Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
Abstract: While reasoning in LLMs plays a natural role in math, code generation, and multi-hop factual questions, its effect on simple, single-hop factual questions remains unclear. Such questions do not require step-by-step logical decomposition, making the utility of reasoning highly counterintuitive. Nevertheless, we find that enabling reasoning substantially expands the capability boundary of the model's parametric knowledge recall, unlocking correct answers that are otherwise effectively unreachable. Why does reasoning aid parametric knowledge recall when there are no complex reasoning steps to be done? To answer this, we design a series of hypothesis-driven controlled experiments, and identify two key driving mechanisms: (1) a computational buffer effect, where the model uses the generated reasoning tokens to perform latent computation independent of their semantic content; and (2) factual priming, where generating topically related facts acts as a semantic bridge that facilitates correct answer retrieval. Importantly, this latter generative self-retrieval mechanism carries inherent risks: we demonstrate that hallucinating intermediate facts during reasoning increases the likelihood of hallucinations in the final answer. Finally, we show that our insights can be harnessed to directly improve model accuracy by prioritizing reasoning trajectories that contain hallucination-free factual statements.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question with a surprising answer: Why does letting an AI “think out loud” help it answer even easy, one-step fact questions (like “Who wrote The Hobbit?”), where step‑by‑step logic shouldn’t be needed? The authors show that turning on reasoning (having the model write a few “thought” sentences before the final answer) helps the AI reach facts it already “knows” but can’t easily pull out. In other words, reasoning unlocks hidden knowledge stored inside the model.
