Reject, Resample, Repeat: Understanding Parallel Reasoning in Language Model Inference
Published 9 Mar 2026 in cs.LG, cs.AI, cs.CL, math.ST, and stat.ML | (2603.07887v1)
Abstract: Inference-time methods that aggregate and prune multiple samples have emerged as a powerful paradigm for steering LLMs, yet we lack any principled understanding of their accuracy-cost tradeoffs. In this paper, we introduce a route to rigorously study such approaches using the lens of particle filtering algorithms such as Sequential Monte Carlo (SMC). Given a base LLM and a process reward model estimating expected terminal rewards, we ask: how accurately can we sample from a target distribution given some number of process reward evaluations? Theoretically, we identify (1) simple criteria enabling non-asymptotic guarantees for SMC; (2) algorithmic improvements to SMC; and (3) a fundamental limit faced by all particle filtering methods. Empirically, we demonstrate that our theoretical criteria effectively govern the sampling error of SMC, though not necessarily its final accuracy, suggesting that theoretical perspectives beyond sampling may be necessary.
The paper presents a particle filtering framework that rigorously integrates parallel inference techniques with reward models for improved LLM completions.
It formalizes criteria such as action-level coverage and bounded chi-squared divergence to ensure reliable approximations and computational efficiency.
Empirical results on benchmark tasks show significant accuracy gains over Best-of-N methods, highlighting both theoretical and practical advancements.
Formal Analysis of Parallel Reasoning in LLM Inference via Particle Filtering
Motivation and Framework
The paper "Reject, Resample, Repeat: Understanding Parallel Reasoning in LLM Inference" (2603.07887) develops a rigorous theoretical and empirical foundation for parallel-inference techniques used to steer LLMs toward high-quality completions. This paradigm leverages multiple generations evaluated and aggregated at inference time, motivated by the practical success of methods such as Best-of-N, self-consistency, and branching policies in mathematical reasoning and question answering.
Central to the analysis is the use of a Process Reward Model (PRM), which scores intermediate or partial generations. The aim is to sample from a distribution tilted by the reward function, i.e., p∗(a1:H)∝p(a1:H)r∗(a1:H), with p being an LLM's base distribution and r∗ a reward measuring task-specific success (e.g., correctness). PRMs are typically trained or heuristically constructed to estimate the future expected reward given a partial sample.
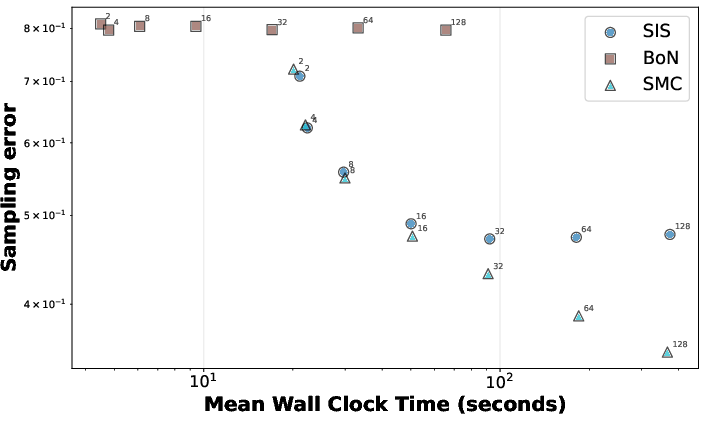
Practical inference-time steering methods are formalized as particle filtering algorithms, particularly Sequential Monte Carlo (SMC), which adaptively prune, replicate, and score multiple particles as tokens are generated.
