Cross-Hand Latent Representation for Vision-Language-Action Models
Abstract: Dexterous manipulation is essential for real-world robot autonomy, mirroring the central role of human hand coordination in daily activity. Humans rely on rich multimodal perception--vision, sound, and language-guided intent--to perform dexterous actions, motivating vision-based, language-conditioned manipulation systems for robots. However, training reliable vision-language-action (VLA) models for dexterous manipulation requires large-scale demonstrations across many robotic hands. In addition, as new dexterous embodiments appear rapidly, collecting data for each becomes costly and impractical, creating a need for scalable cross-embodiment learning. We introduce XL-VLA, a vision-language-action framework integrated with a unified latent action space shared across diverse dexterous hands. This embodiment-invariant latent space is directly pluggable into standard VLA architectures, enabling seamless cross-embodiment training and efficient reuse of both existing and newly collected data. Experimental results demonstrate that XL-VLA consistently outperforms baseline VLA models operating in raw joint spaces, establishing it as an effective solution for scalable cross-embodiment dexterous manipulation.













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Robots with fingers (robot hands) are getting better, but teaching them to handle everyday objects is hard—especially because every robot hand is built a little differently. This paper introduces XL-VLA, a system that lets different robot hands “speak” the same action language. It helps robots see a scene, understand a text instruction, and move their fingers correctly—even if the robot hand changes.
Think of it like teaching several musical instruments to play the same song from one sheet of music. The instruments are different (piano vs. guitar), but the notes (the “action language”) mean the same thing to each of them.
What questions the researchers asked
The authors focused on two practical questions:
- Can we create one shared “action code” that works across many different robot hands?
- If we have that shared code, can a single vision-and-LLM use it to control any of those hands without retraining from scratch?
How they did it (approach explained with analogies)
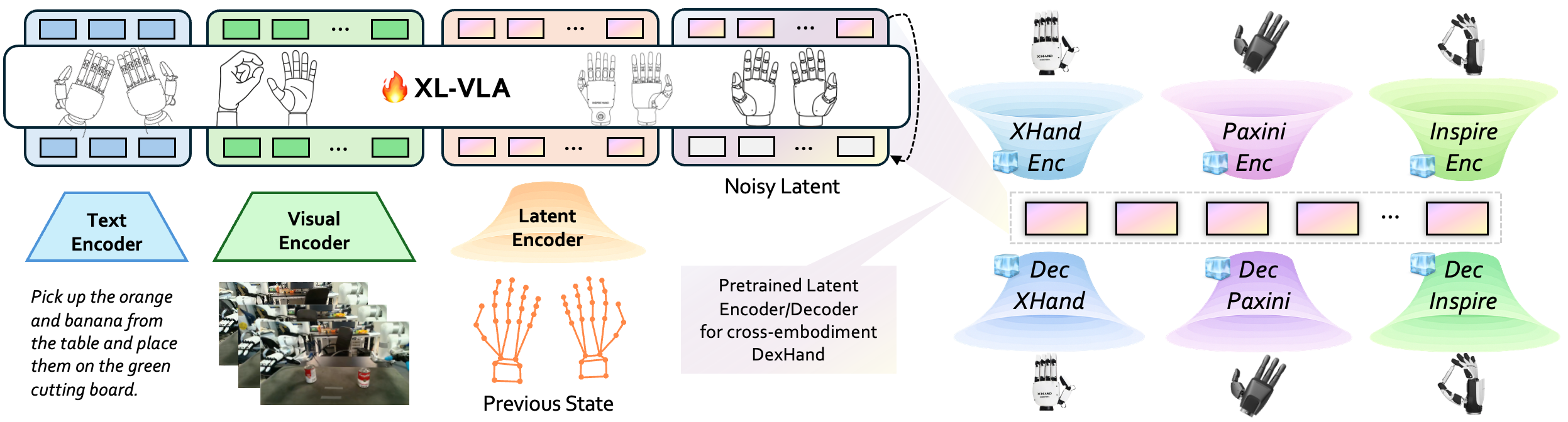
The system has two main parts:
- A shared “action code” for hands
- The team invented a compact, hand-agnostic code (called a “latent space”).
- Imagine compressing a hand pose/motion into a small, universal shorthand—like shrinking a video into a short, meaningful emoji string that any phone can decode.
- Each robot hand has:
- An encoder: turns its joint positions into the shared code (compression).
