M$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
Abstract: Transformers are highly parallel but are limited to computations in the TC$0$ complexity class, excluding tasks such as entity tracking and code execution that provably require greater expressive power. Motivated by this limitation, we revisit non-linear Recurrent Neural Networks (RNNs) for language modeling and introduce Matrix-to-Matrix RNN (M$2$RNN): an architecture with matrix-valued hidden states and expressive non-linear state transitions. We demonstrate that the language modeling performance of non-linear RNNs is limited by their state size. We also demonstrate how the state size expansion mechanism enables efficient use of tensor cores. Empirically, M$2$RNN achieves perfect state tracking generalization at sequence lengths not seen during training. These benefits also translate to large-scale language modeling. In hybrid settings that interleave recurrent layers with attention, Hybrid M$2$RNN outperforms equivalent Gated DeltaNet hybrids by $0.4$-$0.5$ perplexity points on a 7B MoE model, while using $3\times$ smaller state sizes for the recurrent layers. Notably, replacing even a single recurrent layer with M$2$RNN in an existing hybrid architecture yields accuracy gains comparable to Hybrid M$2$RNN with minimal impact on training throughput. Further, the Hybrid Gated DeltaNet models with a single M$2$RNN layer also achieve superior long-context generalization, outperforming state-of-the-art hybrid linear attention architectures by up to $8$ points on LongBench. Together, these results establish non-linear RNN layers as a compelling building block for efficient and scalable LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces a new kind of neural network layer for LLMs called a Matrix‑to‑Matrix RNN (shortened to M2RNN). It’s designed to combine the “smart memory” of older RNNs with the strong performance and long-context abilities seen in today’s top models (like Transformers and state space models such as Mamba). The big idea is to give the RNN a much larger, table‑shaped memory (a matrix) instead of a small, list‑shaped memory (a vector), and to update that memory in a way that’s both powerful for learning and friendly to modern computer hardware.
Goals and questions the paper asks
The authors set out to answer a few simple questions:
- Can we make RNNs better at remembering and using long histories of text (long documents, far‑back facts) without slowing training too much?
- Can we fix the typical weaknesses of efficient “linear” RNNs (which are fast but less expressive) on hard memory tasks and retrieval (finding a specific fact in a long context)?
- Can we keep the strengths of non‑linear RNNs (which are good at tracking complex state, like following rules or evaluating code) while improving their language modeling and hardware efficiency?
- Is a bigger internal memory (state size) the real key to good language modeling and in‑context retrieval, more than whether the model is linear or non‑linear?
How it works (in everyday language)
Think of a LLM as someone taking notes while reading a story:
- A classic RNN keeps a single line of notes. It’s quick, but the line gets crowded and important details get lost.
- Transformers keep a scrapbook of every past page—great for retrieval, but expensive to store and search.
- M2RNN gives the RNN a spreadsheet instead of a single line. That spreadsheet (a matrix) can store much more information, and each new word updates the spreadsheet in a structured way.
Here are the key ideas, explained simply:
- Matrix memory: Instead of a small vector as memory, M2RNN uses a matrix (think: a table with rows and columns). More space means it can store more associations and details from the past.
- Outer product “write”: When a new word arrives, the model creates a small “note” that is like a row times a column (an outer product) and adds it to the spreadsheet. This is a compact way to write lots of information without needing tons of extra parameters.
- Forget gate (a smart eraser): The model learns when to keep old information and when to let it fade. This “forget” signal is computed from the current input, not from the whole memory, so it’s fast and parallelizable.
- Non‑linearity for richer reasoning: The model uses a non‑linear function (like tanh) inside the memory update. This makes it better at “state tracking”—following rules over time, like keeping track of who’s where in a story or stepping through a program.
- Reading from memory: To answer “what should I predict next?”, the model multiplies its memory by a “query” vector (like asking the spreadsheet a question) which pulls out the right information.
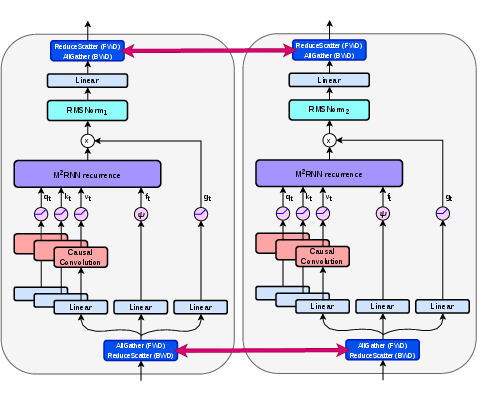
- Efficient on GPUs: The matrix updates are shaped to run well on today’s GPU hardware without wasting compute. The authors wrote custom code (kernels) and describe two ways to split the work across multiple GPUs so it trains at scale.
