- The paper introduces a verification-centric framework that enhances atomic reasoning by employing dual-loop interactions and multi-modal tool integration.
- It details a modular training pipeline, combining mid-training, supervised fine-tuning, DPO, and GRPO to optimize multi-step reasoning and robust tool use.
- Empirical results show state-of-the-art performance with significant accuracy and efficiency gains across various specialized benchmarks.
MiroThinker-1.7 & H1: Verification-Centric Heavy-Duty Research Agents
Agentic Design and Workflow
MiroThinker-1.7 introduces a rigorously designed research agent architecture, grounded in iterative agent-environment interaction for complex multi-step reasoning tasks. The agent operates through a dual-loop mechanism comprising an outer episode loop managing trajectory restarts and an inner step loop responsible for reasoning, tool invocation, and external observation. Context management employs sliding-window filtering and targeted result truncation to sustain deep trajectories under fixed token constraints, ensuring retention of actionable evidence and mitigation of context degradation.
Tool interfaces encapsulate open-web retrieval, code execution (E2B Linux sandbox), and robust file/data transfer, supporting dynamic evidence gathering and synthesis. Malformed tool invocations are intercepted and corrected at the framework level, directly enhancing reliability in extended agentic sessions. Benchmark contamination is strictly prevented through domain blocklists and infrastructure-level source monitoring.
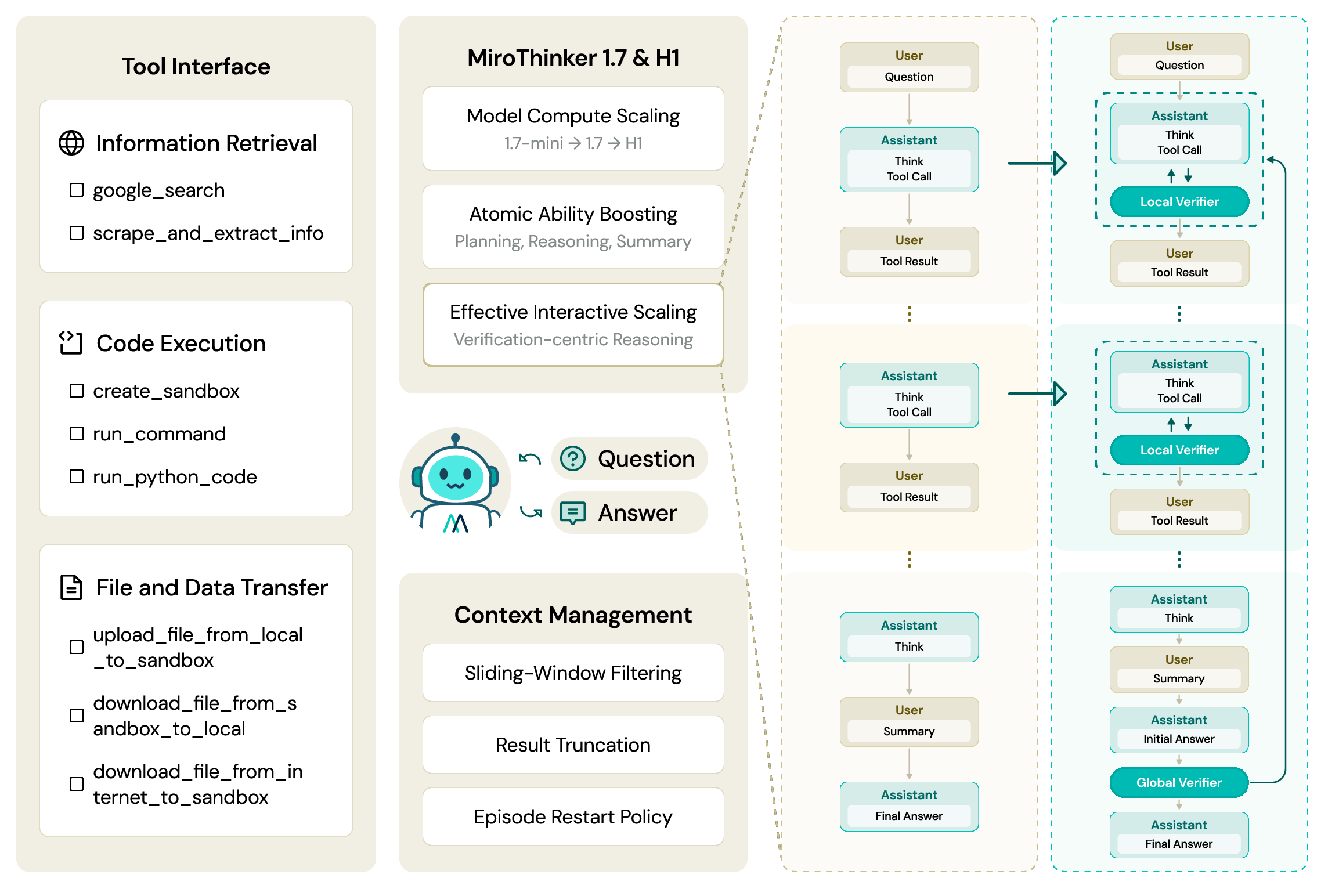
Figure 1: MiroThinker-1.7 system architecture, highlighting integrated agentic pipeline and modular tool interface.
High-Quality QA Construction and Adaptive Difficulty Curriculum
