Search More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
Abstract: Recent deep research agents primarily improve performance by scaling reasoning depth, but this leads to high inference cost and latency in search-intensive scenarios. Moreover, generalization across heterogeneous research settings remains challenging. In this work, we propose \emph{Search More, Think Less} (SMTL), a framework for long-horizon agentic search that targets both efficiency and generalization. SMTL replaces sequential reasoning with parallel evidence acquisition, enabling efficient context management under constrained context budgets. To support generalization across task types, we further introduce a unified data synthesis pipeline that constructs search tasks spanning both deterministic question answering and open-ended research scenarios with task appropriate evaluation metrics. We train an end-to-end agent using supervised fine-tuning and reinforcement learning, achieving strong and often state of the art performance across benchmarks including BrowseComp (48.6\%), GAIA (75.7\%), Xbench (82.0\%), and DeepResearch Bench (45.9\%). Compared to Mirothinker-v1.0, SMTL with maximum 100 interaction steps reduces the average number of reasoning steps on BrowseComp by 70.7\%, while improving accuracy.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new way to make AI “research agents” faster and more reliable when they look things up on the web and piece together answers. The method is called SMTL, which stands for “Search More, Think Less.” Instead of making the AI think in long, slow chains of reasoning, SMTL has the AI gather lots of useful evidence in parallel (at the same time) and then combine it smartly. This makes it both quicker and better at different kinds of tasks.
What questions the paper tries to answer
The paper focuses on two simple questions:
- How can we make web‑searching AI agents solve long, multi-step tasks faster, without getting worse at them?
- How can we train one agent that works well on both kinds of tasks: questions with a single correct answer (like a fact) and open-ended research tasks (like writing a short report)?
How the method works (in everyday terms)
Think of a big school project. You could either:
- Work alone and go step-by-step (slow), or
- Split the project into smaller parts, have friends work on them at the same time, then regroup to combine the results (faster).
SMTL does the second option.
Here’s the approach in simple pieces:
- Planning first: The agent makes a plan that breaks a big question into smaller subtasks (like “find the date,” “check who said it,” “compare two sources”).
- Parallel searching: Instead of doing one subtask after another, it runs several at once using tools like web search and web page reading. This is like sending several teammates to different sources at the same time.
- Regular check-ins: Every few steps, the agent pauses to update the plan—dropping finished parts, adding new ones if needed, and focusing on what matters next.
- Smart memory use: The AI’s “memory” (its context window) isn’t infinite. SMTL keeps memory under control by summarizing and resetting around an updated plan when the history gets too long. Think of it as cleaning up your notes and keeping only the plan and the latest useful info, so you don’t get overwhelmed.
- Training with the right practice:
- For “single correct answer” tasks, the team generated lots of practice questions and answers from real web pages and knowledge graphs (networks that link facts and topics).
- For open-ended research tasks, they generated report-style prompts and filtered example solutions to keep only high-quality ones.
- They first “taught by example” (supervised fine-tuning) using strong teacher models, then let the agent “practice with rewards” (reinforcement learning) where it gets points for giving correct or well-structured answers.
Key idea: SMTL replaces long, slow thinking with wider, smarter searching and better organization.
What they found and why it matters
Across many benchmarks (tests for research agents), SMTL was both accurate and efficient. In short: it solved more problems with fewer slow, back-and-forth steps.
