- The paper introduces AVR, a method that routes tool calls to the minimal VLM needed to meet reliability and safety thresholds.
- It employs multimodal difficulty classification, confidence probing, and memory injection to achieve cost savings and high grounding accuracy.
- Empirical results show up to 78% cost reduction with near-optimal accuracy, challenging scale-as-panacea paradigms in VLM deployment.
Adaptive Vision-LLM Routing for Computer Use Agents: A Technical Summary
Introduction
The proliferation of Computer Use Agents (CUAs) capable of interpreting GUI screenshots and converting natural-language instructions into actionable tool calls has rapidly accelerated the deployment of vision-LLMs (VLMs) into dynamic, interactive environments. However, experiments reveal that a uniform application of a single, frontier-scale VLM is inefficient: grounding accuracy does not reliably scale with model size, and action-difficulty heterogeneity within desktop environments results in significant waste when every tool call is routed through a large, expensive backbone. The paper "Adaptive Vision-LLM Routing for Computer Use Agents" (2603.12823) introduces Adaptive VLM Routing (AVR), a semantically guided, cost-accuracy tradeoff framework that dynamically assigns tool calls to the minimal model required to maintain specified reliability and safety thresholds.
Motivation: Scaling Laws and Heterogeneity
Grounding accuracy on standardized benchmarks such as ScreenSpot-Pro shows weak correlation with VLM scale for GUI agents. Specialized 7B models demonstrably outperform generalist VLMs two orders of magnitude larger, and even within homogeneous model families, scaling yields diminishing accuracy returns. The dominant source of variance is not model size but per-action difficulty—complex, small UI elements and dense toolbars present orders-of-magnitude more challenge than large, labeled interface components.
(Figure 1)
Figure 1: Model size vs. grounding accuracy on ScreenSpot-Pro (log scale). Generalist models (squares) cluster near zero, while 7B GUI specialists (circles) outperform much larger generalists; sublinear accuracy gains are seen with increasing size within the Qwen2.5-VL family (triangles).
This heterogeneity in required model capability underpins the core AVR insight: computational expenditure should track instantaneous action difficulty, not task average.
AVR Architecture and Routing Methodology
AVR inserts a lightweight semantic router between the agent orchestrator and a VLM pool, mediating each tool call’s allocation based on three signals: difficulty classification, model confidence estimation, and memory-compensated context. The process unfolds in three main steps:
- Multimodal Difficulty Classification: Each action’s projected target region and natural language description are embedded and compared against knowledge bases of easy and hard prototypes, delivering a conservative difficulty estimate.
- Confidence-Based Probing: The cheapest VLM is non-generatively probed with logprob scoring; if confidence exceeds a difficulty-adaptive threshold, the action is executed without escalation.
- Warm-Agent Memory Injection: For agents with interaction history, retrieved contextual memories are concatenated to the input, substantially improving low-capability model confidence for context-dependent elements.
The routing policy is formalized as a constrained optimization over cost and target accuracy. Difficulty-adaptive thresholds, modulated between τeasy and τhard, further refine the acceptance and escalation balance.
Empirical Evidence and Analysis
Cost-Accuracy Tradeoff
Analytical cost modeling indicates that retaining 60–90% of calls on a small, cheap model while escalating only uncertain or complex actions yields dramatic cost reductions, even under conservative threshold settings, while preserving near-optimal grounding accuracy.
(Figure 2)
Figure 2: Projected cost per CUA tool call across AVR configurations. Cold routing (no memory) achieves 52% savings; warm routing with difficulty classification projects 78%.
Empirical results from the OpenClaw benchmark (albeit for text agents) validate this tradeoff: confidence-based routing with memory augmentation enables 86% of all queries to be retained on a 7B model without degradation, as knowledge-dependent uncertainty is sharply separated post-memory injection.
(Figure 3)
Figure 3: Confidence score distribution for 5 knowledge-dependent queries. Cold agents (blue) cluster below the threshold, triggering escalation; warm agents (green) cluster well above—memory injection creates a bimodal separation.
Memory as a Model Size Equalizer
Memory injection, by encoding prior successful and failed interactions, is found to be highly asymmetric in benefit: smaller models often cross the routing acceptance threshold with appropriately injected context, whereas large models are marginally affected. The anticipated progression follows a logarithmic "warming curve," where most savings are realized after only a handful of interactions per application.
(Figure 4)
Figure 4: Hypothetical warming curve projected from OpenClaw memory pattern—early interactions provide most information gain for memory compensation.
Difficulty-Driven Application Variance
Per-application variance dramatically exceeds per-model variance in grounding benchmarks. Application-specific UI complexity can create a 7x accuracy gap for a fixed model, underpinning the criticality of per-action routing and the inefficiency of static backbone selection.
