A Survey of Reinforcement Learning For Economics
Abstract: This survey (re)introduces reinforcement learning methods to economists. The curse of dimensionality limits how far exact dynamic programming can be effectively applied, forcing us to rely on suitably "small" problems or our ability to convert "big" problems into smaller ones. While this reduction has been sufficient for many classical applications, a growing class of economic models resists such reduction. Reinforcement learning algorithms offer a natural, sample-based extension of dynamic programming, extending tractability to problems with high-dimensional states, continuous actions, and strategic interactions. I review the theory connecting classical planning to modern learning algorithms and demonstrate their mechanics through simulated examples in pricing, inventory control, strategic games, and preference elicitation. I also examine the practical vulnerabilities of these algorithms, noting their brittleness, sample inefficiency, sensitivity to hyperparameters, and the absence of global convergence guarantees outside of tabular settings. The successes of reinforcement learning remain strictly bounded by these constraints, as well as a reliance on accurate simulators. When guided by economic structure, reinforcement learning provides a remarkably flexible framework. It stands as an imperfect, but promising, addition to the computational economist's toolkit. A companion survey (Rust and Rawat, 2026b) covers the inverse problem of inferring preferences from observed behavior.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is a friendly guide for economists about reinforcement learning (RL) — a way for computers to learn good decisions by trying things out and learning from the results. It explains how RL connects to classic tools economists already use (like dynamic programming), shows where RL helps when problems get too big for old methods, and gives simple examples from economics (like pricing and inventory). It also honestly discusses RL’s weaknesses, so readers know when it’s useful and when it isn’t.
What questions is the paper trying to answer?
- How is RL related to dynamic programming, and how do they both solve the same kind of “what should I do next?” problems?
- What are the main RL algorithms (like Q-learning, policy gradients, and actor–critic), and how do they work in simple terms?
- Where can RL help in economics (pricing, inventory, strategic games, learning preferences, bandits), especially when problems have many variables or uncertainty?
- What are the limits and risks of RL (like needing lots of data, being sensitive to settings, and not always converging to the best answer)?
- How can economists combine economic structure (e.g., incentives, constraints) with RL to get better, safer results?
How does the paper approach this?
The paper is a survey, which means it organizes and explains key ideas rather than presenting one new experiment. It does four main things:
- Links classic planning to learning: It shows that dynamic programming and RL both try to solve the Bellman equation (a recipe for “best future value”), but they do it differently. Dynamic programming needs a full model of the world and updates everything at once; RL learns from sampled experiences and updates gradually.
- Walks through core RL methods using everyday language:
- Monte Carlo: Like taking lots of full journeys and averaging the total scores to judge how good a state is.
- Temporal Difference (TD) learning: Like learning from one step at a time using “prediction errors” (what you got vs. what you expected).
- Q-learning: Gives each action a “grade” in each situation (state) by asking, “what’s the best I could get next?”
- Policy gradients: Instead of learning state/action values first, directly adjust the strategy to make good actions more likely (helpful for continuous choices).
- Actor–critic: A “player” (actor) chooses actions while a “coach” (critic) estimates how good things are and gives feedback.
- Explains modern deep RL: Methods like DQN (good for big state spaces like images), PPO/TRPO (keep policy updates stable by limiting step size), and SAC (rewards exploration by adding entropy).
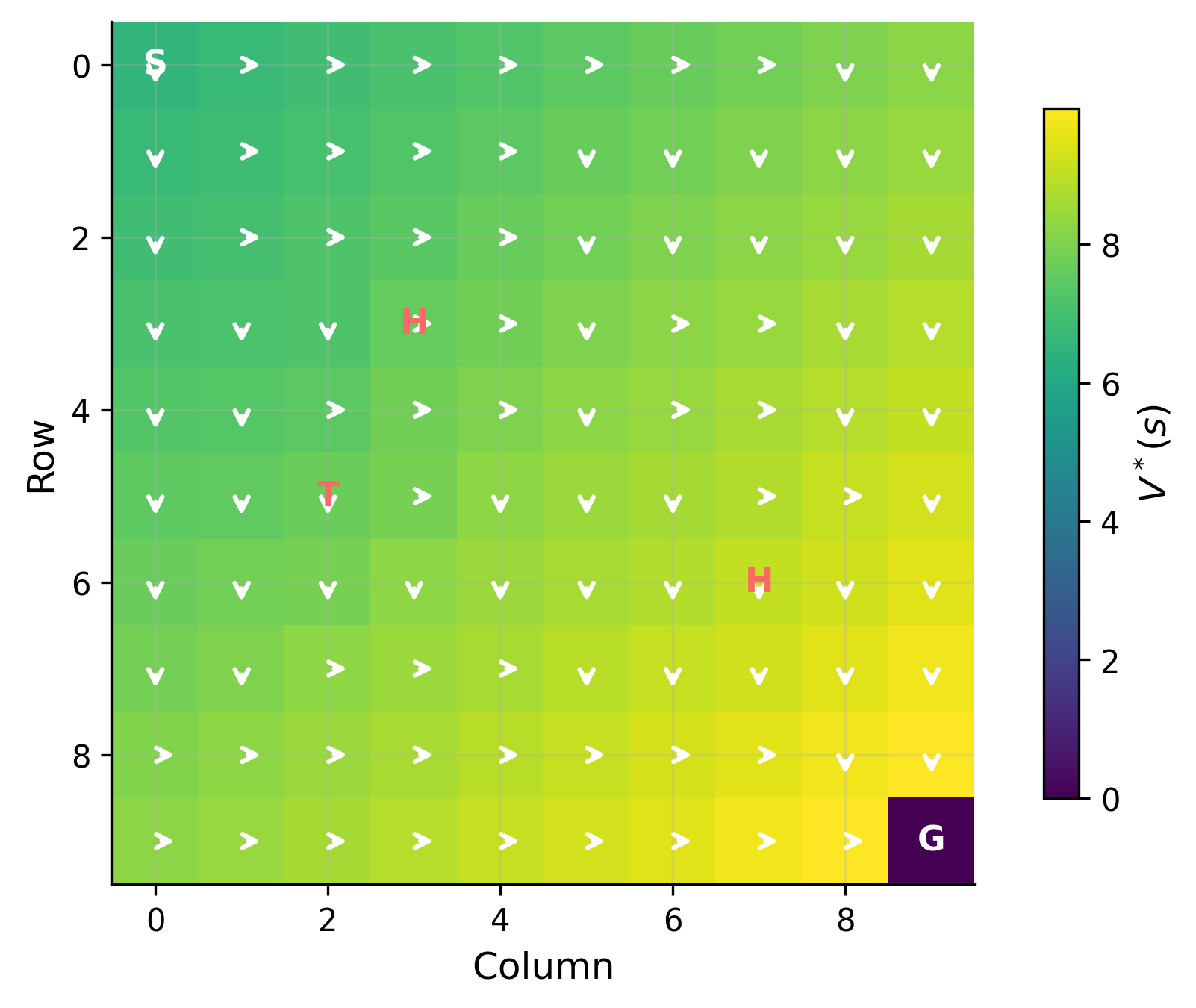
- Uses simple simulated examples: Pricing, inventory control, games between firms, learning people’s preferences, and bandit problems (trial-and-error with limited information).
