VIBEVOICE-ASR Technical Report
Abstract: This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VibeVoice-ASR, a new system that can listen to long audio (like an hour-long meeting or podcast) and write a detailed transcript in one go. It doesn’t just write the words—it also figures out who is speaking and when they spoke, and it works in over 50 languages without needing you to tell it which language is being used. It can even handle people switching languages mid-sentence.
What questions did the researchers ask?
Here are the main goals the team focused on:
- Can we transcribe long recordings (up to 60 minutes) in a single pass instead of cutting them into short chunks?
- Can we combine three tasks—ASR (turning speech to text), speaker diarization (who is speaking), and timestamping (when words are said)—into one unified output?
- Can the system stay accurate across many languages and during code-switching (switching between languages)?
- Can adding a small text prompt (like a list of names or special vocabulary) improve accuracy on tricky terms?
- Can this approach beat strong existing models on real multi-speaker benchmarks?
How does VibeVoice-ASR work?
The big picture
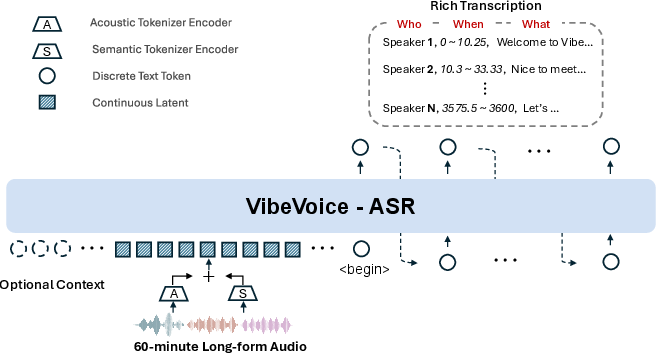
Think of most speech systems like reading a long book by chopping it into many tiny pages, then trying to stitch the pages back together later. That loses the “big picture.” VibeVoice-ASR reads the whole “book” at once. It uses an audio encoder and a LLM to understand the full context, so it keeps track of what was said, who said it, and when.
Handling long audio with “compressed tokens”
Audio is like a fast stream of tiny details. VibeVoice-ASR uses two “tokenizers” (tools that turn audio into compact signals):
- An Acoustic Tokenizer captures how the sound “looks” (pitch, tone, etc.) and compresses audio a lot—down to about 7.5 tokens per second.
- A Semantic Tokenizer captures the meaning of what’s being said.
Because the audio is so compressed, even an hour of sound fits inside the LLM’s memory window. That lets the model understand the entire session at once, which helps avoid confusion and keeps the story consistent.
A “Rich Transcription” output
Instead of only writing plain text, the model generates a structured stream with three parts interleaved:
- “Who” (speaker ID)
- “When” (timestamps)
- “What” (the spoken content)
This means it produces the transcript, the speaker labels, and the timing all in one shot.
Using helpful prompts (context injection)
You can give the system a short prompt with helpful context—like a list of team member names, product codes, or specialized terms. This acts like a cheat sheet, helping the model recognize domain-specific words (for example, medical or legal terms) or words that sound similar but have different meanings.
Making and preparing training data
The team trained and refined the model using:
- High-quality multi-speaker datasets (for conversations) and a music dataset (so the model doesn’t mistake music for speech).
- Synthetic data: they used an advanced AI to write dialogues with tricky names, terms, and code-switching, then generated multi-speaker audio to match. Low-quality samples were filtered out.
- Long-form transcription cleanup: because many old transcripts were created in short chunks, they used an AI refiner to merge and fix them so the long text made sense as a whole.
- Non-speech labeling: segments like Silence, Music, Environmental Sounds, and Unintelligible Speech were tagged so the model wouldn’t “hallucinate” words during noise or silence.
They also gradually trained the LLM to handle longer and longer inputs, increasing its input length from about 8k tokens up to about 65k tokens.