Some highlights:
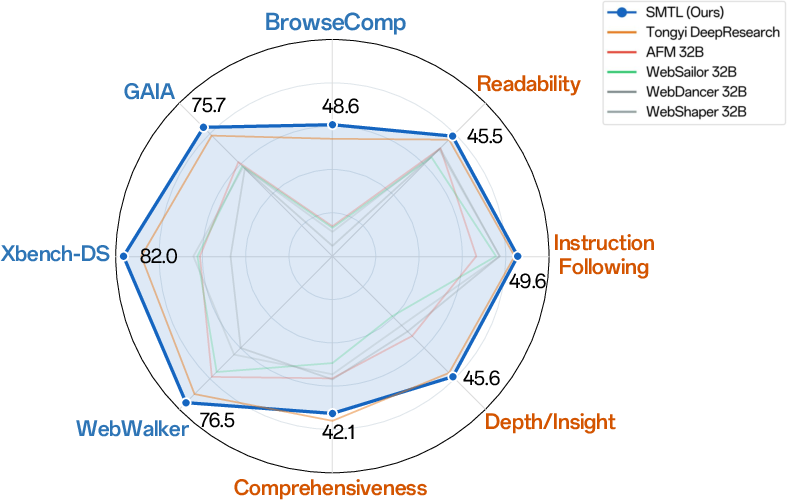
- It reached top or near-top scores on several well-known tests:
- BrowseComp: up to 48.6% accuracy
- GAIA: 75.7%
- XBench (DeepSearch): 82.0%
- DeepResearch Bench (open-ended reports): 45.9% overall
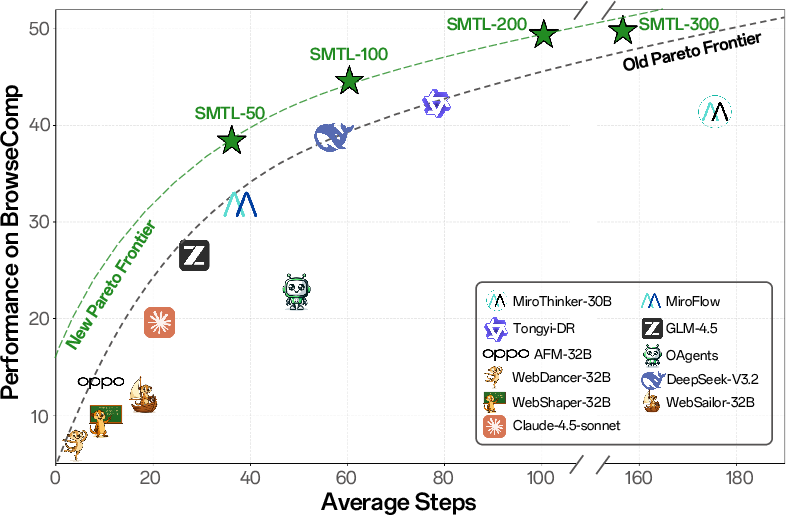
- It used far fewer reasoning steps than a strong baseline (MiroThinker-v1.0) on BrowseComp—about 70% fewer steps—while getting better answers.
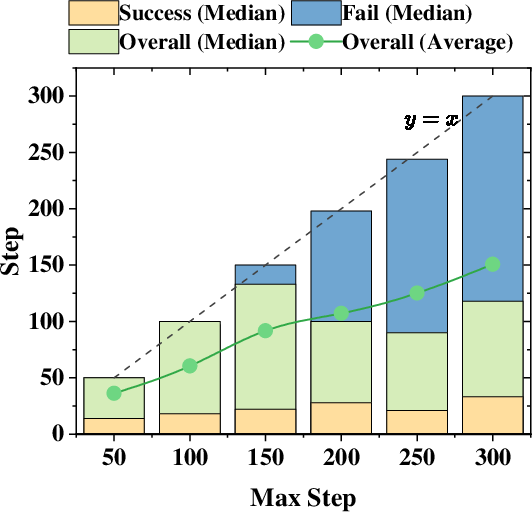
- It did especially well when tasks were long and needed many pieces of evidence. Adding more interaction steps helped mostly on these harder problems.
