Statistical Inference via Generative Models: Flow Matching and Causal Inference
Published 9 Mar 2026 in stat.ML and cs.LG | (2603.09009v1)
Abstract: Generative AI has achieved remarkable empirical success, but from the perspective of statistics it often remains opaque: its predictions may be accurate, yet the underlying mechanism is difficult to interpret, analyze, and trust. This book reinterprets generative AI in the language of statistics, using flow matching as a central example. The key idea is that generative models should be understood not merely as devices for producing plausible data, but as methods for the nonparametric learning of high-dimensional probability distributions. From this viewpoint, missing-data imputation becomes principled sampling from learned conditional distributions, counterfactual analysis becomes the estimation of intervention distributions, and distributional dynamics become statistically analyzable objects. Mathematically, flow matching represents distributional deformation through the continuity equation and a time-dependent velocity field, thereby extending score matching from the learning of static score fields to the learning of transport paths themselves. Building on this foundation, the book develops a statistical framework in which generative models are used to estimate nuisance components while inferential validity is maintained through orthogonalization and cross-fitting in the spirit of double/debiased machine learning. Applications to survival analysis, censoring, missingness, and causal inference show how generative models can be integrated into statistical inference for structured high-dimensional problems.
The paper introduces flow matching as a unified framework for integrating high-dimensional generative models with classical statistical inference to ensure robustness in calibration and identifiability.
It details a rigorous process of learning time-dependent vector fields using optimal transport and Lipschitz regularization to stabilize high-dimensional probability flows.
The method is applied to improve imputation, survival analysis, and causal inference through double machine learning and orthogonalization, demonstrating strong theoretical guarantees.
Statistical Inference via Generative Models: Flow Matching and Causal Inference
The monograph "Statistical Inference via Generative Models: Flow Matching and Causal Inference" (2603.09009) by Shinto Eguchi systematically repositions modern generative models within the framework of statistical inference, focusing particularly on flow matching (FM) as a unifying computational principle. The text bridges the computational advances in generative modeling with traditional concerns of statistical identifiability, calibration, and inferential robustness, offering a rigorous statistical infrastructure for leveraging flexible, high-capacity generators in classical and modern inference tasks.
Generative Models Reframed for Statistical Inference
The foundational stance in the text is a reconceptualization of generative models—not merely as sample generators for plausible data or as black-box density estimators, but as fundamental computational representations for high-dimensional probability distributions. This view is sharply semiparametric: it separates interpretable, low-dimensional structure (e.g., means, causal effects, hazards) from infinite-dimensional residuals (nuisance), typically represented as flexible distributional transformations. The goal is not simply accurate data mimicry, but the construction of statistical procedures—across missing data, causal inference, and beyond—in which inference on interpretable targets is preserved even after aggressive calibration of complex nuisance structure.
The generative modeling procedure is formalized by the transformation X=Gθ(Z), mapping reference noise Z (often Gaussian) to data X. This pushforward setup underpins both likelihood-free and likelihood-based approaches. The key innovation is the assertion that distributional estimation, conditional imputation, and counterfactual simulation become unified computational primitives when generative models are cast in this light.
Flow Matching: Mathematical and Computational Architecture
Flow matching constitutes the main vehicle for this statistical reinterpretation. The method operates by translating the problem of distributional transformation into the learning of a time-dependent vector field vt(x). The dynamic, described by the continuity equation,
∂tρt(x)+∇⋅(ρt(x)vt(x))=0,
ensures mass conservation as samples flow from a tractable base distribution (t=0) to the data distribution (t=1).
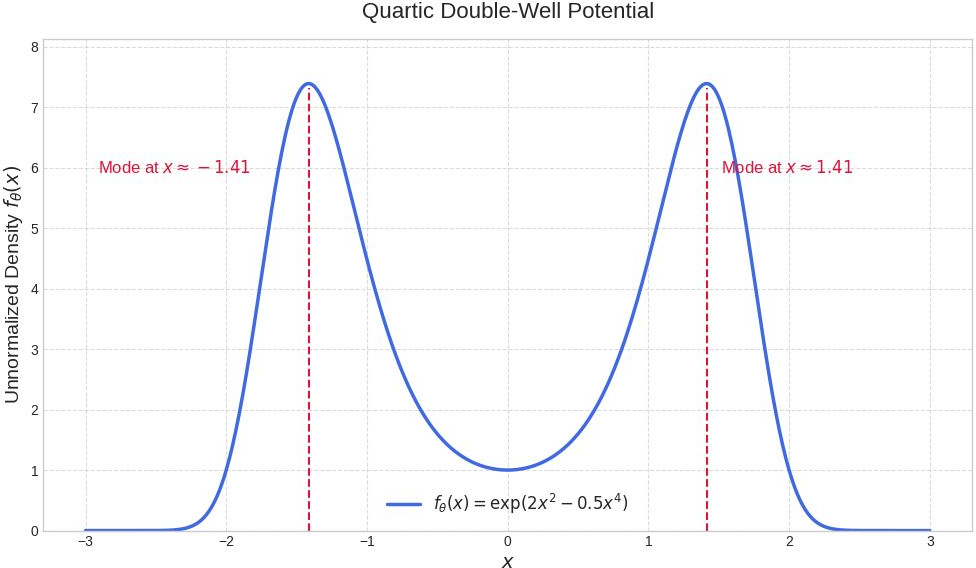
Figure 1: Quartic potential model pθ(x) with θ=(0,2,−0.5).
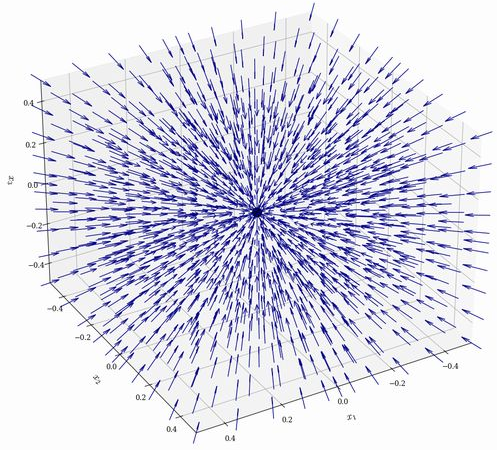
This framework generalizes classical score-based diffusion models, which learn only the score (gradient) field. Flow matching allows for more general, potentially non-gradient (and hence non-reversible) transport, as illustrated by the James-Stein-type shrinkage vector fields:
Figure 2: Vector field induced by a James–Stein-type shrinkage term.
