Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward
Abstract: LLMs exhibit remarkable problem-solving abilities, but struggle with complex tasks due to static internal knowledge. Retrieval-Augmented Generation (RAG) enhances access to external information, yet remains limited in multi-hop reasoning and strategic search due to rigid workflows. Recent advancements in agentic deep research empower LLMs to autonomously reason, search, and synthesize information. However, current approaches relying on outcome-based reinforcement learning (RL) face critical issues such as conflicting gradients and reward sparsity, limiting performance gains and training efficiency. To address these, we first propose Atomic Thought, a novel LLM thinking paradigm that decomposes reasoning into fine-grained functional units. These units are supervised by Reasoning Reward Models (RRMs), which provide Atomic Thought Rewards (ATR) for fine-grained guidance. Building on this, we propose Atom-Searcher, a novel RL framework for agentic deep research that integrates Atomic Thought and ATR. Atom-Searcher uses a curriculum-inspired reward schedule, prioritizing process-level ATR early and transitioning to outcome rewards, accelerating convergence on effective reasoning paths. Experiments on seven benchmarks show consistent improvements over the state-of-the-art. Key advantages include: (1) Atom-Searcher scales computation at test-time. (2) Atomic Thought provides supervision anchors for RRMs, bridging deep research tasks and RRMs. (3) Atom-Searcher exhibits more interpretable, human-like reasoning patterns.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
- Agentic deep research: A paradigm in which LLMs autonomously plan, search, and synthesize information across multiple steps and sources. "Recent advancements in agentic deep research empower LLMs to autonomously reason, search, and synthesize information."
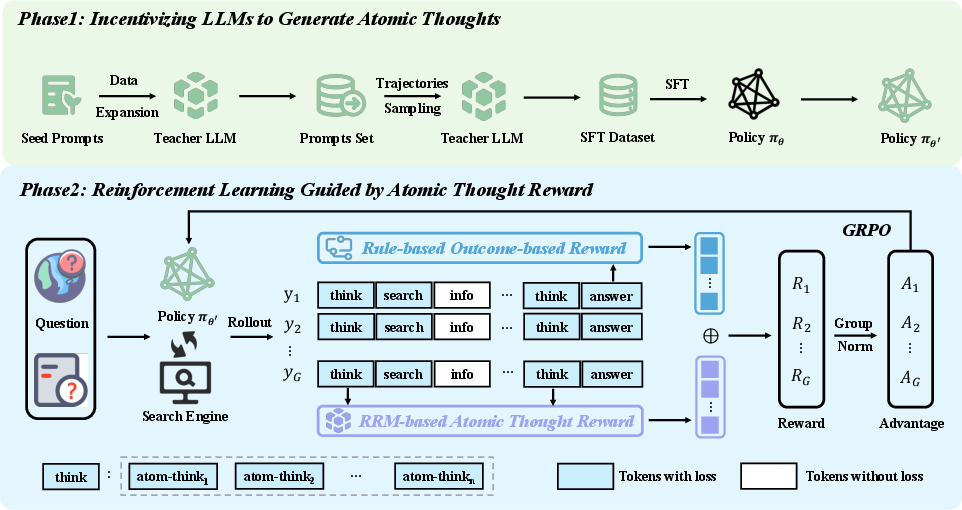
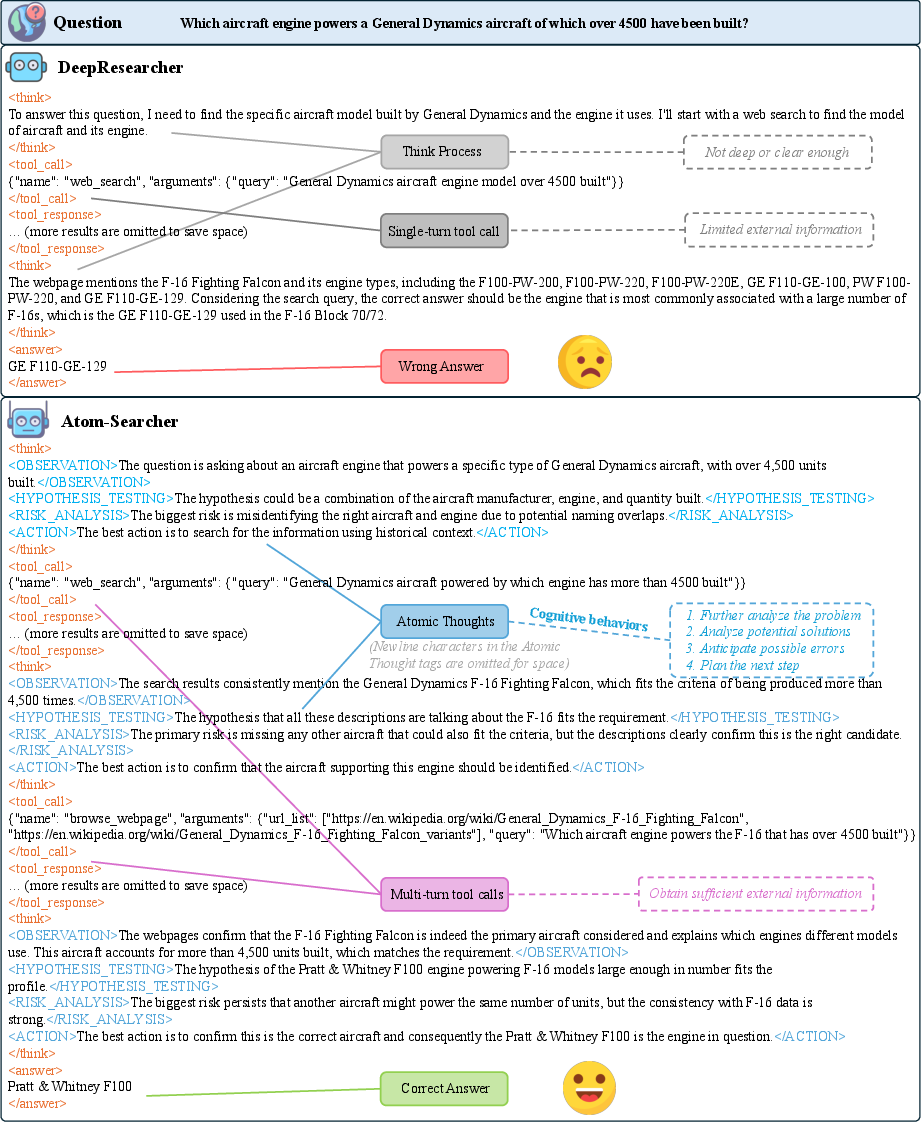
- Atomic Thought: The minimal, functionally coherent unit of reasoning in an LLM’s trajectory, used to structure and supervise process-level thinking. "we first propose Atomic Thought, a novel LLM thinking paradigm that decomposes reasoning into fine-grained functional units."
