Revisiting Shape from Polarization in the Era of Vision Foundation Models
Abstract: We show that, with polarization cues, a lightweight model trained on a small dataset can outperform RGB-only vision foundation models (VFMs) in single-shot object-level surface normal estimation. Shape from polarization (SfP) has long been studied due to the strong physical relationship between polarization and surface geometry. Meanwhile, driven by scaling laws, RGB-only VFMs trained on large datasets have recently achieved impressive performance and surpassed existing SfP methods. This situation raises questions about the necessity of polarization cues, which require specialized hardware and have limited training data. We argue that the weaker performance of prior SfP methods does not come from the polarization modality itself, but from domain gaps. These domain gaps mainly arise from two sources. First, existing synthetic datasets use limited and unrealistic 3D objects, with simple geometry and random texture maps that do not match the underlying shapes. Second, real-world polarization signals are often affected by sensor noise, which is not well modeled during training. To address the first issue, we render a high-quality polarization dataset using 1,954 3D-scanned real-world objects. We further incorporate pretrained DINOv3 priors to improve generalization to unseen objects. To address the second issue, we introduce polarization sensor-aware data augmentation that better reflects real-world conditions. With only 40K training scenes, our method significantly outperforms both state-of-the-art SfP approaches and RGB-only VFMs. Extensive experiments show that polarization cues enable a 33x reduction in training data or an 8x reduction in model parameters, while still achieving better performance than RGB-only counterparts.

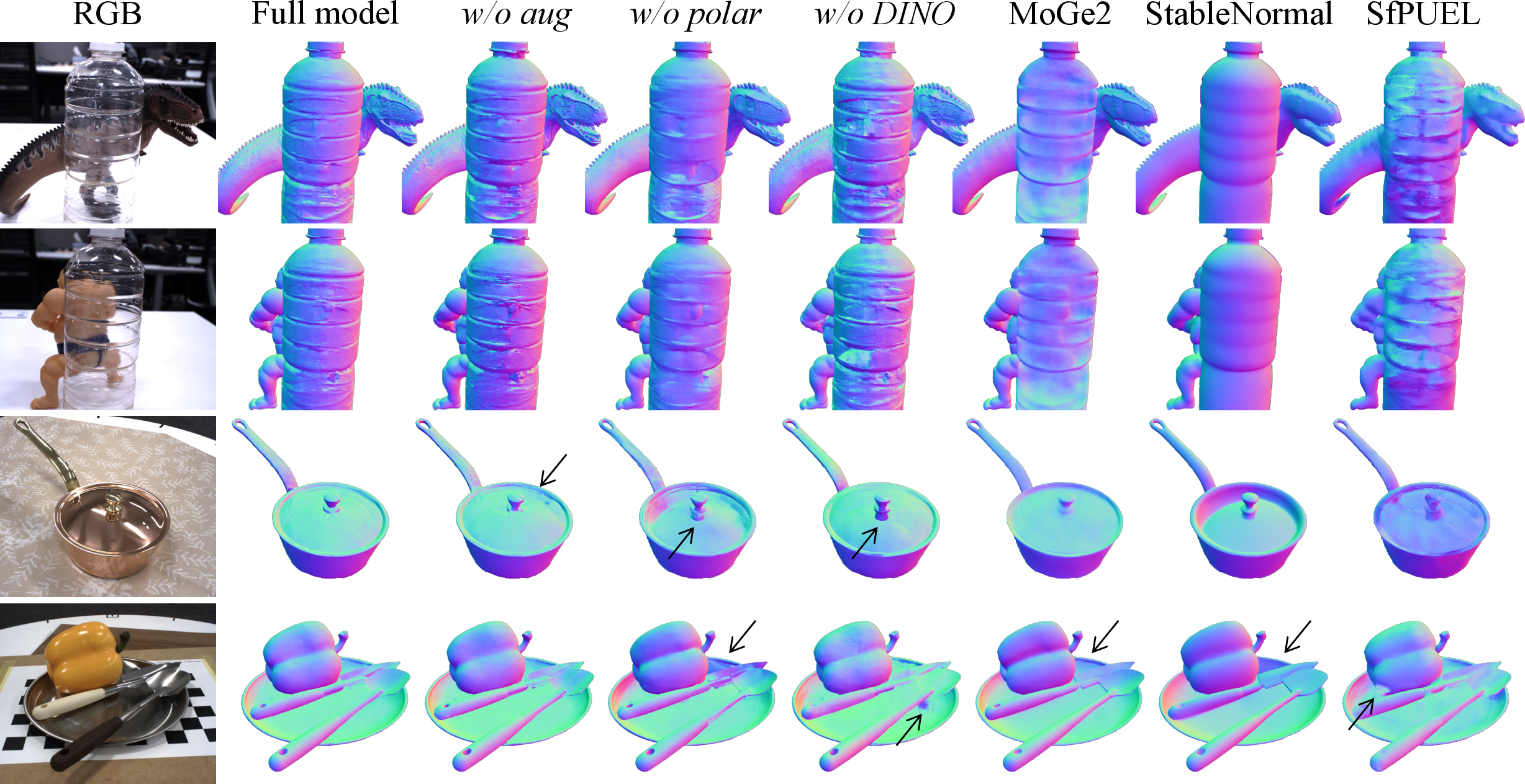

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to figure out the shape of objects from a single photo by using “polarized” light. The goal is to estimate surface normals—tiny arrows that tell you which way each small patch of a surface is facing—like the bristles on a porcupine. The authors prove that if you add polarization information (not just color), a small, fast model trained on a small dataset can beat today’s big, data-hungry vision foundation models that only use normal RGB images.
