TacVLA: Contact-Aware Tactile Fusion for Robust Vision-Language-Action Manipulation
Abstract: Vision-Language-Action (VLA) models have demonstrated significant advantages in robotic manipulation. However, their reliance on vision and language often leads to suboptimal performance in tasks involving visual occlusion, fine-grained manipulation, and physical contact. To address these challenges, we propose TacVLA, a fine-tuned VLA model by incorporating tactile modalities into the transformer-based policy to enhance fine-grained manipulation capabilities. Specifically, we introduce a contact-aware gating mechanism that selectively activates tactile tokens only when contact is detected, enabling adaptive multimodal fusion while avoiding irrelevant tactile interference. The fused visual, language, and tactile tokens are jointly processed within the transformer architecture to strengthen cross-modal grounding during contact-rich interaction. Extensive experiments on constraint-locked disassembly, in-box picking and robustness evaluations demonstrate that our model outperforms baselines, improving the performance by averaging 20% success rate in disassembly, 60% in in-box picking and 2.1x improvement in scenarios with visual occlusion. Videos are available at https://sites.google.com/view/tacvla and code will be released.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to use “touch” (tactile sensing) along with vision and language to do tricky, contact-heavy tasks—like taking parts apart or grabbing items inside a box where the camera view is blocked. The authors build a system called TacVLA that adds touch to a popular kind of robot brain called a Vision-Language-Action (VLA) model. The big idea: let the robot turn on touch information only when it’s actually touching something, so it gets useful feedback without being distracted by noisy, irrelevant signals.
Key Objectives and Questions
The paper focuses on three simple questions:
- How can we make robots better at tasks where seeing is hard (because of shadows, blocking, or the robot’s own hand) and where careful physical contact matters?
- What’s a smart way to combine vision, language instructions, and touch so the robot understands when and how to use each sense?
- Does turning on “touch” only during contact (like a smart switch) make the robot more reliable and successful?
Methods and Approach (Explained Simply)
Think of the robot like a person following a recipe:
- Its “eyes” are cameras (front view and wrist view).
- Its “ears” are language instructions (like “press the clip and pull out the part”).
- Its “skin” is a small grid of touch sensors on the gripper finger that feel pressure.
Here’s how TacVLA works:
- Combining senses as tokens: The robot turns each input (images, words, and touch readings) into small chunks of information called “tokens.” You can think of tokens like LEGO bricks of information the robot can assemble and reason over.
- A transformer brain: The robot uses a transformer (a type of AI model) that can “pay attention” to the most important tokens from vision, language, and touch at each moment.
- Contact-aware gating (the smart switch): Touch is only helpful when the robot is actually touching something. So TacVLA has a simple “switch” that turns on touch tokens only when contact is detected (when enough little touch cells feel pressure). When there’s no contact, the touch tokens are turned off, so they don’t confuse the robot.
- Efficient touch encoding: Instead of treating touch like a big, heavy image, the touch grid is compressed into a small set of tokens. This keeps the robot fast and focused.
- Training: The team starts from a strong, pretrained VLA model and fine-tunes it with examples that include synchronized camera frames, instructions, touch readings, and the correct robot actions. They use a real robot arm (Franka Panda) with a tactile sensor on the gripper.
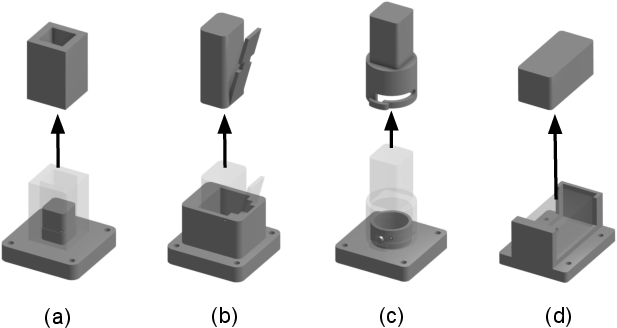
Tasks they tested:
- Four disassembly tasks with different physical tricks (pressing a clip, twisting, sliding) that require careful contact control.