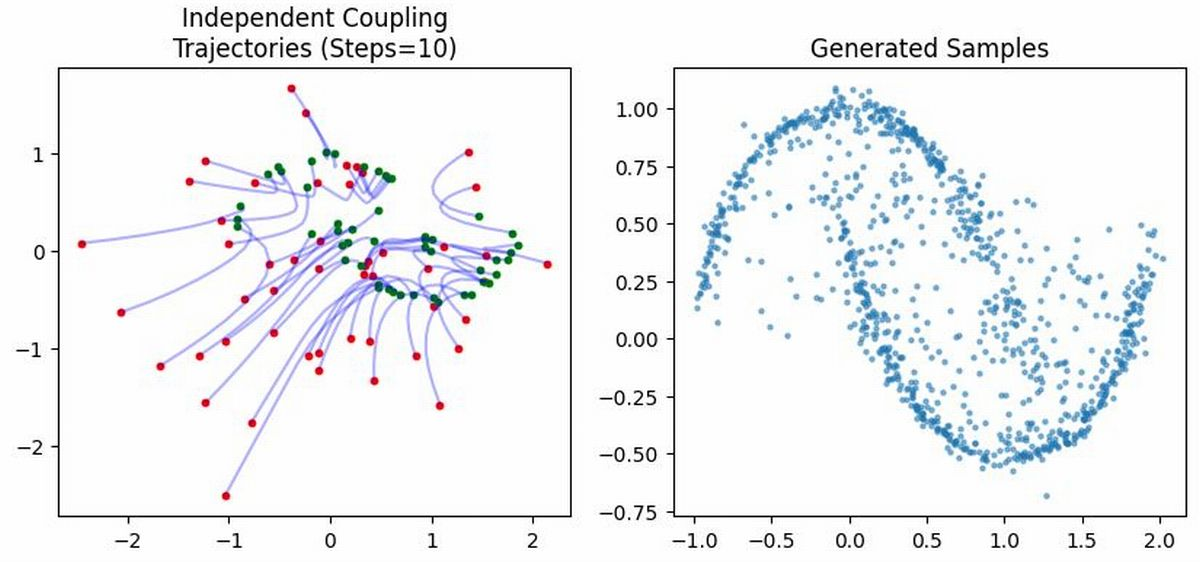
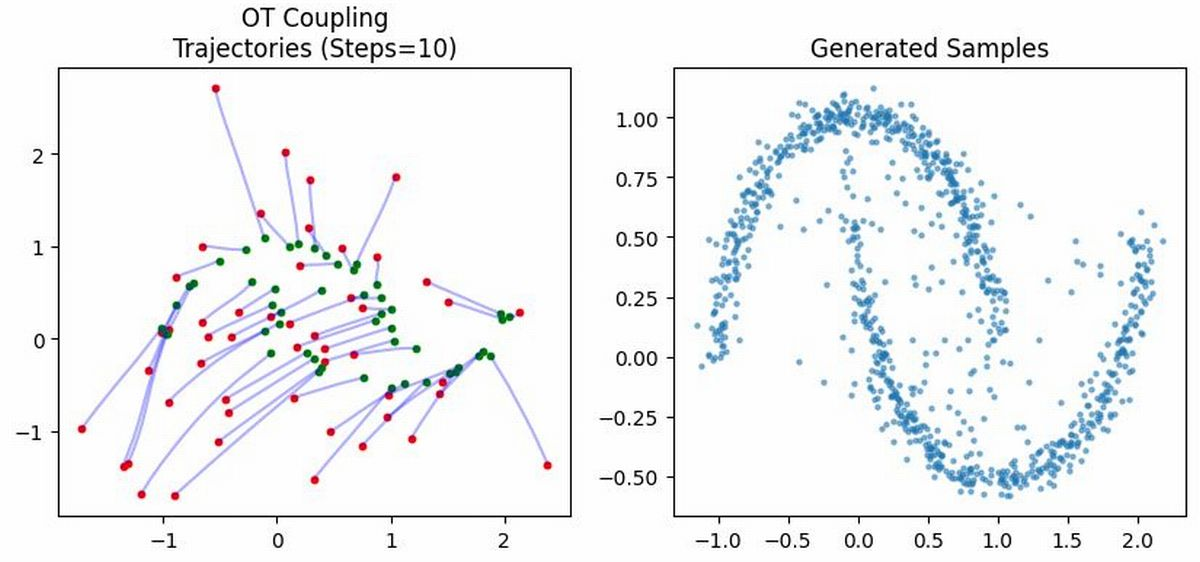
Flow matching proceeds by constructing probability paths—typically via linear or noise-injected interpolation—between pairs of base and data samples, defining conditional flows, and regressing the velocity field against target velocities derived from sample pairs. The optimal transport (OT) perspective is employed both to minimize learning variance (by OT-based coupling) and to motivate geometric regularization of the flows.
Figure 3: Pairings induced by different couplings (illustration).
Theoretical Framework: Approximation, Stability, and Regularization
The monograph develops a deep theoretical treatment of flow learning error, decomposing it into approximation, estimation, and optimization components. Critical is the translation of nonparametric regression theory to the learning of high-dimensional vector fields, with neural networks serving as flexible, scalable approximators.