- A decoder: turns the shared code back into that hand’s joint positions (decompression).
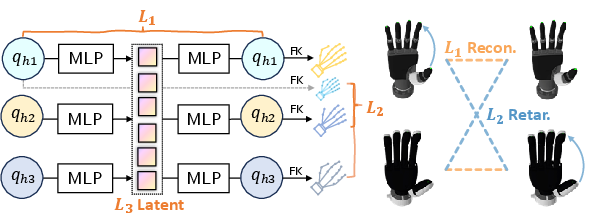
- To make the shared code truly universal, they trained it with three ideas:
- Reconstruction: the decoder should faithfully rebuild the original hand pose.
- Fingertip alignment: the same code should lead to similar finger-tip relationships (like thumb–index pinch distance and direction) across different hands. This uses math that maps joint angles to fingertip positions, similar to predicting where your fingertips are when you bend your knuckles.
- Smoothness: the code should be well-behaved and continuous, so small changes in code make small, smooth changes in hand pose.
Importantly, this part is trained without special paired data. They don’t need matching examples of the exact same pose on every hand. They just sample many safe joint poses for each hand and align fingertip geometry across hands in a self-supervised way.
- A vision–language–action model (the “brain”)
- This model looks at camera images and reads a text instruction (like “stack the cans”).
- Instead of predicting raw finger joint angles directly, it predicts the shared action code.
- Then, the code is decoded into movements for whichever robot hand you’re using.
- This lets one model control many different hands, because the model’s “language” is the shared code, and each hand knows how to translate that code into its own motions.
A small practical detail: the model predicts short chunks of motion (a few seconds at a time), like planning a small dance move rather than the whole routine at once.
What they found and why it matters
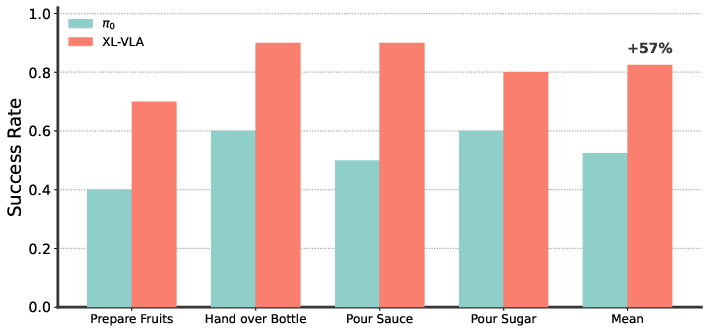
They tested on 10 real-world tasks like handing over a bottle, stacking cans, pushing objects together, and pouring. They used four different robot hands (Ability, Paxini DexH13, X-Hand1, and Inspire), collecting thousands of demonstrations and millions of data points.
Key results show that:
- The XL-VLA approach beat a strong baseline that tried to operate directly in each hand’s raw joint space.
- Success rates improved clearly and consistently across all tasks and all hands. In simple terms, the robots completed more tasks correctly and more reliably.
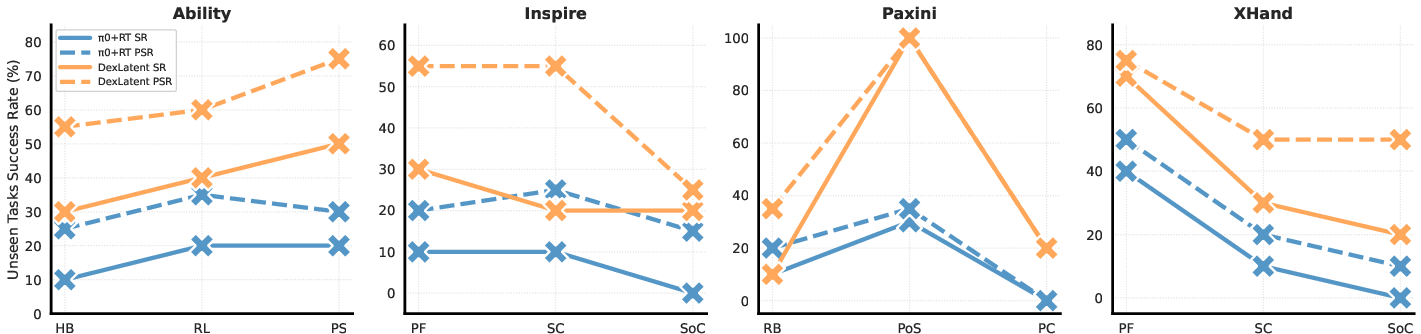
- The system showed “zero-shot” generalization: it could work on new combinations of tasks and hands it hadn’t seen during training—without extra fine-tuning. This is like a student successfully playing a new song on a new instrument after learning the general music language.