The big questions they asked
- Can adding polarization (how light waves are oriented) help a small model estimate object shapes better than huge models that only use color images?
- Why do earlier polarization-based methods lag behind big models, and can we fix that?
- How much can polarization reduce the need for massive training data and giant networks?
How did they do it?
A quick primer: What is polarization and why does it help?
Imagine light as tiny waves. Polarized light is when those waves wiggle mostly in one direction. Polarized sunglasses use this idea to cut glare. When light bounces off a surface, the way it gets polarized depends on the surface’s shape and material. That means polarization carries clues about the 3D shape—clues that plain color (RGB) doesn’t always have.
Two especially useful polarization cues are:
- Degree of Linear Polarization (DoLP): how strongly the light is polarized (0 to 1). Think of it as “how confident” the polarization signal is.
- Angle of Linear Polarization (AoLP): the direction the light’s waves prefer to vibrate. This direction shifts with surface orientation.
A special polarization camera can capture multiple images through tiny filters (like four mini sunglasses angles at once), so you get RGB plus DoLP and AoLP from a single shot.
The problem with earlier methods: the “domain gap”
Earlier polarization approaches often trained on fake (rendered) images that didn’t look enough like real life. Two gaps stood out:
- Unrealistic training objects/textures: Many synthetic datasets used simple, artificial 3D models with random textures that didn’t match the object’s shape.
- Missing sensor noise: Real polarization cameras add blur/noise and have limited precision. Synthetic images were too clean, so models didn’t learn to handle real-world imperfections.
Building better training data
The authors created a synthetic dataset called DTC-p with:
- 40,000 scenes rendered using 1,954 real-world 3D-scanned objects (so textures and geometry match).
- Realistic lighting environments from high-quality environment maps.
- Object-level scenes (one or more objects on ground, varied views).
Making synthetic data behave like real camera data
Instead of just slapping noise on the final images, they mimic the camera pipeline:
- Start from the polarized “views” the camera would see (like four angles).
- Add blur and noise there (this better matches how the real sensor corrupts signals).
- Convert to DoLP and AoLP afterward, just like a real camera would. This makes the noisy AoLP look more realistic—noisy where it should be, and not everywhere.
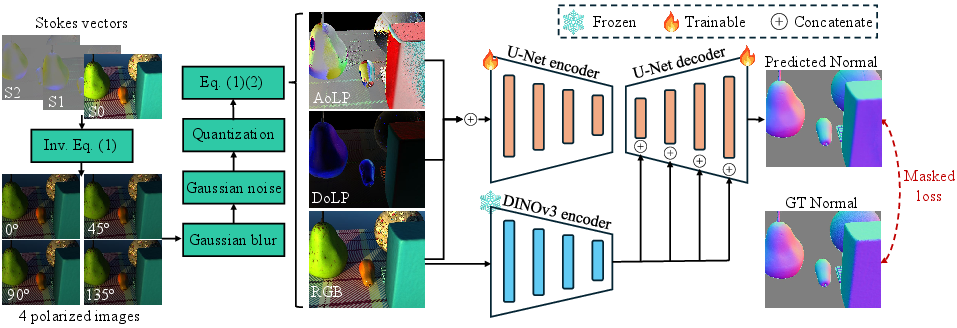
The model: simple, fast, and smart
They use a lightweight neural network that takes RGB + DoLP + AoLP as input and predicts a normal map (the directions of surface patches know where they point). It combines:
- A UNet (a common encoder–decoder network) for pixel-level details.
- Features from a pretrained vision model called DINOv3 (used only on the RGB part) to help generalize to new objects. The training goal is to make the predicted normal directions align with the ground truth (minimize the angle between them).
What did they find, and why is it important?
