Mamba-3: Improved Sequence Modeling using State Space Principles
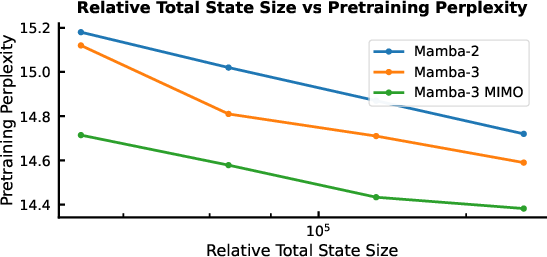
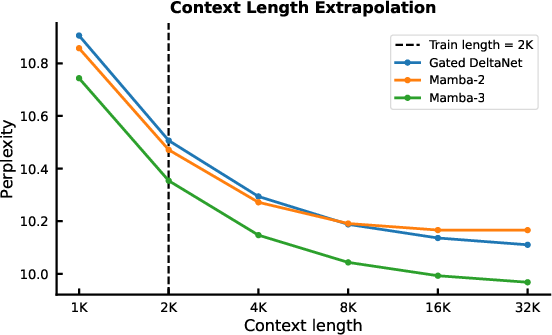
Abstract: Scaling inference-time compute has emerged as an important driver of LLM performance, making inference efficiency a central focus of model design alongside model quality. While the current Transformer-based models deliver strong model quality, their quadratic compute and linear memory make inference expensive. This has spurred the development of sub-quadratic models with reduced linear compute and constant memory requirements. However, many recent linear models trade off model quality and capability for algorithmic efficiency, failing on tasks such as state tracking. Moreover, their theoretically linear inference remains hardware-inefficient in practice. Guided by an inference-first perspective, we introduce three core methodological improvements inspired by the state space model (SSM) viewpoint of linear models. We combine: (1) a more expressive recurrence derived from SSM discretization, (2) a complex-valued state update rule that enables richer state tracking, and (3) a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency. Together with architectural refinements, our Mamba-3 model achieves significant gains across retrieval, state-tracking, and downstream language modeling tasks. At the 1.5B scale, Mamba-3 improves average downstream accuracy by 0.6 percentage points compared to the next best model (Gated DeltaNet), with Mamba-3's MIMO variant further improving accuracy by another 1.2 points for a total 1.8 point gain. Across state-size experiments, Mamba-3 achieves comparable perplexity to Mamba-2 despite using half of its predecessor's state size. Our evaluations demonstrate Mamba-3's ability to advance the performance-efficiency Pareto frontier.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Mamba-3: A simple explanation
What is this paper about?
This paper introduces Mamba-3, a new building block for LLMs (like those behind chatbots). It’s designed to be fast when generating text and also smart at understanding and remembering what it has already seen. It improves on earlier “Mamba” models by changing how it updates its memory, adding a better way to track information over time, and making better use of computer hardware.
What questions did the researchers try to answer?
The authors focused on three big questions:
- How can we make models that generate text both fast and accurate?
- How can we help these models “track state,” meaning remember and update important information step by step (like keeping track of whether the number of 1s in a list is even or odd)?
- How can we use computer chips (like GPUs) more efficiently so the model does more useful work per second during generation?
How does Mamba-3 work? (In everyday language)
Mamba-3 is based on something called a State Space Model (SSM). Think of an SSM as a small, smart “notebook” the model carries while reading a sentence. At each word (or token), it updates the notebook using rules that decide how much to remember from before and how much to write from the new word.
Mamba-3 makes three main improvements to this notebook-update process:
1) A better step-by-step update rule (Exponential-Trapezoidal)
- Problem: Earlier Mambas used a quick-and-simple update that sometimes wasn’t expressive enough.
- Idea: When moving from one word to the next, instead of just using the newest word to update the notebook, Mamba-3 uses a smarter “two-point” update that blends what happened at both the previous and current steps.
- Analogy: If you’re estimating how far you walked in the last minute, the old method only looked at the last second; the new method averages what happened at both the start and end of the minute—usually more accurate.
- Why it helps: This “two-point” update acts like a tiny built-in filter that mixes the last two inputs before updating memory, making the model more expressive without slowing it down.
2) Complex-valued state updates (Rotation-based memory)
- Problem: Many “linear” models struggle with simple state-tracking tasks (like checking if the total number of certain events is even or odd).
- Idea: Let the hidden memory “rotate,” not just fade. Mathematically, this uses complex numbers, but practically it’s like rotating a 2D pointer a little each step.
- Analogy: Imagine a compass needle that turns a bit whenever you see a certain token. The final direction tells you something important (like parity).
