Demystifing Video Reasoning
Abstract: Recent advances in video generation have revealed an unexpected phenomenon: diffusion-based video models exhibit non-trivial reasoning capabilities. Prior work attributes this to a Chain-of-Frames (CoF) mechanism, where reasoning is assumed to unfold sequentially across video frames. In this work, we challenge this assumption and uncover a fundamentally different mechanism. We show that reasoning in video models instead primarily emerges along the diffusion denoising steps. Through qualitative analysis and targeted probing experiments, we find that models explore multiple candidate solutions in early denoising steps and progressively converge to a final answer, a process we term Chain-of-Steps (CoS). Beyond this core mechanism, we identify several emergent reasoning behaviors critical to model performance: (1) working memory, enabling persistent reference; (2) self-correction and enhancement, allowing recovery from incorrect intermediate solutions; and (3) perception before action, where early steps establish semantic grounding and later steps perform structured manipulation. During a diffusion step, we further uncover self-evolved functional specialization within Diffusion Transformers, where early layers encode dense perceptual structure, middle layers execute reasoning, and later layers consolidate latent representations. Motivated by these insights, we present a simple training-free strategy as a proof-of-concept, demonstrating how reasoning can be improved by ensembling latent trajectories from identical models with different random seeds. Overall, our work provides a systematic understanding of how reasoning emerges in video generation models, offering a foundation to guide future research in better exploiting the inherent reasoning dynamics of video models as a new substrate for intelligence.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to figure out how modern video‑making AI models “think.” The authors look at diffusion‑based video generators (the kind that turn random noise into a video) and ask: when these models solve tasks like finding a path in a maze or moving the right object, where does the actual reasoning happen? They discover that the key thinking happens across the model’s denoising steps, not simply from one video frame to the next. They call this process Chain‑of‑Steps (CoS).
What questions were the researchers asking?
The paper focuses on a few simple questions:
- Do video models reason “frame by frame” over time, or “step by step” as they remove noise during generation?
- What does the model’s reasoning look like as it unfolds—does it try multiple ideas and then choose one?
- Inside the model, do different parts specialize in perception (seeing) versus reasoning (deciding)?
- Can we make the model reason better without retraining it?
How did they study it?
Think of a diffusion video model like a foggy image slowly becoming clear. It starts as noisy static and, over many tiny “denoising steps,” turns into a coherent video. The team watched this process very closely.
Here’s what they did, explained in everyday terms:
- Watching the “making‑of”: At each denoising step, they decoded the model’s current “best guess” of the video (like pausing a time‑lapse of a painting being made) to see how decisions evolved.
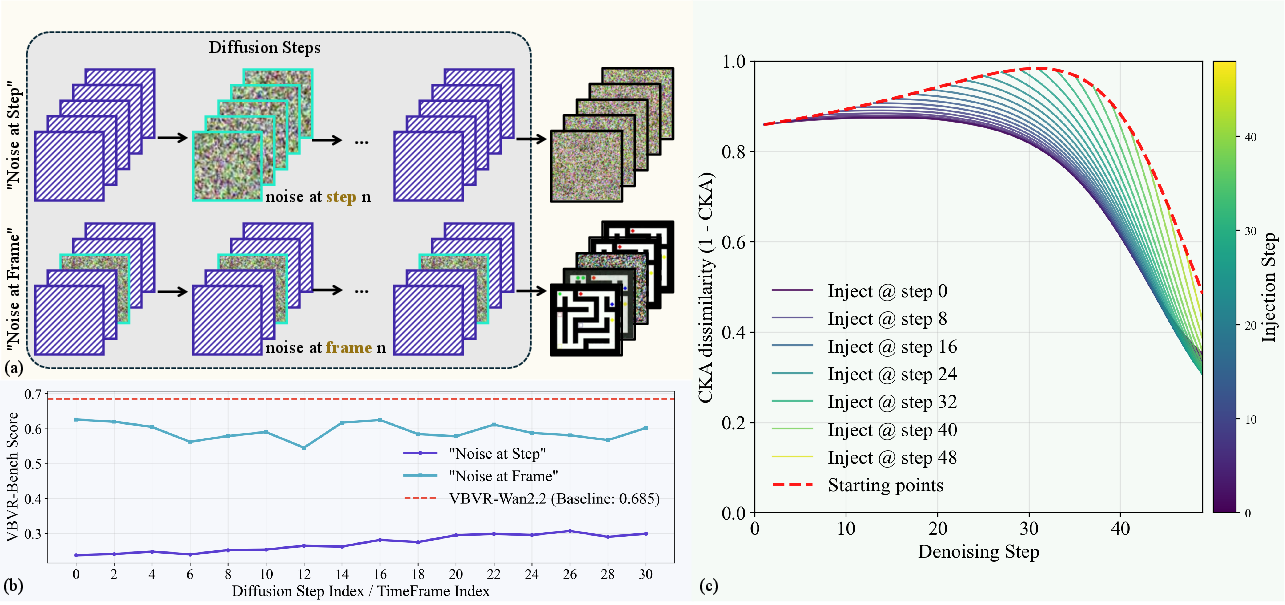
- Step vs. frame stress tests: They added noise in two ways to see what breaks the model’s reasoning more:
- Noise at a specific denoising step (jolting the “thinking moment”).
