- The paper introduces an innovative diarization-aware MS-ASR framework combining speaker diarization with LLMs to enhance transcription of overlapping speech.
- The methodology employs dual encoders for semantic and speaker embeddings and integrates a gated cross-attention mechanism for accurate segment-level transcription.
- Experimental results on AliMeeting and MLC-SLM datasets demonstrate significant improvements in cpWER and tcpWER, validating the system's robustness.
Diarization-Aware Multi-Speaker Automatic Speech Recognition via LLMs
Introduction
The paper explores an innovative approach to Multi-Speaker Automatic Speech Recognition (MS-ASR) by integrating Speaker Diarization with LLMs. Such integration is pivotal for transcribing overlapping speech, a common occurrence in real-world conversational settings including meetings and discussions. Traditional Serialized Output Training (SOT) methods often neglect absolute timing information, a critical limitation for applications demanding precise timing attributes. The framework introduces a diarization-aware approach to MS-ASR, which combines speaker diarization with LLM-based transcription, promising more accurate segment-level transcriptions.
Overview of the Framework
The proposed diarization-aware MS-ASR framework addresses key challenges in multi-speaker environments by providing segment-level transcriptions that incorporate both speaker and semantic embeddings (Figure 1). The architecture allows for robust performance in multilingual settings, especially in complex environments with high overlap among speakers. This work positions LLMs not merely as transcription tools but as comprehensive backends that unify speaker-aware segmentation with accurate transcription.
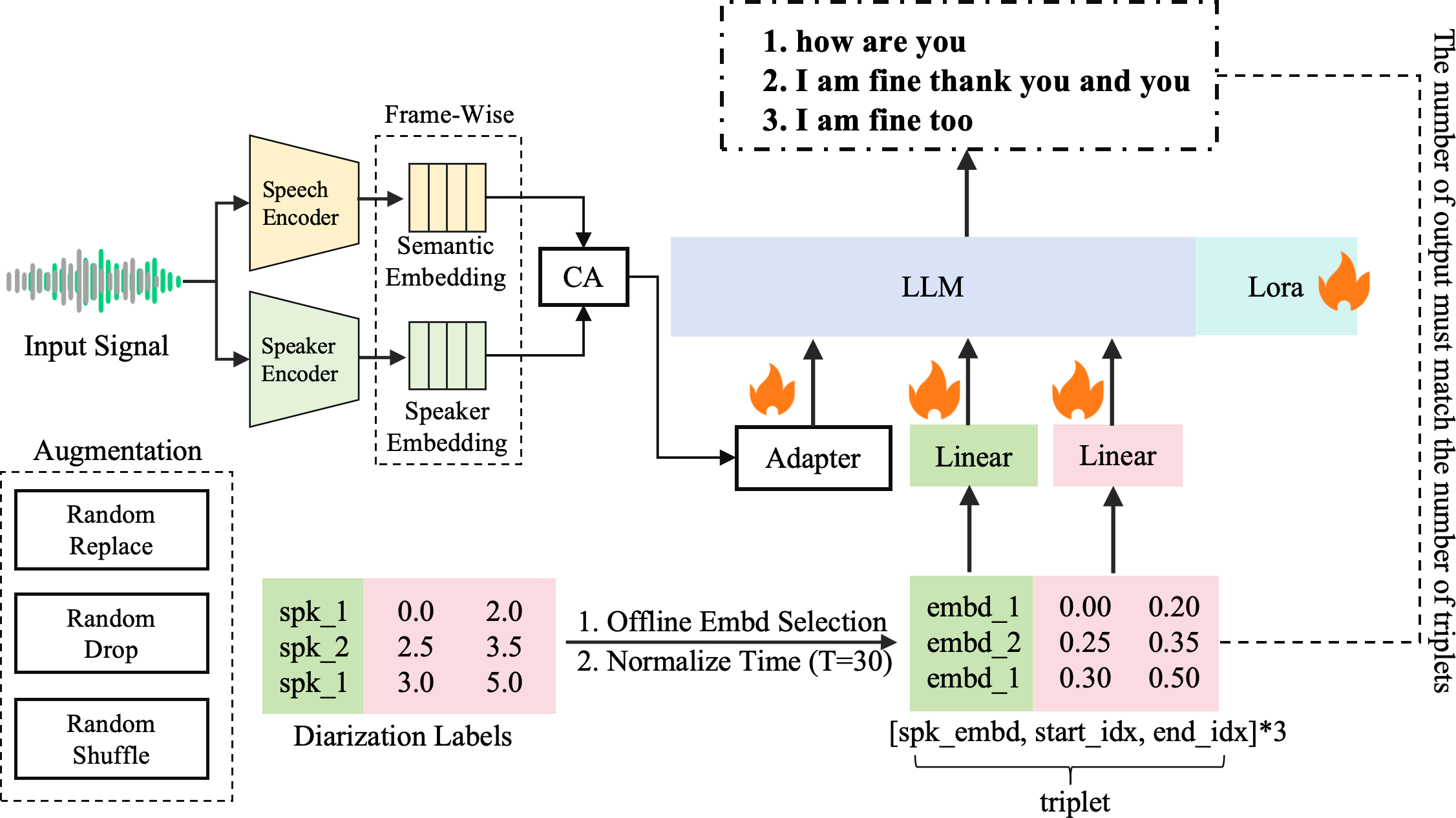
Figure 1: An overview of our framework.
Methodology
The core of the framework integrates a diarization-aware triplet enrollment mechanism. Each triplet consists of a speaker embedding, sentence start time, and sentence end time. This configuration permits nuanced temporal alignment with diarization outputs, allowing for accurate transcription and speaker attribution. The framework employs two parallel encoders, a speech encoder for semantic embeddings and a speaker encoder for speaker-specific features. A gated cross-attention mechanism further enhances the integration of speaker features with semantic embeddings.
Implementation and Data Augmentation
Data augmentation strategies such as embedding replacement, embedding dropout, and triplet shuffling were implemented to enhance model robustness against typical diarization errors. These augmentations simulate real-world errors and ensure the model's ability to handle imperfect data. Additionally, chunk-based inference was employed to manage long-form recordings efficiently, maintaining cross-chunk continuity by consistent speaker embedding and temporal alignment.

Figure 2: The construction of our inputs (three sentences from two speakers).
Experimental Evaluation
Experiments were conducted on the AliMeeting dataset and the MLC-SLM Challenge dataset, demonstrating the framework's effectiveness. The results showed that the proposed system achieved a cpWER of 31.6% and 35.1% on the AliMeeting Eval and Test sets, respectively. These metrics underscore the system’s ability to maintain high-quality, speaker-attributed transcriptions despite increased speaker overlap.
Additionally, tcpWER results highlighted the model's capability to provide accurate temporal alignment alongside transcription accuracy, achieving overall tcpWER scores of 32.17% and 36.36% on the Eval and Test sets, respectively. The significant improvements in tcpWER metrics on diverse datasets validate the model's robustness and adaptability to varying linguistic and speaker conditions.
Conclusion
This work advances MS-ASR by integrating diarization-aware inputs and leveraging LLMs to enhance transcription accuracy and speaker disambiguation. The framework supports joint decoding of multiple speakers with contextual modeling across conversations, addressing the inherent challenges of multi-speaker environments. Future research may extend the system for real-time applications and explore its potential in downstream tasks such as meeting summarization and question answering. The strong performance metrics obtained across multiple datasets underscore the proposed approach's potential in practical applications, marking a significant step toward effective multi-speaker ASR systems.