Deriving Hyperparameter Scaling Laws via Modern Optimization Theory
Abstract: Hyperparameter transfer has become an important component of modern large-scale training recipes. Existing methods, such as muP, primarily focus on transfer between model sizes, with transfer across batch sizes and training horizons often relying on empirical scaling rules informed by insights from timescale preservation, quadratic proxies, and continuous-time approximations. We study hyperparameter scaling laws for modern first-order optimizers through the lens of recent convergence bounds for methods based on the Linear Minimization Oracle (LMO), a framework that includes normalized SGD, signSGD (approximating Adam), and Muon. Treating bounds in recent literature as a proxy and minimizing them across different tuning regimes yields closed-form power-law schedules for learning rate, momentum, and batch size as functions of the iteration or token budget. Our analysis, holding model size fixed, recovers most insights and observations from the literature under a unified and principled perspective, with clear directions open for future research. Our results draw particular attention to the interaction between momentum and batch-size scaling, suggesting that optimal performance may be achieved with several scaling strategies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Deriving Hyperparameter Scaling Laws via Modern Optimization Theory — Explained Simply
What is this paper about?
This paper looks for simple, reliable rules to choose three important training settings (called hyperparameters) when training neural networks:
- learning rate (how big a step the model takes while learning),
- batch size (how many examples it looks at at once),
- momentum (how much it keeps “remembering” past directions).
The authors focus on modern optimizers that behave like Adam or Muon (they use directions that are normalized or sign-based), and they ask: as we change the total amount of training (the “token budget”), how should these hyperparameters change to keep training efficient?
What questions are the authors trying to answer?
In friendly terms:
- If we train longer or on more data, how should we adjust the learning rate, batch size, and momentum?
- Can we write down simple “power laws” (like “scale by the square root”) that tell us what to do?
- Do these rules match what people have seen in practice with big LLMs?
How did they approach the problem?
Think of training as driving a car toward a destination:
- learning rate is how hard you press the gas pedal,
- batch size is how many clues you use at once to decide your direction,
- momentum is like cruise control that smooths sudden changes.
Instead of testing every possible setting, the authors use a math tool called a “performance bound.” You can think of it like a safety ceiling: it guarantees training won’t be worse than a certain score. They then:
- Treat this bound as a “proxy score” for how well training will go.
- Minimize this score with respect to learning rate, batch size, and momentum under different conditions (fixed steps, fixed batch size, fixed momentum, or a fixed total token budget).
- From this, they derive simple scaling rules—how each hyperparameter should grow or shrink as the training budget changes.
Technically, they study a family of optimizers called LMO-based methods (including normalized SGD, signSGD, and Muon). These methods adjust direction using normalized or sign-based updates, which are a good proxy for how Adam-like optimizers behave. They use recent theoretical results that bound how fast such methods converge, then optimize those bounds to get the scaling laws.
What did they find, and why does it matter?
Here are the core takeaways, translated into practical, easy-to-remember rules. “Token budget” () means the total number of training examples processed (tokens = batch size × steps).
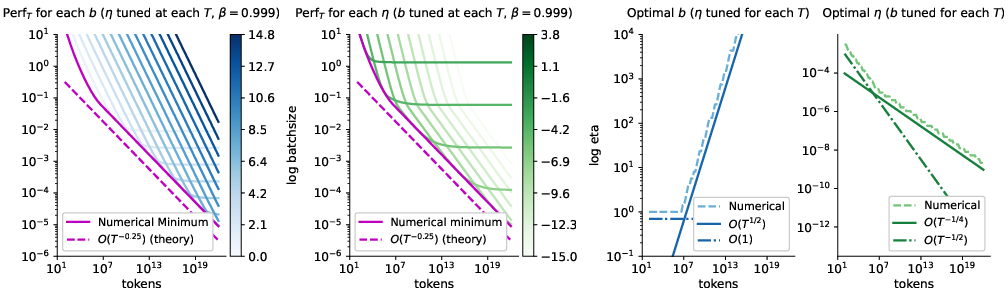
- Square-root rule for batch size and learning rate (with fixed momentum)
- If you multiply your batch size by , the best learning rate should multiply by about .
- If you multiply your token budget by but keep batch size fixed, the best learning rate should divide by about .