Key Objectives
The researchers set out to:
- Check if “reasoning mode” really helps on simple, single-step fact questions.
- Figure out why it helps: Is it because of breaking problems down, or something else?
- Test two ideas: extra thinking time (a “computational buffer”) and “factual priming” (recalling related facts first).
- See whether making up facts during reasoning (“hallucinations”) leads to wrong final answers.
- Show how these insights can be used to make AI answers more accurate in practice.
How They Studied It (Methods)
To keep things fair and controlled, the team used:
- Hybrid LLMs that can be switched between reasoning OFF and reasoning ON, so the same model’s knowledge is tested both ways.
- Two question sets:
- SimpleQA‑Verified: realistic, cleaned questions with labels about whether they’re multi-step or not.
- EntityQuestions: templated, single-hop questions like “Who wrote [book]?” to focus on fact recall instead of tricky wording.
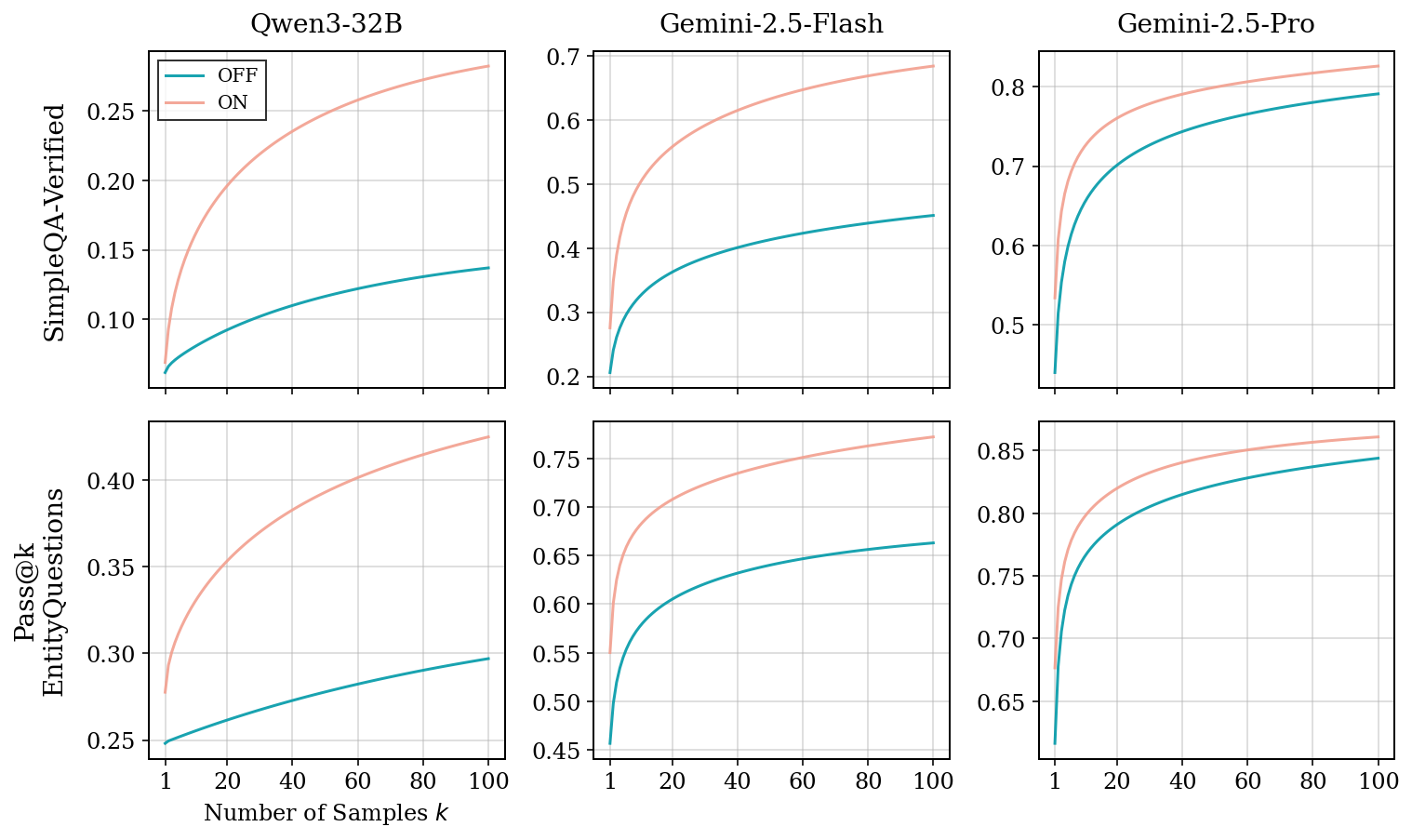
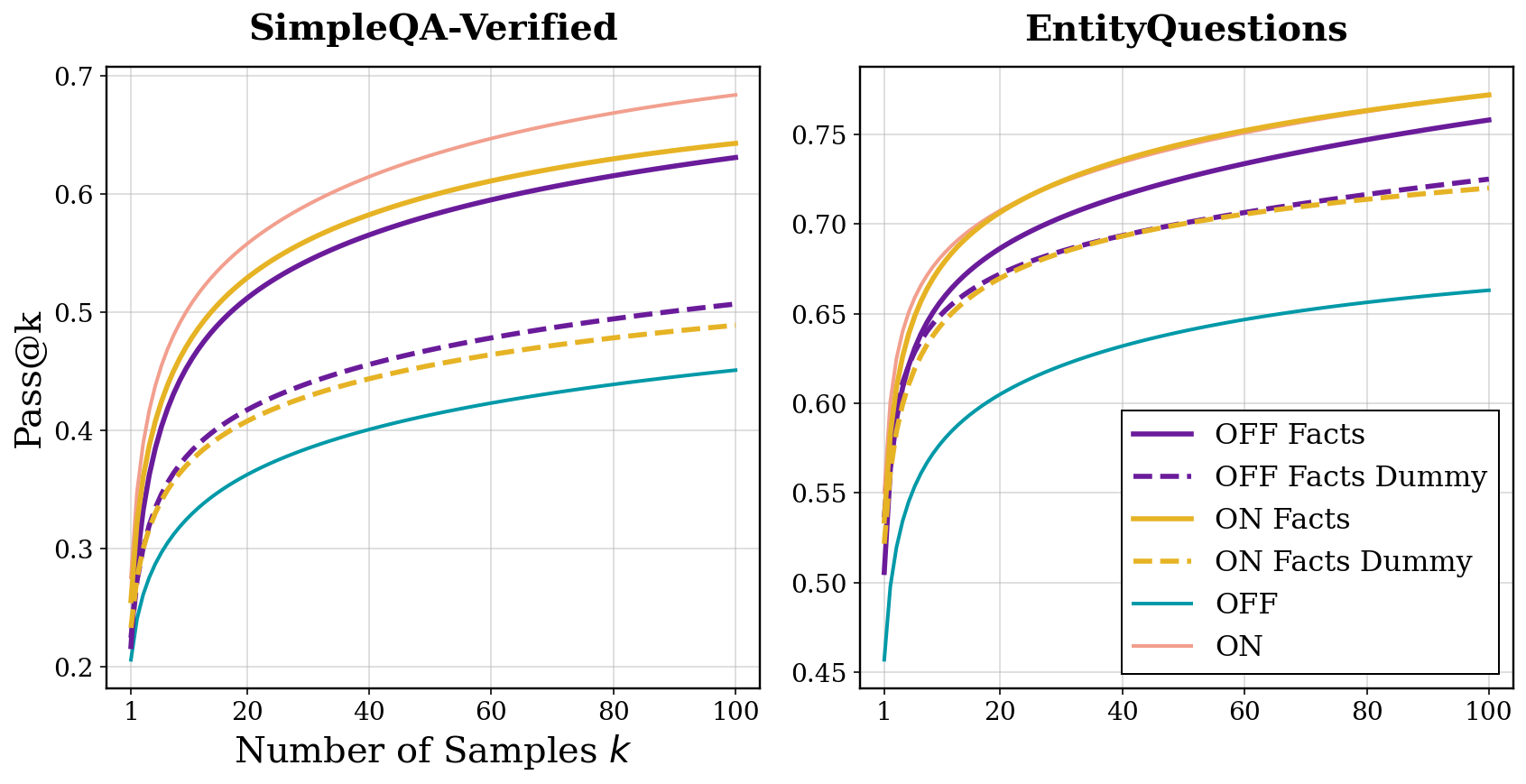
They measured performance with pass@k. Think of k as “how many tries the model gets.” pass@1 is normal accuracy. pass@k asks: “If the model can give k different answers, how often is at least one correct?” This helps reveal whether correct answers exist somewhere in the model’s possibilities—even if they’re not the first guess.
Then they ran controlled experiments to test why reasoning helps:
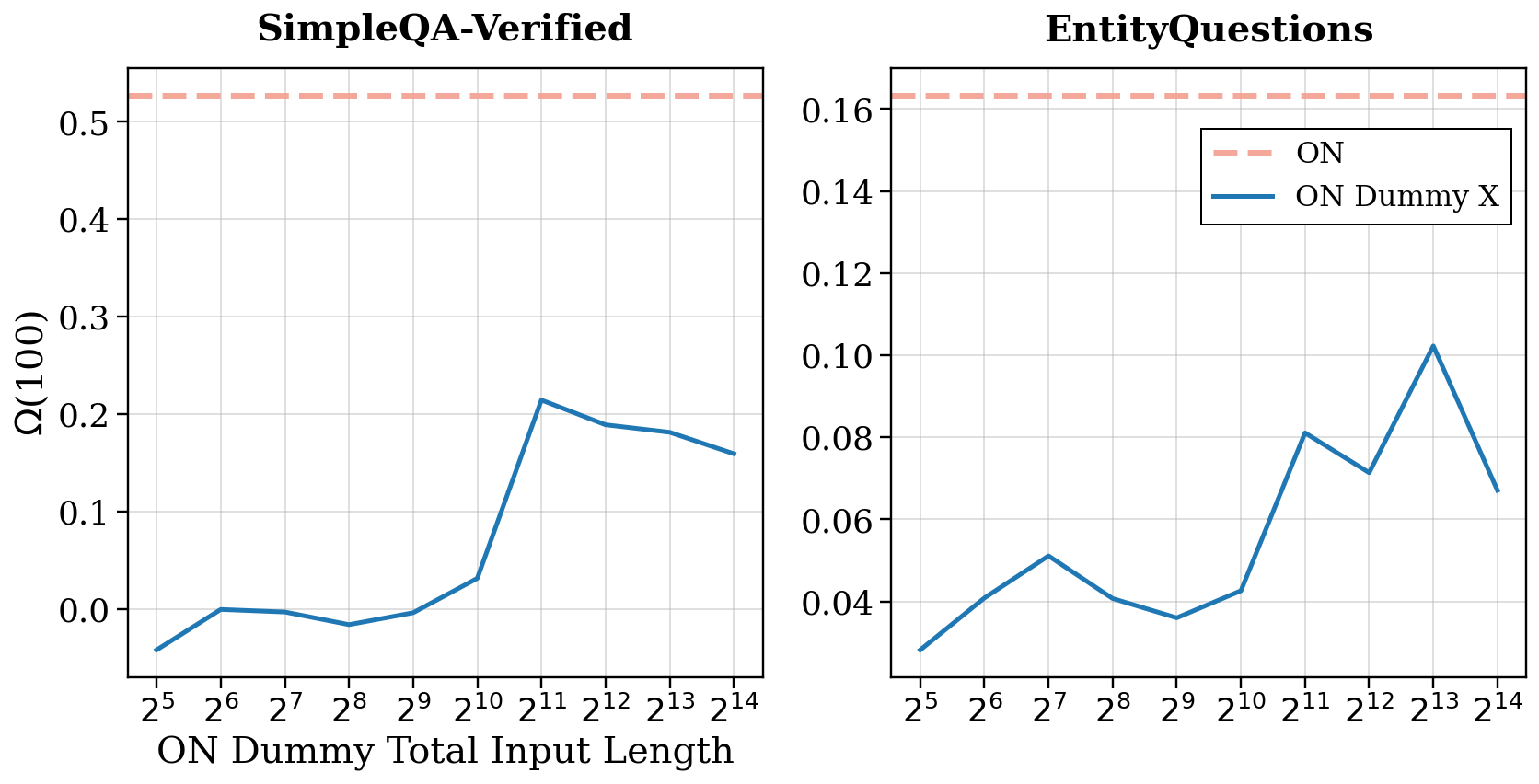
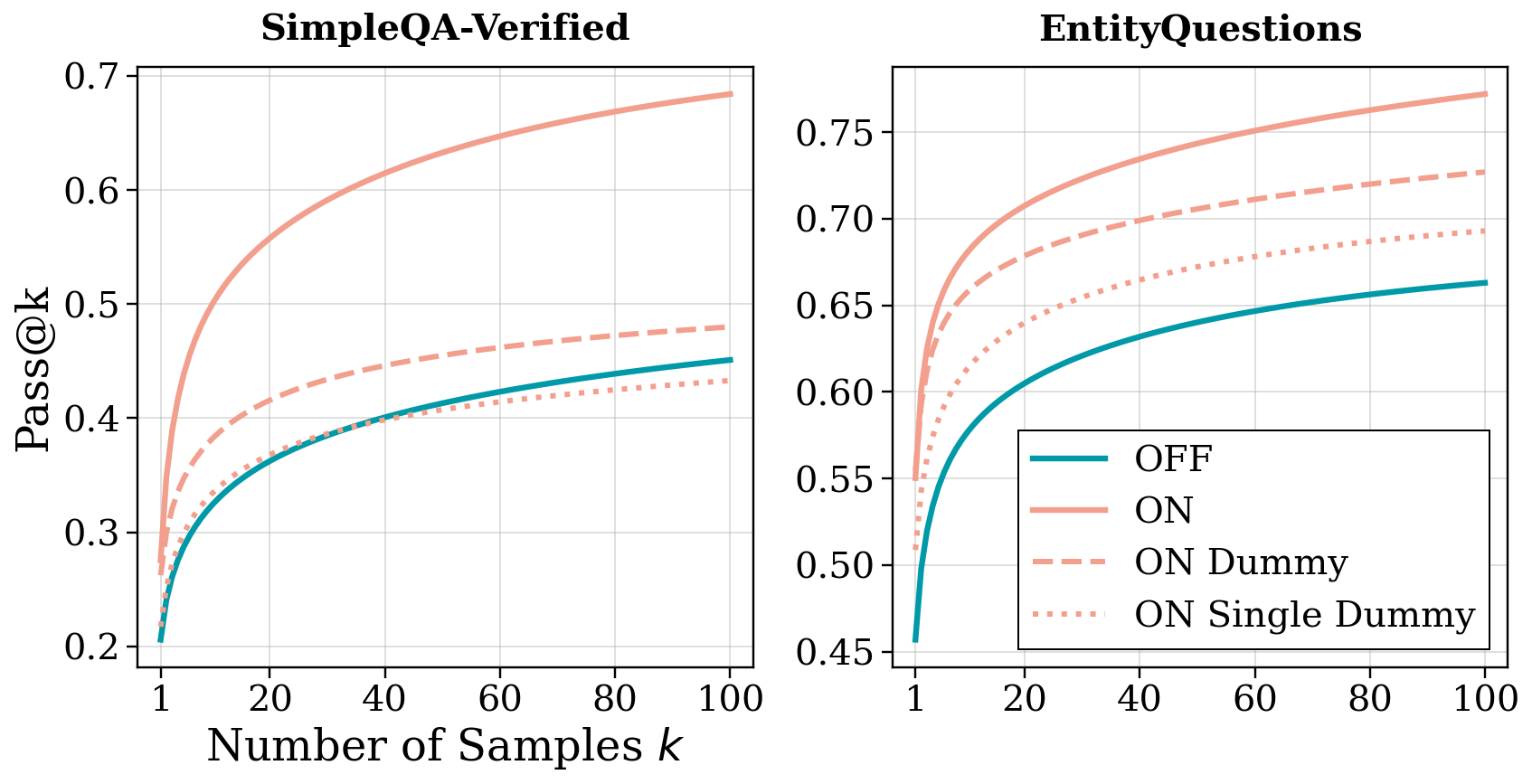
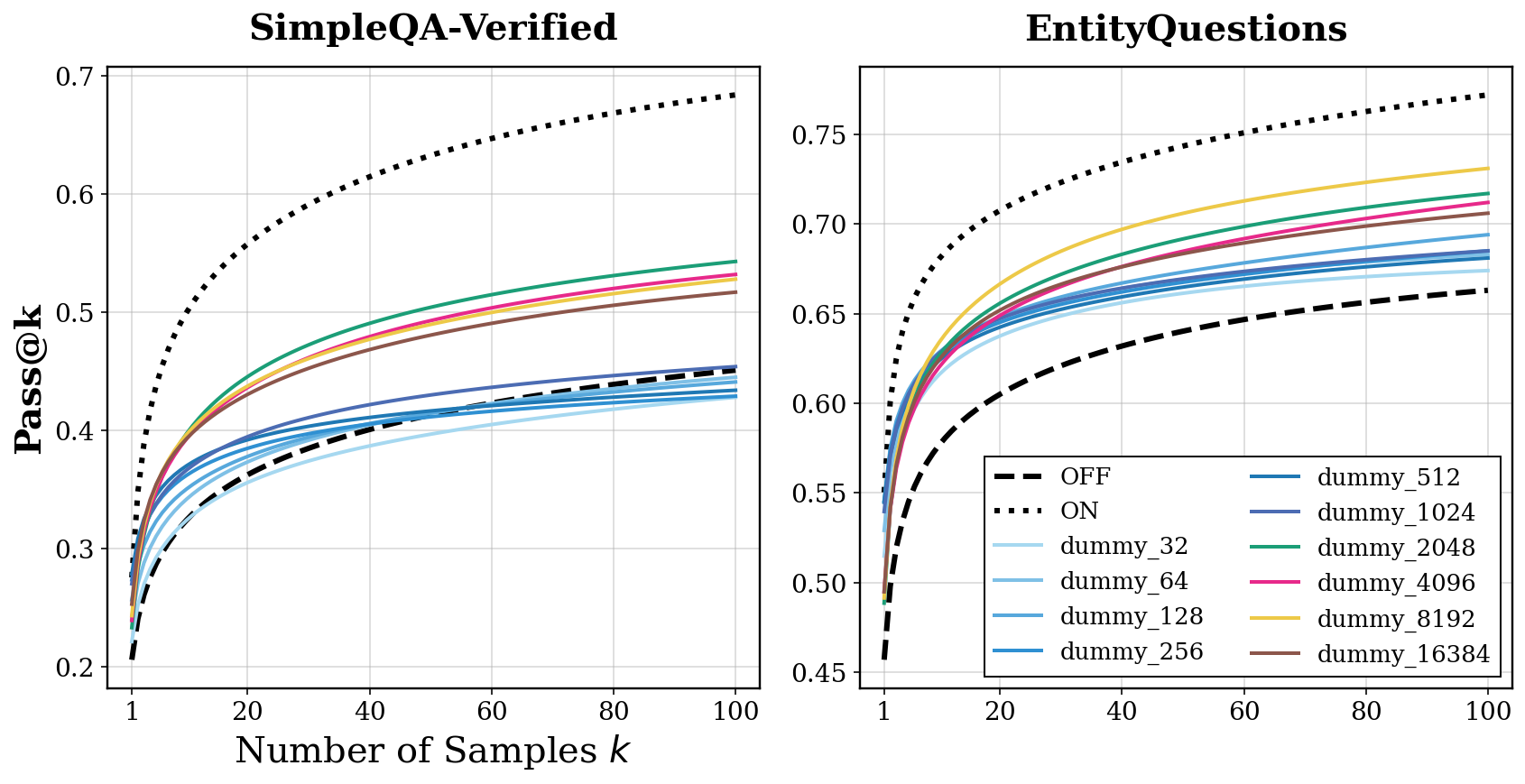
- Computational buffer test: Replace the model’s real “thoughts” with a repeated nonsense line like “Let me think.” If accuracy still improves, that suggests the model uses the extra tokens as “thinking time,” even if the content is meaningless. They tried short and long versions to see how much “extra thinking” helps.