- Why it helps: Rotations let the model store patterns that go in cycles (like odd/even, on/off). The authors show this is closely related to “rotary embeddings” (RoPE), but made data-dependent, which they can compute efficiently.
3) Multi-Input, Multi-Output (MIMO) for better hardware use
- Problem: During generation (making one token at a time), many models are “memory-bound.” That means the GPU spends too much time waiting for data to move around, not doing math.
- Idea: Instead of updating the notebook with a thin, one-to-one update (single-input, single-output), make it handle multiple inputs and outputs at once (MIMO). This turns small calculations into bigger matrix multiplications that GPUs are great at.
- Analogy: If you’re cooking, it’s more efficient to chop many vegetables in one go than to chop one, put the knife down, pick it up again, and repeat.
- Why it helps: MIMO raises the “arithmetic intensity” (more useful math per memory access). In practice, that means better GPU utilization and similar speed—but with more modeling power.
What did they actually do under the hood?
- They developed a new discretization rule (exponential-trapezoidal) that gives a three-term update: the new state depends on the previous state plus a smart blend of the last two inputs.
- They showed how to implement complex (rotation) updates efficiently using data-dependent rotary embeddings (a trick from earlier Transformer research but adapted for SSMs).
- They restructured the update from an outer product to a matrix multiply (MIMO), which fits modern GPU hardware much better during decoding.
- They also kept training efficient by using a “chunked” strategy that mixes parallel and step-by-step computation.
What are the main results and why do they matter?
The authors tested Mamba-3 on language modeling and special state-tracking tasks. Here’s what they found:
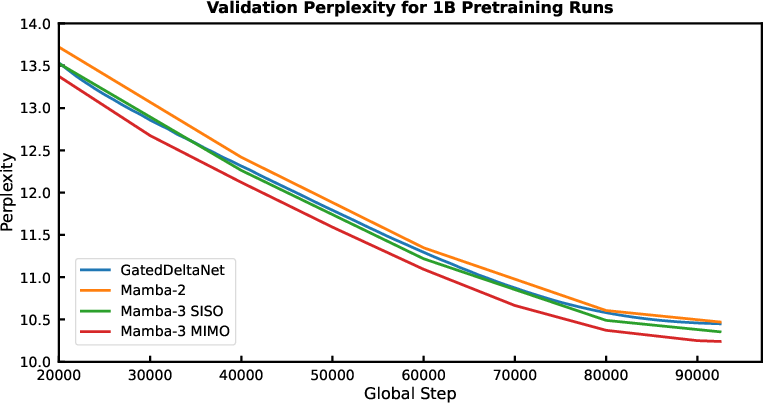
- Better accuracy: At the 1.5B parameter scale, Mamba-3 beats strong baselines (like Gated DeltaNet and even Transformers) on average downstream tasks.
- Strongest version: The MIMO variant of Mamba-3 improves accuracy further without slowing down decoding.
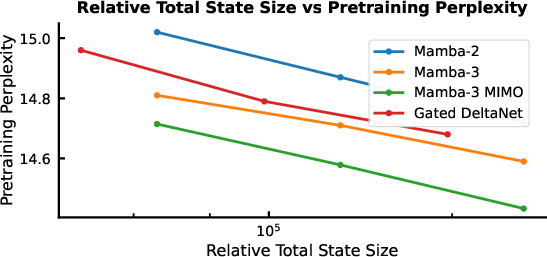
- Same quality with smaller state: With a smaller internal memory (state size), Mamba-3 can match the performance of Mamba-2 that used a larger state—so it’s faster for similar quality.
- New abilities: Thanks to the rotation-based (complex) update, Mamba-3 solves synthetic “state-tracking” tasks that previous versions could not (like parity-like problems that require careful step-by-step tracking).
- Hardware efficiency: The MIMO version does more computation per memory access and keeps GPUs busier, improving performance without increasing the time to generate each token. They also release fast training and inference code.
Why this matters: It pushes the “performance vs. speed” frontier forward—meaning you don’t have to choose as much between being smart and being fast.
What’s the bigger impact?
- For users and developers: Models built with Mamba-3 can be deployed more cheaply and run faster, especially important for apps that generate long texts or run many processes in parallel (like AI agents).
- For research: It shows that carefully designed SSMs can compete with Transformers, and even beat them in certain efficiency-quality trade-offs.
- For the future: The ideas—smarter discretization, rotation-based memory, and MIMO hardware-aware design—could influence many non-Transformer architectures, helping AI systems think step-by-step more reliably while staying practical to run at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-on research:
- Large-scale validation: Model results are reported at ~1.5B parameters; it remains unknown how Mamba-3 (SISO and MIMO) scales to 7B–70B+ and how its performance/latency Pareto changes at those scales and in hybrid (SSM+attention) stacks.
