- The paper presents ConStory-Bench, a 2,000-prompt benchmark and ConStory-Checker to systematically detect consistency errors in long-form narrative generation.
- It categorizes errors into five primary types, revealing that factual detail and timeline inconsistencies scale linearly with narrative length.
- Automated checking demonstrates superior recall over human judgment, with token-level entropy serving as an early indicator of inconsistencies.
Consistency Bugs in Long Story Generation by LLMs: An Expert Synthesis
Introduction and Motivation
Advancements in LLMs have yielded the capability to generate ultra-long narratives. However, maintaining consistency—tracking entities, facts, temporal logic, and narrative style—remains a systematic issue absent from traditional evaluation paradigms. Existing benchmarks have focused on plot quality and fluency, underrepresenting global consistency. This paper introduces ConStory-Bench, designed to detect, categorize, and analyze consistency errors in long-form story generation, and ConStory-Checker, an automated validator grounded in explicit text evidence. The research systematically analyzes the error properties across contemporary LLM architectures, quantifies dominant inconsistency types, and reveals critical challenges for future generation systems.
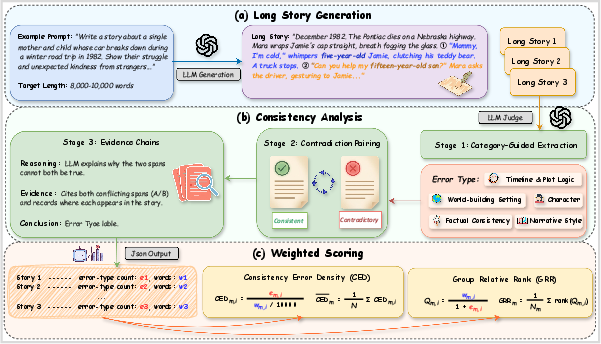
Figure 1: Overview of ConStory-Bench, which comprises a 2,000-prompt benchmark, ConStory-Checker's error extraction pipeline, and scoring metrics for narrative consistency evaluation.
Benchmark Design and Error Taxonomy
ConStory-Bench is constructed from 2,000 prompts, each falling into one of four rigorous narrative generation scenarios: Generation, Continuation, Expansion, and Completion. These scenarios encompass a wide spectrum of story development challenges, explicitly targeting the context maintenance dimension.
The error taxonomy is hierarchical, featuring five primary categories: Timeline/Plot Logic, Characterization, World-building/Setting, Factual Detail Consistency, and Narrative Style, encompassing a total of 19 subtypes. Contradictions span temporal logic failures, character trait memory faults, world rule violations, factual mismatches, and stylistic incoherence.

Figure 2: Consistency error examples from real LLM-generated stories, with highlighted contradictions across taxonomy axes for direct illustration.
Automated Consistency Checking: ConStory-Checker
ConStory-Checker is a four-stage LLM-as-judge pipeline. It employs category-specific extraction, contradiction pairing, explicit evidence chain construction, and standardized JSON reporting. Crucially, judgments are grounded in quoted text positions, supporting transparent, reproducible evaluation aligned with recent advances in structured LLM assessment. Validation against human annotation shows substantially superior recall (+3.2× error discovery rate, F1=0.678 vs. human F1=0.281), particularly in Character Consistency and Factual Accuracy detection.