- Factual priming test: Extract a short list of facts the model mentioned during its reasoning (for example, related names, dates, or places), remove any line that directly gives away the answer, and feed that fact list back to the model as extra context—sometimes with reasoning OFF. If accuracy improves, that shows content matters: listing related facts helps the model recall the correct answer.
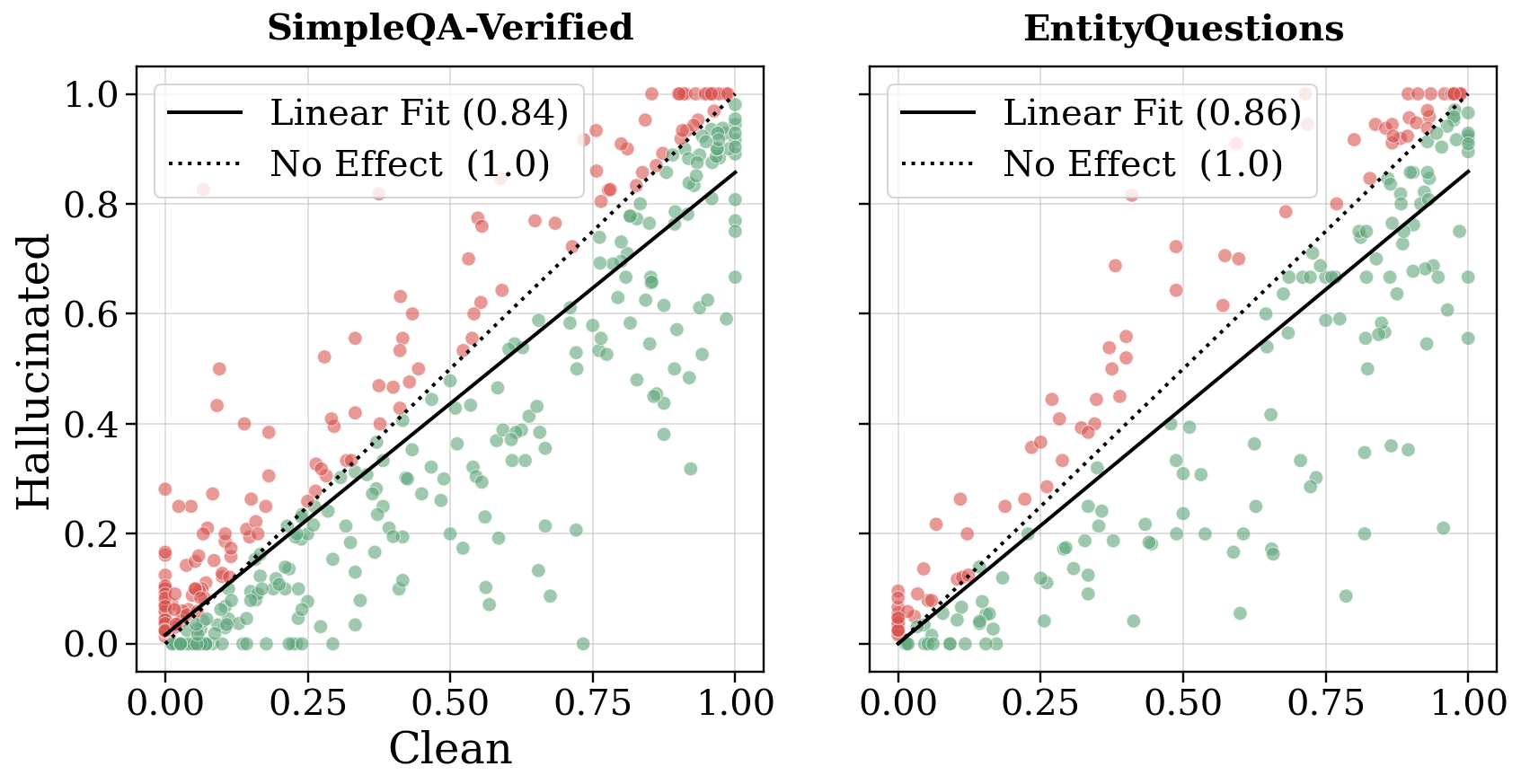
- Hallucination audit: Check every fact the model stated during reasoning using a separate, search-enabled system. Label reasoning paths as “clean” (facts correct) or “hallucinated” (facts wrong), and see which paths lead to better final answers.
- Practical selection: Simulate choosing only reasoning paths that contain facts—or only those with correct facts—and see how much accuracy improves.
Main Findings (What They Discovered)
- Reasoning unlocks hidden knowledge
- Across models and datasets, pass@k curves were higher with reasoning ON. That means the model had correct answers “in there,” but reasoning made them much more reachable.
- The gains were even bigger when the model was allowed more tries (higher k), showing reasoning expands the model’s “capability boundary,” not just top‑1 accuracy.
- Weaker models benefited more, likely because they have more knowledge that’s “hard to reach” without reasoning.
- Question complexity isn’t the main driver
- Questions labeled as “multi-step” or “requires reasoning” did not get bigger benefits than simple questions. So the boost isn’t mainly about breaking down hard problems—it’s about helping the model recall facts it already knows.
- Computational buffer: extra “thinking time” helps—but only up to a point