- Atomic Thought Reward (ATR): A fine-grained reward signal assigned to atomic thoughts to guide learning and mitigate gradient conflicts and sparsity. "we employ a Reasoning Reward Model (RRM) to score the generated Atomic thoughts and construct fine-grained Atomic Thought Reward (ATR)."
- Chain-of-Thought (CoT): A prompting/decoding technique that elicits step-by-step reasoning from LLMs. "CoT: This baseline performs Chain-of-Thought (CoT) reasoning to generate answers without access to any external reference context."
- Credit assignment: The process of attributing reward to individual steps in a trajectory; coarse credit assignment misaligns feedback with true contribution. "A key limitation of outcome-based reward is their coarse credit assignment: it attribute the correctness of intermediate reasoning solely to the final answer, often rewarding or penalizing steps regardless of their actual contribution."
- Curriculum-inspired reward schedule: A training strategy that emphasizes process-level rewards early and gradually shifts weight to outcome rewards as learning progresses. "Atom-Searcher uses a curriculum-inspired reward schedule, prioritizing process-level ATR early and transitioning to outcome rewards, accelerating convergence on effective reasoning paths."
- Entropy collapse: A failure mode in RL where the policy becomes overly deterministic, reducing exploration. "In addition, to mitigate entropy collapse during policy optimization, we adopt a sliding-window-based entropy regulation mechanism"
- Gradient conflicts: Optimization interference where intermediate-step quality and final outcomes receive opposing gradients due to coarse rewards. "This coarse-grained reward design introduces potential gradient conflicts between intermediate reasoning steps and final answers"
- Group Relative Policy Optimization (GRPO): A PPO-style RL algorithm that uses group-normalized advantages and a reference policy for stable updates. "we optimize the policy πθ using the Group Relative Policy Optimization (GRPO) algorithm"
- KL divergence: A measure of divergence between probability distributions, used as a regularization term in policy optimization. "denotes the unbiased estimate of KL divergence"
- Loss masking: Excluding non-trainable or externally provided tokens (e.g., retrieved passages) from the loss to avoid biased updates. "we apply loss masking to exclude these retrieved segments from the optimization objective."