- Compared to a popular “retargeting” method (copying motions from one hand to another), the shared code produced smoother, more coordinated finger behavior and fewer failures.
- They also tested mixing data from different robot bodies (like a tabletop arm and a humanoid), and the shared code still helped, making training simpler and more effective.
Why this is important:
- Collecting custom data for every new robot hand is slow and expensive. A shared action code lets you reuse old data on new hands.
- Builders can swap in new hands without redesigning the entire learning system.
- Robots can learn faster and adapt better, making them more useful in real-world settings.
What this could change going forward
If robots can share the same “action language,” we can:
- Add new robot hands more easily, without starting from scratch.
- Train one model that works with many types of hands, making learning cheaper and more scalable.
- Build robots that handle delicate, everyday tasks—like cooking, sorting, and organizing—more reliably, even as hardware evolves.
In short, XL-VLA moves robotics closer to a future where different robot hands can learn from each other and work with the same smart brain, making dexterous manipulation more practical in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Temporal latent ambiguity: the pipeline encodes 64-step action chunks into a single latent token, but the latent autoencoder is described over single joint configurations. It is unclear whether the latent space models sequence dynamics. Evaluate a sequence-aware latent (e.g., temporal VAE/transformer) and quantify the benefit for dynamic manipulation.
- Open-loop chunking and reactivity: predicting 3.2 s action chunks at 20 Hz may reduce responsiveness to unexpected events. Assess interruptibility, mid-chunk replanning, and control latency; compare shorter chunks or receding-horizon updates.
- Unseen-embodiment generalization not demonstrated: “zero-shot” results are for unseen task–hand combinations among trained hands. Validate onboarding of a truly new hand unseen during VLA training by training only its encoder/decoder and measuring sample complexity, performance, and whether the VLA can remain frozen.
- Manual morphology alignment: finger correspondences are hand-labeled and Paxini’s missing digit is dropped. Develop automated, morphology-agnostic alignment (e.g., mesh- or skeleton-based registration, graph matching) to handle different digit counts and non-anthropomorphic hands.
- Limited geometric alignment signal: the retargeting loss uses only thumb–finger pair distances and directions (pinch geometry). Extend constraints to multi-finger coordination, inter-finger distances, surface normals, palm pose, and grasp wrench metrics to cover non-pinch and palm-mediated contacts.
- Physical feasibility during latent pretraining: sampling random joint configurations within limits ignores self-collisions, tendon couplings, contact feasibility, and joint effort limits. Incorporate collision checking, tendon/underactuation constraints, and contact-aware sampling or simulation rollouts.
- Kinematic model dependence: FK-based losses assume accurate hand calibration. Quantify sensitivity to kinematic errors and propose self-calibration or learning-based FK to improve robustness.
- Underactuation and mimic joints: the decoders do not explicitly enforce hand-specific coupling/mimic constraints. Evaluate constraint violations at execution time and integrate structure-preserving decoders or constrained decoding.
- Missing proprioception/tactile feedback: the policy conditions on images, language, and previous action chunks instead of rich proprioception and contact signals. Test adding joint/velocity/effort/tactile inputs and measure gains on contact-rich tasks.
- Dynamics and control mode: actions are absolute joint positions; torque/velocity control and dynamic behaviors (e.g., in-hand reorientation, fast regrasp) are not explored. Investigate dynamics-aware latents and control modes beyond position.
- Functional transfer vs. geometric executability: the latent replay metric focuses on collision-free executability, not task success. Evaluate cross-hand transfer on actual task completion and object-level outcomes.
- Dataset scale clarity: the abstract cites 2M state–action pairs while experiments mention 2,000 demonstrations. Clarify dataset composition (per-hand, per-task, per-frame counts) and provide scaling analyses linking data volume to performance.
- Task diversity limits: evaluation covers 10 tabletop tasks with a fixed set of objects; few in-hand dexterous skills are probed. Test generalization to unseen objects, clutter, lighting changes, and truly dexterous in-hand manipulation (finger gaiting, rolling, regrasp).
