KARL: Knowledge Agents via Reinforcement Learning
Abstract: We present a system for training enterprise search agents via reinforcement learning that achieves state-of-the-art performance across a diverse suite of hard-to-verify agentic search tasks. Our work makes four core contributions. First, we introduce KARLBench, a multi-capability evaluation suite spanning six distinct search regimes, including constraint-driven entity search, cross-document report synthesis, tabular numerical reasoning, exhaustive entity retrieval, procedural reasoning over technical documentation, and fact aggregation over internal enterprise notes. Second, we show that models trained across heterogeneous search behaviors generalize substantially better than those optimized for any single benchmark. Third, we develop an agentic synthesis pipeline that employs long-horizon reasoning and tool use to generate diverse, grounded, and high-quality training data, with iterative bootstrapping from increasingly capable models. Fourth, we propose a new post-training paradigm based on iterative large-batch off-policy RL that is sample efficient, robust to train-inference engine discrepancies, and naturally extends to multi-task training with out-of-distribution generalization. Compared to Claude 4.6 and GPT 5.2, KARL is Pareto-optimal on KARLBench across cost-quality and latency-quality trade-offs, including tasks that were out-of-distribution during training. With sufficient test-time compute, it surpasses the strongest closed models. These results show that tailored synthetic data in combination with multi-task reinforcement learning enables cost-efficient and high-performing knowledge agents for grounded reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “KARL: Knowledge Agents via Reinforcement Learning”
1) What is this paper about?
This paper introduces KARL, a computer system that acts like a smart research assistant for companies. Instead of guessing answers, it searches through real documents, gathers evidence, and reasons step by step to give grounded, trustworthy answers. The authors also build a new test suite, called KARLBench, to fairly measure how good such assistants are across many kinds of tough, real-world search-and-reason tasks.
2) What were the researchers trying to find out?
In plain terms, they asked:
- Can we train an AI assistant that’s good at many different “research” jobs, not just one?
- Can it find and use information from large collections of company documents, not just the public internet?
- Can we teach it efficiently (without wasting lots of time and money) and still get top-quality results?
- Will a system trained on a mix of search styles handle new, unseen tasks better than a system trained on just one?
3) How did they do it?
Think of teaching KARL like training a well-rounded athlete:
- You set up varied drills (different tasks).
- You create realistic practice materials (hard questions with real evidence).
- You coach it using feedback about what worked and what didn’t.
- During a game, you let it think in parallel and pick the best move.
Here’s what that looks like in AI terms:
- A new benchmark: KARLBench
- Find the one item that fits many rules (constraint-driven search)
- Write a careful report using pieces from many documents (cross-document synthesis)
- Do math with numbers in long tables (tabular reasoning)
- Find all items that match a rule (exhaustive retrieval)
- Follow instructions hidden across tech docs (procedural reasoning)
- Pull facts from messy internal notes (enterprise fact aggregation)
- One simple tool, used cleverly: vector search Imagine an ultra-fast “index” that finds the most relevant chunks of text when you type a query. KARL has only this tool. It asks the search engine for pieces of documents, reads them, asks again, and keeps reasoning. This isolates what’s being tested: smart searching and grounded reasoning.
- Keeping its “memory” tidy: compression Long research can overflow the model’s context window (its short-term memory). KARL learns to summarize its own past steps when things get too long—like a student making notes to keep track of what matters.
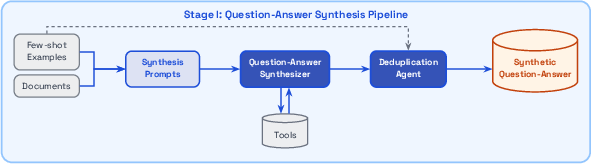
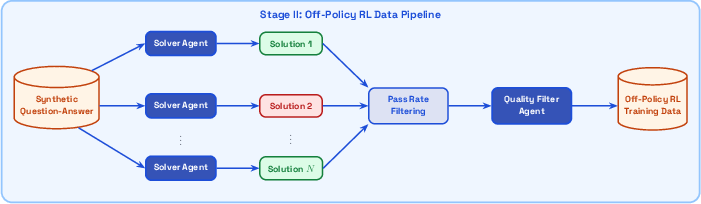
- Making high-quality training data (agentic synthesis) The system creates its own practice questions and answers by: 1) Exploring the document collection and proposing new questions plus answers grounded in retrieved evidence. 2) Trying to solve those questions multiple times. If a question is too easy or nearly impossible, it’s thrown out. A separate check filters out poor-quality or ambiguous ones. This is like a coach inventing drills from the team’s playbook, then keeping only the exercises that challenge—but don’t overwhelm—the player.
