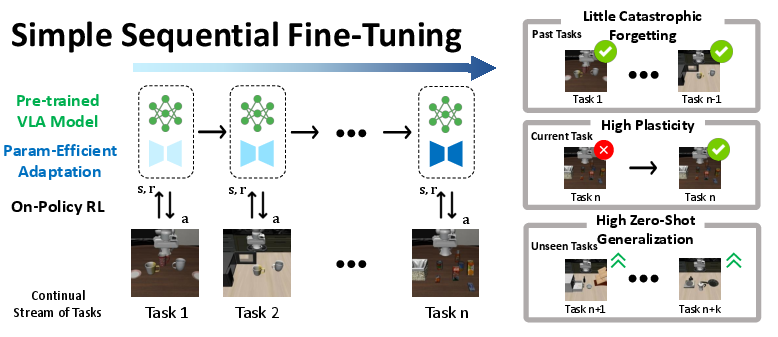
Simple Recipe Works: Vision-Language-Action Models are Natural Continual Learners with Reinforcement Learning
Abstract: Continual Reinforcement Learning (CRL) for Vision-Language-Action (VLA) models is a promising direction toward self-improving embodied agents that can adapt in openended, evolving environments. However, conventional wisdom from continual learning suggests that naive Sequential Fine-Tuning (Seq. FT) leads to catastrophic forgetting, necessitating complex CRL strategies. In this work, we take a step back and conduct a systematic study of CRL for large pretrained VLAs across three models and five challenging lifelong RL benchmarks. We find that, contrary to established belief, simple Seq. FT with low-rank adaptation (LoRA) is remarkably strong: it achieves high plasticity, exhibits little to no forgetting, and retains strong zero-shot generalization, frequently outperforming more sophisticated CRL methods. Through detailed analysis, we show that this robustness arises from a synergy between the large pretrained model, parameter-efficient adaptation, and on-policy RL. Together, these components reshape the stability-plasticity trade-off, making continual adaptation both stable and scalable. Our results position Sequential Fine-Tuning as a powerful method for continual RL with VLAs and provide new insights into lifelong learning in the large model era. Code is available at github.com/UT-Austin-RobIn/continual-vla-rl.
















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how big robot “brain” models that see, read, and act can keep learning new tasks over time without forgetting what they already know. The surprise: a very simple training recipe works really well. Instead of using complex tricks, just fine‑tuning the model on each new task, with a small add‑on called LoRA and a careful kind of practice called on‑policy reinforcement learning, lets the model learn new things while remembering old ones.
What questions did the researchers ask?
They focused on three easy-to-understand questions:
- Can large Vision‑Language‑Action (VLA) models learn a sequence of tasks (like a class schedule) without forgetting earlier tasks?
- Do simple methods (just fine‑tuning one task after another) work as well as or better than complicated “don’t forget” methods?
- Why would this simple method work—what’s going on under the hood?
How did they study it?
Think of a VLA model as a robot brain that:
- sees through cameras (vision),
- understands short instructions (language), and
- moves a robot arm (action).
They set up a “continual learning” test: the robot gets tasks one after another (like “put the bowl on the plate,” then later “open the drawer,” then “place the sponge in the basket”). The robot must learn each new task while still being able to do the old ones.
Here’s the simple recipe they tested:
- Sequential fine‑tuning: train on task 1, then task 2, then task 3, and so on.
- LoRA: a small, lightweight add‑on that lets you nudge the model without changing all of its billions of parameters—like adding sticky notes rather than rewriting a whole book.
- On‑policy reinforcement learning (RL): the model practices by trying things in the environment and learning from the results of its own actions—like learning to balance by riding the bike, not by just reading about it. They use a stable RL method so training doesn’t “crash.”
They compared this simple approach to several well‑known “don’t forget” strategies (like regularization, replaying old data, or isolating parameters) and to a “multi‑task oracle” that trains on all tasks at once (not realistic for continual learning but useful as a reference).
They tested across different robot task suites (LIBERO, RoboCasa, ManiSkill) and different VLA models (like OpenVLA and Pi‑0), and they measured:
- how well the robot does on all learned tasks (overall success),
- how much it forgets old tasks,
- how fast it picks up new tasks,
- and how well it handles new tasks without extra training (zero‑shot generalization).