- Arm–hand coupling: the latent is hand-centric; cross-robot results confound arm, hand, and camera differences. Develop hierarchical latents coupling arms and hands, and ablate the effect of arm embodiment changes independently.
- Camera/viewpoint robustness: the method’s sensitivity to camera placement, calibration, and occlusions is not reported. Evaluate multi-view, egocentric, and changing viewpoints; assess domain randomization or visual augmentation.
- Language robustness: instruction variability, compositional generalization, and multi-step language grounding are not tested. Benchmark with paraphrases, longer instructions, and compositional tasks.
- Encoder/decoder freezing: encoders/decoders are frozen during VLA finetuning. Study whether joint finetuning improves performance or harms cross-embodiment invariance; identify when and how to adapt without overfitting.
- Latent prior choice: only a standard Gaussian prior is used. Explore alternative priors (e.g., VAMP, normalizing flows, β-VAE variants) for better structure, disentanglement, and interpolation fidelity.
- Safety and failure analysis: systematic reporting of self-collisions, joint limit hits, and recovery behavior is missing. Quantify safety events and integrate safety-aware objectives or shields during decoding and control.
- Real-time performance: inference speed, end-to-end latency, and hardware footprint at deployment are not provided. Report control-loop timing, throughput on typical robot PCs, and scaling with number of embodiments.
- New-hand onboarding protocol: no concrete procedure or resource estimate (data minutes, calibration steps, initialization from CAD) is given for adding a new hand. Define a standardized onboarding pipeline and benchmark its cost–performance trade-offs.
- Object-aware latents: the latent space is action-only and not conditioned on object geometry/pose. Investigate object-conditioned latents (e.g., via scene descriptors or affordance features) to improve cross-hand grasp transfer and contact placement.
Practical Applications
Below is a concise mapping from the paper’s findings and methods to practical applications. Each item names the use case, the primary sector(s), what tools/products/workflows could emerge, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Cross-embodiment policy reuse for mixed robot fleets (Robotics, Manufacturing, Logistics)
- Use case: Train a single VLA manipulation policy once and deploy it across stations/end-effectors that have different dexterous hands (e.g., Ability, Inspire, Paxini DexH13, X-Hand1), for tasks like pick-place, stacking, pushing, pouring, and handovers.
- Tools/products/workflows: “Latent Action Adapter” SDK that ships per-hand encoder/decoder; a deployment pipeline that selects the correct decoder at runtime; CI validation with reconstruction/tip RMSE tests from the paper.
- Assumptions/dependencies: Accurate per-hand kinematic model/URDF and joint limits for differentiable FK; camera setup and language interfaces; joint-position control interface; safety interlocks and collision checking.
- Faster bring-up for new dexterous hands (Robotics OEMs, System Integrators)
- Use case: Add a new hand without collecting large, paired demonstrations—pretrain its encoder/decoder using only joint-limit sampling and FK; immediately reuse existing task data and policies.
- Tools/products/workflows: Vendor-provided “decoder pack” generated from the hand’s URDF; automatic test suite using the paper’s L1/L2/L3 metrics to certify readiness.
- Assumptions/dependencies: Reliable FK and finger index alignment across hands; coverage of joint ranges; calibration to real hardware.
- Latent retargeting and replay of demonstrations across hands (Research, R&D labs)
- Use case: Teleoperate or record on one hand and replay the trajectory on another using latent encoding/decoding, for data augmentation or cross-platform evaluation.
- Tools/products/workflows: “Latent Replay” tool that batch-encodes demos and decodes them to a target hand with automated failure checks (self-collision/contact breaks).
- Assumptions/dependencies: Realistic joint limits and hardware guards; tasks not overly dependent on fingertip-specific contact dynamics (no tactile modeling yet).
- Unified manipulation across robot forms (Humanoids + Tabletop arms) (Robotics, Service Robotics)
- Use case: Share manipulation skills between humanoids (e.g., Unitree G1) and arm-based stations via the same latent space to standardize training and deployment.
- Tools/products/workflows: Cross-robot training orchestrator that merges datasets and runs a single XL-VLA model with appropriate per-hand decoders.
- Assumptions/dependencies: Camera placements and control rates compatible with the chunked action interface (64 steps at 20 Hz); consistent task perception cues across platforms.