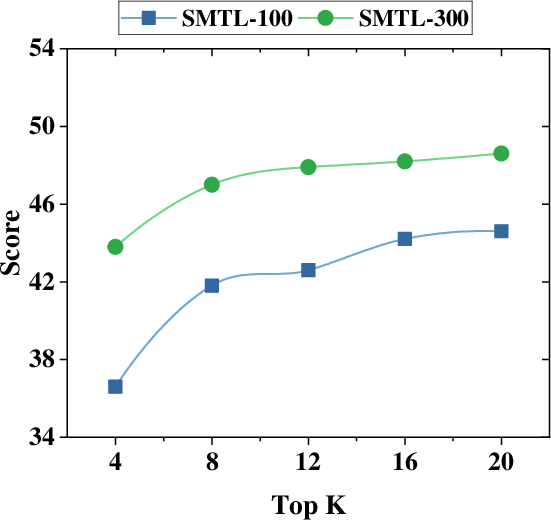
- Widening search (checking more top results per query) improved performance more than just “thinking longer.” In other words, “search breadth” was a better way to scale than “more inner monologue.”
Why this matters:
- Faster and cheaper: Fewer steps and more info per step means lower waiting time and lower compute cost.
- More general: One agent handled both fact-based questions and open-ended research, so you don’t need separate systems.
What this could change in the future
- Better research tools: Search engines and research assistants could gather reliable info faster and write better summaries.
- Smarter scaling: Instead of always building AI that “thinks” longer, we can design AI that “searches” smarter—splitting work into parallel subtasks and regularly re-planning.
- Training that generalizes: The mixed training data (both definite-answer and open-ended tasks) suggests we can build agents that adapt well to different research needs.
- Practical use: From homework help to professional research, this approach can make information-finding tools quicker, clearer, and more trustworthy.
In short, “Search More, Think Less” shows that organizing and widening evidence gathering—then combining it thoughtfully—can beat long, slow chains of thought for many real-world research tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete gaps that future work could address.
- Lack of formal efficiency analysis: no theoretical characterization of expected speed-up or information-efficiency gains from parallel subtask execution versus sequential baselines (e.g., bounds on steps, tool calls, or wall-clock latency).
- Missing wall-clock and cost measurements: latency, throughput, and monetary cost per task under parallel tool use are not reported; network I/O contention, rate limits, and concurrency overhead are unquantified.
- Scheduling policy unspecified: the criteria for selecting “ready-to-execute” subtasks, prioritization, and concurrency limits are not defined or ablated; no comparison of alternative schedulers (e.g., FIFO vs. priority queues vs. learned schedulers).
- Conflict handling under parallelism: the paper does not describe how contradictory or redundant evidence from concurrent subtasks is detected, resolved, or de-duplicated.
- Abstract state representation: the “aggregated reasoning state” s_t and update functions F and R are described only symbolically; concrete implementation details (prompt templates, memory structures, summarization schemes) are missing.
- Plan refinement cadence is fixed (N=5): no sensitivity analysis or adaptive strategies for plan refinement frequency; unclear whether event-triggered or confidence-triggered refinement would improve efficiency.
- Context overflow compression unquantified: forced plan resets that drop pre-plan context are introduced, but their impact on evidence retention, error rates, and citation fidelity is not measured.
- Tool repertoire is narrow: only web search and page crawling are used; generalization to other tool types (APIs, code execution, DB queries, tables, multi-modal inputs) is unexplored.
- Retrieval pipeline details absent: the search engine/provider, query rewriting strategies, deduplication, and reranking (beyond top-k width) are not documented; robustness to search engine variability remains unknown.
- Limited robustness analysis: no experiments on adversarial, misleading, paywalled, or rapidly changing web content; credibility assessment, source trust weighting, and cross-source verification are not modeled or evaluated.
- Evaluation relies on LLM-as-judge: potential bias, instability, and judge-overfitting are not addressed; human evaluation and inter-judge agreement are missing.
- Apples-to-apples comparability unclear: baselines are evaluated under their default inference settings rather than matched budgets, tools, or judges; fairness and reproducibility of comparisons are uncertain.
- Contamination risk not assessed: synthetic data constructed from TaskCraft trajectories and web graphs may overlap with benchmark URLs/content; no data provenance audit or contamination mitigation is reported.
- Binary outcome reward only: RL uses pass/fail rewards; intermediate rewards for tool correctness, evidence quality, verification success, or plan alignment are not explored, limiting credit assignment granularity.