To make ideas concrete, it adopts standard terms:
- “State” = what’s going on now; “Action” = the choice you make; “Reward” = the score you get; “Policy” = your rule for choosing actions; “Value” = how much future reward you expect from a state or from taking an action in a state.
What did the paper find, and why does it matter?
Because it’s a survey, the “findings” are big-picture takeaways:
- RL scales where classic methods struggle: When problems have many variables (high-dimensional states), continuous choices (like picking any price), or multiple learners interacting (strategic games), RL’s “learn from samples” approach can be more practical than exact dynamic programming.
- Same goal, different tools: Dynamic programming and RL both try to optimize long-run rewards. Dynamic programming is fast to converge and exact when you know the full model. RL can work when you don’t know the model but can collect data or build a simulator.
- Core algorithms each fit different needs:
- TD methods learn fast from incremental feedback.
- Q-learning finds good actions without needing to know how the world works inside.
- Policy gradients shine when actions are continuous, like adjusting a price or a robot’s torque.
- Actor–critic blends low-variance learning (critic) with flexible decision rules (actor).
- Deep RL tools (DQN, PPO, SAC) bring these ideas to very large problems.
- Clear limits and risks:
- Sample hungry: RL often needs lots of data or a realistic simulator.
- Brittle: Results can depend heavily on hyperparameters and random seeds.
- No universal guarantees: Outside small/tabular cases, there’s no promise it will find the best policy; in some settings it can even diverge.
- Off-policy + bootstrapping + function approximation can be unstable (the “deadly triad”).
- Guided by economics, RL works better: Using known economic structure (like demand curves, constraints, or equilibrium ideas) can make RL more efficient, more stable, and more interpretable.
How does RL show up in economics? (Simple examples)
- Dynamic pricing: An RL agent adjusts prices over time to learn demand and maximize profits without needing a perfect demand model.
- Inventory control: Decide how much to order and when, balancing stockouts vs. holding costs in uncertain demand.
- Strategic games: Competing firms (multiple agents) learn strategies when information is imperfect or markets change.
- Bandits: Test different choices (ads, promotions) while limiting regret (lost gains) — economic structure can sharpen these strategies.
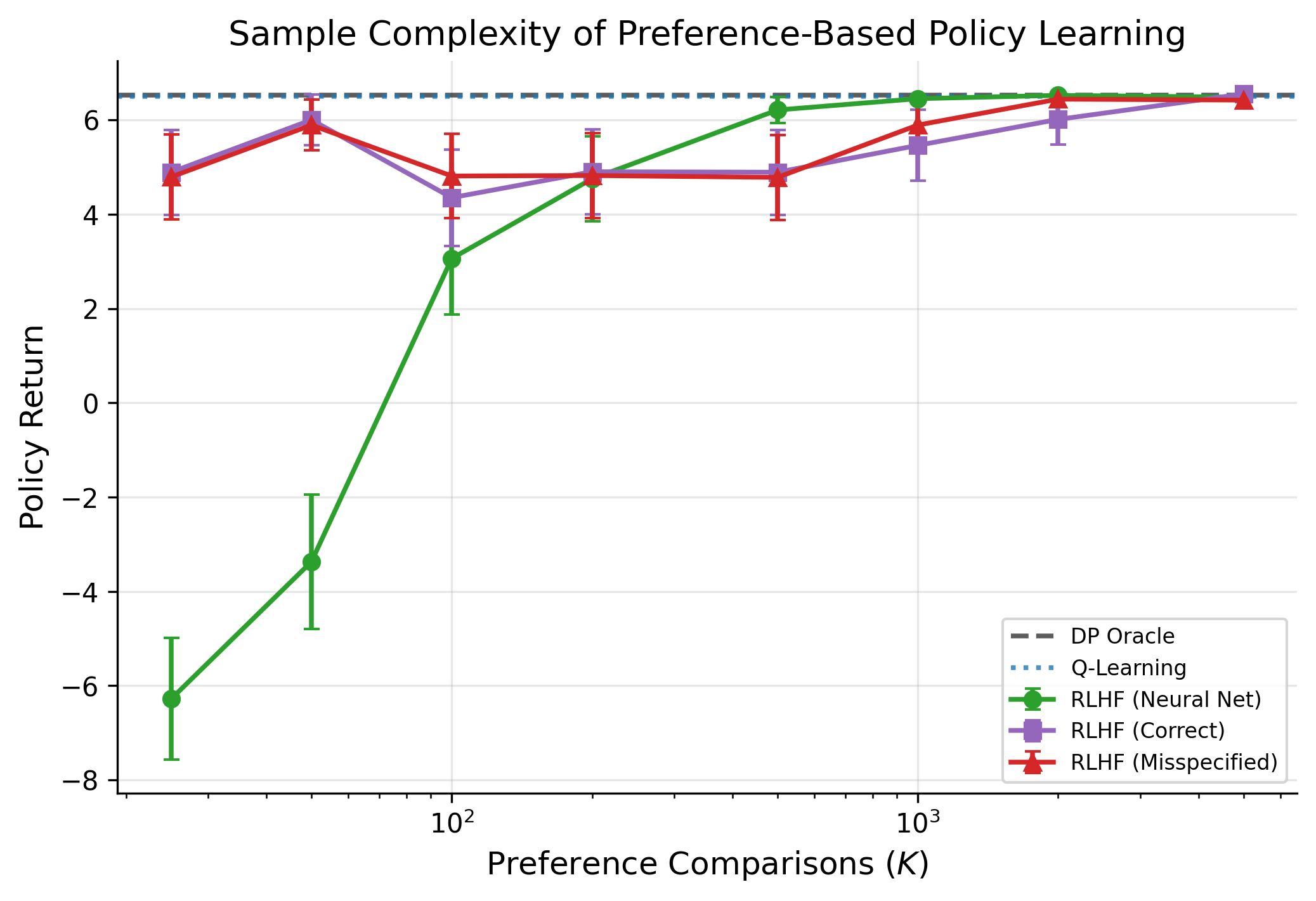
- Preference learning: Inverse RL and RL from human feedback (RLHF) can help infer what customers or users value from their choices.