Analogy: If a normal RNN is a single post‑it, and a Transformer is a giant pile of past pages, M2RNN is a smart spreadsheet with a good eraser and fast search. It can store more than a post‑it but is cheaper than flipping through every past page all the time.
What the researchers found and why it matters
Here are the main takeaways:
- Bigger memory is crucial: The authors show that the disappointing results of traditional non‑linear RNNs (like LSTMs/GRUs) aren’t mainly because they’re non‑linear, but because their memory is too small. When you switch to a matrix‑shaped memory (much larger), language modeling and retrieval improve a lot.
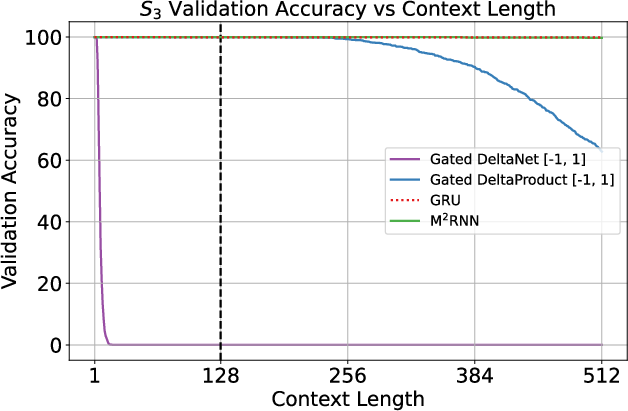
- Better at hard “state tracking” tasks: M2RNN matches or beats other efficient models on problems that require following rules over time—like composing permutations (a classic test for memory and logic). It generalizes better to longer sequences than some recent linear RNN variants even when those variants are theoretically expressive.
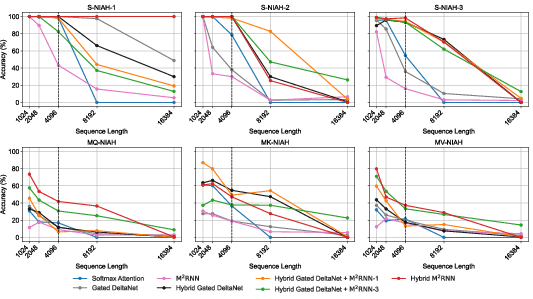
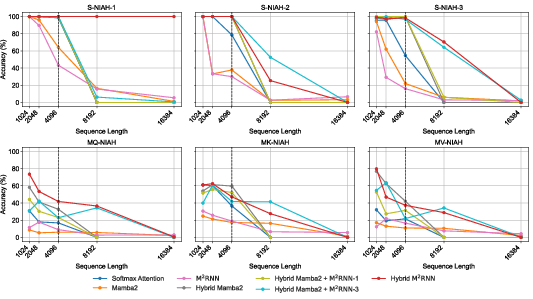
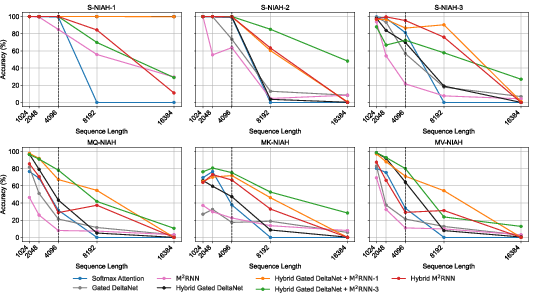
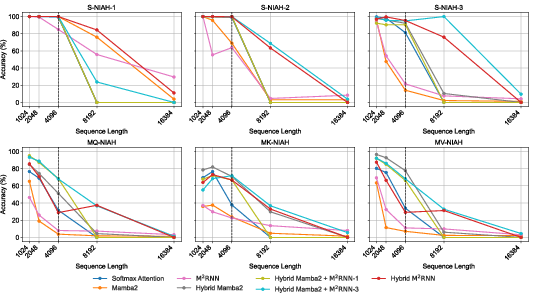
- Stronger long‑context retrieval: Because the matrix memory can store many key‑value associations, M2RNN does a better job at “needle-in-a-haystack” style tasks—finding a specific fact buried in a long document. In their tests, adding M2RNN layers improved long‑context benchmarks by up to 8 points at both mid‑size and large model scales.
- Works well in hybrids: The authors combine M2RNN with fast linear RNN layers (like Mamba‑2 or Gated DeltaNet). Even using just one M2RNN layer among many linear layers gives strong gains, keeping training speed close to the fast baselines while boosting accuracy.
- Hardware‑friendly design: Unlike some recent fast RNN implementations that waste compute when batch sizes are small, M2RNN’s matrix operations fit GPU tensor cores neatly without padding. The team also provides two strategies for splitting the model across multiple GPUs—one that needs no extra communication (but ties you to a specific hardware setup), and one that keeps model size constant across setups (but needs a bit more communication.
