3PoinTr: 3D Point Tracks for Robot Manipulation Pretraining from Casual Videos
Abstract: Data-efficient training of robust robot policies is the key to unlocking automation in a wide array of novel tasks. Current systems require large volumes of demonstrations to achieve robustness, which is impractical in many applications. Learning policies directly from human videos is a promising alternative that removes teleoperation costs, but it shifts the challenge toward overcoming the embodiment gap (differences in kinematics and strategies between robots and humans), often requiring restrictive and carefully choreographed human motions. We propose 3PoinTr, a method for pretraining robot policies from casual and unconstrained human videos, enabling learning from motions natural for humans. 3PoinTr uses a transformer architecture to predict 3D point tracks as an intermediate embodiment-agnostic representation. 3D point tracks encode goal specifications, scene geometry, and spatiotemporal relationships. We use a Perceiver IO architecture to extract a compact representation for sample-efficient behavior cloning, even when point tracks violate downstream embodiment-specific constraints. We conduct thorough evaluation on simulated and real-world tasks, and find that 3PoinTr achieves robust spatial generalization on diverse categories of manipulation tasks with only 20 action-labeled robot demonstrations. 3PoinTr outperforms the baselines, including behavior cloning methods, as well as prior methods for pretraining from human videos. We also provide evaluations of 3PoinTr's 3D point track predictions compared to an existing point track prediction baseline. We find that 3PoinTr produces more accurate and higher quality point tracks due to a lightweight yet expressive architecture built on a single transformer, in addition to a training formulation that preserves supervision of partially occluded points. Project page: https://adamhung60.github.io/3PoinTr/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to teach robots how to move and handle objects by learning from regular human videos (like the kind you can casually record on a phone). The method is called 3PoinTr. Instead of copying human hand motions exactly (which robots can’t always do), 3PoinTr focuses on understanding how objects in a scene move and then uses that knowledge to help the robot plan its own actions.
What questions does the paper try to answer?
The paper looks at three simple questions:
- Can we train robots with far fewer robot-specific examples by first learning from casual human videos?
- How can we avoid the “embodiment gap,” meaning the differences between how humans move and how robots move?
- Is there a general way to represent tasks that works across different scenes and objects, and helps robots plan their moves?
How does 3PoinTr work? (Explained in everyday terms)
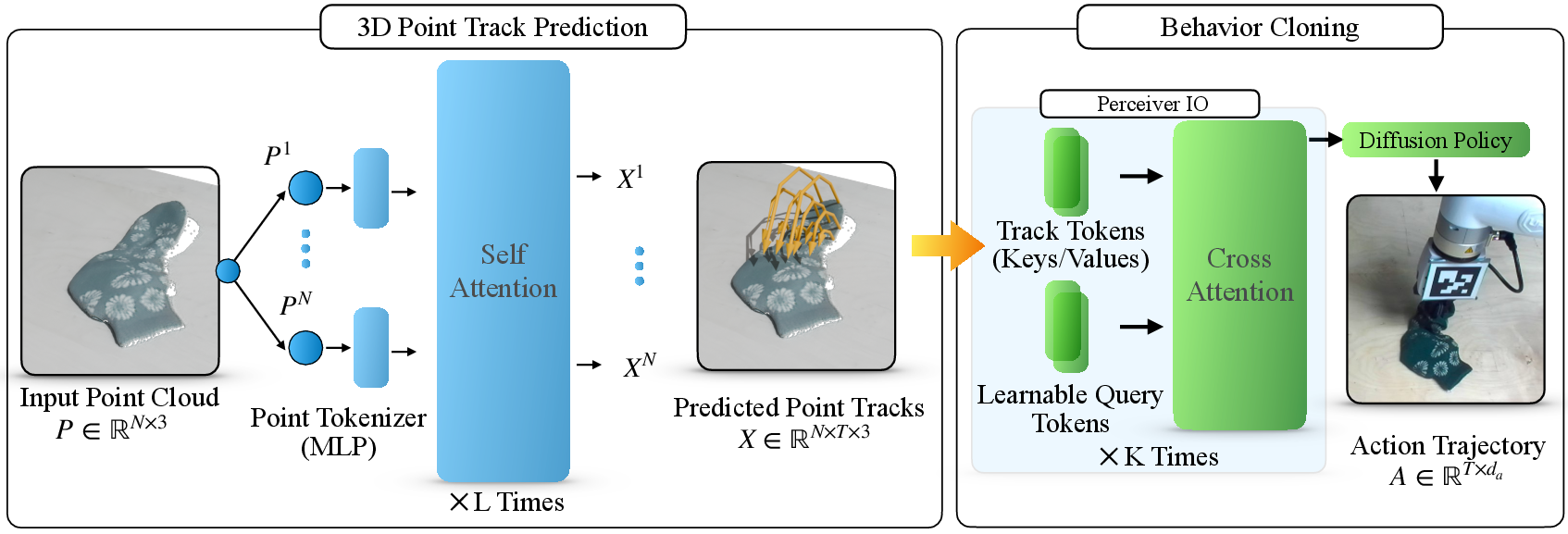
Think of a scene as a 3D cloud of points—like a spray of tiny dots floating in space, each dot marking part of an object or the background. When a person completes a task (like opening a drawer), many of those dots move over time. 3PoinTr tries to predict where each dot will go during the task. These paths are called “3D point tracks.”