- Language-guided workcell operators (Manufacturing, Warehousing)
- Use case: Supervisors specify tasks in natural language (e.g., “Pour sauce into can,” “Stack cans”) and the same policy executes on whichever hand is installed at the station.
- Tools/products/workflows: Operator console with language prompts; status dashboards showing task execution and embodiment used.
- Assumptions/dependencies: VLM backbone fine-tuned on in-domain images/instructions; reliable perception in the facility lighting and object set.
- Rapid prototyping/education across heterogeneous lab hardware (Academia, Education)
- Use case: Students/researchers run the same manipulation assignments on different hands without rewriting control code; cross-embodiment benchmarks.
- Tools/products/workflows: Course kits with prebuilt per-hand encoders/decoders; evaluation scripts using the ablation metrics (joint/tip RMSE, pinch dir./dist. error).
- Assumptions/dependencies: Access to pretrained XL-VLA weights or small-scale fine-tuning compute; standardized camera rigs.
- Cloud policy serving with on-site embodiment adapters (Cloud Robotics, MLOps)
- Use case: Host one XL-VLA model in the cloud and push only lightweight decoders to sites; swap hands on the floor without retraining the central policy.
- Tools/products/workflows: Fleet manager that records per-site decoder versions; rollout gates using latent continuity/interpolation smoothness checks.
- Assumptions/dependencies: Low-latency networking or robust on-edge fallback; versioned URDFs and calibration data.
- Skill sharing marketplaces (Software, Robotics Integrations)
- Use case: Distribute “skill packs” (latent policies for tasks) that decode to any supported hand; integrators pick skills and deploy to their fleet.
- Tools/products/workflows: Registry of latent-compliant decoders; certification badges based on the paper’s cross-embodiment metrics.
- Assumptions/dependencies: Agreement on “latent API” versioning; vendor participation in providing encoders/decoders.
- QA and acceptance testing for new end-effectors (Robotics QA)
- Use case: Before production deployment, run synthetic tests using the paper’s metrics (reconstruction, pinch direction/distance, latent continuity) to assess cross-embodiment fidelity.
- Tools/products/workflows: Automated lab bench that sweeps joint samples, computes FK, and reports pass/fail thresholds per metric.
- Assumptions/dependencies: Accurate FK and consistent finger mapping; reliable joint limit enforcement.
- Home-assistant tasks with upgradeable hands (Consumer Robotics, Daily Life)
- Use case: Kitchen tasks (stacking, pouring, pushing) controlled by language; swapping or upgrading hands without retraining.
- Tools/products/workflows: Home robot with standard camera(s), a local decoder, and language UI; “plug-and-play” hand modules.
- Assumptions/dependencies: Safety layers for contact and spill management; robustness to household clutter and lighting; privacy-compliant LLMs.
Long-Term Applications
- Standardized “DexHand Latent API” across vendors (Policy, Industry Standards)
- Use case: Industry consortia define a common latent space and certification tests so policies and hands interoperate seamlessly across brands.
- Tools/products/workflows: Open benchmarks; compliance test suites using L1/L2/L3; versioned latent specifications.
- Assumptions/dependencies: Broad vendor agreement; governance for evolving the latent spec.
- Cross-embodiment general-purpose manipulation beyond hands (Robotics, Multi-embodiment AI)
- Use case: Extend the shared latent to other end-effectors and tool-changers (e.g., multi-finger, suction, specialized grippers) and even beyond manipulators (mobile bases).
- Tools/products/workflows: Multi-headed encoders/decoders per effector class; task-conditional latent segments for tool use.
- Assumptions/dependencies: New alignment objectives analogous to fingertip geometry for disparate effectors; safety validation.
- Assistive robotics and prosthetics with embodiment-agnostic control (Healthcare)
- Use case: Map user intent (e.g., EMG, gaze, speech) into a shared latent that decodes to different prosthetic hands or assistive devices, enabling easier device upgrades or replacements.
- Tools/products/workflows: Intent-to-latent inference module; clinical calibration via FK-based objectives and task trials.
- Assumptions/dependencies: Medical-grade safety and reliability; integration of tactile/force sensing; regulatory approvals.
- Tactile-rich contact reasoning in the latent space (Robotics)
- Use case: Incorporate tactile and force signals to improve contact-heavy tasks (e.g., cutting, lid opening), making cross-hand transfer more reliable.
- Tools/products/workflows: Multimodal encoders that fuse vision, language, proprioception, and tactile; new losses aligning contact wrenches across hands.
