- The paper introduces an interactive evaluation framework that defines intelligence as budgeted sequential decision processes across logic, math, and strategic games.
- It demonstrates that static, pass-based evaluations underestimate model performance, highlighting critical gaps in reasoning and adaptive query selection.
- Empirical results reveal varied success among LLMs, with models like Gemini-3-flash excelling while overall performance indicates substantial room for improvement.
Interactive Benchmarks: A Unified Paradigm for Intelligence Evaluation
Motivation and Framework
The Interactive Benchmarks framework addresses critical shortcomings in current LLM evaluation protocols, which rely heavily on static datasets and preference-based arenas. The paper posits that the ability to actively acquire information is a core aspect of intelligence, more faithfully captured through interactive evaluation under budget constraints. The paradigm formalizes intelligence as sequential decision processes in two regimes: epistemic truth-seeking (Interactive Proofs) and strategic utility maximization (Interactive Games). Models must reason and act through multi-turn interaction, choosing queries or actions to minimize uncertainty or maximize reward.
(Figure 1)
Figure 1: Overview of the Interactive Benchmarks Framework, separating Interactive Proofs and Interactive Games as sequential decision processes.
Interactive Proofs: Logic and Mathematics
Situation Puzzle Logic
The logic benchmark utilizes the Situation Puzzle dataset, consisting of challenging abductive reasoning instances designed to preclude trivial or memorized solutions. Models interact with a judge via constrained yes/no-style queries under a fixed 20-turn budget, iteratively validating hypotheses to reconstruct hidden explanations. All models achieve 0% accuracy with single-shot (non-interactive) inference, highlighting the necessity of interaction and strategic query selection.
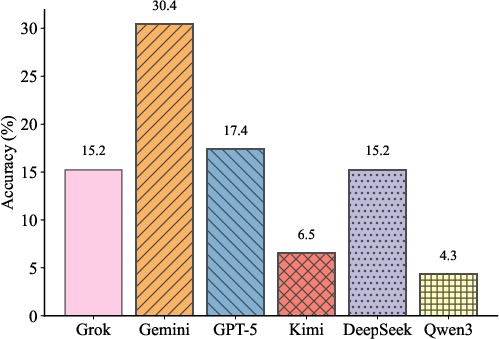
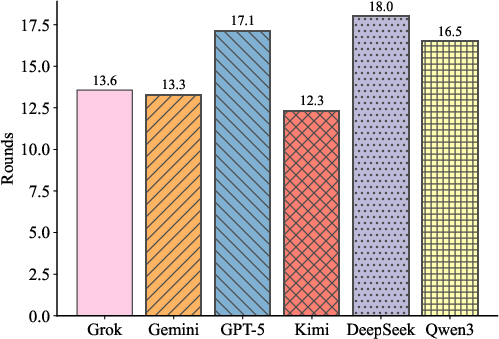
Figure 2: Accuracy on the Situation Puzzle dataset (46 puzzles), showing the fraction solved within 20 turns.
Gemini-3-flash achieves the highest puzzle accuracy (30.4%), followed by GPT-5-mini (17.4%). Qwen3-max lags at 4.3%. Kimi-k2-thinking demonstrates minimal interaction rounds among solved puzzles, indicating efficient convergence, while DeepSeek-v3.2 is slower even when correct. The results underscore persistent deficiencies in logical hypothesis-refinement and information acquisition across frontier models.
Mathematical Interactive Proofs
The framework adapts interactive proofs to mathematics, allowing models to query judgments regarding intermediate claims. This contrasts sharply with the pass@k sampling paradigm that requires repeated full-solution generations. Under a matched token budget, interactive evaluation yields a substantial accuracy gap relative to pass@k, exposing underestimation of practical model ability by static sampling approaches.
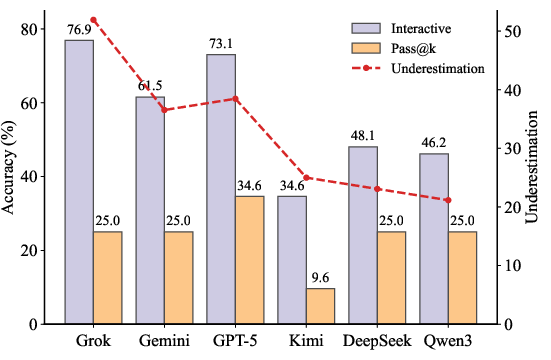
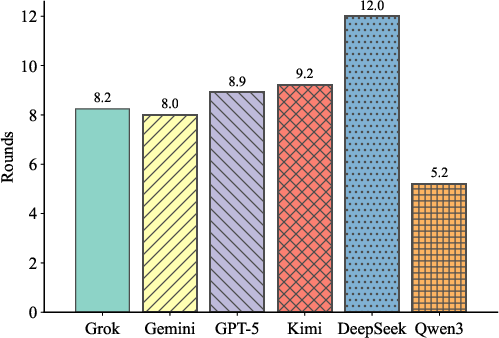
Figure 3: Accuracy under Interactive and Pass@k evaluation regimes; Pass@k significantly underestimates ability relative to interactive evaluation at matched budget.