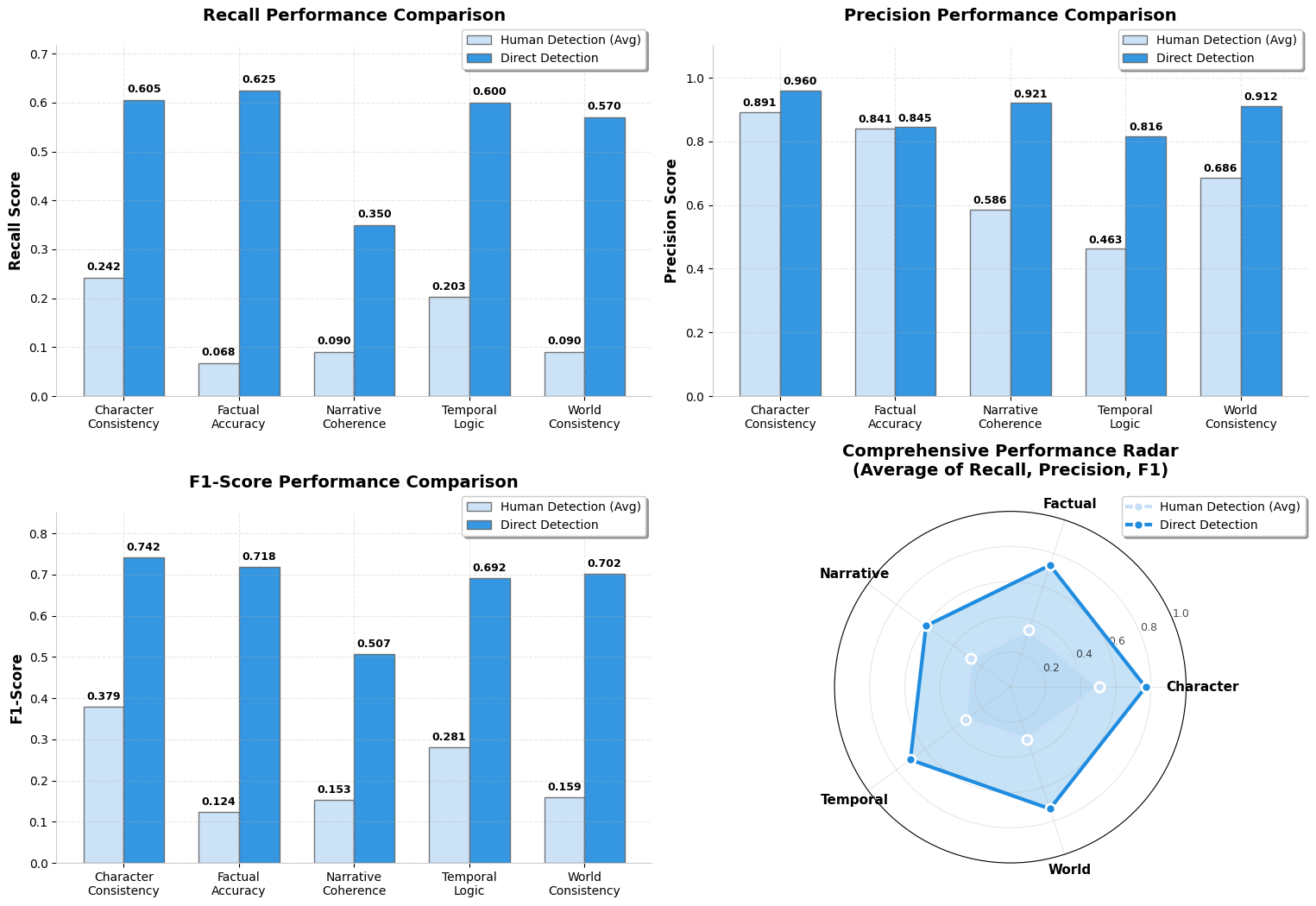
Figure 3: Comparative performance of ConStory-Checker against human experts demonstrating high precision and competitive F1 across error categories.
Comprehensive Model Evaluation
Error Density and Relative Ranking
Model consistency was assessed with two primary metrics: Consistency Error Density (CED, errors per 10K words) to normalize for output length, and Group Relative Rank (GRR) for prompt-level, length-aware output comparison. Empirical results reveal substantial inter-model variance:
- GPT-5-Reasoning achieves lowest CED (0.113) and best GRR (2.80), outperforming all evaluated systems.
- Open-source models (e.g., GLM-4.6: CED 0.528, Qwen3-32B: CED 0.537) approach proprietary performance.
- Enhanced and agentic models (e.g., LongWriter-Zero, SuperWriter) obtain competitive scores via advanced generation strategies.
- All models are most error-prone in Factual Detail and Timeline/Plot Logic.
Output Length and Error Scaling
Story output lengths vary widely. Proprietary models tend to prefer longer narratives (e.g., >90% of GPT-5-Reasoning and Claude-Sonnet-4.5 outputs exceed 6K words), while several open-source and baseline models generate predominantly short texts. There is a near-linear scaling of errors with increasing output length.