- Noise at a specific video frame (jolting one picture in the sequence).
- If step noise hurts more, it suggests the model’s reasoning is step‑driven, not frame‑driven.
- Looking inside the model’s layers: A Diffusion Transformer has many layers. The team measured which layers focused on seeing versus deciding by visualizing activations (how “lit up” each layer is) and doing a “layer swap” test to see which layers changed the final outcome.
- A simple improvement trick: Without retraining, they ran the same model three times with different random starts (like three attempts) and averaged their internal “hidden sketches” early in the process. This “ensemble” keeps more good options alive longer, leading to better decisions.
What did they find?
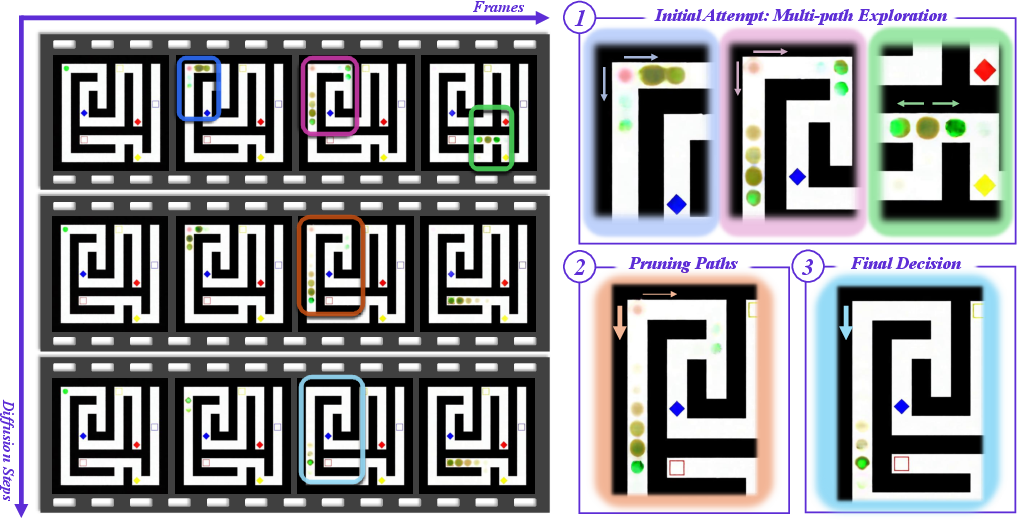
1) Chain‑of‑Steps (CoS) is the main way these models reason
Instead of reasoning across frames (Chain‑of‑Frames), the models do their core thinking along the denoising steps. At each step, the model looks at the whole video at once and updates it, rather than reasoning in frame order.
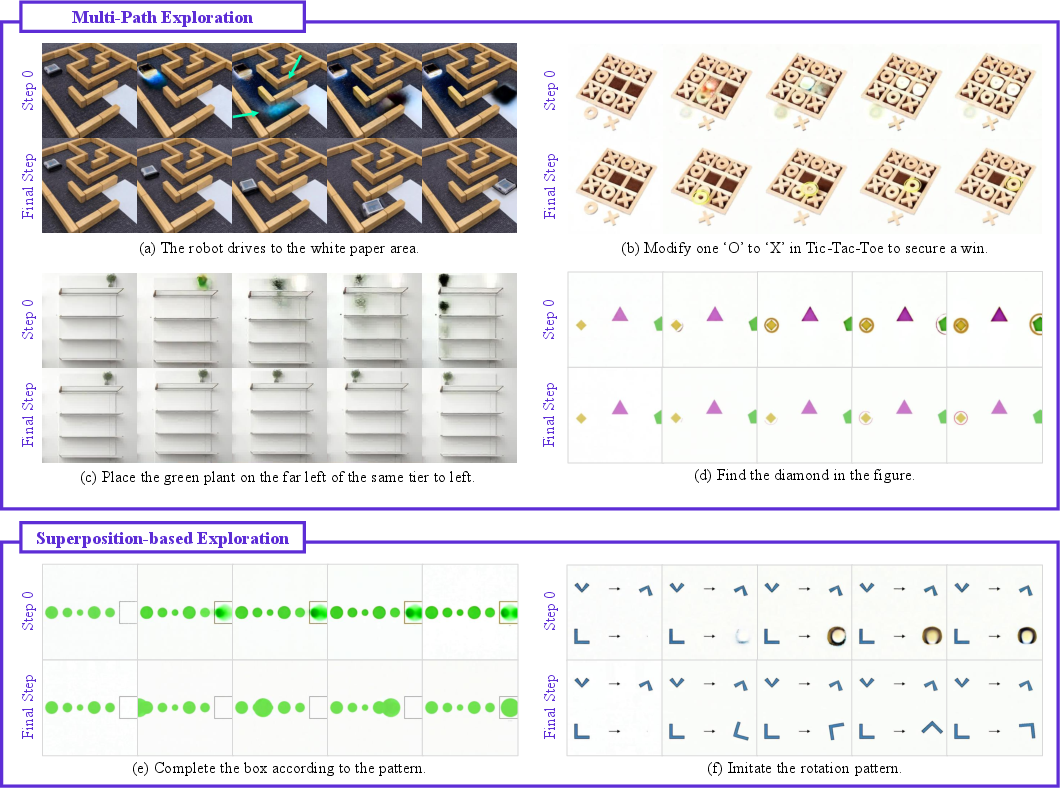
- Early steps = brainstorming: The model entertains multiple possibilities at the same time. For example:
- In a maze task, it faintly draws several possible paths.
