- The paper presents a unified Speech LLM that integrates speaker diarization and ASR using a Llama-3.2-3B-instruct backbone with LoRA optimizations.
- It employs a novel data structure and contextual token interleaving to accurately map speakers with their transcriptions in complex multilingual conversations.
- The approach achieves a 54.87% improvement in tcpWER/tcpCER over baselines, while highlighting the trade-off between model size and performance.
A Unified Speech LLM for Diarization and Speech Recognition in Multilingual Conversations
Introduction
This paper introduces a novel Speech LLM designed to integrate speaker diarization and automatic speech recognition (ASR) in multilingual conversational contexts. Traditional LLMs have expanded to speech-related tasks, yet they face challenges in handling naturally complex multilingual conversations. This study leverages the Multilingual Conversational Speech Language Modeling (MLC-SLM) Challenge, which supplies a dataset tailored to these intricate scenarios. The research primarily focuses on Task II—joint speaker diarization and recognition—demonstrating significant advancements over the baseline with a streamlined model.
End-to-end Speech LLM for Joint Diarization and ASR
In Task II, the conventional approach separates diarization and recognition, resulting in suboptimal performance in scenarios with speaker overlap and multilingual dialogues. The proposed model unifies these processes using a contextual Speech LLM, opting for an end-to-end methodology that iteratively processes audio segments while incorporating conversational context (Figure 1). The architecture employs Llama-3.2-3B-instruct as a backbone, optimized through Local Recurrent Attention (LoRA) and underpinned by a Whisper encoder for rich representation extraction.
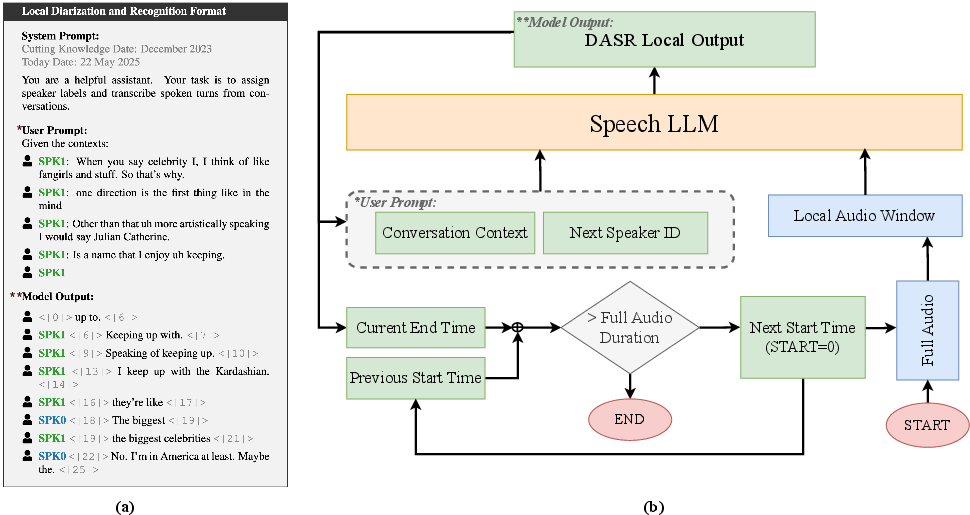
Figure 1: Overview of our approach for local diarization and speech recognition using Speech LLM.
The model's data structure interleaves speaker and timestamp tokens with transcriptions, fostering an alignment between speakers and spoken text. This system excels in annotating speaker roles accurately, benefiting from contextual history and learned structure.
Training and Inference
The model is trained using segmental two-speaker conversations from the MLC-SLM dataset, employing a complex augmentation strategy including SpecAugment, SpecSubstitute, and speed perturbation, alongside a dynamic batching approach. Emphasizing efficiency, only selected components are unfrozen during training to conserve computational resources.
For inference, the model processes audio in strategically defined chunks, ensuring that segment boundaries are coherent with conversational turns. Updates to speaker contexts prevent segmentation artifacts, resulting in naturally diarized transcripts. Moreover, a global alignment post-processing step harmonizes local diarization results with a more consistent speaker identity across the entire audio.
Results and Discussion
The proposed system achieved an 8th place finish in Task II evaluations, surpassing the baseline model's tcpWER/tcpCER by 54.87% while operating on a smaller LLM. Detailed performance metrics displayed in Table 1 affirm the substantial improvement in both diarization and transcription accuracy. The model's efficiency and enhanced contextual understanding are pivotal in achieving these results.
When testing a scaled-down version of the model (1B parameters), performance slightly diminished, suggesting a trade-off between resource constraints and model capability. The comparative analysis of per-language tcpWER demonstrates robustness across various linguistic inputs, with certain idiomatic nuances, such as Thai, reflecting model adaptability's limits (Figure 2).