Here are the headline results:
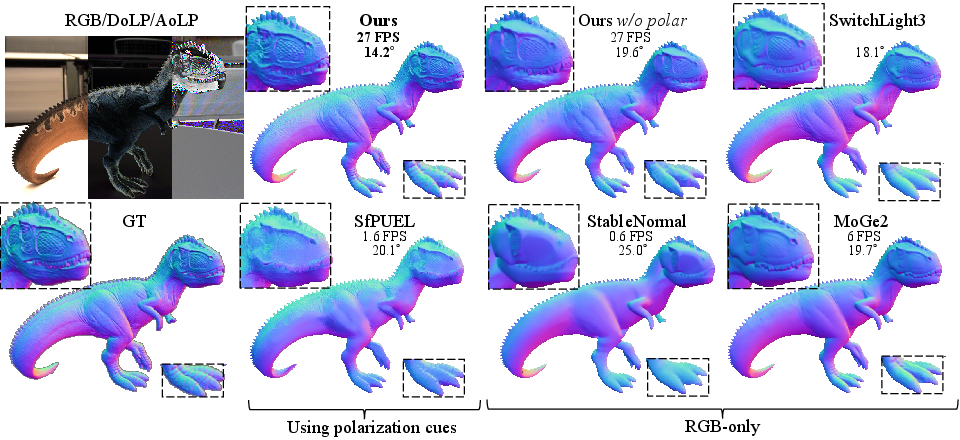
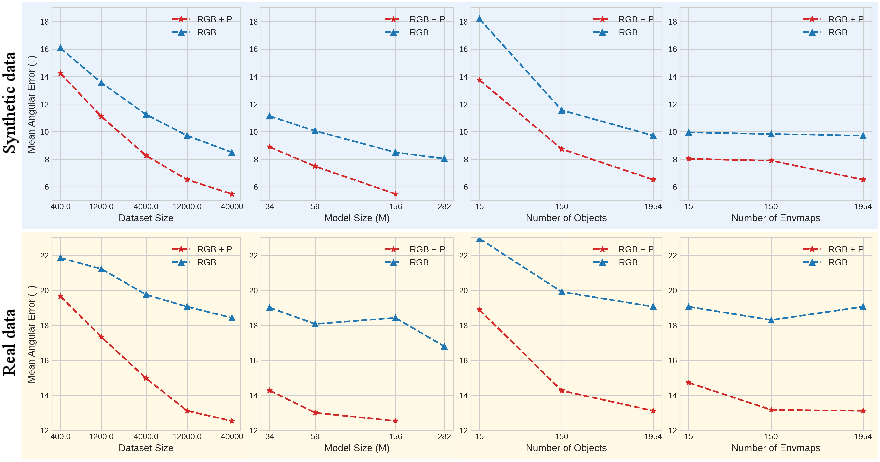
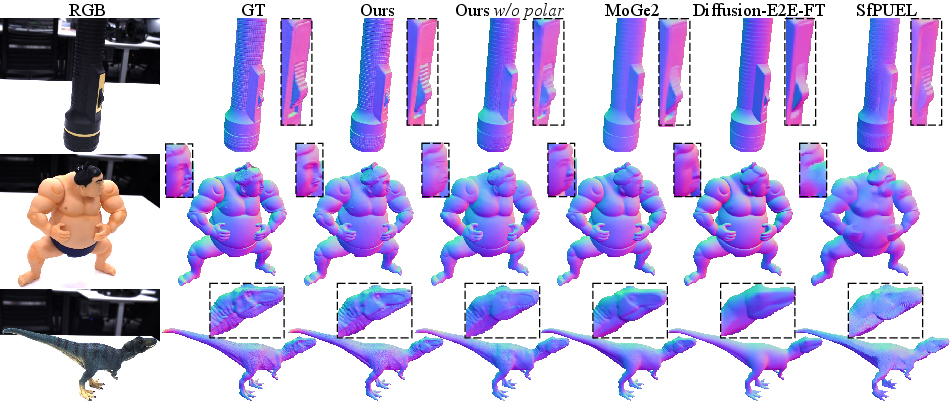
- Better accuracy with far less data: Their method beats the best polarization method and also beats a top RGB-only foundation model (MoGe2), while using about 0.45% as much training data as that VFM.
- Efficiency gains:
- With polarization, you can use about 33× less training data and still match or beat RGB-only counterparts.
- You can also shrink the model by about 8× and keep strong performance.
- Faster than diffusion-based methods: Generative models (like diffusion) can be accurate but slow. This method is fast enough for practical use.
- Closing the synthetic-to-real gap: The realistic dataset and sensor-aware augmentation reduce the “it works on fake images but not on real ones” problem.
- What matters most:
- Polarization cues give the biggest boost.