- In-box picking, where the robot must find and grab an object inside a box with poor visibility—so touch is crucial.
Main Findings and Why They Matter
Here are the main results:
- Big improvements on contact-heavy tasks:
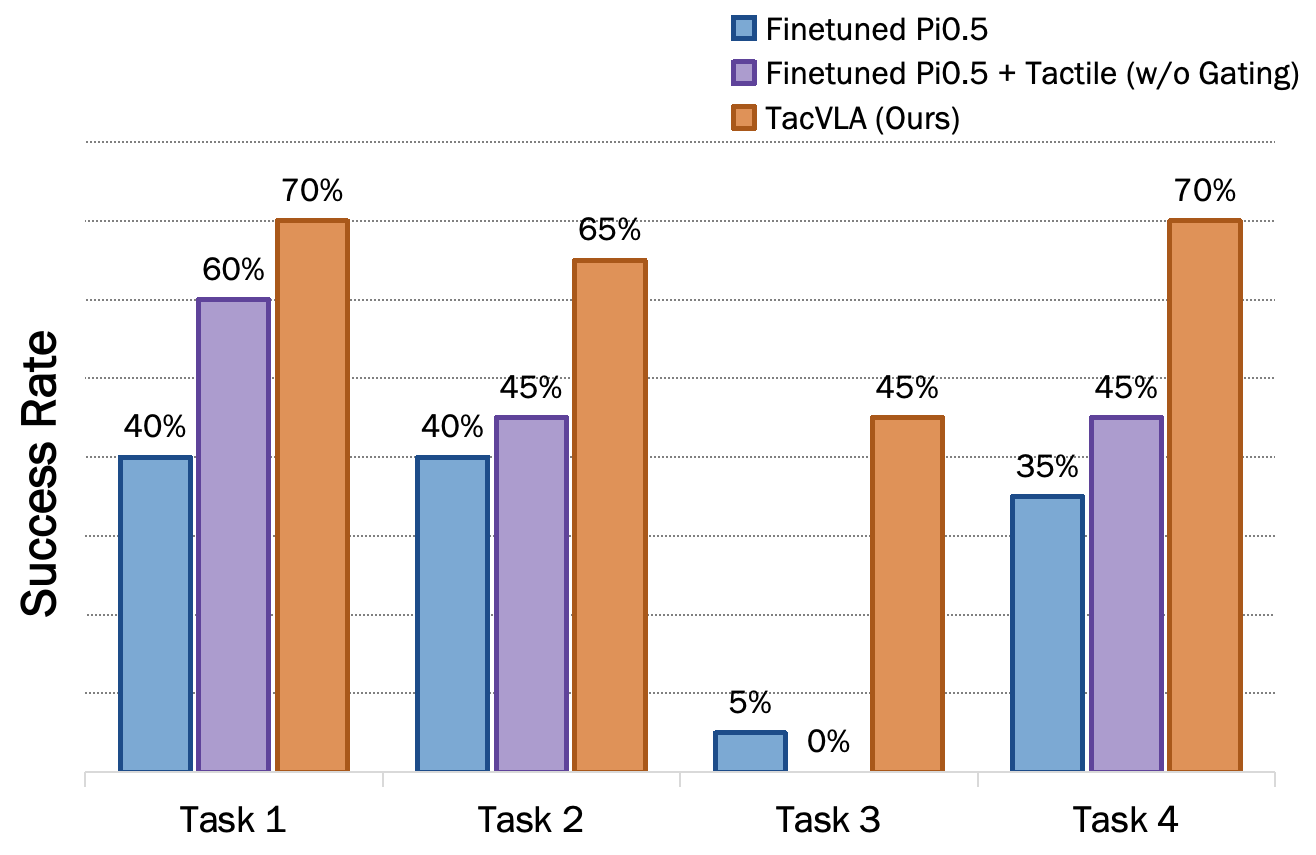
- Across four disassembly tasks, TacVLA achieved an average success rate of about 84%, beating a strong vision-language baseline (about 64%).
- The biggest jump was on the trickiest “slide pull” task (Task 4): TacVLA reached 75% vs. 30% for the baseline.