Why does this matter for the future?
- A bigger toolbox for economists: RL won’t replace classic methods, but it extends them to harder, messier problems.
- Better decision-making under uncertainty: When building a full model is too hard, RL can learn good policies from data or simulation.
- Caution is crucial: Because RL can be brittle or sample-inefficient, combining it with economic theory, good experimental design, and causal thinking is key.
- Real-world impact: With the right guardrails, RL can improve pricing, supply chains, market strategy, and policy design — especially in complex, data-rich environments.
Bottom line
Reinforcement learning is an imperfect but promising addition to the computational economist’s toolkit. It’s powerful when problems are large and complicated, especially if you can simulate them. It works best when guided by economic structure and used with care about stability, data needs, and evaluation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unanswered questions that emerge from the survey’s scope, claims, and caveats; each item is phrased to be directly actionable for future research.
- Convergence with function approximation beyond tabular settings
- Establish sufficient and (ideally) necessary conditions for stability and convergence of value-based, policy-gradient, and actor–critic methods with nonlinear function approximation (deep networks), especially under off-policy data and bootstrapping (i.e., resolving the “deadly triad” in practical regimes).
- Provide theory explaining why heuristics such as target networks, experience replay, double critics, and entropy regularization stabilize learning, and identify when they fail.
- Sample efficiency under economic data constraints
- Design RL algorithms that provably exploit economic structure (e.g., concavity/convexity, monotone comparative statics, separability, homotheticity) to reduce sample complexity.
- Derive regret or PAC bounds tailored to dynamic pricing, inventory control, auctions, and IO models where data are scarce and costly.
- Hyperparameter sensitivity and brittle performance
- Develop principled, provably robust tuning and adaptation schemes (e.g., step-size, exploration temperature, clipping ranges) that maintain performance across tasks without extensive hand-tuning.
- Formalize stability criteria that an algorithm can self-monitor to prevent silent convergence to suboptimal policies.
- Reliance on accurate simulators and model misspecification
- Construct methods that learn and validate simulators from limited observational data, quantify model uncertainty, and propagate it into policy optimization.
- Develop sim-to-real transfer guarantees for economic environments subject to nonstationary demand, strategic behavior, and policy changes.
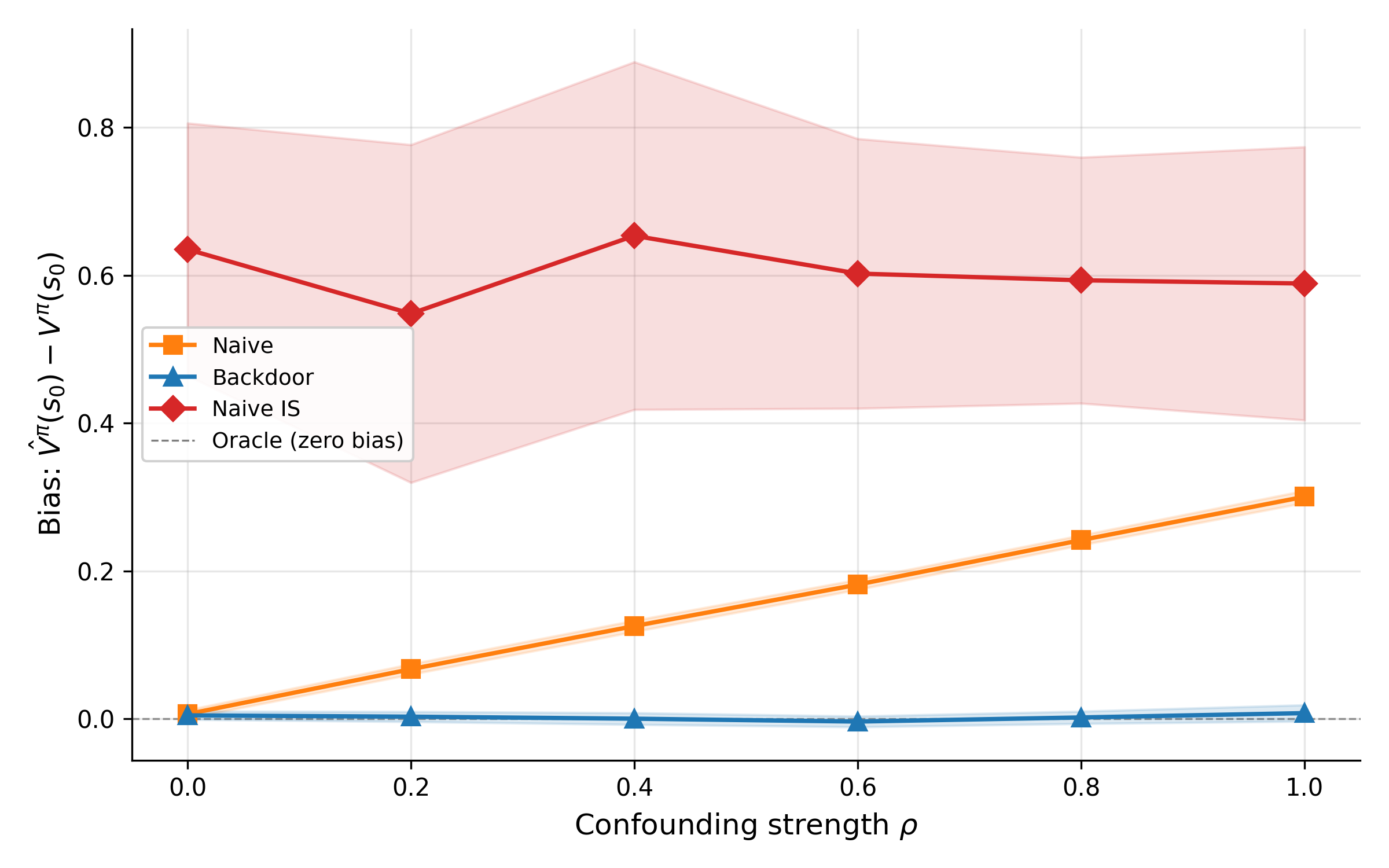
- Offline RL and off-policy evaluation in economics
- Provide identification conditions and practical estimators (doubly robust, marginalized IS, fitted Q–evaluation) for long-horizon, confounded, partially observed economic datasets.
- Characterize worst-case bias from violations of sequential ignorability/positivity and propose diagnostics and sensitivity analyses suitable for observational market data.