- Discretization parameterization: The paper does not specify how is parameterized, initialized, and constrained in practice (beyond ); ablations are missing on the effect of enforcing (2nd-order accuracy) vs leaving unconstrained on stability and accuracy across tasks.
- Stability guarantees: There is no rigorous BIBO/spectral or contractivity analysis for the LTV exponential-trapezoidal recurrence with learned , , , and complex rotations ; conditions that guarantee bounded states and gradients during training/inference are not provided.
- Global error bounds: The derivation sketches local error properties; comprehensive global error bounds for the full selective, data-dependent discretization (including the term) and their dependence on learned schedules are not established.
- Numeric robustness of rotations: The accumulation may suffer from drift or loss of orthogonality over very long contexts; mitigation strategies (e.g., re-orthogonalization, angle clipping, or periodic resets) and their overheads are unstudied.
- Gradient flow and optimization: The impact of complex rotations on gradient stability (vanishing/exploding through and paths), needed regularizers (e.g., spectral penalties on or angle norms), and recommended initializations are not analyzed.
- Convolution replacement claim: While terms are claimed to supplant short causal convolutions, systematic ablations across architectures, scales, and datasets quantifying when convolutions can be removed (and their robustness impact) are not shown.
- MIMO rank selection: No guidance or scaling law is given for choosing MIMO rank as a function of state size , head dim , or hardware; auto-tuning policies balancing FLOPs, memory, and quality are an open problem.
- Parameter budget confounds: To keep parameter count fixed, MIMO increases SSM capacity while reducing MLP width; controlled studies that hold per-module budgets constant are needed to disentangle method gains from parameter reallocation.
- End-to-end training cost: Beyond prefill forward benchmarks, the paper lacks full training throughput, memory footprint, optimizer step-time, and convergence-speed measurements versus and sequence length; backward-pass kernel details and bottlenecks are unspecified.
- Hardware generality: Efficiency results are H100-centric; portability and performance on consumer GPUs, AMD/ROCm, TPUs, Intel GPUs/CPUs, and edge devices, as well as kernel fallbacks and tuning, remain untested.
- Quantization and compression: The behavior of complex rotations and MIMO under 8/4-bit quantization (weights/states), low-rank compression, and sparsity is unreported; calibration schemes and accuracy–efficiency trade-offs are unknown.
- Long-context and streaming: The robustness of and rotation products for contexts ≥128k tokens, streaming scenarios with chunk resets, and cross-chunk state stitching has not been evaluated.
- Memory footprint at decode: Although arithmetic intensity improves, concrete VRAM usage and throughput for multi-stream decoding (varying batch/beam sizes) with MIMO states ( and tensors) are not reported.
- Speculative/assisted decoding: Compatibility of the MIMO recurrence with speculative decoding, assisted decoding, and efficient branch merges (including state reuse and reconciliation) is not discussed.
- Real-world state tracking: Beyond synthetic tasks, there is no evaluation on realistic stateful benchmarks (e.g., program execution, tool-use with persistent memory, dialogue slot tracking, long-horizon retrieval with updates).
- Interaction with attention: Optimal layering ratios, placement, and shared/no-shared RoPE settings between Mamba-3 and attention blocks—and whether complex rotations synergize or interfere with attention RoPE—are unexplored.
- Multimodal and time-series transfer: Generality of exponential-trapezoidal and complex rotations to audio, multivariate time series, and vision (including continuous-time signals) and necessary adaptations are untested.
- Formal expressivity: A precise characterization of functions/languages recognizable by complex Mamba-3 with finite and learned (e.g., classes beyond solvable-group/TC0) and matching lower/upper bounds remain open.
- Alternative integrators: Higher-order, A-stable, or symplectic discretizations tailored to selective SSMs (and their hardware implications) are not explored; trade-offs among accuracy, stability, and kernel efficiency are open.
- Initialization and constraints: Concrete, reproducible recipes ensuring , , bounded , and numerically stable during early training (and their effect on convergence) are absent.
- Robustness and safety: Sensitivity to distribution shift, adversarial prompts, numerical noise, and token corruptions—especially given multiplicative rotations—is not studied.
- Reproducibility scope: While kernels are released, details on data, tokenizer, training schedules, seeds/variance, and whether weights will be released are insufficient for full reproduction.
- Interpretability: Methods to probe how learned rotations encode algorithmic state and to visualize or edit the “implicit convolution” contributions are not provided.
