When Does Sparsity Mitigate the Curse of Depth in LLMs
Abstract: Recent work has demonstrated the curse of depth in LLMs, where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixtureof-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training deptheffective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs. Code is available at https://github.com/pUmpKin-Co/SparsityAndCoD.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a problem in big LLMs called the “curse of depth.” As these models get more and more layers, the later layers often don’t do much—they mostly pass the information along without really changing it. The authors ask: can “sparsity” (making parts of the model or its computations intentionally use fewer connections at a time) fix this, not just to save compute, but to make deep layers actually useful?
The main questions in simple terms
The authors focus on three easy-to-grasp questions:
- Do very deep models actually use their later layers, or do those layers become almost pointless?
- Why does this happen? (They point to “variance,” which you can think of as how “loud” or “wild” the signals get as they pass through many layers.)
- Can making the model “sparser” (using fewer, more focused connections or computations) keep the signals calmer and make the deeper layers helpful again?
How they studied it (with plain-language explanations)
The team used two kinds of tools: careful experiments and some math.
- They trained the same kind of LLM at different depths (12–32 layers) and kept everything else the same. This isolates the effect of depth.
- They measured “how much each layer matters” in three simple ways:
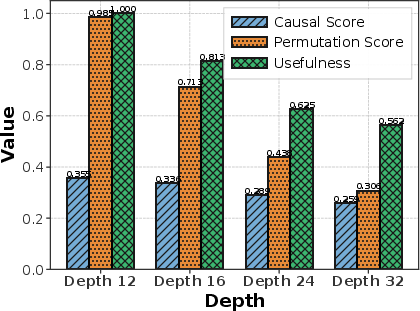
- Causal Score: If you remove a layer, does it mess up what happens in later layers? If not, that layer might not be doing much.
- Permutation Score: If you swap the order of two layers and nothing breaks, those layers may be interchangeable (i.e., not very specialized).
- Usefulness Score: If you replace a layer with a simple “straight-line” version (a linear function) and the model works the same, the layer isn’t adding new, complex thinking.
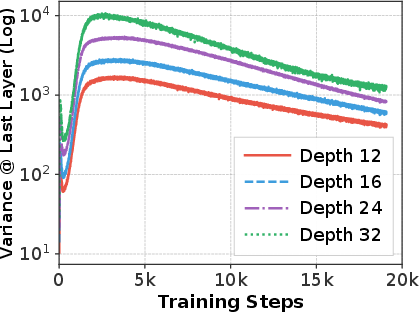
- They tracked “variance” across layers. Think of variance like background volume: if the overall signal gets too loud as it goes deeper, small changes from a layer are hard to hear—so the layer’s effect becomes tiny.
- They tested “sparsity” in two ways:
- Implicit sparsity (it happens naturally during training or from the data):
- Weight decay: a training trick that nudges small weights toward zero, gently simplifying the model.
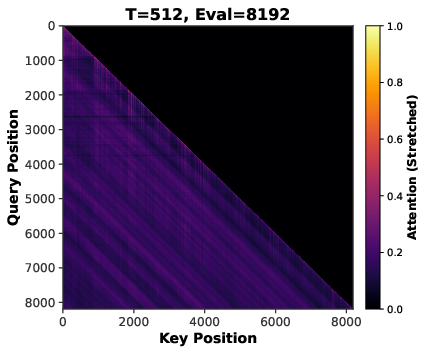
- Long sequences: with longer texts, the attention mechanism naturally focuses on fewer important tokens (making attention more “sparse”).
- Explicit sparsity (built into the model’s design):
- GQA (Grouped Query Attention): multiple “query” heads share the same “key/value” heads, reducing duplicated work.
- MoE (Mixture of Experts): for each token, the model only activates a few specialized “experts,” not all of them.
- They also included math arguments that explain the basic idea: in deep models, variance can grow and make layers act like identity layers (doing almost nothing). Sparsity reduces how much variance grows from one layer to the next, so deeper layers can keep contributing.
To visualize this, imagine a long line of people whispering a message (layers). If the background noise (variance) grows too loud down the line, the whispers from later people don’t change the message much—they’re drowned out. Sparsity is like asking only a few people to talk at once, or averaging several calm voices, which keeps the background noise low so everyone’s contribution is heard.