- The DINOv3 features help generalize to new objects.
- Adding blur/noise before polarization processing is crucial for realism.
- More diverse, realistic objects improve performance more than just adding lots of random lighting.
Why this matters: Many applications—AR/VR, robotics, and quality inspection—need precise, fast shape understanding. This work shows you don’t always need gigantic datasets or slow models if you use the right physics signals (polarization) and realistic training data.
What does this mean for the future?
- Physics + AI beats brute force: Combining a physical cue (polarization) with deep learning can reduce the need for massive data and GPU time. That’s good for cost, speed, and sustainability.
- Specialized sensors are worth it: Even in the era of big vision models, a polarization camera can give you better shape details with smaller, faster models.
- Better datasets matter: Realistic, diverse 3D objects (not just many synthetic scenes) are key to making models work in the real world.
Limitations and what’s next
- Scene-level understanding: The model focuses on objects. It can struggle with large backgrounds (like walls and buildings) because it wasn’t trained on whole scenes.
- Tricky materials and weak signals: Transparent objects and metals weren’t part of training, though the model still did surprisingly well on some. If the object barely polarizes light (like a fuzzy white ball), the polarization signal becomes very weak and noisy, and the benefit drops. Training with more material types and capturing stronger signals would help.
- Better fusion: They used a straightforward way to combine polarization with DINOv3 features; smarter fusion could improve results further.
Key terms, simplified
- Surface normal: A tiny arrow at each pixel that points straight out of the surface—like the direction a small sticker would face if you pressed it onto the object.
- Polarization: The direction light waves wiggle. Reflections change polarization based on shape and material, so it’s a useful shape clue.
- DoLP (Degree of Linear Polarization): How strong the polarization is (0 = none, 1 = very strong).
- AoLP (Angle of Linear Polarization): The direction the light prefers to vibrate in; it shifts with surface orientation.
- Domain gap: The difference between the data you train on and the real-world data you test on. Smaller gap = better real-world performance.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper advances single-shot shape from polarization (SfP) with a new synthetic dataset, sensor-aware augmentation, and DINOv3 fusion, but it leaves several concrete gaps and questions open for future research:
- Scene-level generalization: Training and evaluation focus on object-level inputs; the method fails to correctly infer background structures in scenes. A scene-level dataset with clutter, occlusions, varied scales, and global layout cues is missing.
- Material coverage in training: Training renders use a dielectric pBRDF only; transparent, translucent, and conductive materials are excluded. How to physically simulate (or capture) these materials and incorporate them into training remains open.
- Quantitative OOD assessment: Robustness to transparent and metal objects is shown qualitatively only. A quantitative benchmark and protocol for out-of-distribution materials and geometries is lacking.
- Weak/near-unpolarized targets: When DoLP≈0 the AoLP becomes unreliable and performance collapses. There is no mechanism to detect low-polarization regimes, estimate per-pixel confidence, or adaptively fall back to RGB-only inference.
- Sensor pipeline fidelity: Augmentation adds Gaussian blur/noise and 12-bit quantization after reconstructing four polarization images, but does not model:
- Intensity-dependent shot noise and read noise
- Micro-polarizer mosaic sampling/demosaicing artifacts
- Polarizer angle misalignment, extinction ratio limits, polarization cross-talk, PRNU/DSNU
- Spectral dependence and wavelength-specific polarization effects
- A more faithful, parameterized sensor model or learned noise simulator is needed.
- Cross-sensor generalization: All real data were captured on a single FLIR/Sony 12-bit sensor. Generalization to other polarization cameras (different microgrid patterns, bit-depths, optics, and calibrations) is untested.
- Lighting diversity: Training uses HDR environment maps; the impact of area lights, indoor point sources, HDR/saturation, shadows, interreflections, and mixed lighting is not systematically studied.
- Geometry priors and consistency: The network predicts per-pixel normals without enforcing integrability or shape consistency. How to integrate depth/shape constraints (e.g., Poisson integration, normal-to-depth consistency) to reduce noise/artifacts is unexplored.
- Fusion architecture: The method uses simple multi-scale concatenation of DINOv3 and UNet features. Whether cross-attention, gated fusion, co-embeddings, or transformer-based cross-modal fusion improves generalization and detail recovery is untested.
- Polarization-specific pretraining: The DINOv3 encoder is RGB-pretrained and frozen. Joint pretraining or adaptation with polarization inputs, self-supervised objectives on polarized data, or multimodal pretext tasks remain unexplored.
- Dataset availability and reproducibility: It is unclear whether DTC-p (40K scenes, 1,954 scanned objects) and the exact augmentation parameters will be released. Reproducibility and community benchmarking depend on public access.
