- The paper presents a novel ASR architecture that integrates diarization-conditioned modifications to Whisper (DiCoW) with a local EEND-based diarization pipeline (DiariZen) for robust multilingual, multi-talker performance.
- The methodology leverages transformer adaptations through Frame-Level Diarization-Dependent Transformations (FDDT) and combines weighted WavLM and Conformer embeddings for precise speaker clustering.
- Experimental results demonstrate improved tcpWER/CER metrics and reduced diarization error rates, overcoming challenges from dataset annotation inconsistencies.
BUT System for the MLC-SLM Challenge
Introduction
The "BUT System for the MLC-SLM Challenge" presents a robust architecture for ASR in multilingual and multi-talker settings. This research integrates DiCoW, a diarization-conditioned Whisper variant, with DiariZen, a diarization pipeline built on Pyannote, forming an innovative ASR system designed for the challenging environment of the MLC-SLM challenge. Through extensive experimentation in diverse, out-of-domain multilingual scenarios and subsequent domain adaptation, the study shows superior performance over existing methodologies.
DiariZen Architecture
DiariZen serves as a foundational component of the system, handling speaker diarization tasks through a local end-to-end neural diarization (EEND) framework (Figure 1). This pipeline, built upon Pyannote, segments audio into shorter chunks and applies local EEND. DiariZen uses WavLM and Conformer, leveraging weighted aggregation from WavLM to drive the Conformer layer inputs, culminating in per-speaker embeddings. These embeddings inform a clustering process to yield diarization results that surpass baseline performance.

Figure 1: Framework of local EEND module for DiariZen. Figure adapted from~\cite{han2024leveraging}.
DiCoW: Diarization-Conditioned Whisper