What did they find?
Here are the main takeaways:
- The simple recipe works shockingly well.
- Sequential fine‑tuning + LoRA + on‑policy RL often matches or beats more complex methods designed to prevent forgetting.
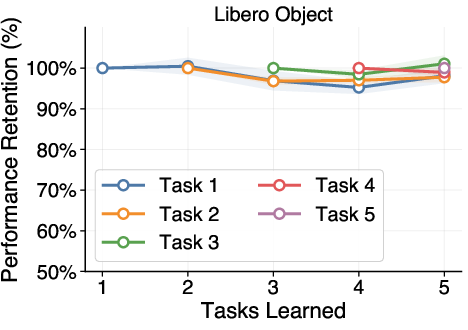
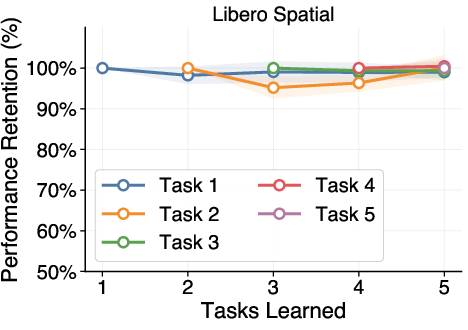
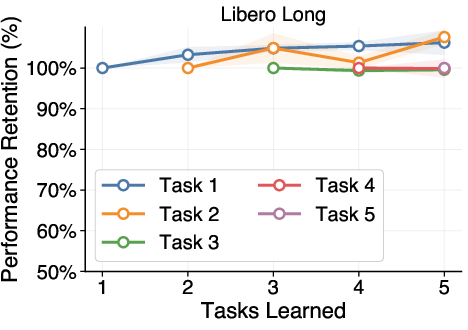
- It shows high plasticity (learns new tasks quickly) and little to no forgetting of earlier tasks.
- It often improves the model’s zero‑shot abilities (doing new tasks it wasn’t trained on).
- It’s robust across many tests.
- It holds up across different task types, different robot environments (changes in camera, lighting, or robot position), different VLA architectures, and even when the order of tasks changes.
- It’s usually close to the “multi‑task oracle” and sometimes even better for zero‑shot generalization.
- Why might this simple approach work?
- Big models have room: Large pretrained models have a lot of “space” to learn new skills without bumping into old ones, so small updates won’t rewrite their core knowledge.
- LoRA keeps updates tidy: LoRA focuses changes into a small, controlled part of the model, like adding focused notes rather than scribbling all over the textbook.
- On‑policy RL nudges, doesn’t shove: Because the model learns from its own current behavior, it tends to adjust gently from what it already does, instead of making wild jumps that could erase old skills.
- All three ingredients matter.
- When they removed RL and used only supervised fine‑tuning, the model forgot a lot.
- When they used a much smaller model, forgetting returned.
- When they removed LoRA and fully updated all parameters, performance and stability got worse.
- Together—big pretrained model + LoRA + on‑policy RL—forgetting dropped and learning stayed strong.
Why does this matter?
- For real robots: It points to a practical way to build robots that keep getting better on the job—learning new tasks in homes, hospitals, or warehouses—without losing what they already know.
- Simpler pipelines: You may not need complicated “memory” systems or huge replay buffers of old data. A straightforward training loop can work very well.
- Rethinking old assumptions: Many believed that simple sequential fine‑tuning would always cause catastrophic forgetting. This paper shows that, with large pretrained VLAs, LoRA, and careful RL, that’s not necessarily true.
- Faster progress for researchers and engineers: The team is releasing code, making it easier for others to test, reproduce, and build on these results.
In short, the paper shows that big, well‑trained robot models can be natural continual learners when you use a small, smart adapter (LoRA) and the right kind of practice (on‑policy RL). That’s a hopeful sign for building lifelong‑learning robots that are both capable and reliable.
Knowledge Gaps
Below is a consolidated, actionable list of the paper’s unresolved gaps, limitations, and open questions. Items are grouped to highlight where future work can most productively extend the study.