- Why this matters: It matches what many practitioners already do and gives a clean theory behind it.
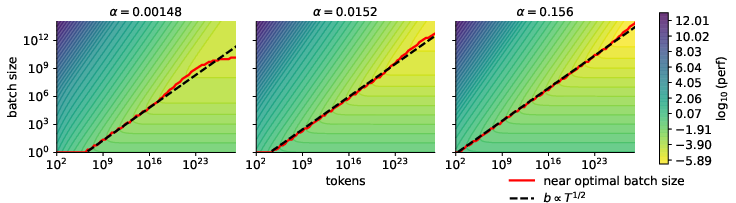
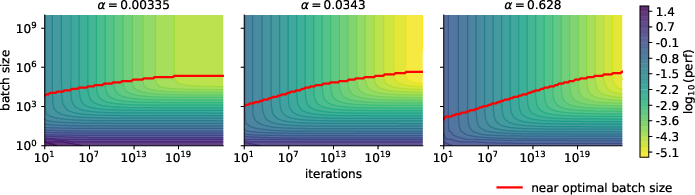
- There is a non-trivial “best” batch size when tokens are fixed (for Adam-like/LMO methods)
- For a fixed total token budget, there is an optimal batch size greater than 1 once training is long enough. Choosing too small or too large a batch size can be suboptimal.
- This is different from vanilla SGD, where the batch size doesn’t have a unique “best” for a fixed token budget (once you tune the learning rate).
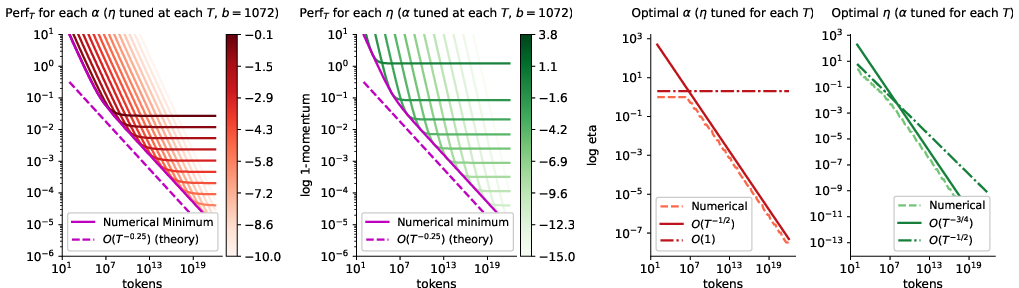
- If your batch size can’t grow (hardware limit), tune momentum with training length
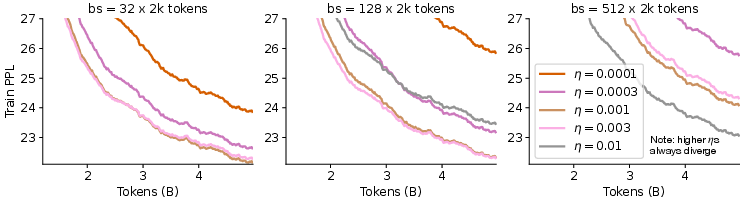
- With a fixed batch size, if you don’t adjust momentum, you can get “stuck” with a noise floor (progress stops improving).
- The fix: as you train longer, gradually increase the momentum (i.e., make it closer to 1). This removes the floor and restores good progress.