- Safe exploration under welfare, legal, and operational constraints
- Create exploration strategies that respect safety, fairness, and regulatory constraints (e.g., price collusion risks, consumer protection), with guarantees on constraint satisfaction during learning.
- Study budgeted and risk-aware exploration (CVaR, chance constraints) for applications where errors are costly or irreversible.
- Multi-agent learning and equilibrium selection
- Develop algorithms with provable convergence to economically relevant equilibria (Nash, correlated, Bayes–Nash) in general-sum, continuous-action, and incomplete-information games.
- Characterize equilibrium selection, stability, and sample complexity of multi-agent RL dynamics when agents learn concurrently and strategically.
- Integrating economic constraints and incentive compatibility
- Incorporate budget, capacity, and market-clearing constraints directly into RL updates (e.g., primal–dual or Lagrangian actor–critic) with theoretical guarantees.
- Combine RL with mechanism design to enforce incentive compatibility and participation constraints during learning.
- Interpretability and mapping to economic primitives
- Develop methods to extract elasticities, marginal values, and policy rules from learned policies, and to impose economically motivated shape constraints (monotonicity, concavity) during training.
- Provide post-hoc explanations that connect policy behavior to standard economic intuition and comparative statics.
- Uncertainty quantification and statistical inference
- Construct confidence intervals and valid hypothesis tests for value estimates and policy improvements under function approximation and dependence (e.g., replay buffers).
- Explore Bayesian and distributionally robust RL for decision-making under model and estimation uncertainty, with finite-sample guarantees.
- Partial observability and hidden state in economic environments
- Establish identification and learning guarantees for POMDPs common in economics (e.g., hidden demand shocks, private types), including sample complexity and state-inference error bounds.
- Design practical belief-state representations that balance tractability, data efficiency, and robustness.
- Continuous action spaces and constrained control
- Provide theory for policy-gradient and actor–critic methods in high-dimensional continuous actions under convex/concave rewards and constraints, including convergence rates and regret bounds.
- Study the impact of action discretization on bias–variance trade-offs and performance guarantees.
- Entropy-regularized control and discrete-choice connections
- Calibrate and interpret the entropy temperature τ in Soft Actor–Critic through the lens of random utility models; extend to nested or mixed logit analogues and study welfare implications.
- Derive identification and estimation procedures when entropy regularization is viewed as a structural taste-shock model.
- Benchmarking and reproducibility for economic RL
- Build standardized, open economic RL benchmarks (pricing, inventory, entry/exit, auctions, dynamic oligopoly, search/matching) with canonical parameterizations and evaluation protocols.
- Establish reproducibility standards, ablation suites, and cross-method comparisons that reflect realistic data, constraints, and nonstationarity.
- Nonstationarity and policy-induced distribution shift
- Develop algorithms that adapt to structural breaks and endogeneity introduced by the agent’s own actions (policy-induced demand shifts, strategic reactions), with detection and adaptation guarantees.
- Analyze performance under covariate shift and concept drift typical in evolving markets and regulatory contexts.
- Joint estimation and control (structural–RL integration)
- Formulate bilevel methods that jointly estimate primitives (preferences, costs, dynamics) and optimize policies, with identification and convergence guarantees.
- Quantify the value of structure: when does adding parametric economic constraints improve vs harm performance under misspecification?
- Human feedback and strategic annotators
- Adapt RL from human feedback to settings with strategic or noisy raters (consumers, regulators, market participants), including incentive-compatible feedback collection and robustness to manipulation.
- Provide sample complexity and bias analyses for preference-learning pipelines in economic decision tasks.
- Real-world validation and field deployment
- Move beyond simulated examples to field experiments or quasi-experimental evidence demonstrating welfare, revenue, and robustness gains from RL in deployed economic systems.
- Document deployment risks, governance protocols, and audit tools to monitor unintended consequences (e.g., tacit collusion, disparate impact).
- Theoretical alignment with average-reward criteria
- Extend the planning–learning synthesis to average-reward formulations prevalent in operations and IO, including convergence rates, bias corrections, and reliable differential value estimation.
- Theory for deep RL heuristics used in practice
- Provide formal analyses of widely used techniques (target networks, prioritized replay, clipping, entropy schedules, double critics) to close the gap between empirically successful recipes and theoretical understanding.
Practical Applications
Immediate Applications
The survey positions reinforcement learning (RL) as a sample-based extension of dynamic programming (DP) for high-dimensional, continuous-action, and strategic settings, while emphasizing brittleness and a reliance on simulators. The following are deployable now with appropriate guardrails.
- Dynamic retail and e-commerce pricing — sectors: retail, e-commerce
- What: Adjust prices/promotions in response to demand, inventory, and competitive signals under constraints.
- How (methods from paper): Tabular/Q-learning or SARSA for discrete price grids; actor-critic, PPO, or SAC for continuous prices; contextual bandits for promotional A/B tests.
- Tools/products/workflows: Offline policy evaluation (OPE) on logged data; constrained RL layers to enforce price bounds/fairness; simulator-backed “shadow mode” testing; continuous hyperparameter monitoring.
- Assumptions/dependencies: Accurate demand simulators or rich logged data; safe exploration is limited—GLIE-style exploration schedules and trust-region methods (TRPO/PPO) mitigate instability; guardrails to avoid emergent collusion or unfair pricing.
- Inventory control and joint pricing–inventory policies — sectors: supply chain, operations research
- What: Learn replenishment and pricing policies with stochastic demand, lead times, and perishability.
- How: TD, Q-learning, or actor-critic to approximate value functions when DP is intractable; SAC for continuous order quantities.
- Tools/products/workflows: Digital twins for warehouses; “what-if” simulators to evaluate policies; entropy-regularized policies (SAC) for robust exploration; rollouts to stress test rare events.
- Assumptions/dependencies: Simulator fidelity on lead times and demand shocks; cost shaping to reflect stockouts/backorders; safety constraints (e.g., minimum service levels).