Why this matters: It suggests a path beyond “Transformers for everything.” We can build models that are fast and scalable, yet still reason over long contexts and track complex states—key skills for coding assistance, long‑document Q&A, and multi‑step reasoning.
What this could change in the future
- More balanced model designs: Instead of relying only on attention or only on linear RNNs, future LLMs may mix fast linear layers with a small number of M2RNN layers to get better memory and reasoning without huge compute costs.
- Better long‑document tools: Apps that need to read, remember, and retrieve from very long texts—like legal documents, scientific papers, or codebases—could become more accurate and responsive.
- Scalable training at large sizes: Because the authors focus on hardware efficiency and distributed training strategies, these ideas can apply to big models, not just small demos.
- A broader toolkit beyond Transformers: M2RNN shows that non‑linear RNNs can be competitive again if we give them the right kind of memory and the right engineering. That opens up new options for building capable, efficient AI systems.
In short, the paper argues—and shows with experiments—that giving RNNs a bigger, smarter memory table and carefully designing how it’s updated can bring strong language modeling and long‑context abilities, while staying practical to train at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and concrete directions for future work identified from the paper.
- Expressivity under realistic constraints
- Clarify whether the expressivity theorem holds under finite-precision arithmetic, mixed precision (BF16/FP8), and with the proposed forget gate; quantify any precision-dependent failure modes.
- Provide formal bounds on what classes beyond regular languages (if any) are representable or efficiently learnable; relate to NC tasks and conditions under which composition generalizes with increasing .
- Quantify the minimal matrix-state size needed to simulate a given vector-valued non-linear RNN (overhead factors, parameter/state scaling).
- Length generalization and state-tracking scope
- Extend experiments beyond to harder (), Dyck languages, and practical program-tracking tasks to test length generalization under distribution shift.
- Compare length generalization against linear RNNs configured with enhanced expressivity (e.g., Householder products, negative eigenvalues) across diverse sequence lengths.
- Capacity and interference analysis of matrix-valued states
- Theoretically and empirically characterize how many key–value associations can be stored and reliably retrieved as a function of , , sequence length, and the forget-gate distribution (load–error curves, interference models).
- Derive guidelines for allocating vs under fixed parameter budgets (and multi-value sharing) to optimize language modeling vs retrieval vs compute/memory.
- Forget gate design and dynamics
- Assess the trade-offs of the state-independent scalar gate versus state-dependent or low-rank state-dependent gates (adaptivity vs parallel precomputation), including stability, gradient flow, and retrieval retention.
- Provide ablations on the initialization ranges for , saturation behavior, and their impact on long-context retention and optimization stability.
- Transition matrix parameterization
- Investigate input-dependent or low-rank input-conditioned transition matrices to trade off expressivity and compute; compare with fixed on language modeling and tracking.
- Study constraints on (orthogonal, skew-symmetric, spectral normalization) for stability over very long sequences, and their effect on performance vs gradient explosion/vanishing.
- Nonlinearity and architectural choices
- Evaluate alternatives to (e.g., GELU, gated activations) for stability, expressivity, and training speed; quantify sensitivity to residual readout design () and the short convolution kernel size.
- Explore low-rank or structured (e.g., Householder products) within this non-linear recurrence to adjust compute while preserving expressivity.
- Training scalability and memory efficiency
- The backward pass is memory-bandwidth bound and currently caches all to HBM; develop and benchmark memory-saving backprop (reversible recurrences, activation checkpointing granularity, low-rank/compressed , truncated BPTT, implicit/adjoint methods).
- Provide end-to-end throughput and memory footprints across sequence lengths (4k–128k+) and batch sizes, including the impact of gradient clipping thresholds and optimizer choices.
- Sequence-parallelization strategies
- Investigate approximate or blockwise sequence parallelization that preserves most benefits (e.g., block-causal composition, segment-level recurrences, hybrid scan variants) and quantify accuracy–efficiency trade-offs versus fully sequential BPTT.
- Hardware portability and precision
- Port kernels beyond Triton/NVIDIA (CUTLASS, ROCm, TPU), and quantify performance, numerical stability, and precision effects (FP8/BF16) on both forward and backward passes.
- Provide latency/throughput/energy-per-token comparisons against Mamba-2, Gated DeltaNet, FlashRNN, and Transformers across context lengths for both training and autoregressive inference.
- Hybrid architecture design and scheduling
- Systematically study where and how often to insert the expensive matrix-to-matrix layers: placement strategies, spacing, and sensitivity to depth/width for different tasks and context lengths.
- Characterize interactions with attention layers (how much quadratic attention is still needed), and derive task-dependent ratios that maximize quality at fixed compute.
