Towards Human-Like Manipulation through RL-Augmented Teleoperation and Mixture-of-Dexterous-Experts VLA
Abstract: While Vision-Language-Action (VLA) models have demonstrated remarkable success in robotic manipulation, their application has largely been confined to low-degree-of-freedom end-effectors performing simple, vision-guided pick-and-place tasks. Extending these models to human-like, bimanual dexterous manipulation-specifically contact-rich in-hand operations-introduces critical challenges in high-fidelity data acquisition, multi-skill learning, and multimodal sensory fusion. In this paper, we propose an integrated framework to address these bottlenecks, built upon two components. First, we introduce IMCopilot (In-hand Manipulation Copilot), a suite of reinforcement learning-trained atomic skills that plays a dual role: it acts as a shared-autonomy assistant to simplify teleoperation data collection, and it serves as a callable low-level execution primitive for the VLA. Second, we present MoDE-VLA (Mixture-of-Dexterous-Experts VLA), an architecture that seamlessly integrates heterogeneous force and tactile modalities into a pretrained VLA backbone. By utilizing a residual injection mechanism, MoDE-VLA enables contact-aware refinement without degrading the model's pretrained knowledge. We validate our approach on four tasks of escalating complexity, demonstrating doubled success rate improvement over the baseline in dexterous contact-rich tasks.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching robots to use their hands more like humans do. Instead of just grabbing and placing objects, the goal is to handle tricky, touch-heavy jobs—like peeling an apple, plugging in a charger, or assembling gears—using two hands and a sense of touch.
To do this, the authors combine:
- a “copilot” that controls the robot’s fingers during hard, in-hand moves, and
- a “robot brain” that sees, understands instructions, and plans actions while using touch and force feedback.
Together, these let the robot perform complex, human-like tasks more reliably.
The main questions the paper asks
The researchers focused on three big questions:
- How can we collect good training demonstrations for very complicated two-handed movements, which are hard even for skilled human operators?
- How can a robot switch between different kinds of skills during a long task (like “move the arm here,” “press with the right force,” “rotate the object in the hand”) without getting confused?
- How can a robot combine different senses—especially sight, force, and touch—so they help rather than overwhelm each other?
How they approached the problem
The team built both hardware and software to make learning and doing these tasks easier.
1) A shared-control teleoperation system with a finger “copilot”
- Teleoperation means a human operator controls the robot using an exoskeleton (like a wearable controller) and VR headset. The operator sees what the robot sees and moves the robot’s arms and fingers directly.
- The robot also shows live “touch” and “force” information in VR so the operator can feel what’s happening (like knowing how hard it’s pressing or if something is slipping).
- The new part: IMCopilot. It’s like cruise control for the robot’s fingers. When the operator hits a foot pedal, IMCopilot takes over finger-level skills that are hard for humans to do directly, such as rotating an apple inside the hand without dropping it.
- How IMCopilot learns: It is trained in a simulator with reinforcement learning (RL)—a trial-and-error method where the robot gets rewards for doing the right thing (e.g., rotating an object smoothly without slipping). It practices basic “atomic” skills like:
- keeping a stable grasp
- rotating an object in-hand around a chosen axis
- Once trained, IMCopilot helps both during data collection (to gather good demonstrations) and during autonomous runs (the robot can trigger the skill on its own when needed).
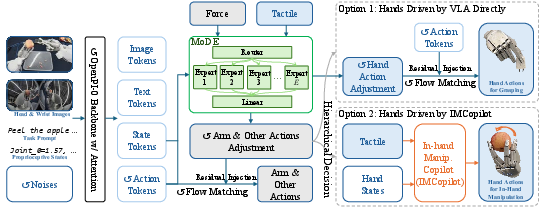
2) A “Mixture-of-Dexterous-Experts” model that uses sight, language, and touch
- The robot’s main “brain” is a Vision-Language-Action (VLA) model. Think of it as:
- Vision: looks at camera images
- Language: reads a simple instruction (like “plug in the charger”)
- Action: predicts what the robot should do next
- The problem: most existing VLA models only work well for simple grabbing tasks using sight. They ignore touch and force, which are crucial for delicate, contact-heavy actions.
- The solution: MoDE-VLA (Mixture-of-Dexterous-Experts VLA).
- “Experts” are like tiny specialists in a group. Some are good at early contact, some at steady pushing, some at fine finger adjustment, etc.
- Force and fingertip touch are processed in their own pathway (instead of being dumped into the main model). This respects that arm forces and fingertip touches mean different things.