How they evaluated it
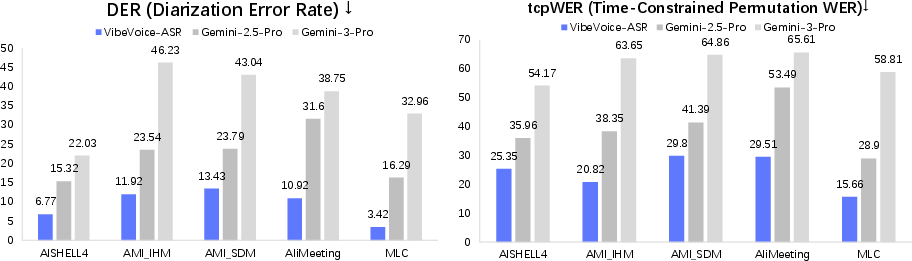
They tested VibeVoice-ASR on public datasets with many speakers in different languages. They measured:
- DER (Diarization Error Rate): how well the model identifies “who spoke when.”
- WER (Word Error Rate): how accurate the words are (ignores who and when).
- cpWER (concatenated min-permutation WER): checks both content and speaker consistency.
- tcpWER (time-constrained min-permutation WER): checks content, speaker consistency, and timing all together.
They compared their model to strong multimodal models and, importantly, ran VibeVoice-ASR on the full audio in one pass.
What did they find?
- The system consistently beat the comparison models on DER and tcpWER across many datasets. In simple terms: it did a better job at keeping track of speakers and aligning words with the correct times.
- On cpWER, it was best in most tests, meaning it kept speaker consistency and content accuracy strong.
- On WER (just word accuracy), it had the lowest error in half the settings and was close on the rest.
- It worked across many languages and handled multi-speaker situations well.
- The prompt-based context feature improved recognition of specialized words and names.
Why is this important?
- Better meeting notes: It can generate clear transcripts that say who spoke and when, even in long meetings.
- More accurate podcasts and lectures: It handles long recordings without splitting them into confusing chunks.
- Fewer systems to glue together: Instead of separate tools for transcription, speaker detection, and timing, you get everything in one output.
- Works across languages and code-switching: Useful for global teams, multilingual podcasts, and classrooms.
- Domain-friendly: With prompts, it can learn your organization’s names, products, and jargon quickly.
Any limitations?
- Multilingual balance: Although it was pre-trained on 50+ languages, later fine-tuning focused mostly on English and Chinese, so performance can drop on languages with less training data.
- Overlapping speech: If two people talk at the same time (like in a busy discussion), the model usually follows the louder speaker and may miss the other. Future versions aim to handle this “cocktail party” problem better.
Knowledge Gaps
Below is a single, consolidated list of knowledge gaps, limitations, and open questions the paper leaves unresolved. Each point is framed to be concrete and actionable for future research.
- Overlapping speech remains unaddressed: the model serializes output and transcribes only the dominant speaker. How to integrate separation-aware modeling (e.g., end-to-end joint source separation + diarization + ASR) and represent parallel utterances in the “Rich Transcription” format is an open design question.
- Multilingual forgetting and coverage: SFT focuses on English/Chinese/code-switching despite pre-training on 50+ languages. The extent of performance drop in low-resource and typologically diverse languages (e.g., morphologically rich, low-resourced scripts) is unquantified; methods for instruction-tuning without catastrophic forgetting across all covered languages are needed.
- Code-switching evaluation gaps: claims of intra- and inter-sentential code-switching support are not backed by benchmarks specifically designed for code-switching (e.g., SEAME, MixIT-style tasks, or realistic bilingual meeting corpora). Quantify performance, error types, and speaker attribution under rapid switches.
- Prompt-based context injection is inadequately characterized: the paper lacks ablations and controlled studies on how prompts (hotwords, background paragraphs) are encoded/positioned, their measurable impact on terminology accuracy, sensitivity to prompt length/order, and failure modes when prompts are wrong, misleading, adversarial, or out-of-domain.