- Much better in hard-to-see situations:
- In the in-box picking task (lots of occlusion), TacVLA got 70% success vs. just 10% for the vision-language baseline.
- Robust under disturbances:
- When the front camera was blocked, TacVLA still worked much better than the vision-only model, showing it can rely on touch when vision fails.
- When a human moved the object mid-task, TacVLA noticed the change via touch, recovered, and completed the job; the baseline struggled.
- The “smart switch” for touch (gating) really helps:
- Without gating (always feeding touch to the model), performance dropped notably—down to 71% average on disassembly and 40% on in-box picking. This shows that using touch only during actual contact makes the model more stable and accurate.
- Better than diffusion-policy baselines:
- TacVLA outperformed two diffusion-based robot control methods that also had access to touch, especially in occluded settings.
Why this matters: Robots often fail when they can’t see well or need to control force precisely. Touch gives them the missing feedback to know “Am I gripping? Is it slipping? Is this stuck?” TacVLA uses touch in a focused, efficient way, making robots more dependable in the real world.
Implications and Potential Impact
- Smarter multimodal robots: TacVLA shows that adding touch—used at the right time—makes robots more capable in everyday, messy environments where cameras get blocked.
- Better industrial and home applications: Tasks like assembly, disassembly, drawer opening, cable routing, and picking from bins or boxes could be done more reliably by robots using this approach.
- Practical integration: The method is efficient (compact touch tokens) and simple (a clear contact rule), making it easier to add to existing VLA models.
- Foundation for future work: The authors note that their contact detector is a basic threshold (on/off). In the future, a learnable or gradual “volume knob” for touch could make robots even better at blending senses smoothly.
In short, TacVLA teaches robots to “feel” when they need to—and ignore touch when they don’t—leading to safer, steadier, and more successful manipulation in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Contact detection is a fixed, heuristic threshold on taxel counts; no sensitivity analysis, adaptive/hysteretic thresholds, or learned (soft/temporal) contact-state estimators are evaluated.
- Gating is strictly binary and tactile-only; there is no exploration of soft/learned modality gating (e.g., attention-based or MoE-style) conditioned on multimodal context, or of multi-level contact states (incipient contact, sustained contact, slip).
- The effect of contact misclassification on policy behavior is unquantified (e.g., false negatives causing tactile underuse, false positives injecting noise); no robustness study to contact detector noise/drift.
- Tactile encoder is frozen during fine-tuning with no described pretraining; the impact of end-to-end training, tactile pretraining objectives, or joint multimodal pretraining is unexplored.
- No analysis of tactile token design choices (token count, encoder architecture, positional encoding schemes) or their effect on performance, sample efficiency, and compute.
- Gating design choices (threshold value, required taxel count, masking vs zeroing, temporal smoothing) are not ablated; their contribution to stability and performance remains unclear.
- The approach assumes a single low-resolution tactile array on one finger; generalization to different tactile modalities (e.g., GelSight, force/torque, capacitive), sensor placements (both fingers, palm), or higher-resolution visuotactile inputs is untested.
- No study on multi-contact scenarios (e.g., distributed contact across multiple sensors) or region-specific gating (activating only tactile tokens corresponding to local contact areas).
- Tactile temporal dynamics (e.g., slip, vibration, force rate) are not modeled; only per-timestep tokens at 10 Hz are used, which may be too low for rich contact events.
- The policy fuses proprioception with language tokens, but the role and contribution of proprioception are not analyzed via ablations.
- Action representation, control horizon H, and closed-loop frequency are not specified or ablated; their effects on stability in contact-rich phases are unknown.
- Compute and latency claims (token efficiency from compact tactile tokens and gating) are not quantified; no measurements of inference time, throughput, or memory on the robot.
- Evaluation focuses on success rate only; there are no metrics for contact quality (forces, slip incidence), efficiency (time-to-completion), smoothness, number of re-grasps, or safety (peak forces).
- Robustness tests are limited: occlusion is only “front camera blocked” with wrist view available; no systematic variation in lighting, motion blur, sensor dropout, or tactile sensor corruption/failure.