- The model adds small “corrections” to the base plan using these touch/force signals—like a chef tasting a dish and adjusting seasoning. This avoids messing up what the base model already does well.
- Hierarchical control: At each moment, the system either:
- directly controls the hands using the VLA (improved with touch/force), or
- triggers IMCopilot to run a finely tuned finger skill (like in-hand rotation), while the VLA keeps controlling the arms.
What they tested and how
They evaluated the system on four tasks that get progressively more contact-heavy:
- Apple peeling (two hands): hold a peeler in one hand and an apple in the other; make repeated peel-and-rotate moves to peel a ring around the apple.
- Test tube rearranging (two hands): pick up a tube, hand it off to the other hand, and place it in a specific slot.
- Gear assembling (one hand): pick up gears and insert them onto shafts with the right alignment and pressure.
- Charger plugging (one hand): pick up a charger and plug it into a power strip.
They measured:
- Success Rate (SR): how often the robot finished the full task.
- Peel Completion Ratio (PCR): how much of the apple ring got peeled (in 25% steps), useful even if the robot didn’t fully finish.
The main results and why they matter
- Better teleoperation data with touch/force feedback:
- With force/touch overlays in VR, human operators made fewer mistakes and collected better demonstrations faster (e.g., more successes in the same time).
- IMCopilot made in-hand rotation much more reliable:
- Success at rotating objects in the hand jumped from 34% with plain teleoperation to 89% with IMCopilot.
- For example, for a small ping-pong ball, success went from 10% (teleop) to 83% (IMCopilot).
- The full MoDE-VLA system outperformed a strong baseline VLA:
- Average Success Rate across tasks rose from 15% (baseline) to 34% (ours).
- Apple peeling: baseline got only 8% peel completion on average; ours reached 73% and achieved 30% full-task success—likely the first autonomous dual-hand apple-peeling demo.
- Gear assembling: 40% → 60% success.
- Charger plugging: 5% → 15% success.
- Tube rearranging: 15% → 30% success.
- Why the improvements happened:
- Force sensing helped detect contact and adjust pressure during insertions.
- Fingertip touch reduced slipping and improved grasp control.
- The MoDE design kept touch/force from confusing the vision-LLM by treating them as separate, specialized inputs and then adding small corrections.
- IMCopilot handled the hardest finger maneuvers (like in-hand rotations), so the main model didn’t have to learn everything at once.
What this means going forward
This research shows a promising path toward robots that use their hands more like humans:
- Mixing look-and-plan intelligence with a sense of touch leads to better control in tight, contact-heavy tasks.
- Letting a “copilot” handle the hardest finger skills makes both training and real use more reliable.
- The approach could be extended to other delicate jobs—like threading, buttoning, tool use, or home-care tasks—where precise touch and multi-step actions are essential.
In short, combining strong vision-LLMs, smart use of touch and force, and a trained “finger copilot” moves robots closer to truly human-like hand skills.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, concrete list of what remains uncertain or unexplored in the paper, framed to guide actionable future research.
- Temporal modeling of contact modalities:
- Force and tactile inputs are replicated from a single-frame snapshot across the action horizon, which ignores their fast temporal dynamics and delays. How would multi-rate, history-aware fusion (e.g., temporal convolution, recurrent modules, or transformers with multi-frequency sampling) affect performance?
- Sensor synchronization and calibration:
- The work does not detail time alignment among RGB, joint torque, and fingertip tactile streams, nor calibration procedures and drift compensation. What is the sensitivity of MoDE-VLA to misalignment and sensor bias/noise?
- Limited skill repertoire in IMCopilot:
- Only two atomic skills (grasp maintenance and rotation) are provided. How to expand to a broader library (e.g., finger gaiting, controlled rolling, regrasping, pivoting, tool reorientation) and automatically discover/learn these skills?
- Skill parameterization and generality:
- Rotation is specified around a given axis; it is unclear how general parameterization (angle, axis, speed, object shape/size) is handled or learned from language. Can IMCopilot skills be language- or vision-parameterized for broader applicability?
- Arbitration between VLA and IMCopilot:
- The scalar trigger c (>0.5) is used to switch to IMCopilot, but the supervision of c, decision policy training, and stability/safety of switching are not described. Can a learned option-critic or hierarchical RL policy improve when and how to switch?
- Bimanual skill invocation:
- IMCopilot is only used for one hand in one task (apple peeling). How does the approach extend to multi-skill, dual-hand coordination (e.g., simultaneous in-hand adjustments in both hands, coordinated finger-object exchanges)?