- Replacing the reasoning content with a repeated dummy line like “Let me think.” still improved accuracy compared to reasoning OFF. That means the model uses the extra tokens as time to refine its guess internally, even if the words don’t mean anything.
- However, making the dummy reasoning extremely long eventually stopped helping and even hurt. And the buffer alone never matched full reasoning performance. So extra compute helps, but it’s not the whole story.
- Factual priming: content matters a lot
- When the researchers extracted the related facts from the model’s thoughts and fed them back in—sometimes with reasoning turned OFF—the model got much better at finding the correct answer. This shows that recalling related facts acts like a semantic bridge that jogs the model’s “memory.”
- In many cases, most of the gain from reasoning came from this factual priming effect.
- Hallucinations in reasoning make final answers worse
- If the model’s reasoning included wrong “facts,” the final answers were much more likely to be wrong. This remained true even when controlling for question difficulty.
- So “generative self-retrieval” (the model reminding itself of facts) is powerful but risky: wrong intermediate facts can steer the model to a wrong final answer.
- A practical win: choose better reasoning paths
- If you keep only reasoning paths that include factual statements, accuracy improves.
- If you keep only the paths whose facts are verified correct, accuracy improves even more (in their tests, by a few to around 12% depending on the dataset).
- This suggests new ways to deploy models: sample several reasoning paths, check their facts, and prefer the “clean” ones.
Why This Matters (Implications)
- For users and developers: Letting models “think” before answering can reveal correct answers they already know but struggle to recall. But that thinking needs to be monitored for made‑up facts.