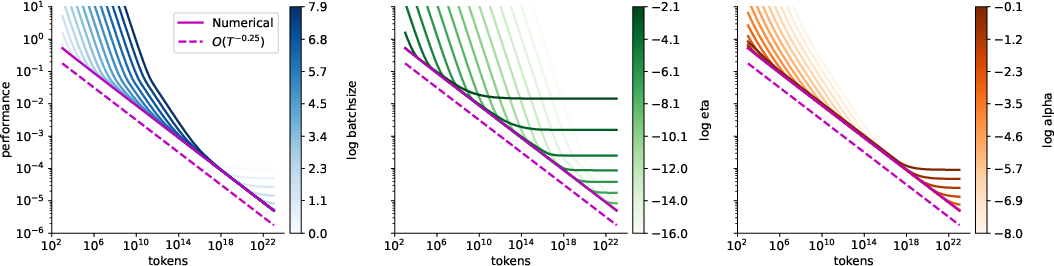
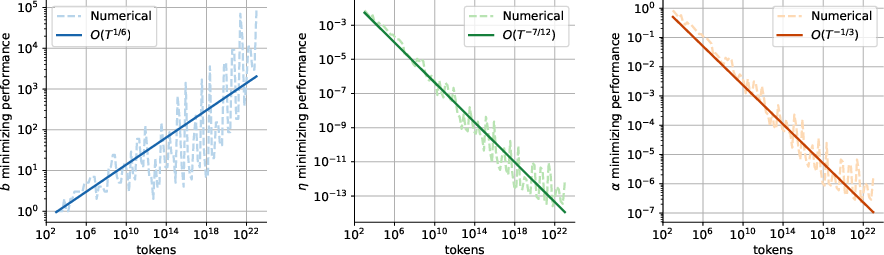
- Jointly tuning everything gives one “compute-optimal” recipe—but it’s not the only good one
- When tuning learning rate, batch size, and momentum together for large token budgets, the math suggests:
- batch size grows slowly like ,
- learning rate shrinks like ,
- momentum approaches 1 like ,
- overall training “difficulty” drops like .
- But here’s the punchline: many different batch-size growth patterns (as long as they don’t grow too fast) are nearly as good if you retune learning rate and momentum appropriately. So there isn’t just one “magic” schedule.
- When tuning learning rate, batch size, and momentum together for large token budgets, the math suggests:
- Practical understanding of momentum and batch size
- As batch size increases (for the same total tokens), the optimal momentum should slightly decrease.
- As training gets longer at a fixed batch size, the optimal momentum should increase (get closer to 1).
- This gives a principled way to adjust momentum—something many training recipes historically leave fixed.
- Limits and scope
- These results hold with fixed model size, constant learning rate (no schedule), and certain standard assumptions about noise in gradients.
- The paper focuses on optimization (how fast you reach a good solution), not directly on generalization (how well you perform on new data).
Simple rules of thumb you can remember
Use these with Adam-like or normalized/sign-based optimizers:
- If you double batch size and keep tokens fixed: multiply learning rate by about √2.
- If you double tokens and keep batch size fixed: divide learning rate by about √2.
- If your batch size can’t increase: push momentum closer to 1 as you train longer.
- If you tune all three, many scaling strategies are almost equally good—don’t feel locked into a single formula.
Why is this important?
Training large models is extremely expensive. Having clear, theory-backed rules for how to adjust hyperparameters when you change batch size or how long you train can:
- reduce trial-and-error,
- improve training stability and speed,
- help “transfer” good settings from small runs to bigger ones,
- save time and compute.
What’s the bigger picture?
This work builds a bridge between practical training tricks and modern optimization theory. It explains why widely used rules like the square-root learning-rate scaling make sense, shows where they do and don’t apply, and offers new guidance—especially about momentum—when batch size is limited. It also opens the door to future work that adds common training features like learning-rate schedules, warmup, weight decay, and changing model size.
In short: the paper turns folk wisdom about hyperparameters into clear, mathematical guidance that can make big-model training more predictable and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of unresolved issues that are missing, uncertain, or left unexplored in the paper; each item is phrased to be concrete and actionable for future research.
- Bound tightness and constants: Quantify how tight the LMO-based nonconvex bound is for modern LLM training regimes; estimate , , , and from real runs and assess whether the predicted rate and exponents hold beyond asymptotics.
- Pre-asymptotic (“burn‑in”) regime: Characterize the finite‑, finite‑ regime where the burn‑in term is not negligible; derive thresholds for the “critical token budget” where becomes optimal as a function of , , and validate empirically.
- Noise model validity: Test the assumption under:
- correlated minibatches and repeated data passes,
- heavy‑tailed gradient noise,
- gradient clipping and mixed precision,
- anisotropic or norm‑mismatched noise relevant to LMO norms.
- Derive revised scaling laws when variance deviates from .
- Time‑varying curvature and noise: Incorporate nonstationary and along training; derive phase‑dependent scalings and stagewise schedules when evolve significantly.
- Mapping to Adam and other adaptive methods: Replace the signSGD proxy with a theory that explicitly models Adam’s second moment (), , and decoupled weight decay; derive batch/token/momentum scaling for and compare to the heuristic.