- In tic‑tac‑toe, it lights up several winning cells.
- When rotating an object, it briefly shows multiple angles “superimposed.”
- Middle steps = pruning: The model starts ruling out bad options and strengthening the promising one.
- Late steps = commitment: It settles on a single, clear answer.
Why this matters: It’s like a student sketching many solutions lightly in pencil before committing in pen. That’s a flexible, robust way to reason.
2) Step noise breaks reasoning more than frame noise
When they injected noise:
- Disrupting a specific denoising step significantly harmed performance.
- Disrupting a single frame was less damaging, because the model can fix frames later using information from all frames at once.
This supports the idea that the “thinking” is concentrated in steps, not frames.
3) Emergent reasoning behaviors appear naturally
The models showed several surprising, helpful behaviors:
- Working memory: They keep important details in mind across steps (like the original position of an object even if it’s briefly hidden).
- Self‑correction: They can fix earlier mistakes as steps progress (like correcting a wrong path or adjusting the number and placement of shapes).
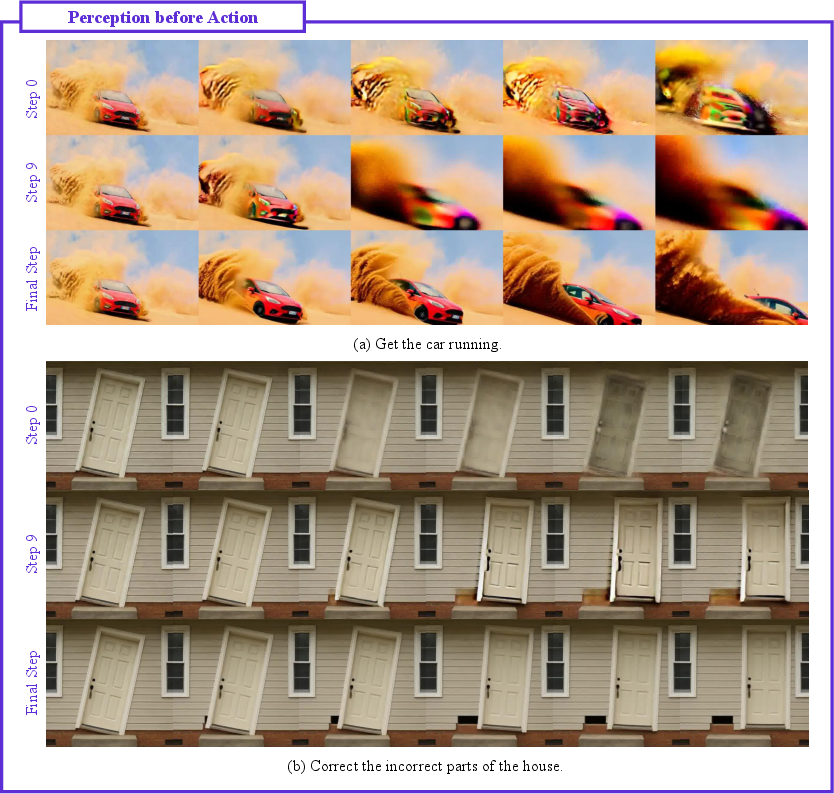
- Perception before action: First they figure out “what and where” (find the car or door), then they handle “how” (move it, open it). In other words, they ground the scene before manipulating it.