- Non-speech event handling is not evaluated: long-form recordings are annotated with acoustic tags via GPT-Audio, but there is no metric, dataset, or analysis of tag accuracy, nor quantification of hallucination reduction (e.g., false text during [Music]/[Silence]).
- Timestamp representation and evaluation details are missing: the structured “When” output format (granularity, collar parameters, alignment strategy) is unspecified; dedicated word/segment-level timestamp error metrics (beyond tcpWER) and calibration under different collars need reporting.
- Speaker label stability and scalability are unclear: the maximum number of distinct speakers reliably handled, stability of “Speaker ID” assignments across long sessions, and cross-session identity consistency (e.g., linking a person across meetings) are not analyzed.
- Lack of long-form stress testing beyond 60 minutes: although sequence length budget allows longer audio, performance, memory/latency, and accuracy trends beyond 60 minutes (e.g., 90–120 minutes) remain unexplored.
- Single-pass inference efficiency and resource requirements: no reporting of throughput, latency, GPU/CPU memory footprint, or cost compared to pipelined systems; trade-offs between accuracy and compute need quantification for practical deployment.
- Training objective and schema design are under-specified: how the LLM is trained to emit interleaved Who/When/What tokens (special token vocabulary, loss functions, alignment strategies, error handling) is not detailed; ablations on schema variants are needed.
- Dual-tokenizer contribution lacks ablation: the specific gains from acoustic vs semantic tokens, their fusion strategy, and sensitivity to token rate (7.5 Hz) are not isolated; how lower/higher frame rates affect time alignment and content accuracy remains unknown.
- Curriculum for long context lacks justification: increasing sequence length from 8,192 to 65,536 tokens is stated, but no ablation shows its necessity, optimal schedule, or impact on stability and generalization.
- Synthetic data pipeline risks and effects: reliance on GPT-5 for script/context generation and VibeVoice for audio synthesis introduces domain biases; the performance contribution of synthetic vs real data (6,000 hours) and the robustness to synthetic artifacts are not quantified.
- Dependence on pseudo-labels and heuristics in pre-training: diarization clustering thresholds (e.g., HDBSCAN + cosine ≥0.67), VAD segmentation, and Whisper-based transcriptions may propagate label noise. Sensitivity analyses and label-noise robustness studies are missing.
- Global Semantic Rectification via GPT-5 is not reproducible/transparent: the impact of text refinement on final accuracy, potential semantic drift, and replicability using open-source models are unreported.
- Fairness of baseline comparisons: Gemini models are evaluated on 240-second chunks while VibeVoice-ASR uses single-pass. The comparative effect of chunking on DER/timestamps and inclusion of strong open-source pipelined baselines (e.g., WhisperX + pyannote) need thorough, matched evaluations.
- Lack of failure mode analysis: the paper reports superior averages but does not characterize typical errors (e.g., speaker confusions during rapid turn-taking, mis-timestamps at overlaps, domain-specific term misspellings) or challenging acoustic conditions (far-field, heavy noise, accents).
- Real-time/streaming and incremental use cases are not addressed: the single-pass design implies offline processing; strategies for streaming inference with bounded latency and consistent speaker/timestamp updates are an open engineering and modeling question.
- Robustness to environmental variability: device, room acoustics, distance, reverberation, and noise robustness are not systematically benchmarked beyond AMI IHM/SDM; broader real-world mic/channel variations should be tested.
- Music robustness claim is unevaluated: the inclusion of Muse data suggests robustness to music, yet there is no metric or test set measuring false speech during music, speech-vs-music discrimination, or singing/lyrics transcription behavior.
- Safety, bias, and privacy aspects are unexplored: risks of prompt manipulation (prompt injection), demographic/accent biases in diarization and ASR, and privacy concerns around speaker labeling are not discussed or quantified.
- Confidence and calibration are missing: there is no mechanism or evaluation of token/word-level confidence scores, uncertainty quantification, or speaker-attribution confidence—important for downstream editing and quality control.