Practical Applications
Overview
This paper introduces Mamba-3, a state space model (SSM)–based sequence layer that advances the performance–efficiency Pareto frontier. Its key innovations are:
- Exponential-trapezoidal discretization: a more expressive, theoretically justified update rule that subsumes Mamba-1/2’s exponential–Euler and implicitly replaces short causal convolutions.
- Complex-valued (RoPE-equivalent) state updates: data-dependent rotary dynamics that restore rotational (state-tracking) capabilities absent in many linear models.
- Multi-input, multi-output (MIMO) SSMs: a decoding-time formulation that increases arithmetic intensity and FLOPs without increasing wall-clock latency, improving hardware utilization.
Below are practical applications derived from these findings, categorized by deployment horizon. Each item notes sectors, potential tools/workflows/products, and key assumptions/dependencies affecting feasibility.
Immediate Applications
These can be deployed with existing tooling and near-term development effort, leveraging the released fast kernels and the architecture’s compatibility with current training/inference stacks.
- High-throughput, cost-efficient LLM inference in production
- Sectors: software, cloud platforms, consumer AI, customer support, e-commerce, media
- What: Replace or augment Transformer layers with Mamba-3 to reduce KV-cache memory and decode cost, while maintaining or improving quality at similar or lower latency; increase GPU utilization via MIMO without regressing wall-clock speed.
- Tools/Workflows/Products:
- Hybrid LLMs (Transformer + Mamba-3 blocks), parameter-matched variants for A/B testing
- Inference stacks (vLLM/DeepSpeed/TensorRT-LLM/Serving frameworks) integrating Mamba-3 kernels
- Throughput-optimized serving profiles that tune MIMO rank R to saturate tensor cores
- Assumptions/Dependencies: GPU tensor-core availability (e.g., NVIDIA H100/A100/L4), integration of Mamba-3 Triton kernels, careful selection of R to remain memory-bound/latency-neutral, quality verified on target workloads
- Edge and on-device LLMs with lower memory footprint
- Sectors: mobile, wearables, automotive, smart home, education
- What: Constant-memory decoding and matched perplexity at half the Mamba-2 state size enable smaller, faster on-device assistants and tutors.
- Tools/Workflows/Products:
- Compact models for smartphones/AR glasses, automotive infotainment
- Offline writing, summarization, and translation apps
- Assumptions/Dependencies: Efficient kernels on non-NVIDIA accelerators (Apple/Qualcomm NPUs), quantization-aware finetuning, thermal/power constraints, memory-bandwidth profiling on-device
- Agentic and tool-using workflows with improved state tracking
- Sectors: software development, enterprise automation, operations, scientific computing
- What: Complex-valued (RoPE-equivalent) SSM updates improve tracking counters, modes, and parity-like behaviors; reduces failure modes in multi-step, stateful tool chains.
- Tools/Workflows/Products:
- Code assistants with better iterative refinement and scratchpad tracking
- Workflow agents (data pipelines, IT runbooks) with long-running state consistency
- Assumptions/Dependencies: Gains beyond synthetic tasks require task-specific evaluation; prompt/training recipes may need to elicit stateful reasoning
- Streaming sequence applications with constant memory
- Sectors: speech (ASR/TTS), real-time translation, contact centers, live captioning, healthcare dictation
- What: Streaming-friendly SSM decoding reduces latency and memory versus attention; MIMO boosts utilization on GPUs during long streams.
- Tools/Workflows/Products:
- Low-latency ASR/TTS servers, simultaneous translation, call-center assistants
- Assumptions/Dependencies: Domain adaptation (audio/tokenization), integration with streaming front-ends, evaluation under noisy, long-form inputs
- Time-series forecasting and anomaly detection
- Sectors: finance (ticks), energy (grid), manufacturing (sensors), logistics, AIOps
- What: SSMs naturally model sequential dynamics; exponential-trapezoidal discretization adds expressivity; MIMO aligns with multi-channel inputs/outputs.
- Tools/Workflows/Products:
- Multivariate forecasting services, predictive maintenance, log anomaly detectors
- Assumptions/Dependencies: Task-specific training datasets and metrics, careful chunking/training recipes for long horizons
- Biosequence and long-context scientific workloads
- Sectors: genomics, proteomics, cheminformatics, scientific text
- What: Efficient long-sequence modeling with constant memory is attractive for DNA/RNA/protein modeling and literature mining.
- Tools/Workflows/Products:
- Sequence encoders/decoders for variant calling, motif discovery, retrieval-augmented literature assistants
- Assumptions/Dependencies: Domain-specific tokenization/labels, benchmarking against SOTA baselines
- Data center utilization and cost optimization
- Sectors: cloud, enterprise IT
- What: MIMO raises arithmetic intensity in memory-bound decode, improving effective GPU utilization and reducing $/token.