Theoretical Contributions
Criteria for Effective Particle Filtering
The analysis establishes two --- action-level coverage and PRM accuracy --- as necessary and sufficient for SMC to yield robust approximations of the reward-tilted distributions in LLM output space. Specifically:
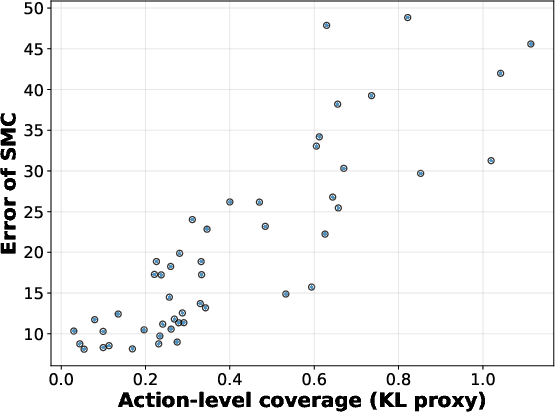
Action-Level Coverage: The proposal distribution must not undersample key actions, formalized by a uniform upper bound on the ratio between target and proposal distributions at each step.
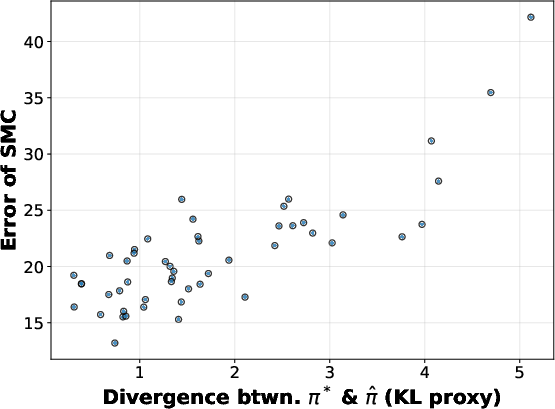
Bounded χ2-Divergence: The intermediate PRM-based target distributions should not diverge excessively from the optimal value function.
The main theorem shows that SMC with N particles samples from a distribution ν satisfying νp∗≤NH2(ϕ+1), with ϕ encapsulating coverage and divergence properties. This parallelizes inference compared to backtracking-based methods like VGB, which achieve similar guarantees with Ω(H2) sequential runtime.
Exponential Error Decay: By wrapping SMC in an outer rejection sampling loop (SMC-RS), exponential suppression of error is attainable when PRM accuracy holds in the stronger L∞ sense.
Inherent Limits: Even with a perfect PRM, SMC requires Ω(H) particles to achieve low error, whereas the one-particle action-level rejection algorithm succeeds trivially under perfect value functions. The SMC-RS variant closes this gap.