- Real-world evaluation scale: The new real test set with ground truth contains only five scenes; public test sets emphasize constrained setups. A larger, diverse real benchmark with high-fidelity ground truth and standardized evaluation is needed.
- Scaling laws for polarization: The paper shows gains at 40K scenes and explores limited ablations. A systematic study of data/model scaling for polarization (e.g., how performance scales with objects, materials, lighting, and model capacity) is missing.
- Training-label fidelity: Synthetic training uses a single pBRDF and renderer settings; the sensitivity of performance to BRDF realism (e.g., anisotropy, subsurface scattering, multi-bounce polarization) is not analyzed.
- Camera orientation and invariance: AoLP is defined relative to sensor axes; robustness to arbitrary camera roll, calibration drift, and per-device orientation offsets is not evaluated.
- Radiometric/white-balance shifts: Inputs are normalized with ImageNet statistics; robustness to color calibration differences, auto-exposure/white-balance variation, and sensor spectral response shifts is not characterized.
- Failure-aware inference: The model provides no uncertainty estimates or confidence maps to flag unreliable regions (e.g., low-DoLP areas or severe noise). Designing calibrated uncertainty and failure detection remains open.
- Downstream utility: Although normals are targeted at AR/VR/robotics/inspection, no downstream tasks (e.g., grasping, relighting, inspection pass/fail) are evaluated to validate practical impact.
- Runtime and deployment: Inference speed is reported on a V100 at a single resolution; performance on CPUs/edge devices, memory footprints, and speed–accuracy trade-offs across model variants are not fully characterized.
- Integration with other sensors: The method focuses on single-shot polarization+RGB. How to combine polarization with minimal extra cues (e.g., ToF, monocular depth priors, events) to resolve remaining ambiguities remains open.
- Pi-ambiguity and disambiguation analysis: The learning-based model implicitly resolves classic SfP ambiguities (e.g., π-ambiguity), but there is no analysis of failure modes or principled disambiguation strategies under challenging materials and lighting.
- Raw-data learning: The approach operates on derived DoLP/AoLP. Learning directly from raw micro-polarizer mosaics (pre-demosaic) to exploit sensor-specific statistics and reduce processing-induced artifacts is not explored.
- Spectral extension: Only RGB linear polarization is considered; leveraging NIR or multi-spectral polarization to boost signal on weakly polarizing surfaces is left unexplored.
- Domain fairness versus VFMs: Comparisons to RGB-only VFMs are conducted on object-centric data; how conclusions transfer to scene-centric benchmarks (where VFMs excel at global context) remains an open question.
These gaps suggest concrete next steps: build scene- and material-diverse polarized datasets with public release; develop physically grounded or learned sensor models; design confidence-aware and fusion-improved architectures; establish quantitative OOD and multi-sensor benchmarks; and evaluate downstream and deployment performance.
Practical Applications
Immediate Applications
The paper’s contributions—a lightweight, single-shot polarization+RGB model, a sensor-aware augmentation pipeline, and a realistic synthetic training set—enable several deployable use cases today, especially where polarization cameras are available and objects are opaque dielectrics.
- Industrial inspection and quality control (Manufacturing)
- Use case: Replace multi-light photometric setups with a single polarization camera to generate per-pixel normal maps for detecting dents, scratches, warping, and texture copying on painted/plastic parts.
- Tools/products/workflows: “PolarNormals SDK” integrated into existing vision stations; on-line inference via NVIDIA Jetson or edge GPU; plugin for HALCON/OpenCV; calibration workflow using the paper’s pre-Stokes augmentation recipe to tune robustness to plant lighting/noise.
- Assumptions/dependencies: Requires a polarization camera (e.g., Sony PolarSens sensor); targets should be opaque dielectric surfaces with sufficient DoLP; object-level framing (not full scenes); adequate SNR and lighting consistency; compute budget for real-time inference.
- Robotic manipulation and bin picking (Robotics, Logistics)
- Use case: Feed high-fidelity normal maps into grasp planning and contact patch estimation for textureless/reflective plastic objects; reduce failure on glossy packaging.
- Tools/products/workflows: ROS node that ingests I0/I45/I90/I135 and outputs normals; integration with grasp planners (e.g., GPD, Dex-Net); training with a small in-house polarized dataset augmented using the paper’s sensor-aware pre-Stokes pipeline.
- Assumptions/dependencies: Object-level views; opaque dielectrics; moderate lighting variation; polarization camera mount on robot; latency budget compatible with interactive frame rates.
- Fast asset digitization for DCC pipelines (AR/VR, Gaming, E-commerce content)
- Use case: Capture per-object normal maps in a single shot to accelerate PBR material authoring, detail transfer, and relighting for 3D assets.
