we instead shard the EMA parameters across GPUs using ZeRO-3, so that each device stores only a fraction of the EMA states."
Collections
Sign up for free to add this paper to one or more collections.