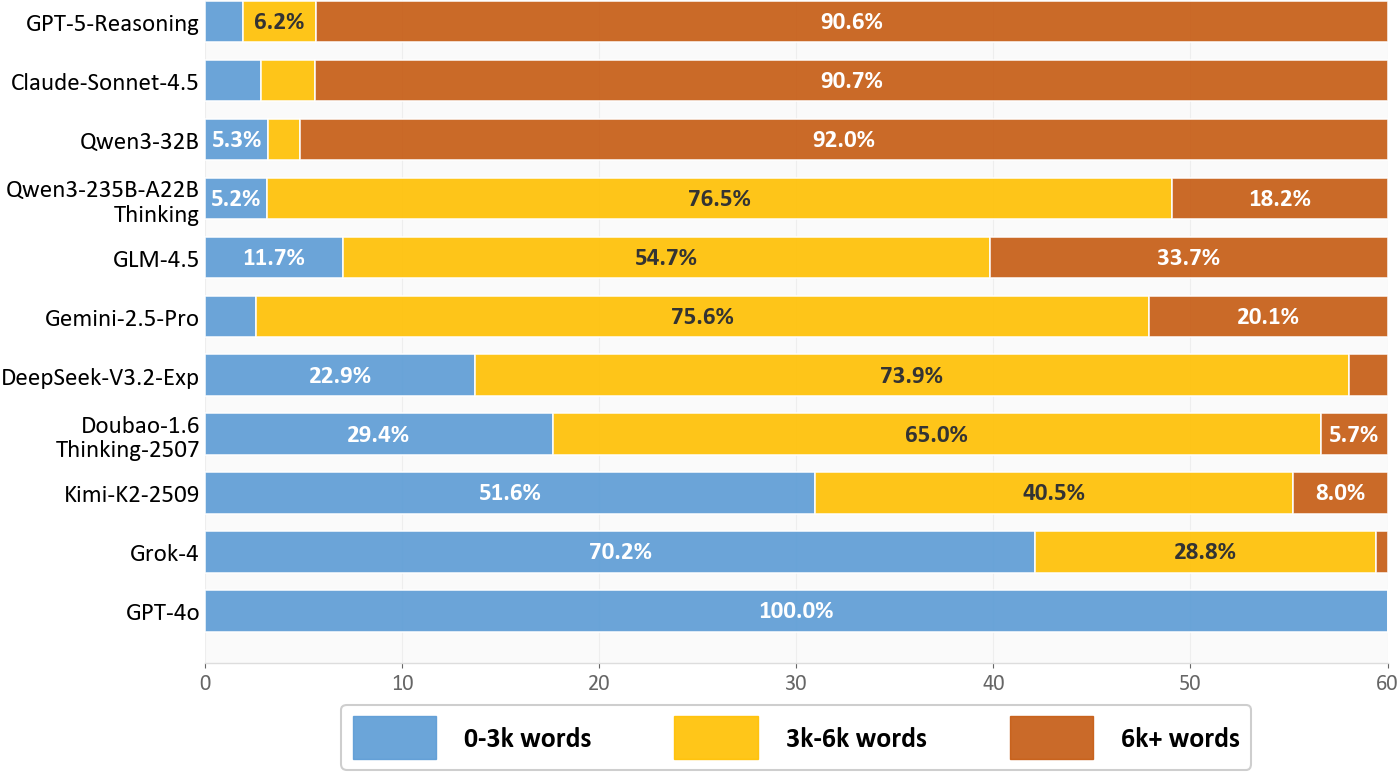
Figure 4: Output length distributions for representative models, evidencing diverse length preferences.