- Online experimentation and allocation — sectors: ad tech, marketplaces, product analytics
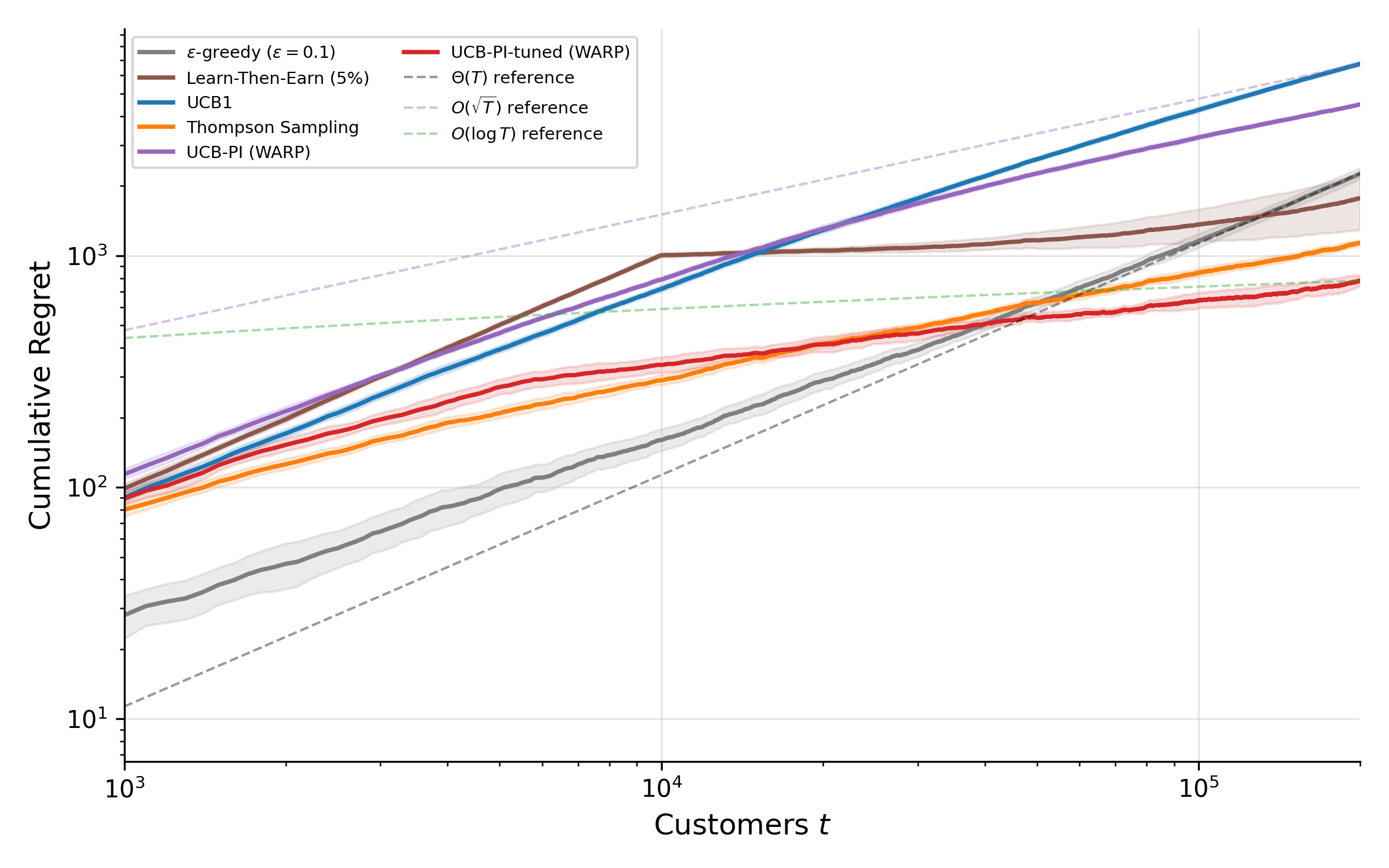
- What: Adaptive A/B testing, ad allocation, and content ranking that trade off exploration and exploitation.
- How: Bandits with economic structure (priors/elasticities) for tighter regret; Thompson sampling and UCB; contextual bandits as a special RL case without long-horizon credit assignment.
- Tools/products/workflows: Experiment platforms with bandit backends; off-policy estimators (importance sampling, doubly robust) to evaluate new policies from logs.
- Assumptions/dependencies: Near-stationary reward distributions; correct propensity logging; safeguards for fairness and exposure caps.
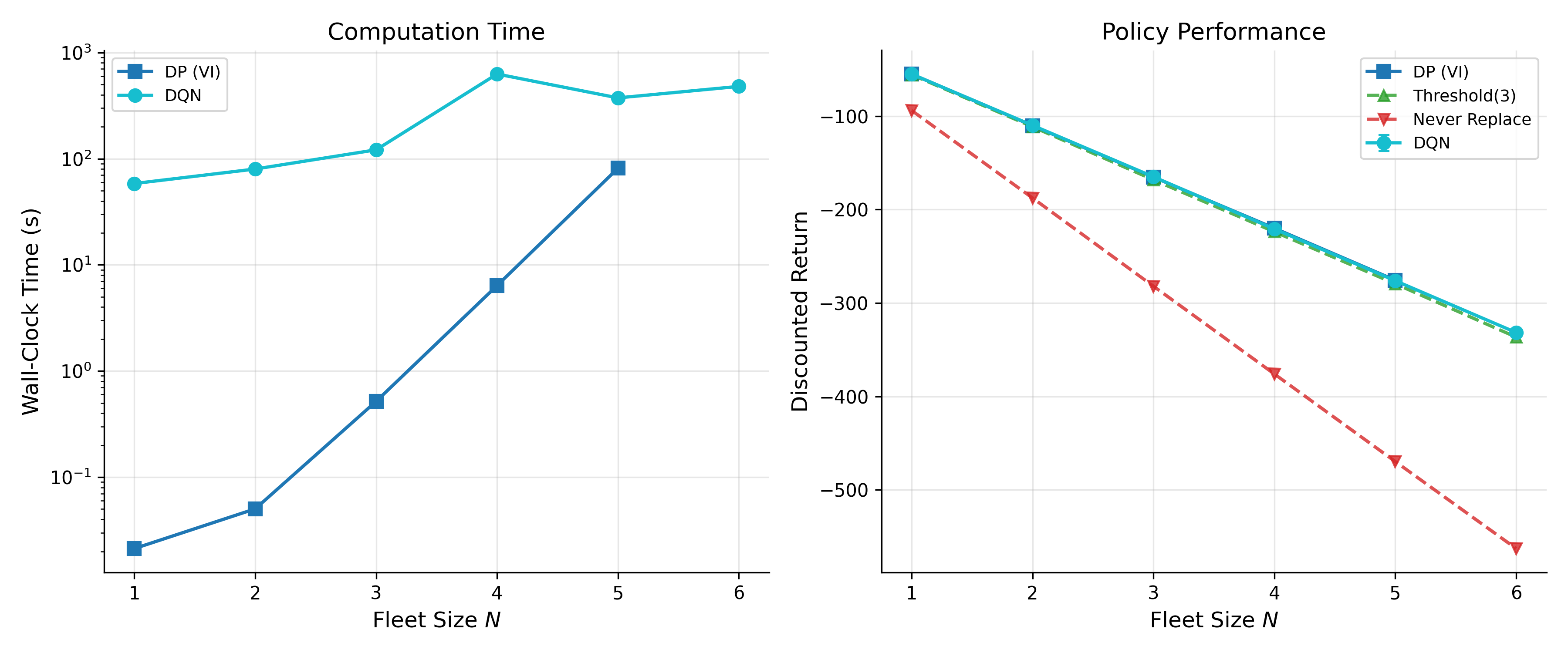
- Fleet/taxi/driver dispatch in zonal networks — sectors: mobility, logistics
- What: Dispatch vehicles across zones to balance supply and demand, similar to Howard’s classical examples.