- MoE and routing interactions
- Analyze how MoE routing interacts with recurrent states (load balance, temporal consistency of experts, potential state–router feedback), and whether expert choice should condition on recurrent statistics.
- Tensor parallelism trade-offs
- Quantify the compute–communication trade-offs of topology-aware vs topology-independent TP at larger scales (8–64 GPUs): overall throughput, activation footprints, overlap of comm/comp, and ease of changing TP topology at inference.
- Provide procedures for post-training “weight surgery” to convert models between TP configurations without retraining, or methods to decouple parameter count from TP topology without extra comm.
- Retrieval and long-context evaluation breadth
- Benchmark against stronger retrieval baselines (e.g., recent hybrid or memory-augmented models) and stress tests with high association counts beyond state capacity, reporting precise failure modes as load increases.
- Measure retention curves over very long contexts (≥128k) and the impact of noisy or distractor-heavy contexts on retrieval fidelity.
- Multimodal applicability
- Validate the approach on non-text modalities (audio, video, vision) and multi-modal fusion, including any required architectural changes in projections/convolutions and their effect on utilization.
- Optimization recipes and robustness
- Provide detailed ablations on initialization (identity vs orthogonal), learning rates, clipping norms, normalization choices, and regularization (dropout, weight decay) to stabilize deep recurrences.
- Study robustness to distribution shift and adversarial prompts, and analyze catastrophic forgetting vs statistics over time.
- Quantization and compression
- Explore quantization-aware training and inference (INT8/FP8) for the matrix-valued recurrence and its gates; assess accuracy–efficiency trade-offs and kernel support.
- Theoretical–empirical scaling laws
- Establish compute- and parameter-normalized scaling laws linking state size , number of matrix-to-matrix layers, and downstream performance, to guide architecture selection across budgets.
- Reproducibility scope
- Release complete training recipes (data, hyperparameters, optimizer settings) for the reported benchmarks to allow community replication and controlled ablations isolating state size vs non-linearity effects.
Practical Applications
Immediate Applications
The following use cases can be deployed now using the paper’s released code, kernels, and models, and by integrating the proposed Matrix-to-Matrix RNN (M2RNN) layers into existing training and inference stacks.
- Hybrid long-context LLMs with improved recall
- Sectors: software, legal, finance, healthcare, enterprise search
- What to do: Replace a small number of Mamba-2 or Gated DeltaNet layers with M2RNN layers in a hybrid stack (even a single layer), then pretrain or finetune.
- Why it matters: Reported up to ~8-point gains on long-context tasks (410M dense and 7B MoE), improved in-context retrieval due to larger matrix-valued state and outer-product writes/reads.
- Tools/workflows: Use the released Triton kernels and training code; initialize W as identity; apply per-step gradient clipping on H_t; adopt multi-value formulation for larger effective state under fixed params.
- Assumptions/dependencies: Requires retraining or finetuning; optimal gains depend on head sizes (K,V), gating hyperparameters, and task; performance may still lag fully quadratic attention on some retrieval tasks.
- Cost- and energy-efficient LLM training with better tensor-core utilization
- Sectors: AI infrastructure, cloud providers, model labs
- What to do: Replace vector-valued non-linear RNN blocks (e.g., FlashRNN/xLSTM-style) or some SSM layers with M2RNN to avoid padding the batch dimension and to tap tensor cores without wasted FLOPs.
- Why it matters: Outer-product expansion yields GEMM shapes independent of batch size; no batch padding needed if K,V are multiples of 16; reduces HBM I/O and wasted FLOPs compared to padded recurrent kernels.
- Tools/workflows: Target NVIDIA Hopper (WGMMA), set K,V to tensor-core-friendly tile sizes; integrate kernels via Triton; use chunked/sequential training as in the paper.
- Assumptions/dependencies: Best on modern NVIDIA GPUs; backward kernel is memory-bandwidth bound in current Triton implementation—CUTLASS optimization pending.
- Streamed, constant-memory inference for edge and server deployments
- Sectors: mobile, robotics, IoT, embedded, customer support
- What to do: Use M2RNN state (K×V per head) to maintain constant-memory inference over long sequences; deploy streaming assistants or summarizers without KV-cache growth.
- Why it matters: Recurrent state is O(1) in sequence length vs. O(T) KV cache; reduces latency/memory on-device and in low-cost servers.
- Tools/workflows: Carry per-layer recurrent states across tokens; combine with occasional attention or retrieval for best accuracy.
- Assumptions/dependencies: Requires runtime that persists per-layer state; throughput depends on sequential recurrence; hybrid stacks recommended for quality.
- Better state tracking for code and structured reasoning
- Sectors: developer tools, program analysis, agents
- What to do: Insert M2RNN layers in code models or agents needing permutation composition, entity tracking, and stepwise program evaluation.