Here’s the idea in two steps:
- Predict the “motion of the dots”:
- The system looks at a 3D snapshot of the scene (a point cloud) at the start.
- It uses a type of AI model called a transformer to predict how every dot will move over time. Imagine the transformer as a smart observer that pays attention to the most important parts of the scene and guesses their future positions.
- Turn those predicted movements into robot actions:
- The method compresses all those dot-movements into a compact summary using another model (Perceiver IO). Think of this as turning a long, detailed movie of moving dots into short, powerful “cliff notes” that capture the essence of the task: what should end up where, and how things relate in space and time.
- A policy model called a Diffusion Policy then uses this compact summary to plan a sequence of robot moves. This is called “open-loop”—the robot plans the whole move sequence in advance rather than constantly checking and correcting at every step.
Why is this helpful?
- It avoids forcing the robot to mimic a human’s exact arm or hand motion (which might be impossible or inefficient for the robot).
- It focuses on object motion and the task goal, which are the parts that really matter.
- It works even with casual, natural human videos (not carefully staged ones).
Simple explanations of the key terms
- Point cloud: a 3D picture made of lots of dots, each marking a point on objects or surfaces.
- 3D point tracks: the path each dot follows over time as the task happens.
- Transformer: an AI model that “pays attention” to important parts of data to make predictions.
- Perceiver IO: a way to turn big, complex data (like many point tracks) into a small, useful summary.
- Diffusion Policy: a planning method that gradually “refines” a rough plan into a good sequence of robot actions.
- Embodiment gap: the differences between how humans move (hands, joints) and how robots move (grippers, arms).
What did the researchers do to test 3PoinTr?
They tried it in both computer simulations and real-world tasks:
- Simulation tasks: stacking blocks, opening a microwave door, and righting a fallen glass.
- Real-world tasks: opening a drawer, righting a glass, throwing away paper in a trash bin, and folding a sock.
They trained the system using:
- Casual human videos to learn how objects move during tasks (predicting point tracks).
- Only a small number of robot demonstrations (as few as 20) to teach the robot how to turn those predicted point tracks into actual robot actions.
They compared 3PoinTr to other methods, including:
- Behavior cloning methods that learn directly from robot demos using images or point clouds.
- Methods that use 2D “flow” (object motion in flat images) from videos.
What did they find, and why does it matter?
Main results:
- 3PoinTr predicted object motion (3D point tracks) more accurately than a strong baseline (General Flow), especially on parts that move a lot and matter for the task.