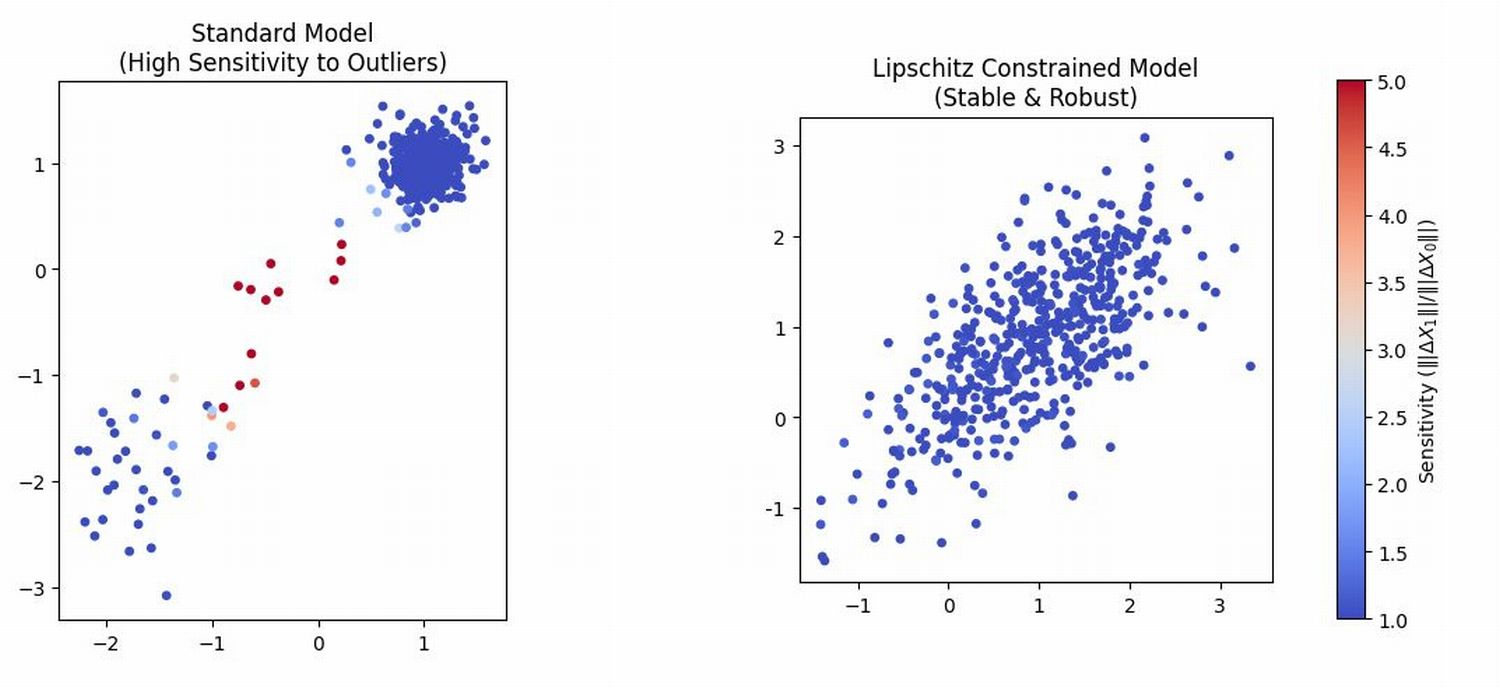
Propagation of learning error through the ODE flow is analyzed via Lipschitz bounds and Grönwall-type inequalities, emphasizing that uncontrolled local oscillations in the velocity field can induce severe instability and error amplification in generated samples. Strong evidence, both theoretical and empirical, is provided for the necessity of explicit control (e.g., spectral normalization) of Lipschitz regularity:
Figure 4: Stabilization and robustness induced by Lipschitz constraints on the velocity field. The color intensity visualizes the sensitivity ratio ∥ΔX1∥/∥ΔX0∥.
The theoretical implications are direct and quantitative: statistical error in the learned velocity field scales up exponentially in the presence of large Lipschitz constants. This analysis justifies the central role of regularization in generative flow architectures.
Orthogonalization and Double Machine Learning (DDML)
A central pillar of the methodology is the integration of modern orthogonalization techniques—specifically, Neyman orthogonality and double/debiased machine learning (DDML)—for valid inferential guarantees when utilizing highly flexible nuisance estimators. The construction of orthogonal estimating equations ensures that errors in nuisance estimation (even at n−1/4 rates) do not impact the first-order asymptotics of the parameter of interest.