What they found and why it matters
Here are the main findings put simply:
- Deeper models really do have a “curse of depth.”
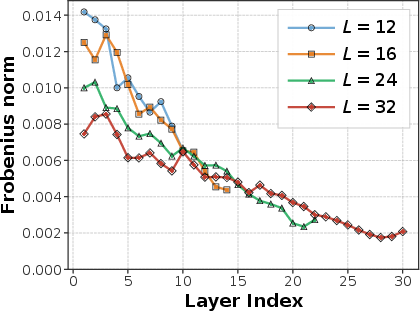
- As depth increases, variance grows. Later layers’ changes are tiny compared to the large “residual stream” (the running sum of earlier signals). In math terms, those layers become close to “identity mappings,” meaning they mostly pass info through unchanged.
- Their layer scores confirm this: deeper models show lower Usefulness and Causal Scores and higher interchangeability (Permutation Score). Translation: many deep layers aren’t adding much new thinking.
- Sparsity acts like a “volume control” for variance—and it works across the board.
- Weight decay (implicit sparsity):
- Moderately stronger weight decay made the final signals calmer and improved both perplexity (a standard language modeling score) and layer usefulness.
- Too much weight decay, however, “over-dampened” the model and hurt performance—so there’s a sweet spot.
- Longer training sequences (implicit sparsity):
- Training with longer contexts made attention focus more sharply on fewer positions (more sparse attention), which lowered variance and improved layer usefulness—up to a point.
- Extremely long sequences eventually gave diminishing returns and could even hurt performance (again, too much dampening reduces capacity).
- GQA/MQA (explicit sparsity):
- Sharing key/value heads (fewer independent key/value sets) reduced variance and nudged more layers to be genuinely useful. Even when compute was kept equal, these models did slightly better.
- MoE (explicit sparsity):
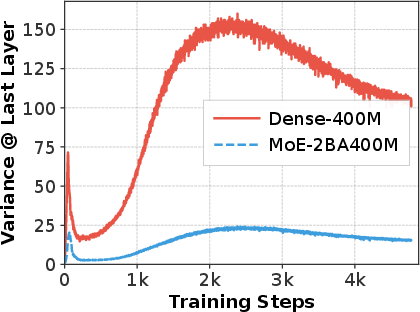
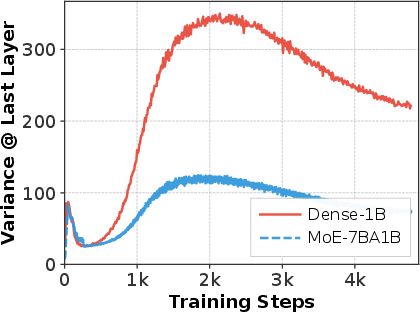
- Activating only a few experts per token (instead of all) reduced variance a lot (3–6× in their tests), improved perplexity by a solid margin, and made far more layers meaningfully useful.
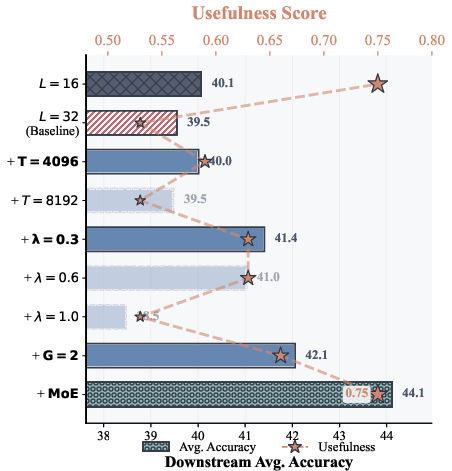
- Putting it all together gives a clear rule of thumb.
- If you want very deep LLMs to actually use their later layers, combine complementary forms of sparsity (for example, moderate weight decay + longer context + GQA + MoE).
- In their experiments, this combo improved downstream task accuracy by about 4.6% and kept more layers truly doing work.
Why this is important
- Bigger isn’t automatically better. Simply stacking more layers often wastes compute because later layers may do very little. This is bad for training efficiency.
- Sparsity isn’t just about speed. People often use sparsity to run models faster. This paper shows sparsity also helps the model learn better by keeping signals stable so deeper layers can contribute.