- For training and design: Don’t just reward longer chains of thought—reward chains that recall true, relevant facts. Teach models to verify or avoid hallucinated facts in their reasoning.
- For deployment: Use reasoning, sample multiple paths, and prefer those with solid, non-hallucinated facts. This can make answers more reliable without needing a brand-new model.
- For research: The biggest gains on simple fact questions come not from step‑by‑step logic, but from two mechanisms:
- A computational buffer (extra “thinking time”),
- Factual priming (recalling related, true facts).
- Balancing these—and reducing hallucinations—can push factual accuracy further.
In short: even for straightforward fact questions, giving an AI space to “think” helps it recall what it already knows. That boost comes from both extra internal processing and from prompting itself with the right related facts—so long as those facts are true.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed to guide actionable follow-up research.
- Dataset scope and generalization
- Results are limited to two English, closed-book QA benchmarks (SimpleQA-Verified and a 4-relation subset of EntityQuestions, 1,000 items each); it is unknown whether the findings hold for other domains (biomedical, legal), ambiguous questions, many-to-many relations, multi-answer settings, or multilingual data.
- The “complex vs. simple” analysis relies on noisy metadata and a small complex subset; controlled pairs of single-hop/multi-hop variants of the same underlying fact are needed to isolate decomposition effects from recall difficulty.
- Model coverage and reproducibility
- Experiments use two proprietary Gemini models and Qwen3-32B; it is unclear whether effects generalize across families, sizes, and open-source models, or to models trained without explicit Chain-of-Thought/RL reasoning.
