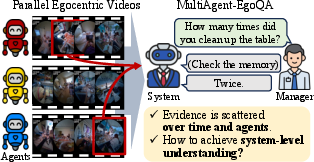
- The paper introduces MA-EgoQA, a benchmark that challenges QA systems to integrate multi-agent, long-horizon egocentric video contexts.
- It details a pipeline combining LLM-generated QA pairs, multi-span synthesis, and cross-agent event abstraction to ensure robust, multi-modal evaluation.
- EgoMAS, a training-free baseline, leverages event-based shared memory and dynamic retrieval to significantly enhance inference efficiency and accuracy.
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Introduction
The paper "MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents" (2603.09827) introduces MA-EgoQA, a new benchmark for evaluating question answering (QA) in realistic multi-agent embodied environments. The primary focus is on the reasoning capabilities and context integration necessary to answer questions that require system-level understanding from temporally aligned, long-horizon egocentric video streams captured by multiple agents. Current video LLMs and benchmarking protocols are inadequate for such scenarios, which motivates the new dataset and corresponding baseline proposed in this work.
Benchmark Design and Contributions
MA-EgoQA is constructed to evaluate a system's ability to understand and reason over multi-agent egocentric video. The benchmark is derived from EgoLife, a 266-hour egocentric video corpus, with simultaneous recordings from six agents over seven days. MA-EgoQA comprises 1,741 questions, each demanding cross-agent, long-term temporal reasoning for correct answering. Key contributions are as follows:
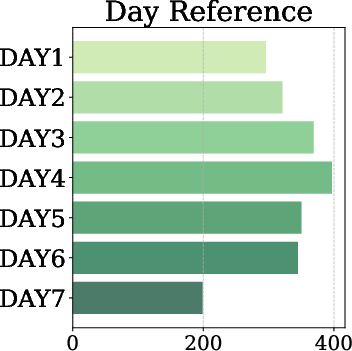
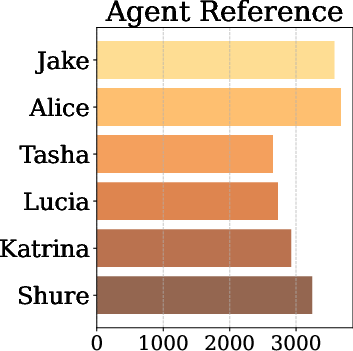
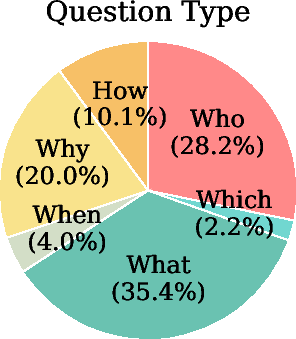
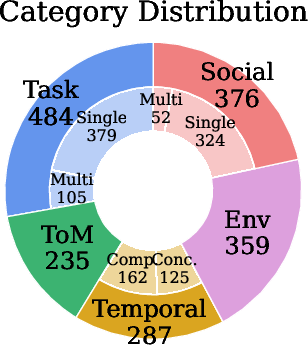
Figure 2: Statistics for MA-EgoQA: per-category sample counts, day/agent reference distributions, and question type statistics.
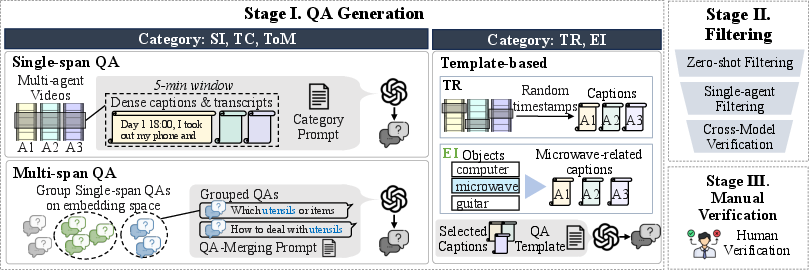
Benchmark Construction Methodology
The benchmark is constructed through a multi-stage pipeline:
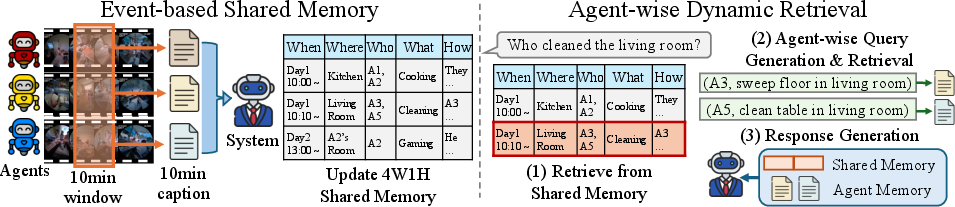
Baseline Model: EgoMAS
The paper also introduces EgoMAS, a training-free centralized system designed as a competitive baseline for MA-EgoQA. EgoMAS is built around two pivotal strategies:
Experimental Results
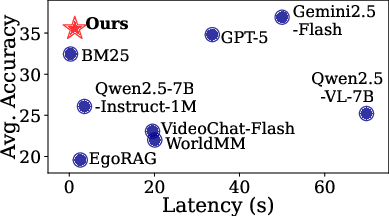
A suite of 16 baseline models—proprietary and open-source LLMs/video LLMs (including Gemini-2.5-Flash, GPT-5, Llama-3.1, Qwen2.5/3, VideoChat-Flash, VideoXL-2)—and several retrieval-augmented (RAG) baselines are benchmarked on MA-EgoQA. Most models employ naive concatenation strategies, and their performance is systematically inferior to retrieval-based approaches.