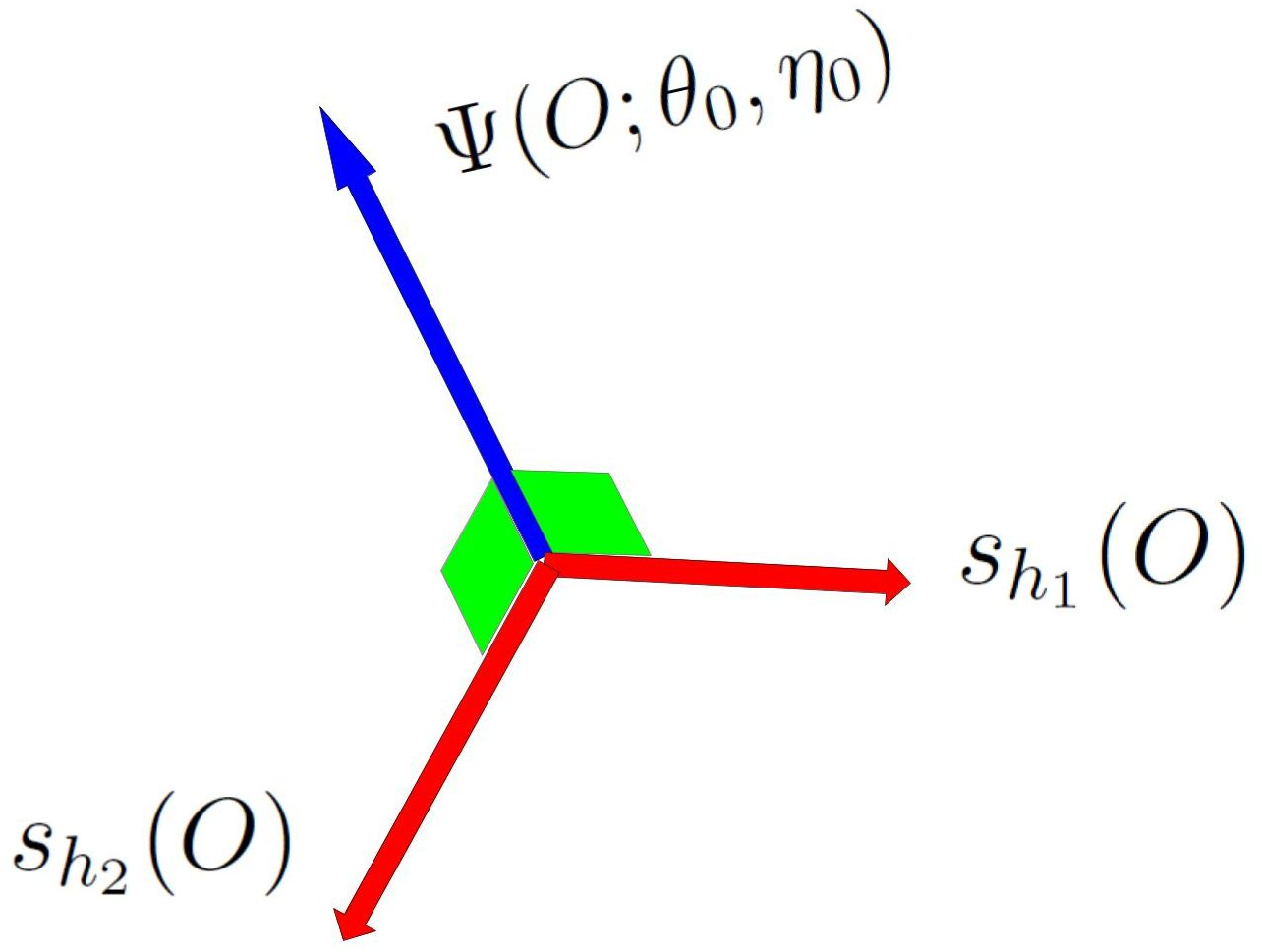
The monograph provides precise expressions for the orthogonal moment functions and elucidates their geometric interpretation (Figure 5). The theoretical results (Theorem 1) formalize n-consistency and asymptotic normality of target estimators even when flexible neural or flow-based nuisance learners are employed.
Figure 5: Neyman orthogonality: parameter score vs nuisance score directions.
Applications: Copulas, Survival, Missing Data, and Causal Inference
Nonparametric Copulas via Flows
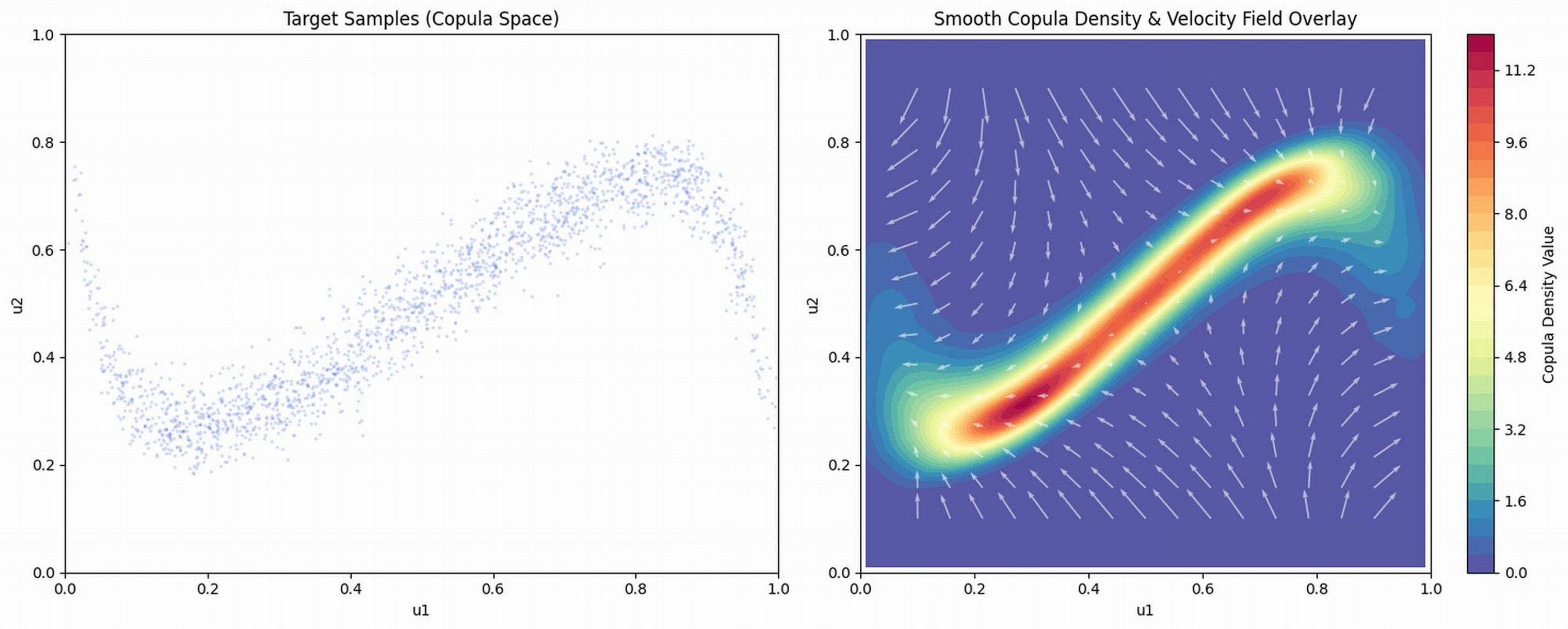
The text leverages flow matching to calibrate high-dimensional copulas while preserving marginal interpretability. By mapping pseudo-observations to Rd via logits or probits and learning a flow in latent space, the framework supports flexible, distribution-free modeling of dependence structures. Significantly, these flows capture nonlinear, asymmetric, and local dependence effects that resist parametric copula families.
Figure 6: Flow-copula learning by FM. Left: target samples exhibiting an S-shaped dependence. Right: samples from the learned model; KDE-based copula-density contours and learned vector field overlay.
