- The paper introduces a unified framework for neuro-symbolic reasoning by co-designing algorithms with specialized hardware to reduce inference latency.
- It employs a DAG abstraction to integrate symbolic, probabilistic, and neural computations, optimizing scheduling and memory usage.
- Empirical results demonstrate 12–50× speedup and 310–681× energy efficiency improvements, enabling scalable real-time applications.
Accelerating Probabilistic Logical Reasoning for Neuro-Symbolic AI: The REASON Framework
Introduction and Motivation
Neuro-symbolic AI architectures invoke both neural network-based perception and symbolic or probabilistic reasoning to achieve high levels of data efficiency, interpretability, and robustness. Monolithic neural models, especially LLMs and DNNs, excel at pattern recognition and natural language understanding but are limited in formal reasoning, multi-step deduction, and transparency. Conversely, symbolic and probabilistic modules provide structured, verifiable, and uncertainty-aware inference critical for tasks such as mathematical reasoning and planning.
However, a crucial operational barrier persists at the system and architectural level: symbolic and probabilistic inference kernels introduce severe latency and energy bottlenecks when mapped onto conventional CPUs and GPUs. These workloads exhibit irregular control and memory access patterns, low arithmetic density, and high sparsity, leading to poor hardware utilization and insufficient scalability, particularly for real-time or edge deployment.
REASON is proposed as an integrated acceleration system that targets these bottlenecks via algorithm-architecture co-design. The framework achieves significant reductions in inference latency and energy consumption, positioning itself as a foundational architecture for scalable deployment of neuro-symbolic AI systems (2601.20784).
Neuro-Symbolic Computation Pipeline
The neuro-symbolic pipeline disaggregates computation into neural, symbolic, and probabilistic modules, each fulfilling a distinct cognitive role. Neural components handle perception and abstraction via DNNs/LLMs, producing high-dimensional intermediate representations. Symbolic modules, implemented with FOL, SAT, and similar logical frameworks, execute deterministic reasoning atop these abstractions. Probabilistic modules utilize tractable models like probabilistic circuits (PC) and HMMs for robust inference under uncertainty.
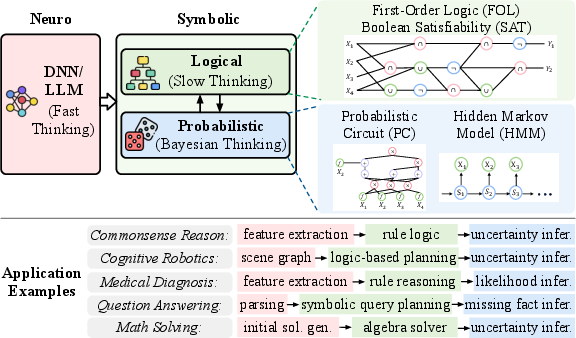
Figure 1: Neuro-symbolic pipeline orchestrating neural, symbolic, and probabilistic modules for compositional cognitive tasks.
This hierarchical structure—intuitive neural generalization, structured symbolic deduction, and uncertainty-aware probabilistic reasoning—yields demonstrable improvements in both reasoning accuracy and scaling. Comparative studies in the paper show that smaller neuro-symbolic models outperform or match the accuracy of substantially larger LLMs and scale more efficiently in both resource and energy use.
Computational Bottlenecks in Neuro-Symbolic Workloads
A significant empirical observation is that symbolic and probabilistic kernels often dominate end-to-end runtime and energy consumption on contemporary hardware platforms. Profiling state-of-the-art neuro-symbolic models—e.g., AlphaGeometry, R²-Guard, GeLaTo, Ctrl-G, NeuroPC, and LINC—reveals that symbolic and probabilistic kernels frequently contribute 35–65% of total runtime, far outpacing neural perception modules on both server-class GPUs and embedded devices.
The performance bottleneck is primarily due to:
- Irregular control flow and memory access patterns.
- Sparse and data-dependent computation graphs.
- High DRAM bandwidth utilization, low ALU utilization, and poor cache locality.
