- The paper introduces SSM-RDU, a reconfigurable dataflow unit that efficiently supports FFT- and scan-based SSM workloads, addressing the quadratic complexity of self-attention models.
- It employs specialized butterfly interconnects and tailored scan modes to achieve up to 5.95× speedup for Hyena and 2.12× for Mamba models, with less than 1% hardware overhead.
- The work challenges GEMM-centric accelerator designs, demonstrating that lightweight architectural enhancements can enable high-performance, scalable long-sequence computations.
SSM-RDU: A Reconfigurable Dataflow Unit for Long-Sequence State-Space Models
Motivation and Problem Statement
LLMs and other sequence models based on self-attention suffer from quadratic complexity relative to sequence length, limiting their efficacy in domains with extended context requirements such as genomics, high-resolution audio, and video modeling. Recent advances in State-Space Models (SSMs)—in particular, Hyena and Mamba—replace self-attention with algorithmic primitives exhibiting log-linear (O(NlogN)) (FFT in Hyena) and linear complexity (scan in Mamba). However, the adoption of these SSM variants is hindered by the poor efficiency of mainstream hardware accelerators, notably GPUs, on non-GEMM workloads due to fixed execution paradigms and specialization for dense matrix operations.
SSM-RDU Architecture and Execution Model
The SSM-RDU architecture extends the SambaNova-style Reconfigurable Dataflow Unit (RDU) paradigm to efficiently support SSM workloads based on FFT and scan, through lightweight architectural augmentations. Key distinctions of the RDU relative to GPU and fixed-function ASICs are its distributed grid of Pattern Compute Units (PCUs) and Pattern Memory Units (PMUs), coupled via a programmable network-on-chip. This enables spatially mapped dataflow execution and kernel fusion: multiple distinct computation kernels can be fused and streamed entirely on-chip, amortizing off-chip DRAM overheads and maximizing resource utilization, as visualized in Figure 1.
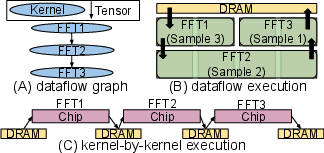
Figure 1: Dataflow versus kernel-by-kernel execution models; the former enables fused, on-chip streaming across kernels.
Each PCU implements a pipelined SIMD architecture with distinct operational modes: element-wise, systolic, and reduction, utilizing multi-source functional units for flexible data movement and compute (Figure 2).
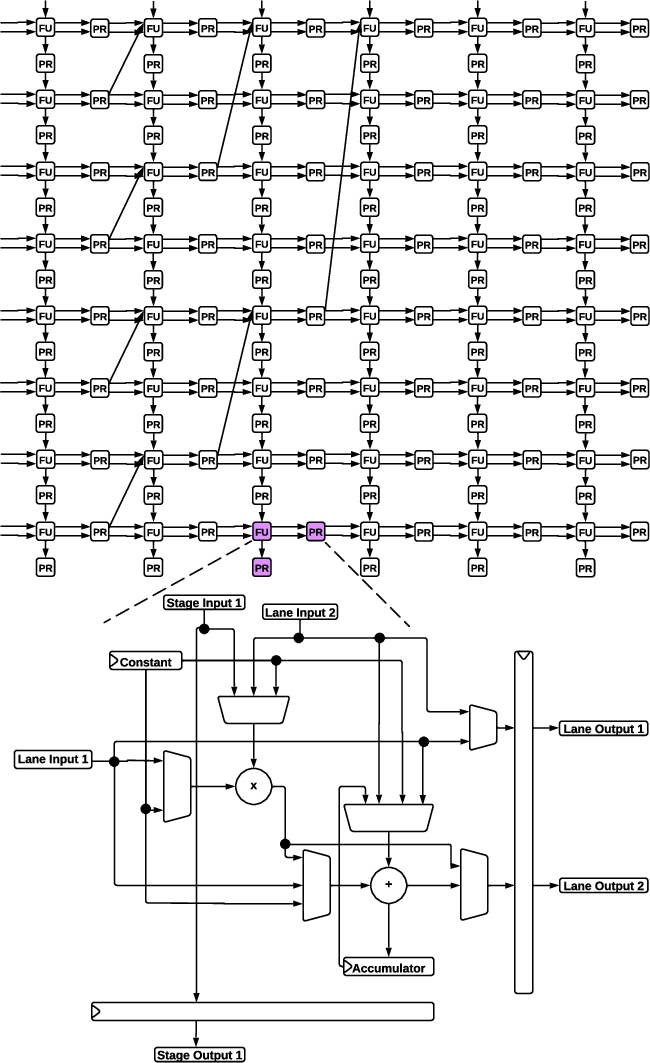
Figure 2: PCU structure, including multi-mode execution and flexible data routing within the SIMD lanes and stages.