- Tools/Workflows/Products:
- Autoscaling/scheduling policies that select MIMO rank by batch size/sequence length
- Capacity planning dashboards showing throughput/latency trade-offs for SISO vs. MIMO
- Assumptions/Dependencies: Accurate profiling, inference scheduler integration, awareness of bandwidth/compute bottlenecks per SKU
- Simplified architectures by replacing short causal convolutions
- Sectors: software (ML infra), research
- What: Exponential-trapezoidal update with explicit B,C biases can replace short causal convs previously deemed essential in recurrent layers, simplifying models.
- Tools/Workflows/Products:
- Cleaner SSM blocks in open-source libraries, fewer custom kernels
- Assumptions/Dependencies: Training stability checks, regression tests on established benchmarks
- Academic research and teaching
- Sectors: academia
- What: A general LTV discretization framework (exp–Euler/exp–trapezoidal) for SSMs; an SSD perspective on parallel forms; open kernels for reproducible research.
- Tools/Workflows/Products:
- Course modules on discretization, state space duality, and efficient inference
- Baseline repositories comparing discretization schemes under identical setups
- Assumptions/Dependencies: Community adoption and standardized benchmarks
- Sustainability and policy-aligned deployments
- Sectors: public sector, sustainability, procurement
- What: Lower memory and improved hardware utilization reduce inference energy and cost; suitable for budget- and sustainability-conscious deployments.
- Tools/Workflows/Products:
- RFP criteria favoring efficient architectures; dashboards reporting energy/token
- Assumptions/Dependencies: Auditable measurement of energy savings; alignment with Green AI policies
Long-Term Applications
These require further research, scaling, ecosystem engineering, or domain validation beyond the current paper’s scope.
- Fully SSM-based general-purpose LLMs that rival Transformers at scale
- Sectors: software, consumer AI, enterprise
- What: Use Mamba-3 blocks throughout to reduce memory and latency while preserving quality at tens/hundreds of billions of parameters.
- Assumptions/Dependencies: Demonstrated scaling laws, training stability at large scale, strong pretraining corpora, inference kernels across hardware vendors
- Dedicated hardware and compiler paths for MIMO SSM decoding
- Sectors: semiconductors, compiler tooling
- What: Architectures co-designed for MIMO SSM arithmetic intensity and SSD chunking; compiler passes that fuse state updates and matmuls.
- Assumptions/Dependencies: Vendor support (NVIDIA/AMD/ASICs), stable operator APIs, ROI for custom silicon features
- State-tracking–centric reasoning systems
- Sectors: formal verification, planning/operations, scientific discovery
- What: Leverage complex-valued SSM dynamics to improve algorithmic reasoning (beyond synthetic tasks) in code verification, symbolic math, or long-horizon planning.
- Assumptions/Dependencies: Benchmarks that isolate state-tracking gains, hybrid neuro-symbolic pipelines, rigorous evaluation of generalization
- Privacy-preserving, on-device assistants for regulated sectors
- Sectors: healthcare, finance, government
- What: On-device Mamba-3 models for PHI/PII-sensitive tasks (dictation, triage assistants, financial advisory copilots) with reduced connectivity and leakage risk.
- Assumptions/Dependencies: Strong on-device kernels across NPUs/CPUs, model compression/quantization, formal privacy assessments, domain finetuning
- Long-context multimodal models (video/audio/text) with constant memory
- Sectors: media, surveillance, autonomous vehicles, education
- What: SSM cores extended to multimodal sequences (e.g., video frames + audio) with MIMO capturing multi-channel inputs/outputs.
- Assumptions/Dependencies: Multimodal pretraining data, cross-modal tokenization, efficient adapters, latency targets for real-time use
- Robust streaming communications and protocol modeling
- Sectors: networking, edge computing
- What: Apply SSMs with strong state-tracking to model/optimize streaming protocols and error control over long horizons.
- Assumptions/Dependencies: Domain-specific loss functions and simulators, integration into network control loops
- Standardized libraries and training recipes for MIMO chunked SSMs
- Sectors: ML frameworks
- What: First-class MIMO SSM abstractions in PyTorch/JAX/TVM/XLA, autotuning of chunk sizes, and kernel fusion across platforms.
- Assumptions/Dependencies: Broad community adoption, consistent APIs, maintenance of kernel performance
- Policy frameworks incentivizing efficient inference
- Sectors: public policy, standards bodies
- What: Certification schemes and tax/credit incentives for lower energy/token deployments; procurement checklists incorporating SSM-based efficiency.