- How KARL learns: off-policy reinforcement learning (RL)
- Stable for large models
- Efficient with big batches of past experiences
- Easy to extend to multiple tasks at once
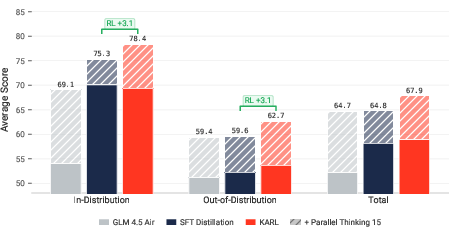
- Multi-task training Instead of training on one type of search, KARL trains on different ones together. This is like cross-training—improving fitness in a way that helps in new, unseen sports. The authors show this helps the model generalize better to tasks it wasn’t explicitly trained on.
- “Thinking harder” at test time
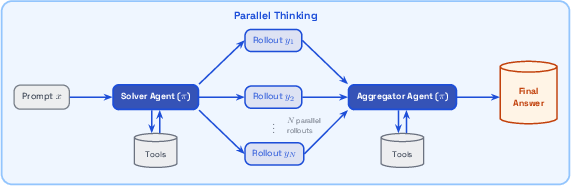
- Parallel Thinking: It generates multiple possible answers in parallel and then uses what it found to build a better final answer. Unlike simple voting, the final step can create an even better, evidence-based response.
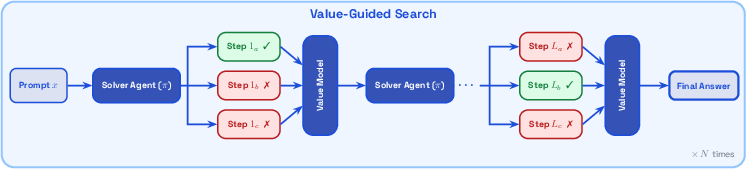
- Value-Guided Search: It trains a small helper model to score how promising each partial idea is and uses that to pick better next steps, like a coach on the sidelines steering the play.
- Strong, fast infrastructure The team built a fast, consistent system to run huge numbers of long searches, and a framework that keeps the behavior identical across training, evaluation, and deployment. That avoids surprises when moving from the lab to real use.
4) What did they find, and why is it important?
- KARLBench shows wide coverage of “grounded reasoning” It tests skills that matter for companies (finance, tech docs, biomedical summaries, internal notes, etc.). This gives a balanced picture of an assistant’s real abilities.
- Training across different search styles helps generalization Models trained on varied tasks performed better on new, held-out tasks than models trained on just one. This matters because real jobs rarely look exactly like the practice set.
- Synthetic, grounded data works The agent-made training data—carefully filtered and tied to retrieved evidence—helped the system learn reliably without hand-labeling tons of examples.
- Off-policy RL was efficient and stable The training method handled large models without the usual tricks, saving time and engineering complexity.
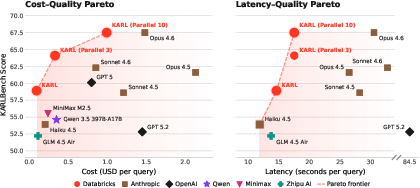
- Competitive performance at lower cost and latency Compared to top closed-source systems (like Claude 4.6 and GPT 5.2), KARL hit a “Pareto-optimal” balance—meaning it offered better or equal quality for the same or lower cost and speed. With more test-time compute (like more parallel rollouts), it matched or even beat the strongest models.
Why it matters: This shows you can build powerful, trustworthy research assistants that work well across many tasks, use real evidence, and don’t break the bank.
5) What’s the big picture impact?
- For companies: KARL-style systems can help teams find facts, do calculations from long reports, follow procedural steps, and summarize findings using their private data. That saves time, improves accuracy, and keeps sensitive information in-house.
- For AI research: The work suggests a recipe that scales: use grounded synthetic data, train with stable off-policy RL across multiple tasks, and add smart test-time strategies when you need extra quality. It also highlights the importance of evaluating across many skills—not just one benchmark.
- For the future: The approach could extend to more tools (like structured databases or code execution), richer document traversal, and stronger privacy controls. It points toward AI assistants that are not only clever, but also careful, explainable, and practical in real workplaces.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Evaluation constrained to a single tool: The agent is restricted to vector search only; it is unclear how KARL performs with richer toolsets (e.g., web browsing, document traversal, table extraction/SQL, code execution, OCR, or multi-tool orchestration).
- Closed-corpus focus: By avoiding live web search, the work sidesteps issues of dynamic content and search engine variability; generalization of KARL’s capabilities to open-web or evolving corpora is not evaluated.
