- The paper presents the first live benchmark for temporal generalization, evaluating forecasting models on continuously evolving GitHub data.
- It employs a strict prequential evaluation protocol across multiple granularities, quantifying both point accuracy (MASE) and probabilistic calibration (scaled CRPS).
- Empirical analysis reveals that pretrained TSFMs yield superior yet dynamically shifting performance compared to classical statistical methods.
Impermanent: A Live Benchmark for Temporal Generalization in Time Series Forecasting
Motivation for Temporal Generalization Benchmarks
Recent developments in time-series forecasting have increasingly turned to large pretrained models—Time Series Foundation Models (TSFMs)—claiming broad cross-temporal and cross-domain generalization capabilities. Despite their outsized influence, most empirical testing relies on static evaluation protocols, typically using train-test splits of fixed datasets. This introduces several critical limitations: test set contamination via training on public benchmarks, performance inflation through test-driven model tuning, and a lack of introspection into models' behavior under realistic temporal shift, non-stationarity, and persistent evolution. Static protocols fail to capture the inherently dynamic environments for which TSFMs are purportedly designed.
"Impermanent" (2603.08707) directly addresses these deficiencies by introducing the first live, contamination-resistant benchmark for temporal generalization in forecasting. Rather than summarize model quality with a single static split, it continuously scores submitted models on rolling, real-evolving data streams, transforming temporal persistence and robustness from undefined aspirations into explicit, measurable phenomena.
Dataset Construction: GitHub Development Activity as a Live Benchmark
The benchmark is instantiated using open-source activity from the top 400 GitHub repositories (by star count), leveraging GH Archive event streams. Each repository-event pair (issues opened, pull requests opened, push events, new stargazers) forms a univariate time series, evaluated at four granularities: hourly, daily, weekly, and monthly. This corpus provides a setting that is both naturally dynamic and highly non-stationary—a sharp contrast to synthetic or well-behaved archives.
The underlying data stream exhibits clear manifestations of real-world complexity: burstiness with isolated spikes, intermittent zero-activity spans, abrupt level regime changes, and scale heterogeneity across both repositories and event types.
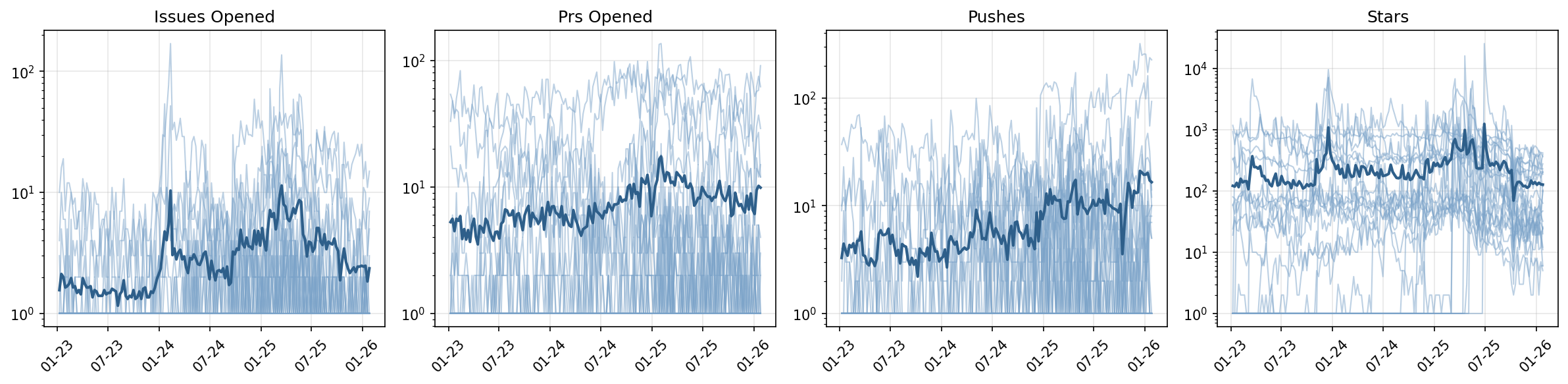
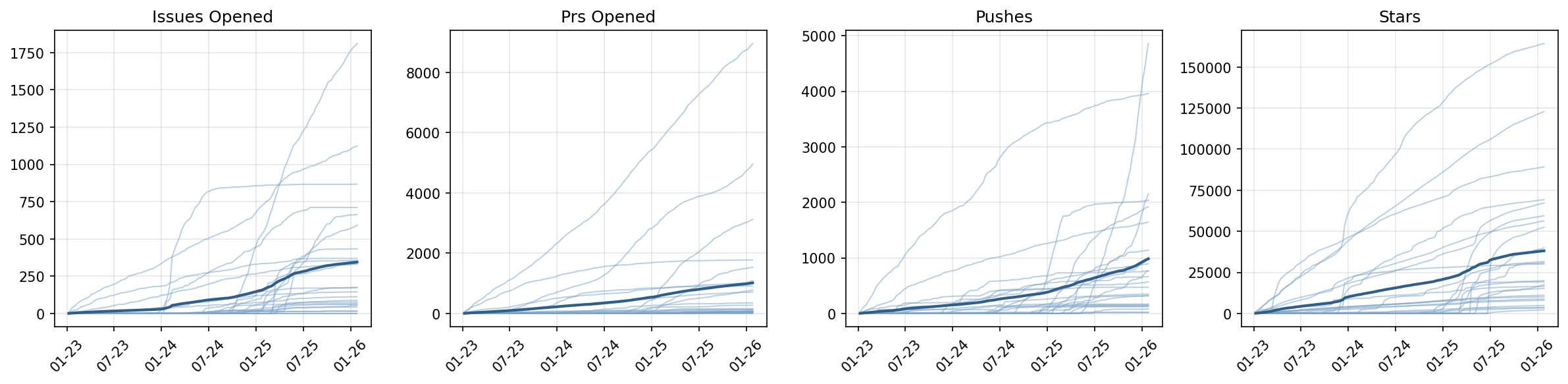
Figure 1: Weekly GitHub activity for 25 sample repositories, showing diverse event patterns and accumulation profiles indicative of non-stationary, bursty dynamics.