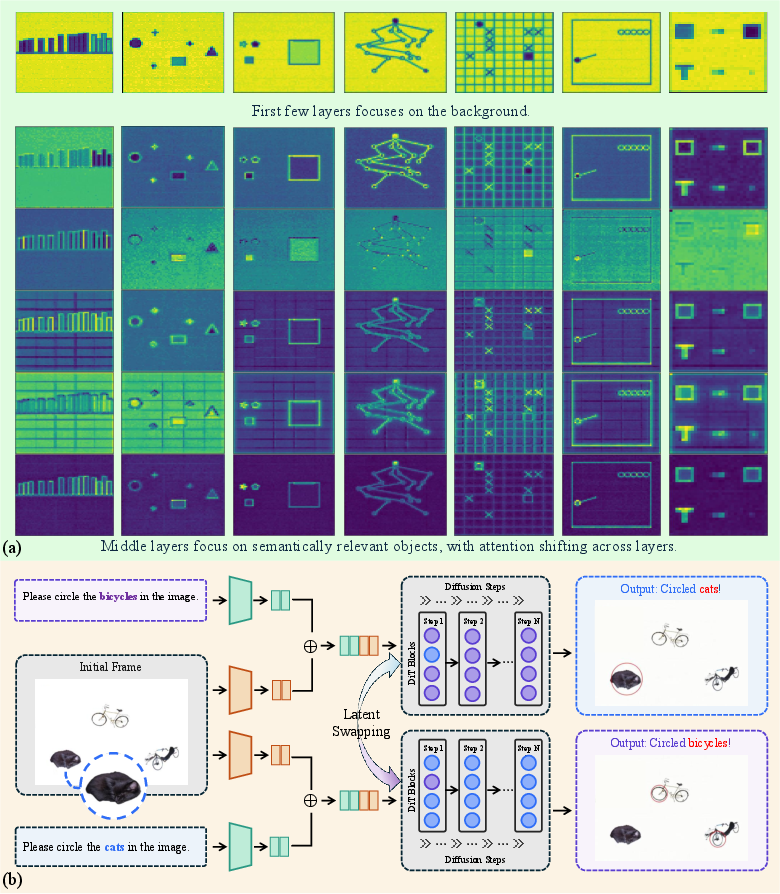
4) Different layers specialize in different roles
Inside one denoising step:
- Early layers: Focus on basic perception—backgrounds, shapes, and structure.
- Middle layers: Do most of the reasoning and decision‑making.
- Late layers: Consolidate everything into a stable internal representation.
A layer swap test showed that changing some middle‑layer representations can flip the model’s final decision, confirming that these layers carry crucial reasoning information.
5) A training‑free ensemble improves reasoning
By running the same model three times with different random seeds and averaging their mid‑layer “hidden sketches” early in generation, the model kept more good ideas alive and was more likely to pick the right one. This simple trick improved benchmark scores by around 2% on a video reasoning test suite.
Why does this matter?
- Better understanding = better tools: Knowing that video models reason along denoising steps helps researchers design smarter, more reliable generators for tasks that require planning, physics sense, or step‑by‑step logic.
- Practical wins without retraining: The ensemble method shows you can boost reasoning quality at inference time with no extra training.
- A new “thinking substrate”: Video models don’t just draw pretty pictures—they can reason in dynamic, consistent worlds. That opens doors for applications in robotics, education, creative tools, and interactive simulations.
In short, this paper shows that diffusion‑based video models “think” by exploring and narrowing options across denoising steps, not simply by stacking frames. They remember, correct themselves, and separate seeing from deciding—features that make them promising platforms for future AI reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems that remain unresolved and could guide follow-up research:
- Generality across architectures: Validate whether Chain-of-Steps (CoS) holds for non-DiT video generators (e.g., UNet-based latent diffusers, consistency/score models, masked/auto-regressive video models) and for architectures with causal or windowed temporal attention instead of full bidirectional attention.
- Training/data dependence: Separate model- and data-driven effects by repeating analyses on (a) base, non–reasoning-finetuned models, (b) models trained on disjoint reasoning distributions, and (c) models with controlled synthetic curricula to test whether CoS emerges without explicit reasoning supervision.
- Sampler and schedule robustness: Systematically vary sampler (ODE/SDE solvers, DPM-Solver, Heun, Euler), noise schedules, step counts, and guidance schedules to determine if CoS persists and to identify the “critical step window” in normalized time (e.g., as a fraction of total steps).
- Flow matching vs DDPM: Assess whether CoS properties (multi-path exploration, step sensitivity) persist under standard DDPM training and other transport objectives beyond flow matching.
- Temporal length and resolution scaling: Test CoS under longer videos, higher frame counts, higher resolutions, and moving-camera settings to examine memory stability, reasoning persistence, and computational scaling.
- Real-world task generalization: Move beyond synthetic puzzles to physics, causal reasoning, and commonsense tasks in natural scenes; quantify transfer to OOD distributions without domain-specific finetuning.
- Quantifying multi-path and superposition: Develop objective metrics to detect, count, and score “parallel hypotheses” across steps; validate that these are not mere denoising blur artifacts by correlating early multi-path extent with final correctness.
- Distinguishing “reasoning” from smoothing: Design counterfactual controls (e.g., generative baselines trained without reasoning tasks) to verify that observed superpositions reflect structured alternatives rather than generic denoising uncertainty.