- Limited hardware-exploitable parallelism.
The resulting inefficiency is exacerbated as the scale or complexity of reasoning tasks increases. Memory-bound kernels, in particular, experience substantial scalability challenges, as evidenced by roofline analyses and microarchitectural profiling.
Unified DAG Abstraction for Symbolic and Probabilistic Reasoning
A key algorithmic innovation is the unification of symbolic and probabilistic reasoning as computations over directed acyclic graphs (DAGs). Logical deduction (SAT, FOL), probabilistic aggregation (PCs), and temporal inference (HMMs) are all mapped to DAG kernels where nodes correspond to atomic operations and edges encode dependencies.

Figure 3: Unified DAG representations for logical, probabilistic, and sequential kernels enable a shared compilation and mapping flow.
This abstraction supports:
- Compiler-driven optimizations for regularization and scheduling.
- Adaptive DAG pruning, which eliminates semantically redundant subgraphs, reducing memory and computational footprint with negligible effect on model accuracy.
- Balanced two-input regularization, where high-fan-in nodes are decomposed into binary trees, standardizing execution and enabling parallelization.
This algorithmic flow reduces task memory requirements by up to 43% on benchmarking tasks, without sacrificing accuracy and with bounded theoretical degradation in likelihood or solution quality.
Architecture: REASON Accelerator Design
REASON introduces a reconfigurable, tree-based architectural substrate tightly integrated as a GPU co-processor.
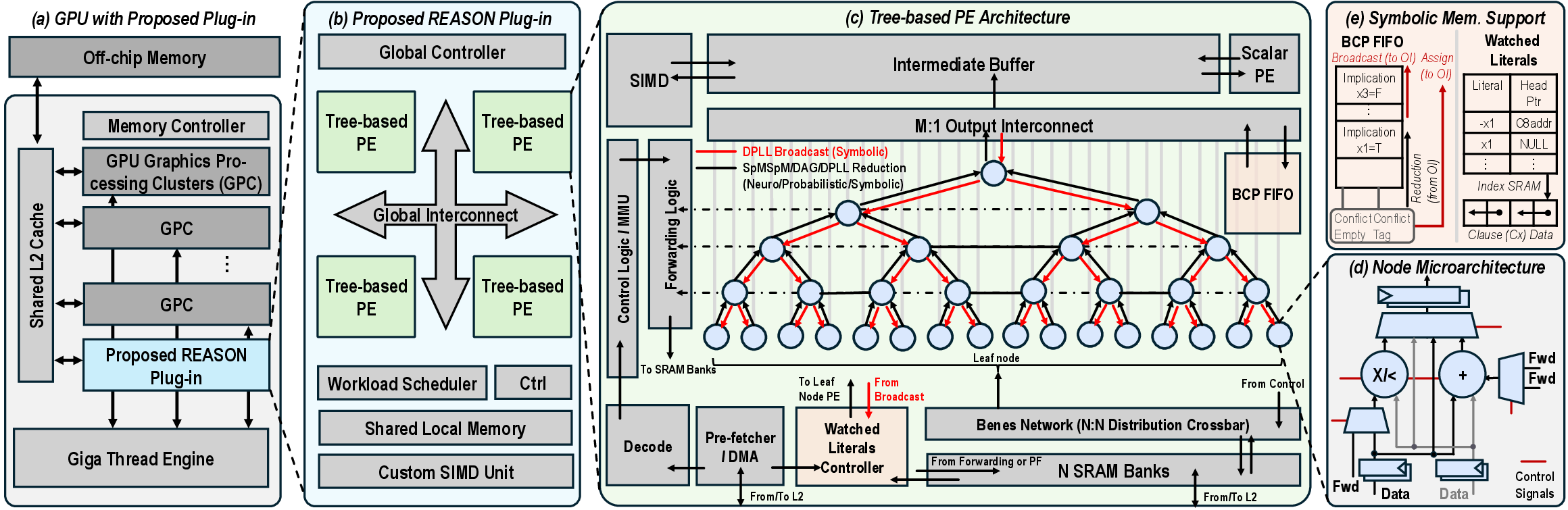
Figure 5: REASON hardware overview, including GPU integration, plug-in architecture with tree-based processing elements, and memory organization for symbolic reasoning.