- The ON/OFF control mechanism (system tokens/instructions) may itself induce distributional shifts; more principled toggles (e.g., logit patching, ablations, or architectural switches) would better isolate reasoning effects.
- For Qwen3-32B, ON and OFF use different decoding hyperparameters; identical settings are needed to cleanly attribute gains to reasoning rather than sampling choices.
- Metrics and evaluation validity
- pass@k and the proposed Ω metric: sensitivity to k-range, temperature/top-p, and the chosen k-weighting scheme is unreported; alternative boundary measures (e.g., compute-normalized pass@k, CDF gaps, probability mass diagnostics) could validate the “capability boundary expansion” claim.
- Reliance on an LLM autorater (Gemini-2.5-Flash) for answer correctness risks grader bias; broader human evaluation, cross-rater agreement, and cross-model grading (e.g., ensemble of raters) are needed to confirm gains.
- The Ω equation is new (and rendered garbled in-text); releasing exact code and conducting sensitivity analyses to the weighting function would improve interpretability and comparability.
- Compute vs. content disentanglement
- Dummy-trace experiments use “Let me think” which may carry implicit reasoning priors; control with multiple fillers (random tokens, punctuation noise, rare/no-op tokens) is needed to ensure improvements are purely content-independent.
- The non-monotonic effect of dummy length lacks a predictive model; what determines the optimal compute budget per question/model, and can it be adaptively selected at inference time?
- It remains unclear whether the “buffer” effect stems from longer contexts (positional/attention dynamics) vs. genuine multi-step latent computation; probing internal activations, attention patterns, and layer-wise dynamics could adjudicate.
- Factual priming mechanism: scope, causality, and failure modes
- Fact extraction uses prompted LLMs and heuristic filters; error rates, leakage (removing answer-revealing content), and stability across extractors are not fully quantified.
- Causal tests are incomplete: inserting unrelated-but-topical facts, contradictory facts, neutral filler, or partially incorrect lists would reveal the boundary between helpful priming and harmful interference.
- The degree and type of relatedness that help (e.g., knowledge-graph distance, semantic similarity, entity co-occurrence) are unmeasured; systematic ablations could map which facts most effectively bridge to the answer.
- It is unknown whether the priming effect holds when facts are provided by external retrieval (RAG) vs. self-generated; head-to-head comparisons could separate “generation warm-up” from “content utility.”
- Hallucination auditing and causal impact
- The verifier is a search-enabled LLM; despite a small human spot-check, broader human validation, adversarial tests, and cross-verifier agreement are needed to quantify false positives/negatives and abstention behavior.
- The within-question analysis controls for difficulty but remains correlational; interventional studies (e.g., programmatically flipping a key fact’s truth value) are needed to estimate the causal effect of hallucinated intermediates on final answers.
- Only explicit “fact” statements are audited; other misleading reasoning moves (spurious heuristics, unjustified eliminations) are not captured and may also drive downstream errors.
- Practical deployment and cost
- The proposed selection strategy is simulated with oracle-quality fact verification; a deployable, low-latency detector for fact presence/correctness (without web search or with bounded-cost retrieval) remains to be designed and evaluated.
- Compute-normalized comparisons are missing: given ON traces are longer and fact-verification adds calls, how do gains compare under equal wall-time/token budgets to alternative strategies (e.g., more OFF samples, self-consistency, reflection, or RAG)?
- Robustness to real-world constraints (rate limits, partial search failure, stale web results) and the impact on user latency/throughput have not been quantified.
- Boundary characterization and error taxonomy
- Which questions benefit most from reasoning (e.g., tail entity frequency, recency, answer type, surface form ambiguity) is unreported; stratified analyses could guide targeted training/inference.
- Distinguishing boundary expansion from probability sharpening would benefit from token-level probability analyses (e.g., whether reasoning creates new high-probability answer modes vs. reorders existing ones).
- Training implications
- Process rewards to encourage “factually grounded, hallucination-free” reasoning are proposed but not tested; experiments comparing reward types (fact presence, verifier-approved facts, uncertainty-aware abstention) are needed.
- It is unknown whether models can be trained to self-detect uncertain or unverifiable intermediate facts and defer or query tools accordingly, and what the recall–precision trade-offs look like.
- Interaction with tools and retrieval
- Reasoning traces often “plan” to search, yet evaluation disables tools; the interaction between factual priming, tool use (search/RAG), and compute budgets remains unexplored.
- Do the identified mechanisms persist, amplify, or diminish in open-book settings, and how should compute be allocated between generation, retrieval, and verification?
- Transparency and release
- Full prompts, code for Ω and pass@k estimation, fact-extraction/verification pipelines, and anonymized outputs would improve reproducibility and enable independent audits of pipeline-induced biases.
Practical Applications
Immediate Applications
- Reasoning-on for single‑hop factual QA to increase coverage (Industry: software, enterprise support, customer service; Education; Finance)
- Tools/workflows: Enable the model’s reasoning mode for “simple” factual questions; sample multiple trajectories (pass@k), and select the best answer; set a moderate reasoning token budget to capture the computational buffer effect without excessive latency.
- Assumptions/dependencies: Access to a model that supports a reasoning toggle; additional token budget and latency are acceptable; A/B testing shows gains on your domain data.
- Factual-priming pipeline before answering (Industry: healthcare knowledge assistants, legal/finance research tools; Education)
- Tools/workflows: Two-step inference: (1) ask the model to list related facts, filter out question restatements and answer‑revealing statements; (2) answer conditioned on this fact list (even with reasoning off). This captures most of the benefit while keeping outputs concise.
- Assumptions/dependencies: Reliable fact-extraction prompts; domain adaptation for filters; slight extra latency for the pre‑answer step.
- Hallucination‑aware trajectory selection at inference (Industry: high‑stakes sectors such as healthcare, finance, legal; Policy/Compliance)
- Tools/workflows: For each sampled reasoning trace, extract intermediate facts and verify them via search or a domain KB; prioritize “clean” traces (no hallucinated facts) when selecting the final answer. The paper shows +5–12% accuracy improvements from such selection.