- Perturbation breadth: Extend noise experiments to per-layer, per-token, and cross-attention-only corruptions; vary noise magnitudes and types (masking, shuffling, dropout) to map sensitivity across steps, frames, and modules.
- Temporal attention necessity: Causally test the “all-frames-at-each-step” claim by constraining temporal attention (causal, local windows, sparsity) and measuring the impact on CoS signatures and performance.
- Text-conditioning pathway: Analyze where and when prompt semantics enter and persist (cross-attention ablations per layer/step, guidance scale sweeps); probe whether instruction content is retained across steps (text-token linear probes, attention rollout).
- VAE/decoder confounds: Replicate CoS visualizations directly in latent space and with different decoders to rule out decoder blur as the source of apparent superposition or multi-path behavior.
- Layer specialization causality: Replace visualization with stronger causal tests (systematic layer-wise re-initialization, pruning, adapters, low-rank swaps across many tasks) and linear probes for object identity, spatial relations, and action plans.
- Step–layer interaction maps: Build a 2D sensitivity map over diffusion steps × transformer layers to identify minimal sufficient “reasoning bands” and to test whether specialization shifts with task type or input complexity.
- Working memory limits: Characterize capacity and decay of “persistent anchors” under occlusions, distractors, long horizons, and clutter; measure retention as a function of step index and video length.
- Perception-before-action boundary: Devise automatic detectors for the transition point (e.g., change-point tests on probe accuracy or activation statistics), and study how its timing varies with task difficulty or prompt ambiguity.
- Self-correction prevalence and triggers: Quantify how often and under what conditions “aha” reversals occur; test interventions (e.g., guidance schedules, controlled noise injections) that amplify or suppress self-correction.
- From observation to training: Explore training-time objectives that exploit CoS (e.g., intermediate step supervision, path-consistency or hypothesis-diversity regularizers, memory preservation losses) rather than only inference-time ensembling.
- Ensemble design space: Systematically study number of seeds, ensembling layers, step windows, spatial-temporal pooling strategies, and late-step vs early-step aggregation; report compute–accuracy tradeoffs and failure modes.
- Cross-model ensembles: Test ensembling across different model initializations or architectures (not just seeds of the same model) and measure complementarity vs interference in latent-space fusion.
- Statistical rigor and error analysis: Add confidence intervals, significance tests across many seeds/prompts, and per-category error analyses (especially where scores decreased) to validate claims and diagnose regressions.
- Information flow metrics: Complement CKA with alternative measures (mutual information, representational dissimilarity, Fisher information, Jacobian-based attributions) and specify the exact representations used for reproducibility.
- Robustness to adversarial or hard cases: Evaluate CoS stability under adversarial prompts, ambiguous instructions, distractor objects, and conflicting constraints; measure brittleness of step-wise reasoning.
- Reproducibility and accessibility: Release code for step-wise decodings, hooks, and perturbations; provide models or surrogates (if proprietary) so the community can replicate and extend the analyses.
Practical Applications
Overview
Below is an overview of practical, real-world applications that follow from the paper’s findings on Chain-of-Steps (CoS) reasoning in diffusion-based video models, the emergent behaviors (working memory, self-correction, perception-before-action), the layer-wise functional specialization, and the training-free latent-trajectory ensemble. Applications are grouped into Immediate (deployable now) and Long-Term (requiring further research, scaling, or development). Each item includes sectors, potential tools or workflows, and key assumptions or dependencies.
Immediate Applications
The following applications can be implemented with current diffusion video generators and standard engineering effort, primarily by adding inference-time hooks, lightweight tooling, or workflow changes.
- Inference-time multi-seed latent ensembling to boost reasoning reliability
- Sectors: Media/entertainment, advertising, gaming, software tooling, robotics simulation
- What: Run identical models with different random seeds; average or merge mid-layer latents during early diffusion steps (e.g., layers 20–29 at step s≈0) to preserve multiple candidate reasoning paths and increase the chance of converging to correct outcomes.
- Tools/Workflows: “Reasoning Path Ensemble” plugin for DiT-based video models; batch orchestration to spawn N seeds; mid-layer latent aggregator; auto-select best take via task-specific scoring (e.g., VBVR metrics).
- Assumptions/Dependencies: Access to internal latents and layer hooks; increased compute (∼2–3× per seed); model behavior similar to VBVR-Wan2.2; quality gains are task- and model-dependent.
- Step-wise latent visualization for debugging, QA, and prompt engineering
- Sectors: Software tooling, research, education, enterprise AI platform teams
- What: Decode estimated clean latent at each diffusion step; visualize layer activation heatmaps to observe “perception before action,” multi-path exploration, and self-correction; use these to refine prompts or constraints.
- Tools/Workflows: “Video Reasoning Inspector” dashboards (per-step decoded frames, layer activation heatmaps, token energy maps); prompt-edit loops aligned to step dynamics.