- Why it matters: M2RNN matches/exceeds non-linear RNN expressivity and shows strong length generalization on S3; matrix state helps retain structured associations.
- Tools/workflows: Pretrain on code, instrument length generalization tests; adjust K,V to match capacity needs.
- Assumptions/dependencies: Gains in real-world code tasks require finetuning and careful curricula; still sequential over time during training.
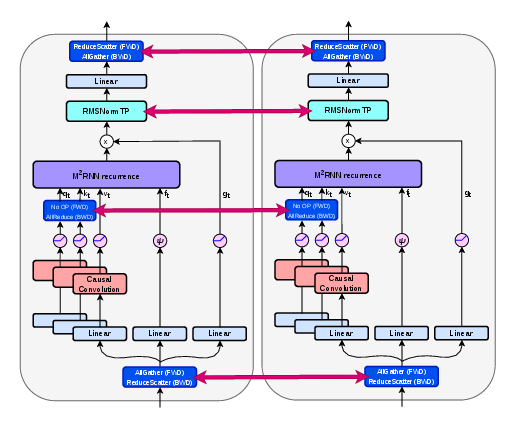
- Distributed training using topology-aware or topology-independent TP
- Sectors: model labs, hyperscalers
- What to do: Choose TP strategy:
- Topology-aware: Match N_q=N_k=N_TP with grouped values; no extra comms; parameter count tied to TP topology.
- Topology-independent: Keep N_q=N_k=1, shard value heads; use RMSNormTP with added synchronization to preserve parameter count across TP sizes.
- Why it matters: Enables multi-GPU scaling of M2RNN without redesigning kernels; deployable with Megatron/DeepSpeed-like stacks.
- Tools/workflows: Initialize shared projections identically across ranks; integrate RMSNormTP; profile interconnect bandwidth.
- Assumptions/dependencies: Topology-aware increases param/activation sizes; topology-independent adds comms in RMSNorm forward/backward.
- Long-context analytics for logs and time series
- Sectors: cybersecurity, observability, finance (market data), IoT monitoring
- What to do: Use M2RNN layers to improve recall over long sequences in streaming anomaly detection, event correlation, and compliance logs.
- Why it matters: Large matrix state and forget gate support long-horizon patterns with constant memory; sequential inference aligns with streaming inputs.
- Tools/workflows: Finetune hybrid models on domain logs; deploy streaming inference microservices.
- Assumptions/dependencies: Training on long sequences remains slower than fully parallel attention; benefits depend on domain signal and hyperparameters.
- Improved ASR/streaming NLP pipelines
- Sectors: speech, contact centers
- What to do: Replace/augment RNN/SSM blocks with M2RNN in streaming encoders or LLMs for ASR and diarization/post-processing.
- Why it matters: Continuous streams benefit from constant-memory recurrence and stronger state tracking for long utterances.
- Tools/workflows: Integrate as a drop-in block; use depthwise causal convs and SiLU as in the paper for stable pre-recurrence features.
- Assumptions/dependencies: Latency budget must tolerate sequential recurrence steps; may keep limited attention for global cues.
- Academic baselines and open benchmarks
- Sectors: academia, open-source
- What to do: Use M2RNN as a baseline for studying expressivity (regular languages), length generalization, and retrieval capacity.
- Why it matters: Provides a concrete, efficient non-linear RNN with matrix states, bridging gaps between theory and practice.
- Tools/workflows: Reproduce S_k tasks, LongBench-style evaluations; vary state sizes and gate initializations.
- Assumptions/dependencies: Requires GPU access for efficient experiments; care with gradient clipping and initialization.
Long-Term Applications
These use cases require additional research, scaling, software engineering, or ecosystem support before widespread deployment.
- M2RNN-first foundation models at frontier scale
- Sectors: general-purpose AI, cloud
- Vision: Architectures that replace most attention/SSM with M2RNN while retaining competitive pretraining efficiency and quality.
- What’s needed: Faster backward kernels (e.g., CUTLASS), improved sequence-parallelization or scan-like methods for non-linear recurrences, robust recipes at >10–70B scale.
- Assumptions/dependencies: Novel parallelization (beyond Newton-based methods) and kernel/graph compilation advances.
- Multimodal long-context models with constant-memory inference
- Sectors: video analytics, meeting assistants, AR/VR
- Vision: M2RNN-backed memory for audio-video-text streams with hour-scale contexts on-device or in cost-efficient servers.
- What’s needed: Adapting matrix-state recurrence to vision/audio encoders and cross-modal read/write patterns; training data and compute.
- Assumptions/dependencies: Stable training at very long horizons; hybrid attention for global cross-modal alignment.