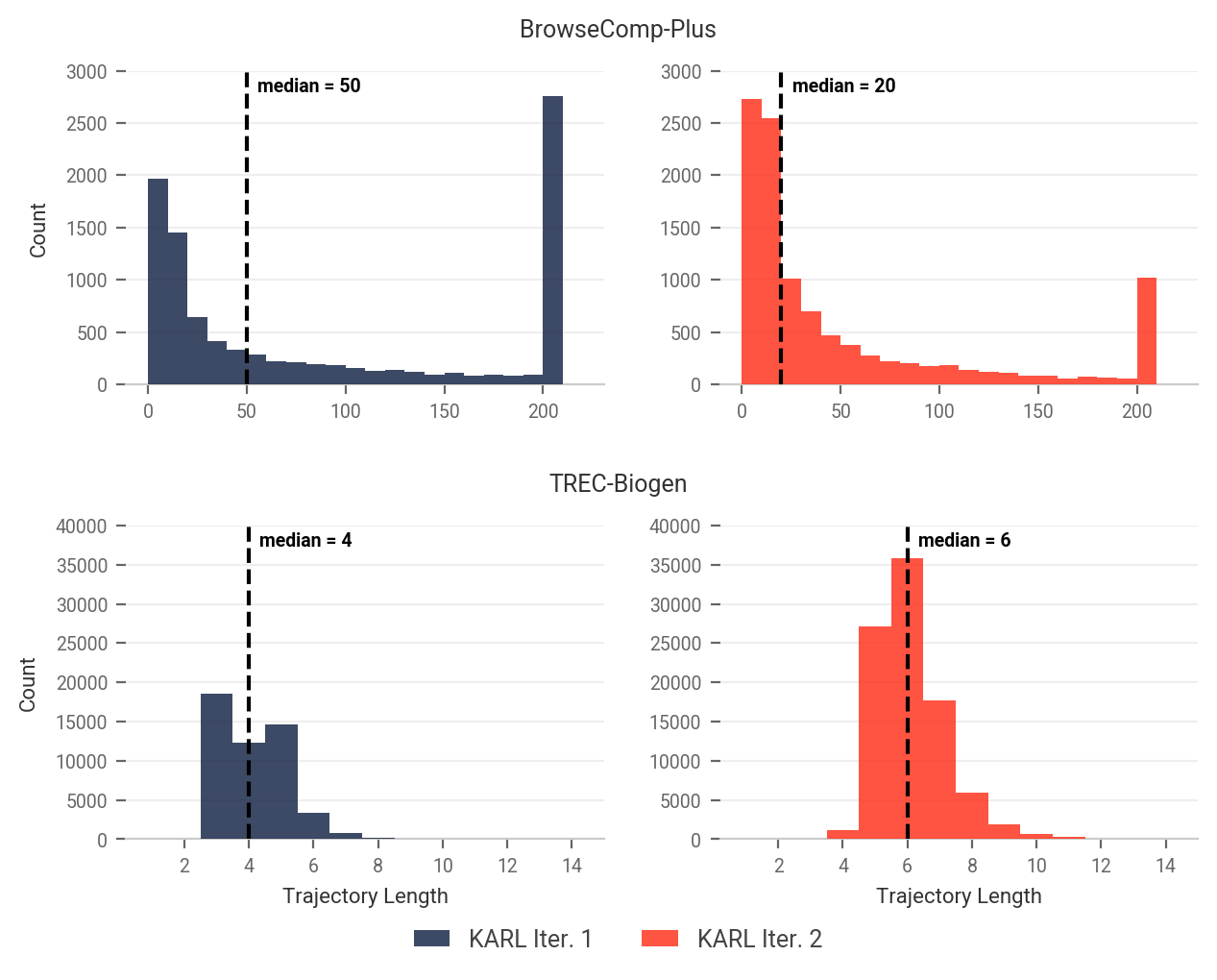
- Retrieval coverage limits on BrowseComp-Plus: Indexing only the first 512 tokens per document imposes a hard upper bound; the impact of enabling document traversal or more complete indexing on both baseline and KARL performance is not measured.
- PMBench availability and reproducibility: PMBench is proprietary; lack of public release (data, prompts, nuggets, and indexing) prevents independent validation of reported gains and hinders community benchmarking.
- Potential evaluation bias on QAMPARI: Indexing only documents that contain at least one gold entity may alter the search prior and difficulty; how this design choice affects absolute and comparative performance is not studied.
- Embedding/model heterogeneity across tasks: Different embedding models and retrieval hyperparameters are used per dataset; no ablation isolates how embedding choice and k-values affect results or fairness of cross-model comparisons.