- Assumptions/Dependencies: Model introspection capability; VAE decoder access; reproducible hooks to capture features per step.
- Step-level robustness testing via noise injection (QA)
- Sectors: Model evaluation and QA, safety auditing, vendor benchmarking
- What: Systematically inject noise at specific diffusion steps vs. frames to identify critical steps and failure modes; prioritize protections around sensitive windows (e.g., steps 20–30).
- Tools/Workflows: “Step Noise Sensitivity” harness; CKA-based information-flow reports; regression tests integrated into CI.
- Assumptions/Dependencies: Ability to perturb latents by step/frame; model-dependent sensitivity ranges; benchmark tasks (VBVR-Bench or similar).
- Sampling schedule and compute allocation tuning around reasoning-critical steps
- Sectors: Engineering, platform optimization
- What: Allocate more denoising iterations, higher precision, or stronger guidance (CFG) in the mid-step window where conclusions solidify; reduce compute in late steps that mostly consolidate.
- Tools/Workflows: Dynamic sampler profiles; step-aware CFG/guidance curves; A/B tests to maximize accuracy per unit compute.
- Assumptions/Dependencies: Model’s critical windows vary by architecture and training; requires profiling.
- Step-aware constraint injection for task compliance (lightweight steering without retraining)
- Sectors: Media production, enterprise content pipelines
- What: Apply classifier-free guidance or auxiliary masks selectively during middle denoising steps to enforce constraints (e.g., object placement, motion path).
- Tools/Workflows: “Mid-step Guidance” controllers that activate only after perception settles; task-specific constraint maps (e.g., layout masks).
- Assumptions/Dependencies: Some model control interfaces exist (CFG, masking); steering strength must be tuned to avoid overshoot artifacts.
- Interactive education demos that reveal reasoning dynamics
- Sectors: Education, STEM outreach, cognitive science demos
- What: Show multi-hypothesis exploration and pruning in maze-solving, object selection, rotations, and pattern completion—helping learners grasp search and decision-making processes.
- Tools/Workflows: Web demos of per-step decoding and layer activities; curriculum content illustrating CoS vs. CoF.
- Assumptions/Dependencies: Open-source or licensed models with enough fidelity; curated, safe tasks.
- Synthetic data generation leveraging multi-hypothesis exploration
- Sectors: Robotics sim, RL pretraining, perception model augmentation
- What: Use early-step superpositions/multi-paths to produce diverse trajectories and scene outcomes for training downstream models.
- Tools/Workflows: Seed ensembles to generate variant motion plans or object arrangements; post-filtering via task validators.
- Assumptions/Dependencies: Physical plausibility remains imperfect; must apply validators or physics-based checks.
- Audit trace logging of intermediate latents for compliance and reproducibility
- Sectors: Enterprise AI governance, regulated industries (e.g., media compliance)
- What: Archive step-wise latents, activations, and seed metadata to support reproducibility and post-hoc analysis of decisions.
- Tools/Workflows: “Step Trace Logger” integrated in inference pipeline; audit reports linking decisions to step windows.
- Assumptions/Dependencies: Storage overhead; privacy and IP considerations; internal policy alignment.
Long-Term Applications
The following applications require architectural extensions, training-time changes, physics grounding, integration with other systems, or policy standardization.
- Training-time CoS-aware curricula and losses
- Sectors: Model development, foundation model training
- What: Explicitly teach models to maintain hypotheses early, reason in mid-layers, and consolidate late—e.g., losses focused on mid-layer correctness and temporal consistency.
- Tools/Workflows: “Reasoning-aware schedulers,” mid-layer supervision, multi-hypothesis retention objectives.
- Assumptions/Dependencies: Access to large-scale video reasoning datasets; significant compute; careful regularization to avoid mode collapse.
- Step-conditioned control modules (“reasoning controllers”)
- Sectors: Robotics, simulation, video editing, interactive content
- What: New control nets that attach to middle layers to guide choices (paths, selections, rotations) once perception stabilizes.
- Tools/Workflows: Cross-attention controllers activated in steps where reasoning peaks; task-specific constraints injected programmatically.
- Assumptions/Dependencies: Architectural changes; training with paired constraints; APIs for controller activation.
- Embodied AI planning via video models as internal simulators
- Sectors: Robotics, autonomous systems, industrial automation
- What: Use CoS multi-path exploration to plan and evaluate trajectories before acting, mirroring “perception before action” and rapid hypothesis pruning.
- Tools/Workflows: Closed-loop controller integrating step-aware video planning and execution policy; confidence monitors to switch plans.
- Assumptions/Dependencies: Real-time inference; physics grounding; safety certification; domain gap mitigation.
- Scenario generation for autonomous driving and safety analysis
- Sectors: Automotive, insurance, public safety testing
- What: Generate diverse, rare-edge-case scenarios by exploiting superposition and multi-path exploration; select plausible outcomes via physics/semantic validators.