- Norm choice and architecture dependence: Analyze how the choice of norm (e.g., vs spectral) and the norm‑equivalence constant depend on layer shapes, parameterization, and architecture; quantify how this shifts constants and possibly exponents.
- Inexact LMO implementations: Model the gap between idealized LMO updates and practical approximations in Muon/Scion (e.g., approximate spectral norms, per‑layer constraints); determine how inexactness alters optimal scalings.
- Learning‑rate schedules and warmup: Extend the analysis beyond constant to scheduled learning rates (cosine/step/linear warmup), and derive how schedule parameters should scale with , , and .
- Weight decay and regularization: Incorporate decoupled weight decay (and other regularizers) into the bound and re‑derive scaling laws for ; quantify interactions with generalization.
- Generalization and finite‑sample effects: Move beyond the population‑risk oracle to account for finite datasets, multiple epochs, and test loss; determine how optimization‑optimal schedules trade off with generalization‑optimal schedules.
- Reconciling LR–token trends: Provide a formal, path‑dependent analysis explaining when can empirically increase with under joint growth, and design experiments that isolate path effects from true compute‑optimal behavior.
- Joint scaling with model size: The current analysis fixes model size ; derive how scale jointly with under P and alternative parameterizations, including how and evolve.
- Compute/wall‑clock optimality: Incorporate systems constraints (per‑step latency, communication, memory, pipeline bubbles) to translate token‑optimal schedules into wall‑clock/energy‑optimal schedules; re‑derive batch versus step tradeoffs.
- SGD versus LMO in practice: Provide controlled empirical comparisons that verify the paper’s claim that SGD lacks a nontrivial token‑optimal after tuning ; delineate regimes where LMO advantages are practically significant.
- Loss connection and landscape assumptions: Replace star‑convex assumptions with weaker or empirically validated conditions connecting reductions to loss/perplexity improvements; calibrate the gradient‑norm proxy against loss curves.
- Robustness to gradient clipping and safety constraints: Determine how clipping (ubiquitous in LLM training) modifies the bound terms and optimal exponents; derive clipping‑aware scaling rules.
- Layerwise/parameterwise schedules: Investigate whether layerwise norms and per‑layer hyperparameters (common in Muon/AdamW) imply different optimal exponents across layers; propose practical layerwise scaling recipes.
- Hardware‑capped batch sizes: Provide explicit momentum and LR schedules that recover when , quantify constants, and test stability (e.g., how fast must decrease and numerical issues when ).
- Stability and numerical constraints: Among the many near‑optimal batch growth laws (e.g., for ), establish constraints that prevent unstable or (e.g., overly small or large ), and propose selection criteria beyond asymptotic optimality.
- Sensitivity to initialization and pretraining protocols: Analyze how different initializations, pretraining curricula, and data mixtures affect , , and the crossover to the variance‑dominated regime; derive initialization‑aware scaling.
- Calibration on real LLMs: Move beyond small‑scale demonstrations to multi‑billion‑parameter LLMs; fit , validate exponents for Muon, sign‑based Adam approximations, and AdamW, and release reproducible benchmarks.
- Formalizing near‑optimality classes: Prove a characterization of “equivalence classes” of batch/momentum/LR schedules that achieve up to constant factors, and identify practically preferable members based on throughput, memory, and generalization.
- Data non‑IID and sequence effects: Model temporal correlations in token streams, document‑level batching, and dataset non‑IIDness; re‑derive variance scaling and resulting hyperparameter exponents under realistic data pipelines.
- Extension to mixed‑objective training: Study how auxiliary losses (e.g., RLHF, contrastive objectives, auxiliary pretraining tasks) alter effective , , and the optimal scaling laws when objectives are interleaved.
- Linking critical batch size to theory: Connect empirical notions of critical batch size to the bound terms (optimization vs variance vs trust‑region terms) and provide predictive formulas for the critical/efficient batch size as training progresses.
- Explicit constants and crossover analysis: Provide closed‑form expressions for constants in , , and compute crossover points where different terms dominate; turn asymptotic rules into deployable knobs for practitioners.