- There’s a balance. Too little variance control and deep layers become pointless; too much and the model can’t learn rich patterns. The best results come from moderate, well-chosen sparsity.
- Practical takeaway for building LLMs: Use a mix of sparsity tools (like weight decay, longer contexts, GQA, and MoE) to make deep models both efficient and truly deep in what they learn.
Key takeaways
- The “curse of depth” is real: later layers in very deep LLMs often do almost nothing because the signal gets too “loud” (variance grows).
- Sparsity—both implicit (e.g., weight decay, longer sequences) and explicit (e.g., GQA, MoE)—naturally reduces that loudness and makes deeper layers useful again.
- There’s a sweet spot: moderate sparsity improves performance and layer usefulness; too much can over-dampen the model.
- Combining sparsity methods is a practical recipe for training deeper, more effective LLMs, leading to measurable accuracy gains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper establishes an intriguing link between sparsity and mitigation of the curse of depth (CoD) via variance dampening. However, several aspects remain underexplored or uncertain:
- Architectural generality
- Does the variance-dampening effect of sparsity hold for alternative normalization/residual designs (e.g., RMSNorm, DeepNet/ScaledInit, Mix-LN, MHC/HyperConnections, Post-LN, sandwich norm) beyond the Pre-LN setting studied?
- How do sparse attention variants (linear/flash/sdpa approximations, local/long-range hybrid attention) interact with CoD and sparsity-induced variance control?
- Scaling behavior and external validity
- Do the observed trends persist at substantially larger scales (e.g., 7B–70B dense models, multi-hundred-billion-parameter MoE) and over longer training durations (tokens)?
- What is the behavior under realistic training regimes with curriculum, data mixtures, and instruction tuning/RLHF—does sparsity still mitigate CoD?
- Task and capability coverage
- Are gains from sparsity uniform across diverse capabilities (math, code, multilingual, long-context retrieval, reasoning with chain-of-thought), or are there task-dependent trade-offs?
- Does sparsity that increases attention peaking compromise long-range dependency modeling in tasks requiring global context?
- Theoretical assumptions and gaps
- The main variance bound assumes independence between weights and masks (W and D) and Gaussian inputs; training-induced sparsity violates independence. Can theory be extended to dependent, data-driven sparsity patterns and non-Gaussian, structured activations (e.g., with LayerNorm, RoPE, softmax)?
- The analysis reduces attention/FFN to linear maps and assumes uniform attention/independence across values; can tighter, realistic bounds be derived incorporating softmax, RoPE, gating noise, and routing dynamics?
- How can effective mask density be rigorously connected to measurable quantities in real models (e.g., attention sparsity histograms, expert selection statistics) to make the bound predictive?
- Causality vs. correlation
- The work shows correlations between increased sparsity, reduced variance, and improved layer metrics; can causal attribution be strengthened via controlled interventions that modify variance without changing capacity or inductive biases (e.g., variance-preserving rescaling vs. sparsity-only changes)?
- For MoE and GQA, can matched-capacity/compute ablations isolate variance effects from capacity, grouping, or routing-induced inductive biases?
- Experimental controls and confounds
- Depth-scaling experiments hold width fixed but allow parameter count to vary with depth; can results be replicated with strictly matched parameter/compute budgets (e.g., adjust width vs. depth to keep total params constant)?
- Sequence-length experiments adjust steps to keep FLOPs constant, but longer sequences alter gradient noise, batch statistics, and token distributions; can these confounds be disentangled (e.g., via microbatching/accumulation controls or synthetic benchmarks)?
- Over-dampening and optimality
- The paper observes “over-dampening” with excessive weight decay or very long sequences; can a principled criterion (or schedule) be derived to set sparsity levels that optimize the variance–capacity trade-off across training?
- How do multiple sparsity mechanisms interact (weight decay, long context, GQA, MoE)? Are their effects additive, redundant, or synergistic—and how to tune them jointly?
- Metrics and measurement rigor
- The layer effectiveness metrics depend on choices (e.g., usefulness threshold α=0.1) and contain typos in formulas; how sensitive are conclusions to these choices, and can standardized, robust metrics be established?
- Are conclusions statistically robust across seeds and datasets (most results cite few seeds)? Provide confidence intervals and significance tests for variance and effectiveness metrics.