Scope and External Validity
- Real-world validation is absent: all experiments are in simulation (LIBERO, RoboCasa, ManiSkill). It remains unknown whether the observed “no forgetting” behavior and Seq. FT advantages hold on physical robots with real sensor noise, reset challenges, and safety constraints.
- Limited diversity of task distributions: evaluated tasks largely involve language-conditioned manipulation with shared state/action spaces and sparse binary rewards. The behavior under broader domains (e.g., locomotion, deformable objects, multi-agent, continuous non-stationarity) is untested.
- Explicit task identity via language instructions: continual learning with latent/implicit or drifting task identities is not studied; generality to settings without explicit instruction conditioning is unknown.
- Short task sequences and scale: robustness of Seq. FT to much longer task streams (dozens/hundreds) and long revisit intervals is not established; capacity saturation and performance drift over long horizons are unmeasured.
- Limited model and architecture coverage: the main results rely on OpenVLA-OFT, with single-domain checks for OpenVLA and Pi-0. Cross-architecture consistency across many VLAs (diffusion, transformers with different backbones) and across multiple domains per model remains unexplored.
Evaluation Design and Metrics
- Statistical confidence is limited: only 3 seeds per configuration due to compute; the strength and variance of conclusions under higher replication is unknown.
- Sample efficiency and compute cost are not reported: success metrics are provided without measuring data/compute per task or per success point, leaving open whether Seq. FT is more efficient than baselines.
- Memory footprints vs. performance trade-offs are underreported: especially for parameter-isolation and replay approaches (e.g., growth with number of tasks), preventing a fair cost–benefit comparison.
- Sensitivity to adversarial/anti-curriculum orderings is only lightly probed: permutations within one benchmark are tested, but systematically adversarial task orderings designed to maximize interference have not been evaluated.
- Generalization characterization is coarse: “Zero-Shot Success” (ZS) captures retention of pretrained capabilities, but finer-grained analyses (e.g., compositional generalization, cross-scene transfer beyond minor perturbations, OOD language variations) are missing.
Algorithmic Choices and Ablations
- On-policy RL exclusivity: the findings rely on GRPO (on-policy). It is unknown whether Seq. FT’s stability persists under off-policy algorithms (e.g., SAC, DDPG, Q-learning variants), or other on-policy methods (e.g., PPO with different clipping/entropy schemes).
- PEFT method narrowness: LoRA is the only PEFT method deeply studied. Effects of alternative PEFTs (IA3, adapters, prefix/prompt tuning, partial-layer FT) and hybrid strategies on forgetting/plasticity are not examined.
- LoRA hyperparameters and placement: the impact of LoRA rank, target layers/modules, layerwise placement, and merge timing/strategy on stability and plasticity is not systematically explored.
- Pretraining dependence: ablations show smaller models forget; however, the role of pretraining quality/scale/data composition (e.g., weaker or domain-mismatched pretraining) on Seq. FT’s success is not quantified.
- Replay and regularization baselines breadth: several important CL methods (e.g., GEM/A-GEM, SI/MAS, OGD/PCGrad, orthogonal gradient constraints) are absent; it is unclear if Seq. FT still dominates against a broader, modern baseline set.
- Fairness and tuning asymmetries: method-specific hyperparameters were locally swept while Seq. FT used defaults; systematic hyperparameter optimization across methods (including stronger tuning of baselines) is needed to ensure fair comparisons.
Mechanistic Understanding and Theory
- Partial theoretical account: the paper offers qualitative arguments (e.g., on-policy implicit KL control, diagonal Fisher “energy” proxies, LoRA low-rank constraints), but lacks formal analysis or bounds predicting when Seq. FT should avoid forgetting.
- Approximate Fisher analysis: reliance on diagonal FIM and local second-order approximations may miss cross-parameter interactions; whether conclusions hold with structured/low-rank FIM or empirical Fisher variants remains open.
- Missing direct measurements of policy drift: forward KL to the base policy (and per-layer/per-module drift) is hypothesized to correlate with forgetting, but not systematically measured across methods and tasks.
- Gradient and representation geometry: claims about high-dimensional “null spaces” and LoRA constraining harmful updates would benefit from concrete measures (e.g., gradient cosine similarity across tasks, subspace overlap, representational CKA) and intervention studies.