The QA synthesis framework leverages complementary Corpus-based and WebHop pipelines. Corpus-based generation exploits interlinked document graphs for high-throughput multi-hop QA via prompt-driven diversifications, while WebHop develops structured multi-hop reasoning trees grounded in open-web content, ensuring controlled reasoning depth and obfuscation of direct answer cues. Hierarchical solvability verification and adaptive leaf entity descriptions enforce non-triviality and solution uniqueness, with difficulty-adaptive post-hoc filtering established via search-agent discriminators.
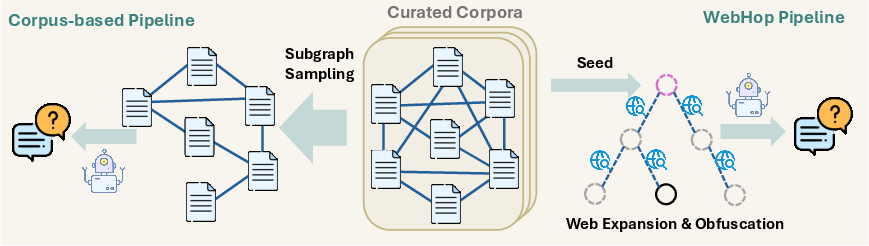
Figure 2: Dual-pipeline QA synthesis: corpus-based for breadth and WebHop for calibrated reasoning tree depth and verification.
Integrated Agentic Training Pipeline
Training proceeds in four stages: mid-training for atomic agentic capability enhancement (planning, reasoning, tool-use, summarization), supervised fine-tuning for multi-step trajectory imitation, direct preference optimization (DPO) employing correctness-based pairwise ranking without structural constraints, and reinforcement learning via Group Relative Policy Optimization (GRPO) in distributed environments.
Mid-training supervision is provided on diversified planning and reasoning/summarization samples, filtered by taxonomy-based LLM judges. SFT exploits cleaned multi-turn triplets with strict noise removal. DPO employs answer-centric preference pairs, stabilized by auxiliary SFT loss and alignment distillation for the mini variant. GRPO operates with streaming rollout acceleration, priority scheduling for difficult samples, explicit entropy control, and targeted KL penalization—optimizing for scalable and robust agentic RL.

Figure 3: MiroThinker-1.7 agentic training pipeline, integrating mid-training, SFT, preference optimization, and RL.