- Jacobian computations and ||J−I||F estimates can be noisy/approximate at scale; what are the exact procedures (sampling, token positions, normalization), and how do results change with alternative Jacobian proxies (e.g., singular value spectra of layer maps)?
- Mechanistic understanding
- Which submodules drive variance growth and mitigation (attention vs. MLP, early vs. late layers)? A fine-grained per-block/per-head analysis could identify intervention targets.
- How does sparsity reshape gradient flow (e.g., gradient norms, Fisher information, NTK dynamics) and representation geometry (e.g., anisotropy, token-wise variance/kurtosis) across depth?
- MoE-specific gaps
- How do routing noise, capacity factors, expert load balancing, and expert collapse affect variance control and CoD? Are benefits robust under realistic training instabilities?
- Does the 1/k variance reduction persist when routing depends on activations (nonlinear, discontinuous selection) and under distribution shift?
- GQA-specific gaps
- Beyond key/value sharing, how do different grouping strategies (learned vs. fixed groups), head dimensions, and head mixing influence variance and layer utility?
- What is the trade-off between reduced variance and potential loss of head diversity/expressivity as grouping increases?
- Interaction with other regularizers and design choices
- How do dropout, attention dropout, activation functions (GeLU/SwiGLU/ReLU), weight tying, and normalization hyperparameters interact with sparsity-induced variance control?
- Does combining sparsity with explicit variance-control initializations or residual-scaling (e.g., DeepNet, µParam scaling) yield additive or diminishing returns?
- Practical efficiency and systems aspects
- The paper argues sparsity is compute-friendly but does not report wall-clock training/inference efficiency, memory bandwidth, and communication overheads (especially for MoE). Do practical speedups align with theoretical FLOP reductions?
- Does variance dampening help or hinder training stability (loss spikes, divergence) and convergence speed in wall-clock terms?
- Generalization across modalities and settings
- Do results transfer to vision transformers, speech, or multimodal LLMs where attention statistics and normalization differ?
- Are benefits maintained under continual learning or domain adaptation, where variance control may affect plasticity/forgetting?
- Evaluation breadth
- The “rule-of-thumb” recipe is validated primarily on ARC-C and HellaSwag with a 4.6% improvement; does it generalize across a broader, standardized benchmark suite (e.g., MMLU subsets, BIG-bench, GSM8K, HumanEval, multilingual tasks) and across training/evaluation context lengths?
- Bridging theory and practice
- Can a calibrated mapping be built from measured sparsity signals (e.g., attention weight distributions, fraction of active experts, weight magnitude histograms) to predicted variance bounds and expected layer effectiveness—enabling proactive tuning during training?
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s findings as concrete guidance for training, evaluating, and operating LLMs. Each item includes target sectors, potential tools/workflows, and feasibility notes.
- Depth-effective training recipes for LLMs (software, AI platforms)
- What: Adopt the paper’s rule-of-thumb: combine moderate weight decay (e.g., around 0.1), extend training context to ~2k–4k tokens, enable GQA (e.g., groups 4–16), and leverage sparse MoE (e.g., top-k) when feasible to mitigate variance growth and improve layer utilization.
- Tools/workflows: “Sparsity-aware trainer” that auto-tunes weight decay and sequence length schedules; presets for GQA and MoE.
- Assumptions/dependencies: Pre-LN Transformer backbones; tuning to avoid over-dampening (too much weight decay or too-long contexts can hurt performance).
- Layer effectiveness monitoring in MLOps (software, ML operations)
- What: Integrate Causal Score, Permutation Score, and Usefulness Score dashboards to flag underutilized layers and diagnose the curse of depth during training.
- Tools/workflows:
layer_effectiveness_profilermodule; CI hooks in training pipelines; variance trend alerts on last-layer hidden states. - Assumptions/dependencies: Access to hidden states and per-layer swaps/ablations in staging; minor training overhead.
- Compute- and cost-efficient inference via GQA (industry-wide, cloud inference)
- What: Switch to Grouped Query Attention (GQA) or MQA in inference stacks to reduce KV memory/computation while also improving depth utilization.
- Tools/workflows: Model conversion scripts to GQA; inference kernels supporting shared KV.
- Assumptions/dependencies: Kernel support for GQA/MQA; regression tests to preserve quality.