- Privacy-preserving on-device personal assistants with day-long memory
- Sectors: consumer, enterprise productivity
- Vision: Assistants that retain session histories without cloud KV caches, running on laptops/phones with constant memory.
- What’s needed: Efficient mobile kernels, quantization, power-aware scheduling, and UX models tailored for incremental memory.
- Assumptions/dependencies: Vendor support (NVIDIA/Apple/Qualcomm/AMD) for tensor-core-like acceleration on edge hardware.
- Robotics and control with improved temporal credit assignment
- Sectors: robotics, autonomy, industrial automation
- Vision: Controllers or language-conditioned policies leveraging M2RNN’s state tracking for long-horizon tasks and plans.
- What’s needed: Integration with control stacks (e.g., RL, differentiable physics), safety/robustness studies, real-time scheduling.
- Assumptions/dependencies: Deterministic latency under sequential recurrence; hardware acceleration on embedded GPUs/NPUs.
- Financial compliance and audit-trail recall at enterprise scale
- Sectors: finance, regtech
- Vision: Constant-memory systems tracking months of event streams and retrieving specific obligations or anomalies on demand.
- What’s needed: Domain-adapted long-context finetuning, explainability for regulatory acceptance, alignment with audit workflows.
- Assumptions/dependencies: Verified improvements vs. search+RAG baselines; governance and drift monitoring.
- Continuous patient monitoring and longitudinal EHR modeling
- Sectors: healthcare
- Vision: Models that integrate streaming vitals and long EHR histories with improved recall and stable memory.
- What’s needed: Clinical data integration, validation studies, regulatory clearance; secure on-prem/edge deployment.
- Assumptions/dependencies: Robustness and interpretability; compliance (HIPAA/GDPR).
- Compiler and framework support for RNN-centric large models
- Sectors: ML frameworks, hardware vendors
- Vision: First-class scheduling, fusion, and tensor-core paths for matrix-state RNNs (forward/backward), standardized RMSNormTP.
- What’s needed: CUTLASS/Triton/CUDA graph optimizations, automatic tile sizing for K,V, distributed runtime support.
- Assumptions/dependencies: Collaboration with framework and hardware providers; cross-vendor support (NVIDIA/AMD/Intel).
- Parallelizable training algorithms for non-linear recurrences
- Sectors: research labs, academia
- Vision: Practical, memory- and compute-efficient methods to parallelize non-linear RNNs across sequence length without sacrificing expressivity.
- What’s needed: New approximate scan mechanisms, better-conditioned recurrences, or structured Jacobians beyond diagonal.
- Assumptions/dependencies: Convergence guarantees, stable iteration counts, and competitive wall-clock vs. sequential BPTT.
- Differentiable memory modules for RAG and tool-augmented systems
- Sectors: enterprise AI, developer platforms
- Vision: Use M2RNN as a learned memory in retrieval-augmented pipelines, reducing reliance on large external KV stores while improving recall.
- What’s needed: Interfaces for read/write with retrievers, curriculum for memory-augmented training, evaluation at production scale.
- Assumptions/dependencies: Interop with vector databases and latency budgets; empirical validation against strong RAG baselines.
- Standardized long-context benchmarks and policy guidance for efficient AI
- Sectors: academia, policy, sustainability
- Vision: Benchmarks and best practices that measure energy/memory efficiency and long-context quality; procurement guidance favoring sub-quadratic inference.
- What’s needed: Open datasets, reporting standards (FLOPs, memory footprint, energy), and industry adoption.
- Assumptions/dependencies: Community consensus and reproducibility infrastructure.
Notes on feasibility and dependencies across applications:
- Hardware: Best efficiency on GPUs with tensor cores (e.g., NVIDIA Hopper) and K,V multiples of 16; performance may degrade on older/CPU-only hardware.
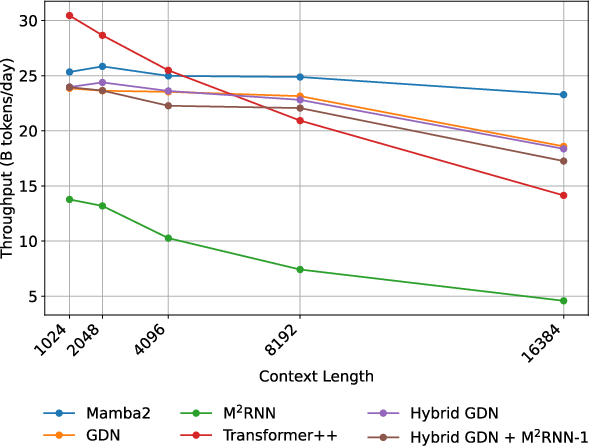
- Training: Non-parallelizable recurrence over sequence length increases training cost; using M2RNN layers sparingly mitigates throughput impact (~within 6% of hybrid baselines in paper).