- Markov Decision Process (MDP): A formalism for sequential decision-making defined by states, actions, transitions, and rewards. "We model the process of completing the agentic deep research tasks as a finite-horizon Markov Decision Process (MDP)"
- Monte Carlo Tree Search (MCTS): A simulation-based planning algorithm for exploring action sequences under uncertainty. "CoRAG employs Monte Carlo Tree Search (MCTS) to dynamically select document blocks under budget constraints."
- Multi-hop reasoning: Composing multiple inference steps, often across documents, to solve complex queries. "ineffective at handling real-world questions that require sophisticated multi-hop reasoning and strategic search planning"
- Outcome-based reinforcement learning (RL): RL that provides rewards solely based on final outcomes (e.g., the final answer), not intermediate process quality. "current approaches relying on outcome-based reinforcement learning (RL) face critical issues such as conflicting gradients and reward sparsity"
- Out-of-domain (OOD): Data or tasks that differ from the training distribution, used to test generalization. "both in-domain (ID) and out-of-domain (OOD) scenarios"
- Reasoning Reward Model (RRM): A model that evaluates and scores reasoning steps to provide fine-grained supervisory signals. "we employ a Reasoning Reward Model (RRM) to score the generated Atomic thoughts"
- Retrieval-Augmented Generation (RAG): Enhancing LLM generation by retrieving and incorporating external knowledge sources. "Retrieval-Augmented Generation (RAG) offers solution by equipping LLMs with external information sources"
- Reward sparsity: A situation where feedback is infrequent (e.g., only at the end), making learning inefficient. "reward sparsity, limiting performance gains and training efficiency."
- Sliding-window-based entropy regulation: A technique to maintain exploration by regulating policy entropy over recent steps. "we adopt a sliding-window-based entropy regulation mechanism"
- Supervised fine-tuning (SFT): Post-training on labeled data to specialize or align model behavior. "perform SFT on the policy model to incentivize its ability to generate atomic thoughts."
- Test-Time Scaling: Improving performance by allocating more compute at inference (e.g., longer thinking, more tool calls). "effectively achieves Test-Time Scaling without the introduction of additional incentives for generating more tokens"
Practical Applications
Practical Applications of Atom-Searcher (Atomic Thought + ATR + Curriculum RL)
Below are actionable applications derived from the paper’s Atomic Thought paradigm, Reasoning Reward Models (RRMs), Atomic Thought Rewards (ATR), curriculum-inspired reward aggregation, and the Atom-Searcher RL framework for agentic deep research. Applications are grouped by time-to-deploy and tagged with sectors, with concrete tools/workflows and key assumptions or dependencies.
Immediate Applications
- Evidence-centered research assistant for knowledge work (software, finance, consulting, marketing) — Atom-Searcher can drive multi-hop web research to produce auditable briefs with explicit “atomic thought” segments (e.g., plan, verify, reflect). — Tools/workflows: Browser-integrated agent with tagged think traces; ATR-based quality gate before finalization; test-time scaling knobs for depth/budget control. — Assumptions/dependencies: Reliable web search/browse APIs; acceptable compute latency for longer “think” traces; governance for source attribution.
- Enterprise intranet search and synthesis copilot (software, operations, legal, HR) — Enhances internal RAG with strategic multi-hop search over wikis, tickets, runbooks, and policy docs; improves accuracy by scoring process steps with RRMs. — Tools/workflows: “Atomic Thought Logger” SDK; RRM microservice to score process steps; hybrid reward–trained model tuned on enterprise corpora. — Assumptions/dependencies: Access controls/privacy; domain-adapted RRM prompts; audit logging for compliance.
- Compliance and due diligence summarization (finance, legal, procurement) — Produces explainable, step-tagged compliance checks and vendor due diligence with explicit verification and risk analysis substeps. — Tools/workflows: “Risk/Verification” atomic-thought templates; ATR thresholds to gate report release; checklists generated from process-level traces. — Assumptions/dependencies: Up-to-date regulations; human-in-the-loop signoff; robust citation requirements.
- Investigative journalism and OSINT triage (media, public sector) — Multi-source, conflict-aware synthesis with transparent reasoning segments for claim verification and counter-claim tracking. — Tools/workflows: Web agent with source de-duplication; hypothesis tracking via atomic thoughts; ATR-weighted prioritization of leads. — Assumptions/dependencies: Source credibility modeling; content licensing; timing/latency tolerance for deeper searches.
- Academic literature review and related work synthesis (academia, pharma R&D) — Iterative search and synthesis with explicit plan/verify/limitations steps; more reliable scoping and gap analysis. — Tools/workflows: Scholar/API connectors; “atomic extraction” of methods/findings; ATR to filter low-value reading paths. — Assumptions/dependencies: Access to academic indices; domain-tuned RRMs; proper citation formatting.