- Assumptions/Dependencies: Reliable, comparable energy metrics; stakeholder consensus
- New products: “MIMO-aware” inference schedulers and SSM-centric accelerators
- Sectors: cloud, MLOps
- What: Controllers that dynamically adjust MIMO rank and chunk size by load/latency; accelerators optimized for SSD masks and MIMO matmuls.
- Assumptions/Dependencies: Real-time telemetry, integration into autoscalers, demand forecasting, hardware vendor partnerships
- Scientific modeling of dynamical systems at scale
- Sectors: climate/energy, biology, materials
- What: Use expressive discretizations and MIMO for large-scale PDE/ODE surrogates in simulation and control.
- Assumptions/Dependencies: Physics-informed training, hybrid simulation loops, validation against high-fidelity models
Notes on Feasibility and Dependencies
- Performance scaling: Reported gains are at 1.5B scale and on selected downstream tasks. Validation at larger scales and on diverse benchmarks is needed for some use cases.
- Kernel maturity: The authors release fast Triton training/inference kernels. Wider deployment depends on integration into mainstream serving stacks and support on non-NVIDIA hardware.
- Complex-valued (RoPE-equivalent) updates: Demonstrated strong gains on synthetic state-tracking; real-world impact depends on task alignment and training curricula that elicit these capabilities.
- MIMO tuning: Benefits depend on hardware being memory-bound during decode and on selecting an MIMO rank R that increases arithmetic intensity without increasing latency. Profiling is required per hardware/sequence regime.
- Architectural swaps: Replacing short causal convolutions with exponential-trapezoidal dynamics simplifies models but calls for stability and convergence checks per domain.
- Domain adaptation: For specialized sectors (e.g., healthcare, finance, genomics), data curation and finetuning remain essential to realize the architecture’s benefits.
Glossary
- agentic workflows: Coordinated, multi-step inference or task execution patterns where models act as agents, often in parallel. "The rapid rise of parallel, agentic workflows has only intensified the need for efficient inference and deployment of such models~{openai_gpt53_codex_2026,anthropic_claude_opus_46_2026}."
- arithmetic intensity: The ratio of floating-point operations to memory traffic for a computation; higher values indicate better use of compute relative to memory bandwidth. "their decoding phase has low arithmetic intensity (the ratio of FLOPs to memory traffic), resulting in large portions of hardware remaining idle."
- bfloat16 matmul: Matrix multiplication using the bfloat16 (brain floating point) format, offering high throughput on modern accelerators. "the arithmetic intensity for bfloat16 matmul is about $295$ ops per byte for NVIDIA H100-SXM5~{nvidia_h100_2022}."
- block-diagonal matrix: A matrix composed of square blocks on its diagonal with zeros elsewhere, often used to model independent subspaces or rotations. "its transition matrix is a scalar decayed block-diagonal matrix of data-dependent rotation matrices ()."
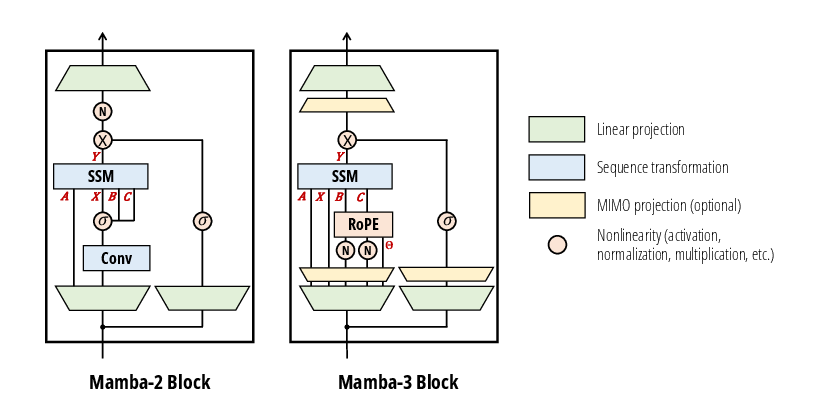
- causal convolution: A convolution that only uses past and present inputs (not future ones), preserving causality in sequence models. "Mamba-3 can empirically replace the short causal convolution in LLM architectures, which was previously hypothesized to be essential for recurrent models."
- chunked algorithm: A computation strategy that splits a long sequence into smaller chunks to balance parallelism and recurrence across segments. "Many modern SISO recurrent models, including Mamba-2, are computed using a chunked algorithm, where the sequence is divided into chunks of length ."
- complex-valued SSM: A state space model whose state and/or parameters are complex numbers, allowing rotational dynamics that enhance state-tracking capabilities. "By viewing the underlying SSM of Mamba-3 as complex-valued, we enable a more expressive state update than Mamba-2's."
- convex combination: A linear combination of points where the weights are non-negative and sum to one, often used to blend estimates. "it approximates the integral with a data-dependent, convex combination of both interval endpoints."