Verification-Centric Reasoning: Local and Global Modes
MiroThinker-H1 extends MiroThinker-1.7 with explicit local and global verification mechanisms.
Local Verification: At each intermediate step, the agent evaluates and refines candidate actions, disrupting probability-biased degenerate exploration modes. This ensures effective exploration of the solution space, with empirical evidence showing a six-fold reduction in steps on hard subsets (BrowseComp) and an increase of +26.4% in pass@1 (Table: Local Verifier).
Global Verification: Chains of evidence are audited before answer commitment. The agent resamples or completes reasoning chains if evidence is insufficient, ultimately selecting the answer with maximal evidence support under a bounded compute budget. This mechanism yields log-linear accuracy scaling with compute budget; BrowseComp performance increases from 85.9 to 88.2 as budget is scaled from 16× to 64×.
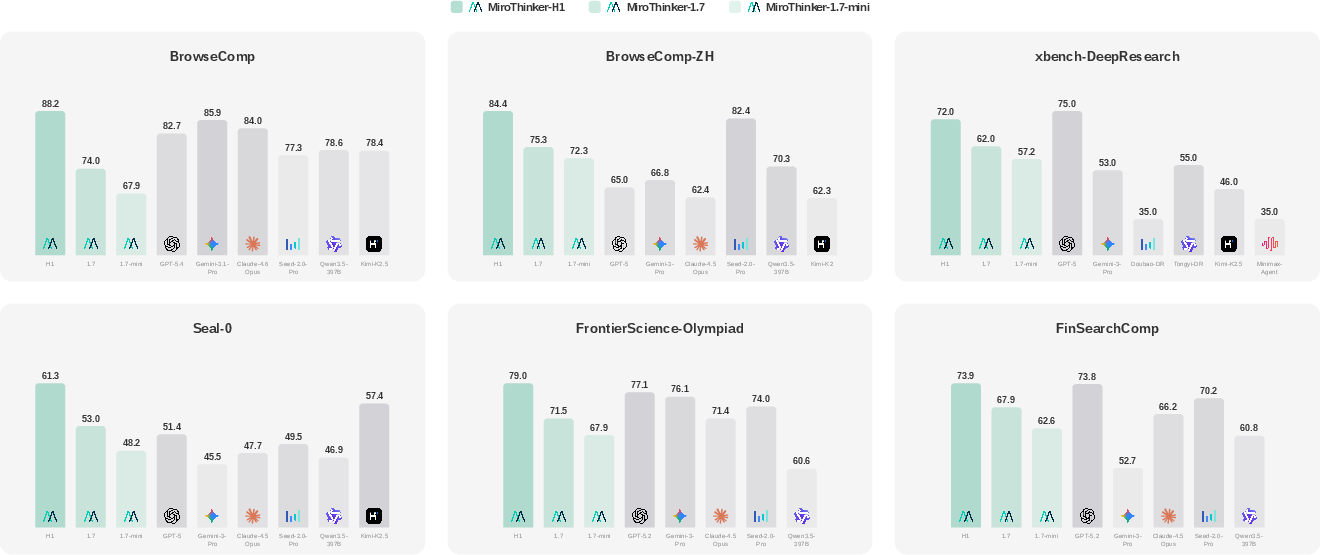
Figure 4: MiroThinker performance against frontier agents and commercial agentic foundation models across benchmarks.