Crucially, the hardness results show that for myopic (non-lookahead) particle filtering, superlinear scaling in the number of particles as a function of horizon H is unavoidable under modest PRM error.
Empirical Validation
Synthetic Prompt-Switching Tasks
Experiments examine SMC's behavior when manipulating action-level coverage and PRM accuracy in controlled prompt-switching settings (where p and p∗ are LLM output distributions under different prompts). Sampling error is evaluated using logprob discrepancy metrics, revealing strong correlations between theoretical quantities (coverage, divergence) and empirical error.
Figure 2: SMC performance as a function of the number of particles in prompt-switching; SMC outperforms sequential importance sampling (SIS) and Best-of-N.
Math Problem-Solving Benchmarks
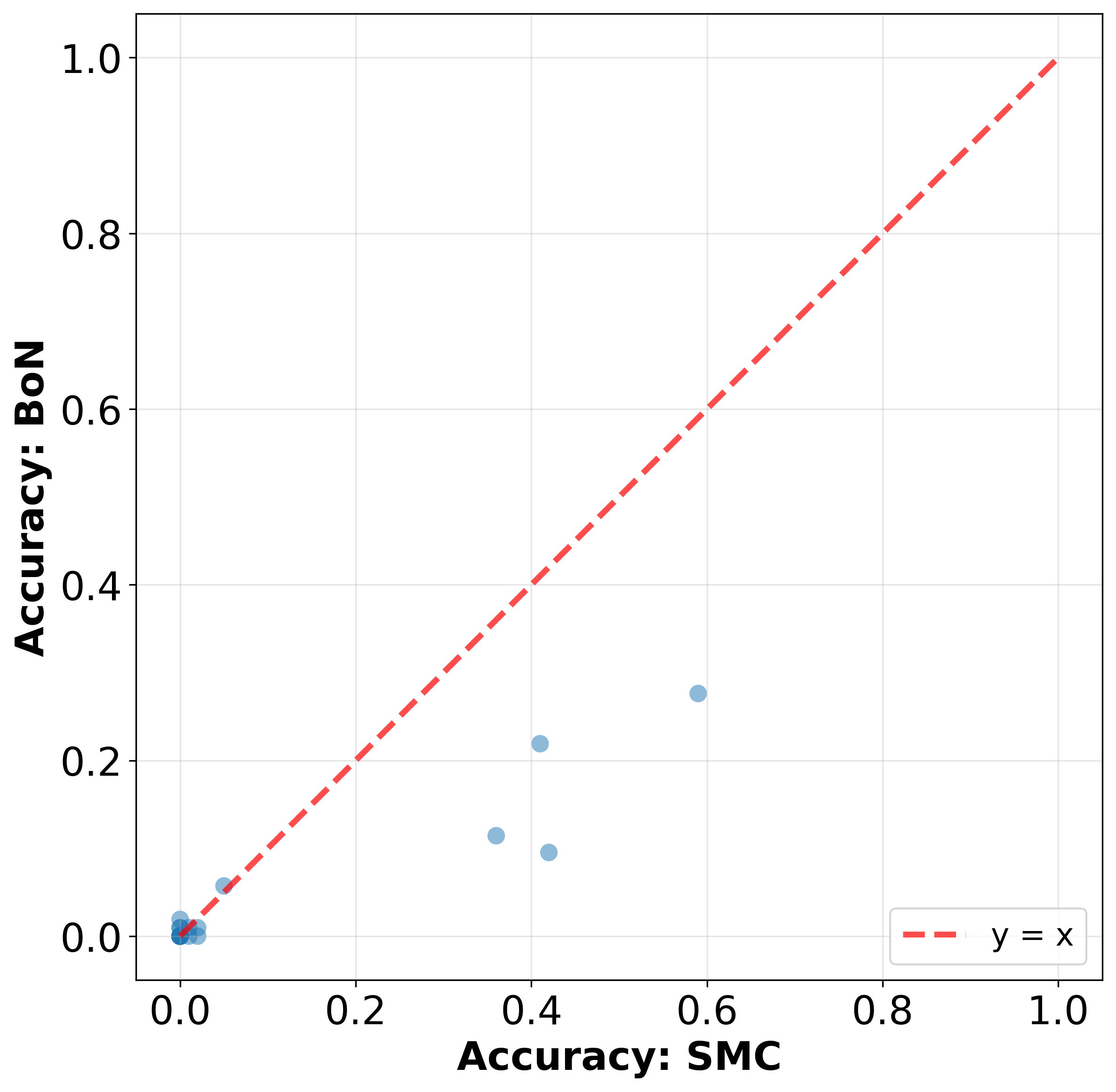
On tasks such as Math500 and AIME, SMC outperforms Best-of-N sampling across nearly all individual problems, not merely in expectation. This is visually confirmed by plotting SMC accuracy against Best-of-N for each problem.
Figure 3: SMC with N=32 particles improves performance over Best-of-N on Math500 for most problems.