- Tools/products/workflows: Polarization capture rig + turntable; Blender/Unreal/Unity importer that maps predicted normals into tangent-space normal textures; batch processing pipeline for SKU digitization.
- Assumptions/dependencies: Opaque dielectric objects; background segmentation or masking; studio lighting or HDRI control; not a full geometry solution—normals complement depth/meshing.
- Rapid geometry cues for inverse rendering and relighting (VFX, Product visualization)
- Use case: Provide accurate object-level normals to bootstrap inverse rendering solvers, speed BRDF fitting, and improve relighting fidelity.
- Tools/products/workflows: Integration with commercial tools (e.g., SwitchLight-like pipelines) as a normal prior; automatic consistency checks for texture copying artifacts.
- Assumptions/dependencies: Registration between capture and solver; best on opaque dielectrics; sensitivity to low DoLP.
- Low-data, small-model training for normal estimation (Software/AI, Academia)
- Use case: Train high-accuracy normal estimators with ~40K scenes and compact networks by adding polarization, reducing compute and data collection budgets.
- Tools/products/workflows: Adopt the hybrid UNet + frozen DINOv3 backbone; use the provided pre-Stokes blur/noise/quantization augmentation to close synthetic-to-real gaps; curriculum to scale from 34M–282M parameters as needed.
- Assumptions/dependencies: Access to polarization inputs during deployment; DINOv3 licensing/compliance; similar domain between synthetic assets and target objects.
- Best-practice synthetic data generation for polarized vision (Academia, Software/AI)
- Use case: Build synthetic polarized datasets that generalize by prioritizing 3D-scanned, geometry-consistent textures and applying noise/blur before Stokes/AoLP/DoLP computation.
- Tools/products/workflows: Mitsuba3 polarized renderer; asset curation emphasizing object diversity over sheer scene count; augmentation blocks implemented in data loaders.
- Assumptions/dependencies: Availability of scanned assets (e.g., Digital Twin Catalog or equivalents); renderer support for polarized light; compute budget for rendering.
- Sensor and algorithm benchmarking (Metrology, Camera vendors)
- Use case: Emulate real sensor characteristics (optics blur, shot noise, 12-bit quantization) in silico to benchmark camera SKUs and algorithm robustness.
- Tools/products/workflows: Pre-Stokes augmentation as a standardized bench; MAE/accuracy metrics matched to the paper; regression testing across firmware changes.
- Assumptions/dependencies: Detailed sensor specs; agreement on benchmark protocols; access to representative 3D assets/HDRIs.
- Field robotics under challenging materials (e.g., warehouse plastics) (Robotics)
- Use case: Improve perception of glossy plastic shrink-wrapped items where RGB-only models over-smooth normals.
- Tools/products/workflows: Onboard polarized cameras; fusion of normals with RGB/depth for grasp safety checks.
- Assumptions/dependencies: Sufficient polarization signal; controlled vantage (object-level); illumination that maintains DoLP above noise.
- Education and research (Academia)
- Use case: Teach physics-based sensing and robust multimodal fusion; replicate results with smaller compute and datasets.
- Tools/products/workflows: Course labs using polarization cameras; exercises on pre-Stokes augmentation and domain gap analysis; reproducible SfP baselines.
- Assumptions/dependencies: Access to hardware or prerecorded polarized datasets; open-source code availability (if released).
- Niche maker/atelier digitization (Prosumer/Design)
- Use case: Makers capture fine surface details of props/models for 3D printing finishing workflows.
- Tools/products/workflows: Desktop polarized camera rigs; batch normal extraction and texture baking.
- Assumptions/dependencies: Specialized hardware; constrained to non-metallic opaque parts; small-scale adoption.
Long-Term Applications
These require further research, scaling to scenes/materials, hardware evolution (e.g., higher-bit sensors), or more extensive datasets beyond object-level dielectrics.
- Scene-level normal estimation for AR occlusion and robotics mapping (AR/VR, Robotics)
- Potential: Extend from object-level to room/urban-scale normals for better occlusion, physics interactions, and traversability analysis.
- Emergent tools: Polarization-aware scene normal networks with global context (e.g., transformers); SLAM fusion of polarized normals and depth.
- Dependencies: New training datasets with scene-scale captures; handling of background structures; robust global lighting variation.
- Automotive perception and road surface understanding (Automotive)
- Potential: Detect thin-film reflections, wetness, and surface micro-geometry on roads and obstacles with polarization-assisted normals.
- Emergent tools: Wide-FOV polarized sensors; multi-sensor fusion (LiDAR, radar, RGB) with polarization priors.
- Dependencies: Outdoor robustness to low DoLP regions; scene-level generalization; automotive-grade sensors and calibration.