Mapping of SSM Primitives to Hardware
FFT Support for Hyena
The Hyena SSM replaces O(N2) attention with FFT-based convolution kernels. Standard Cooley-Tukey FFT algorithms map poorly to vector or systolic architectures due to their variable data dependencies and non-local memory accesses. SSM-RDU leverages an efficient variant based on Bailey's FFT algorithm, which restructures the computation (reshaping, independent column FFTs, twiddle factor multiplications, row FFTs—see Figure 3) to enhance vectorization and improve data locality.
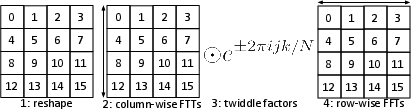
Figure 3: Bailey’s FFT decomposes the problem for improved vectorization on modern architectures.
Executing vector-FFT on a baseline PCU (lacking cross-lane connections) leads to significant underutilization. The SSM-RDU introduces minimal, specialized butterfly interconnects between PCU pipeline stages, enabling spatial unrolling and pipelined execution of the FFT dataflow graph (Figure 4), directly addressing hardware inefficiency.
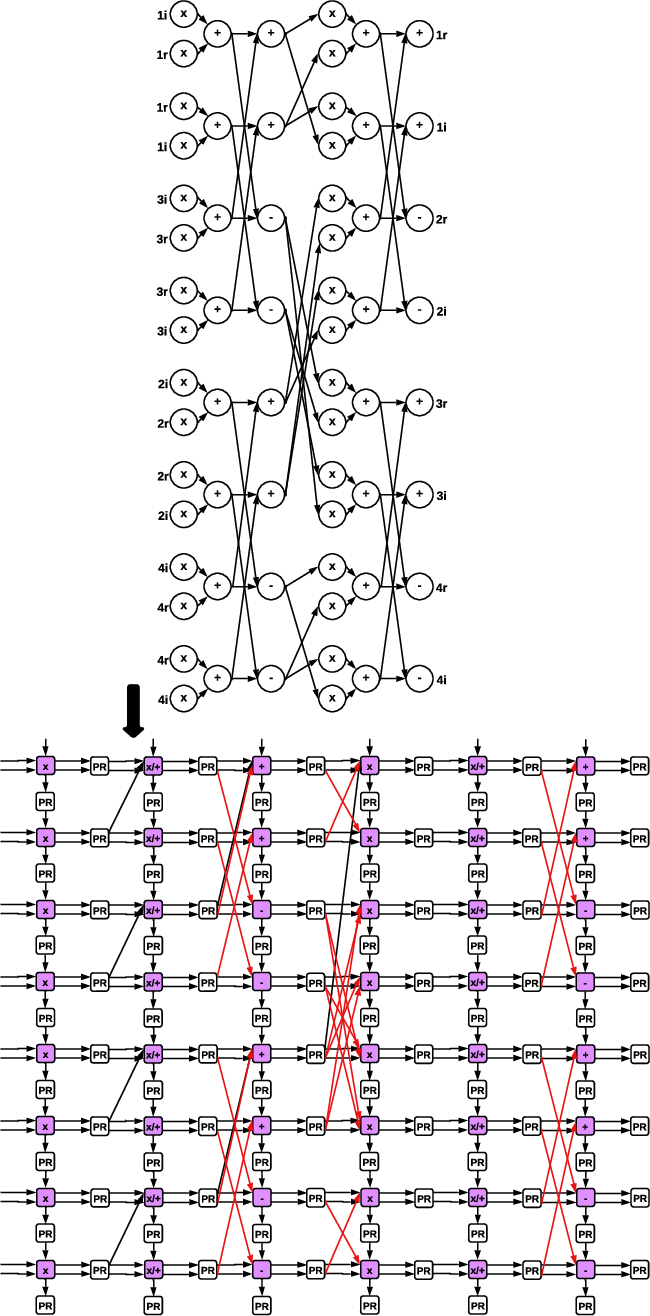
Figure 4: Augmented butterfly interconnects enable efficient FFT mapping onto the PCU for log-linear compute.