Practical Applications
Practical Applications of “Deriving Hyperparameter Scaling Laws via Modern Optimization Theory”
This paper offers closed-form, theoretically grounded scaling rules for learning rate, momentum, and batch size as functions of training iterations or token budget, within a Linear Minimization Oracle (LMO) optimizer family that includes normalized SGD, signSGD (approximating Adam), and Muon. Below, we distill real-world applications organized by deployment horizon, with sector links, potential tools/workflows, and feasibility assumptions.
Immediate Applications
These can be deployed now using existing optimizers (AdamW, signSGD variants, Muon/Scion) and common training stacks (PyTorch, JAX, DeepSpeed, Megatron, FSDP/ZeRO).
- Compute-aware training recipes for fixed model size
- Use case: Given a token budget and batch size , set learning rate and momentum using the paper’s closed-form rules to reach near-optimal optimization efficiency (expected gradient norm) without extensive grid search.
- Action:
- Fixed momentum (typical default β): set learning rate .
- Hardware-limited batch size: remove the noise floor by momentum tuning with and (equivalently, with the previous choice ).
- Joint tuning (if permitted): a theoretically optimal asymptotic schedule is , , ; however, many milder batch growth laws are near-optimal when momentum/learning rate are re-tuned accordingly.
- Sectors/workflows:
- Software/AI infrastructure: pretraining and continued pretraining of LLMs and vision models.
- Cloud/enterprise MLOps: cost-optimized training pipelines under fixed budgets.
- Assumptions/dependencies: constant learning rate (no decay), fixed model size, unbiased gradient oracle with variance , large-horizon regime for some results, LMO-like update behavior (e.g., Adam’s sign dynamics). Generalization effects are not modeled.
- Hyperparameter transfer across token budgets
- Use case: Transfer a known-good configuration to a new training duration without re-running large sweeps.
- Action:
- If changes by factor , scale at fixed .
- If changes by factor (at fixed and momentum), scale .
- If is capped, increase momentum (β→1) over longer horizons using .
- Sectors/workflows:
- Academia/benchmarks: reproducible scaling across different run lengths.
- Industry: extending training runs when budgets allow.
- Assumptions/dependencies: same as above; transfer presumes similar data, initialization, and optimizer family.
- Hardware-constrained training optimization
- Use case: Maintain efficiency when GPU memory caps batch size (edge devices, small clusters, robotics platforms).
- Action: At fixed , tune momentum with and learning rate with to avoid a variance-driven performance floor.
- Sectors/workflows:
- Robotics/edge computing: on-device or near-device fine-tuning.
- Healthcare (privacy-preserving/federated): client-specific limits.
- Assumptions/dependencies: stochastic gradients with variance decreasing ~1/√b; LMO-style optimizer behavior; stable momentum implementation on device.
- AutoML/HPO acceleration via principled priors
- Use case: Cut hyperparameter search time/cost by seeding searches with scaling-law-derived priors and/or constraining search manifolds.
- Action: Plug –– power laws into Bayesian optimization priors or population-based training schedules; prioritize tuning constants over exponents.
- Sectors/workflows:
- AutoML platforms; internal HPO services in AI labs.
- Assumptions/dependencies: optimizer resembles normalized/LMO family (e.g., Adam’s sign dynamics); constants () unknown but can be absorbed into tuned prefactors.
- Training orchestration and capacity planning
- Use case: Translate compute or token budgets into planned batch/step/momentum schedules to meet target optimization performance.
- Action: Use and the hyperbolic step–batch trade-off to plan minimal steps and minimal batch to hit a fixed target risk; adopt momentum scaling when batch growth is infeasible.
- Sectors/workflows:
- Cloud providers; enterprise MLOps; finance/FP&A for AI spend planning.
- Assumptions/dependencies: performance proxy is the expected gradient norm bound; ignores generalization and pipeline overheads.
- Defaults and plugins for training stacks
- Use case: Provide better “out-of-the-box” defaults that adapt to user budgets.
- Action:
- Implement a “scaling-law scheduler” module for PyTorch, JAX, DeepSpeed, FSDP/ZeRO, Megatron that sets from and hardware limits.
- Provide adapters for AdamW (using signSGD-with-momentum approximation) and Muon/Scion.
- Sectors/workflows:
- Open-source frameworks; internal tooling in labs.