- Human disturbance evaluation is anecdotal and single-scenario; no quantitative robustness across diverse disturbance types (object displacement, unexpected forces, tool collisions).
- Generalization is not measured: tasks are limited to four disassembly variants and one in-box picking on a single robot/gripper; no evaluation on unseen objects, materials/friction, shapes, or out-of-distribution environments.
- Cross-embodiment robustness is untested (e.g., different arms, end-effectors, compliance, kinematics); transfer to dexterous hands or soft grippers is unknown.
- Language grounding is evaluated with simple, fixed prompts; no tests of linguistic generalization (paraphrases, multi-step instructions, ambiguous commands), or how tactile improves language disambiguation.
- Data scale is small (50 demos per task) and collected via teleoperation; no study of sample efficiency, data scaling laws, or benefits of tactile under limited-data regimes.
- Training protocol fairness across baselines is unclear (e.g., different training budgets/objectives); no controlled comparisons isolating architecture vs data/training differences.
- No exploration of online adaptation or continual learning to address tactile sensor drift, wear, or changing contact properties over time.
- Safety considerations are not integrated (e.g., force limits, compliant control, variable impedance) despite contact-rich settings; how tactile cues could proactively enforce safety is open.
- Failure modes of TacVLA are not deeply analyzed; when and why it fails (e.g., soft contacts, deformables, high friction variance) remains unspecified.
- Integration of tactile with planning/hierarchical control is not explored; how to use contact events to trigger subtask transitions or re-planning is an open question.
- Multimodal fusion remains one-way (tactile gated by tactile); there is no study of gating/attenuation of visual or language tokens (e.g., down-weighting occluded views) for balanced cross-modal arbitration.
- Reproducibility details are incomplete (exact thresholds, LoRA ranks, learning rates, horizon, architecture specifics); robust replication and hyperparameter sensitivity analysis are needed.
Practical Applications
Overview
TacVLA introduces contact-aware tactile fusion into Vision-Language-Action (VLA) robotic policies. It tokenizes a compact tactile array and gates tactile tokens based on detected contact, enabling robust manipulation under visual occlusion and during fine-grained, contact-rich tasks. Demonstrations show strong gains in constraint-locked disassembly and in-box picking on a Franka Panda platform, with clear robustness under occlusion and human disturbance. Below are practical applications that leverage these findings, organized by deployment horizon.
Immediate Applications
The following items are deployable with current hardware, software stacks (e.g., OpenVLA/Pi0.5 backbones), and typical lab/industrial workflows.
- Robust “blind” in-box picking in logistics and warehousing
- Sector: Robotics (Supply Chain, E-commerce Fulfillment)
- Use case: Retrieve items from visually occluded bins/boxes where cameras have limited access or poor lighting; reduce mis-grasps and empty lifts.
- Tools/workflows: Tactile finger retrofits; TacVLA policy fine-tuned via LoRA on task demos; contact-aware gating to only act on tactile signals when confirmed contact occurs; ROS2 nodes integrating SigLIP camera streams, tactile encoder, and Pi0.5 action expert.
- Assumptions/Dependencies: Availability of compact tactile arrays; synchronized multi-modal data collection; per-site threshold calibration for contact detection; short-horizon task scripting via language prompts.
- Constraint-locked disassembly cells for electronics and small assemblies
- Sector: Manufacturing, Electronics Recycling (De-manufacturing)
- Use case: Press-clip release, shaft rotation, slide-pull extractions, and other contact-intensive separations; improved success rates and fewer stalls compared to vision-only policies.
- Tools/workflows: TacVLA-powered disassembly station; curated task prompts; teleoperation-to-LoRA fine-tuning of the policy; tactile gating to avoid token competition during approach and to leverage touch during separation.
- Assumptions/Dependencies: Object-specific demonstrations; gripper-compatible tactile sensor mounting; safety interlocks and force limits; consistent camera placement; job-specific threshold tuning.
- Retrofitting existing VLA manipulators with tactile gating
- Sector: Robotics (Systems Integration, Software)
- Use case: Add tactile arrays and a contact-aware gating module to existing Pi0.5/OpenVLA deployments to gain robustness under occlusion and contact-rich phases.