- Fact-checking and misinformation triage (policy, media, platforms) — Fine-grained scoring of reasoning chains reduces reward sparsity and improves detection of reasoning shortcuts or cherry-picking. — Tools/workflows: RRM-facilitated rubric for claim/quote/source evaluation; ATR-triggered flags for inconsistent steps. — Assumptions/dependencies: Calibrated RRMs for domain nuances; adversarial robustness; clear policy on platform interventions.
- Explainable customer support assistant (software, consumer electronics, SaaS) — Agents follow structured “diagnose → test → verify” atomic thoughts across knowledge bases and forums; creates auditable fixes. — Tools/workflows: Instrumented troubleshooting flows with thought tags; ATR-based guardrails to avoid premature resolutions. — Assumptions/dependencies: Up-to-date KBs; latency budgets; escalation paths to humans.
- Developer copilot with strategic doc/code search (software engineering) — Plans and verifies code answers using structured web/doc search; tags limitations and risks explicitly. — Tools/workflows: Repository/issue tracker connectors; “verification” atomic thought to run examples or cite docs; ATR to penalize hallucinated APIs. — Assumptions/dependencies: Sandbox execution where allowed; codebase permissions; privacy.
- Procurement and vendor comparison assistant (operations, finance) — Multi-criteria comparison with explicit hypotheses, risk analysis, and verification traces to support purchase decisions. — Tools/workflows: Structured comparison templates; ATR thresholds for evidence sufficiency; cost/performance sensitivity analysis. — Assumptions/dependencies: Accurate vendor data; consistent taxonomy of criteria; human review for final decisions.
- Education: metacognitive tutoring and study skills coach (education, consumer) — Teaches students to plan, reflect, verify, and check sources by surfacing atomic thoughts and scoring them with an RRM rubric. — Tools/workflows: Instructor dashboard showing process-level progress; “self-check” atomic thought prompts; personalized feedback via RRM scores. — Assumptions/dependencies: Age-appropriate content filters; clarity that it’s not grading final correctness alone; privacy.
- Training pipeline enhancement for existing agents (ML operations) — Integrate ATR with outcome rewards in RL fine-tuning to alleviate gradient conflicts and speed convergence for any agentic workflow (not just web search). — Tools/workflows: Curriculum reward scheduler module; GRPO-based trainer with loss masking; ATR scoring service. — Assumptions/dependencies: Access to compute for multi-trajectory rollouts; stable reward API; tagged thought output capability.
- Transparent audit console for AI-assisted decision-making (governance, risk, compliance) — Exposes atom-level reasoning for internal audit, model risk management, and regulatory reporting. — Tools/workflows: “Reasoning Trace Explorer” UI; ATR heatmaps over trajectories; exportable audit artifacts with citations. — Assumptions/dependencies: Organizational acceptance of process logging; secure storage and PII handling.
- Personal research assistant for life decisions (consumer: travel, major purchases, health information seeking) — Structured planning, verification of claims, and risk analysis for product comparisons, travel planning, or lifestyle choices. — Tools/workflows: Browser plugin; “verify before recommend” flow; adjustable test-time compute slider for thoroughness vs speed. — Assumptions/dependencies: Clear disclosures; non-professional advice disclaimers; up-to-date data sources.
Long-Term Applications
- Regulated decision-support with verifiable reasoning (healthcare, legal, public policy) — Deploy agents that surface process-level evidence trails suitable for audits and regulatory scrutiny. — Tools/workflows: Certified “Atomic Thought” schemas; domain RRMs validated by clinical/legal standards; human-AI joint signoff. — Assumptions/dependencies: Regulatory acceptance of process-level evidence; rigorous validation; liability frameworks.
- Autonomous science assistants for hypothesis generation and experimental planning (academia, biotech, materials) — Multi-hop literature and data synthesis to propose testable hypotheses, with explicit uncertainty and risk atoms. — Tools/workflows: LIMS/ELN integration; structured hypothesis and verification templates; ATR to encourage conservative claims. — Assumptions/dependencies: Access to datasets/instruments; strong domain RRMs; oversight by domain experts.
- Policy impact analysis and multi-scenario evidence synthesis (government, think tanks, NGOs) — Agents evaluate trade-offs with transparent assumptions, counterfactuals, and contested evidence handling. — Tools/workflows: Scenario planning modules; source reliability weighting; “conflict resolution” atomic thoughts. — Assumptions/dependencies: Diverse datasets; bias-aware RRMs; stakeholder review cycles.