- Output schema standardization and interoperability: how the Rich Transcription maps to standard formats (RTTM/CTM/JSON) and guarantees compatibility with existing meeting analytics tools is not specified; conversion and validation tools should be provided.
- Reproducibility details are incomplete: key hyperparameters (optimizers beyond Adam, batch sizes, learning rates, training steps), exact LLM backbone variant/config, and data splits for each evaluation dataset are not fully documented, hindering faithful reproduction.
Practical Applications
Overview
Based on the VibeVoice-ASR technical report, the system’s single-pass, long-context, multilingual ASR with integrated diarization, timestamping, and prompt-based context injection enables a wide range of practical deployments. Below are actionable use cases, organized by deployment horizon, with sector links, possible tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Enterprise meeting transcription and analytics (software/productivity)
- Use: Generate hour-long, speaker-attributed, time-aligned transcripts for meetings, all-hands, standups, and design reviews; compute speaker talk-time and participation metrics.
- Tools/workflows: VibeVoice-ASR → Rich Transcription JSON → summarizer/action-item extractor → ticketing/CRM (e.g., Jira, Salesforce).
- Assumptions/dependencies: Quality audio capture; GPU/LLM context to handle ~27k audio tokens; domain vocabulary provided via prompt-based context for best accuracy; privacy controls for sensitive content.
- Earnings calls and investor relations (finance)
- Use: Accurate diarized transcription of earnings calls and analyst Q&A; identify speaker roles (CEO/CFO/analysts) and timestamped quotes for downstream analytics and compliance.
- Tools/workflows: ASR + diarization → structured transcript → financial KPI extraction and sentiment by speaker → searchable archive.
- Assumptions/dependencies: Glossaries for company/product names via context prompts; on-prem/cloud deployment depending on compliance.
- Legal proceedings, depositions, and hearings (legal/policy)
- Use: Create official transcripts with “who said what and when” for court records, public hearings, and regulatory meetings.
- Tools/workflows: Rich Transcription → human review in transcript editor → certified export; diarization supports clear attribution.
- Assumptions/dependencies: High-fidelity audio; human QC for legal-grade accuracy; data governance.
- Call center and customer support analysis (enterprise/telecom)
- Use: Multi-party, long-call transcription with speaker separation (agent vs. customer), time-aligned QA/compliance checks, and domain terminology recognition.
- Tools/workflows: ASR + diarization → QA/compliance rules engine → agent coaching dashboards.
- Assumptions/dependencies: Overlap limitation (dominant speaker bias) may reduce fidelity in crosstalk-heavy calls; hotword lists for product/plan names improve outcomes.
- Podcast and broadcast production (media/entertainment)
- Use: Diarized, timestamped transcripts for chaptering, show notes, clip discovery, and searchable archives; handle multilingual/code-switched content.
- Tools/workflows: VibeVoice-ASR → transcript/timestamps → automatic chapter markers → editor integration (e.g., NLE timelines).
- Assumptions/dependencies: Consistent mic setup for panel shows; post-processing for overlapped banter.
- Lecture capture and educational content indexing (education/edtech)
- Use: Long lecture/Q&A transcription with speaker identities (instructor vs. students), timestamp-aligned notes, and searchable knowledge repositories.
- Tools/workflows: Transcript → topic/quiz generation → LMS integration; segment-level timestamps enable content navigation.
- Assumptions/dependencies: Classroom acoustics; domain terms supplied via context (course glossary); consent/privacy for student speech.
- Accessibility services (cross-sector)
- Use: Time-synced captions for recorded events, talks, and workshops; improved comprehension for hearing-impaired users.
- Tools/workflows: ASR timestamps → live/on-demand caption files (e.g., WebVTT/SRT) with speaker labels.
- Assumptions/dependencies: Primarily offline/near-real-time; human correction for high-stakes accessibility needs.