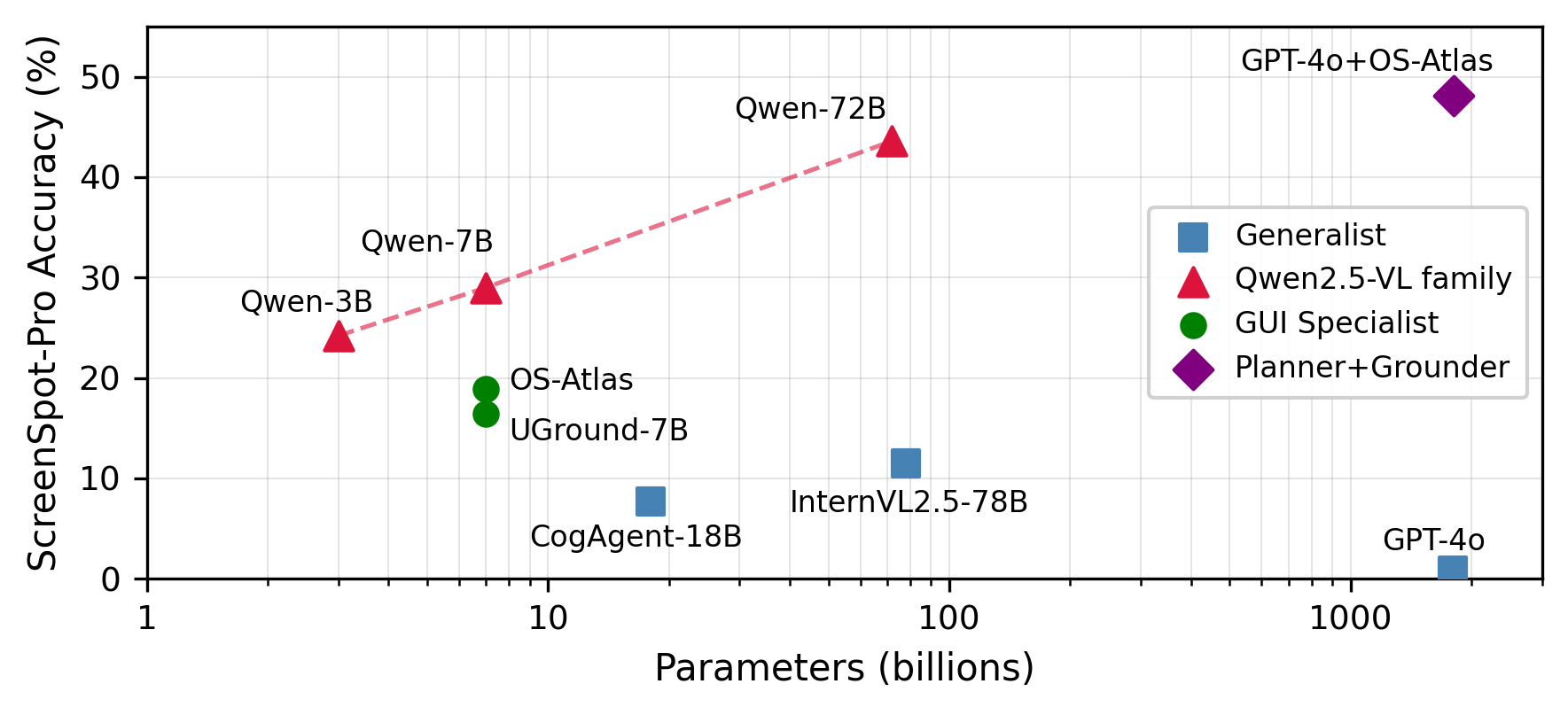
Figure 5: Per-application accuracy distribution. Dashed lines indicate Qwen2.5-VL family averages (29.0% for 7B, 43.6% for 72B), while individual applications vary widely.
Safety Integration via the Visual Confused Deputy
AVR is extended with a safety override through integration with the Visual Confused Deputy guardrail, which deploys contrastive knowledge-base classification to detect potentially harmful or ambiguous actions. Actions flagged as risky are routed, regardless of cost, to the most competent available model and subjected to guardrail verification—a unified policy enforcing both economic and security constraints.
Practical and Theoretical Implications
Practical Implications
- Scalable Deployment: For large-scale, production CUA deployments, particularly those with steady workloads in enterprise automation or accessibility domains, AVR achieves 52–78% projected inference cost savings while maintaining accuracy within 2 percentage points of large-model-only use.
- Latency Considerations: Probing introduces a minor latency penalty (hundreds of milliseconds), but retention on the small model more than compensates in aggregate. Savings accrue mainly on longer interaction sequences.
Theoretical Significance
- Challenging Scale-Centric Paradigms: The lack of monotonic accuracy improvement with size refutes the common scale-as-panacea hypothesis for visual grounding and supports specialization or routing as key deployment strategies.
- Memory as Capacity Amplifier: The finding that memory injection functionally equalizes capability on knowledge-dependent tasks, especially in smaller models, extends recent memory-augmented agent literature and suggests that true visual reasoning (not just recall) delimits model sufficiency.
- Dynamic Inference Allocation: The reformulation of CUA inference as an action-level routing and allocation problem enriches agent orchestration frameworks and may generalize to other highly heterogeneous task distributions.
Limitations
- Direct measurement of cost/accuracy projections in end-to-end CUA scenarios is currently absent; real-world evaluation is required.
- Probe cost is proportional to screenshot size, providing diminishing savings for very low-action-count sessions or enormous image inputs.
- Cold-start agents without pre-existing memory will realize lower initial benefits; pre-seeding and KB coverage are future challenges.
Conclusion
AVR redefines VLM orchestration for computer-use agents by explicitly harnessing per-action heterogeneity, economically exploiting memory, and fusing safety cues into the routing process. The approach operationalizes fine-grained, adaptive model selection, delivering substantial cost reductions without sacrificing reliability or security. The future trajectory includes end-to-end policy learning, more granular memory management, and application to larger, more heterogeneous model pools and real-world CUAs.
References
(2603.12823)