- Faster training convergence and stability via weight decay tuning (software, finance, healthcare)
- What: Use moderate weight decay to reduce variance accumulation and improve layer usefulness without harming capacity.
- Tools/workflows: LR–WD grid search with variance/utilization early-stopping criteria; WD warmup/cooldown schedules.
- Assumptions/dependencies: Avoid high WD (e.g., ≥1.0) to prevent collapse; monitor perplexity and usefulness jointly.
- Long-context pretraining/finetuning that avoids variance blow-up (legal, healthcare, education, enterprise knowledge management)
- What: Train on longer sequences (≈2k–4k) to induce attention sparsity and reduce variance, improving long-document reasoning.
- Tools/workflows: Curriculum schedules that ramp sequence length; attention sparsity and entropy monitors.
- Assumptions/dependencies: Very long contexts (e.g., 8k+) can over-dampen; dataset must contain long documents to realize benefits.
- Efficiency upgrade paths for existing models through selective layer pruning (software, mobile)
- What: Use low usefulness/permutation scores to prune or skip redundant deep layers, yielding smaller or faster models with minimal loss.
- Tools/workflows: “Depth-pruner” that targets layers below usefulness thresholds; A/B tests against task metrics.
- Assumptions/dependencies: Post-hoc pruning safer if combined with brief recovery finetuning; monitor distribution shifts.
- MoE retrofits for capacity without proportional compute (cloud AI, enterprise NLP)
- What: Replace dense FFNs with top-k MoE to keep active compute constant while expanding total parameters and improving layer utilization.
- Tools/workflows: Router load-balancing, expert parallel kernels; “MoE-as-a-Library” components.
- Assumptions/dependencies: Routing stability/load balancing; hardware/software support for expert parallelism.
- Sector-specific long-context applications with better depth utilization (healthcare, legal, finance)
- What: Summarization and retrieval-augmented generation over EHRs, contracts, filings; improved consistency from variance dampening.
- Tools/workflows: Long-context finetuning (2k–4k), GQA-enabled inference; Usefulness-based pruning for edge deployments.
- Assumptions/dependencies: Data governance and privacy; domain evaluation sets to confirm robustness.
- Variance-aware hyperparameter search (research labs, applied ML)
- What: Include last-layer variance and effectiveness scores as objectives in AutoML/HP search to avoid CoD regimes.
- Tools/workflows: Multi-objective HPO with variance/utilization constraints.
- Assumptions/dependencies: Slightly higher evaluation cost; effectiveness metrics must be reproducible across seeds.
- Model cards and internal QA with depth-utilization metrics (governance, compliance)
- What: Report “effective nonlinear depth” (Usefulness score), variance trends, and sparsity settings to audit compute utilization.
- Tools/workflows: Model card templates extended with utilization figures and sparsity configs.
- Assumptions/dependencies: Organizational buy-in; standardized thresholds for “effective” layers.
Long-Term Applications
These opportunities require further research, scaling, systems engineering, or standardization before widespread deployment.
- Automatic sparsity controllers for training (software, AutoML)
- What: Closed-loop controllers that adjust weight decay, sequence length, GQA grouping, and MoE top-k on the fly to maintain target variance and usefulness.
- Tools/products: “AutoSparsity” controller integrated with schedulers and router policies.
- Dependencies: Robust online estimators of variance/utilization; stability guarantees.
- Dynamic depth execution at inference (cloud, edge, mobile)
- What: Skip or condense layers adaptively based on token-level usefulness forecasts to cut latency/energy.
- Tools/products: Depth-gating runtime; token-level confidence/usefulness predictors.
- Dependencies: Real-time signals; guardrails to prevent accuracy cliffs.
- Energy-efficiency and sustainability standards incorporating depth utilization (policy, regulators, ESG)
- What: Require reporting of effective depth, sparsity configs, and variance control in AI energy audits and procurement.
- Tools/products: Standardized metrics and audits; green AI certifications reflecting utilization, not just FLOPs.
- Dependencies: Multi-stakeholder consensus; sector-specific benchmarks.
- Compiler/runtime support for sparse routing and shared-KV (systems, hardware)
- What: Kernels and scheduling for MoE/GQA that co-optimize memory bandwidth, cache locality, and interconnect traffic.
- Tools/products: Triton/CUDA extensions; graph compilers that fuse KV-sharing and expert routing.