- Assumptions/dependencies: Standardized tactile hardware or sim-to-real transfer; richer datasets.
- Auto-adaptation to novel hands with minimal information (Auto-Calibration)
- Use case: For a new hand with incomplete kinematic data, learn the decoder online from a short, safe calibration routine using self-supervision and perception.
- Tools/products/workflows: On-robot self-exploration with safety envelopes; Bayesian or meta-learning for fast decoder fitting.
- Assumptions/dependencies: Safe exploration frameworks; modest operator oversight.
- Skill composability and hierarchical planning in latent space (Software, AI Planning)
- Use case: Compose complex, long-horizon tasks by sequencing latent “chunks” learned across embodiments; combine pouring, handovers, and arranging without rewriting per-hand controllers.
- Tools/products/workflows: Latent-level task graph planners; verification via interpolation smoothness and jerk constraints.
- Assumptions/dependencies: Larger datasets for multi-step tasks; robust perception-language grounding.
- Sim-to-real at scale via latent alignment (Robotics, Simulation)
- Use case: Train skills extensively in simulation across synthetic hand models and transfer to real hands using the same latent decoder interface.
- Tools/products/workflows: Sim generator that randomizes kinematics within a family and enforces FK-based retargeting objectives; domain randomization pipelines.
- Assumptions/dependencies: High-fidelity simulation of kinematics and contacts; bridging sim-real perception gaps.
- Regulatory procurement and anti–vendor-lock-in policies (Policy, Public Sector)
- Use case: Public tenders specify latent-API compliance to ensure interchangeable hands/end-effectors and future upgrades without retraining core policies.
- Tools/products/workflows: Procurement checklists referencing latent tests (e.g., pinch direction/distance errors under thresholds); audit trails.
- Assumptions/dependencies: Mature standard and third-party conformance testing.
- Personalized home/enterprise robots with modular manipulation packs (Daily Life, Enterprise)
- Use case: Users purchase “task packs” (e.g., kitchen pack, office pack) that work with any compliant hand; robots upgrade hardware without losing skills.
- Tools/products/workflows: App store for latent-compliant tasks; subscription-based updates.
- Assumptions/dependencies: Stable latent spec; safe deployment infrastructure at scale.
- Collaborative multi-robot ecosystems (Robotics, Warehousing)
- Use case: Different robots with different hands share and hand off tasks fluidly (e.g., one robot pours, another arranges), coordinated in the same latent action space.
- Tools/products/workflows: Multi-robot schedulers operating in latent-space task primitives; shared perception and language coordination.
- Assumptions/dependencies: Reliable cross-robot calibration; safety and timing guarantees in shared workcells.
Notes on feasibility constraints common across applications:
- The method assumes access to accurate robot hand kinematics and fingertip indexing for the retargeting loss. Missing digits (e.g., Paxini lacks a little finger) require special handling.
- The VLA backbone needs in-domain visual data and language instructions; camera calibration and robust perception are prerequisites.
- No tactile sensing is used in the current results; contact-rich tasks may require extensions for stability and safety.
- Training at scale may require substantial compute (authors used 8× H100 GPUs), although per-hand encoder/decoder training is lightweight.
- Safety and compliance (collision avoidance, joint-limit enforcement, fail-safes) must wrap around the latent decoder for real-world deployment.
Glossary
- Action chunk: A fixed-length sequence of joint-position commands grouped for prediction or execution. "At the policy level we operate on action chunks:"
- Action expert: A submodule specialized in predicting actions from encoded inputs. "paired with an action expert that operates in a shared latent action space for cross-embodiment control."
- Actuation: The mechanism by which joints are driven, affecting dynamics and control. "substantial kinematic and actuation differences across hands."
- Autoencoder: A neural network that encodes inputs into a latent representation and decodes them to reconstruct the original. "We propose an unsupervised latent autoencoder framework that learns a unified action space applicable to a wide range of hands."
- Bimanual: Using or involving two hands or arms simultaneously. "We use a bimanual 7-DoF xArm and a Unitree G1 humanoid..."
- Cross-embodiment: Operating a single policy across different robot bodies without per-robot retraining. "Cross embodiment typically refers to learning a single policy that can flexibly adapt across diverse embodimentsâe.g., different humanoids or dexterous handsâwithout per-robot retraining"
- Decoder: A network that maps latent codes back to embodiment-specific joint actions. "the pretrained latent encoders and decoders remain frozen."