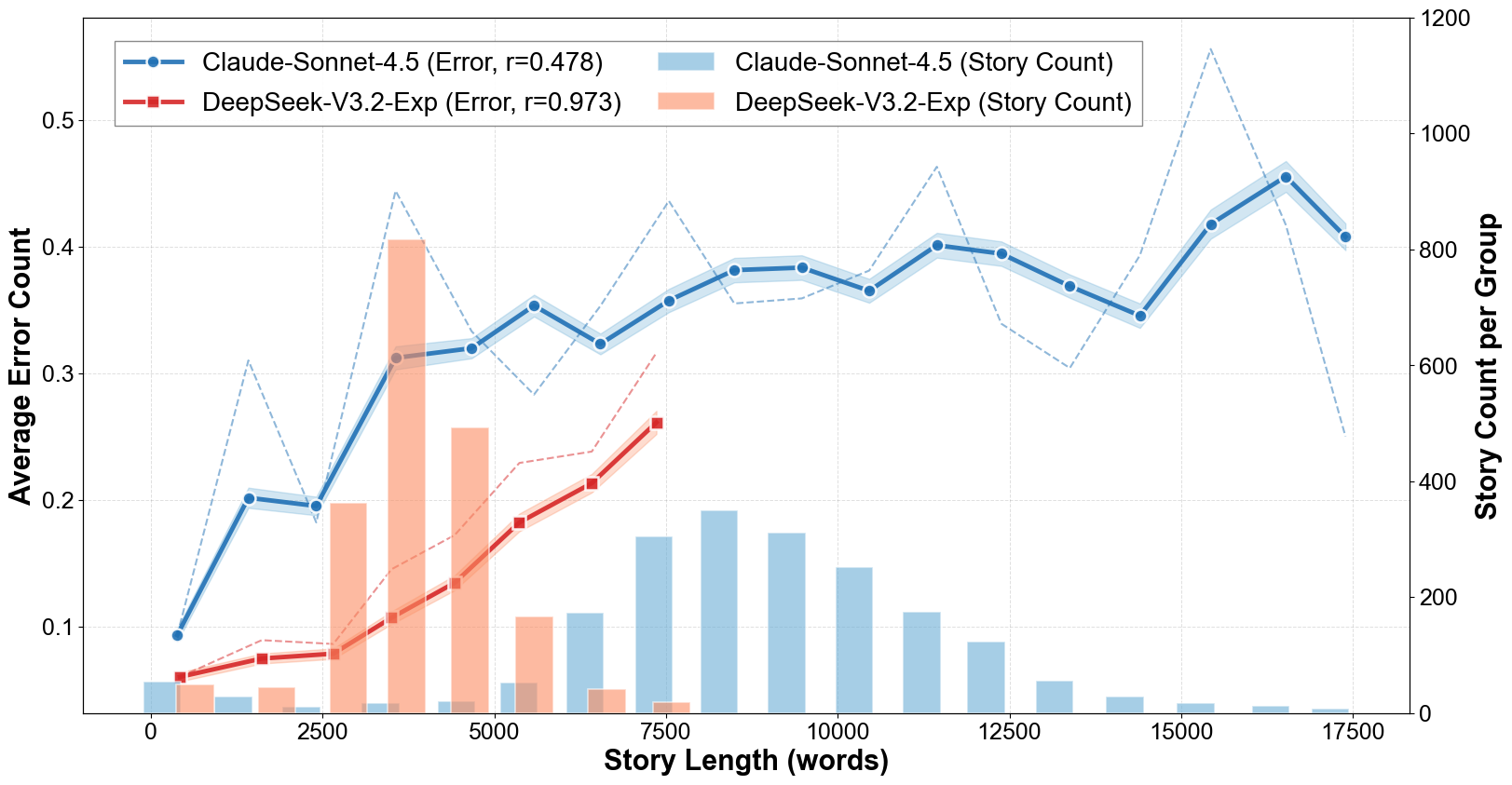
Figure 5: Consistency error count increases approximately linearly with narrative length, highlighting the challenge in scaling coherence maintenance.
Error Type Prevalence and Co-occurrence
Aggregate error analysis uncovers that Factual Detail inconsistencies strongly correlate with Characterization, World-building, and Temporal Logic errors (e.g., Factual–Characterization: r=0.304), suggesting shared underlying mechanisms and a compounding effect in longer contexts. Narrative Style errors, conversely, have minimal correlation with other categories, indicating orthogonal origins.
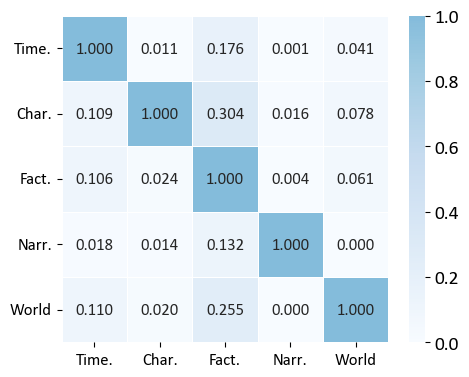
Figure 6: Correlation matrix of error categories, with darker blue indicating more frequent co-occurrence; Factual Detail occupies a central position.