- Dependencies: Hardware topology awareness; vendor support.
- Curriculum strategies for length and sparsity co-scheduling (education tech, research)
- What: Joint schedules that ramp sequence length and sparsity to optimize stability, generalization, and long-context competence.
- Tools/products: “Length–Sparsity Curriculum” modules in training frameworks.
- Dependencies: Theory-guided schedules that avoid over-dampening; domain-specific tuning.
- Cross-modal extension to vision, speech, and multimodal transformers (healthcare imaging, robotics, media)
- What: Apply sparsity-as-variance-regularizer to deep vision/speech stacks to stabilize very deep models.
- Tools/products: Multimodal kernels with GQA/MoE analogs; modality-specific effectiveness metrics.
- Dependencies: Empirical validation across modalities; adaptation of metrics.
- Safety and alignment with sparse routing (policy, safety research)
- What: Analyze whether MoE routing concentrates errors/bias in experts and how variance reduction interacts with toxicity/robustness.
- Tools/products: Expert-level auditing tools; bias/robustness probes per expert.
- Dependencies: Access to routing logs; privacy-preserving telemetry.
- Standardized “depth utilization” sections in model cards and benchmarks (academia, community standards)
- What: Benchmarks that score models on effective nonlinear depth and variance control alongside accuracy.
- Tools/products: Public suites to compute Causal/Permutation/Usefulness scores.
- Dependencies: Agreement on protocols and thresholds; seed sensitivity studies.
- Automated layer reordering and specialization during training (research, AutoML)
- What: Use permutation scores to learn beneficial layer orderings or heterogeneous blocks that maximize specialization.
- Tools/products: NAS components optimizing order/type per depth.
- Dependencies: Stability of reordering; compatibility with checkpoints.
- Hardware co-design for sparse deep LLMs (semiconductors, cloud providers)
- What: Architectures optimized for KV sharing and expert routing, with memory hierarchies favoring sparse access patterns.
- Tools/products: MoE-first accelerators; KV-sharing caches.
- Dependencies: Market scale; software–hardware co-development timelines.
- Domain-specific long-context assistants with depth-efficient backbones (legal, healthcare, finance, education)
- What: Turn-key assistants handling 100+ page contexts with stable depth utilization and controlled variance.
- Tools/products: Verticalized “Depth-Efficient LLM” templates with GQA/MoE and length curricula.
- Dependencies: Licensed corpora; evaluation and compliance frameworks.
Notes on Assumptions and Dependencies (global)
- Model class: Results are derived for Pre-LayerNorm Transformers; transfer to other architectures or post-LN variants requires validation.
- Theory assumptions: Independence assumptions (e.g., masks and weights) are idealizations; the empirical guidance remains robust but not guaranteed in all regimes.
- Over-dampening risk: Too-strong weight decay or excessively long sequences can reduce capacity; monitor perplexity and usefulness jointly.
- Scale generalization: Experiments cover ~1.2B dense and 2B/7B MoE settings; extrapolation to 10B+ and instruction-tuned/chat models needs testing.
- Systems constraints: Effective MoE and GQA deployment depend on router balance, expert parallelism, and kernel support.
- Data characteristics: Benefits from long-context training depend on availability of long documents and task alignment.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from gradient-based parameter updates to improve training stability. "We employ the AdamW optimizer~\citep{loshchilov2019decoupledweightdecayregularization} with weight decay values of , while keeping all other hyperparameters fixed."
- ARC-C: The Challenge subset of the AI2 Reasoning Challenge benchmark for evaluating reasoning on difficult science questions. "We evaluate using average accuracy on ARC-C~\citep{clark2018thinksolvedquestionanswering} and HellaSwag~\citep{zellers2019hellaswagmachinereallyfinish}, and Usefulness Score."