- Software maturity: Backward kernel currently memory-bound in Triton; production-grade CUTLASS kernels and deeper framework integration will improve adoption.
- Scaling: Results shown at 410M dense and 7B MoE; extrapolation to much larger models requires engineering and empirical validation.
- Stability: Training relies on identity/orthogonal W initialization, per-step gradient clipping, and carefully tuned forget gates; deviations may affect stability and performance.
Glossary
- Autoregressive inference: Generating outputs one step at a time, conditioning on all previously generated outputs, often used for efficient decoding. "memory-efficient and fast autoregressive inference (using the recurrent form)"
- Backpropagation through time (BPTT): The training algorithm for RNNs that unfolds the network through time and applies backpropagation across time steps. "Training non-linear RNNs with backpropagation through time (BPTT) is susceptible to exploding gradients,"
- Causal attention: An attention mechanism that prevents each position from attending to future positions, enforcing autoregressive ordering. "decoder-only Transformer, composed of alternating multi-layer perceptron (MLP) and causal attention layers"
- CUTLASS: An NVIDIA CUDA C++ template library for high-performance GEMM and related operations used to build custom kernels. "We are developing an optimized implementation in CUTLASS to address this bottleneck."
- Delta update rule: A recurrence update that adds a learned change (delta) to the state, improving memorization and recall in linear RNNs. "introduce the delta update rule, showing significant improvements in associative recall,"
- Deterministic finite-state automata (DFAs): Abstract machines with a finite number of states that deterministically process input symbols, recognizing regular languages. "can simulate deterministic finite-state automata (DFAs)."
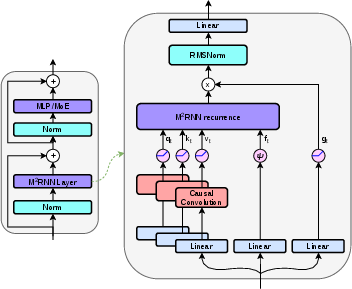
- Depthwise causal short-convolution: A per-channel causal convolution with a small kernel, used to inject local context while preserving sequence order. "followed by a depthwise causal short-convolution (kernel size 4)"
- Diagonal transition matrices: Transition matrices constrained to be diagonal, limiting interactions across state dimensions and model expressivity. "linear SSMs with input-independent or diagonal transition matrices"
- FlashRNN: A family of optimized RNN kernels/mechanisms designed to improve GPU efficiency (tiling, on-chip reuse) for recurrent computation. "FlashRNN \cite{flashrnn} propose to parallelize a vector-valued non-linear recurrence over the batch dimension () and the number of heads ()."
- Floating-point operations (FLOPs): The count of arithmetic operations (adds/multiplies) used as a proxy for computational cost. "leading to substantial wasted FLOPs due to padding."
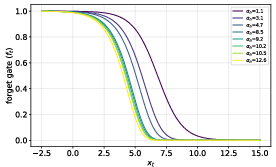
- Forget gate: A multiplicative gate that controls how much of the previous state is retained in gated RNNs, mitigating vanishing/exploding gradients. "We use a scalar-valued (per-head) forget gate ."
- General Matrix Multiply (GEMM): The core linear algebra operation (matrix multiplication) heavily used in deep learning kernels. "Computing the GEMM (General Matrix Multiply) $#1{W} h_{t-1}$ on a GPU proceeds by tiling the output"
- Gated DeltaNet: A linear RNN/SSM variant that augments delta-style updates with gating to improve expressivity and stability. "Gated DeltaNet fails to learn the task altogether."
- Gated DeltaProduct: A gated SSM that parameterizes transitions as products of Householder matrices, enabling richer dynamics. "Gated DeltaProduct~ achieves near-perfect accuracy up to context length $256$,"
- H3 block: A specific architectural block (from H3/Hungry Hungry Hippos) often coupled with gated MLPs in hybrid sequence models. "we adopt a hybrid architecture combining the H3 block \cite{fu2022hungry} with a gated MLP,"
- High Bandwidth Memory (HBM): High-speed on-package memory used in modern GPUs; accesses are much slower than on-chip SRAM/shared memory. "forcing costly HBM I/O and synchronization."