Positional Dynamics of Consistency Errors
Contradictions tend to surface predominantly in the narrative's middle segments (fact establishment at ~15–30%, contradiction appearance at ~40–60% of story progression), with specific error classes (geographical, temporal) showing large positional gaps (e.g., geographical avg. gap: 31.0%), consistent with long-distance memory breakdowns. Perspective/confusion errors cluster locally, suggesting different computational failure modes.
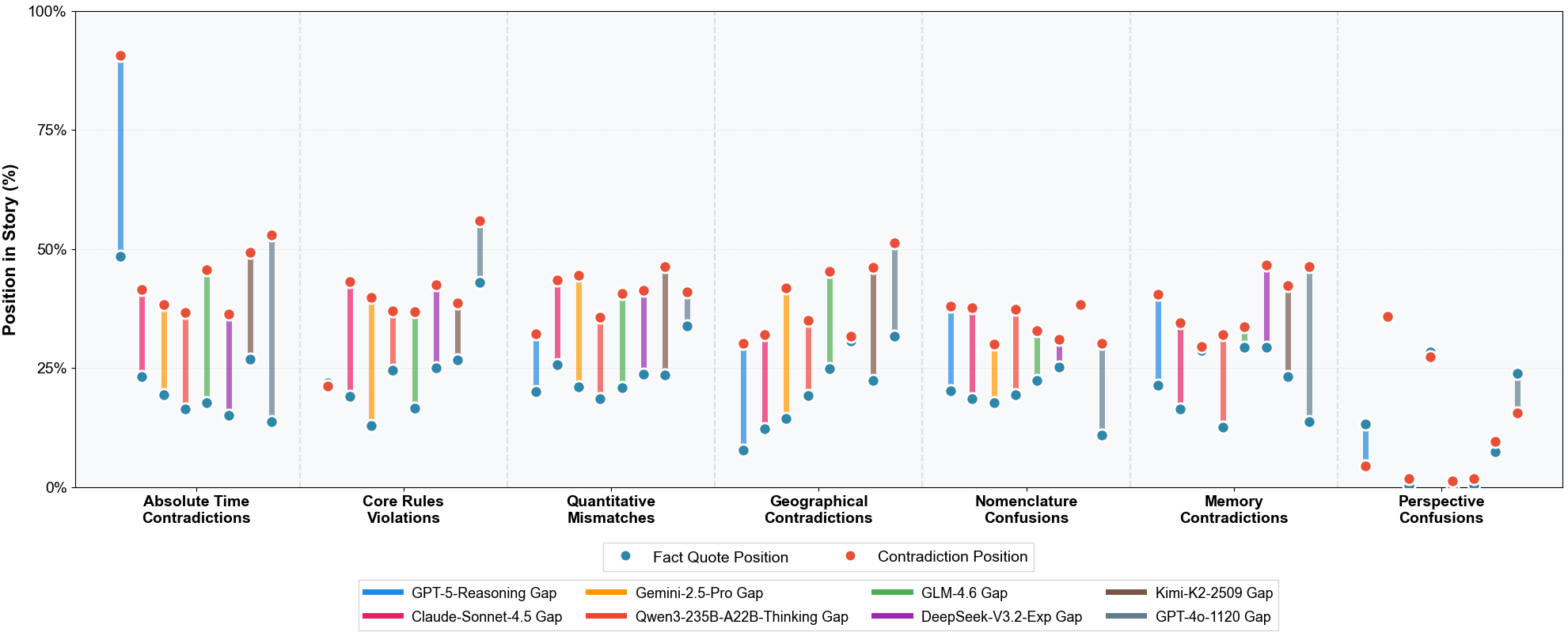
Figure 7: Distribution of error subtypes over narrative position, with fact and contradiction position gaps visualized per error type and model.