- Media monitoring and quote attribution (public relations/newsrooms)
- Use: Track who said what in press conferences/panels; auto-extract speaker-attributed quotes with timestamps for verification and publication.
- Tools/workflows: Transcript → named-speaker quote extraction → editorial CMS pipelines.
- Assumptions/dependencies: Consistent speaker separation; identity mapping beyond “Speaker 1/2/3” may require manual labeling.
- Multilingual and code-switching transcription (global operations, public sector)
- Use: Transcribe multilingual meetings, community forums, and public hearings without preset language selection; handle intra-utterance code switching.
- Tools/workflows: End-to-end ASR → language-aware indexing → optional MT for cross-lingual access.
- Assumptions/dependencies: Best performance in languages emphasized during SFT (strongest in English/Chinese); additional fine-tuning may be needed for low-resource languages.
- Compliance logging for regulated industries (finance/healthcare)
- Use: Generate timestamped, diarized records for audits (e.g., MiFID II) and telehealth session documentation.
- Tools/workflows: ASR output → secure storage with retention policies → automated compliance checks.
- Assumptions/dependencies: On-prem or VPC deployments; strong data governance; domain lexicons via prompts (drug names, medical terms).
- Content search and knowledge ingestion (enterprise knowledge management)
- Use: Ingest long-form audio into enterprise search with accurate speaker/time anchors; enable semantic retrieval of spoken content.
- Tools/workflows: ASR → segment embeddings anchored to timestamps → vector search with time-coded previews.
- Assumptions/dependencies: Compute for embedding generation; consistent schema for Rich Transcription.
- Dataset curation and benchmarking (academia)
- Use: Create high-quality, diarization-aware transcripts for new long-form corpora; study code-switching and diarization in the wild.
- Tools/workflows: VibeVoice-ASR + open-source pipelines → gold/silver labels → public benchmarks and SFT for low-resource languages.
- Assumptions/dependencies: Ethical data sourcing; human verification for research-grade datasets.
- Post-production audio cleanup and editing (media/software)
- Use: Quickly locate segments by speaker/time to trim pauses, remove non-speech intervals (explicitly tagged), and create highlight reels.
- Tools/workflows: Non-speech tag-aware cuts → automated editing scripts → export to NLE.
- Assumptions/dependencies: Non-speech tagging quality; workflow integration with editors.
Long-Term Applications
- Real-time/streaming multi-speaker transcription with low latency (enterprise/media)
- Use: Live captioning/analytics for long events with continuous speaker attribution and timestamps.
- Tools/workflows: Incremental decoding with long-context maintenance; streaming summarization/action extraction.
- Assumptions/dependencies: Architectural modifications for streaming; efficient memory management; robust handling of partial contexts.
- Overlapping speech handling (“cocktail party problem”) (call centers, meetings, emergency comms)
- Use: Separate and transcribe simultaneous speakers rather than only the dominant voice.
- Tools/workflows: Separation-aware modeling (e.g., joint source separation + ASR) integrated with Rich Transcription.
- Assumptions/dependencies: New training regimes; multi-channel audio where available; increased compute.
- Speaker identity enrollment and cross-session linking (enterprise/legal)
- Use: Map diarized “Speaker 1/2” to real identities with optional enrollment, maintain identity across meetings/sessions.
- Tools/workflows: Speaker recognition and embedding databases; privacy-preserving identity linkage.
- Assumptions/dependencies: Consent and biometric policies; robustness to channel/condition variability.
- Domain-specialized, low-resource language adaptation at scale (public sector/NGOs/education)
- Use: High-quality transcription for underrepresented languages and domains (e.g., healthcare in regional languages).
- Tools/workflows: Community-sourced SFT datasets; active learning and on-device adaptation.
- Assumptions/dependencies: Data availability and annotation budgets; local compute or funded cloud resources.
- End-to-end meeting assistants with grounded task automation (software/productivity)
- Use: From diarized transcripts to verified action items, decisions, and follow-ups tied to the right speaker/time, executed in downstream systems.