Key Architectural Elements
- Tree-Structured Processing Elements (PEs): Each PE is a reconfigurable tree, mapping logical and probabilistic operations efficiently. The architecture supports dynamic switching between symbolic (logical), probabilistic, and sparse neural computation.
- Optimized Memory Hierarchy: Dual-port, wide-bit SRAM banks and a Benes crossbar deliver high-bandwidth and conflict-free access patterns, essential for memory-bound irregular DAG traversal.
- Watched-Literal Memory Layout: Hardware-managed clause indexing accelerates Boolean constraint propagation, essential for SAT and FOL-based reasoning.
- Pipeline-Friendly Dataflow: Multi-level intra-REASON and GPU-REASON pipelines maximize computation overlap, minimizing idle cycles and communication stalls.
Compiler support comprises block decomposition, PE mapping, and conflict-aware scheduling tailored for the irregular execution patterns inherent to neuro-symbolic computation.
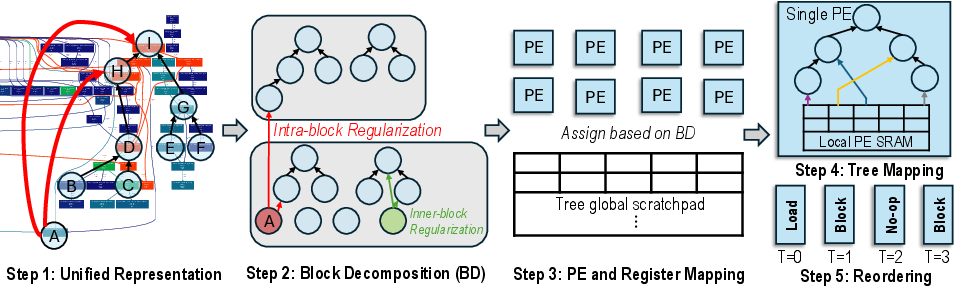
Figure 7: Compiler-architecture co-design for mapping DAGs to PE trees with pipeline-conscious scheduling and efficient register allocation.
System Integration and Parallel Execution
REASON operates as a tightly coupled GPU co-processor, sharing L2 cache and on-chip communication fabric. Workload partitioning is explicit: neural (LLM/DNN) kernels execute on GPU, while symbolic/probabilistic DAG kernels are executed on REASON. Pipelined execution enables concurrent processing of multiple task batches, further improving throughput and masking kernel-level latencies.
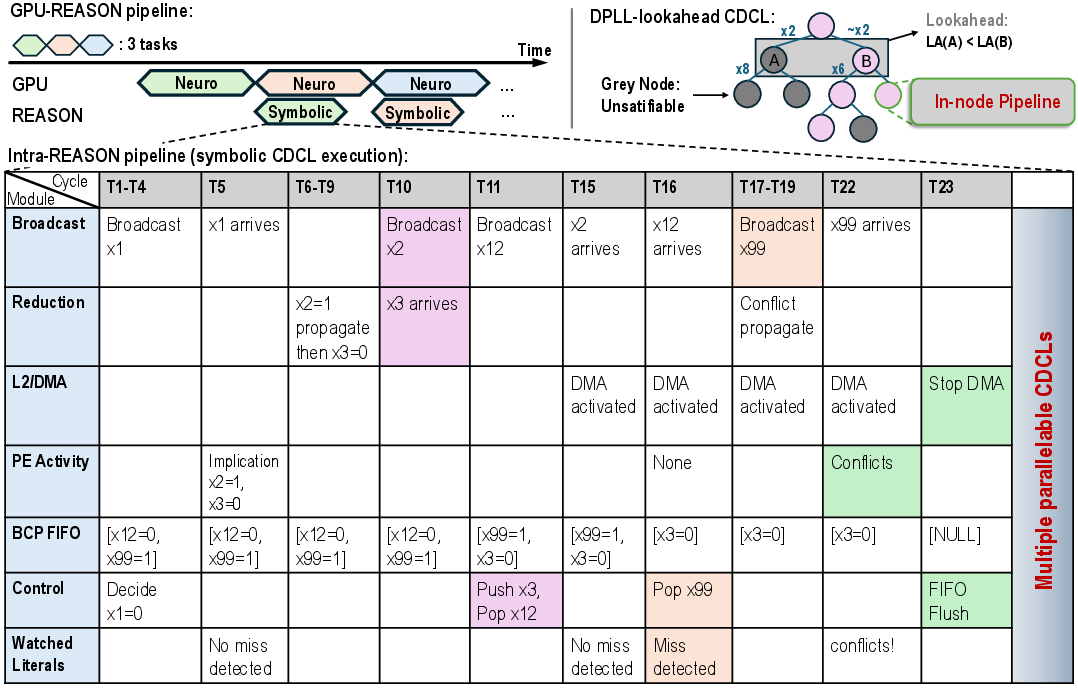
Figure 2: Two-level execution pipeline: overlapped GPU-REASON execution and cycle-level timing of pipelined SAT solving with efficient broadcast/reduction and conflict handling.
Empirical Results and Comparative Analysis
REASON yields 12–50× speedup and 310–681× energy efficiency over GPU/CPU baselines across a standardized suite of reasoning tasks. The accelerator achieves real-time (<1s) end-to-end task completion, using 6 mm² area and 2.12 W peak power at 28 nm.
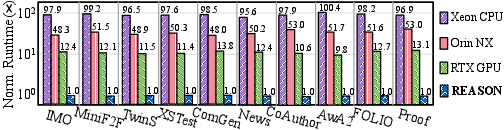
Figure 4: REASON delivers substantial end-to-end runtime reductions versus mainstream CPUs and GPUs across diverse cognitive reasoning workloads.