- Robustness and generalization:
- Evaluations are limited to four tasks with 20 trials each, and average SR remains modest (34%). How does the system generalize to new objects, textures, friction, geometries, and tools, or to perturbations, occlusions, and sensor failures?
- Operator variability and user study:
- Cognitive load reduction via shared autonomy is claimed but not quantified across operators. How do performance and data quality vary with user expertise, and what is the impact on scalability?
- Dataset scale, composition, and release:
- The number of demonstrations per task, task distribution, and data diversity are not reported. Is the dataset (with trigger annotations) released, and how does dataset size/composition affect learning curves and generalization?
- Baseline breadth:
- Comparisons are only against π0. There is no head-to-head evaluation with force/tactile-aware VLAs (e.g., ForceVLA, TA-VLA, Tactile-VLA) or fast–slow refinement architectures. Do the proposed gains hold against these stronger baselines?
- MoDE design ablations:
- The contribution of sparse MoE vs. a single shared MLP, residual injection vs. direct concatenation, the number of experts E, and top-k routing are not ablated. How do these choices affect performance, routing specialization, and stability (e.g., expert collapse, load-balancing)?
- Multi-rate fusion:
- Force/tactile typically run at higher frequency than vision. The paper does not explore multi-rate conditioning or asynchronous fusion. Can explicitly modeling different sampling rates improve responsiveness and contact handling?
- Control and safety considerations:
- The controller relies on PD tracking and residual action corrections; variable impedance or hybrid position–force control is not explored. How do different low-level control schemes influence safety, stability, and success in knife/peeler tasks?
- Inference latency and control frequency:
- The method uses flow-matching denoising with N=10 steps but does not report latency, cycle time, or throughput. What are the real-time constraints, and how does latency affect contact stability?
- Tactile signal richness:
- Fingertip sensors are reduced to 6-DoF force/wrench via API; raw tactile images (if available) are not leveraged. Would modeling richer tactile images or contact geometry yield better slip detection and in-hand precision?
- Failure mode taxonomy:
- The paper reports success metrics but lacks detailed error analysis (e.g., slip, misalignment, excessive force, premature switching). Which failures dominate, and how can they inform targeted improvements?
- Language grounding:
- Despite using a VLA backbone, language generalization (paraphrases, multi-step instructions, ambiguous references) is not studied. How well does the system follow varied natural language commands for dexterous tasks?
- Learning to trigger sub-skills from language/vision:
- It is unclear how demonstrations annotate the IMCopilot-trigger times and whether the model learns this from language/visual cues. Can supervisory signals for skill boundaries be automatically inferred (e.g., through segmentation or inverse RL)?
- Sim-to-real quantification for IMCopilot:
- The RL skills use domain randomization for zero-shot transfer, but systematic sim-to-real metrics across objects, friction regimes, and long-term use are not provided. What are the failure cases of sim-to-real and how to reduce the gap?
- Reproducibility across hardware:
- The approach is evaluated on a specific dual-arm, dual-hand platform with proprietary sensors. How transferable are the models and skills to other hand morphologies, different tactile sensors, or lower-DoF hands?
- Multi-task vs. per-task training:
- It is not specified whether a single MoDE-VLA is trained across tasks or per-task fine-tuning is used. How does multi-task training affect interference, forgetting, and generalization?
- Data collection mismatch:
- Wrist cameras are used for training but not shown to the teleoperator; potential mismatch between operator guidance and policy perception is not analyzed. Does this induce biases or suboptimal demonstrations?
- Safety with sharp tools:
- Tasks involve a peeler; there is no discussion of safety envelopes, force/torque thresholds, or failure containment policies. What safeguards are required to deploy such policies in unconstrained environments?
- Action integration and stability:
- Euler integration with N=10 is used for flow-matching inference; other samplers or adaptive step sizes are not explored. How do numerical integration choices impact policy stability during contact?
- Continual learning and adaptation:
- The framework does not include on-robot adaptation (DAgger, online IL, or RL fine-tuning). Can contact-aware continual learning improve long-horizon robustness without catastrophic forgetting?
- Skill discovery and modularity at scale:
- Beyond manual definition of two primitives, how can the system autonomously discover, name, and reuse sub-skills, and learn modular interfaces (APIs) for large libraries of dexterous behaviors?
These gaps suggest concrete avenues for improving temporal fusion, hierarchical gating, skill breadth, robustness, and reproducibility of RL-augmented teleoperation and force/tactile-aware VLA models for dexterous manipulation.