- Assumptions/dependencies: Search/KG access; added cost/latency for verification; privacy/compliance review for external lookups.
- Dynamic compute budgeting to exploit the computational buffer (Industry: on‑device/mobile, embedded; Software)
- Tools/workflows: Set and tune a per‑query “thinking token” cap; start with a moderate cap (e.g., up to ~2k tokens) and stop early when marginal returns plateau; avoid very long traces given non‑monotonic gains.
- Assumptions/dependencies: Telemetry to monitor pass@k vs. token use; product tolerance for variable latency; model exhibits non‑monotonic length–accuracy trade‑offs similar to those reported.
- Capability-boundary monitoring with pass@k (Industry & Academia: MLOps, evaluation teams)
- Tools/workflows: Track pass@k curves (not just top‑1) to detect whether reasoning unlocks “hidden knowledge”; include an “ON vs. OFF” dashboard; optionally compute a weighted improvement score over k to summarize effects.
- Assumptions/dependencies: Ability to sample multiple responses; robust autoraters or reference answers; consistent evaluation prompts.
- Reasoning‑content scanning for safety/compliance (Industry: regulated sectors; Policy)
- Tools/workflows: Inspect reasoning traces for unverifiable facts; if present, fall back to retrieval‑augmented answers, human review, or withhold an answer; log reasoning‑stage hallucinations as risk signals.
- Assumptions/dependencies: Access to the model’s reasoning traces (some providers hide them); scalable verification; clear escalation policies.
- RAG query refinement via fact lists (Industry: enterprise search, legal/finance research)
- Tools/workflows: Use the model’s self‑generated fact list as structured queries to a retriever; retrieve and re‑ground before finalizing the answer; optionally suppress the final step if retrieved evidence conflicts with the generated facts.
- Assumptions/dependencies: Retrieval infrastructure; mapping from fact statements to queries; evidence‑consistency checks.
- Small/mid‑size LLM deployment optimization (Industry: edge/mobile/IoT)
- Tools/workflows: Prefer enabling reasoning on smaller models to unlock “hidden knowledge” (the paper finds larger marginal benefits for less capable models); tune token budgets for latency targets.
- Assumptions/dependencies: Device constraints on battery/latency; empirical validation on target tasks.
- End‑user prompting patterns to boost recall (Daily life; Education)
- Tools/workflows: Encourage users to ask assistants to “list relevant facts first, then answer” and “verify the facts used”; useful for study, research, and personal knowledge tasks.
- Assumptions/dependencies: Users accept extra tokens/cost; assistant supports stepwise prompting.
- Documentation & support bots for obscure lookups (Industry: developer tools, SaaS support)
- Tools/workflows: Enable reasoning; add a lightweight fact‑priming step for queries like “Which API function does X?” or “Who authored library Y?”; optionally verify facts against internal docs before replying.
- Assumptions/dependencies: Access to internal documentation/KBs; privacy controls for verification.
Long‑Term Applications
- Process‑reward training for factual reasoning (Academia & Industry: model training; Policy for certification)
- Tools/workflows: Train or fine‑tune LLMs with rewards that encourage recall of verifiable intermediate facts and penalize hallucinated ones; combine with verifier feedback during RL or preference optimization.
- Assumptions/dependencies: High‑quality verifiers and curated reward signals; compute budget; access to reasoning traces during training.
- Architectures that decouple “compute tokens” from semantic content (Academia & Industry)
- Tools/workflows: Introduce latent computation steps (non‑semantic tokens) the model can use to refine predictions without emitting verbose CoT; automate dynamic allocation based on uncertainty.
- Assumptions/dependencies: Changes to decoding/training; user experience and policy considerations for hidden reasoning.
- CoT compression to “fact lists” (Academia & Industry)
- Tools/workflows: Learn to compress long CoT into minimal, non‑answer‑revealing fact lists that still provide priming gains; reduces cost while preserving benefits.
- Assumptions/dependencies: Training data with CoT ↔ fact‑list pairs; careful leakage control; domain adaptation.
- Domain‑specific verification backends (Healthcare, Finance, Legal)
- Tools/workflows: Integrate SNOMED/ICD, drug labels, SEC filings, case law, or proprietary KGs as fact verifiers for intermediate statements; enforce “clean‑trace‑only” answer selection.
- Assumptions/dependencies: Up‑to‑date domain KGs; entity linking and normalization; governance for proprietary data.
- Multi‑agent reasoning: generate–verify–answer (Industry & Academia)
- Tools/workflows: One agent proposes facts (priming), another verifies/corrects them, a third composes the final answer; orchestrate with explicit acceptance thresholds.
- Assumptions/dependencies: Reliable coordination; latency management; robust disagreement resolution.
- Standardized “Reasoning Trace” objects and APIs (Industry; Policy)
- Tools/workflows: Define interoperable schemas for intermediate facts, verification results, and selection decisions to plug into MLOps, auditing, and compliance tools.
- Assumptions/dependencies: Vendor buy‑in; privacy/security standards for trace storage and access.
- Human‑in‑the‑loop triage for high‑stakes use (Policy; Healthcare/Legal/Finance)
- Tools/workflows: If no “clean” reasoning trace is found after N samples, escalate to human review; prioritize questions with high impact or low verification coverage.
- Assumptions/dependencies: Clear triage thresholds; staffing and workflow integration; audit trails.
- Curriculum and pedagogy aligned with factual priming (Education)
- Tools/workflows: Learning tools that prompt students to enumerate related facts before answering; use the model to give feedback on completeness and correctness of fact lists.
- Assumptions/dependencies: Alignment with curricula; safeguards against misinformation; explainability features.
- Energy/latency‑aware inference schedulers (Industry: platform engineering)
- Tools/workflows: Allocate reasoning token budgets and sampling counts based on task criticality and SLA; pre‑compute or cache verified fact patterns for frequent queries.
- Assumptions/dependencies: Observability for compute–quality trade‑offs; caching infrastructure; task classification.
- Evaluation standards focused on capability boundary (Academia; Policy/Certification)
- Tools/workflows: Establish pass@k‑based benchmarks for factual recall under reasoning; require reporting of ON vs. OFF performance, verification rates, and hallucination propagation.