Exploratory statistics—using descriptors such as spectral centroid and entropy—further illustrate the spectrum of temporal behaviors encountered, from slowly varying series with periodic trends to erratic, broadband signals.
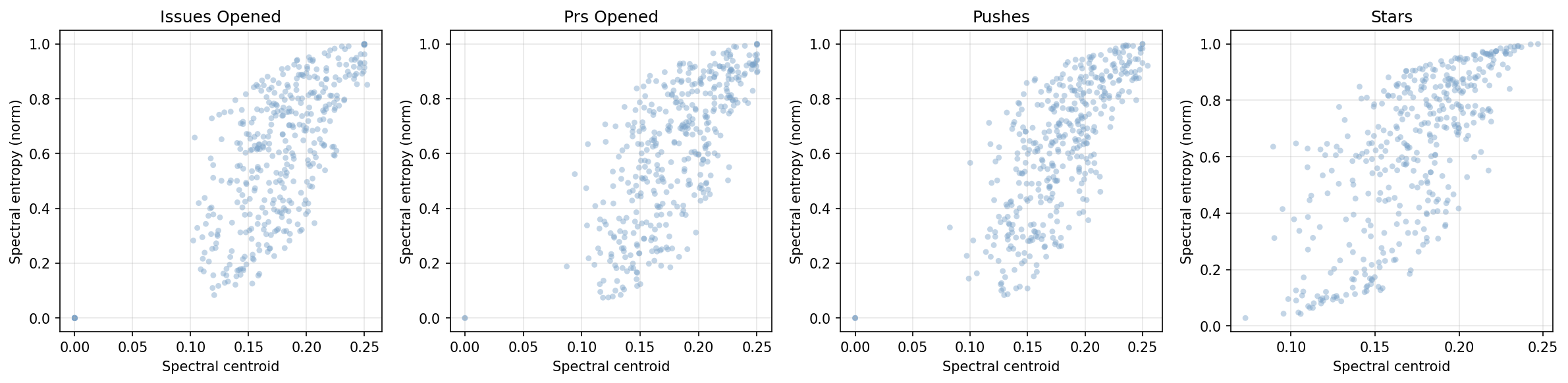
Figure 2: Distribution of temporal descriptors across event types, capturing variations in typical frequency, irregularity, and spectral spread.
At a coarser temporal resolution, the scale and diversity of event regimes become even more pronounced.
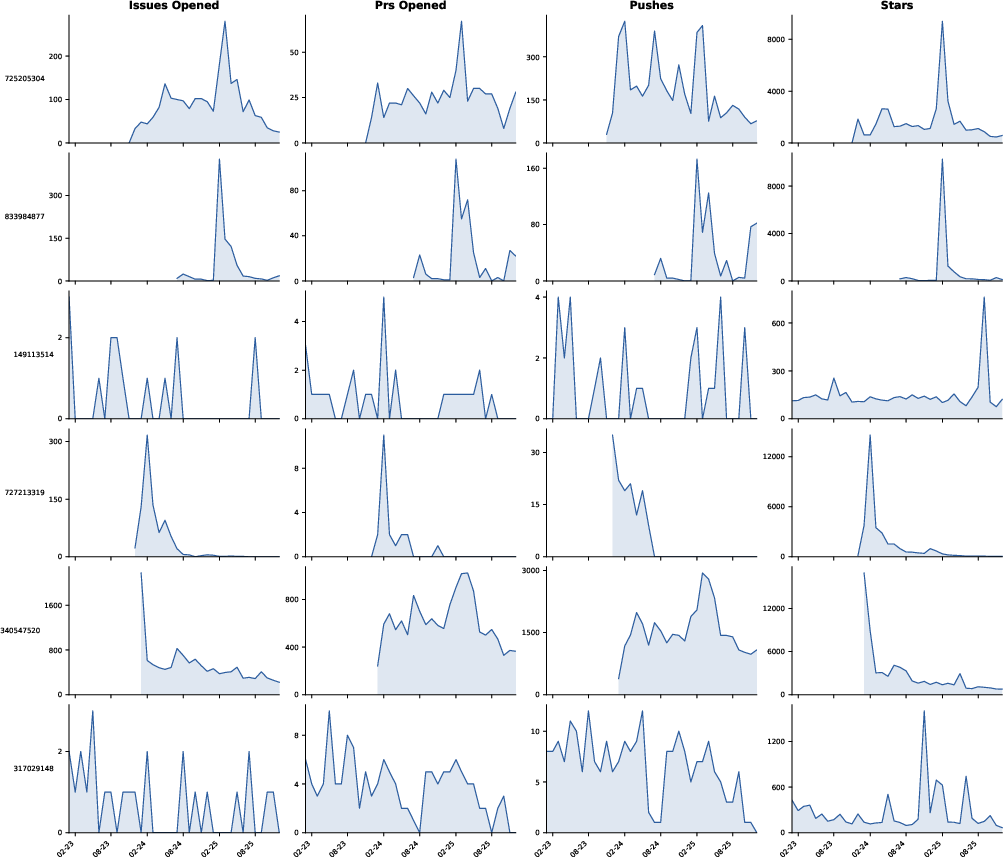
Figure 3: Monthly event counts for six repositories, highlighting intermittency, spikes, regime shifts, and cross-series heterogeneity.