Practical Applications
Immediate Applications
The paper’s RL-augmented teleoperation and MoDE-VLA fusion methods can be deployed today to enhance contact-rich manipulation in settings where high-DoF hardware and force/tactile sensing are available. Below are concrete use cases, linked to sectors and anticipated tools/workflows, with key dependencies noted.
- Shared-autonomy teleoperation to boost operator performance in contact-rich tasks (Robotics; Manufacturing, Lab Automation)
- Use IMCopilot’s atomic skills (e.g., in-hand rotation, grasp stabilization) as pedal-triggered assistance during VR/exoskeleton teleop to reduce cognitive load and improve success in insertion, swapping, and hand-off routines.
- Tools/workflows: VR overlays for force/tactile feedback; vibrotactile fingertip cues; skill-trigger UI (foot pedals); logging pipelines that record synchronized RGB, proprioception, torques, and tactile for dataset creation.
- Dependencies: Access to exoskeleton or glove-based teleop; fingertip tactile and joint torque sensing; safety-rated control stack; operator training.
- Data collection pipelines with skill-level assistance for high-DoF demonstrations (Academia; Robotics R&D)
- Replace difficult hand phases in demonstrations (e.g., in-hand rotation during bimanual tasks) with IMCopilot to obtain higher-fidelity trajectories faster.
- Tools/workflows: Demonstration capture suite integrating skill invocation markers; automatic segmentation by skill phase for hierarchical learning; IsaacLab-based RL training for atomic skills with domain randomization.
- Dependencies: High-DoF hands; simulator-to-real calibration; reproducible exoskeleton retargeting.
- Retrofitting existing VLA policies with contact-aware residual refinement (Software/Robotics; Platforms using pi_0/OpenVLA-like backbones)
- Integrate MoDE-VLA’s dedicated force/tactile pathway and sparse expert routing as a drop-in residual module to improve insertion, alignment, and force-regulated phases without erasing pretrained visual-language capabilities.
- Tools/workflows: Plugin/module for residual injection heads (separate arm/hand projections); top-k routed MoE for per-timestep specialization; minimal retraining on contact-rich data.
- Dependencies: Availability of force (arm torques) and tactile (fingertip wrenches) streams; synchronized high-rate sensing; compute for training/inference.
- Benchmarking and skill libraries for in-hand manipulation (Academia; Open-source robotics communities)
- Publish and reuse RL-trained atomic skills (grasp maintenance, in-hand rotation) and evaluation protocols (e.g., rotation success across objects) to standardize dexterous skill research.
- Tools/workflows: Skill API callable from higher-level policies; standardized metrics (success rate, completion ratio); dataset schemas that include tactile/force.
- Dependencies: Consistent interfaces for dexterous hands; licensing and reproducibility of hardware/software stacks.
- Improved laboratory and small-part handling with contact cues (Industry; Lab Automation, Electronics QA)
- Deploy MoDE-VLA for test tube rearrangement, charger/connector plugging, and small-gear insertion where force onset detection and slip prevention are critical.
- Tools/workflows: Station-level cells with multi-view cameras and tactile fingertips; task templates and prompts for VLA; safety envelopes and compliance limits.
- Dependencies: Robust calibration of tactile sensors; jigs/fixtures for repeatability; throughput requirements compatible with current success rates.
- Operator training and upskilling with tactile/force-informed VR (Education; Corporate training)
- Use the VR teleop system with real-time contact overlays to teach safe, compliant manipulation, and to quantitatively assess skill acquisition.
- Tools/workflows: Training curricula that progress from free-space to contact-rich phases; replay and analytics of force/tactile traces; competency scoring.
- Dependencies: Training hardware availability; ergonomics and fatigue management; standardized scenarios.
Long-Term Applications
Scaling the framework and broadening hardware access can enable autonomy and shared autonomy in more complex, safety-critical, or consumer-facing domains. The following use cases require further research, scaling, or engineering.
- Autonomous bimanual service robots for home and hospitality tasks (Service Robotics; Daily Life)
- Tasks like peeling fruit, preparing ingredients, tidying and organizing, plugging appliances, and manipulating diverse household items with in-hand dexterity.
- Potential products/workflows: Household robots with dexterous hands and tactile fingertips; hierarchical controllers where VLAs plan and IMCopilot-like skills execute fine manipulation.
- Dependencies: Cost-effective, reliable high-DoF hands; robust generalization across objects/surfaces; strong safety, compliance, and perception in unstructured environments.