Survival Analysis: Extending Cox by Flows
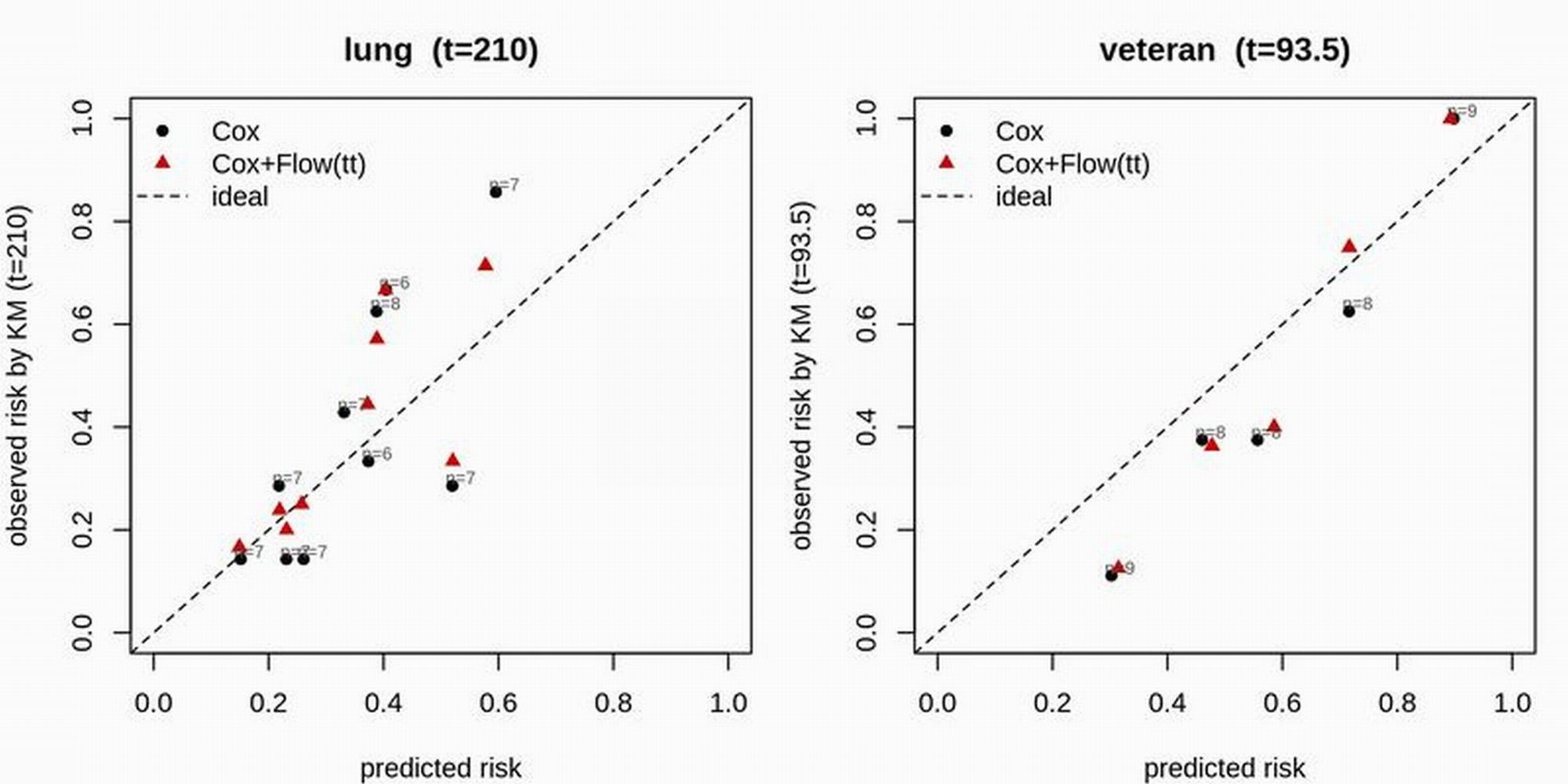
The methodology is extended to survival analysis, where flows correct departures from proportional hazards (PH) models by absorbing non-PH structure into a flexible nuisance generator, while preserving inferential validity for main effects. Calibration, both theoretical and empirical, demonstrates that such corrections only activate when justified by the data.
Figure 7: Calibration curves for a PH-good case (lung) and a PH-bad case (veteran). When PH holds, Cox and Cox+TV coincide; when PH is violated, Cox+TV moves toward the ideal line.
Missing Data: Multiple Imputation by Conditional Flows
FM-based conditional generation is employed as a multiple imputation (MI) engine, significantly outperforming chained-equation regressions when the conditional distribution is nonlinear or multimodal. The method preserves distributional shapes, critical for downstream uncertainty quantification.