- RL training stability and efficiency: training details (e.g., number of updates, variance, convergence diagnostics) are sparse; effects of importance sampling corrections and trajectory filtering on stability are not empirically validated.
- Negative trajectory filtering may reduce robustness: excluding environment-induced failures and long trajectories may bias training away from real-world instability; robustness to timeouts and rate limits is untested.
- Limited failure analysis: failures are characterized mainly by hitting max steps; no taxonomy of error types (planning errors, retrieval misses, verification failures, hallucinations) or targeted mitigations.
- Limited ablations: beyond max steps and retrieval top-k, key factors (number of parallel subtasks, plan quality, summarization/compression strategies, judge choice, tool-call formats) are not systematically ablated.
- Citation fidelity and grounding metrics absent: deep research evaluation uses comprehensiveness/depth/readability but does not measure citation correctness, traceability, or evidence coverage precision.
- Generalization scope: the framework’s transfer to multi-modal tasks, time-sensitive queries, code/data analysis, and domain-specific research (e.g., scientific literature) remains untested.
- Model scaling behavior: only a 30B backbone is reported; scaling laws across parameter sizes (small and large models), and trade-offs between model size, parallelism, and efficiency are unexplored.
- Adaptive budget control: fixed max-step limits are used; adaptive allocation of interaction budget across subtasks or based on confidence/uncertainty is not investigated.
- Data pipeline quality controls: LLM-based entity extraction and graph construction may introduce noise; error rates in node/edge extraction, graph coverage, and the impact on downstream task difficulty are unreported.
- Teacher dependence: SFT distills from GPT-5 and DeepSeek-V3.2; the extent to which gains come from teacher signals versus the SMTL architecture is not disentangled (e.g., ablations without distillation).
- Judge-model specification: the specific LLM-as-judge model(s), temperature, and prompts are referenced but not fully enumerated; replicability across judge choices is not studied.
- Real-world deployment considerations: rate-limit handling, parallel request throttling, caching, ethical sourcing, and compliance with robots.txt/publisher policies are not discussed.
- Security and safety: vulnerability to prompt injection, tracking pixels, malicious scripts on crawled pages, and the agent’s potential to amplify disinformation are not assessed.
- Domain coverage bias: corpus and synthetic tasks span selected domains; coverage gaps, domain difficulty variance, and stratified performance are not analyzed.
- Multi-agent baselines: the proposed single-agent parallelism is not compared against multi-agent division-of-labor frameworks; coordination vs. parallelism trade-offs remain open.
- Plan-quality measurement: no metrics or diagnostics for plan correctness, subtask decomposition quality, or refinement effectiveness; learning-to-plan improvements are not evaluated.
- Reproducibility details: hardware specs, concurrency settings, bandwidth constraints, and exact tool configurations are insufficiently documented to reproduce latency and efficiency claims.
- Statistical significance: reported benchmark gains lack confidence intervals or significance testing; sensitivity to random seeds and run-to-run variance is not provided.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed with today’s tooling by leveraging SMTL’s parallel evidence acquisition, plan-centric context management, and unified task/data pipeline.
- Parallel research copilot for analysts (Finance, Consulting, Market Intelligence)
- What it does: Executes multiple web queries and site crawls concurrently, aggregates evidence, and periodically re-plans to converge on defensible insights with citations.
- Tools/workflows: Browser extension or desktop app; web search + crawling; “evidence board” UI that mirrors SMTL’s subtask graph; retrieval breadth (top-k) knob; plan-centric reset to manage long sessions.
- Dependencies/assumptions: API rate limits and CAPTCHAs; quality/availability of sources; GPU/CPU budget for 30B-class inference; organizational policies on web data use.
- Legal and compliance due diligence (Legal, Risk, Compliance)
- What it does: Parallel retrieval across regulations, sanctions lists, case law, and disclosures; verification-oriented subtasks to minimize missed precedents.