- HouseHolder matrices: Orthogonal matrices generated by reflections; products of these can flexibly represent rotations/reflections in transition dynamics. "allowing a product of HouseHolder matrices further increases the expressivity"
- In-context retrieval: The ability of a model to retrieve specific information from earlier context tokens during inference without parameter updates. "Linear RNNs exhibit weak performance in in-context retrieval tasks"
- Jacobian: The matrix of all first-order partial derivatives; in RNN parallelization via implicit methods it must be formed/handled, incurring high cost. "storing the Jacobian requires substantial memory"
- Kernel features: Feature mappings used to approximate attention via inner products in a transformed space. "propose computing linear attention via a dot product of kernel features,"
- Long Short-Term Memory (LSTM): A gated RNN architecture designed to capture long-range dependencies using input/forget/output gates and cell states. "The Long Short-Term Memory (LSTM)"
- Mamba-1: A state space model architecture (SSM) with efficient linear-time training and inference properties. "SSMs like Mamba-1 \cite{mamba1} can alternatively be accelerated via the parallel scan algorithm"
- Mamba-2: An improved SSM variant that increases effective state size (e.g., grouping/multi-value) to boost modeling capacity. "Mamba-2 \cite{mamba2} increases the effective state size through a grouping strategy"
- Matrix-to-Matrix RNN: The proposed non-linear RNN with matrix-valued states and outer-product updates to expand capacity and improve retrieval. "We propose Matrix-to-Matrix RNN (), a non-linear RNN architecture"
- Matrix-valued hidden states: Hidden states represented as matrices (e.g., K×V) rather than vectors, increasing capacity for associations. "which uses matrix-valued hidden states."
- Multi-value attention formulation: A parameter-sharing strategy where multiple value heads share a single query/key, increasing effective state without linear parameter growth. "we use an outer product with the multi-value attention formulation proposed by \citet{mamba2}"
- NC1: A circuit complexity class of problems solvable by poly-size, log-depth boolean circuits; strictly harder than TC0. "NC denotes the class of languages decidable by logarithmic-depth boolean circuits of polynomial size"
- Newton's method: An iterative root-finding method used here to parallelize non-linear RNNs by solving a system of non-linear equations. "solving it via Newton's method"
- Orthogonal initialization: Initializing weight matrices to be orthogonal to help stabilize training dynamics. "orthogonal initialization outperforms normal initialization."
- Outer product state expansion: Expanding the recurrent state by writing rank-1 updates k_t v_tT, increasing capacity with modest parameter cost. "We adopt an outer product state expansion strategy similar to that of linear attention"
- Parallel scan algorithm: An algorithmic technique to compute associative recurrences in parallel across sequence length. "SSMs like Mamba-1 \cite{mamba1} can alternatively be accelerated via the parallel scan algorithm"
- Permutation group S_5: The symmetric group on five elements; used as a benchmark for hard state-tracking/expressivity tests. "hard state tracking tasks like the permutation group cannot be solved"
- Random feature methods: Techniques that approximate kernels/attention using randomized feature maps for efficiency. "approximate attention using random feature methods,"
- Regular languages: The class of languages recognizable by finite automata; non-linear RNNs under finite precision can recognize all regular languages. "capable of recognizing all regular languages."
- RMSNorm: Root Mean Square Layer Normalization, a lightweight normalization technique often used in place of LayerNorm. "applies RMSNorm~\cite{rmsnorm} with different weights"
- SiLU activation: The Sigmoid Linear Unit activation function, also known as Swish, used in projections and gates. "and SiLU activation"
- State Space Models (SSMs): Sequence models that evolve a latent state via linear dynamical systems, offering linear-time recurrences. "State Space Models (SSMs) and linear attention"
- Streaming multiprocessor (SM): The fundamental GPU execution unit that runs thread blocks and holds on-chip resources like shared memory. "a single streaming multiprocessor (SM),"
- TC0: A circuit complexity class solvable by constant-depth threshold circuits; includes relatively simple state-tracking tasks. "TC denotes the class of languages decidable by constant-depth threshold boolean circuits of polynomial size."
- Tensor cores: Specialized hardware units on NVIDIA GPUs that accelerate mixed-precision matrix operations. "matrix multiplication units (tensor cores on NVIDIA GPUs"
- Tensor parallelism (TP): Model-parallel training technique that partitions layer computations across multiple devices to fit and accelerate large models. "two strategies for applying tensor parallelism (TP) to layers"
- Transition matrix: The matrix defining how the hidden state evolves from one step to the next in a recurrence. "$#1{W} \in \mathbb{R}^{V \times V}$ is the transition matrix for the recurrence (independent of the input)"
- Triton DSL: A domain-specific language for writing custom GPU kernels in Python with high performance. "implemented in the Triton DSL"
- WGMMA instruction: A Hopper-generation NVIDIA GPU instruction for warp-group matrix multiply-accumulate on tensor cores. "utilize the WGMMA instruction on NVIDIA Hopper GPUs"
- WMMA instruction: A warp-level matrix multiply-accumulate instruction on NVIDIA GPUs used to leverage tensor cores. "for using the WMMA instruction"
- Word problem: In group theory, deciding whether a product of generators equals the identity; used here with S_5 as a hardness benchmark. "at least as hard as the word problem,"
Collections
Sign up for free to add this paper to one or more collections.