- data-dependent rotary embedding: A version of rotary positional embeddings where rotation angles depend on the input data, enabling adaptive phase shifts. "we show that our complex-valued update rule is equivalent to a data-dependent rotary embedding and can be efficiently computed~{su2023roformerenhancedtransformerrotary}"
- decode latency: The time taken to generate output tokens during inference; critical for real-time or interactive applications. "a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency."
- exponential-Euler discretization: A discretization that integrates the exponential of the linear part and then applies an Euler approximation to the input integral. "One of our instantiations, referred to as ``exponential-Euler,'' formalizes Mamba-1 and Mamba-2's heuristic discretization that previously lacked theoretical justification."
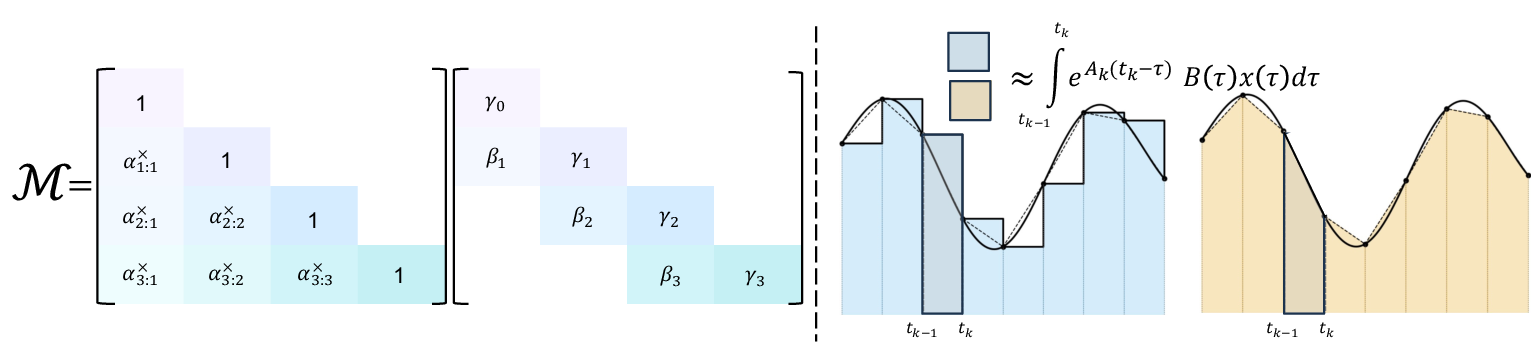
- exponential-trapezoidal discretization: A discretization that integrates the exponential of the linear part and applies a generalized trapezoidal rule to the input integral, improving accuracy and expressivity. "Our new
exponential-trapezoidal'' instantiation is a more expressive generalization ofexponential-Euler,'' where the recurrence can be expanded to reveal an implicit convolution applied on the SSM input." - FLOPs: Floating-point operations; a measure of computational work performed by an algorithm or hardware. "It increases decoding FLOPs by up to 4 relative to Mamba-2 at fixed state size, while maintaining similar wall-clock decode latency,"
- Hadamard product: Element-wise multiplication of two matrices or tensors of the same shape. "The Hadamard product between two tensors is denoted by ."
- KV cache: The key–value cache in Transformer models that stores past attention keys and values to avoid recomputation during decoding. "they are fundamentally bottlenecked by linearly increasing memory demands through the KV cache"
- linear-time invariant (LTI) system: A system whose dynamics do not change over time and obey linearity; classical target for control and signal processing methods. "These mechanisms were traditionally stated and applied to linear-time invariant (LTI) systems,"
- linear-time varying (LTV) system: A linear system whose parameters change over time, complicating discretization and analysis compared to LTI systems. "their derivations do not directly apply to linear-time varying (LTV) systems."
- local truncation error: The per-step error introduced by a numerical discretization method when approximating differential equations. "Euler's rule provides only a first-order approximation of the state-input integral and its local truncation error scales as ."
- matrix-multiplication (matmul): A core linear algebra operation; using matmul-focused implementations leverages optimized hardware like tensor cores. "This parallel formulation enables the hardware-efficient matmul-focused calculation of the SSM output for training."
- memory-bound: A regime where performance is limited by memory bandwidth rather than compute capability. "their decoding is heavily memory-bound, resulting in low hardware utilization."
- multi-input, multi-output (MIMO): A system that processes multiple input streams to produce multiple outputs simultaneously, increasing expressivity and compute utilization. "Mamba-3 (MIMO) improves hardware utilization."