Robustness and Failure Modes
- Conflicting-task scenarios: tasks that require incompatible behaviors (e.g., same instruction mapping to different actions across contexts or opposing action policies) are not designed/tested; Seq. FT’s limits under strong interference are unknown.
- Heavier distribution shifts: beyond camera/lighting/robot-base perturbations, robustness to significant scene changes, occlusions, sensor failures, distractors, and dynamics shifts is not quantified.
- Reward noise and delays: the stability and performance of Seq. FT under noisy, delayed, or non-stationary rewards (including reward misspecification) remain untested.
- Continual adaptation with no resets or online non-episodic streams: whether Seq. FT remains stable when the environment cannot be reset cleanly between tasks or when tasks change gradually within episodes is unknown.
Practical Considerations and Deployment
- Real-world sample budgets and safety: on-policy RL can be sample- and safety-intensive; how to translate the proposed recipe (Seq. FT + LoRA + on-policy RL) to safe and data-efficient real-robot learning remains open.
- Continual capacity management: while LoRA helps initially, the long-term accumulation of updates and potential capacity saturation (or the need to rotate/drop adapters) is not studied.
- Inference-time efficiency: the impact of continual fine-tuning on inference latency/memory (especially with multiple adapters, if used) and deployment constraints is not assessed.
Open Questions for Future Research
- Under what precise conditions (task similarity, pretraining scale, LoRA rank, RL hyperparameters) does Seq. FT switch from “no forgetting” to catastrophic forgetting, and can these be predicted a priori?
- Can we derive principled, task-aware schedules for LoRA rank, learning rate, and on-policy batch size that provably control forward KL drift and forgetting across long task sequences?
- Do hybrid methods (e.g., Seq. FT augmented with minimal replay or lightweight regularization) yield better stability–plasticity trade-offs without compromising zero-shot generalization?
- How does Seq. FT affect submodules differently (vision encoder, language encoder, policy head), and can selective adaptation further reduce interference while improving plasticity?
- Can the observed generalization gains over multitask training be causally linked to representation anisotropy, curriculum effects, or implicit regularization from on-policy data—and replicated under stronger adversarial test conditions?
Practical Applications
Overview
This paper shows that, for large Vision-Language-Action (VLA) models, a simple recipe—Sequential Fine-Tuning with Low-Rank Adaptation (LoRA) using on-policy reinforcement learning (e.g., GRPO)—acts as a strong and stable continual learning method. It delivers high plasticity, little to no forgetting, and preserved (often improved) zero-shot generalization across multiple VLA architectures and benchmarks. Below are concrete applications and workflows that this finding enables.
Immediate Applications
- Field adaptation for deployed robots with a simpler training loop [Robotics, Manufacturing, Warehousing, Service]: Replace complex continual-learning stacks with SeqFT+LoRA+on-policy RL to adapt robots to new tasks, tools, or layouts without replay buffers or task-specific isolation. Tools/workflows: “AdapterOps” pipeline for nightly/weekly LoRA updates; GRPO training job template; rollbackable adapter versions. Assumptions/dependencies: access to a large pretrained VLA, safe on-policy interaction (or high-fidelity sim), resettable tasks, reward signals, and basic safety monitors.
- Rapid retargeting to environment changes (camera, lighting, base pose) [Robotics, Logistics]: Use short SeqFT sessions to adapt vision and control to new camera placements, illumination, or robot base shifts when rearranging a warehouse cell or home environment. Tools: environment-perturbation scripts; ZS/NBT dashboards to validate generalization retention. Dependencies: sufficient interaction budget; stable RL hyperparameters.
- Privacy- and compliance-friendly continual learning without replay buffers [Healthcare, Home Robotics, Regulated Settings]: Skip storing past task data or human demos by relying on on-policy updates; reduces data retention risk and simplifies compliance. Tools: “No-Replay” training profile; audit artifacts of policies/adapters instead of datasets. Dependencies: reliable online data collection, well-defined sparse rewards.
