- The paper introduces a modular, unified ASR pipeline integrating VAD, LID, ASR, and punctuation modules for robust, real-world speech recognition.
- The approach leverages expanded training data (from 70k to ~200k hours) and advanced tokenization within Conformer-based architectures to enhance transcription and timestamp accuracy.
- Empirical evaluations show superior performance over competitive baselines across Mandarin, dialects, and singing, supporting downstream tasks like subtitle generation and NLP.
FireRedASR2S: An Integrated Industrial-Grade All-in-One Automatic Speech Recognition System
System Architecture and Modular Pipeline
FireRedASR2S is introduced as a modular, unified pipeline integrating four major speech processing components: Voice Activity Detection (FireRedVAD), Spoken Language Identification (FireRedLID), Automatic Speech Recognition (FireRedASR2), and Punctuation Prediction (FireRedPunc). The system architecture is specifically designed for robustness in real-world deployments, targeting scenarios involving long-form audio, multilingual and code-switched speech, background acoustic events, singing, and diverse Chinese dialects.
FireRedASR2S processes raw waveforms sequentially, leveraging FireRedVAD for segmentation, FireRedLID for language/dialect identification, FireRedASR2 for transcription (with confidence scores and timestamps), and FireRedPunc for punctuation restoration. Each module maintains compatibility for standalone deployment, while the unified pipeline produces structured, annotated transcription outputs with precise temporal and confidence information, essential for downstream tasks such as subtitle generation and machine translation.

Figure 1: FireRedASR2S sequential pipeline from waveform input to structured transcription output with integrated VAD, LID, ASR, and punctuation modules.
Automatic Speech Recognition Module
FireRedASR2, the core ASR module, is instantiated in two major variants: FireRedASR2-AED (Attention-based Encoder-Decoder) and FireRedASR2-LLM (Encoder-Adapter-LLM). Both utilize end-to-end architectures with Conformer-based encoders and differ in their decoder strategies. Notable advancements over previous generations include:
- Substantial expansion of training data: From 70k to ∼200k hours, encompassing Mandarin, English, code-switching, dialects, and singing.
- Tokenization enhancements: Mixed-token strategy with a vocabulary of 8,667, optimizing both Mandarin and English tasks.
- Timestamp support in AED: Post-hoc CTC projection branch allows reliable token/word timestamp computation, aligning encoder outputs with transcription tokens for precise timing.
Confidence scores for utterances are derived from aggregated token-level posteriors, with heuristic refinements enhancing practical reliability. The LLM-based variant (FireRedASR2-LLM) uses a lightweight adapter mapping encoder outputs to a pretrained text LLM's embedding space, supporting parameter-efficient adaptation and facilitating LLM-style prompt formatting.
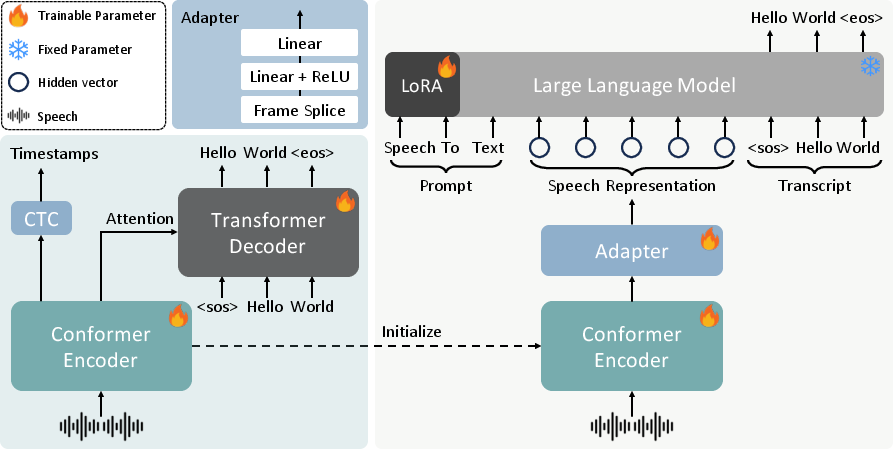
Figure 2: Comparative architecture of FireRedASR2-AED and FireRedASR2-LLM end-to-end models with Adapter for LLM integration.