- Tools/Workflows: Scenario banks with step-aware diversity measures; physics-informed filters; human-in-the-loop review.
- Assumptions/Dependencies: Strong validators; domain-specific realism; regulatory acceptance of synthetic test data.
- Healthcare training simulators (procedures, triage, device handling)
- Sectors: Healthcare education, medical device training
- What: Step-wise video planning to show multiple intervention paths, error self-correction, and outcome convergence in procedural simulations.
- Tools/Workflows: Clinical prompt libraries; validated scenario sets; tutor dashboards showing reasoning layers.
- Assumptions/Dependencies: Rigorous clinical validation; bias and safety guardrails; regulatory approval.
- Standards and policy for step-level transparency and auditing
- Sectors: Governance, compliance, safety policy
- What: Guidelines requiring retention and disclosure of intermediate latents/activations for high-stakes content or decision-making systems.
- Tools/Workflows: “Step Transparency” specs; audit APIs; third-party certification processes.
- Assumptions/Dependencies: Multi-stakeholder consensus; privacy/IP management; tooling maturity.
- Hardware and systems optimization for ensemble-heavy reasoning
- Sectors: Cloud providers, chip vendors, platform engineering
- What: Accelerators and schedulers optimized for parallel multi-seed early-step computation and latent aggregation.
- Tools/Workflows: Step-batched inference; memory-efficient latent sharing; high-throughput VAE decode.
- Assumptions/Dependencies: Vendor support; cost-benefit vs. single-seed improvements.
- Harmful content interception using early-step monitors
- Sectors: Trust & safety, content moderation
- What: Detect problematic trajectories while hypotheses are still superposed; apply corrective controllers or halt generation before consolidation.
- Tools/Workflows: Step-aware detectors; mid-step gating/fallback mechanisms; audit logs.
- Assumptions/Dependencies: Robust detectors; low false positives; scalable policy frameworks.
- Distillation of mid-layer reasoning into lighter models
- Sectors: Edge AI, mobile, AR/VR
- What: Capture the “reasoning core” from middle layers and distill into compact models for on-device planning or quick edits.
- Tools/Workflows: Layer-targeted distillation pipelines; teacher–student training with step-aware signals.
- Assumptions/Dependencies: Effective transfer of behaviors; performance trade-offs.
- CoS generalization to multimodal and cross-sensor settings
- Sectors: Audio-visual production, robotics (vision + proprioception), smart cities
- What: Extend step-wise reasoning dynamics to audio and sensor streams; coordinate perception-before-action across modalities.
- Tools/Workflows: Unified DiT architectures for multimodal latents; cross-modal controllers; evaluation suites.
- Assumptions/Dependencies: Model research; data availability; synchronization challenges.
Cross-cutting Assumptions and Dependencies
- Model access: Many immediate workflows require introspection (layer hooks, latent decoding) in DiT-based video models and compatible VAEs.
- Compute and cost: Multi-seed ensembles increase inference cost; ROI varies by task.
- Model specificity: Critical step windows (e.g., steps 20–30) and layer indices are architecture- and training-dependent; profiling is necessary.
- Task domains: Physical plausibility and commonsense remain challenging; validators and human oversight are needed for safety-critical applications.
- Data and benchmarks: Performance depends on task difficulty and benchmark choice (e.g., VBVR-Bench); standardized evaluations improve comparability.
- Governance: Archiving intermediates raises privacy/IP concerns; policies must balance transparency with protection.
Glossary
- Bidirectional attention: An attention mechanism that attends over the entire sequence in both directions, enabling global context aggregation at each step. "Due to bidirectional attention over the entire sequence, reasoning is performed across all frames simultaneously at each denoising step, with intermediate hypotheses progressively refined as the process unfolds."
- Chain-of-Frames (CoF): A hypothesized mechanism where reasoning unfolds sequentially across video frames. "Prior work attributes this to a Chain-of-Frames (CoF) mechanism, where reasoning is assumed to unfold sequentially across video frames."
- Chain-of-Steps (CoS): The proposed mechanism where reasoning primarily emerges along diffusion denoising steps rather than across frames. "we find that models explore multiple candidate solutions in early denoising steps and progressively converge to a final answer, a process we term Chain-of-Steps (CoS)."
- CKA dissimilarity: A representational dissimilarity measure (Centered Kernel Alignment) used to quantify changes in internal activations. "We visualize CKA dissimilarity \cite{kornblith2019similarity}, where 1.0 indicates complete corruption and 0.0 indicates no effect."
- Clean latent (): The model’s estimate of the denoised latent state at a given step. "we examine the estimated clean latent at each diffusion step ."
- Classifier-Free Guidance (CFG): A guidance technique that steers generation by contrasting conditional and unconditional predictions; here referenced via its inference pass. "We specifically capture the hidden states from the first forward pass (the positive CFG pass) to isolate the model's primary reasoning trajectory."