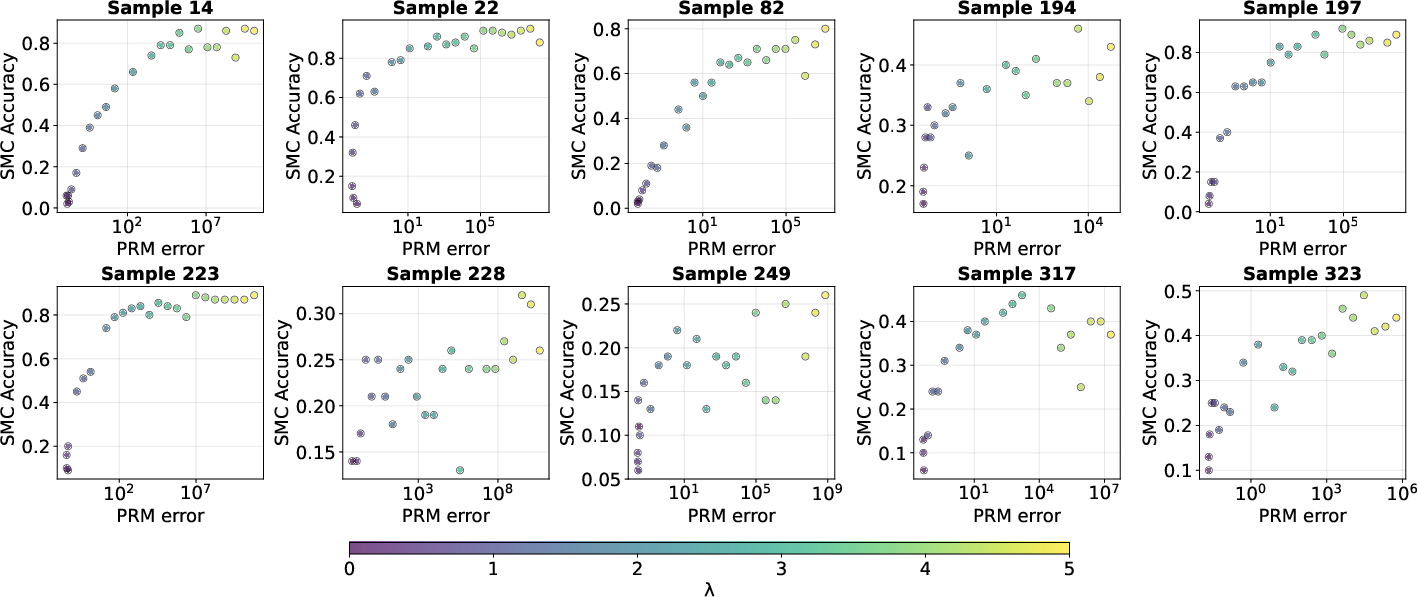
Interestingly, larger PRM divergence (as measured via empirical χ2) sometimes correlates with higher accuracy––a deviation from the theoretical prediction. This suggests that in practice, modes missed by the PRM may be less relevant to accuracy, or that aggressive pruning (e.g., via lower temperature scaling) can refine solution space more effectively, albeit risking mode misspecification.
Figure 4: Influence of PRM error (χ2 divergence) on SMC accuracy for Math500; higher divergence is sometimes associated with greater accuracy.
Key Numerical Results
SMC achieves uniform accuracy improvements over Best-of-N across Math500 tasks, not just on average.
Empirical correlation coefficients in action-level coverage experiments reach values r=0.83–$0.89$, indicating strong predictive power of the theoretical metrics.
SMC requires N=Ω(H) particles for non-trivial accuracy, even with perfect PRMs, formalizing computational limits.
Figure 5: r=0.83.
Figure 6: r=0.70.
Figure 7: r=0.78.
Practical and Theoretical Implications
This work unifies and extends the theoretical landscape of inference-time steering in LLMs. The criteria derived serve not only as diagnostic tools for practical tuning (e.g., selecting PRMs, determining particle counts), but also as fundamental guides for developing new variants that minimize both coverage gaps and PRM misestimation. The explicit identification of computational lower bounds underscores the limits of purely parallel inference and suggests avenues for hybrid, lookahead, or batch/backtracking approaches in future implementations.
The surprising empirical findings (e.g., the benefit of aggressive PRM temperature scaling even at high divergence) point to the limitations of distributional closeness as a metric of success in tasks where only partial mass coverage (e.g., finding one correct answer) suffices. This motivates the search for weaker but more problem-aligned theoretical metrics, as well as robust methodologies for process reward selection in applied domains.
Future Directions
Among unresolved questions are:
Closing the gap in upper/lower bounds for SMC error versus particle counts (1/N vs. $1/N$).
Formalizing guarantees for partial mass coverage or alternative utility metrics.
Extending the analysis to inference-time interventions beyond simple aggregation and pruning, such as splicing or cross-contextual summarization.
Conclusion
The paper provides a comprehensive theoretical and empirical analysis of particle filtering algorithms for inference-time steering of LLMs, with rigorous criteria for success and quantification of inherent computational barriers. It bridges prior ad hoc empirical findings with formal guarantees, enabling principled design and evaluation of parallel reasoning mechanisms and serving as a foundation for future progress in efficient, high-quality LLM inference.