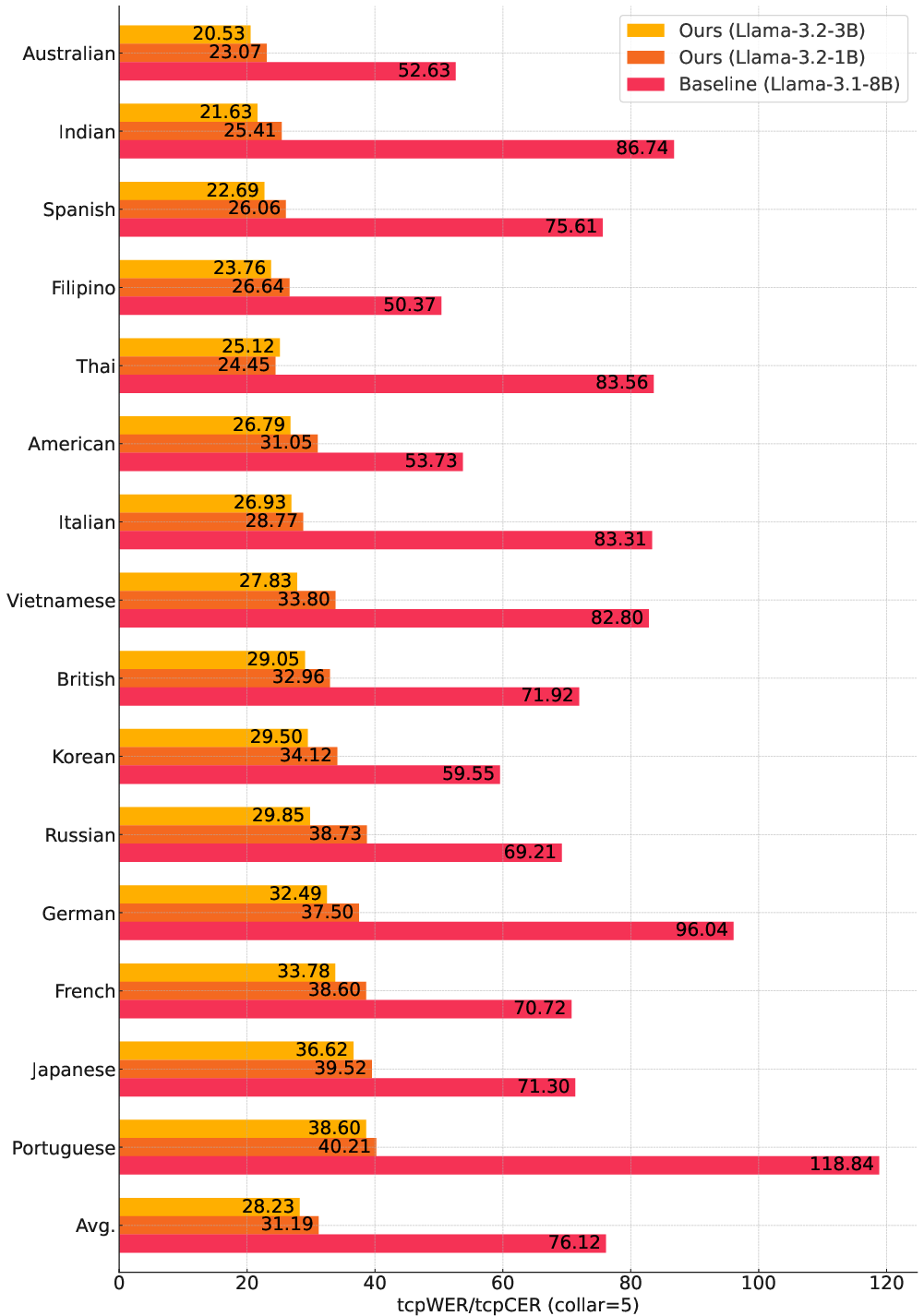
Figure 2: Per-language tcpWER/tcpCER (\%) comparison on the development set for MLC-SLM Task II.
Fine-tuning ASR-based Speech LLM
Task I focused on evaluating fine-tuned multilingual ASR models. While the primary submission placed 20th due to limited training epochs, subsequent extended fine-tuning showcased significant improvements in accuracy across numerous languages, underscoring the importance of comprehensive training schedules. The two-phase training strategy—language-specific pretraining followed by unified multilingual fine-tuning—proved effective in adapting to diverse linguistic contexts (Table 2).
Conclusions
This study proposes a sophisticated methodology integrating diarization and ASR for complex multilingual speech contexts using a Speech LLM. The model demonstrates a substantial tcpWER/tcpCER improvement over baseline systems, despite reduced model size. This work supports the potential of LLMs in enhancing transcript accuracy through integrated diarization and ASR, with results suggesting further exploration into adaptive learning strategies for optimized multilingual performance.