- Tools/workflows: Connectors to Lexis/Westlaw/EDGAR/OFAC; audit-ready citation matrix; per-subtask quality gates; LLM-as-judge for structural checks.
- Dependencies/assumptions: Licensing for legal databases; strict provenance and audit logging; domain-tuned prompts; on-prem deployment for sensitive data.
- Clinical evidence synthesis and guideline checks (Healthcare)
- What it does: Concurrent searches of PubMed/ClinicalTrials.gov/guidelines with plan-driven aggregation into PICO-style summaries and uncertainty notes.
- Tools/workflows: Evidence graph and cross-source verification subtasks; top-k calibrated for recall; structured output templates.
- Dependencies/assumptions: Medical QA review and safety guardrails; access to paywalled literature; clear disclaimers; HIPAA/PHI controls when needed.
- Enterprise knowledge assistant (Software/IT, HR, Ops)
- What it does: Answers multi-hop internal questions by parallel retrieval from Confluence/SharePoint/Git, compressing context via SMTL’s plan-centric reset.
- Tools/workflows: LightRAG + Jina-based indexing; access-control–aware connectors; context compression that drops pre-plan history during overflow.
- Dependencies/assumptions: Identity and permissions integration; change-data capture for freshness; on-prem inference or private VPC.
- Newsroom fact-checking and backgrounders (Media)
- What it does: Constructs parallel verification subtasks for claims, triangulating across sources to produce an evidence-weighted brief.
- Tools/workflows: Source quality scoring; contradiction detection; “what we don’t know yet” section; step/latency budgeting.
- Dependencies/assumptions: Fast crawl infrastructure; editorial standards for source reliability; legal review for sensitive topics.
- Vendor and counterparty risk dossiers (Procurement, Finance)
- What it does: Builds a multi-hypothesis plan (ownership, sanctions, litigation, ESG signals) and fills it via concurrent web and registry checks.
- Tools/workflows: CRM/ERP connectors; evidence dashboards; periodic plan refinement to prioritize high-signal subtasks.
- Dependencies/assumptions: PII handling; commercial registry access; consistent entity resolution.
- Patent prior art and competitive landscaping (IP, R&D)
- What it does: Queries USPTO/EPO/WIPO/arXiv in parallel and synthesizes clusters of similar claims/technologies with links.
- Tools/workflows: Graph-based aggregation; similarity reranking; plan resets to stay within context while tracking many documents.
- Dependencies/assumptions: Database licensing; domain prompts; attorney oversight.
- Customer support triage and resolution copilot (Customer Service)
- What it does: Parallel lookups across KB, ticket history, forum threads, and logs; synthesizes recommended fixes with links.
- Tools/workflows: Multi-source connectors; per-step tool-call quotas (~3–4) to boost information density; guardrails to avoid unsafe actions.
- Dependencies/assumptions: Real-time connectors; privacy controls; secure handling of customer data.
- SEO and content briefs with citations (Marketing)
- What it does: Concurrently analyzes SERP, competitor content, and authoritative sources; outputs a brief with topic gaps and references.
- Tools/workflows: Top-k tuning for recall; structured “coverage vs. authority” view; periodic plan refinement.
- Dependencies/assumptions: Adherence to search engine ToS; robust de-duplication; human editing.
- Unified training data generation for internal agents (MLOps, AI Platform)
- What it does: Uses the paper’s subgraph-based data synthesis pipeline to create multi-type agentic search tasks (deterministic + open-ended) for SFT/RL.
- Tools/workflows: LightRAG graph building; BFS subgraph extraction; LLM-as-judge filtering; trajectory efficiency filters (shortest-correct).
- Dependencies/assumptions: Compute budget; license compliance for corpora; evaluation beyond LLM judges for critical settings.
Long-Term Applications
The following concepts are feasible but require additional research, scaling, domain adaptation, or governance to meet performance, safety, or compliance thresholds.
- Living policy briefs and regulatory impact assessments (Government/Policy)
- What it could do: Maintain continuously-updated briefs with parallel monitoring of new rules, hearings, court decisions, and stakeholder statements.