- How: On-policy algorithms (SARSA, actor-critic) to account for exploration costs; trust-region updates (PPO/TRPO) to stabilize policy improvement.
- Tools/products/workflows: City-level simulators; KPI dashboards for wait time and utilization; staged deployment with geofenced pilots.
- Assumptions/dependencies: High-quality demand forecasts; safety constraints to prevent service deserts; non-stationarity handled via continual learning.
- Multi-agent simulations for strategy testing — sectors: marketplaces, platforms, industrial organization (academia/industry labs)
- What: Use self-play and multi-agent RL to explore strategic interactions (e.g., bidding, matching, platform fee policies) in silico.
- How: Multi-agent Q-learning/actor-critic; Monte Carlo tree search (MCTS) for discrete strategy spaces; self-play to approximate equilibria under imperfect information.
- Tools/products/workflows: PettingZoo/Ray RLlib-like frameworks; scenario banks; policy evaluation against baselines.
- Assumptions/dependencies: Equilibrium selection is nontrivial; results are simulator-dependent; instability from non-stationarity among learning agents.
- Preference elicitation for product design and UX — sectors: software, consumer research
- What: Learn user preferences from interaction logs and targeted queries to guide product ranking or feature choices.
- How: Inverse RL and RL from human feedback (RLHF) to infer/shape reward functions; dueling bandits for pairwise comparisons.
- Tools/products/workflows: Human-in-the-loop labeling UIs; priors over reward parameters; online active query scheduling.
- Assumptions/dependencies: Consistent human feedback; privacy constraints; careful reward design to avoid reward hacking.
- Teaching, curricula, and research prototyping — sectors: academia, education
- What: Integrate RL–DP unification into econometrics/computation courses; replicate pricing/inventory and strategic game examples.
- How: Monte Carlo, TD(λ), Q-learning, policy gradients, PPO/SAC; emphasize deadly triad and stability practices.
- Tools/products/workflows: Notebook-based labs; Gym-like environments; unit tests for convergence checks.
- Assumptions/dependencies: Compute availability; clear guidance on hyperparameter sensitivity and diagnostics.
- Causal-aware policy evaluation in logged-data settings — sectors: tech platforms, public policy pilots
- What: Evaluate candidate policies without online exploration using off-policy evaluation with causal estimators.
- How: Importance sampling and doubly robust estimators linked to the survey’s RL–causal inference discussion; combine with conservative policy improvement.
- Tools/products/workflows: OPE pipelines; confidence intervals on value estimates; safe deployment thresholds.
- Assumptions/dependencies: Correctly logged propensities; overlap/support conditions; bias–variance trade-offs acknowledged.
Long-Term Applications
These applications require further research, reliable simulators or offline pipelines, stronger safety/robustness guarantees, or scaling infrastructure before broad deployment.
- Autonomous pricing under regulation and strategic interaction — sectors: retail, airlines, platforms; policy/regulation
- What: RL-driven pricing that adapts to competitors and demand while respecting anti-collusion and fairness rules.
- How: Multi-agent RL with entropy regularization (SAC) and trust regions (PPO/TRPO); constrained RL to encode regulatory constraints; equilibrium-aware training.
- Tools/products/workflows: Regulatory sandboxes; algorithm audits and transparency reporting; anomaly detectors for supra-competitive patterns.
- Assumptions/dependencies: Formal safety constraints; monitoring; simulator/game models capturing competitor reactions; resolution of policy risks highlighted in the survey.
- Market and mechanism design via self-play — sectors: auctions, ride-share, marketplaces
- What: Learn and test auction rules, surge/fee policies, or matching mechanisms through agent-based multi-agent RL.
- How: Self-play with policy gradients; MCTS for discrete mechanism components; joint optimization over mechanism and agent policies.
- Tools/products/workflows: “Mechanism labs” with configurable agents; stress tests across demand/supply regimes.
- Assumptions/dependencies: Existence/selection of equilibria; convergence issues in general-sum games; explainability for regulator acceptance.
- Macroeconomic policy search in heterogeneous-agent models — sectors: public policy, central banks, academia
- What: Use RL to discover robust fiscal/monetary rules in high-dimensional macro models where DP struggles.
- How: Actor-critic or natural policy gradients as scalable approximations to policy iteration; deep function approximation for value and policy surfaces.
- Tools/products/workflows: High-fidelity macro simulators; distributed training; policy stress-testing against rare shocks.
- Assumptions/dependencies: Simulator fidelity and identification; stability guarantees beyond tabular are limited; transparent policy interpretations.
- Energy demand response and dynamic tariffs — sectors: energy, utilities
- What: Continuous, personalized tariffs or incentives to shift loads while maintaining customer satisfaction.
- How: SAC for continuous action spaces (prices/incentives); bandits for customer-segment exploration; entropy regularization for robust exploration.
- Tools/products/workflows: Digital twins of grids; opt-out and fairness constraints; privacy-preserving data feeds.
- Assumptions/dependencies: High-stakes safety constraints; regulator approval; reliable demand elasticity estimation.
- Healthcare and education resource allocation — sectors: healthcare, education, public sector
- What: Adaptive assignment of interventions (appointments, tutoring, outreach) to maximize outcomes subject to fairness and budget constraints.
- How: Contextual bandits for short-horizon decisions; actor-critic with constraints for multi-step care pathways; causal-RL pipelines for off-policy evaluation before deployment.
- Tools/products/workflows: Human-in-the-loop oversight; triage thresholds; fairness-aware reward design.
- Assumptions/dependencies: Ethical review; strong safety guarantees; robust identification under shifting populations.
- Integrated causal–RL systems for policy optimization — sectors: cross-sector (tech, policy)
- What: Combine causal identification with RL to learn policies that generalize out of sample and under interventions.
- How: Doubly robust OPE + conservative policy iteration; policy gradient updates constrained by causal bounds; natural gradients to stabilize updates.