Voice Activity Detection and Event Segmentation
FireRedVAD employs Deep Feedforward Sequential Memory Network (DFSMN) architectures, notably compact (0.6M parameters), for streaming/non-streaming VAD and multi-label event detection (speech, singing, music). Training leverages thousands of hours of meticulously human-annotated acoustic event data, avoiding weaknesses in models relying on forced-alignment. The mVAD variant performs parallel frame-level multi-label classification. Deterministic post-processing enforces minimum segment constraints, merges/refines boundaries, and ensures robust segmentation suitable for ASR deployment.
Hierarchical Multilingual and Dialect Identification
FireRedLID advances hierarchical label prediction using Conformer-Transformer sequence models. The label space is structured with a two-level token prediction: initial language identification (100+ languages), followed (where applicable) by Chinese dialect identification (20+ dialects grouped into 8 clusters). The encoder is initialized from pretrained FireRedASR2-AED weights, harnessing substantial representation learning from large-scale speech recognition data. Training employs cross-entropy sequence loss with teacher forcing. The compact label sequence design addresses ambiguity and realizes efficient, low-latency inference.
Punctuation Prediction for Chinese and English
FireRedPunc utilizes a BERT-style encoder (pretrained LERT) with a token-level classifier for restoration of the four most frequent punctuation marks (, . ? !). Training covers 18.57B Chinese and 2.20B English tokens from multi-domain corpora. The inference pipeline inserts predicted punctuation tokens directly into ASR outputs, optimizing readability and supporting further downstream NLP integration.
Empirical Evaluation and Strong Numerical Results
ASR
On 24 public test sets (Mandarin, dialects, singing), FireRedASR2-LLM achieves 2.89% average CER across Mandarin benchmarks and 11.55% on dialects—outperforming all major commercial and open-source baselines, including Doubao-ASR, Qwen3-ASR, and Fun-ASR. AED variant offers a competitive accuracy-efficiency trade-off.
VAD
On FLEURS-VAD-102 (102 languages), FireRedVAD achieves 99.60% AUC-ROC and 97.57% F1, surpassing Silero-VAD, TEN-VAD, and FunASR-VAD, with remarkably low false alarm and miss rates.
LID
Multilingual utterance-level accuracy exceeds 97% on FLEURS, with substantial superiority over Whisper and SpeechBrain. Chinese dialect accuracy reaches 88.47%, demonstrating effectiveness in fine-grained dialect identification.
Punctuation
FireRedPunc yields 82.96% F1 on Chinese, 74.83% F1 on English, and an aggregated 78.90% F1, significantly exceeding FunASR-Punc.
Practical and Theoretical Implications
The FireRedASR2S system underscores the efficacy of modular pipelines with clean interfaces, supporting scalable, reproducible deployment across varied acoustic domains. The central design decision—scaling supervised data diversity—proves critical for robust ASR and dialect generalization, advocating a shift from architectural tweaks toward data-centric optimization for industrial ASR.
Human-annotated event supervision for VAD/mVAD substantiates gains in segmentation reliability under adverse conditions, aligning with the practical requirements of processing user-generated and heterogeneous content.
Hierarchical token-level LID paves the way for nuanced multilingual routing and dialect tagging, providing a template for future low-latency, fine-grained language processing.
Punctuation prediction with pretrained encoders and broad-domain corpora yields translation-quality outputs, making ASR outputs directly amenable for cross-modal and downstream NLP tasks.
Speculation on Future Developments
FireRedASR2S opens avenues for further scaling in both model size and training data; leveraging instruction-tuned and in-context learning paradigms with LLMs will likely amplify cross-lingual and domain-adaptive capability. Expansion to more languages and dialects, integration of LLM-based contextual adaptation, and refinement of timestamp precision for multimodal applications are anticipated. The alignment of modularity with unified, open-source deployment will remain instrumental for both practical and research advancement in automatic speech understanding.
Conclusion
FireRedASR2S sets a formal reference for industrial-grade, integrated speech recognition pipelines. Its SOTA module performance across ASR, VAD, LID, and punctuation prediction underscores both the theoretical rigor and practical utility of large-scale supervised data, modularity, and hierarchical modeling strategies. The system is released as open-source, facilitating further research and deployment. Ongoing work will target broader language/dialect coverage, enhanced timestamping, and deeper integration with LLMs and speech foundation models.