Token-Level Uncertainty as a Marker of Consistency Failures
A systematic entropy analysis finds that error-prone segments exhibit significantly higher token-level entropy (Qwen3-4B: +19.24%, Qwen3-30B: +12.03%). This supports the thesis that LLMs possess measurable uncertainty preceding inconsistency, establishing entropy (and related metrics such as perplexity and token probability) as a quantitative early-warning signal for proactive contradiction mitigation.
A cross-family leaderboard, visualized through GRR-based bar plots, demonstrates that proprietary models like GPT-5-Reasoning dominate consistency, but advanced open-source, capability-enhanced, and agentic systems are closing the gap.
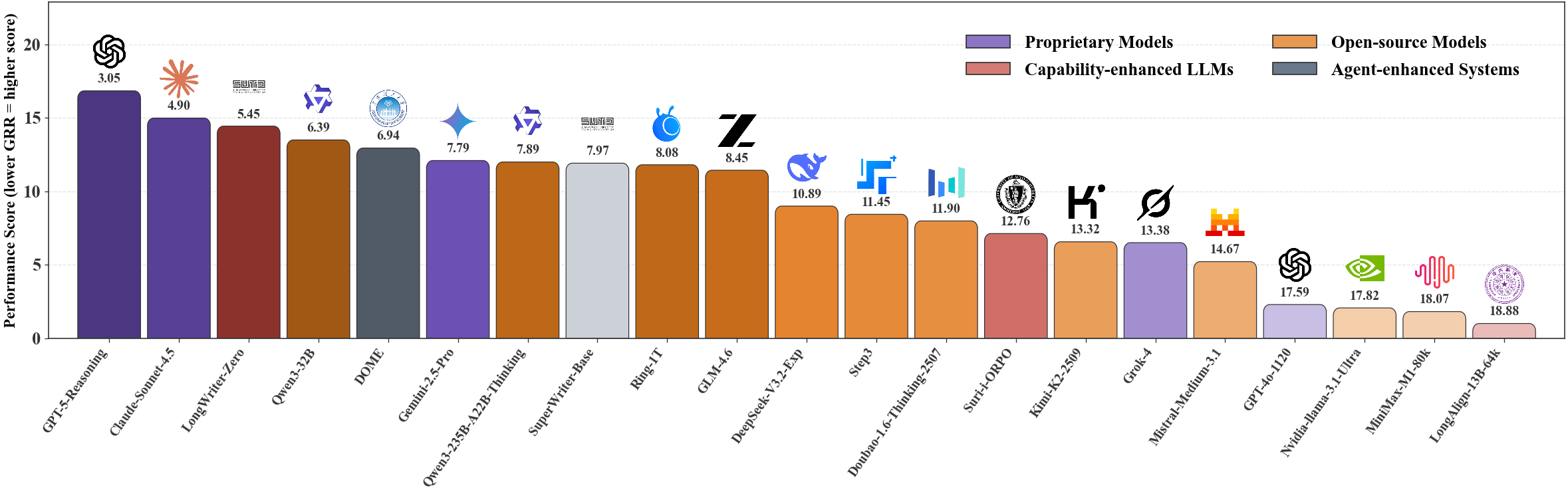
Figure 8: Performance leaderboard highlighting GRR-based relative consistency rankings across LLM families.