Grok-4.1-fast achieves 76.9% accuracy, GPT-5-mini reaches 73.1%, and Gemini-3-flash outperforms Kimi-k2-thinking (34.6%). Qwen3-max, despite fewer turns required for correct solutions, exhibits limited generalization and performance across diverse instances. The design offers interpretable traces of hypothesis testing and error-correction, distinguishing robust reasoning from guessing.
Interactive Games: Poker and Trust Game
Texas Hold’em Poker
Poker is selected as a canonical imperfect-information benchmark for Theory of Mind and long-horizon strategic reasoning. Six LLMs compete across 10 tables (500 hands each), with performance assessed via average winnings, VPIP, fold rate, and latency. Gemini-3-flash leads on profit per hand and consistency, with Grok-4.1-fast and GPT-5-mini also posting positive returns. GPT-5-mini adopts the most aggressive profile (highest VPIP, lowest fold rate), while DeepSeek-v3.2 is excessively conservative.
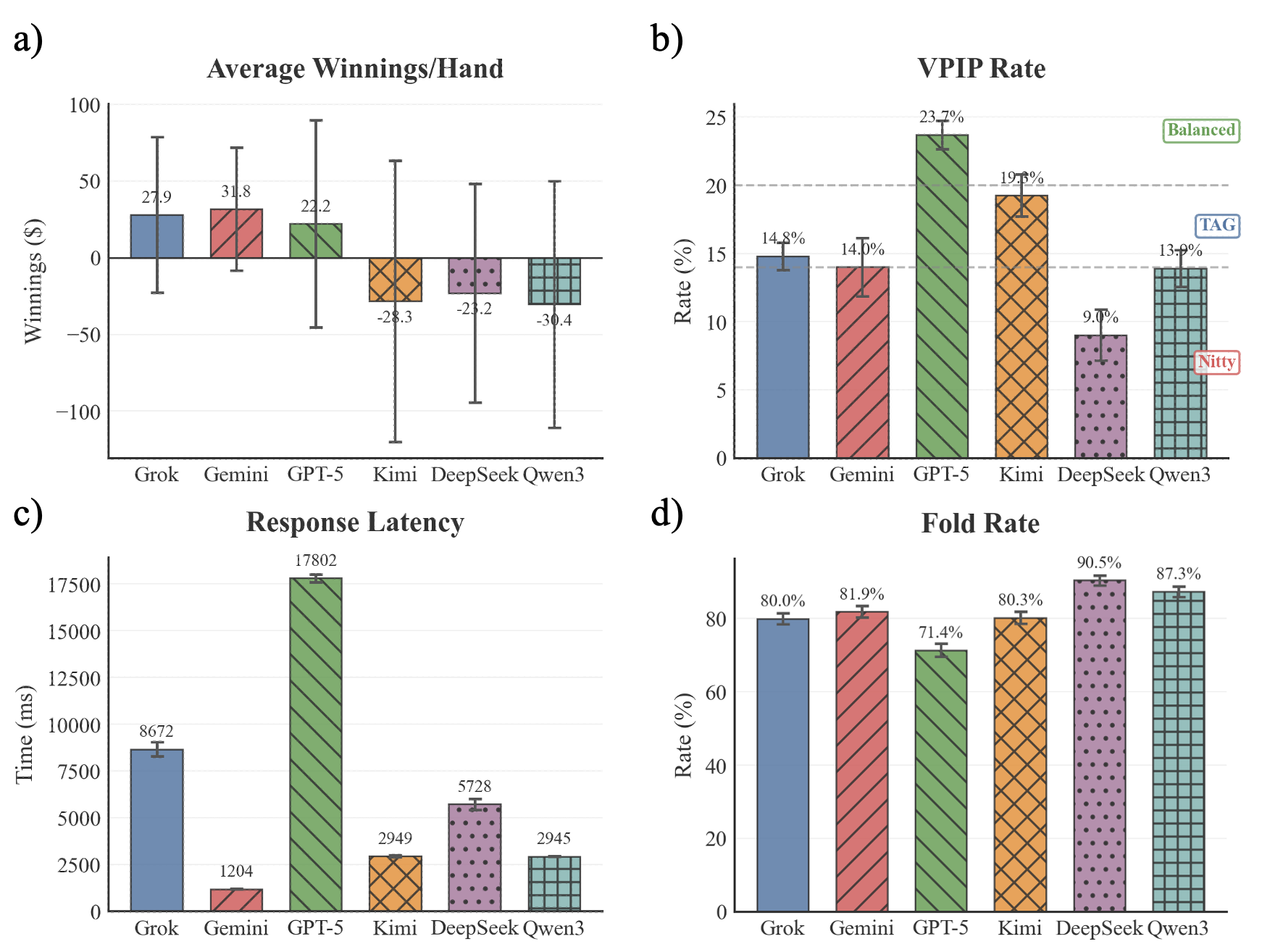
Figure 4: Comparison of six LLM poker agents across 10 tables: winnings, VPIP, latency, and fold rate; Gemini-3-flash, Grok-4.1-fast, and GPT-5-mini are consistently profitable.