- Tools/workflows: ASR → structured minutes with who/what/when → task creation (e.g., tickets, calendar invites) with traceable links to source audio.
- Assumptions/dependencies: Reliable NLU on top of transcripts; enterprise integrations; human-in-the-loop verification.
- Cross-lingual workflows: ASR → MT → multilingual subtitles and dubbing (media/education)
- Use: Produce accurate subtitles and assisted dubbing for long-form content with speaker/timing fidelity.
- Tools/workflows: ASR timestamps → MT with speaker-aware segmentation → TTS for dubbing with speaker/time constraints.
- Assumptions/dependencies: High-quality MT/TTS; speaker style transfer; QC pipelines.
- Governance and open-meeting transparency at scale (policy/civic tech)
- Use: Standardized, speaker-attributed transcripts for legislative bodies and public forums, searchable across sessions and languages.
- Tools/workflows: ASR → public portals with search-by-speaker/time → archives for FOIA/Open Data.
- Assumptions/dependencies: Procurement, accessibility standards, and data retention policies.
- Human-robot/agent interaction logging in multi-party environments (robotics)
- Use: Long-form, multi-speaker logs to improve team-robot collaboration and training data for conversational agents.
- Tools/workflows: Diarized transcripts → intent/turn-taking analytics → policy learning for multi-party coordination.
- Assumptions/dependencies: Noisy/overlap-resistant models; sensor fusion (audio + video) for robust turn detection.
- High-noise, field-deployed transcription (public safety, journalism in the field)
- Use: Accurate diarized transcripts from bodycams, field recorders, and press scrums.
- Tools/workflows: Noise-robust ASR + separation-aware diarization; post-hoc enhancement.
- Assumptions/dependencies: Robustness to overlapping speech and adverse acoustics; specialized fine-tuning.
- Privacy-preserving on-device or edge deployments (healthcare/finance/government)
- Use: Run long-form ASR pipelines without transmitting audio to the cloud.
- Tools/workflows: Model distillation/quantization for edge; secure enclaves; federated updates.
- Assumptions/dependencies: Hardware constraints; performance trade-offs; compliance audits.
Notes on Feasibility and Dependencies (cross-cutting)
- Compute and memory: Single-pass processing of 60-minute audio requires LLM context windows (~27k audio tokens plus prompts) and sufficient GPU memory; batch/offline processing is currently more practical than real-time in many settings.
- Audio quality: Microphone placement and room acoustics materially affect diarization and WER; multi-channel inputs help but are not required.
- Language coverage: Strongest SFT support for English/Chinese; expect degradation on low-resource languages without additional fine-tuning.
- Overlapping speech: Current model tends to favor the dominant speaker in crosstalk; high-overlap scenarios need future enhancements.
- Context injection: Supplying accurate glossaries/hotwords and background notes significantly improves domain terms and named entities.
- Compliance and privacy: Regulated sectors may require on-prem or private cloud deployments, role-based access control, and auditable pipelines.
- Open-source ecosystem: Availability of model weights, inference code (e.g., vLLM), and Hugging Face artifacts accelerates integration, but organizations should validate licensing and support requirements.
Glossary
- Acoustic Tokenizer: A module that tokenizes audio to capture spectral details for downstream modeling. "integrates an Acoustic Tokenizer for spectral fidelity"
- Autoregressive generation: A decoding process where each output token is generated conditioned on previously generated tokens. "to autoregressively generate the target sequence."
- code-switching: Alternating between languages within or across utterances. "and natively handles code-switching within and across utterances."
- Concatenated minimum-Permutation WER (cpWER): A metric that measures transcription accuracy while being invariant to speaker label permutations by concatenating utterances per speaker. "Concatenated minimum-Permutation WER (cpWER) evaluates transcription accuracy under speaker permutation invariance by concatenating all utterances belonging to the same speaker and computing the minimum WER over all possible speaker permutations; this metric jointly reflects content recognition accuracy and speaker consistency, while being insensitive to local time alignment errors."