- Assumptions/dependencies: clean API access to momentum parameters (e.g., β1/β2 in AdamW); reliable token counters and batch controllers.
- Federated and multi-client training robustness
- Use case: Normalize client-side hyperparameters across heterogeneous batch sizes and training durations.
- Action: Per-client scaling of with and duration with ; if clients are small-batch-limited, increase momentum (β per client) as per .
- Sectors/workflows:
- Healthcare, finance, mobile/edge federated learning.
- Assumptions/dependencies: client gradient noise obeys similar variance scaling; coordination server can distribute per-client hyperparameters.
- Fine-tuning and RLHF/online updates
- Use case: Short- to mid-horizon fine-tunes where is known (or capped) and is small.
- Action: Start from ; if convergence stalls due to variance, raise β towards 1 with .
- Sectors/workflows:
- Software product teams fine-tuning LLMs; content moderation, RLHF stages.
- Assumptions/dependencies: stationary objective approximation over the short horizon; stability under higher momentum.
- Reporting and reproducibility standards in academic experiments
- Use case: Present results that transfer across compute regimes.
- Action: Report and β scaled to and using the paper’s rules; include batch–step trade-off contours to clarify regime.
- Sectors/workflows:
- Academia; open benchmarks (e.g., Pythia-like suites).
- Assumptions/dependencies: consistent token accounting; same optimizer family across comparisons.
- Sustainability and cost-reduction guidelines
- Use case: Reduce overtraining inefficiencies that inflate energy use and cloud spend.
- Action: Pre-flight calculators that predict performance vs. using the proxy; stop wasting budget in suboptimal batch/step regions; tune momentum when batch increases are capped.
- Sectors/workflows:
- Policy/ESG reporting for AI; enterprise sustainability.
- Assumptions/dependencies: proxy correlates with final task performance in small-epoch training; ignores generalization gap.
Long-Term Applications
These require further empirical validation at extreme scales, integration with additional training features (weight decay, warmup, LR decay), or extension beyond fixed model size.
- Unified scaling across model size, token budget, and batch (integration with μP)
- Vision: Combine these token/batch/momentum laws with model-size transfer (μP) to produce end-to-end recipes for scaling models and training durations simultaneously.
- Sectors/workflows: frontier LLM/Multimodal labs; foundation model pretraining.
- Dependencies: theory for joint scaling; interaction with parameterization, initialization, and curvature.
- Online, feedback-driven controllers for
- Vision: Closed-loop schedulers that estimate noise/curvature on the fly and adjust momentum and batch size to stay near the frontier.
- Sectors/workflows: autonomous training systems; automated lab environments.
- Dependencies: robust online variance/curvature estimators; stability under dynamic and β changes; integration with pipeline latencies.
- Generalization-aware scaling laws
- Vision: Extend the optimization proxy to include generalization behavior (e.g., flatness-sensitive terms, heavy-tailed noise, non- scaling) to better match observed learning-rate trends when both and grow.
- Sectors/workflows: safety-critical domains (healthcare diagnostics, finance risk models); curriculum learning design.
- Dependencies: new bounds capturing data- and model-dependent generalization; empirical calibration.
- Co-design with warmup, weight decay, and LR decay
- Vision: Incorporate common training heuristics into the theoretical framework to produce complete schedules (warmup length ∝ budget, decay rates tied to and α).
- Sectors/workflows: standardized training stacks for industry benchmarks.
- Dependencies: revised convergence bounds that include scheduling and regularization effects.
- Hardware–optimizer co-optimization
- Vision: Schedule batch growth subject to memory/throughput curves while adjusting momentum as per theory to meet target accuracy under latency/energy constraints.
- Sectors/workflows: cloud providers, accelerator vendors; energy/edge systems.
- Dependencies: accurate systems models (throughput vs. batch), coordination with gradient accumulation and mixed precision.
- Cross-paradigm extensions (RL, sequence modeling beyond LMOs)
- Vision: Adapt proxy-based scaling to RL, off-policy updates, and non-LMO optimizers (e.g., Shampoo), bridging theory to broader training regimes.
- Sectors/workflows: robotics, autonomous driving, recommendation systems.
- Dependencies: bounds in nonstationary or correlated-sample settings; alternative norm geometries.