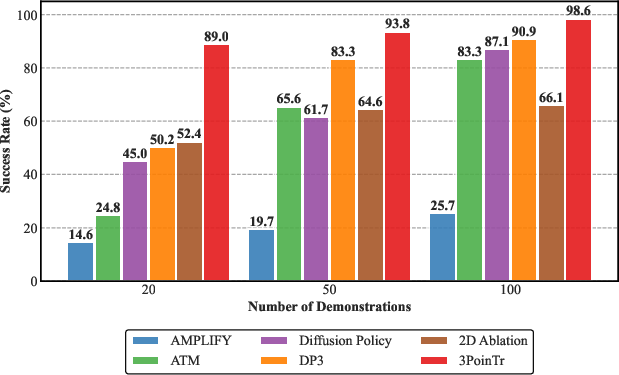
- With only 20 robot demonstrations, 3PoinTr’s policies succeeded more often than other methods in both simulation and real-life tasks.
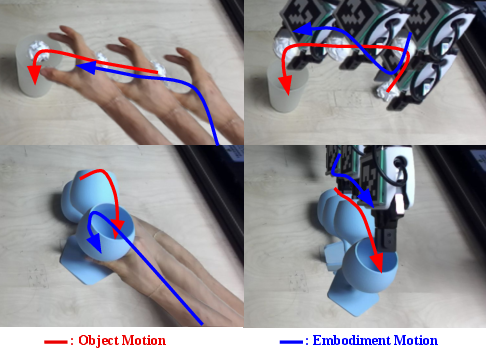
- It handled differences between human and robot motions well. For example, in the “right a glass” task, the human might grab it differently than the robot, but 3PoinTr still learned the key object motion and helped the robot plan its own, robot-friendly way to do the task.
Why this matters:
- Robots usually need lots of expensive robot-specific training data. 3PoinTr reduces that need by learning useful “priors” (general knowledge) from casual human videos first.
- Using a 3D representation (point tracks) captures the shape and motion of the world more clearly than 2D images, and maps more naturally to robot actions in 3D space.
- Focusing on object motion rather than human hand motion makes the method more flexible and robust across different robots and scenes.
What could this change in the future?
- Faster training: Teaching robots could become much quicker and cheaper, because you can start with readily available human videos and then fine-tune with a small number of robot examples.
- General-purpose skills: This approach could help robots learn a wide range of manipulation tasks, even with different objects and environments.
- Internet-scale learning: As tracking and 3D reconstruction get better, robots could learn from large collections of in-the-wild videos online, not just lab recordings.
The authors note some limitations and future directions:
- They trained one task at a time in consistent settings; future work could handle many tasks, views, and environments in a single generalist model.
- Open-loop planning is sample-efficient but doesn’t correct mistakes mid-task; later versions might combine this with closed-loop feedback.
- Tracking can be tricky for transparent or occluded objects; better tracking and depth estimation will help.
In short, 3PoinTr shows a promising way to use simple, everyday human videos to teach robots how to manipulate objects—by predicting how the scene itself should move—so robots can figure out their own best way to act.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that the paper leaves unresolved—intended to guide actionable future research.
- Multi-task scalability: The method is trained and evaluated one task at a time; how to condition and train a single generalist policy that handles multiple tasks and disambiguates goals across varied scenes, objects, and instructions.
- Goal specification: No mechanism to specify or switch goals (e.g., via language, goal images, or waypoints); future work needs explicit conditioning for goal/intent to enable multi-task and user-directed behavior.
- Viewpoint and environment diversity: Training/evaluation assume fixed, static camera(s) in a lab; robustness to varied camera intrinsics/extrinsics, moving cameras, egocentric views, different sensors, and diverse backgrounds remains untested.
- Internet-scale videos: Although motivated by casual/in-the-wild videos, experiments use controlled lab videos; feasibility with monocular, compressed, shaky, or edited internet content (without stereo depth and clean segmentation) is open.
- Monocular 3D lifting: Real-world 3D tracks rely on stereo depth (FoundationStereo); methods for reliable 3D track lifting from monocular videos (e.g., SfM, depth priors) and their impact on policy performance are not explored.
- Embodiment segmentation: The approach requires excluding embodiment points (robot/human hands), relying on SAM3; robustness to imperfect embodiment segmentation or multiple agents in unconstrained videos is unquantified.