- Fixed retrieved-token budget and k caps: Using a uniform retrieved-token budget (e.g., k ≤ 20) may constrain recall in tasks requiring exhaustive aggregation (e.g., QAMPARI, PMBench); sensitivity to k and budget scaling is not explored.
- Minimal corpus preprocessing by design: While promoting generalization, the choice to avoid corpus-specific chunking, linking, or metadata enrichment obscures how much of KARL’s gains would persist or improve with stronger retrieval pipelines.
- End-to-end learned compression: Compression quality, failure modes, and its contribution to final performance are not quantified; no comparison is provided against specialist summarizers or alternative compression strategies.
- Reward design and credit assignment: Assigning the terminal rollout reward to all segments (including compression) may dilute or misplace learning signal; step-level credit assignment or reward shaping is not investigated.
- Nugget-based evaluation alignment: Nugget completeness is used uniformly, but its correlation with human judgments (especially for multi-paragraph synthesis in TREC-Biogen or procedural answers in FreshStack) is not validated via human studies.
- Synthetic data quality and decontamination: The synthesis and quality filter agents are themselves LMs; false positives/negatives in ambiguity and factuality detection are unquantified. Using evaluation examples as few-shot seeds (TREC-Biogen) heightens leakage risk despite de-duplication; deeper decontamination beyond surface similarity is not assessed.
- Self-bootstrapping risks: Iteratively training on model-generated questions/solutions may induce distributional drift or amplify model biases; mechanisms to detect and mitigate error propagation in the synthesis loop are not presented.
- Limited multi-task scope: Multi-task RL is demonstrated on only two tasks (BrowseComp-Plus and TREC-Biogen); it is unknown how scalability to more diverse tasks affects stability, interference, and OOD generalization.
- Task balancing strategy: The simple “equal training tokens” heuristic may be suboptimal; alternatives (e.g., difficulty-aware sampling, temperature-based task mixing, per-task curriculum) are not explored.
- Multi-expert distillation vs. multi-task RL: Claims of better OOD generalization for multi-task RL rely on two-task experiments; whether the advantage persists with more experts/tasks or alternative distillation recipes is untested.
- Off-policy RL stability and limits: OAPL’s robustness claims lack detailed ablations versus online GRPO across architectures and scales (e.g., actual MoE vs. dense); boundaries where off-policy learning degrades are not mapped.
- Trainer–inference discrepancy: While robustness to trainer–inference engine differences is claimed, the magnitude and conditions of such discrepancies and their impact on quality/latency are not quantified.
- Test-time compute (TTC) methodology gaps: Parallel Thinking and VGS lack comprehensive ablations on N, k, value-model size, and aggregation prompts; cost/latency/quality trade-offs and saturation points are not systematically reported.
- Aggregation strategy analysis: The paper notes the aggregator can synthesize better answers than any single rollout, but does not compare against strong baselines (e.g., weighted majority, consensus debate, cross-evidence validation).
- Value model calibration and generalization: The value model is trained on rollouts from the same policy; its calibration, susceptibility to overfitting, and transfer across tasks or policies are not assessed.
- Fairness of cross-model comparisons: Competitors may use different tool stacks or web access; without standardizing tools/retrieval and reporting compute budgets, the comparability of Pareto frontiers is uncertain.
- Latency and operational constraints: Although cost–quality and latency–quality Pareto claims are made, per-task latency distributions under different TTC budgets and real-world SLAs are not detailed.
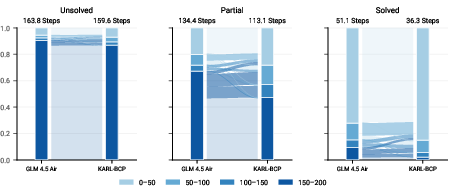
- Failure mode analysis: The paper lacks qualitative error analysis across tasks (e.g., common retrieval misses, spurious compression, numeric reasoning slips, or synthesis inconsistencies), limiting diagnostic insight.
- Security, privacy, and governance: Training on internal notes (PMBench) and deploying agentic retrieval in enterprise settings pose data governance and privacy questions that are not addressed (e.g., access control, auditability, PII handling).
- Release of artifacts: The “aroll” harness, prompts, reward code, compression prompts, aggregation prompts, and TTC configs are not indicated as being released; reproducibility and community adoption are therefore constrained.
- Domain transfer to non-text modalities: KARL is evaluated on text corpora; performance on documents with rich tables, figures, or code repositories requiring execution/runtime validation is not assessed.