- Tools/workflows: “TacVLA Plugin” for multimodal tokenization and gating; LoRA adapters for fast fine-tuning; monitoring dashboards for contact-state and attention masks.
- Assumptions/Dependencies: Firmware/hardware interfaces for tactile sensors; inference latency budgets compatible with added modalities; model licenses and code release availability.
- Quality assurance protocols for occlusion robustness and disturbance recovery
- Sector: Industrial QA, Safety Engineering
- Use case: Formalize tests that block cameras or introduce human disturbances; certify that manipulation policies recover via tactile feedback before proceeding.
- Tools/workflows: Occlusion simulation fixtures; runtime disturbance scenarios; success-rate reporting; ablation testing (with/without gating).
- Assumptions/Dependencies: Access to evaluation scripts; standardized test suites; safety oversight for human-in-the-loop disturbance trials.
- Academic benchmarking and curriculum integration
- Sector: Academia (Robotics, Embodied AI)
- Use case: Replicate disassembly/in-box picking tasks; study gating vs. naïve tactile fusion; teach multimodal fusion principles and cross-modal grounding.
- Tools/workflows: Open dataset structure (10 Hz synchronized modalities); reproducible LoRA fine-tuning pipelines; ablation notebooks; tactile tokenization exemplars.
- Assumptions/Dependencies: Franka or comparable robot arms; two-camera setup; tactile sensor procurement; institutional compute resources.
- Software components for contact-aware multimodal fusion
- Sector: Software (Robotics SDKs, Middleware)
- Use case: Library modules providing compact tactile tokenization, contact-state detection, attention masking, and multimodal concatenation for transformer backbones.
- Tools/workflows: “Contact-aware Fusion SDK” with APIs for SigLIP/PaliGemma pipelines; telemetry hooks for contact flags; ROS2 integration.
- Assumptions/Dependencies: Maintenance of API compatibility with evolving VLM/VLA backbones; sensor driver stability; cross-platform support.
Long-Term Applications
These items require further research, scaling, validation, or regulatory approvals before broad deployment.
- Household assistive robots for cluttered, occluded environments
- Sector: Consumer Robotics
- Use case: Reliable retrieval from drawers, cabinets, backpacks; delicate operations like opening containers, unplugging connectors, or removing stuck items with tactile confirmation.
- Tools/workflows: Generalist TacVLA policies trained over diverse home tasks; language-guided plans; adaptive thresholds and learned modality weighting beyond binary gating.
- Assumptions/Dependencies: Robust generalization across objects and homes; affordable, durable tactile sensing; safety certification; low-latency on-device inference.
- Surgical and medical manipulation with touch-augmented policies
- Sector: Healthcare (Surgical Robotics, Rehabilitation)
- Use case: Tactilely informed palpation, gentle tissue manipulation, catheter insertion in visually constrained settings; language-guided workflows in operating rooms.
- Tools/workflows: Sterilizable high-resolution tactile sensors; validated contact-aware fusion under strict safety and reliability standards; surgeon-in-the-loop prompting.
- Assumptions/Dependencies: Regulatory clearance; clinical trials; higher spatial/force resolution tactile sensing; formal safety proofs; liability frameworks.
- Autonomous de-manufacturing and circular economy lines
- Sector: Manufacturing, Energy & Sustainability
- Use case: Adaptive disassembly of heterogeneous products; identification and separation of components under occlusion; tactile-assisted connector release strategies.
- Tools/workflows: Multi-product TacVLA policies integrated with vision-3D reconstruction; schedule-aware task prompts; tactile-driven failure recovery; ERP integration for parts tracking.
- Assumptions/Dependencies: Scalable data collection across SKUs; integration with product databases; robust handling of wear/variance; workforce upskilling.
- Human–robot collaboration with disturbance-aware recovery
- Sector: Robotics (Cobots, HRI)
- Use case: Safe task continuation when humans relocate objects mid-task; tactilely verified re-grasping; language feedback loops for correction.