- Even frontier models such as Gemini-2.5-Flash achieve only 36.9% average accuracy (random: 20%). Many open LLMs and video LLMs perform marginally above chance, highlighting severe context integration and distraction by irrelevant frames.
- RAG-based baselines and EgoMAS substantially outperform naive approaches, despite using significantly less input context (e.g., EgoMAS (Gemini backbone): 41.4% avg, +4.48% over Gemini-2.5-Flash direct input; EgoMAS (Qwen3VL-8B-Thinking): 40.3%; all still far below the Oracle ceiling).
- ToM remains the most challenging category, indicating the difficulty of reasoning about unobservable, latent mental states.
Fine-grained Analysis
- Multi-agent and Long-horizon Challenges: Using only a single agent’s memory leads to large drops in accuracy, demonstrating that MA-EgoQA questions fundamentally require multi-agent integration and temporal understanding. Accuracy consistently degrades as more agents must be referenced per question.
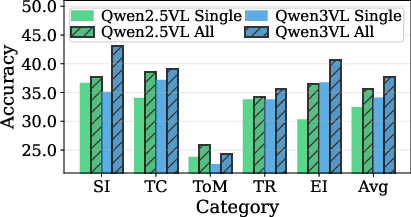
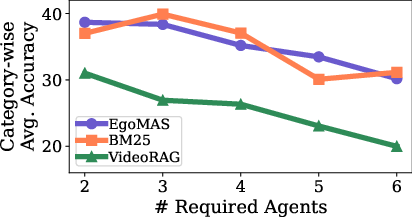
Figure 5: (Left) Performance gap using single-agent vs. all-agent memory; (Right) Accuracy versus number of required agents.
Implications and Future Directions
MA-EgoQA exposes the inability of current LLM and video LLM systems—even those with extended context—to reason over multi-agent, long-horizon, multimodal data. Crucially, naive context concatenation is ineffective and inefficient, and models must acquire finer-grained event abstraction, memory fusion, and retrieval-guided reasoning to close a >40% gap to oracle performance.
From a practical perspective, specialized memory schemas (such as event-centric shared memory) and dynamic, agent-wise retrieval are markedly superior approaches, and suggest a path for scalable, efficient QA in real-world, distributed agent systems. Future advances in multi-agent system LLMs will require not only scaling input capacity, but also advances in knowledge representation (i.e., entity-centric and event-centric modeling), improvement in retrieval, and recursive, compositional query planning. The persistent challenge with ToM reveals unsolved issues in modeling implicit/occluded mental processes from distributed, multimodal observations.
The benchmark further catalyzes progress towards embodied AI assistants capable of transparent reportability, agentic collaboration, and robust system-level monitoring in complex physical environments.
Conclusion
MA-EgoQA represents a consequential step toward evaluating multi-agent video QA, shifting the focus from isolated agent experiences to systemic, temporally extended, and cross-agent memory integration. The strong empirical gap between best baseline and oracle, especially for tasks requiring ToM and multi-span reasoning, defines substantial open challenges for embodied QA and multi-agent LLM architectures. This benchmark will be fundamental for driving innovation in scalable agent memory, fusion protocols, and inference in future human-robot and distributed agent systems.

Figure 7: Case Study: EgoMAS outperforms strong baselines by effectively retrieving and integrating multi-agent events; naive context concatenation and non-fused retrieval fail on complex queries.