- Occlusion robustness at inference: Training masks losses for occluded timesteps, but inference predicts long-horizon tracks from a single snapshot; systematic evaluation under severe, prolonged occlusions is missing.
- Uncertainty and multimodality: Point track prediction is deterministic and single-hypothesis; modeling multimodal futures, uncertainty estimates, and their use in robust planning or risk-aware control is unexplored.
- Physical plausibility: Losses are purely positional (L1) without enforcing kinematic constraints, contact dynamics, or collision avoidance; integrating physics priors or constraints to yield physically consistent tracks remains open.
- Variable horizon and timing: A fixed prediction horizon with normalized time is used; learning variable-length plans with termination criteria and adaptive temporal resolution (e.g., around contact events) is not addressed.
- Closed-loop control: The policy is open-loop to avoid covariate shift, but cannot correct errors or handle disturbances; designing closed-loop or receding-horizon variants that retain the benefits of track conditioning is an open problem.
- Online replanning: There is no mechanism to update track predictions or actions mid-execution; integrating fast re-planning with updated observations and uncertainty would improve robustness in dynamic settings.
- Multi-modal fusion: Policies ignore images, proprioception, force/tactile, and text; determining when and how to fuse these modalities with tracks for harder tasks (e.g., force-sensitive or long-horizon) is left open.
- Non-rigid and complex objects: While “Fold Sock” is included, broader evaluation on highly deformable, transparent, reflective, or articulated objects (and their tracking/3D-lifting failures) is limited.
- Clutter and multi-object interactions: The method’s scalability to cluttered scenes with many moving objects, distractors, and inter-object interactions (including unintended contacts) is not studied.
- Cross-embodiment generalization: Although “embodiment-agnostic” is claimed, experiments use a single robot (xArm 7); how well the learned representation transfers across different arms, grippers, and kinematics remains unknown.
- Safety and feasibility: The diffusion policy maps tracks to actions without explicit feasibility/safety constraints; integrating constraints (joint limits, collision avoidance, grasp stability) into action generation is an open direction.
- Sensitivity to calibration: Actions are expressed in the camera frame; the impact of camera-to-robot calibration errors and drift on performance is not analyzed.
- Equivariance and invariance: The model is not explicitly SE(3)-equivariant; exploring equivariant architectures for better generalization to pose changes and new camera placements is an open avenue.
- Learned query design: The Perceiver IO uses a small set (often one) of learned queries; there is no ablation on the number/type of queries, their interpretability, or how they partition task-relevant factors.
- Representation ablations: Limited analysis of alternatives to Perceiver IO (e.g., pooling, set transformers) and of track tokenization choices (dimensionality, trajectory encoders) to understand what matters most.
- Point density and sampling: Policies use 2048 subsampled points; sensitivity to point density, sampling strategy, and compute–performance trade-offs is not explored.
- End-to-end finetuning: The track predictor is frozen during policy learning; whether joint finetuning with a small number of demonstrations yields better alignment and sample efficiency is unknown.
- Data scaling laws: There is no systematic study of how pretraining dataset size/type affects policy performance, nor of mixing human and robot videos to assess transfer and potential negative transfer.
- Baseline fairness and ablations: Advantages due to open-loop vs closed-loop are confounded; evaluating closed-loop versions of 3PoinTr or open-loop versions of baselines would isolate representation effects.
- Real-time performance: Inference latency and computational footprint (track predictor + Perceiver IO + diffusion policy) are not reported; feasibility for time-critical manipulation is unclear.
- Robust failure analysis: The paper lacks detailed error attribution (track prediction error vs action mapping vs control execution) and diagnostic benchmarks to guide targeted improvements.
Practical Applications
Immediate Applications
The following applications can be deployed today with controlled setups, a static calibrated camera, and a modest number of robot demos (≈20) for each new task.
- Teach-by-showing for short-horizon service and home tasks
- Sectors: Robotics (consumer/service), Smart home, Elder care (non-clinical)
- Use case: A user records casual videos of tasks like opening drawers, disposing trash, righting a cup, or folding a sock; the robot pretrains on these videos and fine-tunes with ~20 teleoperated demos to execute reliably.