- Long-horizon navigation tools: For tasks with lengthy documents (e.g., FinanceBench), the absence of structured navigation tools (e.g., table readers, section jumpers) leaves open whether KARL can scale to even longer, more complex corpora.
- Continual learning and corpus drift: How KARL adapts to frequent corpus updates in enterprise settings (without catastrophic forgetting or costly re-training) is left unexplored.
Practical Applications
Overview
Based on the paper “KARL: Knowledge Agents via Reinforcement Learning,” the following items translate the system’s findings, methods, and innovations into practical applications across industry, academia, policy, and daily life. Each item notes sectors and key dependencies that may affect feasibility.
Immediate Applications
- Enterprise knowledge agent for internal corpora
- Sectors: software, finance, manufacturing, legal, government
- What: Deploy a vector-search–only, grounded reasoning assistant over intranet docs (wikis, PM notes, policies, SOPs). Handles constraint-driven entity search, fact aggregation, and cross-document synthesis with end-to-end context compression.
- Tools/products/workflows: “Enterprise KARL” chatbot; secure RAG service with compression plugin; aroll harness for identical behavior across data collection, training, and serving.
- Dependencies/assumptions: High-quality embeddings and indexing; closed corpora access and data governance; nugget-based QA evaluation setup.
- Financial report analysis and KPI extraction
- Sector: finance
- What: Navigate 10-K/10-Qs and investor PDFs to compute year-over-year metrics, extract tabular values, and generate audit-ready calculations.
- Tools/products/workflows: Finance copilot with vector search; TTC “Parallel Thinking” mode for reliability; nugget-based rubric to assess completeness.
- Dependencies/assumptions: Page-level indexing quality; coverage of tables; guardrails for accuracy; compliance sign-off.
- Biomedical literature review synthesis (non-clinical decision support)
- Sector: healthcare, pharma/biotech
- What: Cross-document evidence aggregation (e.g., vaccine effectiveness summaries) for medical affairs and research reviews.
- Tools/products/workflows: Evidence-synthesis agent on PubMed-like corpora; nugget conversion for multi-reference answers; QA dashboards with completeness scoring.
- Dependencies/assumptions: Curated corpora; human-in-the-loop review; not a substitute for clinical decision-making.
- Regulatory, risk, and compliance audit search
- Sectors: finance, healthcare, energy, defense
- What: Exhaustive retrieval of entities/events across policies, logs, and controls (e.g., sanctions, governance controls, audit trails).
- Tools/products/workflows: QAMPARI-style exhaustive search mode; deduplicated evidence bundles; report synthesis with traceable nuggets.
- Dependencies/assumptions: Structured access to logs/docs; precision/recall thresholds set with compliance teams.
- Developer support and customer support assistants
- Sectors: software, IT services, SaaS
- What: Procedural reasoning over technical documentation to produce step-by-step fixes and runbooks.
- Tools/products/workflows: FreshStack-like doc agent; value-guided search (VGS) to prefer solutions that empirically lead to correct outcomes; integrated into ticketing systems.
- Dependencies/assumptions: Up-to-date docs; safe tool-call policies; clarity on when to escalate to humans.
- Internal planning and notes synthesis (PMBench-style)
- Sectors: software, product orgs across industries
- What: Aggregate dispersed facts from meeting notes and planning documents to answer “who/what/when/risks” queries with source citations.
- Tools/products/workflows: Lightweight PM knowledge agent; parallel rollouts with aggregator to boost correctness when inputs are noisy.
- Dependencies/assumptions: Proper access controls; redaction where needed; minimal preprocessing sufficient for retrieval coverage.
- Upgrade existing RAG systems with context compression
- Sectors: software, knowledge management platforms
- What: Introduce RL-tuned compression within agent loops to maintain salient context and reduce prompt costs without sacrificing accuracy.
- Tools/products/workflows: Compression lifecycle plugin integrated into existing RAG pipelines; reward-driven end-to-end optimization.
- Dependencies/assumptions: Stable prompt templates; compatibility with current LLM serving stack.
- Agentic synthetic data generation for enterprise fine-tuning
- Sectors: software/ML platform teams, model vendors
- What: Use the agentic synthesis pipeline to produce grounded, decontaminated question–answer pairs and solution trajectories from company corpora; filter by pass-rate to target “learnable” difficulty.
- Tools/products/workflows: “Agentic Synthesis Studio” with dedup and quality filters; bootstrapping with progressively stronger checkpoints.
- Dependencies/assumptions: Few-shot seed examples; compute for rollouts; decontamination to avoid evaluation leakage.