- Tools/workflows: HRI policies combining contact-aware gating with variable impedance control; natural language clarification prompts; compliance modules (e.g., CompliantVLA-like adaptors).
- Assumptions/Dependencies: Standards for safe contact; learned modality weighting replacing hard thresholds; reliable intent recognition; workplace policies.
- Maintenance and inspection in visually challenging environments
- Sector: Energy, Infrastructure
- Use case: Valve operations, pipe fittings, connector manipulations in low-light or occluded spaces; tactilely driven exploration and verification before actuation.
- Tools/workflows: Mobile platforms with tactile fingertips; TacVLA policies augmented with SE(3)-equivariant 3D modules; occlusion-robust QA suites.
- Assumptions/Dependencies: Ruggedized sensors; environmental robustness; integration with digital twins; remote supervision.
- Standards and policy frameworks for multimodal safety in manipulation
- Sector: Policy/Regulatory
- Use case: Guidelines that encourage or require tactile sensing and contact-aware fusion for certain contact-rich tasks; reporting on occlusion robustness; incident logging with multimodal traces.
- Tools/workflows: Certification tests (occlusion, disturbance, contact verification); data governance standards for synchronized multimodal logs; procurement requirements for tactile-equipped systems.
- Assumptions/Dependencies: Consensus on benchmarks; industry adoption; regulatory bodies’ engagement; clear cost–benefit evidence.
- Education and open research ecosystems for multimodal manipulation
- Sector: Academia, Education
- Use case: Shared curricula and open benchmarks (disassembly, occluded picking) for training the next generation of roboticists in multimodal fusion and gating.
- Tools/workflows: Community datasets; standardized evaluation harnesses; open-source SDKs; competitions.
- Assumptions/Dependencies: Stable funding; accessible hardware; shared baselines across labs; ongoing maintenance.
Cross-cutting assumptions and dependencies
- Hardware: Availability and integration of compact tactile arrays compatible with common grippers; sensor durability and calibration workflows; multi-camera setups.
- Software: Access to pretrained VLM/VLA backbones (e.g., Pi0.5/OpenVLA) and LoRA fine-tuning; real-time inference on edge compute; ROS2/Middleware integrations.
- Data: Synchronized multimodal collection (vision, language prompts, tactile, proprioception) at sufficient rates; high-quality teleoperation demonstrations for fine-tuning.
- Method: Contact detection thresholds tuned to task/materials; potential need for learnable modality weighting (beyond binary gating) for complex/long-horizon tasks.
- Safety and compliance: Force/torque limits; human-in-the-loop protocols; certification for regulated environments (healthcare, heavy industry).
Glossary
- 3D Diffusion Policy: A diffusion-based visuomotor control method that operates on 3D representations to generate actions. "3D Diffusion Policy"
- 7-DoF: Seven degrees of freedom; describes a robot arm with seven independent joints/motions. "a 7-DoF Franka Emika Panda robotic arm"
- Action expert: The policy head that generates continuous actions conditioned on fused tokens. "The fused representation is then provided as a prefix to an action expert module"
- Attention mask: A mask that controls which tokens can attend to which others during attention computation. "We apply a contact-dependent attention mask"
- Contact mechanics: The study of forces and deformations at contacting surfaces relevant to manipulation. "It directly measures contact mechanics, normal and shear forces"
- Contact-aware gating mechanism: A module that activates tactile inputs only when contact is detected to avoid irrelevant interference. "we introduce a contact-aware gating mechanism that selectively activates tactile tokens only when contact is detected"
- Constraint-locked disassembly: Tasks where parts are constrained by geometry and require specific contact-rich motions to separate. "Extensive experiments on constraint-locked disassembly, in-box picking and robustness evaluations"
- Cross-attend: An attention operation where tokens from different modalities attend to each other. "allows vision, language, and tactile tokens to freely cross-attend"
- Cross-modal grounding: Aligning and binding information across modalities to support accurate action decisions. "to strengthen cross-modal grounding during contact-rich interaction."