- Tools/products/workflows: “Video-to-Skill” mobile app for capture; 3PoinTr track predictor service; ROS/MoveIt node for flow-conditioned Diffusion Policy execution; on-robot skill library management.
- Assumptions/dependencies: Static eye-to-hand calibrated camera; reliable 2D point tracking and depth (e.g., CoTracker + stereo depth); safe, predictable environments; open-loop execution with safety interlocks.
- Rapid changeover for manufacturing and assembly of low-volume/high-mix SKUs
- Sectors: Manufacturing (SMEs and flexible cells), Industrial robotics
- Use case: Line operators record casual videos of new pick-place, opening/closing, and alignment tasks; robots are retrained with ~20 labeled demos instead of extensive reprogramming.
- Tools/products/workflows: On-prem 3PoinTr SDK integrated with MES; “Skill Studio” workstation to ingest floor videos, remove embodiment points, pretrain tracks, and compile robot skills; versioned skill deployments.
- Assumptions/dependencies: Repeatable fixturing or consistent camera pose; reliable grippers; safety gating for open-loop plans; IT policies for video data handling.
- Logistics and e-commerce exception handling
- Sectors: Warehousing, Fulfillment
- Use case: Training robots to right tipped containers, open bins or flaps, or re-orient irregular items using casual human videos from the floor, plus 20 demos for each site-specific variant.
- Tools/products/workflows: Exception “capture-and-train” workflow; asynchronous cloud pretraining of point tracks, on-site policy fine-tuning; monitoring dashboard for success rate and retrain triggers.
- Assumptions/dependencies: Adequate lighting for tracking; minimal occlusion during demonstrations; consistent camera placement over workcells.
- Facilities and hospitality operations
- Sectors: Facilities management, Hospitality/Retail service robots
- Use case: Robots are taught cabinet/door handle operations, waste disposal, and restocking motions via casual staff videos.
- Tools/products/workflows: Multi-task skill set per venue; templated articulation tasks (e.g., drawer, door) with parameterized 3D tracks; role-based deployment controls.
- Assumptions/dependencies: Task geometry within robot reach; compliance with site safety rules; standardized camera rigs for each station.
- Non-clinical hospital logistics and environmental services
- Sectors: Healthcare (facilities operations, not patient care)
- Use case: Opening supply cabinets, fetching non-critical items, disposing waste—taught from staff videos to reduce teleoperation burden.
- Tools/products/workflows: HIPAA-compliant on-prem training pipeline with automated face blurring; audit logs for video provenance; 3PoinTr pretraining from non-embodiment tracks.
- Assumptions/dependencies: Strict privacy/compliance controls on recorded videos; safe open-loop path execution; human oversight.
- Academic and R&D acceleration for manipulation research
- Sectors: Academia, Robotics R&D labs
- Use case: Replace large teleop datasets with 3D track pretraining from lab videos, achieving strong generalization with ~20 labeled demos per task; ablation studies on embodiment-agnostic representations.
- Tools/products/workflows: Open-source 3PoinTr training pipelines; benchmarks for 3D point-track ADE and policy success; course labs on video-to-policy learning.
- Assumptions/dependencies: Availability of stereo or RGB-D; baseline familiarity with ROS and Diffusion Policy-style training.
- Robotics software vendor SDKs and integrator offerings
- Sectors: Software, Robotics OEMs and integrators
- Use case: Ship a “video-to-policy” SDK that wraps 3PoinTr (track predictor + Perceiver IO compressor + flow-conditioned Diffusion Policy), with simple APIs for ingesting videos and exporting robot skills.
- Tools/products/workflows: Precompiled inference engines for embedded GPUs; ROS action servers; CI/CD for skill versioning; connectors to common arms (UR, FANUC, ABB, xArm).
- Assumptions/dependencies: GPU resources for training/inference; licensing for 2D tracking, depth, segmentation models; customer data governance.