- Cost- and energy-efficient post-training via LoRA [Robotics, Edge ML]: Update a small number of parameters at the edge or on-prem GPUs, lowering compute, energy, and networking costs versus full fine-tuning or replay-heavy methods. Tools: LoRA rank presets; adapter quantization; edge-compatible GRPO configs. Dependencies: base VLA sized to available hardware; efficient dataloaders.
- Fleet-level adapter management and A/B validation [Operations, MLOps for Robotics]: Maintain per-site/per-task LoRA adapters, roll out canary updates, and monitor Average Success, Negative Backward Transfer (NBT), and Zero-Shot Success (ZS) as SLAs. Tools: LoRA registry, retention plots, “ZS Monitor” alerts, KL-drift watchdogs. Dependencies: telemetry from robots, evaluation harness with held-out tasks, release gating.
- Stronger baseline and reproducible curriculum studies in research [Academia]: Adopt SeqFT-LoRA-on-policy RL as the default continual-learning baseline; use the released codebase to benchmark against EWC/replay/isolation. Tools: the authors’ code (github.com/UT-Austin-RobIn/continual-vla-rl); standardized metrics (AVG, NBT, FWT, ZS); seed-controlled scripts. Dependencies: compute budget for on-policy runs; consistent evaluation splits.
- Mechanistic diagnostics for safe updates [Academia, Safety Engineering]: Monitor Fisher energy along gradient directions and effective rank changes to detect interference or layer overwriting; halt or slow learning when risk is high. Tools: “FisherGuard” diagnostics; per-layer effective-rank tracker; KL-divergence limits. Dependencies: approximate (diagonal) Fisher estimation; logging hooks in training loop.
- Adapter marketplaces for manipulation skills [Robotics, Manufacturing]: Package LoRA adapters for common tasks (e.g., “open drawer,” “place bowl”) that clients can fine-tune further on their own embodiments. Tools: signed adapter artifacts; compatibility metadata; adapter-merging/selection utilities. Dependencies: base model alignment across customers; licensing and IP controls.
- Cross-model portability in sim-to-real prototyping [Software + Sim, Robotics]: Start with OpenVLA or Pi-0 in simulation (RoboCasa, ManiSkill), then use the same SeqFT recipe to move between models or environments. Tools: model-agnostic training driver; environment wrappers; policy checkpoints. Dependencies: observation/action space calibration, instruction formats, physics engine fidelity.
- Teaching labs and coursework in continual RL/VLA [Education]: Use the simple recipe to make hands-on labs feasible; students measure forgetting, ZS retention, and curriculum effects without complex replay/regularization stacks. Tools: lab notebooks, metric dashboards, prebuilt task sequences. Dependencies: GPU access; sandboxed simulators.
Long-Term Applications
- Self-improving robotic fleets with federated continual RL [Robotics, Logistics, Consumer]: Robots learn new tasks on-device with on-policy RL and LoRA, and periodically sync adapters to a central registry for cross-site transfer. Tools: “Fleet Adapter Manager,” adapter dedup/composition, privacy-preserving aggregation. Dependencies: robust on-device training, safe interaction policies, network bandwidth, federated governance.
- Regulatory frameworks for continual-learning embodied AI [Policy, Safety]: Standardize deployment-time metrics (NBT, ZS) as certification criteria; require audit trails of on-policy updates, KL-drift caps, and rollback procedures. Tools: certification test suites; compliance checkers integrated with training logs. Dependencies: sector-specific regulators (e.g., healthcare, industrial), conformance labs, incident reporting.
- Autonomous lab automation that learns new protocols sequentially [Healthcare, Biotech R&D]: Lab robots adapt to new assays or glassware and preserve old protocols without curated replay datasets. Tools: protocol adapters library; stepwise reward templates; “failure-safe” interlocks. Dependencies: high-fidelity simulators or safe dry runs, contamination/safety controls, human-in-the-loop checkpoints.
- Assistive and home robots that personalize safely over time [Healthcare, Consumer]: Household or eldercare robots refine routines (placement preferences, device usage) while retaining core capabilities. Tools: daily “micro-updates,” household-specific adapters, policy validation on proxy tasks before execution. Dependencies: robust reward design from natural-language instructions, safety interlocks, liability frameworks.