- Tools/workflows: Event-driven plan refresh; domain-specific reliability models; evidence lineage tracking.
- Dependencies/assumptions: Trusted evaluation beyond LLM-as-judge; transparent provenance; cross-agency data sharing agreements.
- End-to-end systematic review automation to publication-ready drafts (Healthcare/Academia)
- What it could do: From protocol generation to screening, data extraction, bias assessment, and GRADE synthesis with human-in-the-loop checkpoints.
- Tools/workflows: Parallel screeners; protocol-aware plans; structured evidence tables; reproducible pipelines.
- Dependencies/assumptions: Clinical validation; IRB/ethics where applicable; strong citation and de-duplication guarantees.
- Enterprise “Agentic Search Fabric” (Software, Platform)
- What it could do: A horizontally-scalable orchestrator for parallel tool calls, plan refinement, and context management across teams, with per-org RL finetuning.
- Tools/workflows: GPU/CPU autoscaling; AgentOps telemetry (steps, tool-call density, latency); governance and approval workflows.
- Dependencies/assumptions: Significant MLOps investment; reliability SLAs; cost controls.
- Scientific discovery copilots integrating code execution (R&D)
- What it could do: Parallel literature search, dataset retrieval, and Jupyter/SQL analysis subtasks; design-of-experiments planning from evidence graphs.
- Tools/workflows: Safe code execution sandboxes; data license compliance; experiment tracking.
- Dependencies/assumptions: High-precision grounding; domain-tuned backbones; lab validation loops.
- Risk-aware research for strategy and investment decisions (Finance)
- What it could do: Multi-hypothesis plans with scenario testing; real-time feeds; audit-ready trails of evidence and rationales.
- Tools/workflows: Streaming connectors; risk dashboards; counterfactual research subtasks.
- Dependencies/assumptions: Compliance (MiFID/SEC); robust red-teaming against hallucinations; alignment with house views.
- Multilingual, locale-aware agentic search (Global enterprises)
- What it could do: Parallel, cross-lingual retrieval and synthesis with locale-specific sources and regulations.
- Tools/workflows: Multilingual KG construction; cross-lingual rerankers; locale-aware prompts.
- Dependencies/assumptions: Multilingual training data; region-specific compliance; culturally-aware evaluation.
- Smart-city and emergency response research agents (Public Safety, Energy)
- What it could do: Fuse web advisories, sensor feeds, and social channels in parallel; generate action-oriented situational briefs.
- Tools/workflows: Multi-modal tool adapters; strict latency budgets; plan compression under streaming.
- Dependencies/assumptions: Real-time data integrity; safety-critical validation; jurisdictional data policies.
- On-device or edge agentic search for privacy-sensitive orgs (Security, Healthcare)
- What it could do: Use SMTL’s context compression and plan resets to run smaller local models for private corpora and intranets.
- Tools/workflows: 7–13B distilled variants; hardware-aware schedulers; offline indexing.
- Dependencies/assumptions: Model compression/distillation quality; hardware constraints; privacy audits.
- Autonomous literature-curation and learning pathways (EdTech)
- What it could do: Track learner goals; parallel source discovery; staged synthesis into personalized curricula with spaced updates.
- Tools/workflows: Learning profiles; pedagogical plan templates; “evidence you should read next” recommender.
- Dependencies/assumptions: Consent and privacy; bias mitigation; alignment to standards.
- Open ecosystem for agentic benchmarks and training marketplaces (AI community)
- What it could do: Community-driven sharing of subgraph-based datasets, tasks, and standardized judge prompts; reproducible agent training recipes.
- Tools/workflows: Dataset hubs; evaluation suites beyond LLM judges; leaderboard governance.
- Dependencies/assumptions: IP/licensing clarity; consensus on metrics; sustainable maintenance.
- Legal argument drafting with precedent graphs (Legal)
- What it could do: Build dynamic graphs of binding/ persuasive precedent and statutes; propose arguments and counter-arguments with weighted support.