Experimental results demonstrate that this FFT-mode PCU realizes substantial speedups for long-sequence Hyena models. Notably, the Vector-FFT Hyena decoder on the FFT-mode RDU achieves a 1.95× speedup over GEMM-FFT on the baseline RDU and 5.95× over NVIDIA A100 for FFT-heavy SSMs (Figure 5, Figure 6).
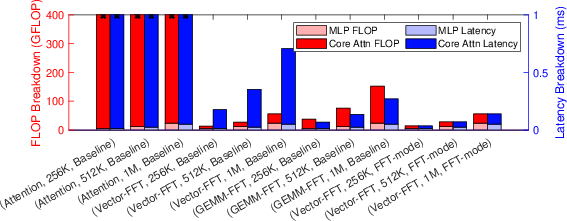
Figure 5: Speedups for various decoder and PCU architectural configurations. FFT-mode hardware delivers the lowest latency.
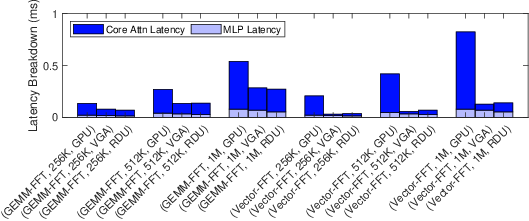
Figure 6: Comparative latency breakdown across GPU, VGA ASIC, and RDU; FFT-mode RDU and VGA outperform GPU by 5.95×.
Parallel Scan Support for Mamba
The Mamba SSM replaces attention with a linear-time scan (prefix-sum) operation. The baseline RDU is not well-suited for parallel scan variants (Hillis-Steele and Blelloch), since these require cross-lane data propagation. By embedding minimal, dedicated interconnects for spatially executing either scan variant (Figure 7), SSM-RDU achieves full utilization and low-latency computation.
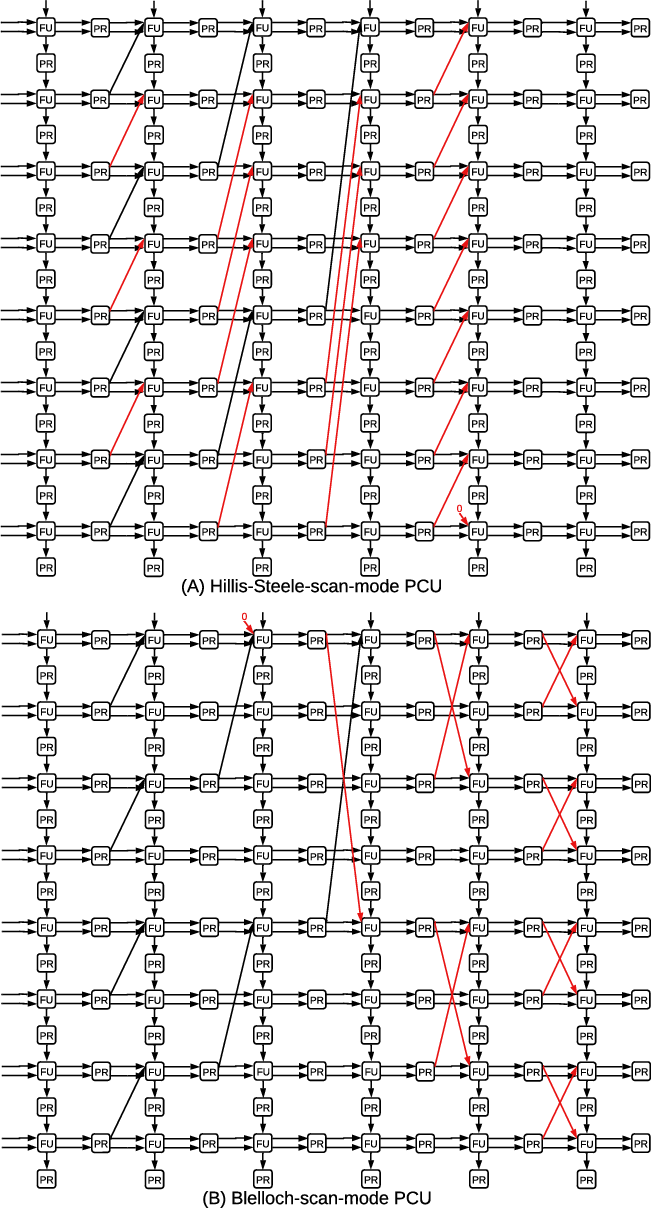
Figure 7: Enhanced PCU implements cross-lane interconnects for high-performance parallel scan algorithms.