- Construction and energy inspection robots that adapt per site [Construction, Energy]: Robots learn site-specific navigation/manipulation policies (scaffolds, valves, panels) and generalize across assets with minimal forgetting. Tools: site adapter packs; intermittent on-site training windows; digital twin validation. Dependencies: access constraints, hazard detection, digital-twin fidelity.
- Adapter composition and routing at scale [Software, Robotics Platforms]: Automatically select/compose LoRA adapters per instruction and context (mixture-of-adapters) to cover thousands of skills. Tools: “Adapter Router,” confidence/uncertainty gating, on-the-fly adapter merging. Dependencies: routing algorithms, conflict resolution, latency budgets.
- Hardware and runtime support for low-rank adaptation and on-policy RL [Semiconductors, Systems]: Accelerators and runtimes that natively optimize LoRA ops and on-policy sampling/control loops on edge devices. Tools: kernel libraries, memory-efficient adapter caching, batched on-policy rollout engines. Dependencies: vendor support, standards for adapter formats.
- Cross-embodiment transfer with thin alignment layers [Robotics]: Share adapters across robots with different kinematics by adding small alignment modules while keeping the core VLA and adapters. Tools: embodiment adapters; calibration routines; embodiment-agnostic instruction schemas. Dependencies: standardized action semantics, calibration time, safety validation.
- Continuous-validation pipelines and drift guardrails [MLOps, Safety]: Turn the paper’s metrics into always-on monitors; pause or revert training when NBT rises or ZS drops beyond thresholds, or when forward KL to the base policy exceeds limits. Tools: “CRL Dashboard,” auto-rollback, shadow evaluation on held-out tasks. Dependencies: evaluation compute, curated sentinel tasks, alerting/on-call procedures.
- Sector-wide benchmarks and testbeds for continual VLA [Academia, Consortia]: Establish public lifelong learning suites with evolving tasks, standardized on-policy protocols, and shared leaderboards emphasizing retention and ZS. Tools: benchmark consortium, reproducibility kits, neutral evaluation servers. Dependencies: community buy-in, funding for maintenance, standard licensing.
Notes on feasibility across applications:
- The paper’s strong results depend on the synergy of three elements: large pretrained VLAs, parameter-efficient adaptation (LoRA), and on-policy RL with stable settings (e.g., GRPO, small learning rates). Removing any one significantly increases forgetting.
- Safety, reset/recovery mechanisms, and reward design remain critical for real-world training. Many immediate uses are easiest in simulation or controlled industrial cells before broad, open-world deployment.
- Tasks in the paper share observation/action spaces and use language-conditioned instructions; cross-domain deployments may require interface alignment and calibration layers.
- While the findings generalize across multiple VLA models and environment perturbations, real-world performance will depend on sim-to-real fidelity, sensing reliability, and hardware constraints.
Glossary
- Action chunking: Predicting short horizons of actions at each decision step instead of a single action, to improve control efficiency in VLAs. "A closely related variant uses action chunking, where the policy predicts short action horizons at each decision step rather than a single action, with OpenVLA-OFT as a representative example"
- Advantage function: In policy gradient RL, a value estimating how much better an action is compared to the policy’s baseline at a state. "where is the on-policy state distribution and is the advantage function."
- Autoregressive action generation: Producing actions token-by-token conditioned on observations and instructions, analogous to language generation. "A major family of models adopts autoregressive action generation: RT-1, RT-2, and OpenVLA discretize actions into tokens and decode them auto-regressively conditioned on images and task instructions."
- Catastrophic forgetting: Loss of performance on previously learned tasks after training on new ones in a sequential setting. "naive Sequential Fine-Tuning (Seq. FT) leads to catastrophic forgetting"
- Continual Reinforcement Learning (CRL): Reinforcement learning where an agent must learn sequentially across changing tasks while retaining past competence. "Continual Reinforcement Learning (CRL) for Vision-Language-Action (VLA) models is a promising direction toward self-improving embodied agents"
- Dark Experience Replay: A replay-based continual learning method that stores and reuses compressed representations of past experiences. "Expert Replay and Dark Experience Replay"
- Diffusion-based policies: Controllers that generate continuous actions by iteratively denoising samples from a diffusion process. "diffusion-based policies generate actions through iterative denoising"
- Dynamic Weight Expansion: A parameter-isolation approach that adds new parameters to accommodate new tasks while preserving old knowledge. "Dynamic Weight Expansion (parameter isolation)"
- Elastic Weight Consolidation: A regularization-based method that penalizes changes to parameters important to previous tasks using a Fisher-based penalty. "Elastic Weight Consolidation (regularization-based)"
- Expert Replay: A replay-based method that preserves performance by rehearsing stored expert demonstrations from prior tasks. "Expert Replay and Dark Experience Replay"
- Fisher Information Matrix (FIM): A matrix capturing parameter sensitivity; used to estimate how much changing parameters will affect performance on prior tasks. "and denote the Fisher Information Matrix (FIM) with respect to the pre-training tasks."