- ARC-E: The Easy subset of the AI2 Reasoning Challenge benchmark for evaluating reasoning on easier science questions. "ARC-C & ARC-E & Hellaswag"
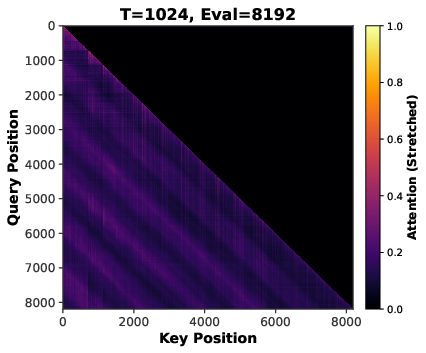
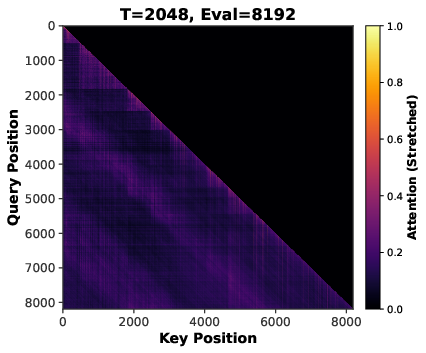
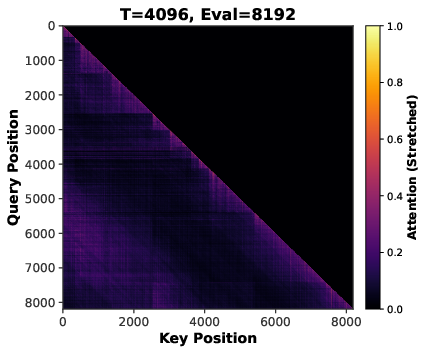
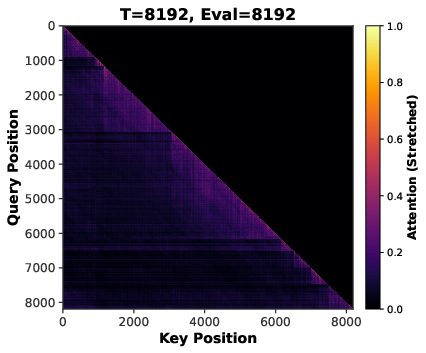
- Attention sparsity: The phenomenon where many attention weights become near-zero, concentrating computation on a subset of tokens. "attention sparsity induced by long-context inputs"
- Causal Score: A metric that measures how much removing a layer perturbs computations in subsequent layers. "The causal score measures how much each layer influences the computations of all subsequent layers~\citep{csordas2025language}."
- Curse of Depth (CoD): The degradation where deeper layers become under-utilized as variance accumulates and transformations approach identity. "have recently summarized this phenomenon as the curse of depth (CoD) and identified variance propagation as a key underlying cause of this ineffectiveness."
- Expert-activation sparsity: In MoE architectures, the design where only a subset of experts is activated per token, reducing active computation. "expert-activation sparsity in Mixture-of-Experts."
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used here to quantify deviation from identity. "(b) Jacobian Frobenius norm ."
- Gating network: A trainable module that selects which experts to activate for each token in MoE models. "a gating network routes each token to its top- experts:"
- Grouped Query Attention (GQA): An attention variant where multiple query heads share the same key/value projections to reduce computation. "GQA~\citep{ainslie2023gqa,shazeer2019fasttransformerdecodingwritehead} reduces attention computation by sharing key-value heads across multiple query heads."
- HellaSwag: A commonsense inference benchmark focusing on sentence completion tasks. "We evaluate using average accuracy on ARC-C~\citep{clark2018thinksolvedquestionanswering} and HellaSwag~\citep{zellers2019hellaswagmachinereallyfinish}, and Usefulness Score."
- Jacobian: The matrix of first-order partial derivatives describing local sensitivity of outputs to inputs. "causing deep layers to become functionally ineffective as their Jacobians approach the identity."