- Cross-modal interaction: Information exchange between different sensory or representation modalities within a model. "inefficient cross-modal interaction"
- Diffusion Policy: A policy that generates actions via a denoising diffusion process conditioned on observations. "Diffusion Policy"
- Flow-matching objective: A training objective for generative modeling that matches probability flows, used here for action prediction. "which is trained with a flow-matching objective"
- GelSight: A vision-based tactile sensor that captures high-resolution surface contact images. "Vision-based tactile sensors such as GelSight provide high-resolution contact observations"
- Incipient slip: The onset of slipping at the contact interface detectable through tactile sensing. "incipient slip, and even acoustic feedback"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that adapts large models via low-rank updates. "We fine-tune TacVLA using Low-Rank Adaptation (LoRA)"
- MLP-based encoder: A lightweight multi-layer perceptron used to embed tactile measurements into token representations. "embedded using a lightweight MLP-based encoder"
- Modality arbitration: A mechanism that selects or weights modalities based on context or state (e.g., contact). "token-level modality arbitration conditioned on contact state"
- Modality tokenizers: Components that convert each input modality into token sequences for transformer processing. "the model consists of four components: modality tokenizers, a pretrained VLM backbone, and an action expert, and a contact-aware gating module."
- Multimodal fusion: Combining information from multiple modalities into a unified representation. "enabling adaptive multimodal fusion while avoiding irrelevant tactile interference."
- Multimodal token sequence: The concatenated sequence of tokens from different modalities at a given timestep. "Let the multimodal token sequence at time be"
- Non-causal attention mechanism: Attention without causal masking, allowing tokens to attend bidirectionally across the sequence. "A non-causal attention mechanism over this prefix allows"
- PaliGemma tokenizer: A tokenizer used to convert text (and here, language plus proprioception) into tokens. "tokenized using the PaliGemma tokenizer."
- Positional embeddings: Encodings added to tokens to preserve spatial or temporal order. "2D sine-cosine positional embeddings"
- Proprioception: Internal robot state measurements (e.g., joint positions/velocities) used as model inputs. "Language instructions along with robot proprioception are tokenized"
- SigLIP: A visual encoder pretrained with a sigmoid loss for language-image pretraining. "encoded using a SigLIP visual encoder"
- State-dependent modality routing: Dynamically enabling or suppressing modalities based on the current state (e.g., contact). "By preserving a fixed token topology while enabling state-dependent modality routing"
- Tactile array: A grid of tactile sensing elements that measures distributed contact pressures. "the tactile array"
- Tactile map: The 2D pressure distribution captured by a tactile array at a timestep. "project[s] the tactile map into 36 tactile tokens."
- Tactile tokens: Low-dimensional token representations derived from tactile signals for transformer processing. "selectively activates tactile tokens"
- Taxel: A single sensing element (tactile pixel) in a tactile array. "number of taxels exceeding a predefined pressure threshold"
- Teleoperation: Human-operated control of a robot to collect demonstration data. "each contains 50 demonstration collected by human teleoperation."
- Threshold-based criterion: A rule using fixed thresholds to detect events like contact from sensor signals. "Physical contact is detected using a threshold-based criterion"
- Token topology: The structural arrangement and positions of tokens within a sequence. "By preserving a fixed token topology"
- Transformer architecture: An attention-based neural network architecture used for multimodal processing. "within the transformer architecture"
- Transformer-based policy: A control policy implemented with transformer networks to process tokenized inputs. "incorporating tactile modalities into the transformer-based policy"
- VLA (Vision-Language-Action): A framework/models that integrate visual perception, language understanding, and action generation. "Vision-Language-Action (VLA) models have demonstrated significant advantages in robotic manipulation."
- VLM (Vision LLM): A model pretrained to jointly process and relate vision and language. "By integrating pretrained Vision LLMs (VLMs), these models can effectively interpret"
- Visual occlusion: When objects block the camera’s view, degrading visual information. "scenarios with visual occlusion."
- Visuomotor policies: Control policies mapping visual (and other) inputs to motor actions. "enhancing physical grounding of visuomotor policies."
- Visuotactile: Combining visual and tactile sensing for perception and control. "visuotactile manipulation policies"
Collections
Sign up for free to add this paper to one or more collections.