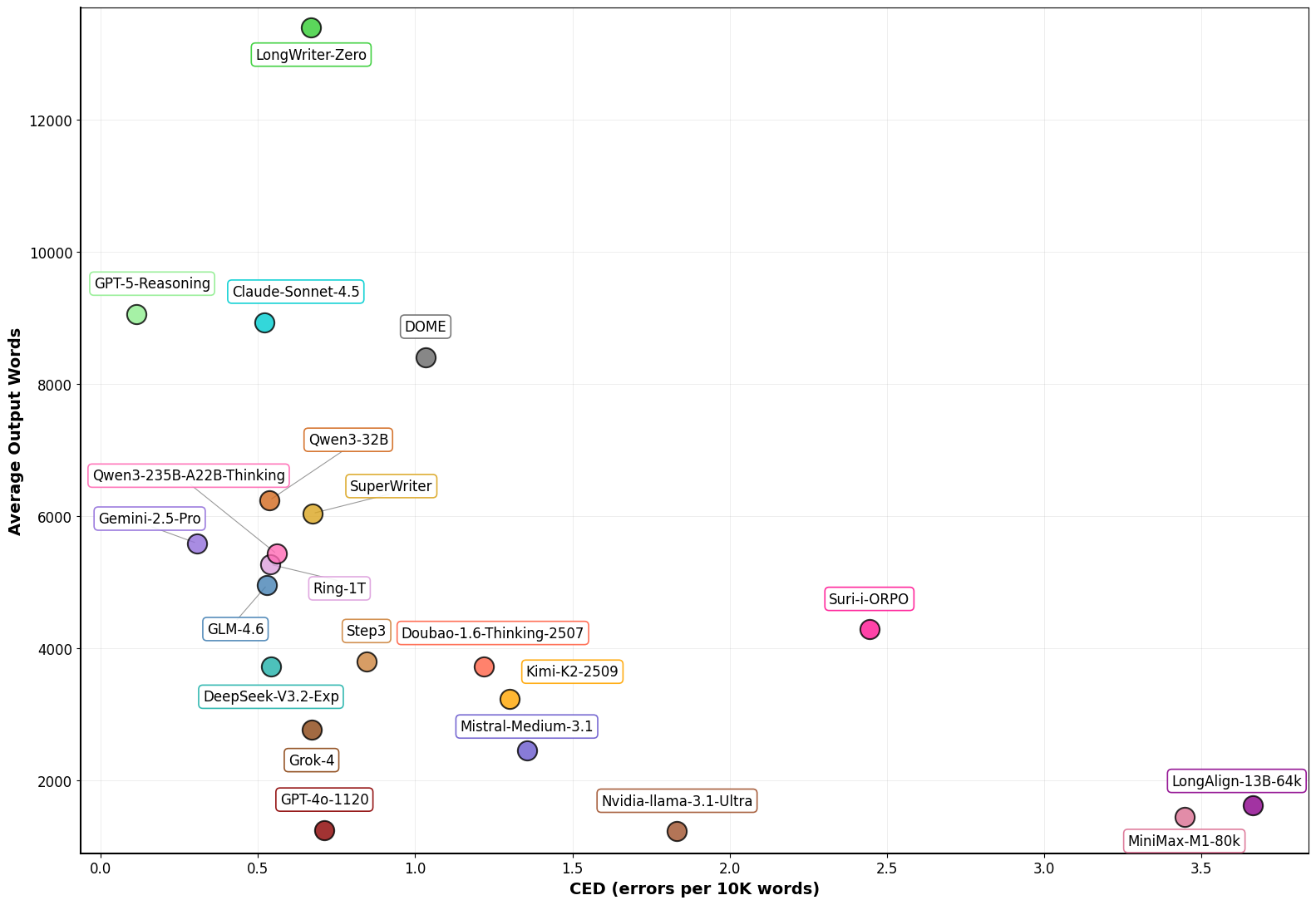
Figure 9: Scatter plot relating consistency performance (CED) to average output length for evaluated systems.
Model-specific error co-occurrence matrices further support the robustness of aggregate trends while illuminating architecture-specific interaction patterns.