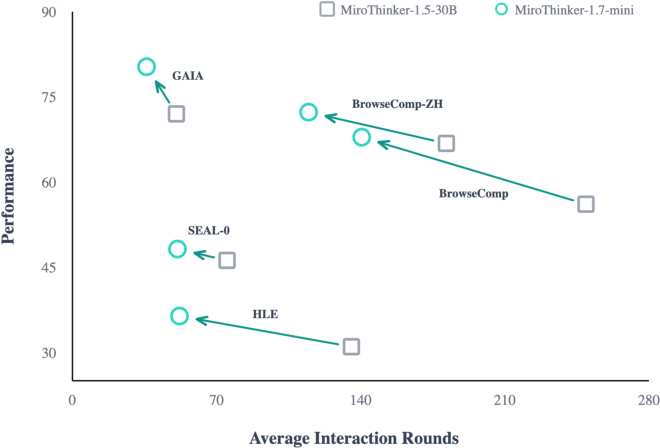
Figure 5: Performance versus interaction rounds: MiroThinker-1.7-mini consistently achieves higher performance with fewer turns, validating effective interaction scaling.
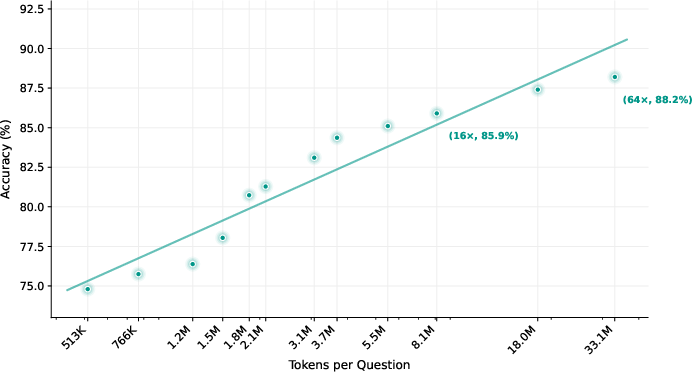
Figure 6: Token scaling curve: MiroThinker-H1 on BrowseComp, accuracy progressing from 85.9 to 88.2 as compute budget increases to 64×.
MiroThinker-H1 achieves state-of-the-art scores across agentic and professional-domain benchmarks:
- BrowseComp: 88.2, BrowseComp-ZH: 84.4, exceeding Gemini-3.1-Pro and Seed-2.0-Pro.
- GAIA: 88.5, setting a new SOTA margin over GPT-5 baseline (76.4).
- FrontierSci-Olympiad: 79.0, FinSearchComp: 73.9, and MedBrowseComp: 56.5, outperforming leading specialized agents.
- Long-form Report Quality: MiroThinker-H1 achieves top scores on evaluation dimensions of report quality and factuality, notably outpacing Gemini-3.1-Pro and ChatGPT-5.4 Deep Research.
Efficiency is demonstrated by MiroThinker-1.7-mini (3B active params), which rivals larger proprietary models with substantially reduced interaction rounds and maintains competitive results across all test categories.
Theoretical and Practical Implications
The results empirically validate that interaction scaling must enhance atomic reasoning step quality to be effective, rather than extending trajectory length uncritically. Verification-centric augmentation substantially raises reliability thresholds, ensuring both local step correction and global chain coherence. The modular training pipeline and curriculum design provide an adaptable foundation for next-generation research agents, with implications for autonomous expert-level reasoning in scientific, financial, and medical domains.
MiroThinker-H1’s ability to integrate verification at inference and multi-level reinforcement learning signals a shift toward research agents capable of reliably solving long-horizon, open-ended tasks—bridging the gap toward general-purpose AI assistants for real-world research.
Future Directions
Potential extensions include continuous scaling of verification mechanisms, joint training for fine-grained evidence synthesis, structured decompositions for explainability, and further efficiency optimizations. As benchmarks grow in complexity and domain specificity, agentic training signals must be diversified and verification must be made more granular, possibly leveraging multi-agent coordination.
Conclusion
MiroThinker-1.7 and MiroThinker-H1 represent an advancement in agentic AI for complex reasoning tasks, establishing robust atomic step improvement, explicit verification-centric approaches, and state-of-the-art empirical performance across general and specialized benchmarks. The scalable, modular framework demonstrates strong practical efficacy and points toward future research in reliable, heavy-duty research agents for advanced multi-step reasoning (2603.15726).