- Tools/products/workflows: Unified pipelines that log propensities and confounders; simulation-based sensitivity analysis.
- Assumptions/dependencies: Strong ignorability/overlap; robustness to covariate shift; scalable uncertainty quantification.
- Preference aggregation and social choice with RLHF/IRL — sectors: public policy, platforms
- What: Learn societal preferences to guide collective decisions (e.g., urban planning trade-offs) through structured feedback and behavior traces.
- How: IRL to infer reward functions from revealed preferences; RLHF to integrate human judgments at scale; entropy regularization to maintain option diversity during learning.
- Tools/products/workflows: Deliberation interfaces; rater training and calibration; governance frameworks for feedback quality.
- Assumptions/dependencies: Preference stability and measurement; bias mitigation; legitimacy of aggregation mechanisms.
- Simulator ecosystems and benchmarks for economic RL — sectors: academia, industry consortia
- What: Shared, validated simulators for pricing, inventory, and strategic markets to standardize evaluation and accelerate research.
- How: Codify DP baselines and RL variants (MC, TD(λ), Q-learning, PPO, SAC) with reproducible seeds and diagnostics.
- Tools/products/workflows: Open-source libraries; benchmark leaderboards; reporting standards for hyperparameters and robustness tests.
- Assumptions/dependencies: Community governance; continual updating to match real-world shifts; acceptance by regulators for pre-deployment evidence.
- Finance applications with offline RL and constraints — sectors: asset management, trading
- What: Portfolio optimization and execution with strict risk, liquidity, and compliance constraints using logged market data.
- How: Conservative/offline RL extensions of actor-critic; trust-region updates; advantage estimation under heavy-tailed returns.
- Tools/products/workflows: Offline datasets with propensities; risk overlays; scenario-based policy audits.
- Assumptions/dependencies: Survey notes separate literature; strong model risk management; limited exploration, reliance on historical regimes.
Cross-cutting assumptions and dependencies (impacting feasibility across applications)
- Simulator fidelity and data quality: The survey stresses reliance on accurate simulators or sufficiently rich logged data; misspecification undermines learned policies.
- Stability and convergence: Outside tabular settings, global convergence is not guaranteed; deadly triad (bootstrapping + off-policy + function approximation) can cause divergence; prefer on-policy or trust-region methods with diagnostics.
- Sample efficiency and hyperparameter sensitivity: RL can be data-hungry and brittle; use replay buffers, target networks, and entropy regularization to stabilize; maintain rigorous tuning and monitoring.
- Safety, constraints, and governance: Exploration is costly in many economic settings; encode constraints (fairness, regulatory rules, budgets) directly; adopt staged rollouts and human oversight.
- Strategic and multi-agent non-stationarity: In markets with learning competitors, environments are non-stationary; self-play and equilibrium analysis are necessary but not sufficient for guarantees.
- Explainability and auditability: For policy and regulated industries, transparent value/policy representations and audit trails are essential for adoption.
Glossary
- Actor-critic methods: Algorithms that maintain both a parameterized policy (actor) and a value function estimator (critic), updating them jointly via temporal-difference signals. "Actor-critic methods combine both ideas."
- Algorithmic collusion: Phenomenon where independent learning algorithms in markets converge to supra-competitive pricing without explicit coordination. "Algorithmic collusion, in which independent pricing algorithms learn to sustain supra-competitive prices"
- Approximate dynamic programming: Methods that approximate dynamic programming solutions via truncated search and learned value surrogates instead of exact computation. "This is approximate dynamic programming."
- Banach's fixed-point theorem: A result guaranteeing a unique fixed point for contractions on complete metric spaces and convergence of iterates to it. "Banach's fixed-point theorem then guarantees a unique bounded solution to the Bellman equation"
- Bandit problems: Sequential choice problems balancing exploration and exploitation when rewards for actions are uncertain. "Chapter 6 addresses bandit problems."
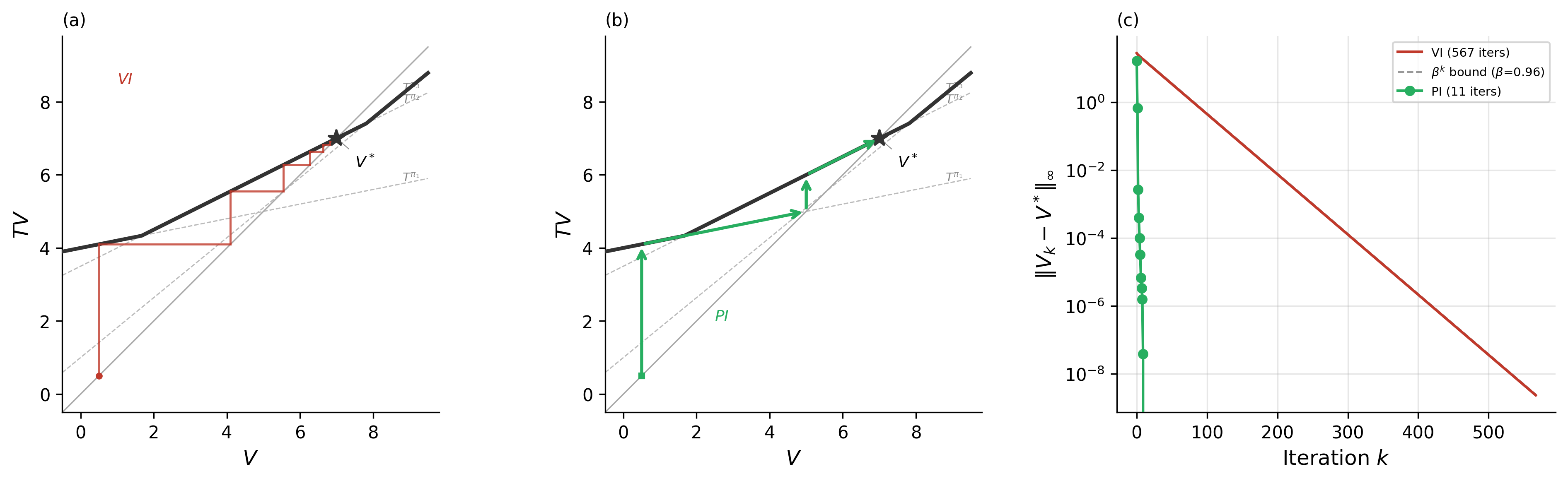
- Bellman equation: The recursive optimality condition expressing a value function in terms of immediate reward and discounted future value. "Both dynamic programming and reinforcement learning solve the Bellman equation;"
- Bellman operator: The dynamic programming operator mapping a value function to a new one via maximization and expectation over transitions. "the Bellman operator defined by "
- Bootstrapping: Updating estimates using other current estimates rather than full observed returns, trading bias for lower variance. "Bootstrapping means updating value estimates using other value estimates rather than observed returns."