- Tools/workflows: Citation graph construction; contradiction surfacing; claim-level evidence mapping.
- Dependencies/assumptions: Very high reliability and auditability; malpractice liability frameworks; rigorous human oversight.
- Corporate threat intelligence synthesis (Cybersecurity)
- What it could do: Parallel ingestion of advisories, malware reports, and dark-web posts; prioritized, deduplicated intel briefs.
- Tools/workflows: IOC extraction subtasks; source-trust scoring; time-bounded plan cycles.
- Dependencies/assumptions: Access to feeds; false-positive controls; incident-response integration.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from gradient updates to improve training stability. "using the AdamW optimizer"
- advantage estimator: A statistic in policy-gradient RL that estimates how much better an action is than a baseline, guiding gradient updates. "RLOO provides an unbiased advantage estimator."
- agentic workflow: A structured process where an LLM agent plans, uses tools, and interacts with its environment across steps to solve tasks. "we design an efficient parallel agentic workflow"
- breadth-first search (BFS): A graph traversal method that explores neighbors level by level, often used to collect nodes within a hop radius. "perform a breadth-first search (BFS) up to hops"
- branching factor: The number of outgoing edges (children) per node in a search or graph, controlling search width. "By adjusting the hop depth and branching factor, we flexibly control task difficulty"
- context budget: The maximum token capacity available for a model’s input history, constraining how much prior information can be retained. "enabling efficient context management under constrained context budgets."
- context window: The size (in tokens) of text a model can process at once during inference. "with a context window of 128K tokens."
- cosine decay learning rate schedule: A learning rate schedule that decreases following a cosine curve to smooth training. "a cosine decay learning rate schedule with an initial learning rate of "
- deterministic question-answering: Tasks where a single ground-truth answer exists and evaluation focuses on correctness. "deterministic question-answering tasks with clear ground-truth answers"
- dynamic plan refinement: Periodically updating and improving the task plan during execution based on intermediate results. "Dynamic Plan Refinement."
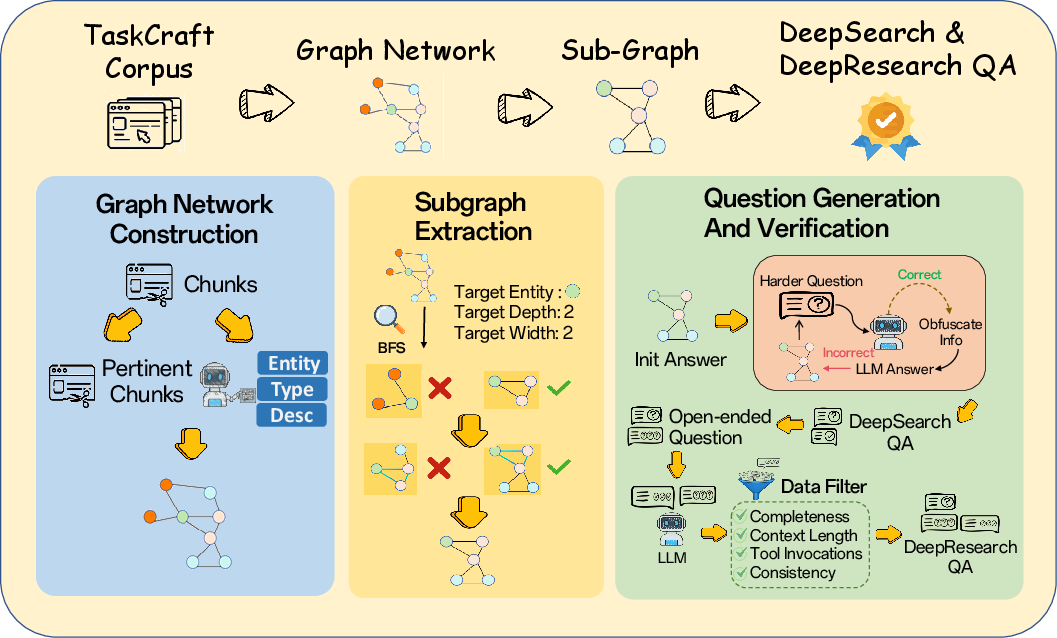
- embedding-plus-reranker retrieval mechanism: A retrieval pipeline that first recalls candidates via embeddings and then reorders them with a reranker for precision. "By integrating an embedding-plus-reranker retrieval mechanism, we recall pertinent chunks"
- interaction budget: A cap on the number of agent steps or tool interactions allowed for solving a task. "To align with the interaction budgets commonly used by baselines"
- knowledge-driven graph network: A graph constructed from extracted entities and relations that encodes domain knowledge. "to instantiate a knowledge-driven graph network."