- Off-policy RL post-training (OAPL) for domain adaptation
- Sectors: ML platforms, enterprise AI teams
- What: Post-train a base LM to enterprise tasks using large-batch, iterative off-policy RL without complex online RL infra.
- Tools/products/workflows: OAPL training pipeline with group rollouts and KL-regularized regression objective; masked multi-step trajectories (search queries, compressions).
- Dependencies/assumptions: Rewardable tasks (e.g., nugget metrics or binary success); capacity for dataset regeneration across iterations.
- Nugget-based evaluation framework for grounded QA
- Sectors: enterprise AI QA, procurement, governance
- What: Standardize evaluation with nugget completeness scoring for varied task types (single-fact, exhaustive sets, multi-para reports).
- Tools/products/workflows: Internal “KARLBench-like” eval suite; task-specific nugget prompts; leaderboards tracking cost/latency vs quality.
- Dependencies/assumptions: Gold references or curated nugget sets; agreement on reward prompts.
- High-throughput offline retrieval for data generation and testing
- Sectors: ML platform, infra
- What: Embedded, columnar vector DB per worker to achieve 500+ QPS per host for rollout collection and TTC.
- Tools/products/workflows: In-process vector search library; cached indexes; uniform tool interface for training and serving.
- Dependencies/assumptions: Memory footprint and storage budgets; consistent embedding models across environments.
- Parallel Thinking inference mode
- Sectors: all deploying LLM agents
- What: Launch an “N-parallel rollouts + aggregation” inference mode that often beats best-of-N or simple majority vote, while keeping latency manageable via parallelism.
- Tools/products/workflows: Aggregation prompt that can use tools for verification/refinement; budget-aware N selection.
- Dependencies/assumptions: Headroom for parallel compute; aggregation tuned to task; monitoring for diminishing returns.
- Value-Guided Search (VGS) with small value model
- Sectors: support, finance, biomedical synthesis
- What: Train a small value model to predict future success probability token-by-token and steer step selection during inference.
- Tools/products/workflows: BFS-style step expansion with value scoring; final rollout aggregation via weighted voting or best-of-N.
- Dependencies/assumptions: Binary or nugget-derived rewards for value training; validation of value calibration.
Long-Term Applications
- Multi-tool, enterprise-grade research agents
- Sectors: finance, legal, healthcare, manufacturing
- What: Extend from vector search to multi-tool orchestration (browsers, table parsers, spreadsheets, code execution, doc traversal) for broader grounded reasoning (e.g., deep table extraction, live market data).
- Tools/products/workflows: Tool-augmented agent harness with safety gates; RL that includes tool selection and outcomes.
- Dependencies/assumptions: Tool reliability; expanded evaluation to multi-tool settings; stronger safety/observability.
- Real-time enterprise “deep research” with compliance
- Sectors: government, regulated industries
- What: Generalize the deep research paradigm to secure/certified corpora, combining live intranet sources with archived records for evidence-backed policy or executive briefs.
- Tools/products/workflows: Hybrid closed–open indexing; differential privacy where required; governance dashboards.
- Dependencies/assumptions: Content freshness and versioning; legal review for web content use; robust provenance tracking.
- Safety-critical decision support (with rigorous validation)
- Sectors: healthcare, energy, aerospace
- What: Pilot evidence synthesis for clinical guidelines, safety notices, and engineering incident analysis with strict guardrails and post-market monitoring.
- Tools/products/workflows: Human-in-the-loop workflows; red teams and external validation; documented uncertainty estimates.
- Dependencies/assumptions: Regulatory approval; extensive domain-specific evaluation; liability and audit readiness.
- Budget-aware test-time compute scheduling
- Sectors: platform, cloud AI, cost-sensitive deployments
- What: Dynamic controllers to allocate rollouts (N) per query based on difficulty estimates or value scores to optimize cost–latency–quality per request.
- Tools/products/workflows: Difficulty heuristics from value models; SLAs and budgets encoded in serving policies.
- Dependencies/assumptions: Accurate difficulty prediction; service mesh coordination; customer-configurable QoS.
- Continual learning via pass-rate–targeted active learning
- Sectors: enterprise AI platforms
- What: Use pass-rate bands to continuously mine “learnable but hard” examples from production queries/doc updates for ongoing improvement.
- Tools/products/workflows: Feedback loops in aroll harness; automated synthesis and filtering; periodic OAPL iterations.
- Dependencies/assumptions: Data consent; drift monitoring; robust decontamination.
- Cross-modal grounded reasoning
- Sectors: manufacturing, education, energy
- What: Incorporate figures, schematics, and images in manuals (e.g., wiring diagrams) into procedural reasoning and troubleshooting.