- Assumptions/dependencies: Community consensus on metrics and autoraters; diverse, verified datasets.
- Pretraining that enhances semantic “spreading activation” (Academia & Industry)
- Tools/workflows: Explore objectives that strengthen association pathways among related facts (e.g., graph‑regularized contrastive learning) to make factual priming more reliable and efficient.
- Assumptions/dependencies: Large‑scale curated corpora/graphs; careful evaluation to avoid spurious associations.
- Privacy‑preserving verification (Policy; Industry)
- Tools/workflows: On‑prem or federated verifiers; differential privacy where needed; policy templates specifying how intermediate facts can be verified and logged.
- Assumptions/dependencies: Infrastructure for on‑prem KGs/search; compliance requirements; security audits.
- Reasoning‑aware scheduling for smaller vs. larger models (Industry)
- Tools/workflows: Route queries likely to benefit from reasoning to smaller models with higher marginal returns (higher “Ω”), reserving larger models for cases where reasoning yields little extra; reduce cost while maintaining accuracy.
- Assumptions/dependencies: Reliable benefit predictors; router accuracy; monitoring to avoid regressions.
Glossary
- Abstention: A verifier’s option to refrain from labeling when evidence is insufficient to decide correctness. Example: "allowing abstention if correctness cannot be reliably determined"
- Autorater: An automated evaluator (often an LLM) used to grade predicted answers against ground truth. Example: "we do this using Gemini-2.5-Flash as autorater"
- Capability boundary: The set of answers a model can reach given its current parameters and sampling; used to assess whether reasoning unlocks otherwise unreachable answers. Example: "We probe the model's parametric recall capability boundary using the pass@ metric"
- Chain-of-Thought: A step-by-step intermediate reasoning trace generated before the final answer. Example: "Reasoning LLMs (R-LLMs) are trained to generate a long Chain-of-Thought with a step-by-step solution before predicting the final response"
- Closed-book QA: Question answering without access to external tools or retrieval; answers must come from the model’s internal (parametric) knowledge. Example: "Pass@ curves across two closed-book QA benchmarks and three LLMs, comparing the same models with reasoning OFF vs ON."
- Computational buffer effect: The idea that extra reasoning tokens provide time/space for hidden computation, improving answers regardless of the trace’s content. Example: "a computational buffer effect, where the model uses the generated reasoning tokens to perform latent computation independent of their semantic content"
- Control tokens: Special tokens or instructions that switch a model’s inference behavior (e.g., reasoning ON/OFF). Example: "trained to recognize control tokens or system instructions dictating the inference mode"
- Factual priming: Generating related facts to semantically bridge from the question to the correct answer. Example: "factual priming, where generating topically related facts acts as a semantic bridge that facilitates correct answer retrieval."
- Generative self-retrieval: The model’s behavior of recalling related facts it has stored to guide itself toward the answer. Example: "the model engages in generative self-retrieval, constructing contextual bridges to the answer by recalling related facts."
- Hallucination: Fabricated or incorrect content generated by the model that is presented as fact. Example: "hallucinating intermediate facts during reasoning increases the likelihood of hallucinations in the final answer."
- Hybrid models: Models supporting both reasoning-enabled (ON) and reasoning-disabled (OFF) inference modes to isolate reasoning effects. Example: "we use hybrid models where reasoning can be toggled ON/OFF"
- Inference-time techniques: Methods applied during generation (not training) to improve results, such as selective sampling or reranking. Example: "prioritized during deployment via inference-time techniques"
- Latent computation: Hidden internal processing the model performs while generating tokens, not explicitly reflected in the text. Example: "R-LLMs can use the generated reasoning tokens to perform latent computation and refine their predictions."
- ON/OFF bias: A potential confound where models perform better simply due to being in reasoning mode, independent of computation length or content. Example: "We next rule out a potential confounder, which we term ON/OFF bias"
- Parametric knowledge: Information encoded in the model’s parameters rather than retrieved externally. Example: "expands the capability boundary of the model's parametric knowledge recall, unlocking correct answers that are otherwise effectively unreachable."
- pass@: The probability that at least one of k sampled answers is correct; used to study capability boundaries. Example: "We use the pass@ metric"
- Process rewards: Training signals that reward desirable intermediate reasoning steps (not just final correctness). Example: "training with process rewards that encourage factually supported intermediate steps."
- Reasoning effectiveness metric Ω: A weighted summary measure comparing pass@ with reasoning ON vs OFF across k, emphasizing larger k. Example: "we define a unified reasoning effectiveness metric that accounts for the entire range of values."
- Reasoning LLMs (R-LLMs): LLMs trained to produce explicit reasoning (e.g., Chain-of-Thought) before answers. Example: "Reasoning LLMs (R-LLMs) are trained to generate a long Chain-of-Thought with a step-by-step solution before predicting the final response"
- Search-enabled verification: Validating facts using an LLM with web search access to check correctness. Example: "evaluated via a dedicated, search-enabled verification call to Gemini-2.5-Flash"
- Single-hop: Questions answerable with one direct fact or step, without multi-step reasoning. Example: "simple, single-hop factual questions"
- Spreading activation: A cognitive mechanism where activating a concept primes related concepts, facilitating retrieval. Example: "processing a concept spreads ``activation'' through a semantic network, priming related neighbors by lowering the threshold for their retrieval"
- Test-time selection: Choosing among sampled reasoning traces/answers at inference to improve final accuracy. Example: "we adopt a test-time selection strategy to probe the gains implied by our findings."
- Temperature: A sampling parameter controlling randomness in token selection; higher means more diversity. Example: "setting temperature to "
- Top-k: Sampling from only the k most probable tokens at each step. Example: "top-"
- Top-p: Nucleus sampling from the smallest set of tokens whose cumulative probability exceeds p. Example: "top-"
- Unbiased estimation method: A statistically unbiased procedure to estimate pass@ from finite samples. Example: "We use the unbiased estimation method from \citet{chen2021evaluating}."
Collections
Sign up for free to add this paper to one or more collections.