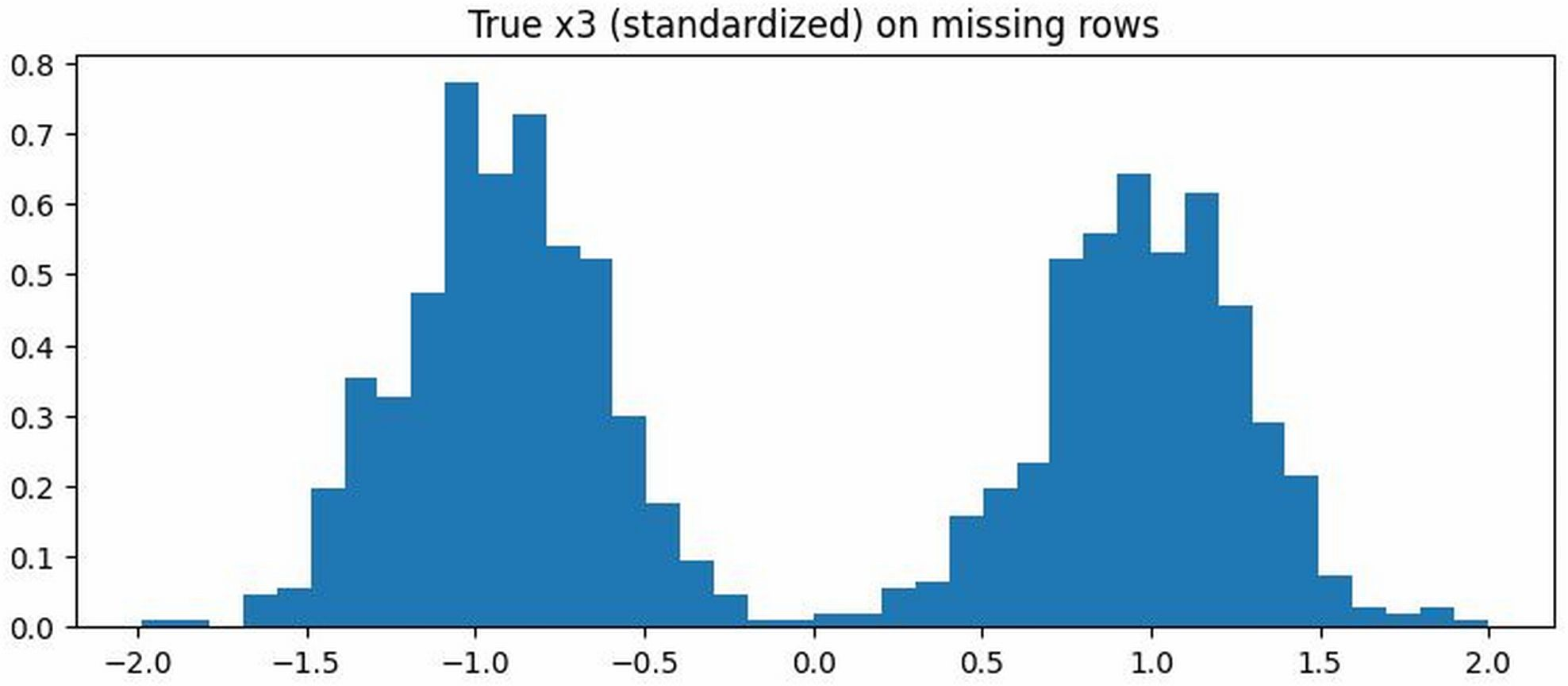
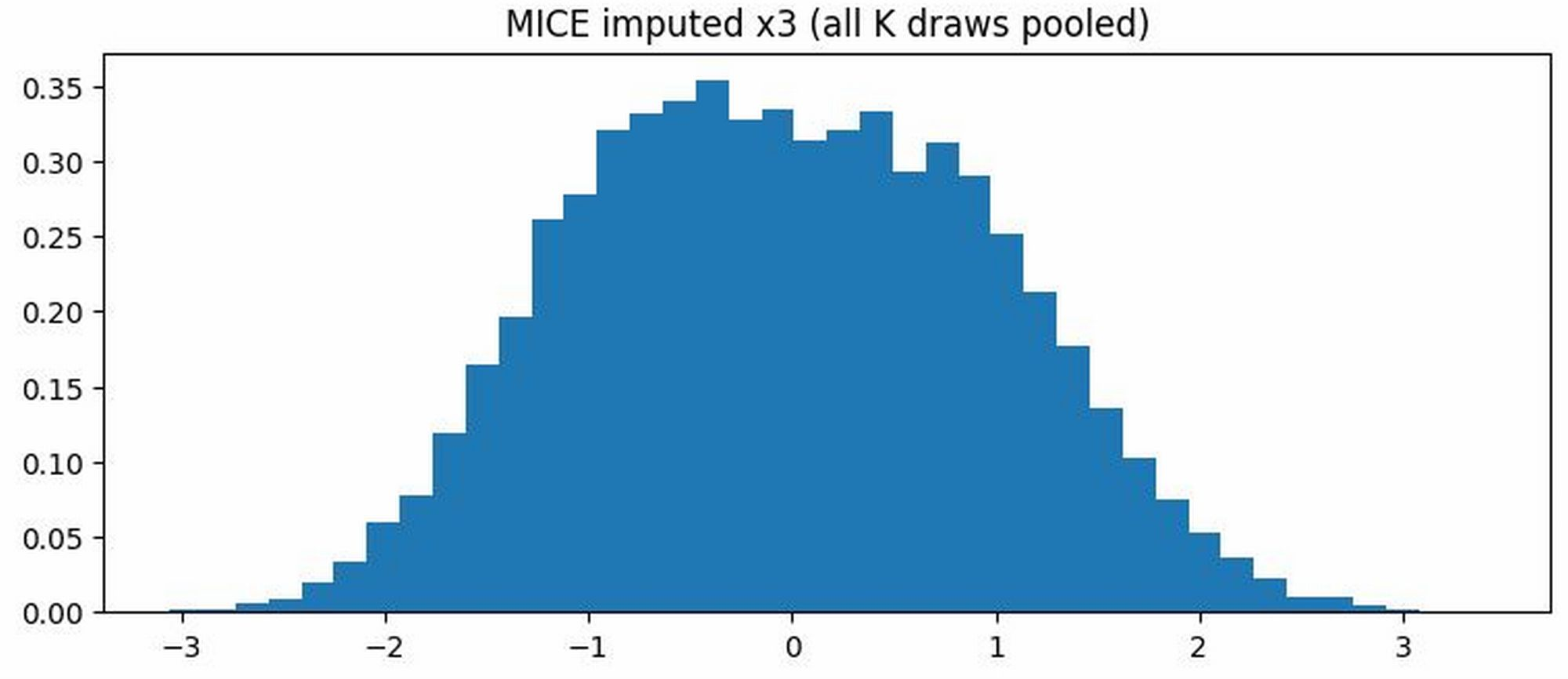
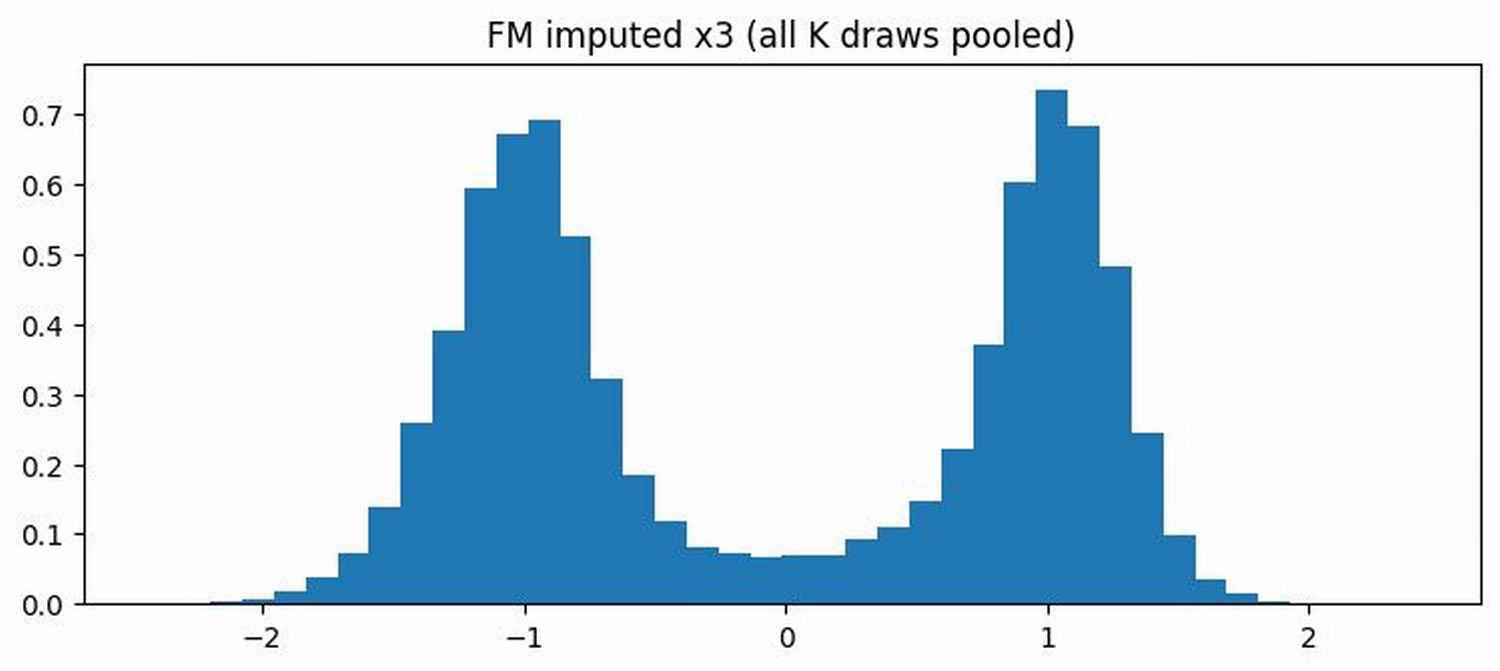
Figure 8: Distribution of X3 among missing rows (M3=1). Top: true X3 (bimodal). Middle: MICE imputation (unimodal collapse). Bottom: FM-based imputation (bimodality preserved).
Causal Inference: Counterfactual Distributions and OT
Causal effect estimation (ATE, CATE) is reformulated as a distributional transport problem, in which flows