- Tools/products/workflows: Multimodal embeddings and retrieval; toolchain for OCR and diagram parsing; extended nugget metrics.
- Dependencies/assumptions: High-quality multimodal encoders; scalable indexing and chunking for images/figures.
- Sector-wide benchmark standardization and procurement criteria
- Sectors: policy, government, standards bodies
- What: Adopt KARLBench-like suites (nugget-based, multi-capability) as procurement standards for AI assistants in regulated contexts.
- Tools/products/workflows: Public/sector-specific corpora and tests; cost/latency/quality Pareto reporting; open evaluation protocols.
- Dependencies/assumptions: Consensus on tasks and rubrics; versioned datasets; transparent reporting.
- Marketplace of specialized knowledge agents
- Sectors: software, consulting, vertical AI vendors
- What: Offer pre-trained, OAPL-tuned agents per vertical (e.g., IFRS finance agent, SOC2/ISO compliance agent, automotive service agent) with plug-in TTC profiles.
- Tools/products/workflows: Deployment blueprints; customer-specific fine-tuning with agentic synthesis; policy packs and guardrails.
- Dependencies/assumptions: IP/licensing for training data; clear customization boundaries; support for varied vector DBs.
- Autonomous knowledge graph construction from grounded QA
- Sectors: enterprise search, analytics
- What: Convert stable nuggets and citations into edge assertions for continuously updated, auditable knowledge graphs feeding search and analytics.
- Tools/products/workflows: Nugget-to-graph pipelines; confidence scoring from value models; change detection and rollback.
- Dependencies/assumptions: Schema design; provenance capture; reconciliation and dedup.
- Scalable MoE RL post-training as a managed service
- Sectors: ML infrastructure, cloud providers
- What: Offer OAPL-based post-training for customers’ base models, with multi-task setups and stability on large MoEs without GRPO heuristics.
- Tools/products/workflows: Data generation at scale with embedded vector search; offline large-batch RL; hyperparameter sweeps amortized over generated datasets.
- Dependencies/assumptions: GPU capacity; privacy/security controls; robust failure handling and monitoring.
Glossary
- Agentic retrieval: Agent-driven iterative search and evidence gathering over a corpus using tools. "Our objective is to evaluate agentic retrieval under heterogeneous and realistic corpus conditions"
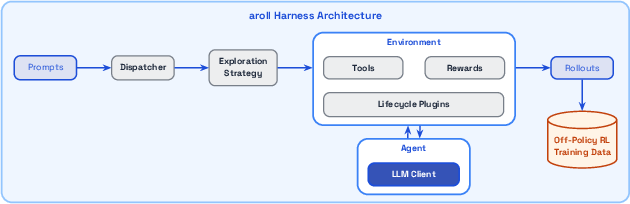
- aroll: The paper’s high-throughput internal agentic rollout framework for collecting, training on, and evaluating long-horizon agent trajectories. "We built our internal agentic rollout framework (called ``aroll'' for convenience)"
- Best-of-N: A test-time compute strategy that samples N candidate answers and selects the best one according to some criterion. "more expressive than simple TTC strategies such as Best-of- or Majority Vote."
- Breadth-First-Search (BFS): A tree search strategy that explores all nodes at a given depth before moving deeper; used here to navigate candidate continuations guided by a value model. "This is the simple Breadth-First-Search (BFS) implementation proposed in VGS"
- Closed-corpus benchmarks: Evaluation settings where retrieval happens over a fixed, indexed corpus rather than the live web. "we deliberately focus on closed-corpus benchmarks rather than web-search–based evaluation settings"
- Clipped importance weighting: An off-policy correction heuristic that limits (clips) importance weights to stabilize training. "without requiring heuristics such as clipped importance weighting, data deletion, or router replay"
- Columnar vector database: A column-oriented data store optimized here for fast, in-process vector similarity search. "we utilized an embedded, columnar vector database for vector search."
- Compression (context management): Summarizing interaction history to stay within token limits while preserving salient information for subsequent reasoning. "For long rollouts, we design a compression mechanism for context management."
- Decontamination pipeline: A process that removes exact or near-duplicate data to avoid test contamination. "based on the LMSys-recommended decontamination pipeline"
- Deduplication Agent: A component that filters out exact or near-duplicate synthesized examples before training. "the Deduplication Agent filters out any exact or near-duplicates."