- Operator-in-the-loop low-risk task authoring
- Sectors: Energy (non-critical), Construction (tools and fixtures), Utilities
- Use case: Technicians capture a valve-turning or latch-opening video to pretrain; fine-tune with a few demos; operator reviews and approves open-loop plans in a digital twin before execution.
- Tools/products/workflows: Review UI showing predicted 3D point tracks and planned end-effector trajectories; one-click deployment with geofenced safety zones.
- Assumptions/dependencies: Predictable task geometry; no high-consequence failure modes; human approval checkpoints.
- Organizational policy templates for video-driven robot training
- Sectors: Policy/Compliance across industries
- Use case: Draft internal SOPs for video capture (privacy, consent), data retention, safety validation of open-loop plans, and incident response for mis-executions.
- Tools/products/workflows: Checklists for anonymization; storage encryption policies; pre-deployment simulation sign-off.
- Assumptions/dependencies: Legal review; workforce training on approved capture practices.
Long-Term Applications
These applications require further research, scaling, or engineering, notably around in-the-wild video variability, closed-loop control, multi-view/moving cameras, broader generalization, and stronger safety assurances.
- Generalist manipulation from internet-scale casual videos
- Sectors: Robotics (foundation models), Software
- Use case: Pretrain 3D point-track priors on large in-the-wild video corpora to enable broad, zero-shot or few-shot manipulation across tasks, objects, and environments.
- Tools/products/workflows: “TrackFM” foundation model for 3D tracks; cross-embodiment adapters; skill retrieval conditioned by scene context.
- Dependencies/assumptions: Robust tracking under occlusion/reflectivity/low light; scalable multi-camera reconstruction; data curation and privacy compliance.
- Closed-loop flow-conditioned controllers with error recovery
- Sectors: Robotics (industrial, service)
- Use case: Combine 3PoinTr priors with online perception and control to handle disturbances, dynamic scenes, and recovery from partial failures.
- Tools/products/workflows: Hybrid open-loop plan + residual closed-loop policy; state observers that re-plan track-consistent subgoals; safety monitors.
- Dependencies/assumptions: Occlusion-robust online tracking; latency-bounded re-planning; reliable contact estimation.
- Multi-task, multi-view, and mobile manipulation in unstructured environments
- Sectors: Field robotics, Domestic robotics
- Use case: Train a single policy conditioned on 3D point-track priors that works across tasks, moving cameras, and different environments (kitchens, workshops, outdoors).
- Tools/products/workflows: Viewpoint-invariant track encoders; SLAM-integrated lifting of 2D tracks to 3D; domain-randomized pretraining.
- Dependencies/assumptions: Accurate extrinsics over time; robust depth from monocular/stereo under motion; large-scale varied datasets.
- Deformable and complex contact-rich manipulation at scale
- Sectors: Laundry automation, Food handling, Packaging
- Use case: Robust folding, bagging, wrapping, cloth/tool manipulation learned from casual videos, with policies that generalize across materials and shapes.
- Tools/products/workflows: Track representations augmented with physical priors for deformables; contact-phase-aware action chunking; tactile integration.
- Dependencies/assumptions: Better deformable tracking and modeling; high-frame-rate sensing; improved data augmentation for material variability.
- Cross-embodiment “skill stores” and inter-robot transfer
- Sectors: Robotics platforms and marketplaces
- Use case: Share embodiment-agnostic 3D track priors as portable task descriptors that adapt to diverse robot kinematics via small fine-tunes.
- Tools/products/workflows: Standardized “track spec” format; adapter libraries for different arms/grippers; validation suites for safety and performance.
- Dependencies/assumptions: Interoperability standards; certification processes; clear licensing for shared video-derived assets.
- Language + video conditioning for natural instruction
- Sectors: VLA systems, Human-robot interaction
- Use case: “Do this like in the clip” workflows that combine a short user video with a language instruction to select or compose skills.
- Tools/products/workflows: Multimodal encoders fusing text and 3D tracks; retrieval-augmented policy conditioning; on-device explanation/visualization tools.
- Dependencies/assumptions: Robust alignment between semantics (text) and geometry (tracks); user interfaces for disambiguation and safety.