implement the transformation induced by interventions (the g-formula), yielding generators for counterfactual outcomes under observed and hypothetical policies. Orthogonalization ensures valid uncertainty quantification, decoupled from complex nuisance learning.
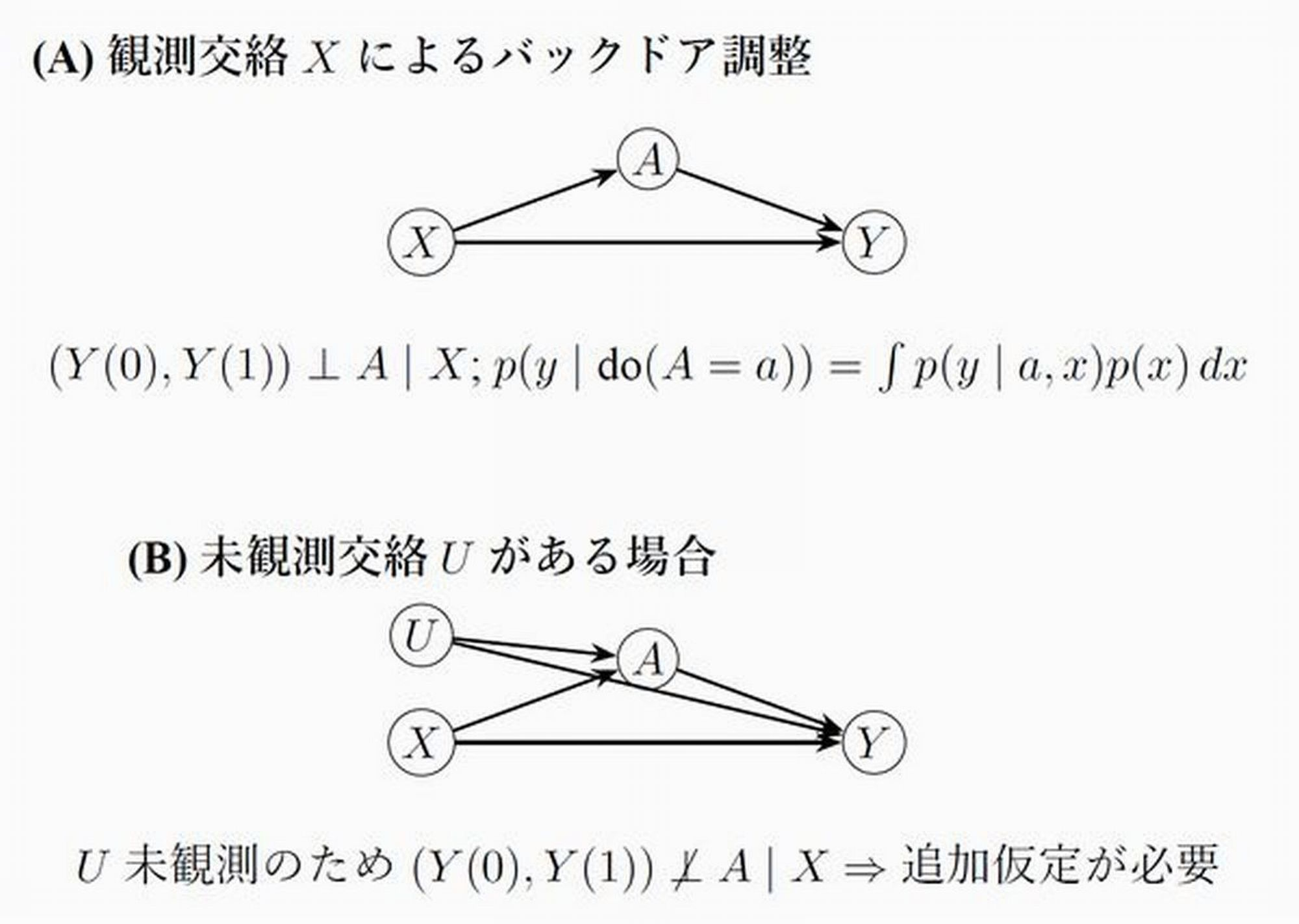
Figure 9: A basic causal DAG example. (A) Conditioning on X closes the backdoor path; (B) Unobserved confounder U induces unidentified counterfactual distribution.