- Flexible small-batch assembly without rigid fixturing (Manufacturing; Electronics, Medical Devices)
- Use MoDE-VLA’s contact-aware refinement and modular skill libraries to replace or reduce task-specific jigs for tight-tolerance insertions and assemblies.
- Potential products/workflows: “Skill packs” for common insertions (USB, press-fit, threaded) with automatic routing to force/tactile experts; quick changeovers via language prompts.
- Dependencies: High repeatability and cycle-time guarantees; traceability and quality inspection; vendor-agnostic tactile/force interfaces.
- Remote maintenance in hazardous or hard-to-reach environments with shared autonomy (Energy, Utilities, Aerospace, Nuclear)
- Operators teleoperate bimanual robots with IMCopilot assisting on fine manipulation (valve turning, connector mating, cable routing), reducing fatigue and increasing reliability.
- Potential products/workflows: Ruggedized teleop kits; low-latency comms with predictive displays; safety-certified shared-autonomy gating of skills.
- Dependencies: Network latency/robustness; fail-safes and compliance; environmental hardening of tactile sensors.
- Assistive and healthcare robotics for activities of daily living (Healthcare; Elder care, Rehabilitation)
- Assisting with dressing, feeding preparation, or device handling where gentle, contact-aware manipulation is essential.
- Potential products/workflows: Assistive manipulators with compliant tactile fingertips; personalized skill libraries adapted to user-specific needs; clinician-in-the-loop tele-assist.
- Dependencies: Clinical validation; rigorous safety and hygiene standards; regulatory approvals; intuitive user interfaces.
- Scalable multimodal VLA ecosystems and standards (Policy & Standards; Software/Robotics)
- Establish standard formats for force/tactile data, benchmarks for contact-rich VLAs, and safety frameworks for shared autonomy and residual correction modules.
- Potential initiatives: Interoperable APIs for tactile/force sensors across vendors; certification guidelines for contact-aware autonomy; datasets and leaderboards for dexterous benchmarks.
- Dependencies: Cross-industry collaboration; consensus on metrics and testbeds; governance for data sharing and IP.
- Continual learning of dexterous “mixture-of-experts” skills in the open world (Academia; Long-horizon autonomy)
- Expand MoDE to larger expert pools, online routing, and lifelong skill acquisition from teleop and self-practice, enabling broad generalization across tasks and materials.
- Potential workflows: On-robot self-supervision for contact regimes; automated discovery of new experts; hierarchical policy distillation.
- Dependencies: Safe exploration in contact-rich settings; catastrophic forgetting mitigation; scalable data infrastructure.
- Affordable tactile-dexterous hardware for mass deployment (Hardware Ecosystem; Cross-sector)
- Reduce cost/complexity of high-DoF hands and robust tactile sensors to make contact-aware manipulation economically viable for SMEs and consumer markets.
- Potential products: Modular dexterous end-effectors with standardized tactile arrays; calibration and self-diagnosis toolchains.
- Dependencies: Manufacturing advances; durability and maintenance; supply chain maturity.
Assumptions and cross-cutting dependencies for feasibility:
- High-DoF dexterous hands with reliable tactile sensing and arm torque readouts are central to performance; availability and robustness remain gating factors.
- Accurate calibration and synchronization across vision, force, tactile, and proprioception streams are required for MoDE-VLA’s residual corrections to be effective.
- Safety, compliance control, and fail-safe gating are mandatory for contact-rich deployment, particularly in human-adjacent environments.
- Compute and data requirements (for flow-matching VLAs and MoE routing) must be matched with real-time constraints; edge acceleration or efficient distillation may be necessary for production.
Glossary
- Action horizon: The number of future timesteps for which the policy predicts actions. "where is the action horizon and the action dimension"
- Asymmetric actor-critic: A reinforcement learning setup where the critic has access to more information (e.g., privileged state) than the actor to stabilize training. "employing an asymmetric actor-critic architecture"
- Cross-attention: A transformer mechanism where one token sequence attends to another (e.g., actions attend to vision-language tokens). "they share key-value pairs through cross-attention across all transformer layers."
- Degree of Freedom (DoF): An independent coordinate of motion in a robot’s kinematic structure. "teleoperating a bimanual system with 63 DoFs is highly challenging,"
- Denoising state: The current noise level or intermediate state during generative denoising/integration in flow matching. "the current denoising state"
- Domain randomization: Training technique that randomizes simulation parameters to improve generalization and sim-to-real transfer. "we apply domain randomization over object scale, mass, friction, center-of-mass offset, gravity, and PD gains."