- Flow-matching head: A continuous-action policy head trained via flow matching, used to produce smooth action distributions. "Pi-0 adopts a flow-matching head built on a vision-language backbone as an alternative continuous-action VLA design"
- Forward KL divergence: The Kullback–Leibler divergence measuring how much the adapted policy deviates from the base policy’s support. "This necessarily increases the forward KL divergence"
- Forward Transfer (FWT): A metric assessing how learning earlier tasks helps performance on future tasks. "Forward Transfer (FWT), which measures generalization."
- Group Relative Policy Optimization (GRPO): A stable policy-gradient algorithm used for on-policy post-training of large models. "we use Group Relative Policy Optimization (GRPO), a stable policy-gradient method that has achieved strong empirical performance in large-scale post-training."
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning technique that injects low-rank updates into frozen weights. "simple Seq. FT with low-rank adaptation (LoRA) is remarkably strong"
- Markov Decision Process (MDP): A formal RL framework specifying states, actions, transitions, horizon, and rewards for a task. "We formulate each task in VLA post-training as a finite-horizon, language-conditioned Markov Decision Process (MDP):"
- Multi-task oracle: A performance upper bound obtained by joint training on all tasks simultaneously, violating the continual setting. "often surpasses the multi-task oracle."
- Nuclear norm: The sum of singular values of a matrix; used here to quantify the magnitude of weight updates. "The mean nuclear norm per layer is also lower for LoRA (0.259 vs. 0.609)"
- On-policy reinforcement learning: RL where data are collected from the current policy and used immediately for updates, limiting drift. "we adopt on-policy reinforcement learning throughout this work."
- Parameter-efficient fine-tuning (PEFT): Adapting large models by training a small set of additional parameters while keeping most weights frozen. "parameter-efficient fine-tuning (PEFT) methods, such as LoRA"
- Parameter isolation: Continual learning strategy that allocates separate parameters or modules to different tasks to avoid interference. "parameter isolation to constrain parameter updates."
- Policy-gradient method: An RL approach that adjusts policy parameters in the direction that increases expected return using stochastic gradients. "a stable policy-gradient method"
- Rayleigh quotient: A scalar measuring directional curvature with respect to a matrix; used here to quantify interference via the FIM. "We therefore compute the Rayleigh quotient of the Fisher Information Matrix along the gradient direction as"
- Regularization-based methods: Continual learning techniques that penalize parameter changes to reduce interference with previously learned tasks. "regularization-based methods that constrain parameter updates to reduce interference"
- Reinforcement Learning post-training (RL post-training): Applying RL after pretraining to refine and improve model behavior on downstream tasks. "RL post-training recently emerged as an effective methodology to refine and improve large pretrained Vision-Language-Action (VLA) models"
- Replay-based methods: Continual learning strategies that store and reuse past data or representations to mitigate forgetting. "replay-based methods that preserve and reuse past experience"
- Stabilityâplasticity dilemma: The trade-off between preserving old knowledge (stability) and rapidly learning new tasks (plasticity). "This trade-off between retaining past knowledge and remaining adaptable is known as the stabilityâplasticity dilemma"
- Zero-shot generalization: The ability of a model to perform on unseen tasks or conditions without additional training. "retains strong zero-shot generalization"
- Zero-Shot Success (ZS): An evaluation metric measuring how well pretrained capabilities are preserved after continual learning. "we introduce Zero-Shot Success (ZS) as a new metric"
Collections
Sign up for free to add this paper to one or more collections.