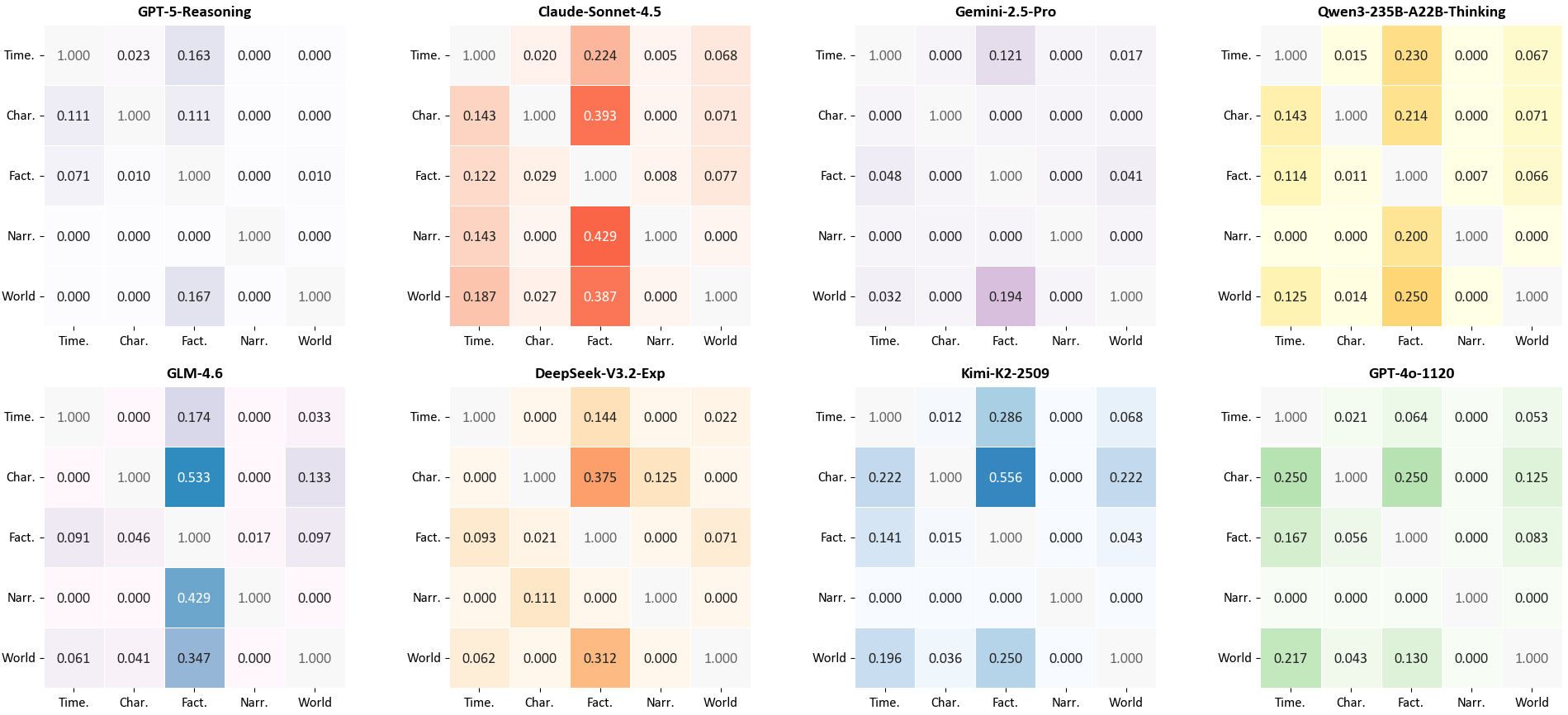
Figure 10: Model-wise error correlation matrices for eight models, illustrating cross-category dependency heterogeneity.
Implications and Future Directions
Theoretical Implications
The observed clustering of errors around specific narrative regions and their co-occurrence patterns reinforce the necessity for non-local, context-aware memory architectures. The robust association of high token-level entropy with error emergence empirically grounds the argument for using uncertainty quantification as a signal for narrative self-verification within generative models.
Practical Implications
Practical deployment of long-form LLM-generated narratives should leverage local entropy-based routines to trigger consistency-checking modules proactively, particularly when generating high-entropy segments. Hybrid systems incorporating agentic memory, explicit entity and fact tracking, or long-range attention mechanisms are likely to yield consistency improvements. Moreover, the documented superiority of automated consistency checking over human judgment in this setting positions LLM-based pipelines as practical, scalable QA for long-form content production.
Future Research
Major open directions include extending the benchmark to non-Western and multilingual narrative conventions, developing models that distinguish intentional from erroneous contradiction, and adapting frameworks to complex technical or expository (non-fiction) long-form generation. Advancements in long-range context modeling, continual entity linking, and explicit reasoning chains will be critical.
Conclusion
This paper delivers a rigorous framework—ConStory-Bench and ConStory-Checker—enabling reproducible, fine-grained measurement of narrative consistency in LLM-generated long stories. The main findings demonstrate that current systems, despite improvements, systematically introduce consistency bugs, especially as story length increases, with error density strongly associated with factual and temporal-tracking failures. Quantitative uncertainty signals anticipate these errors, offering a foundation for real-time detection and mitigation. The methodology and results chart a precise path for the next generation of reliable, long-form NLG systems.