The experiment demonstrates that shallow selectivity is inadequate; disciplined, adaptive strategies are essential for sustained profitability in complex, adversarial environments.
Trust Game: Iterated Prisoner’s Dilemma
The Trust Game evaluates adaptive behavior in repeated strategic interaction, with random horizon to avoid last-round effects. Models are scored by average discounted payoff, cooperation rate, and betrayal rate. Only Qwen3-max (1.867) and GPT-5-mini (1.836) outperform Grim Trigger (1.811) and Tit-for-Tat (1.782) baselines. Qwen3-max and GPT-5-mini manifest high cooperation and low betrayal rates; Gemini-3-flash and DeepSeek-v3.2 demonstrate less adaptive and cooperative strategies.
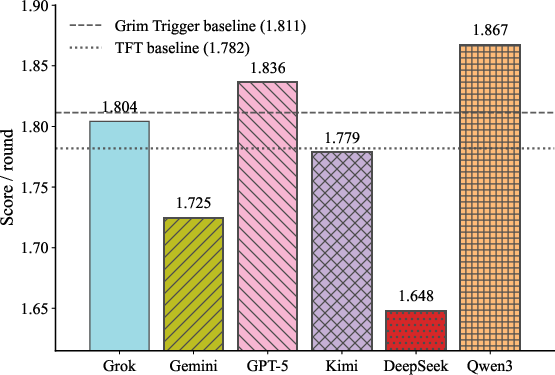
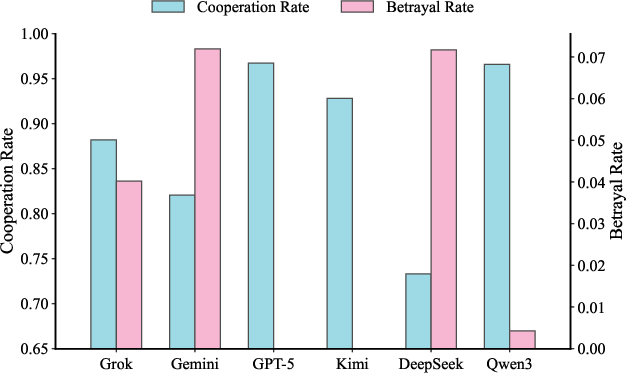
Figure 5: Average payoff per round in the Trust Game, with Grim Trigger and Tit-for-Tat baselines shown as dashed lines.
Behavioral breakdowns reveal persistent deficits in online adaptation and opponent modeling in many models, motivating ongoing refinement in agent training.
Comparison to Prior Benchmarks
The paper critiques static, preference-based, and agentic benchmarks for failing to isolate interactive reasoning capabilities. Interactive Benchmarks provide a theoretically principled evaluation protocol, formalizing interaction as budgeted sequential decision processes that generalize across domains. Unlike prior multi-turn evaluation benchmarks, which often entwine task-specific priors and reward shaping, this framework isolates the contribution of interaction and offers reproducible, objective comparison.
Implications and Future Directions
Interactive Benchmarks redefine model evaluation, quantifying intelligence as an information-acquisition and strategic reasoning process. The empirical results establish that current LLMs retain substantial room for improvement. Models that excel in static or passively sampled tasks are not robustly agentic. The framework's interpretability yields novel insights into reasoning efficiency, query strategies, and adaptive responses.
Practically, the protocol suggests integrating interactive reasoning objectives into training. Theoretically, it promotes unified evaluation across epistemic and strategic regimes, supporting deeper agentic intelligence. Research directions include expanding benchmark coverage, refining interaction optimization methods, and leveraging interactive traces for feedback-driven agent training.
Conclusion
Interactive Benchmarks represent a coherent evaluation architecture combining budgeted interaction, rigorous protocols, and reproducible metrics across logic, math, and games. The paradigm not only exposes limitations of static and preference-based evaluations but also quantifies agents' information-acquisition and strategic reasoning abilities. The persistent performance gaps highlight essential directions for both LLM architecture and training methodology, with implications for real-world deployment and future artificial intelligence systems (2603.04737).