- multi-value attention (MVA): An attention variant where multiple values per key are processed, often to increase capacity within heads. "Mamba's multi-value attention (MVA) head structure results in shared across heads,"
- Normal Plus Low Rank (NPLR): A structured matrix decomposition where a normal (often diagonalizable) part is combined with a low-rank correction, used in earlier SSMs. "S4~{S4} used complex-valued Normal Plus Low Rank (NPLR) matrices,"
- outer product: The product of a column vector and a row vector producing a matrix; often used in SSM state updates. "we switch from an outer-productâbased state update to a matrix-multiplicationâbased state update."
- Pareto frontier: The set of solutions where improving one objective (e.g., quality) would worsen another (e.g., efficiency). "Our evaluations demonstrate Mamba-3's ability to advance the performance-efficiency Pareto frontier."
- perplexity: A standard language modeling metric measuring the likelihood of a test set; lower is better. "Across state-size experiments, Mamba-3 achieves comparable perplexity to Mamba-2 despite using half of its predecessor's state size."
- prefill speed: Throughput during the initial (parallelizable) stage of processing input tokens before decoding in autoregressive models. "\Cref{tab:benchmark} benchmarks the prefill speed of various kernels which is equivalent to the forward pass of the training kernel."
- right-hand approximation: A quadrature method that approximates an integral using the value at the right endpoint of the interval. "the state-transition integral is approximated by a right-hand approximation, i.e. for all "
- RoPE trick: Implementing complex-valued transitions via cumulative rotary embeddings applied to real-valued parameters for efficiency. "We refer to the usage of a transformed real-valued SSM to compute the complex SSM as the ``RoPE trick.''"
- rotary embeddings (RoPE): Positional encodings implemented as rotations in feature space; can be data-independent or data-dependent. "We empirically demonstrate that the efficient RoPE-like calculation is able to near perfectly solve arithmetic tasks,"
- selective SSMs: State space models whose parameters (e.g., transition or input matrices) depend on the current input token, allowing data-dependent dynamics. "We provide a simple technique for discretizing time-varying, selective SSMs."
- semiseparable matrix: A structured matrix with low-rank off-diagonal blocks; useful for efficient computations. "Mamba-3 corresponds to a mask whose structure is a 1-semiseparable matrix composed with a 2-band matrix:"
- self-attention: A mechanism where each token attends to all previous tokens; standard in Transformers but with quadratic complexity. "quadratically increasing compute requirements through the self-attention mechanism."
- single-input, single-output (SISO): A system with one input and one output per time step; a baseline for extending to MIMO. "such a transition exactly coincides with the generalization from a single-input single-output (SISO) sequence dynamics to a multiple-input multiple-output (MIMO) one."
- state-input: The component B(t)x(t) of an SSM that injects the current input into the state dynamics. "We will occasionally refer to as the state-transition and as the state-input; this also extends to their discretized counterparts."
- state space duality (SSD): A framework showing the equivalence between recurrent SSM computations and parallel matrix forms with structured masks. "Through the state space duality (SSD) framework, recurrent SSMs can be represented within a parallel form that incorporates an element-wise mask to model the state-transition decay."
- state space model (SSM): A model describing system dynamics via hidden states updated by linear ODEs or recurrences with inputs. "State Space Models (SSMs) describe continuous-time linear dynamics via"
- state-transition: The part of an SSM that updates the hidden state based on its previous value, often parameterized by A(t). "We will occasionally refer to as the state-transition and as the state-input;"
- structured mask: A masking matrix with specific structure used to represent decays or convolutions in parallel SSM forms. "SSD provides a general framework for a duality between linear recurrence and parallelizable (matrix-multiplication-based) computational forms ... where is a structured mask,"
- tensor cores: Specialized hardware units on GPUs optimized for matrix multiplications, accelerating SSM computations. "the SSM recurrence can be efficiently computed with the matrix multiplication tensor cores of GPUs."
- test-time compute: Computational budget consumed during inference (as opposed to training), often scaled to improve performance. "Test-time compute has emerged as a key driver of progress in LLMs,"
- trapezoidal rule: A numerical integration method that averages function values at interval endpoints for second-order accuracy. "This generalization extends the classical trapezoidal rule {Süli_Mayers_2003}, which simply averages the interval endpoints"
- two-band matrix: A matrix with nonzero entries on two diagonals (e.g., main and first subdiagonal), representing short-range convolutional structure. "a mask whose structure is a 1-semiseparable matrix composed with a 2-band matrix:"
- zero-order hold (ZOH): A discretization method that assumes the input is held constant over each sampling interval. "The classical zero-order hold discretization method can be derived from the foundation above with a specific approximation of the right-hand side integral."
Collections
Sign up for free to add this paper to one or more collections.