- Denoising trajectory: The path through latent space traced as noise is removed step by step during generation. "Chain-of-Steps (CoS), a reasoning process that unfolds along the denoising trajectory."
- Diffusion denoising steps: Iterative stages in diffusion models where noise is progressively removed to form structured outputs. "We show that reasoning in video models instead primarily emerges along the diffusion denoising steps."
- Diffusion Transformers (DiTs): Transformer-based architectures adapted for diffusion generative modeling. "the emergence of Diffusion Transformers (DiTs)~\cite{dit_peebles2023scalable} has enabled effective scaling of data and model size."
- Flow matching: A training framework where the model learns a vector field to transport noise to data along a continuous path. "When trained with flow matching\cite{lipman2022flow}, the latent evolves along a continuous transport path between noise and data:"
- Functional specialization (within Diffusion Transformers): The emergent division of labor across layers, with early layers focusing on perception and later layers on reasoning and consolidation. "we further uncover self-evolved functional specialization within Diffusion Transformers, where early layers encode dense perceptual structure, middle layers execute reasoning, and later layers consolidate latent representations."
- Latent trajectory: The sequence of latent states explored during generation, here used for ensembling. "reasoning can be improved by ensembling latent trajectories from identical models with different random seeds."
- Latent workspace: The internal latent space where multiple hypotheses are temporarily maintained during early steps. "the model populates the latent workspace with multiple hypotheses."
- Layer-wise latent swapping: An intervention that replaces latent representations at a specific layer to study causal effects on outputs. "we conduct a layer-wise latent swapping experiment on object recognition and grounding tasks at the first diffusion step."
- Model Soup: A technique of averaging parameters from multiple models in the same basin to improve performance. "Inspired by Model Soup~\cite{2022modelsoups}, which merges models within the same optimization basin, we implement a multi-seed ensemble at the latent level during the early diffusion steps that are critical for the reasoning trajectory (\cref{sec:noise_perturbation})."
- Multi-path exploration: A reasoning mode where the model concurrently explores several possible solutions before pruning down to one. "By analyzing intermediate latent predictions at each step, we move beyond the "Chain-of-Frames" (CoF) temporal analogy and identify two distinct modes of Step-wise Reasoning: Multi-path Exploration and Superposition-based Exploration."
- Multi-seed ensemble: An inference-time strategy that aggregates outputs from runs with different random seeds to stabilize reasoning. "we implement a multi-seed ensemble at the latent level during the early diffusion steps that are critical for the reasoning trajectory"
- Noise at Frame: A perturbation scheme injecting Gaussian noise into a specific frame across all steps to test robustness. "2) "Noise at Frame": ."
- Noise at Step: A perturbation scheme injecting Gaussian noise into all frames at a specific diffusion step to disrupt the process. "1) "Noise at Step": ."
- Noise scale (): A per-step scalar controlling the magnitude of noise/perturbation during diffusion. "The noise scale controls the magnitude of perturbation at each step."
- Patch embedding: The layer that converts spatiotemporal patches into token embeddings for transformer processing. "grid dimensions captured from the model's patch_embedding layer"
- Perception before action: An emergent pattern where the model first grounds objects and then performs reasoning/manipulation. "perception before action, where early steps establish semantic grounding and later steps perform structured manipulation."
- Semantic grounding: The process of correctly identifying and locating target entities before manipulating them. "early steps establish semantic grounding and later steps perform structured manipulation."
- Superposition-based exploration: A reasoning mode where multiple mutually exclusive hypotheses are temporarily represented simultaneously. "Another distinctive mode observable along the diffusion trajectory is superposition-based exploration, where the model temporarily represents multiple mutually exclusive logical states simultaneously."
- Token representations: The internal vector embeddings corresponding to spatiotemporal patches that the transformer processes. "We further conduct a fine-grained analysis of the Diffusion Transformer by examining token representations within a single diffusion step."
- Transport path: The continuous interpolation between noise and data along which latent states evolve during training/inference. "the latent evolves along a continuous transport path between noise and data:"
- Velocity field: The learned vector field that dictates how latent variables move along the transport path. "The model learns a velocity field conditioned on prompt , describing how the latent moves along this trajectory."
- Vision tokens: Discrete tokenized representations of video patches used by the transformer. "Let represent the latent representations (vision tokens) at layer of the transformer backbone."
- Working memory: The model’s ability to maintain salient information across denoising steps for consistent reasoning. "First, these models exhibit a form of working memory that is crucial for tasks requiring persistent references (\eg, object permanence)."
- Zero-shot learners: Models that can perform tasks without task-specific training or examples. "treating them as zero-shot learners operating a in spatiotemporal environments~\cite{wiedemer2025video, thinkwithvideo_tong2025thinking, rulerbench_he2025ruler}."
Collections
Sign up for free to add this paper to one or more collections.