- Causal inference: The study of cause–effect relationships and identification strategies linking interventions to outcomes. "Chapter 8 connects reinforcement learning to causal inference."
- Conjugate gradient methods: Iterative solvers for large linear systems that avoid explicit matrix inversion, useful for natural gradient steps. "Practical implementations use conjugate gradient methods to solve without forming explicitly."
- Convolutional neural network: A neural architecture using learned spatial filters well-suited for grid-like inputs such as images. "a single convolutional neural network"
- Curse of dimensionality: Exponential growth in computational burden with increasing state/action/horizon dimensions. "He called this exponential growth the curse of dimensionality."
- Deadly triad: The combination of bootstrapping, off-policy learning, and function approximation that can cause divergence. "the deadly triad."
- Discrete choice models: Econometric frameworks modeling probabilistic choice among discrete alternatives, often via softmax/logit. "connecting to discrete choice models in econometrics."
- Eligibility trace: A decaying memory mechanism assigning credit to recently visited states/actions during TD learning. "the eligibility trace for state ."
- Entropy regularization: Augmenting the objective with an entropy term to encourage exploration and prevent premature determinism. "adds entropy regularization to the actor-critic framework."
- Exploring starts: An exploration assumption/technique where episodes begin from randomly chosen state–action pairs. "Under exploring starts (every pair begins an episode infinitely often)"
- Experience replay: A mechanism that stores and reuses past transitions to break correlation and improve sample efficiency. "Experience replay"
- Fisher information matrix: A matrix capturing the local curvature of the policy distribution, used to define natural gradients. "The update uses the Fisher information matrix :"
- GLIE (greedy-in-the-limit with infinite exploration): An exploration condition ensuring infinite exploration while the policy becomes greedy asymptotically. "greedy-in-the-limit with infinite exploration (GLIE) condition"
- Hamilton-Jacobi-Bellman equation: The continuous-time analogue of the Bellman equation in optimal control. "The continuous-time analogue is the Hamilton-Jacobi-Bellman equation."
- Heterogeneous agents: Economic models where agents differ in characteristics or states rather than being identical. "macroeconomic models with heterogeneous agents"
- Inverse reinforcement learning: The problem of inferring reward functions or preferences from observed behavior. "inverse reinforcement learning"
- Kullback-Leibler divergence: A measure of dissimilarity between probability distributions. "The Kullback-Leibler divergence "
- Minimax: An optimization principle for zero-sum games where a player maximizes the worst-case (opponent-optimal) outcome. "The minimax principle governs adversarial search."
- Monte Carlo tree search: A lookahead method that uses random rollouts to estimate node values and guide tree exploration. "Monte Carlo tree search"
- Multi-agent algorithms: Methods designed for environments with multiple interacting decision-makers, often seeking equilibria. "multi-agent algorithms compute equilibria under imperfect information"
- Natural policy gradient: A policy gradient preconditioned by the inverse Fisher information to respect the geometry of policy distributions. "introduced the natural policy gradient"
- Off-policy: Learning about a target policy while data are generated by a different behavior policy. "This makes Q-learning off-policy:"
- On-policy: Learning about the same policy that generates the experience data. "as an on-policy alternative"
- Policy gradients: Methods that directly optimize parameterized policies by estimating gradients of expected return. "policy gradients, that optimize the policy directly"
- Policy gradient theorem: A result expressing the policy gradient in terms of on-policy state–action visitation and advantage, independent of dynamics. "follows from the policy gradient theorem"
- Policy iteration: An algorithm alternating between policy evaluation and improvement to converge to an optimal policy. "policy iteration"
- Principle of optimality: The property that the remainder of an optimal trajectory is itself optimal from the next state onward. "the principle of optimality"
- Proximal Policy Optimization (PPO): A policy optimization method using a clipped surrogate objective to constrain update size and stabilize training. "Proximal Policy Optimization (PPO)"
- Q-learning: An off-policy TD control algorithm that learns the optimal action-value function by bootstrapping and maximization. "Q-learning achieves this via incremental updates:"
- REINFORCE: The classic Monte Carlo policy gradient algorithm using the score-function (log-derivative) estimator. "update by REINFORCE."
- Residual gradient: Algorithms that minimize the mean-squared Bellman residual to ensure convergence under function approximation. "residual gradient algorithms"
- Rescorla-Wagner: A prediction-error learning model from psychology where associative strengths update via discrepancies between expected and received rewards. "Rescorla-Wagner"
- RLHF: Reinforcement Learning from Human Feedback, where human judgments guide policy learning. "RLHF"
- Soft Actor-Critic (SAC): An off-policy actor–critic algorithm maximizing entropy-regularized returns for stable, sample-efficient control. "Soft Actor-Critic (SAC)"
- Soft Bellman operator: The Bellman operator under entropy-regularized objectives, incorporating expected log-policy terms. "The soft Bellman operator for the critic is:"
- Softmax: A transformation mapping scores to a probability distribution via exponentiated normalization. "softmax in the Q-values"
- Stochastic approximation: A framework for analyzing convergence of noisy iterative algorithms such as TD and Q-learning. "unified stochastic approximation proof"
- Structural estimation: Econometric methods estimating parameters of theory-consistent structural models from data. "structural estimation"
- Surrogate objective: An alternative objective used to approximate or bound the true objective for more stable optimization. "a surrogate objective"
- Target network: A lagged copy of network parameters used to stabilize bootstrapped targets during training. "A target network used a frozen copy of parameters "
- Temporal difference (TD) learning: Methods that update value estimates using differences between successive predictions. "temporal difference (TD) learning"
- Temporal difference error: The one-step prediction discrepancy driving TD updates. "The temporal difference error "
- Transition kernel: The conditional probability distribution over next states given a current state and action. "a transition kernel "
- Trust Region Policy Optimization (TRPO): A policy optimization approach that constrains updates by a KL-divergence trust region for stability. "Trust Region Policy Optimization (TRPO)"
- Two-timescale learning rates: Using different step-size schedules so one component (e.g., critic) updates faster than another (e.g., actor). "two-timescale learning rates ()"
- Value iteration: A dynamic programming algorithm that repeatedly applies the Bellman optimality operator to compute optimal values. "Value iteration computes by iterating"
Collections
Sign up for free to add this paper to one or more collections.