- Dexterous manipulation: Fine-grained multi-fingered control of objects. "Dexterous manipulation is essential for real-world robot autonomy, mirroring the central role of human hand coordination in daily activity."
- DoF (degrees of freedom): The number of independent joint motions. "We use a bimanual 7-DoF xArm and a Unitree G1 humanoid..."
- Embodiment: The specific physical robot configuration for which actions are defined. "as new dexterous embodiments appear rapidly"
- Embodiment-invariant latent space: A shared representation designed to not depend on robot-specific morphology. "This embodiment-invariant latent space is directly pluggable into standard VLA architectures"
- Encoder: A network that maps raw actions or states into a lower-dimensional latent representation. "the pretrained latent encoders and decoders remain frozen."
- End-effector (EEF): The tool or hand at the end of a robot arm that interacts with the environment. "Deployment specifies the robot embodiments evaluated and whether crossâend-effector transfer is supported."
- End-effector latents: Latent variables that parameterize the pose or motion of the robot's end-effector. "continuous end-effector latents trained on retargeted pairs and generated by diffusion"
- Forward kinematics (FK): The mapping from joint angles to fingertip or end-effector positions via the robot’s kinematic model. "we use differentiable forward kinematics (FK) to map joints to fingertip positions"
- Gaussian prior: A normal distribution used as a regularizing prior over latent variables. "by imposing a standard Gaussian prior on the latent variables."
- Gaussian posterior: The distribution over latents conditioned on inputs, parameterized by an encoder. "The encoder outputs the parameters of a Gaussian posterior"
- Jerk: The time derivative of acceleration, used to assess motion smoothness. "Interp. Accel./Jerk Mean"
- KL regularization: A Kullback–Leibler divergence penalty encouraging latents to follow a chosen prior. "The full latent training loss combines reconstruction, retargeting, and KL regularization:"
- Kinematics: The geometric relations of robot joints and links, independent of dynamics. "Despite differing kinematics, all hands produce consistent poses from the same latent code"
- Latent action space: A compact, shared representation in which actions are encoded for cross-robot transfer. "a unified latent action space shared across diverse dexterous hands."
- Latent manifold: The low-dimensional space structure in which latent codes lie. "This architecture provides a unified latent manifold while preserving the structure of each embodiment."
- Latent regularization: Constraints on latents to enforce smoothness or distributional properties. "latent regularization loss ."
- Latent tokens: Compact representations of actions fed into sequence models instead of raw states. "In XL-VLA we instead feed latent action tokens:"
- Morphology: The physical structure and layout of a robot, influencing its action space. "robotic action spaces are inherently tied to the morphology of the robot."
- Multimodal: Combining multiple data modalities (e.g., vision, language) within a model. "a VLA backbone that encodes multimodal inputs "
- Pinch behaviors: Coordinated thumb–finger motions used for grasping and precision manipulation. "This loss encourages the same latent code to produce geometrically consistent pinch behaviors across different hands."
- Proprioception: Internal sensing of joint states and positions used as an input modality. "Input denotes which modalities (vision, language, proprioception) are used for training."
- Reparameterization trick: A sampling method enabling backpropagation through stochastic latent variables. "using the reparameterization trick"
- Retargeting loss: A loss term aligning geometry across embodiments by penalizing fingertip discrepancies. "Retargeting Loss ()."
- Sequence-to-sequence modeling: Predicting outputs as sequences conditioned on input sequences. "unifying vision and language can be naturally expressed through sequence-to-sequence modeling"
- Sim-to-real: Transferring policies trained in simulation to physical robots. "simulation (sim\,\,real)"
- Teleoperation: Human-controlled operation used to collect demonstrations for training. "We collect a large-scale teleoperation dataset"
- VAE (variational autoencoder): A probabilistic autoencoder using a latent prior and KL loss. "we employ a multi-headed VAE-style autoencoder."
- Vision-LLM (VLM): A model that jointly processes images and text. "VLA models adapt large visionâLLMs (VLMs) to robot control"
- Vision-Language-Action (VLA) model: A model that integrates vision and language to predict robot actions. "We introduce XL-VLA, a vision-language-action framework integrated with a unified latent action space"
- Zero-shot: Generalizing to new tasks or embodiments without additional training. "zero-shot transfer to unseen embodiments."
Collections
Sign up for free to add this paper to one or more collections.