- Standards and policy for compute-efficient training
- Vision: Industry norms that encourage budget-aware hyperparameter scaling, reported alongside emissions estimates and compute footprints.
- Sectors/workflows: regulators, standards bodies, cloud consumption reporting.
- Dependencies: consensus on proxies/metrics; alignment with carbon accounting methodologies.
- Educational and diagnostic tools
- Vision: Interactive simulators that forecast performance versus , helping students/practitioners internalize scaling behavior; run “what-if” budget scenarios.
- Sectors/workflows: education platforms; internal training at AI organizations.
- Dependencies: user-friendly implementations of the proxy with documented caveats.
- Optimizer design leveraging LMO insights
- Vision: New Adam-like methods that explicitly manage normalization and momentum–batch coupling to preserve near-optimal scaling under practical constraints.
- Sectors/workflows: optimizer libraries; high-throughput training products.
- Dependencies: theory–practice bridging for non-Euclidean norms; stability with mixed-precision and sharded training.
Cross-cutting assumptions and caveats to feasibility
- The core proxy optimizes expected gradient norm; it does not directly account for generalization. Empirically, small-epoch improvements often correlate with downstream performance, but this can break in some regimes.
- Results assume: constant learning rates (no decay), fixed model size, unbiased stochastic gradients with variance scaling , Lipschitz-smooth objectives, and large-horizon approximations for some derivations ().
- For AdamW, the signSGD-with-momentum approximation underlies the mapping; care is needed with β1/β2 choices. The momentum scaling insight suggests decreasing β as batch increases and increasing β as grows at fixed small .
- Deviations such as heavy-tailed gradients, non- noise, or norm mismatch can shift exponents; the paper outlines these as open areas for refinement.
- Constants () affect prefactors; in practice, treat power-law exponents as guides and fit constants on small pilots.
Glossary
- Adam: A popular adaptive first-order optimizer that uses estimates of first and second moments of gradients to scale updates. "signSGD (approximating Adam)"
- Adaptive methods: Optimizers that adjust learning rates based on gradient statistics across parameters during training. "for adaptive methods, at a fixed token budget, scaling requires "
- Bias-dominated regime: A training phase where optimization error (bias) dominates over stochastic noise (variance), often early in training. "in the bias-dominated, early-training regime, the critical batch size is ;"
- Convergence bounds: Theoretical upper bounds on optimization error or gradient norms that describe how fast an algorithm approaches optimality. "through the lens of recent convergence bounds for methods based on the Linear Minimization Oracle (LMO)"
- Continuous-time approximations: Analyses that model discrete optimization algorithms with continuous-time differential equations. "continuous-time approximations."
- Critical batch size: The batch size beyond which further increases yield diminishing returns in step-efficiency. "Several works instead discuss the notion of critical batch size"
- Dual norm: For a given norm, the associated norm on the dual space used to measure gradients or forces; satisfies Hölder's inequality. "Let be any norm, with dual norm "
- Euclidean geometry: Optimization under the standard 2-norm geometry, as opposed to non-Euclidean norms. "extend beyond convex settings and Euclidean geometry"
- FLOPs: Floating point operations, a measure of computational cost. "training budgets of FLOPs"
- Gradient noise variance: The variance of the stochastic gradient estimator, often decreasing with larger batch sizes. "the gradient noise variance is upper bounded by a constant "
- Heavy tails: Distributions with heavier-than-Gaussian tails, which can affect noise behavior and optimization dynamics. "non- noise scaling, heavy tails, or norm-mismatched variance for LMO methods"
- Hyperbolic relation: An inverse relationship (hyperbola-like) between two variables, here step count and batch size, for meeting a target performance. "the classical hyperbolic relations between batch size and step count"
- Hyperparameter scaling laws: Predictive rules describing how optimal hyperparameters change with model, data, or compute scale. "We study hyperparameter scaling laws for modern first-order optimizers"
- Hyperparameter transfer: Techniques for mapping tuned hyperparameters from one training regime (e.g., size) to another. "Hyperparameter transfer has become an important component of modern large-scale training recipes."
- Large-horizon regime: The setting of many optimization steps where asymptotic approximations become valid. "In the large-horizon regime "
- Learning rate transfer: Transferring a learning-rate choice across different model sizes or training regimes. "enabling learning rate transfer across model sizes."