- knowledge graph: A structured graph of entities and relationships used for reasoning and retrieval. "Given the constructed knowledge graph, we extract task-specific subgraphs"
- LLM-as-a-Judge: Using a LLM to evaluate the quality or correctness of outputs. "then evaluated by an LLM-as-a-Judge"
- multi-hop reasoning: Reasoning that integrates information across multiple linked steps or document hops. "To support cross-domain generalization and multi-hop reasoning, we construct the raw corpus"
- on-policy rollouts: Trajectories sampled using the current policy during reinforcement learning. "For each question, 8 on-policy rollouts are generated"
- outcome-based reward: A reward signal determined solely by the final result (e.g., correctness) rather than intermediate steps. "we optimize trajectories using an outcome-based reward."
- overflow-triggered compression scheme: A mechanism that summarizes or resets context when it exceeds the allowed limit. "SMTL couples periodic plan refinement with an overflow-triggered compression scheme"
- parallel evidence acquisition: Collecting information concurrently across subtasks to increase information density per step. "replaces sequential reasoning with parallel evidence acquisition"
- Pareto frontier: The set of solutions that are optimal trade-offs between competing objectives (e.g., accuracy vs steps). "SMTL consistently lies on the Pareto frontier of accuracy versus trajectory length"
- plan-and-execute pipelines: Agent architectures that explicitly separate high-level planning from low-level execution. "including plan-and-execute pipelines and hierarchical agent systems"
- plan-centric reset: Dropping prior context while retaining a refreshed plan to continue execution efficiently. "This plan-centric reset preserves the latest execution state"
- plan-driven context management: Managing what to keep in the prompt based on the current task plan to maximize useful context. "using plan-driven context management to achieve efficient long-horizon search under constrained context budgets."
- plan refinement interval: The fixed frequency at which the agent updates its plan during interaction. "a plan refinement interval of N=5 interaction steps."
- random-walk strategy: A stochastic traversal method used to sample subgraphs by moving randomly through nodes. "using a controlled random-walk strategy."
- REINFORCE Leave-One-Out (RLOO): A policy-gradient RL algorithm variant that uses a leave-one-out baseline for unbiased advantage estimation. "We adopt a slightly modified version of the REINFORCE Leave-One-Out (RLOO) algorithm"
- sequence-level importance sampling: Weighting entire sampled sequences to correct for distribution mismatch between training and inference. "we apply sequence-level importance sampling for rollout correction"
- subgraph extraction: Selecting a localized subset of a larger graph for task construction or reasoning. "Subgraph Extraction."
- supervised fine-tuning (SFT): Post-training that aligns a model to desired behaviors using labeled trajectories or examples. "We perform supervised fine-tuning (SFT) to initialize the agent"
- tool-in-the-loop generation: Data or task synthesis processes that actively use external tools during creation. "highlight the effectiveness of tool-in-the-loop generation"
- top-: A retrieval parameter specifying how many results to return for each query. "varying the parameter top-, which controls the number of URLs returned for each query."
- vLLM: A high-throughput, memory-efficient inference engine for serving LLMs. "we use vLLM, with a context window of 128K tokens."
Collections
Sign up for free to add this paper to one or more collections.