The DiCoW component modifies Whisper to incorporate frame-level diarization via Frame-Level Diarization-Dependent Transformations (FDDT) (Figure 2). This schema captures contextual speaker activities through an STNO mask, distinguishing between silence, target speaker activity, non-target speaker presence, and overlap. These probabilistic representations are integrated within the Whisper encoder by adapting each Transformer layer with probability-weighted transformations, thereby preserving the core strengths of the Whisper architecture while enhancing its handling of multi-speaker environments.
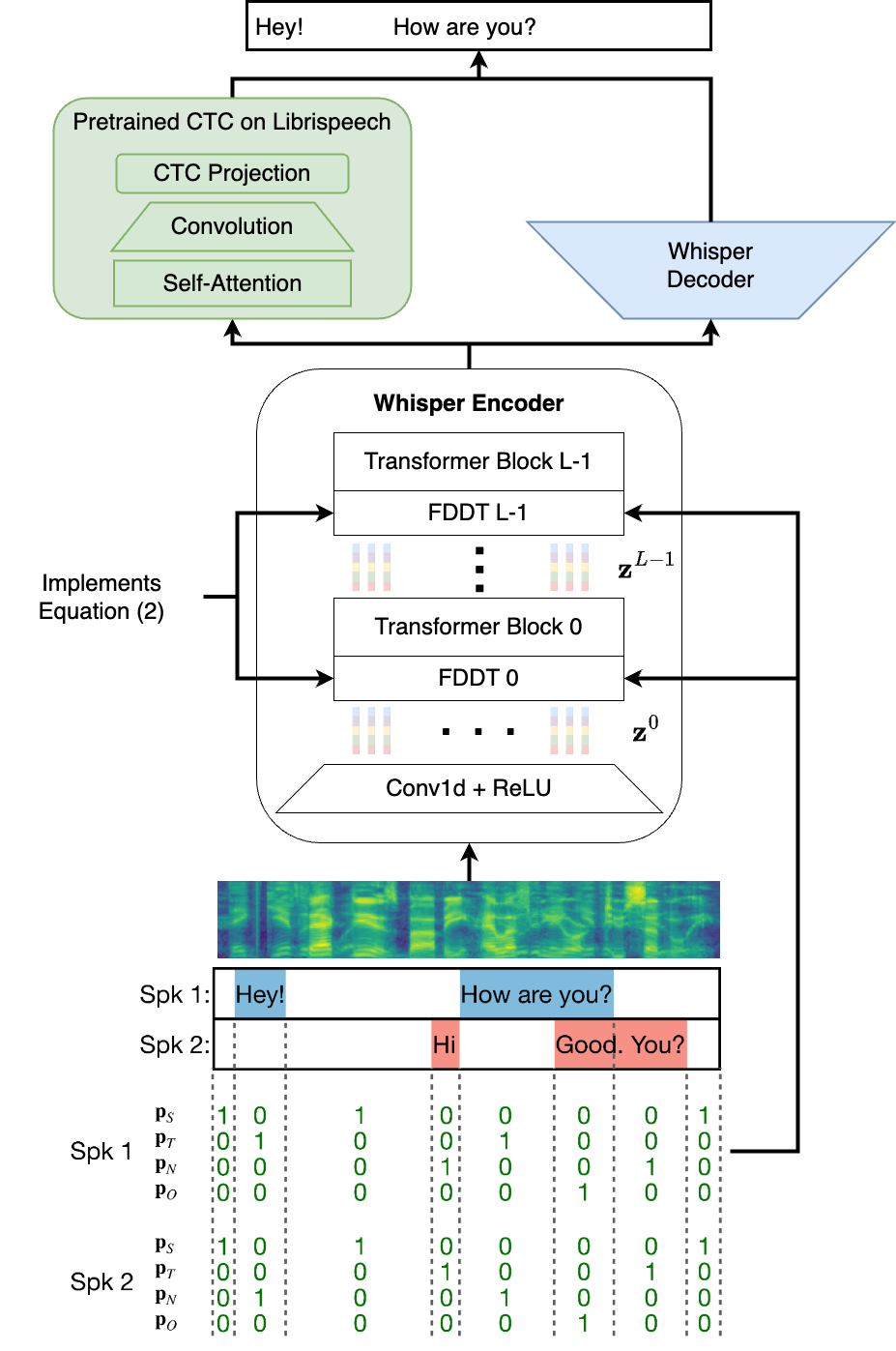
Figure 2: Overview of the DiCoW model architecture. The model is based on the Whisper architecture, with modifications to incorporate frame-level diarization information through Frame-Level Diarization Dependent Transformations (FDDT). Figure adapted from~\cite{polok2024dicowdiarizationconditionedwhispertarget}.
Experimental Setup and Results
Evaluations were conducted using both zero-shot and fine-tuned settings in multilingual conditions. DiariZen displayed consistent superiority over Pyannote in diarization error rates (DER), and when integrated with DiCoW, significantly advanced tcpWER/CER metrics on ground-truth and diarization-driven segmentations. However, labeling inconsistencies posed challenges, which fine-tuning strategies sought to alleviate, yielding a micro-average tcpWER/CER improvement to 16.75% and a second-place ranking in the Task 2 of the challenge.
Impact of Labeling Inconsistencies
A critical analysis of dataset annotations revealed substantial inconsistencies, such as omitted speech segments, which skew training and evaluation. A proposed mitigation leverages auxiliary voice activity detection (VAD) to recalibrate speech and silence boundaries, aligning training more closely with ideal test conditions. This adjustment led to noticeable performance enhancements, demonstrating robustness in diarization and ASR outputs (Figure 3).