- Linear Minimization Oracle (LMO): A framework that updates in the direction minimizing a linearization under a norm constraint; includes normalized and sign-based updates. "methods based on the Linear Minimization Oracle (LMO), a framework that includes normalized SGD, signSGD (approximating Adam), and Muon."
- Lipschitz gradients: A smoothness condition where gradients do not change too rapidly, bounded by a Lipschitz constant. "the loss has -Lipschitz gradients, with respect to the general norm"
- Momentum burn-in: The initial phase where moving averages (momentum) have not yet stabilized, introducing transient error terms. "momentum ``burn-in'' / averaging term ;"
- Muon: An optimizer using orthogonalized (spectral-norm-based) updates to improve training stability. "spectral norm: Muon (orthogonalized update)"
- Norm equivalence constant: A factor bounding one norm by another in finite-dimensional spaces, used to relate analysis across norms. "where is a norm equivalence constant"
- Norm-based optimizers: Methods whose update directions or constraints are defined by norms other than the Euclidean norm. "captures a family of norm-based optimizers directly relevant to modern practice"
- Normalized SGD: A variant of SGD that normalizes the update direction by its norm, often coupled with momentum. "Euclidean $|\cdot|=|\cdot|_2): normalized SGD with momentum"
- Normalized steepest descent: Updates taken along the steepest descent direction normalized in a chosen norm, as instantiated by LMO. "normalized steepest descent~(LMO) methods, not vanilla SGD."
- Noise floor: A lower bound on achievable error due to stochastic gradient noise that persists even as iterations increase. "a noise floor term (2\rho\sigma\sqrt{\frac{\alpha}{b}"
- Operator-norm updates: Updates constrained or scaled by an operator norm (e.g., spectral norm) at the layer or matrix level. "Muon/Scion-style operator-norm updates"
- Orthogonalized update: An update modified to be orthogonal (or approximately so) to certain directions, often via spectral normalization. "Muon (orthogonalized update)"
- Power-law schedules: Hyperparameter schedules that scale as a power of training budget or steps. "yields closed-form power-law schedules for learning rate, momentum, and batch size"
- Proxy objective: A tractable objective (often a bound) optimized in place of the true, harder-to-evaluate training objective. "Define the following proxy~(the right-hand-side of \eqref{eq:lmo-nonconvex-bound} up to constants):"
- SDE (stochastic differential equation): Continuous-time models used to approximate and analyze stochastic optimization dynamics. "stochastic differential equation~(SDE) approximations"
- SignSGD: An optimizer that uses only the sign of gradient components (with or without momentum). "signSGD with momentum"
- Speed-matching flows: SDE-based analyses aligning the “speeds” (time scales) of different dynamics to optimize convergence. "theoretical insights around speed-matching flows in the SDE literature"
- Square-root learning rate scaling: The rule that optimal learning rate scales with the square root of batch size (or inversely with training horizon’s square root). "we recover the well-known square-root learning rate scaling with batch size"
- Star-convex: A generalization of convexity where all segments from a fixed point to the set lie within the set, enabling certain guarantees. "For the star-convex case~\citep{kovalev2025muon}, the gradient norm can be lower bounded"
- Token budget: The total number of training data tokens processed, often equal to batch size times number of steps. "token budget ."
- Trust-region error terms: Errors arising from approximating the objective within a region where the model is trusted to be accurate. "smoothness/trust-region error terms proportional to "
- Unbiased stochastic gradient oracle: An assumption that the stochastic gradient estimator has expectation equal to the true gradient. "assumes access to an unbiased stochastic gradient oracle for the population objective."
- Unconstrained Stochastic Conditional Gradient method: Another name for Frank–Wolfe-type methods applied without explicit constraints, related here to LMO. "Also known as Unconstrained Stochastic Conditional Gradient method"
- Warmup: A training schedule that begins with a smaller learning rate and gradually increases it before holding or decaying. "incorporating weight decay, learning-rate scheduling, and warmup into our analysis."
- Weight decay: A regularization technique that penalizes large weights, typically implemented as L2 regularization. "incorporating weight decay, learning-rate scheduling, and warmup into our analysis."
Collections
Sign up for free to add this paper to one or more collections.