- Key/value-sharing sparsity: Architectural sparsity where multiple queries share the same key/value representations to limit variance and computation. "including key/value-sharing sparsity in Grouped-Query Attention"
- Layer Normalization (LN): A normalization technique that standardizes activations across features within a token to stabilize training. "the forward pass applies layer normalization before the transformation:"
- Layer pruning: Removing entire layers post-training to compress models by exploiting redundancy. "enabling model compression through layer pruning~\citep{li2405owlore,dumitru2024layer,yin2023outlier}"
- Mixture-of-Experts (MoE): An architecture with many expert sub-networks where only a small subset is activated per input for efficiency and capacity. "Mixture of Experts (MoE) activates only parameter subsets~\citep{liu2025deepseek,yang2025qwen3}"
- Mix-LN: An alternative normalization method proposed to improve stability and depth scaling in Transformers. "alternative normalization like Mix-LN~\citep{li2024mix,cai2025seednorm,ding2021cogview,wang2024deepnet}"
- MMLU: A benchmark (Massive Multitask Language Understanding) evaluating broad knowledge and reasoning across many subjects. "MMLU"
- Multi-Head Attention (MHA): The standard attention mechanism using multiple heads to capture diverse relationships. "denotes either a Multi-Head Attention (MHA) or FFN module,"
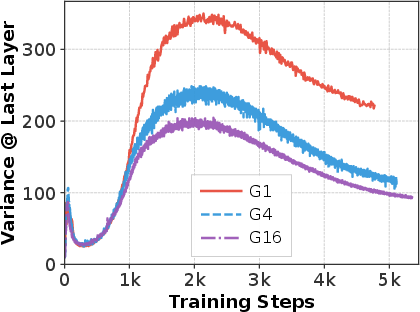
- Multi-Query Attention (MQA): An attention variant where multiple queries share a single key/value set, further reducing compute versus GQA. "We train 1.2B models with equal training FLOPs using group sizes (MHA, GQA, and MQA~\citep{shazeer2019fasttransformerdecodingwritehead}, respectively)."
- Permutation Score: A metric that quantifies layer specialization by measuring performance drop when swapping layer positions. "The permutation score quantifies layer specialization by measuring performance degradation when layer positions are swapped~\cite{kapl2025depth}."
- Perplexity (PPL): A standard language modeling metric where lower values indicate better predictive performance. "Validation perplexity and layer effectiveness scores across weight decay ."
- Pre-Layer Normalization (Pre-LN): A Transformer design applying LayerNorm before sublayers to improve training stability. "In widely adopted Pre-Layer Normalization (Pre-LN) architectures~\citep{xiong2020layer,kan2025stability,wang2203deepnet}, output variance tends to grow sub-exponentially with model depth~\citep{sun2025curse,takase2023spike}."
- Residual-depth recursion: A formal recursion describing residual updates across layers used to analyze variance growth. "Let follow the residual-depth recursion"
- Residual stream: The running summed representation in residual networks to which each layer adds its update. "the magnitude of the residual stream dwarfs the updates provided by individual layers"
- RoPE (Rotary Positional Embeddings): A positional encoding method that introduces relative position information via rotations in embedding space. "Position embeddings like RoPE~\citep{su2024roformer} introduce distance-dependent attention decay that the dot product decreases with relative distance."
- Scaled Initialization: Initialization schemes that explicitly scale parameters to control activation/gradient variance in deep networks. "such as Scaled Initialization~\citep{zhang2019improving,luther2019variancepreserving,takase2023spike}"
- Sequence length scaling: Training with longer input contexts to induce sparser and more stable attention patterns. "Sequence length scaling induce implicit sparsity in attention mechanisms through positional bias and softmax normalization~\citep{su2024roformer,xiao2023efficient,zhang2023h2o}."
- Softmax normalization: The exponentiation-and-normalization operation converting scores into a probability distribution in attention. "Softmax normalization over longer sequences produces more peaked distributions, concentrating attention on top-scoring positions while suppressing others toward zero~\citep{xiao2023efficient,zhang2023h2o,yuan2025native}."
- Top-k routing: A selection mechanism in MoE where the k highest-scoring experts are activated per token. "a gating network routes each token to its top- experts:"
- Usefulness Score: A metric that quantifies a layer’s nonlinearity and contribution by measuring loss increase when replaced by its best linear approximation. "Usefulness Score evaluates each layer's contribution to final performance."
- Variance propagation: The growth and transmission of activation variance across layers that can push deep blocks toward identity. "identified variance propagation as a key underlying cause of this ineffectiveness."
- Weierstrass theorem: A classical result ensuring convergence of bounded monotone sequences, invoked to argue stability at infinite depth. "and the Weierstrass theorem guarantees convergence."
- Weight decay: L2 regularization added to the loss or decoupled in the optimizer to shrink weights and induce sparsity. "Weight decay applies regularization to model parameters, adding penalty term to the loss function~\citep{loshchilov2019decoupledweightdecayregularization}."
Collections
Sign up for free to add this paper to one or more collections.