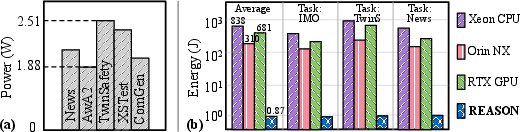
Figure 6: REASON significantly improves energy efficiency over baseline CPU/GPU systems for symbolic and probabilistic workloads.
Compared to ML accelerators like TPU (systolic array) and DPU (tree-based array), REASON matches neural throughput while providing higher efficiency for symbolic and probabilistic kernels, translating to superior system-level speedup for neuro-symbolic agents.

Figure 12: REASON attains improved end-to-end efficiency over TPU-like and DPU-like accelerator designs for neuro-symbolic system workloads.
Ablation studies underscore the necessity of algorithm-architecture co-design: algorithmic optimizations alone reduce runtime by 12–22%, but the combined effect with REASON hardware delivers runtime reductions to only ∼2% of the original baseline for targeted reasoning workloads.
Implications and Prospects for Neuro-Symbolic AI
By addressing the operational bottleneck for scalable, efficient neuro-symbolic AI, REASON brings practical deployment of agentic and interpretable cognitive systems within reach for a broad range of applications—including mathematical reasoning, formal verification, and robust autonomous agents. The architectural unification of symbolic and probabilistic execution, along with modular GPU co-design, positions REASON as a general solution compatible with future advances in LLM+tools pipelines.
Future work may explore:
- Extension to even more irregular reasoning kernels (e.g., higher-order logics, complex probabilistic programming).
- Further hardware-software co-design for dynamic workload adaptation and real-time optimization.
- Integration with memory-centric and brain-inspired architectures to support lifelong continual reasoning and learning.
Conclusion
REASON demonstrates that targeting the explicit computational structure of symbolic and probabilistic reasoning through unified DAG abstraction and flexible hardware is critical for unlocking neuro-symbolic AI at practical latency and energy budgets. Its systematic co-design principles yield robust, scalable, and interpretable cognitive architectures, setting a precedent for future advances in hybrid neural-symbolic-agentic systems (2601.20784).