- GRPO: An online reinforcement learning algorithm used for post-training LLMs; known to require stability heuristics in MoE settings. "stabilizing online GRPO training for large-scale MoE models"
- Group rollouts: Multiple responses generated for the same prompt under a reference policy, used to estimate values and advantages. "is the group rollouts generated by $\pi_{\text{ref}$ given "
- KL-regularized RL objective: An RL objective that maximizes reward while penalizing divergence from a reference policy via the KL divergence. "the KL-regularized RL objective:"
- LATS: A lookahead tree-search method that uses the LLM itself to evaluate step-level candidates during search. "compared to LATS~\citep{zhou2024lats}, which uses the LLM itself as a step-level evaluator"
- Lifecycle Plugins: Modular hooks that modify the agent–environment loop for behaviors like compression, step limits, or tool access control. "Lifecycle Plugins that intercept fixed points in the environment's interaction loop"
- Long-horizon reasoning: Multi-step reasoning that spans many tool calls and decisions before producing a final answer. "employs long-horizon reasoning and tool use"
- Majority Vote: An aggregation method that outputs the answer most frequently proposed among multiple sampled candidates. "more expressive than simple TTC strategies such as Best-of- or Majority Vote."
- Mixture-of-Experts (MoE): A model architecture where a router selects among specialized expert subnetworks for each token or input. "large-scale MoE models"
- Multi-expert distillation: Training a single student model by supervising it on outputs from multiple specialized teacher models. "Multi-expert distillation has been used in the literature to train some of the best open-source models"
- Nugget-based completion: An evaluation method that scores answers by checking for predefined atomic facts (“nuggets”) they contain. "We unify answer evaluation across all tasks using nugget-based completion"
- Nugget-based evaluation framework: A TREC-style evaluation approach that decomposes references into granular facts and measures coverage. "consistent with the nugget-based evaluation framework spearheaded by \cite{voorhees2003trecqa}"
- OAPL (Optimal Advantage-based Policy Optimization with Lagged Inference policy): The paper’s off-policy RL post-training recipe that regresses to an advantage-implied target under KL regularization. "We use Optimal Advantage-based Policy Optimization with Lagged Inference policy -- OAPL"
- Off-policy RL: Reinforcement learning that optimizes a policy using data generated by a different (reference) policy. "a new post-training recipe based on the concept of Large Batch Iterative Off-policy RL."
- Off-policyness: The degree to which training data are generated by a behavior different from the current policy, potentially causing distribution mismatch. "By embracing the off-policyness in the design of the objective"
- Out-of-distribution generalization: Maintaining strong performance on tasks or distributions not seen during training. "with out-of-distribution generalization"
- Pareto frontiers: The set of models that are not strictly dominated across multiple objectives (e.g., cost–quality, latency–quality). "The cost–quality and latency–quality Pareto frontiers show that KARL achieves favorable trade-offs over existing models."
- Pareto-optimal: A point on the Pareto frontier that cannot improve one objective without degrading another. "KARL is Pareto-optimal on KARLBench"
- Parallel Thinking: A test-time compute strategy where multiple rollouts are generated in parallel and then aggregated into a final answer. "We apply Parallel Thinking ~\citep{zhao2025samplescrutinizescaleeffective, ...} as a task-independent TTC strategy"
- Reference model: A baseline policy used for sampling and KL regularization during off-policy optimization. "We denote $\pi_{\text{ref}$ as the reference model"
- Router replay: A MoE training heuristic that replays router (expert-selection) decisions to stabilize learning. "without requiring heuristics such as clipped importance weighting, data deletion, or router replay"
- Step budgeting: Imposing a limit on the number of tool/assistant steps in a rollout to control cost and latency. "Cross-cutting concerns such as context compression, step budgeting, and tool gating"
- Supervised fine-tuning (SFT): Training a model on labeled examples with standard supervised learning objectives. "via SFT (supervised fine-tuning)"
- Test-time compute (TTC): Additional computation at inference time (e.g., multiple rollouts or search) to improve answer quality. "We investigate test-time compute (TTC) as a powerful augmentative method to boost performance"
- Tool gating: Controlling whether and how an agent can invoke external tools during its reasoning process. "Cross-cutting concerns such as context compression, step budgeting, and tool gating"
- Value model: A model that predicts the probability of eventual success given a partial rollout, used to steer search. "a value model which predicts the future probability of the success given any partial rollout."
- Value-Guided Search (VGS): A search method that uses a value model to score candidate continuations and select high-value branches. "We also apply Value-Guided Search (VGS) — a method that performs parallel tree search using a value model"
- Vector search: Retrieval by nearest-neighbor search in embedding space over chunked documents. "we equip the agent with a single tool: vector search."
- vLLM: A high-throughput LLM inference engine used in serving/evaluation pipelines. "discrepancies between the trainer and the inference engine (e.g.\ vLLM)"
Collections
Sign up for free to add this paper to one or more collections.