Strong distributional fidelity is demonstrated using FM-based conditional generators, especially in the tails, where regression-based methods can fail.
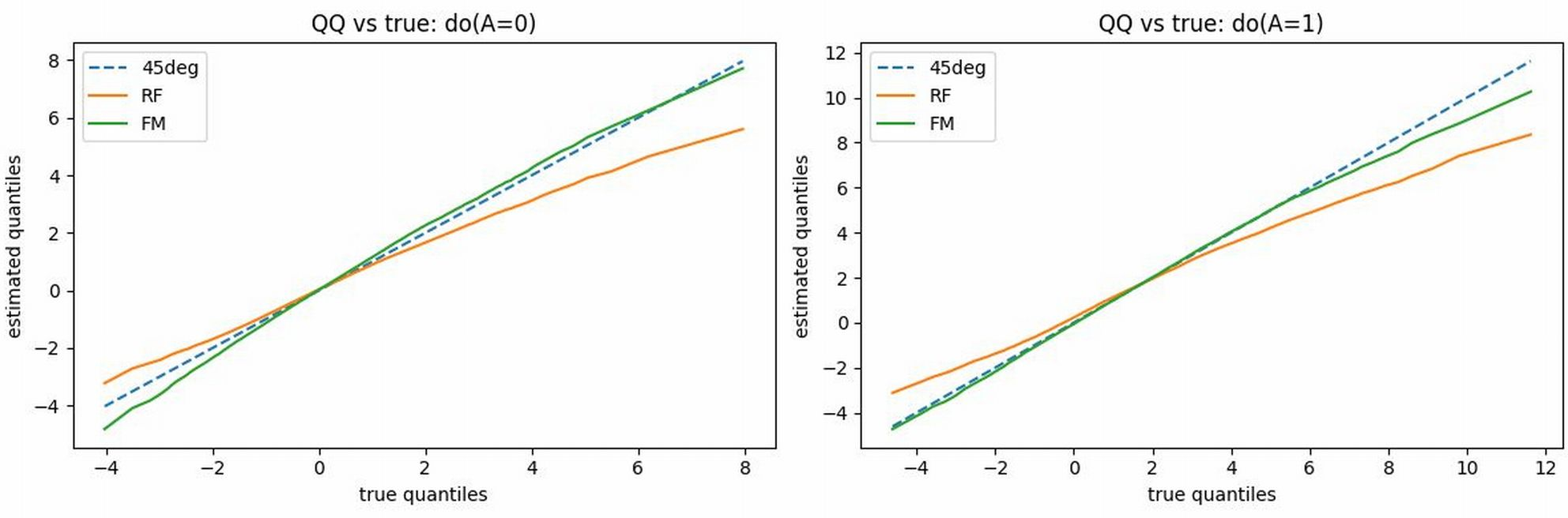
Figure 10: QQ plots for interventional distributions (truth vs estimate). FM reproduces tails accurately; regression-based methods underestimate extremes, especially for do(A=1).
Model Diagnostics and Density-Free Goodness-of-Fit
To address the opacity and calibration risks of high-capacity generative models, the text develops an explicit diagnostic toolkit, featuring Kernel Stein Discrepancy (KSD) for density-free two-sample testing and denoising score matching (DSM) for computationally efficient estimation of score fields. The framework provides a multi-layered analysis for uncertainty, parsing modeling, estimation, and Monte Carlo error, and delineates their implications for inference.
Implications, Limitations, and Future Directions
This monograph fundamentally advances the statistical infrastructure for using generative models as tools for estimation, inference, imputation, and simulation. Notably, it:
Empowers inference in high dimensions by reinterpreting generative models as nonparametric distribution estimators and integrating robust inferential design.
Enables principled calibration of model misspecification, accounting for infinite-dimensional departures via explicit transformation modules that do not erode interpretability.
Institutionalizes regularization and diagnostic checking as necessary for the stability and trustworthiness of flow-based generation.
Limitations persist, especially concerning theoretical rates under strong ultra-high-dimensional regimes, identifiability under MNAR missingness, or in the presence of unmeasured confounding. Empirical selection of regularization and diagnostic protocols remains an area for further refinement. Future work will likely extend these constructions to structured domains (graphs, manifolds), continuous-time interventions, explicit policy learning, and rigorous uncertainty quantification through distributional bootstrap of generative procedures.
Conclusion
By recasting flow matching and generative modeling as integral components of semiparametric inference, orthogonalization, and calibration, the text establishes a pathway for generative AI and rigorous statistical inference to co-evolve. The resulting toolbox is positioned not as a black box, but as a transparent and diagnosable computational engine—capable of tackling infinite-dimensional misspecification, supporting modern scientific and causal inquiry, and unifying sampling, learning, and inference under an interpretable, robust framework.