Experimentally, the parallel-scan Mamba decoder achieves a 562.98× speedup over serial scan and an additional 1.75× over the baseline RDU with the dedicated scan-mode. Against an A100 GPU, scan-mode RDUs provide a 2.12× throughput improvement for long-sequence Mamba inference (Figure 8, Figure 9).
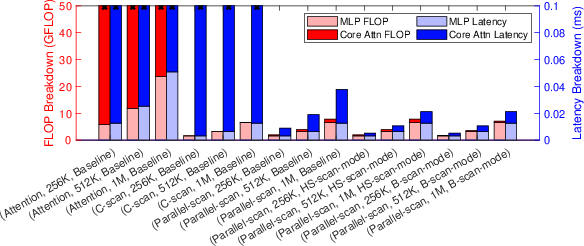
Figure 8: Comparison of decoder designs highlights dramatic latency reduction from parallel scan and scan-mode extensions.
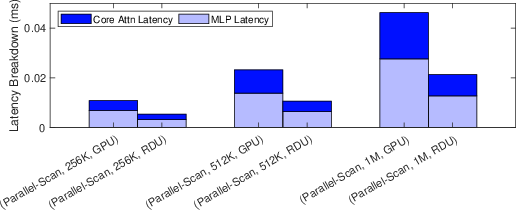
Figure 9: RDU delivers a 2.12× speedup over GPU for parallel-scan Mamba decoding.
Hardware Overhead Analysis
A compelling aspect of the proposed architectural augmentations is their minimal physical footprint. Synthesis results indicate that the FFT-mode, HS-scan-mode, and B-scan-mode PCU enhancements all incur less than 1% area and power overhead relative to the baseline design, maintaining the architectural flexibility of RDUs.
Architectural and Practical Implications
This work establishes that highly targeted, lightweight architectural enhancements can enable RDUs to spatially map and efficiently execute core SSM workloads—including both Hyena’s vector-FFT and Mamba’s parallel-scan—yielding multi-fold speedups over conventional accelerator hardware with negligible additional cost. Unlike fixed-function ASICs, SSM-RDU maintains reconfigurability and broad applicability across a diverse workload set.
On a theoretical level, the results challenge the consensus around GEMM-centric design, demonstrating that supporting log-linear and linear primitives is critical for the future of sequence modeling as SSM-based paradigms proliferate. From a systems perspective, such architectural flexibility positions the RDU as a competitive platform not only for LLM inference but for any dataflow-dominated, long-sequence computation.
Future Outlook
With the proliferation of task- and domain-specific SSMs, hardware specialization for key primitives (FFT, scan, and emerging analogues) is likely to continue. The SSM-RDU approach sets the stage for runtime-adaptive datapath specialization, dynamic resource allocation, and scalable on-chip fusion for increasingly heterogeneous workloads. The low overhead of the architectural enhancements also makes them candidates for rapid integration in existing reconfigurable and programmable accelerators. Further research could address mapping and scheduling mechanisms for classes of algorithms expressible as generalized scan/FFT operations and extend these principles to training accelerators and multi-node deployments.
Conclusion
SSM-RDU achieves efficient architectural support for FFT- and scan-centric SSMs via minimal, targeted enhancements to the RDU fabric. The architecture yields strong empirical speedups—up to 5.95× over leading GPUs for Hyena, and 2.12× for Mamba—at negligible cost in area and power. This work demonstrates that judicious microarchitectural interventions unlock dataflow execution models competitive with, or exceeding, fixed-function ASICs while maintaining general-purpose reconfigurability, and anticipates a hardware-software co-design trajectory focused on log-linear and linear sequence model primitives (2503.22937).