- context fragmentation: Loss of global semantic continuity caused by processing long audio in isolated chunks. "challenges of context fragmentation and multi-speaker complexity"
- context injection: Providing user-supplied text (e.g., keywords, descriptions) to guide recognition. "we introduce a prompt-based context injection mechanism."
- context window: The maximum sequence length a LLM can attend to in a single pass. "fits comfortably within the context window of modern LLMs."
- cosine similarity: A measure of angular similarity between vectors, used here to compare cluster centroids. "refined by merging clusters whose centroids have a cosine similarity greater than 0.67"
- curriculum learning: A training strategy that gradually increases task difficulty or input length over time. "We employed a curriculum learning strategy for the LLM input sequence length, progressively increasing from 8,192 to 65,536 tokens."
- decoder-only LLM: A transformer architecture that uses only a decoder stack for next-token prediction. "processed by a decoder-only LLM backbone (e.g., Qwen 2.5~\cite{qwen2_5})"
- Diarization Error Rate (DER): A metric that quantifies errors in assigning speech to speakers, including confusions and misses. "Diarization Error Rate (DER) measures the accuracy of speaker attribution by accounting for speaker confusion, missed speech, and false alarm speech,"
- diarization invariant word error rate (WER): A WER variant computed without penalizing speaker label differences. "reports both diarization error rate (DER) and diarization invariant word error rate (WER)."
- dual-tokenizers: Using two tokenizers (acoustic and semantic) to produce complementary audio representations. "ingesting continuous latents from dual-tokenizers alongside optional user-provided context."
- Global Semantic Rectification: Post-processing that merges chunked transcripts into coherent long-form text. "coherent, globally consistent long texts (\"Global Semantic Rectification\")."
- HDBSCAN: A density-based clustering algorithm used for speaker clustering without specifying the number of clusters. "clustered with HDBSCAN~\citep{campello2013density},"
- hotwords: User-specified keywords that the model prioritizes during recognition. "ranging from hotword lists to background descriptions"
- MeetEval: An evaluation protocol and toolkit for multi-speaker meeting transcription. "We follow the MeetEval evaluation protocol"
- Rich Transcription: A structured output that interleaves speaker IDs, timestamps, and content. "it generates a structured Rich Transcription stream"
- separation-aware modeling: Approaches that explicitly handle overlapping speech by modeling multiple concurrent speakers. "Future iterations will explore separation-aware modeling to address this challenge."
- single-pass processing: Handling the entire long audio input in one forward pass without chunking. "supports single-pass processing for up to 60 minutes of audio."
- sliding-window paradigm: Processing long inputs in sequential overlapping chunks rather than all at once. "abandons the sliding-window paradigm"
- speaker diarization: The task of segmenting audio and labeling segments by speaker identity. "It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task."
- speaker embeddings: Vector representations of speaker characteristics used for clustering and attribution. "speaker embeddings are extracted from overlapping frames (1.5 s window, 0.75 s hop),"
- temporal collar: A tolerance window used in evaluation to match words by time proximity. "within a predefined temporal collar"
- Time-Constrained minimum-Permutation WER (tcpWER): A cpWER variant that additionally requires word matches to respect time alignment. "Time-Constrained minimum-Permutation WER (tcpWER) further extends cpWER by enforcing temporal alignment constraints, such that words are only matched if they occur within a predefined temporal collar,"
- ultra-low frame rate tokenizer: A tokenizer that produces very few tokens per second to fit long audio within LLM context limits. "ultra-low frame rate tokenizer ($7.5$\,Hz)"
- Voice Activity Detection (VAD): Detecting speech versus non-speech regions in audio. "segmented using Silero voice activity detection (VAD) into clips of up to 30 seconds"
Collections
Sign up for free to add this paper to one or more collections.