- Euler's method: A numerical integration scheme used here to integrate the learned velocity field from noise to action. "via Euler's method with steps"
- Exoskeleton: A wearable robotic interface that maps human motions/forces to a robot for teleoperation. "Exoskeleton-based teleoperation interfaces mechanically couple human and robot joints,"
- Flow-matching loss: An objective for training models to learn a velocity field that transports noise to data distributions. "The training objective minimizes the flow-matching loss"
- IMCopilot (In-hand Manipulation Copilot): A suite of RL-trained low-level dexterous hand skills used for shared autonomy and callable primitives. "we introduce IMCopilot (In-hand Manipulation Copilot), a suite of reinforcement learning-trained atomic skills"
- In-hand manipulation: Dexterous control of an object within the hand by coordinating fingers and contacts. "in-hand manipulation skills to rotate the apple between successive cuts."
- IsaacLab: A robotics simulation environment used for physics-based RL training. "within the IsaacLab~\cite{mittal2025isaaclab} simulation environment"
- Mixture-of-Dexterous-Experts (MoDE): An MoE-based module that routes force/tactile tokens to specialized experts for contact-aware refinement. "MoDE-VLA (Mixture-of-Dexterous-Experts VLA)"
- Mixture-of-Experts (MoE): An architecture with multiple expert networks where a router selects a subset per input token. "Mixture-of-Experts layer comprising expert MLPs with top- scatter routing"
- PaliGemma: A vision-language transformer backbone used to fuse image and text tokens. "a PaliGemma vision-LLM (Gemma-3B~\cite{beyer2024pali})"
- PD controller: A proportional-derivative control loop used to track joint targets in low-level control. "tracked by low-level PD controllers."
- Privileged information: Additional state (e.g., object pose, friction) available during training to the critic/teacher but not at deployment. "both actor and critic receive privileged information "
- Proprioception: Internal sensing of the robot’s joint states and motions used as input to policies. "a 3-step history of proprioception"
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that constrains updates via clipped objectives. "Each skill is trained using Proximal Policy Optimization (PPO)~\cite{schulman2017ppo}"
- Residual injection: Adding learned corrections to base model predictions without overwriting pretrained capabilities. "By utilizing a residual injection mechanism, MoDE-VLA enables contact-aware refinement"
- Self-attention: A transformer operation where tokens within a sequence attend to each other to compute contextualized representations. "Forceâtactile tokens interact with backbone representations through self-attention,"
- Shared autonomy: A paradigm where control is shared between a human and an autonomous assistant. "it acts as a shared-autonomy assistant to simplify teleoperation data collection,"
- SigLIP: A vision embedding model/tokenizer used to convert images into token sequences. "a SigLIP~\cite{zhai2023sigmoid} vision tokenizer (So400m/14)"
- Sim-to-real transfer: Techniques enabling policies trained in simulation to perform effectively on real robots. "zero-shot sim-to-real transfer"
- Sinusoidal step-positional encodings: Periodic embeddings added to tokens to encode their temporal positions across the action horizon. "sinusoidal step-positional encodings"
- Sparse MoE routing: Routing tokens to only a few selected experts to specialize computation and reduce cost. "are refined via sparse MoE routing~\cite{shazeer2017outrageously} for per-timestep expert specialization"
- Teacher-student distillation: Training a student policy to mimic a teacher that has access to richer information. "teacher-student distillation~\cite{qi2022hora}"
- Teleoperation: Remote control of a robot by a human operator, often via motion/force retargeting. "Teleoperation is fundamental to data-driven dexterous manipulation,"
- Top- scatter routing: An MoE mechanism that assigns each token to the top-k experts according to router scores. "top- scatter routing~\cite{shazeer2017outrageously, riquelme2021scaling}"
- Velocity field: A vector field learned to transform noisy actions toward clean actions in flow matching. "the model predicts a velocity field "
- Vibrotactile feedback: Tactile cues delivered through vibration to convey contact events to the human operator. "The exoskeleton gloves also provide vibrotactile feedback to each fingertip"
- Vision-Language-Action (VLA): Models that map visual and language inputs to robot action outputs. "Vision-Language-Action (VLA) models have demonstrated remarkable success in robotic manipulation,"
- Wrench: A 6D vector combining forces and torques measured at a contact. "6-DoF force and wrench readings"
Collections
Sign up for free to add this paper to one or more collections.