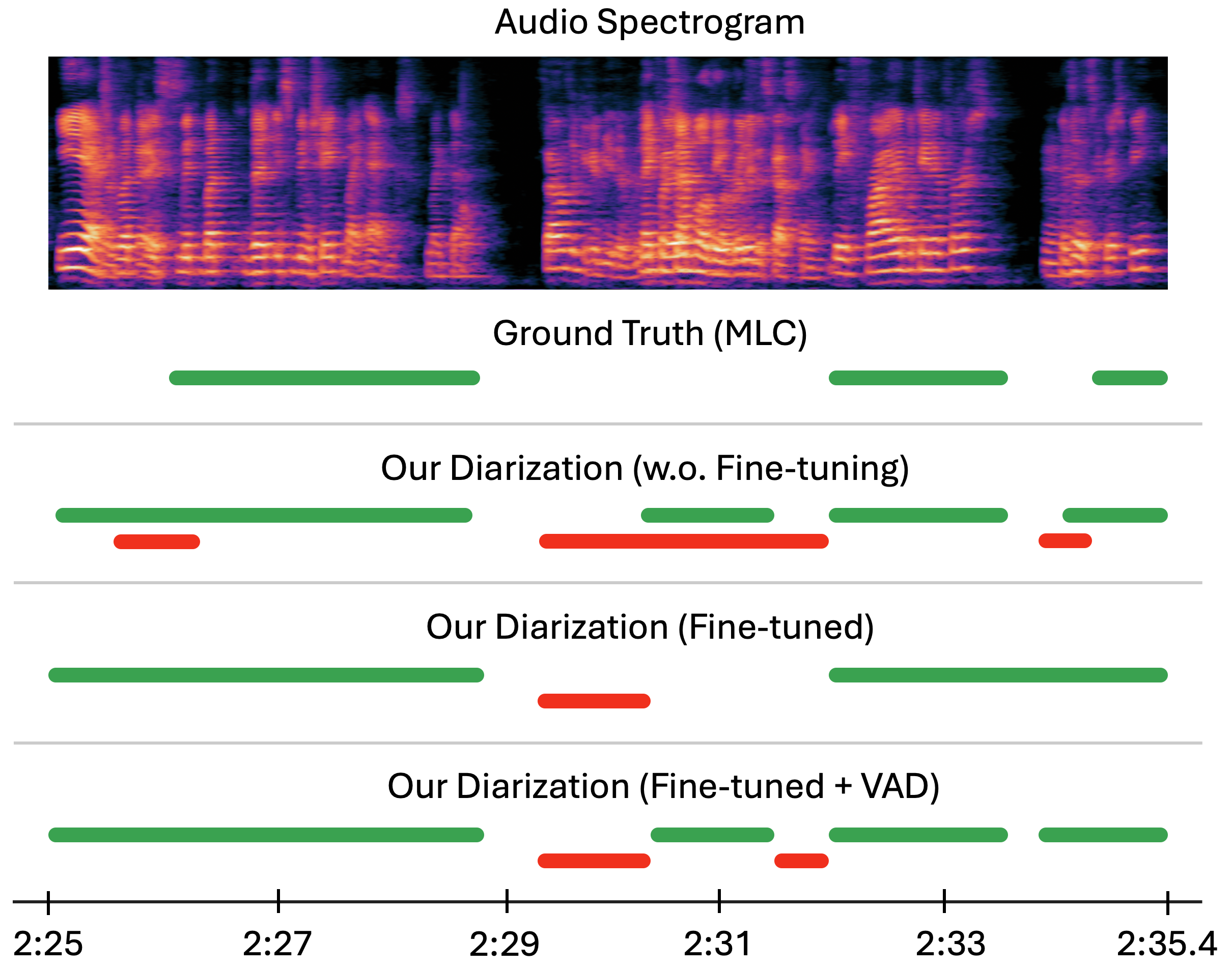
Figure 3: Example of the ground truth diarization; our system before fine-tuning on MLC; the same system after fine-tuning; and the fine-tuned system with probabilities merged using auxiliary VAD.
Conclusions
This study introduces a comprehensive, non-LLM framework for multilingual, multi-talker ASR, integrating advanced diarization-conditioned strategies with significant improvements in performance metrics across languages. Despite observed dataset annotation issues, this dual-strategy system demonstrates notable efficacy and potential expansion through introduction of diarization-conditioned speech LLMs. Future endeavors demand investigation into optimized training routines for inaccurately labeled data and potential integration of more advanced diarization techniques for further performance gains.