- Inspection of metals and transparent/glassy materials (Manufacturing, Electronics)
- Potential: Extend model and training data to conductors and transparent objects for detecting micro-scratches on metals/glass, lens curvature, and wafer topography.
- Emergent tools: Dataset expansions with conductor/transparent pBRDFs; polarization-aware inverse rendering pipelines.
- Dependencies: New rendering models and real captures for these materials; robust handling of specular ambiguities; tailored augmentation.
- Mobile and wearable deployment (Consumer AR, Field service)
- Potential: Integrate compact polarization sensors into smartphones/AR glasses for on-device normals supporting relighting and object scanning.
- Emergent tools: Mobile-optimized inference (NNAPI/CoreML), ISP-level pre-Stokes processing; app SDKs for developers.
- Dependencies: Hardware integration of micro-polarizer arrays; power/thermal constraints; low-light SNR; UX and calibration.
- Weak-signal polarization imaging (Healthcare, Cultural heritage, Robotics)
- Potential: Reliably estimate normals when DoLP is low (e.g., biological tissues, matte white objects) via better sensors (14–16 bit ADCs), coded illumination, or computational imaging.
- Emergent tools: Joint ToF + polarization cameras; burst imaging with coded polarizers; denoising priors tailored to AoLP statistics.
- Dependencies: Hardware advances; new learning objectives that account for near-zero DoLP; data collection with controlled lighting.
- Multimodal foundation models with physics priors (Software/AI)
- Potential: Generalize the paper’s efficiency gains to other sensing modalities (e.g., ToF, event, hyperspectral) via pre-signal augmentation and physics-guided inputs.
- Emergent tools: Unified sensor-aware augmentation libraries; compact multimodal backbones with frozen pretrained RGB encoders.
- Dependencies: Cross-modal datasets; standardized augmentation protocols; licensing for pretrained encoders.
- Few-view 3D reconstruction and inverse rendering (Graphics, Metrology)
- Potential: Use single-shot normals to initialize NeRF/3DGS and reduce views/time for high-fidelity reconstruction and material estimation.
- Emergent tools: Polarization-initialized radiance field solvers; reconstruction workflows for reflective objects.
- Dependencies: Algorithmic fusion with radiance fields; reliable alignment; material-diverse training.
- Cinematography and on-set VFX capture (Media/Entertainment)
- Potential: Rapid capture of normals for props and small set pieces to aid relighting and compositing.
- Emergent tools: Portable polarized rigs; DCC plugins to ingest normals and auto-generate bump/roughness maps.
- Dependencies: Robustness under production lighting; expansion to fabrics/hair; integration with production pipelines.
- Standards, benchmarks, and procurement guidelines (Policy, Industry consortia)
- Potential: Establish standardized polarized datasets, augmentation practices (pre-Stokes noise/blur/quantization), and evaluation metrics for industrial adoption.
- Emergent tools: Open benchmarks akin to KITTI/ETH3D for polarization; best-practice documents for sensor vendors and end users.
- Dependencies: Community coordination; open licensing for assets; multi-vendor participation.
- Real-time, on-device inverse rendering for consumer apps (Consumer software)
- Potential: One-shot normals plus learned priors enable material-aware relighting and AR try-on effects without cloud compute.
- Emergent tools: On-device inference stacks; creative apps exposing relighting sliders driven by normals.
- Dependencies: Device hardware with polarized sensors; power-efficient models; UX validation.
- Agricultural and materials science phenotyping (Agritech, R&D)
- Potential: Quantify micro-geometry (e.g., leaf surface features, coatings) in the field to assess health or process quality.
- Emergent tools: Rugged polarized cameras; pipelines for outdoor domain adaptation.
- Dependencies: Outdoor domain generalization; low-DoLP handling; annotated datasets for target domains.
Notes on feasibility across applications
- The method excels on object-level, opaque dielectric materials under conditions where polarization cues are measurable. Scene-level understanding, metals/transparencies, and nearly unpolarized targets require dataset expansion and/or hardware improvements.
- Real-time/interactive inference was demonstrated on a V100 GPU at 512×612 with FP16; embedded deployment will need optimization and may alter FPS.
- The sensor-aware augmentation should be applied before Stokes/AoLP/DoLP computation to realistically simulate sensor noise; this is a critical dependency for synthetic-to-real transfer.
- Data/parameter efficiency gains (≈33× less data or ≈8× fewer parameters than RGB-only VFMs at similar accuracy) are contingent on having polarization inputs at training and inference time.
Glossary
- 3D Gaussian Splatting (3DGS): A real-time radiance field representation that renders scenes by splatting 3D Gaussians in screen space. "based on NeRF \cite{mildenhall2020nerf} or 3DGS \cite{kerbl20233d}."