- Regulated applications with high safety requirements
- Sectors: Healthcare (near-patient tasks), Energy (critical infrastructure), Aviation
- Use case: Robots perform semi-autonomous manipulation under strict safety envelopes, trained from compliant video datasets and certified pipelines.
- Tools/products/workflows: Formal safety cases; uncertainty-aware controllers; black-box recorders for post-incident analysis.
- Dependencies/assumptions: Regulatory frameworks for data provenance and model validation; redundancy and fault tolerance; extensive validation suites.
- Edge/onboard training and adaptation
- Sectors: Embedded AI, Mobile robots
- Use case: Onboard pretraining/fine-tuning from newly captured videos in the field for rapid adaptation without cloud connectivity.
- Tools/products/workflows: Quantized 3PoinTr and Diffusion Policy variants; streaming training on edge GPUs/NPUs; incremental model updates with rollback.
- Dependencies/assumptions: Efficient model architectures; thermal/power constraints; secure update mechanisms.
- Enterprise governance for video-derived robot skills
- Sectors: Policy/Compliance, Enterprise IT
- Use case: Company-wide governance over who can capture, train, approve, and deploy video-derived skills; audits of data lineage; privacy-respecting sharing.
- Tools/products/workflows: Data catalogs for video assets; PII detection/anonymization; model cards documenting training sources and limitations.
- Dependencies/assumptions: Cross-functional buy-in; integration with identity and access management; evolving legal standards.
These applications leverage the paper’s core innovations: embodiment-agnostic 3D point tracks learned from casual videos; a Perceiver IO compressor for compact task representations; and a flow-conditioned Diffusion Policy that achieves high success with as few as ~20 labeled robot demonstrations. Feasibility today is strongest for short-horizon, predictable tasks with static calibrated cameras and reliable tracking/depth; broader generalization, closed-loop robustness, and compliance for high-stakes use will benefit from continued research and engineering.
Glossary
- 1D U-Net: A one-dimensional U-shaped convolutional architecture used here as the backbone for sequence denoising in diffusion-based policies. "a 1D U-Net~\cite{ronneberger_u-net_2015} diffusion architecture"
- 3D Average Displacement Error (ADE): A metric that averages the Euclidean distance between predicted and ground-truth 3D point positions over time. "We report the 3D Average Displacement Error (ADE \cite{general_flow}) in millimeters for all points (total ADE), as well as the 5\% of points that moved the most (5\,\% ADE)."
- 3D point clouds: Sets of 3D points representing scene geometry, often used as inputs for perception and control. "Like 3D point clouds, 3D point tracks also align with the robot action space."
- 3D point tracks: Time-indexed 3D trajectories for points in a scene that capture object and scene motion. "3PoinTr uses a transformer architecture to predict 3D point tracks as an intermediate embodiment-agnostic representation."
- 6-D orientation representation: A continuous 6-dimensional vector parameterization of 3D rotations used to avoid discontinuities in angles. "6-D orientation representation~\cite{zhou_continuity_2020}"
- Affordance masks: Per-pixel or per-point masks indicating actionable regions (affordances) relevant to tasks. "affordance masks \cite{bahl_affordances_2023}"
- Behavior cloning: A supervised imitation learning approach that trains a policy to mimic expert demonstrations. "Behavior cloning is one type of imitation learning that employs supervised learning to train a policy which mimics expert demonstrations."
- Closed-loop control: A control paradigm where actions are updated using feedback from new observations at each step. "Future work might reintroduce closed-loop control"
- Conditional VAE: A variational autoencoder conditioned on inputs to model output distributions for tasks like flow prediction. "conditional VAE"
- Cross-attention: An attention mechanism where a set of query tokens attends to another set of tokens to extract relevant information. "Perceiver IO-style cross-attention module."
- Cross-embodiment retargeting: Mapping motions or trajectories from one embodiment (e.g., human) to another (e.g., robot). "cross-embodiment retargeting"
- Covariate shift: A distribution shift between training inputs and inputs encountered during policy rollouts, which can degrade performance. "covariate shift---distribution shift between training and rollouts---"
- Diffusion Policy: A policy class that generates actions by denoising from noise using diffusion models. "and use a Perceiver IO architecture and Diffusion Policy to enable state-of-the-art imitation learning."