Evaluation Protocol and Leaderboard Infrastructure
Forecasting models are evaluated in a streaming protocol. At each cutoff time, a model receives a trailing context window of historical values and must produce point and probabilistic forecasts for the next h periods. Unlike traditional backtesting, all predictions are made strictly sequentially: ground-truth values for the forecast window are not accessible to the model, and scoring is delayed until observations are available, eliminating test-set leakage.
Key dimensions of the protocol include:
- Strict prequential evaluation: Models are not permitted retrospective access to future or overlapping past test labels, countering both contamination and overfitting.
- Multiple granularities: Hourly, daily, weekly, and monthly series support analysis across recurring seasonalities and regime durations.
- Robust metric reporting: Both point-wise (MASE) and probabilistic (scaled CRPS) error metrics are computed and normalized against a naive zero baseline for interpretability and stability.
- Fully automated, reproducible infrastructure: The pipeline leverages cloud infrastructure (Modal, S3) for regular ingestion, aggregation, and archiving, enabling transparent reproducibility and extensibility.
Twelve models spanning naive baselines, classical statistical methods (AutoARIMA, AutoETS, Prophet, CES, DynOptTheta), and open-source TSFMs (Chronos-2, TiRex, TimesFM, Moirai) are routinely benchmarked. All foundation model submissions are required to publish weights and inference code, mitigating reproducibility concerns prevalent in LLM evaluation.
Empirical Results and Analysis
Initial results spanning cutoff windows up to February 2026 reveal important phenomena:
- Pretrained foundation models consistently claim the top ranks in both point and probabilistic accuracy, with TimesFM yielding the lowest median MASE and CRPS values across the diverse stream, and TiRex, Moirai, and Chronos-2 following closely.
- Classical seasonal-naive and statistical methods (e.g., SeasonalNaive, DynOptTheta, AutoETS) display competitive MASE rankings under certain event types but are sharply outperformed in terms of probabilistic calibration under shift and burst regimes.
- Model rankings are observed to be dynamic, shifting as new data accumulates. Thus, "early leaderboard superiority" does not guarantee persistent dominance—underscoring the limits of static-benchmark-driven claims about TSFMs' real-world utility.
A notable empirical finding is that, although TSFMs achieve the best overall rankings, the separation from optimized classical methods is moderate for certain subpopulations, and variance in model orderings across organizational boundaries (event type, repository activity) is substantial.
Practical, Theoretical, and Prospective Implications
By bridging the gap between static benchmarks and the operational deployment setting, Impermanent exposes key questions in TSFM development:
- Generalization under temporal drift: Foundation models must do more than memorize or interpolate across a static snapshot. Persistent accuracy and calibration through regime shifts is now testable, and vulnerability to shift is quantifiable.
- Test-leakage resistance: By construction, benchmarks of this form provide definitive immunity to data leakage and retroactive optimization, a critical requirement as models scale and training provenance becomes opaque.
- Stability of model superiority: As model rankings are tracked over time, the degree to which static-benchmarked models maintain their advantage in deployment can be empirically mapped.
Impermanent is architected for extensibility. Immediate next steps include:
- Expansion to other live domains with rich time series structure (finance, IoT, retail).
- Augmentation with context-aided forecasting protocols incorporating exogenous events and textual information.
- Extension of evaluation to encompass adaptation protocols, intervention response, and long-horizon performance stability.
Conclusion
Impermanent constitutes a foundational shift in the benchmarking of time series forecasting models by providing a live, sequential, open-world evaluation setting that robustly tests temporal generalization, robustness to drift, and performance persistence. The continuous leaderboard, built on real, non-stationary data, makes claims of foundation-model generality falsifiable and opens avenues for deeper theoretical work on shift-resilient temporal representation learning. Its modular framework lays the groundwork for future research on dynamic forecasting, context-aware models, and deployment-faithful validation methodologies (2603.08707).