- Affine-invariant point map: A 3D representation that remains consistent under affine transforms, used to stabilize geometry predictions. "introducing an affine-invariant point map as a new 3D representation (MoGe \cite{wang2025moge, wang2025moge2})."
- Angle of Linear Polarization (AoLP): The orientation angle of the linear polarization component of light, derived from Stokes parameters and correlated with surface normals. "the Degree of Linear Polarization (DoLP) and the Angle of Linear Polarization (AoLP), which are widely used in SfP due to their strong correlation with surface geometry, are computed as"
- ConvNeXt: A convolutional backbone architecture used for feature extraction in visual models. "the DINOv3 \cite{simeoni2025dinov3} branch adopts a ConvNeXt (base size) \cite{liu2022convnet} backbone."
- Cosine loss: A loss function that penalizes angular discrepancy via cosine similarity between predicted and ground-truth normals. "We supervise the predicted normal using cosine loss,"
- Degree of Linear Polarization (DoLP): The proportion of light intensity that is linearly polarized, computed from Stokes parameters and informative of surface properties. "the Degree of Linear Polarization (DoLP) and the Angle of Linear Polarization (AoLP), which are widely used in SfP due to their strong correlation with surface geometry, are computed as"
- Diffuse–specular ambiguity: The ambiguity between diffuse and specular reflection components that complicates polarization-based normal recovery. "diffuseâspecular ambiguity and ambiguity,"
- Diffusion models: Generative models that learn data distributions via iterative denoising, providing strong priors for geometry estimation. "Another line of work leverages priors from diffusion models \cite{ho2020denoising} for surface normal estimation."
- DINOv3: A pretrained self-supervised vision model whose features serve as a prior to improve generalization. "we further integrate features from the recently pretrained model DINOv3 \cite{simeoni2025dinov3} as a prior into our model."
- Environment map: A panoramic illumination representation used to light synthetic scenes during rendering. "Environment maps are randomly rotated."
- Inverse rendering: Estimating scene properties (geometry, materials, lighting) from images by matching rendered and observed imagery. "a commercial inverse rendering tool (SwitchLight3 \cite{beeble_switchlight3})."
- LiDAR: An active depth-sensing modality using laser pulses; used as an auxiliary cue for geometry. "and lidar inputs \cite{scheuble2024polarization}."
- Mean angular error (MAE): The average angular difference between predicted and ground-truth surface normals; lower is better. "we report the mean angular error (MAE) between the estimated and ground truth normals."
- Mitsuba3: A physically based renderer (with polarization support) used to synthesize training and evaluation data. "All scenes are rendered using Mitsuba3 \cite{jakob2022dr} in polarized mode"
- Near-coaxial camera–projector setup: A hardware arrangement with nearly aligned optical axes to reduce ambiguities in polarization-based reconstruction. "a near-coaxial cameraâprojector setup \cite{baek2018simultaneous}."
- NeRF: Neural Radiance Fields; a neural volumetric representation for view synthesis and reconstruction. "based on NeRF \cite{mildenhall2020nerf} or 3DGS \cite{kerbl20233d}."
- pBRDF: A polarized bidirectional reflectance distribution function modeling polarization-dependent reflectance. "a pBRDF model proposed by Baek \etal \cite{baek2018simultaneous}."
- Photometric stereo: A method estimating surface normals from images under varying illumination directions. "photometric stereo priors \cite{lyu2024sfpuel},"
- Pi ambiguity: A 180-degree ambiguity in the recovered polarization angle that flips normal direction. " ambiguity,"
- Polarization extinction ratio: A measure of a polarizer’s ability to transmit one polarization state while blocking the orthogonal one; degradation lowers signal fidelity. "polarization extinction ratio degradation,"
- Shape from polarization (SfP): Recovering surface shape or normals from polarization cues in images. "This task is known as shape from polarization (SfP)."
- Shot noise: Photon-counting noise inherent to sensors that disproportionately affects weak polarization signals. "such as shot noise and lens blur."
- Stokes vector: A vector representation of the polarization state of light (for linear polarization, typically [s0, s1, s2]). "The polarization state of light is commonly represented by Stokes vectors."
- Time-of-flight sensors: Depth sensors measuring distance via light travel time; can disambiguate polarization-based estimates. "time-of-flight sensors \cite{kadambi2015polarized, baek2022all}"
- UNet: An encoder–decoder convolutional architecture with skip connections for dense prediction tasks. "a UNet \cite{ronneberger2015u}"
- Vision foundation models (VFMs): Large pretrained vision models that generalize across tasks and datasets, often requiring substantial data and compute. "vision foundation models (VFMs)."
Collections
Sign up for free to add this paper to one or more collections.