- Embodiment gap: The mismatch in kinematics and strategies between humans and robots that complicates transfer from human videos. "overcoming the embodiment gap (differences in kinematics and strategies between robots and humans)"
- Embodiment points: Points belonging to the agent (e.g., robot) that are excluded to keep the representation independent of the specific embodiment. "excluding embodiment points."
- Embodiment-agnostic: Not tied to any specific body; transferable across humans and robots. "embodiment-agnostic 3D point track predictions."
- End-effector: The robot’s terminal tool (e.g., gripper) that interacts with objects. "end-effector position, end-effector orientation, and gripper value."
- Eye-to-hand calibration: Calibration procedure that determines a camera’s pose relative to the robot/workspace. "eye-to-hand calibration"
- Foundation models: Large pretrained models that serve as general-purpose backbones enabling capabilities like robust tracking. "computer vision foundation models~\cite{karaev_cotracker_2024}"
- Furthest point sampling: A sampling strategy that selects points to maximize spatial coverage by iteratively choosing the farthest point. "we use furthest point sampling to sample 20 initial configurations"
- Heuristic policy: A rule-based policy using hand-crafted assumptions instead of learned mappings. "but uses a heuristic policy that assumes a pre-defined object-grasping location."
- Imitation learning: Learning control policies from expert demonstrations rather than reinforcement signals. "Imitation learning aims to learn policies from expert demonstrations."
- L1 loss: A loss function based on absolute errors, used here for 3D position errors. "use an L1 loss on 3D position error"
- Learned query tokens: Trainable embeddings that attend to a large set of tokens to extract compact task representations. "A small set of learned query tokens attends to the full set of point track tokens"
- Model-based planning: Planning actions using an explicit model of dynamics rather than direct policy learning. "due to their reliance on model-based planning for robot execution"
- Multi-Layer Perceptron (MLP): A feed-forward neural network composed of fully connected layers and nonlinearities. "We compute the tokens by feeding the observed points into MLPs."
- Open-loop policy: A control strategy that outputs a full action sequence without using feedback during execution. "our open-loop policy formulation"
- Perceiver IO: A general architecture that uses latent arrays and flexible cross-attention queries to process large inputs and produce structured outputs. "We use a Perceiver IO architecture to extract a compact representation"
- Point flow: Dense per-point motion fields that describe how scene points move over time. "embodiment point flow predictions"
- PointNeXt: A point cloud processing architecture (successor to PointNet++) used as an encoder-decoder in some baselines. "PointNeXt~\cite{qian_pointnext_2022}"
- Retargeting: Transferring human motion trajectories (e.g., keypoints) to robot end-effectors. "retarget predicted human keypoint trajectories to robot end-effectors"
- Self-attention: An attention mechanism that relates elements within the same set to compute contextualized representations. "The transformer uses self-attention with queries , keys and value tokens "
- Sim-to-real gap: The performance gap arising from differences between simulated training and real-world deployment. "it remains 2D, and introduces a sim-to-real gap."
- Spatiotemporal relationships: Relationships that jointly capture spatial structure and temporal evolution. "spatiotemporal relationships."
- Stereo-to-depth model: A model that estimates depth from stereo image pairs. "stereo-to-depth model \cite{wen_foundationstereo_2025}"
- Teleoperation: Human remote control of a robot to collect demonstrations. "to teleoperate the same UFactory xArm 7"
- Transformer decoder: The decoder component of a transformer architecture that produces outputs (e.g., trajectories) conditioned on inputs. "pass through a transformer decoder"
- Unit-sphere normalization: Normalizing points so that they lie within a unit sphere to stabilize training. "per-sample unit-sphere normalization."
- Visibility masks: Binary indicators specifying whether points are visible at each timestep in a video/sequence. "per-frame visibility masks."
Collections
Sign up for free to add this paper to one or more collections.