- Enterprise-grade autonomous web agents with safe browsing (software, cybersecurity) — End-to-end web interaction with containment, content sanitization, and interpretable process trails. — Tools/workflows: Secure browsing sandboxes; provenance and watermarking; ATR to penalize unsafe or low-value browsing. — Assumptions/dependencies: Robust web interaction APIs; content safety and copyright compliance; red-team testing.
- Multi-agent research systems with specialized atomic thought roles (software, education, scientific discovery) — Decompose research into planner, verifier, critic, and synthesizer agents coordinated via ATR-calibrated exchanges. — Tools/workflows: Orchestration frameworks; inter-agent RRM scoring; role-specific atomic thought libraries. — Assumptions/dependencies: Communication protocols; cost control; convergence guarantees.
- Industry-specific RRMs and ATR rubrics (healthcare guidelines, financial analysis, legal reasoning) — Domain-calibrated reward models that better assess process quality and reduce reward sparsity in specialized tasks. — Tools/workflows: RRM training datasets curated per domain; rubric authoring tools; ongoing post-deployment calibration. — Assumptions/dependencies: Expert-annotated data; continual learning infrastructure; evaluation suites.
- Standardization of thought tagging and audit artifacts (cross-industry) — Common schemas for atomic thought tags and audit logs to enable interoperability and compliance. — Tools/workflows: Open standards consortium; validators; reference implementations and certification. — Assumptions/dependencies: Multi-stakeholder alignment; regulatory buy-in; backward compatibility.
- Budget-aware test-time scaling controllers (cloud cost, edge/on-device) — Adaptive controllers that trade off depth of thinking and tool calls against latency/cost under service-level constraints. — Tools/workflows: Dynamic token/tool call budgets; performance–cost dashboards; per-task difficulty estimators. — Assumptions/dependencies: Reliable performance–cost models; resource governance; business rules.
- Training-method exports to non-web agents (robotics planning, data engineering, autonomous ops) — Use ATR-style process rewards and curricula to mitigate credit assignment issues in long-horizon tasks beyond text. — Tools/workflows: Simulator-integrated RRMs (or proxy evaluators); atomic action/plan tags; hybrid reward trainers. — Assumptions/dependencies: MDP reformulations with textual/plannable intermediates; safe exploration.
- Corporate knowledge graph curation with provenance (energy, manufacturing, pharma) — Agents ingest and reconcile documents into a KG while exposing atom-level reasoning and source trails. — Tools/workflows: KG builders with “explainable merge” atoms; ATR to discourage spurious links; dispute resolution flows. — Assumptions/dependencies: Data normalization; ontology design; source licensing.
- Process analytics and continuous improvement for AI agents (MLOps, quality) — Use ATR distributions to detect regressions, shortcutting, or drift in agent reasoning patterns over time. — Tools/workflows: Reasoning telemetry pipelines; ATR-based anomaly detection; automatic retraining triggers. — Assumptions/dependencies: Longitudinal logging; privacy-preserving analytics; robust baselines.
- Educational accreditation and assessment of reasoning processes (education policy) — Move beyond answer-only grading to process-quality assessment at scale using RRMs anchored by atomic thoughts. — Tools/workflows: Assessment rubrics encoded in RRMs; audit-friendly student portfolios; fairness audits. — Assumptions/dependencies: Stakeholder agreement; bias and equity controls; data security.
- Marketplaces for evaluators and atomic-thought plugins (ecosystem) — Third-party RRMs/rubrics and reusable atomic thought libraries for specific domains and tasks. — Tools/workflows: Plugin registries; evaluator benchmarking; revenue-sharing and governance. — Assumptions/dependencies: Open APIs; IP/licensing norms; quality/reputation systems.
Notes on Feasibility and Cross-Cutting Dependencies
- Model capability and tagging: Requires models capable of reliably emitting structured tags (> , <atom-think>, etc.) and adhering to tool-call schemas. > > - RRM availability and cost: Access to a strong, domain-appropriate RRM (e.g., Qwen family, DeepSeek-R1-like) with acceptable inference cost/latency. > > - Compute budgets: Test-time scaling increases tokens and tool calls; productization needs budget controllers and caching. > > - Data and access: Web and/or enterprise data access, with appropriate privacy, security, and licensing. > > - Safety, audit, and compliance: Process logging introduces sensitive traces; requires secure storage, PII handling, and clear governance. > > - Human-in-the-loop: For high-stakes applications, human review remains a key assumption for approval and liability management. > > - Domain adaptation: Domain-specific RRMs and prompts may be necessary to ensure accurate process scoring and reduce spurious reward signals.
Collections
Sign up for free to add this paper to one or more collections.